面试文档(自用)
Redis知识
Redis为什么这么快
Redis为什么这么快
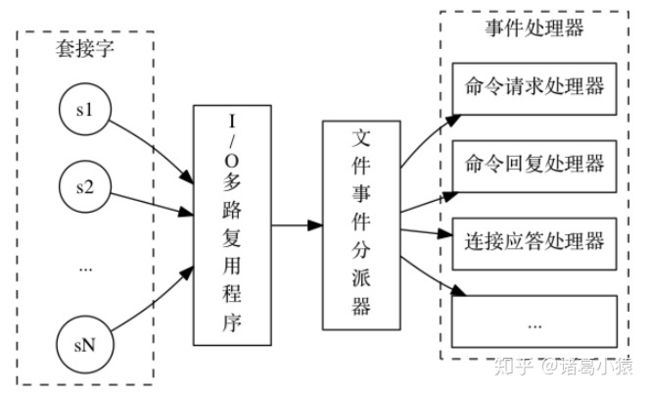
答案:
- redis是纯内存操作:数据存放在内存中,内存的响应时间大约是100纳秒,这是Redis每秒万亿级别访问的重要基础。
- 非阻塞I/O:Redis采用epoll做为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间。
- 单线程避免了线程切换和竞态产生的消耗。
Redis采用单线程模型,每条命令执行如果占用大量时间,会造成其他线程阻塞,对于Redis这种高性能服务是致命的,所以Redis是面向高速执行的数据库
Redis的主要缺点是数据库容量受到物理内存的限制,不能作海量数据的高性能读写,因此Redis适合的场景主要局限在较小的数据量的高性能操作和运算。
Redis系列之 缓存穿透,缓存击穿,缓存雪崩
Redis系列之 缓存穿透,缓存击穿,缓存雪崩
-
缓存穿透:
是指缓存和数据库中没有数据,而用户不断发起请求,过多的请求会导致数据库压力过大而宕机。
- 解决方法:Cache null策略,布隆过滤器
-
缓存击穿
是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
- 解决办法:设置热点数据不过期,分布式锁
-
缓存雪崩
是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
- 解决办法:数据预热,缓存过期时间随机,Redis集群
Redis有哪几种数据结构
Redis支持5种数据类型:String(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、 Bitmap 、HyperLogLog 、 Geospatial
-
String一个
key对应一个valueString类型是二进制安全的,因此redis的string可以包含任何数据,比如jpg图片或者序列化对象String类型的值最大能存储512MB常用命令:
get、set、decr、incr、mget等 -
hashhash是一个键值对集合:是一个String类型的field和value的映射表hash特别适合用于存储对象每个
hash可存储2^(32-1)键值对常用命令:
hget、hset、hgetall等 -
listlist是一个简单的字符串列表、按照插入顺序排序,你可以添加一个元素到列表的头部或者尾部list类型经常会被用于消息队列的服务、以完成多程序之间的消息交换列表最多可存储
2^(32-1)个元素常用命令:
lpush、rpush、lpop、rpop、lrange等 -
setset也是一个字符串列表,和列表不同的是,在插入和删除时会判断是否存在了该元素。集合的最大的优势在于可以进行交集并集差集操作。集合是通过hash表实现的,因此,添加,删除,查找的复杂度都是o(1)应用场景:
- 利用交集求共同好友。
- 利用唯一性,可统计访问网站的所有独立
IP。 - 好友推荐的时候根据
tag求交集,大于某个thresold就可以推荐
集合最多可存储
2^(32-1)个元素常用命令:
sadd、spop、smembers、sunion等 -
zset和
set一样是String类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数却可以重复。应用场景:
- 例如存储全班同学的成绩,其集合
value可以是同学的学号、而score就可以是成绩 - 排行榜应用,根据得分列出
topN的用户等。
常用命令:
zadd、zrange、zrem、zcard等 - 例如存储全班同学的成绩,其集合
-
Bitmap通过操作二进制位记录数据。
-
HyperLogLog被用于估计一个set中元素数量的概率性数据结构
-
Geospatial被用于地理空间关系计算
Redis的淘汰策略
六种淘汰策略
volatile-lru:从设置了过期时间的数据集中,选择最近最久未使用的数据释放
allkeys-lru:从数据集中(包括设置过期时间以及未设置过期时间的数据集中释放),选择最近最久未被使用的数据释放
volatile-random:从设置了过期时间的数据集中,随机选择一个数据进行释放
allkeys-random:从数据集中(包括了设置过期时间以及未设置过期时间)随机选择一个数据进行入释放
volatile-ttl:从设置了过期时间的数据集中,选择马上就要过期的数据进行释放操作;
noeviction:不删除任意数据(但redis还会根据引用计数器进行释放),这时如果内存不够时,会直接返回错误。
默认的内存策略是noeviction,在Redis中LRU算法是一个近似算法,默认情况下,Redis随机挑选5个键,并且从中选取一个最近最久未使用的key进行淘汰,在配置文件中可以通过maxmemory-samples的值来设置redis需要检查key的个数,但是检查的越多,耗费的时间也就越久,但是结构越精确(也就是Redis从内存中淘汰的对象未使用的时间也就越久~),设置多少,综合权衡。
