非抢占式RCU中的一些概念
该记录着重介绍下:2.6.34版本中非抢占式RCU的基本概念。
RCU保护的是指针,因为指针的赋值可以使用原子操作完成;
在非抢占式RCU中:
对于读者,RCU仅需要抢占失效,因此获得读锁和释放读锁分别定义为: 对于非抢占式RCU,在操作读取数据的过程中不允许进程切换,否则因为写者需要等待读者完成,写者进程也会一直被阻塞。 #define rcu_read_lock() preempt_disable() #define rcu_read_unlock() preeempt_enable() 变种: #define rcu_read_lock_bh() local_bh_disable() #define rcut_read_unlock_bh() local_bh_enable() 每个变种只在修改是通过call_rcu_bh进行的情况下使用,因为call_rcu_bh将把softirq的执行完毕也认为是一个quiescent state,因此如果修改是通过call_rcu_bh进行的,在进程上下文的读段临界区必须使用这一变种)。 rcu_dereference(p)相当于p rc_assign_pointer(p, v)相当于p = v;
注意,关于写者:
写者在访问被RCU保护的共享数据时不需要和读者竞争任何锁,只有在有多于一个写者的情况下需要获得某种锁以与其它写者同步。
写者修改数据前先拷贝一个被修改元素的副本,然后在副本上进行修改,修改完毕后将向垃圾回收器注册一个回调函数以便在适当的时机执行真正的修改操作。
如何判断当前的一个读者已经完成了相应的读操作?
grace period 与 quiescent state的定义:
grace period(宽限期): The time waits for any currently executing RCU read-side critical sections to complete, and the length of this wait is known as a "grace period". quiescent state(静默状态): CPU发生了上下文切换称为经历一次quiescent state grace period就是所有CPU都经历一次quiescent state所需要的等待时间。因为对于非抢占式RCU机制而言,当所有CPU都经过quiescent state就意味着所有读者完成了对共享临界区的访问。
垃圾收集器在grace period之后调用写者注册的回调函数来完成真正的数据释放、唤醒线程等操作。
下图,引述自:http://blog.csdn.net/junguo/article/details/8244530
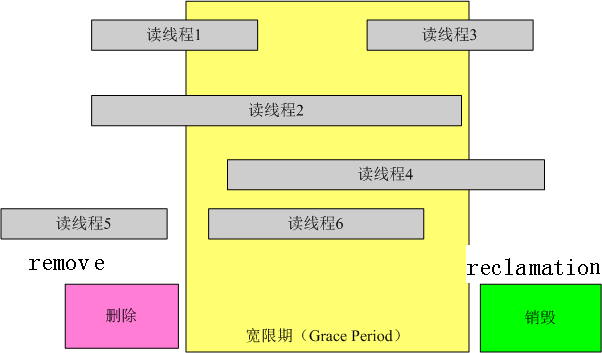
对图中的remove(删除)与reclamation(销毁),RCU作者本人做了解释:
The basic idea behind RCU is to split updates into "removal" and "reclamation" phases. The removal phase removes references to data items within a data structure (possibly by replacing them with references to new versions of these data items), and can run concurrently with readers. The reason that it is safe to run the removal phase concurrently with readers is the semantics of modern CPUs guarantee that readers will see either the old or the new version of the data structure rather than a partially updated reference. The reclamation phase does the work of reclaiming (e.g., freeing) the data items removed from the data structure during the removal phase. Because reclaiming data items can disrupt any readers concurrently referencing those data items, the reclamation phase must not start until readers no longer hold references to those data items. Splitting the update into removal and reclamation phases permits the updater to perform the removal phase immediately, and to defer the reclamation phase until all readers active during the removal phase have completed, either by blocking until they finish or by registering a callback that is invoked after they finish. Only readers that are active during the removal phase need be considered, because any reader starting after the removal phase will be unable to gain a reference to the removed data items, and therefore cannot be disrupted by the reclamation phase. So the typical RCU update sequence goes something like the following: a、Remove pointers to a data structure, so that subsequent readers cannot gain a reference to it. b、Wait for all previous readers to complete their RCU read-side critical sections. c、At this point, there cannot be any readers who hold references to the data structure, so it now may safely be reclaimed (e.g., kfree()d).
非抢占式RCU的优缺点,以及引入RCU机制给优先级带来的问题:
引述自:http://lwn.net/Articles/263130/
Advantages of RCU include performance, deadlock immunity, and realtime latency.
There are, of course, limitations to RCU, including the fact that readers and updaters run concurrently, that low-priority RCU readers can block high-priority threads waiting for a grace period to elapse, and that grace-period latencies can extend for many milliseconds.
RCU与seqlock的不同:
Although seqlock readers can run concurrently with seqlock writers, whenever this happens, the read_seqretry() primitive will force the reader to retry. This means that any work done by a seqlock reader running concurrently with a seqlock updater will be discarded and redone. So seqlock readers can run concurrently with updaters, but they cannot actually get any work done in this case.
RCU类似于“强引用计数机制”
Because grace periods are not allowed to complete while there is an RCU read-side critical section in progress, the RCU read-side primitives may be used as a restricted reference-counting mechanism. The effect is that if any RCU-protected data element is accessed within an RCU read-side critical section, that data element is guaranteed to remain in existence for the duration of that RCU read-side critical section.
RCU机制不是简单的等待事件完成
One of RCU's great strengths is that it allows you to wait for each of thousands of different things to finish without having to explicitly track each and every one of them, and without having to worry about the performance degradation, scalability limitations, complex deadlock scenarios, and memory-leak hazards that are inherent in schemes that use explicit tracking.