**一般来说,推荐使用的策略是volatile-lru,并辨识Redis中保存的数据的重要性。**对于那些重要的,绝对不能丢弃的数据(如配置类数据等),应不设置有效期,这样Redis就永远不会淘汰这些数据。对于那些相对不是那么重要的,并且能够热加载的数据(比如缓存最近登录的用户信息,当在Redis中找不到时,程序会去DB中读取),可以设置上有效期,这样在内存不够时Redis就会淘汰这部分数据。
Redis的持久化
Redis的持久化策略有两种:
-
RDB:快照形式是直接把内存中的数据保存到一个dump文件中,定时保存。 -
AOF:把所有的对Redis的服务器进行修改的命令都存在一个文件里,命令的集合 -
RDB的优缺点:
-
优点:
- 对性能的影响最小,
Redis在保存RDB快照时会fork出子进程进行,几乎不影响Redis处理客服端请求的效率。 - 每次快照都会生成一个完整的数据快照文件,所以**可以辅助其他手段保存多个时间点的快照(**例如把每天0点的快照备份至其他存储媒介中)
- 作为非常可靠的灾难恢复手段。使用
RDB文件进行数据恢复要比使用AOF要快很多。
- 对性能的影响最小,
-
缺点:
- 快照是定期生成的,所以在
Redis crash时或多或少会丢失一部分数据 - 如果数据集非常大且
cpu不够强(比如单核cpu),Redis在fork子进程时可能会消耗相对较长的时间,影响Redis对外提供服务的性能。
- 快照是定期生成的,所以在
-
AOF的原理
AOF提供了三种
fsync配置,always/everysec/no,通过配置项[appendfsync]指定:appendfsync no:不进行fsync,将flush文件的时机交给OS决定,速度最快appendfsync always:每写入一条日志就进行一次fsync操作,数据安全性最高,但速度最慢appendfsync everysec:折中的做法,交由后台线程每秒fsync一次随着
AOF不断地记录写操作日志,因为所有的操作都会记录,所以必定会出现一些无用的日志。大量无用的日志会让AOF文件过大,也会让数据恢复的时间过长。不过Redis提供了AOF rewrite功能,可以重写AOF文件,只保留能够把数据恢复到最新状态的最小写操作集。AOF rewrite可以通过BGREWRITEAOF命令触发,也可以配置Redis定期自动进行:auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb上面两行配置的含义是,
Redis在每次AOF rewrite时,会记录完成rewrite后的AOF日志大小,当AOF日志大小在该基础上增长了100%后,自动进行AOF rewrite。同时如果增长的大小没有达到64mb,则不会进行注意:
Rewrite原理 : AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename)。遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
-
AOF的优缺点
-
优点:
- 最安全,在启用
appendfsync always时,任何已写入的数据都不会丢失,使用在启用appendfsync everysec也至多只会丢失1秒的数据。AOF文件在发生断电等问题时也不会损坏,即使出现了某条日志只写入了一半的情况,也可以使用redis-check-aof工具轻松修复。AOF文件易读,可修改,在进行了某些错误的数据清除操作后,只要AOF文件没有rewrite,就可以把AOF文件备份出来,把错误的命令删除,然后恢复数据。
- 最安全,在启用
-
缺点:
-
AOF文件通常比RDB文件更大性能消耗比RDB高数据恢复速度比RDB慢Redis的数据持久化工作本身就会带来延迟,需要根据数据的安全级别和性能要求制定合理的持久化策略:AOF + fsync always的设置虽然能够绝对确保数据安全,但每个操作都会触发一次fsync,会对Redis的性能有比较明显的影响AOF + fsync every second是比较好的折中方案不过大多数应用场景下,建议至少开启
RDB方式的数据持久化。Redis对于数据备份是非常友好的, 因为你可以在服务器运行的时候对RDB文件进行复制:RDB文件一旦被创建, 就不会进行任何修改。 当服务器要创建一个新的RDB文件时, 它先将文件的内容保存在一个临时文件里面, 当临时文件写入完毕时, 程序才使用rename(2)原子地用临时文件替换原来的RDB文件。
-
Redis的过期策略
1.设置过期时间
- expire key time—这是最常用的方式
- setex(String key,int seconds,String value) —字符串独有的方式
注意:
- 除了字符串自己独有设置过期时间的方法外,其他方法都需要依靠expire方法来设置时间
- 如果没有设置时间,那缓存就是永不过期
- 如果设置了过期时间,之后又想让缓存永不过期,使用persist key
2.三种过期策略
-
定时删除
- 含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
- 优点:保证内存被尽快释放
- 缺点:
- 若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
- 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
- 没人用
-
惰性删除
- 含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
- 优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
- 缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
-
定期删除
- 含义:每隔一段时间执行一次删除过期key操作
- 优点:
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用–处理"定时删除"的缺点
- 定期删除过期key–处理"惰性删除"的缺点
- 缺点
- 在内存友好方面,不如"定时删除"
- 在CPU时间友好方面,不如"惰性删除"
- 难点
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
3.Redis采用的过期策略
惰性删除+定期删除
- 惰性删除流程
- 在进行get或setnx(当key不存在时设置value)等操作时,先检查key是否过期
- 若过期,删除key,然后执行相应操作
- 若没过期,则直接执行相应操作
- 定期删除流程(简而言之,就是对指定个数的数据库的每一个库随机删除小于等于指定个数的过期key)
- 遍历每个数据库(redis.conf中配置的
database数量,默认为16)- 检查当前库中的指定个数个key(默认每个库检查20个key,相当于循环下面的操作20次)
- 如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
- 随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
- 判断定期删除操作是否已经到达时长,若已经到达,直接退出定期删除。
- 检查当前库中的指定个数个key(默认每个库检查20个key,相当于循环下面的操作20次)
- 遍历每个数据库(redis.conf中配置的
- 注意:
- 对于定期删除,在程序中有一个全局变量current_db来记录下一个将要遍历的库,假设有16个库,我们这一次定期删除遍历了10个,那此时的current_db就是11,下一次定期删除就从第11个库开始遍历,假设current_db等于15了,那么之后遍历就再从0号库开始(此时current_db==0)
4.RDB对过期key的处理
过期key对RDB没有任何影响
- 从内存数据库持久化数据到RDB文件
- 持久化key之前,会检查是否过期,过期的key不进入RDB文件
- 从RDB文件恢复数据到内存数据库
- 数据载入数据库之前,会对key先进行过期检查,如果过期,不导入数据库(主库情况)
5.AOF对过期key的处理
过期key对AOF没有任何影响
- 从内存数据库持久化数据到AOF文件:
- 当key过期后,还没有被删除,此时进行执行持久化操作(该key是不会进入aof文件的,因为没有发生修改命令)
- 当key过期后,在发生删除操作时,程序会向aof文件追加一条del命令(在将来的以aof文件恢复数据的时候该过期的键就会被删掉)
- AOF重写
- 重写时,会先判断key是否过期,已过期的key不会重写到aof文件
Redis管道
Redis是基于请求/响应协议的TCP服务,在客服端向服务器发送一个查询请求时,需要监听socket的返回,该监听过程一直阻塞,直到服务器有结果返回。由于Redis集群通常部署在不同服务器上,所以每次查询都会存在一定的网络延迟,多次请求的话可能会使延迟累加,使得Redis性能大大下降,因此Redis提出了管道技术
Redis管道技术,允许在服务器未响应的时候,连续多次发送多个请求,并最终一次性读取所有服务器的响应。这样能显著提升Redis的性能。
Redis事务
Redis支持分布式环境下的事务操作,其事务可以一次执行多个命令,事务中的所有命令都会序列化地顺序执行。
Redis的事务执行流程如下:
- 事务开启:客服端执行Multi命令开启事务
- 提交请求:客服端提交命令到事务
- 任务入队列:Redis将客服端请求放入事务队列中等待执行
- 入队状态反馈:服务器返回QURUD,表示命令已被放入事务队列
- 执行命令:客服端通过Exec执行事务
- 事务执行错误:在Redis事务中如果某条命令执行错误,则其他命令会继续执行,不会回滚。可以通过watch监控事务的执行状态并处理命令执行错误的异常情况。
- 执行结果反馈:服务器向客服端返回事务执行的结果。

| 命令 | 说明 |
|---|---|
| Multi | 标记一个事务块的开始 |
| Exec | 执行所有事务块内的命令 |
| Discard | 取消事务,放弃执行事务块内的所有命令 |
| Watch | 监视一个key,在事务执行之前如果这个key被其他命令改动,那么事务将被打断 |
| UnWatch | 取消watch命令对所有key的监视 |
Redis发布 订阅
Redis发布/订阅是一种消息通信模式,发送者(pub)向频道(Channel)发送消息,订阅者(Sub)接收频道上的消息。
Redis的集群模式及工作原理
Redis有三种集群模式:主从模式、哨兵模式、和集群模式。
(1)主从模式:
所有的写请求都被发送到主数据库上,再由主数据库将数据同步到从数据库上,主数据库主要用于执行写操作和数据同步,从数据库主要用于执行读操作,缓解系统的压力。
(2)哨兵模式
在主从模式上添加一个哨兵的角色来监控集群的运行状态。哨兵通过发送命令让Redis服务器返回其运行状态。哨兵是一个独立运行的进程,在监测到Master宕机时会自动将Slave切换成Master,然后通过发布/订阅模式通知其他从服务器修改其配置文件。完成主备热切。
(3)集群模式
Redis集群实现了在多个Redis节点之间进行数据分片和数据复制。
基于Redis集群的数据自动分片能力,我们能够方便的对Redis集群进行横向扩展,以提高Redis集群的吞吐量。
基于Redis集群的数据复制能力,在集群中的一部分节点失效或者无法进行通信时,Redis任然可以基于副本数据对外提供服务,这提高了集群的可用性。
Redis 集群数据复制的原理
1)若启动一个Slave机器进程,则它会向Master机器发送一个“sync command”命令,请求同步连接。
2)无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照保存到数据文件中(执行rdb操作),同时Master还会记录修改数据的所有命令并缓存在数据文件中。
3)后台进程完成缓存操作之后,Maste机器就会向Slave机器发送数据文件,Slave端机器将数据文件保存到硬盘上,然后将其加载到内存中,接着Master机器就会将修改数据的所有操作一并发送给Slave端机器。若Slave出现故障导致宕机,则恢复正常后会自动重新连接。
4)Master机器收到Slave端机器的连接后,将其完整的数据文件发送给Slave端机器,如果Mater同时收到多个Slave发来的同步请求,则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的Slave端机器,确保所有的Slave端机器都正常。
如果在主从复制过程中遭遇连接断开,则重新连接之后可以从中断处继续进行复制,而不必重新同步。
断点续传的工作原理具体如下。
主服务器端为复制流维护一个内存缓冲区(in-memory backlog)。主从服务器都维护一个复制偏移量(replication offset)和master run id。当连接断开时,从服务器会重新连接上主服务器,然后请求继续复制,假如主从服务器的两个master run id相同,并且指定的偏移量在内存缓冲区中还有效,则复制就会从上次中断的点开始继续。如果其中一个条件不满足,就会进行完全重新同步(在2.8版本之前就是直接进行完全重新同步)。
Redis 集群方案
1.codis
目前使用最多的集群方案,基本和twemproxy一致的效果,但它支持在结点数量改变的情况下,旧结点数据可恢复到新hash节点。
Codis分片机制:
Codis默认所有的key划分为1024个slot,对客户端传入的key做crc32运算计算hash值,再将hash后的整数值对1024取模获取key的slot。codis会在内存中维护slot与redis实例的对应关系。根据映射关系将数据转发到对应的实例。
codis集群通过对zk与etcd的支持来保证数据的一致性,如果是依赖zk,那么codisProxy的slot关系信息会存储在zk节点上,通过zk的监听机制来共享slot信息。
如何扩容:
进行扩容,意味着集群中增加新的redis实例,这时slot与实例的映射关系需要调整,意味着一部分数据需要进行迁移。
首先第一个问题是,我们需要找到槽位对应的所有key。codis增加了slotsscan命令,可以遍历指定slot下所有的key。然后挨个将每个key迁移到新的redis节点。迁移过程中,codis收到新请求,如果是查询key,那么会强制先完成迁移工作,然后再提供对外服务。
最后一点,迁移操作是一个move操作,即迁移完成后,旧实例中就不存在key了。
自动均衡机制:
redis新增实例,手动均衡slot比较麻烦,所以codis提供了自动均衡机制。自动均衡机制会在系统空闲时观察每个实例对应的slot数量,不平衡会自动进行迁移。
Codis的劣势
1.使用codis扩容的机器,redis不再支持事务。
2.rename这种危险的命令也不支持。官方文档中提供了不支持的命令列表。
3.为了支持迁移,单个key对应的value不宜过大。过大会导致迁移卡顿,官方建议小于1M,所以不适合存放社交关系数据等等。
4.网络开销比单个实例要大,性能略微下降。可以通过增加代理数量来弥补性能不足。
5.如果依赖zk,那么会增加zk运维成本。
Codis的优势
1.设计上比官方的redis cluster方案要简单。
2.托管给zk或者etcd,省去了分布式一致性逻辑。
问题:mget查询多个key的场景,codis会将key按照映射关系分组,然后对涉及的redis执行mget,最后由codis汇总返回。
分布式缓存设计的核心问题
缓存预热
指用户在请求数据前,先将数据加载到缓存系统中,用户查询事先被预热的缓存数据,以提高系统的查询效率。
缓存更新
缓存更新是指在数据变化后及时将变化后的数据更新到缓存中。常见的缓存更新策略有以下4种:
- 定时更新:定时将底层数据库的内容更新到缓存系统中
- 过期更新:将缓存种过期的数据更新为最新数据并更新缓存的过期时间
- 写请求更新:在用户有写请求时先写数据库同时更新缓存
- 读请求更新:有读请求时,如果缓存数据不存在或者过期,将底层数据库的查询结果更新到缓存中。
缓存淘汰策略
- FIFO(先进先出):判断被存储的时间,离目前最远的数据优先被淘汰
- LRU(最近被使用):判断缓存最近被使用的时间,距离当前时间最远的数据优先被淘汰。
- LFU(最不经常使用):在一段时间内,被使用次数最少的缓存优先被淘汰。
缓存雪崩
大量的缓存同一时间失效,造成数据库的压力过大进而可能发生宕机的现象。
解决办法:
- 请求加锁
- 失效更新
- 设置不同的失效时间
缓存穿透
缓存穿透是指由于缓存系统故障或者用户频繁查询系统中不存在的数据,导致请求穿过缓存系统不断发送到数据库,造成数据库过载的现象。
解决方法:
- 布隆过滤器:会过滤掉不存在数据请求的请求
- Cache null策略:在缓存中也缓存null这个数据。
缓存降级
是指由于访问量剧增,为保证核心业务的正常运行,减少或关闭非核心业务对资源的使用,常见的策略如下:
- 写降级:写请求增大,可以先只对Cache更新,事后在异步更新到数据库中。
- 读降级:只对Cache进行读取,并将结果返回给用户,适用于对数据实时性要求不高的场景。
Redis系列之事务及乐观锁
参考知乎文章
在redis中,是有事务的。但是redis的事务是弱事务。事务没有隔离级别,事务中的多条命令也不是原子性的
redis的事物使用有三步:
- 开启事物 (multi)
- 命令入队 (需要执行的命令写入队列,先进先出,队列中是一组命令。)
- 执行事物 (exec)
事物开启后,也可以取消事物(discard):
编译时报错,是因为队列中的命令本身有问题,导致在命令入队的时候就报错;有编译错误的时候,执行exec会提示失败,所有的命令都不能执行。
运行时错误,是入栈的命令本身没有错误,但是在出队执行的时候报错,比如对String做自增操作。
运行时报错了,但是事物不会回滚,而且,出错后不会影响后续的命令执行,只会有出错的那一条命令执行失败。所以,对于队列中的命令,是不存在原子性的。
redis的事物没有隔离性,
Redis使用watch实现了一个乐观锁。
Redis系列之分布式锁
redis系列之——分布式锁
什么是分布式锁
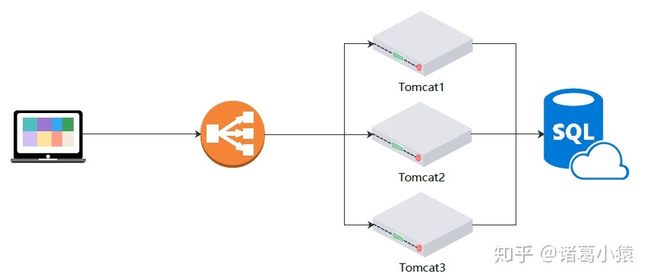
先说一个场景,消费者在购物网站上下单或收银员在POS机上下单,由于网络等问题,在连续点击了两下,后端网站如何处理,如何响应?对于这个问题,前端需要处理,后端也需要处理。这里主要说后端,后端不光要处理重复订单问题,还有处理幂等问题。幂等问题简单来说就是相同的请求,要有相同的响应结果,这里就不展开了。重复订单该如何处理?
对于一个小的访问量不大的网站,部署了一个tomcat,这个问题可以简单的通过JVM提供的同步锁synchronized实现。但是当网站访问量越来越大时,需要扩展机器,synchronized就不能起作用了。相同的下单参数连续两次请求后端服务器,可能会被分发到两个tomcat上,就会出现synchronized失效问题。
幂等操作:
在编程中,一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。例如,“getUsername()和setTrue()”函数就是一个幂等函数。用通俗的话讲:就是针对一个操作,不管做多少次,产生效果或返回的结果都是一样的
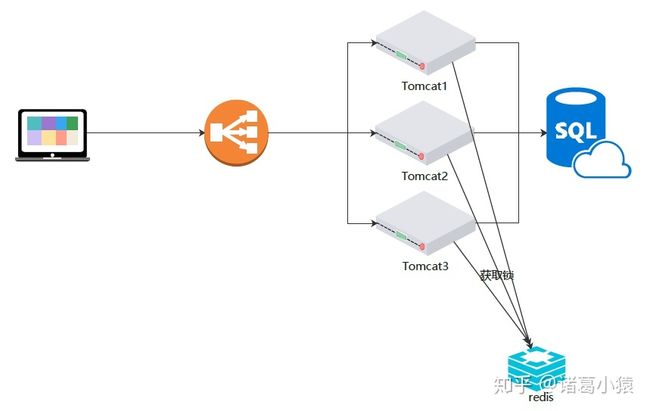
分布式锁要解决的就是多机器部署时,相同请求并发访问时资源竞争问题。请求到达每个tomcat时,首先要去redis中注册锁,注册成功返回true则说明获得了锁,可以继续处理相关的业务,处理完成后释放锁。同一时刻只能有一个tomcat能获得锁,其他没获得锁的tomcat则多次尝试继续获得锁,没有获得锁不能处理业务。获得锁的tomcat释放锁后,其他的tomcat才能有一个获得锁。
解决重复订单问题:
在请求进入方法前,加锁,往后的同一个请求(requestId相同)无法获取锁,就被判定为重复请求,抛出异常,等第一个请求调用完毕后再释放锁。
这里是使用redis做外部存储介质存储锁的,使用zookeeper也是类似的。万变不离其宗,原理都一样,只是技术选型有差别。
Redis系列之数据持久化(RDB和AOF)
Redis系列之数据持久化(RDB和AOF)
Redis数据类型之bitmaps
redis系列之——数据类型bitmaps:今天你签到了吗?
什么是bitmaps
来看看官方对Bitmaps的说明:
- Bitmaps 并不是实际的数据类型,而是定义在String类型上的一个面向字节操作的集合。因为字符串是二进制安全的块,他们的最大长度是512M,最适合设置成2^32个不同字节。
- bitmaps的位操作分成两类:1.固定时间的单个位操作,比如把String的某个位设置为1或者0,或者获取某个位上的值 2.对于一组位的操作,对给定的bit范围内,统计设定值为1的数目(比如人口统计)。
- bitmaps最大的优势是在存储数据时可以极大的节省空间,比如在一个项目中采用自增长的id来标识用户,就可以仅用512M的内存来记录40亿用户的信息(比如用户是否希望收到新的通知,用1和0标识)
简单来说bitmaps就是一个长度可变的bit数组。每个位只能存储0或1。我们先来看看bitmap的具体表示,当我们使用命令 setbit key (0,2,4,6) 1后,这个bit数组的具体表示为:
bit0bit1bit2bit3bit4bit5bit6bit710101010
一天的1亿人的登录情况(登录、未登录)就可以使用一个长度为1亿的bit数组存储,数组的索引就是用户的userId(假设userId是自增的)。
使用场景
由于bit数组的每个位置只能存储0或者1这两个状态;所以对于实际生活中,处理两个状态的业务场景就可以考虑使用bitmaps。如用户登陆/未登录,签到/未签到,关注/未关注,打卡/未打卡等。同时bitmap还通过了相关的统计方法进行快速统计。
由于bit数组的每个位置只能存储0或者1这两个状态;所以对于实际生活中,处理两个状态的业务场景就可以考虑使用bitmaps。如用户登陆/未登录,签到/未签到,关注/未关注,打卡/未打卡等。同时bitmap还通过了相关的统计方法进行快速统计。
内存占用比较
假如一个平台有8亿用户,平均日活跃用户有1亿,,分别使用List和Bitmap存储平台某一天是否活跃(登陆)用户时内存占用情况(1KB=1000bit):
数据类型每个userId占用空间需要存储的用户量内存使用总量List4 * 8bit=32bit(假设userId用的是int存储)100,000,00032bit * 100,000,000= 400MBBitmaps1bit800,000,0001bit * 800,000,000=100MB
假如一个平台有8亿用户,平均日活跃用户有100万,,分别使用List和Bitmap存储平台某一天是否活跃(登陆)用户时内存占用情况(1KB=1000bit):
数据类型每个userId占用空间需要存储的用户量内存使用总量List4 * 8bit=32bit(假设userId用的是int存储)1,000,00032bit * 1,000,000= 4MBBitmaps1bit800,000,0001bit * 800,000,000=100MB
所以并不是在所有的情况下,使用bitmap都是最好的选择。平台虽然有8亿用户,但是活跃的用户很少,这是使用Bitmaps,如果只有一个用户登录(加入是userId=800,000,000-1这个用户登录),也需要分配100MB的空间。
注意
bitmaps类型(string)最大长度为512M。 setbit时的偏移量很大时,可能会有较大耗时。 bitmaps不是绝对的好,有时可能更浪费空间。
Bloot Filter该怎么做,你是不是已经知道了?
完成,收工!!
Redis系列之数据类型geospatial
如何实现定位功能
说到定位,很多人第一反应应该是,实时上报经纬度,数据库中提前存储好所有的经纬度,然后用上报的经纬度和数据库中的经纬度进行比较,计算出附近的人或共享单车。这种做法需要循环遍历,数据库中的数据量大,查询慢,效率低。
那么,这些app是如何做到既能够精确定位,又能够实时查询的呢?答案就是使用geohash。redis的"数据类型"geospatial就能计算出geohash。redis使用geohash技术将实时上报的精度和纬度,通过一定的算法转化成最长12个字符的字符串,两个位置的经纬度计算的字符串的前缀越相同,则两个位置离得越近。这样一来就可以通过数据库的like加上geohash的前几位模糊查询数据库的数据了。比如ofo共享单车,数据库中用一张表t_bike专门存储ofo的每一辆车的编号no、经度longitude 、纬度latitude、geohash等字段,当每一辆车上报自己的经纬度时,同时计算一个geohash存到表中;当用户要用车时,上报用户的实时位置的经纬度,并计算一个hash值,比如hash=efgrtv98fjng,那么可以使用:
select * from t_bike where geohash like 'efgrtv98%'
就可以找到附近有多少车了。like后面使用的hash位数越多,查找的范围越准确。
查询的前提是开启实时定位功能。
Geohash技术
geohash技术就是将经纬度转换成最长12个字符的字符串,同时两个位置越近,生成的字符串的前缀越一致。这是如何实现的呢?
例如,东方明珠的经纬度,东经121.506377,北纬31.245105。
下面就以东方明珠为例,简单说一下如何将这两个经纬度计算成一个hash字符串的。
geohash的计算
1.使用二分法生成二进制
将纬度(-90,90)分成两个区间,(-90,0)和(0,90),如果目标纬度落在左边区间则记为0,否则记为1;再将目标纬度所在的那个区间在通过二分法分成两个相等的区间,如果目标纬度落在左边区间则记为0,否则记为1,以此类推。
同样的,将经度(-180,180)也通过这种方式计算。
最终,经度和纬度计算后,分别得到一个由0和1组成的二进制。
假如,东方明珠的经纬度计算后,得到两个二进制位:
经度:110101100101001110111100011010
纬度:101011000101010000110101100101
2.合并二进制
将上面的两个二进制按照“偶数位放经度,奇数位放纬度”的原则,从0位开始数起,合并成一个二进制。
可以理解成将纬度向后移动一位,然后将两行压成一行。
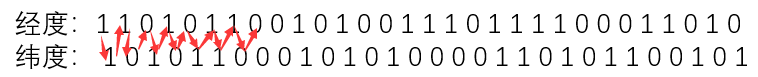
结果: 111001100111100000110011000110101000111110110001011010011001
3.二进制转换成十进制
把上面合并后的60位二进制,按照从左往右,每5位划分成1个组,如果最后一组如果不足5位就用0补齐到5位。分组后所示:
分组结果: 11100 11001 11100 00011 00110 00110 10100 01111 10110 00101 10100 11001
将上面的每组二进制分别转成十进制:
十进制结果: 28 25 28 3 6 6 20 15 22 5 20 25
4.十进制转base32字符串
使用base32编码表,将每个十进制数替换成编码表中的字符,获得一个字符串。
base32编码表如下:
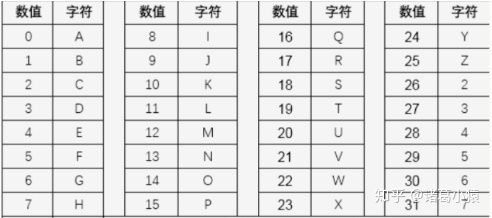
转化后的字符串:
base32字符串:4Z4CGGUPWFUZ
这就是模拟东方明珠的经纬度生产的geohash的值(不是真实值)。
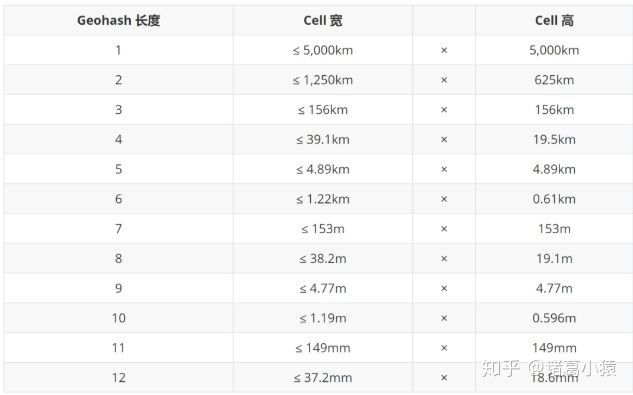
geohash的精度
geohash这个字符串在地图上表示一个矩形的块。
hash的字符串长1位-12位,对应精度的级别1-12级。字符串越长,位置越精确。
上面模拟的东方明珠的hash有12位字符串,精度在37mm以内。上面可以看出,6位hash的精度在1.2km以内。所以当两个hash的前6位相同时,就可以将范围缩小到1.2km以内了。在实际的应用中,我们就可以通过调整精度级别控制搜索的范围。
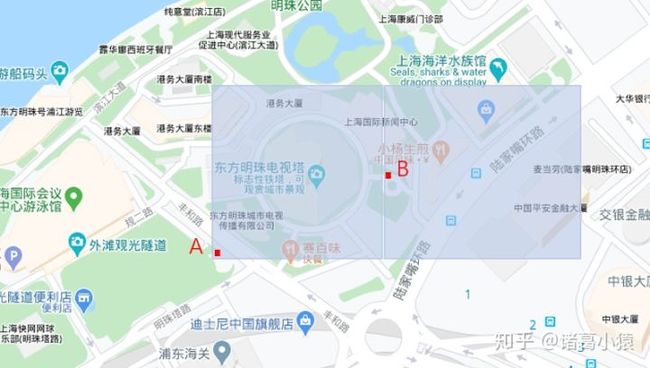
geohash的区块中,同一个区块内部的点被认为是最近的。如下图,如果你在东方明珠圆圈的中心,搜索最近的便利店,你会搜索到A点,而搜索不到B点,虽然B点是最近的。这就是geohash的边界问题。这个该如何解决呢?
其实,就是将该区块上下左右以及四个对角的8个区块的hash都计算一遍,分别计算这些便利店和自己之间的距离,找到最近的一家。因为这是的数据量已经非常小了,计算周边的8个块也很快。
redis> GEOADD china:city 121.47 31.23 shanghai #添加上海的经纬度
(integer) 1
redis> GEOADD china:city 116.40 39.90 beijing #添加北京的经纬度
(integer) 1
redis> GEODIST china:city shanghai beijing km #计算上海和北京之间的直线距离
"1067.3788"
redis> GEORADIUS china:city 116 39 1500 km #找到离经纬度为116,39的位置1500km以内的地方有哪些 ,因为redis中只有两个城市,所以只能显示两个
1) "beijing"
2) "shanghai"
redis> GEOHASH china:city beijing #获得北京的geohash
1) "wx4fbxxfke0"
Redis系列之一致性hash算法
redis系列之——一致性hash算法
Redis系列之高可用(主从、哨兵、集群)
Redis系列之高可用(主从、哨兵、集群)
一,主从模式
一般,系统的高可用都是通过部署多台机器实现的。redis为了避免单点故障,也需要部署多台机器。
因为部署了多台机器,所以就会涉及到不同机器的的数据同步问题。
为此,redis提供了Redis提供了复制(replication)功能,当一台redis数据库中的数据发生了变化,这个变化会被自动的同步到其他的redis机器上去。
redis多机器部署时,这些机器节点会被分成两类,一类是主节点(master节点),一类是从节点(slave节点)。一般主节点可以进行读、写操作,而从节点只能进行读操作。同时由于主节点可以写,数据会发生变化,当主节点的数据发生变化时,会将变化的数据同步给从节点,这样从节点的数据就可以和主节点的数据保持一致了。一个主节点可以有多个从节点,但是一个从节点会只会有一个主节点,也就是所谓的一主多从结构。
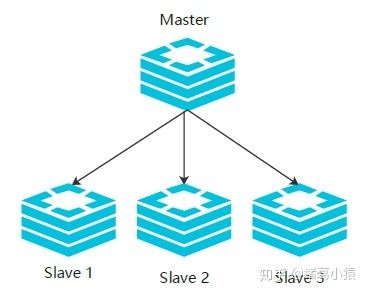
二, 哨兵模式
主从模式下,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这种方式并不推荐,实际生产中,我们优先考虑哨兵模式。这种模式下,master宕机,哨兵会自动选举master并将其他的slave指向新的master。
在主从模式下,redis同时提供了哨兵命令redis-sentinel,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵进程向所有的redis机器发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
哨兵可以有多个,一般为了便于决策选举,使用奇数个哨兵。哨兵可以和redis机器部署在一起,也可以部署在其他的机器上。多个哨兵构成一个哨兵集群,哨兵直接也会相互通信,检查哨兵是否正常运行,同时发现master宕机哨兵之间会进行决策选举新的master
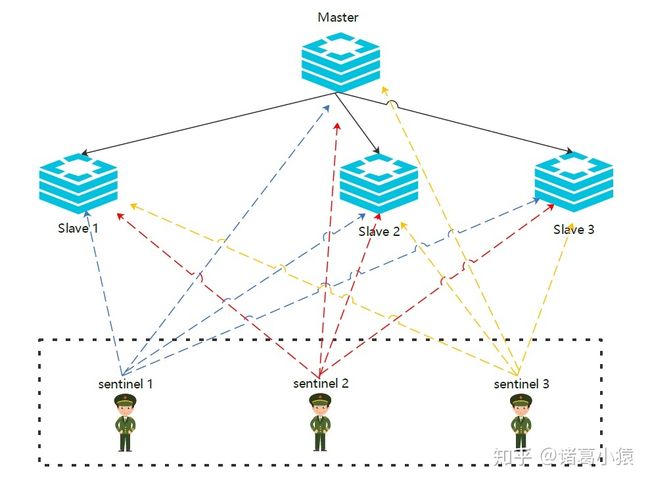
哨兵模式的作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器;
- 当哨兵监测到master宕机,会自动将slave切换到master,然后通过发布订阅模式通过其他的从服务器,修改配置文件,让它们切换主机;
- 然而一个哨兵进程对Redis服务器进行监控,也可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
哨兵很像kafka集群中的zookeeper的功能
三,集群模式
先说一个误区:Redis的集群模式本身没有使用一致性hash算法,而是使用slots插槽。这是很多人的一个误区。这里先留个坑,后面我会出一期《 redis系列之——一致性hash算法》。
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,对数据进行分片,也就是说每台 Redis 节点上存储不同的内容;
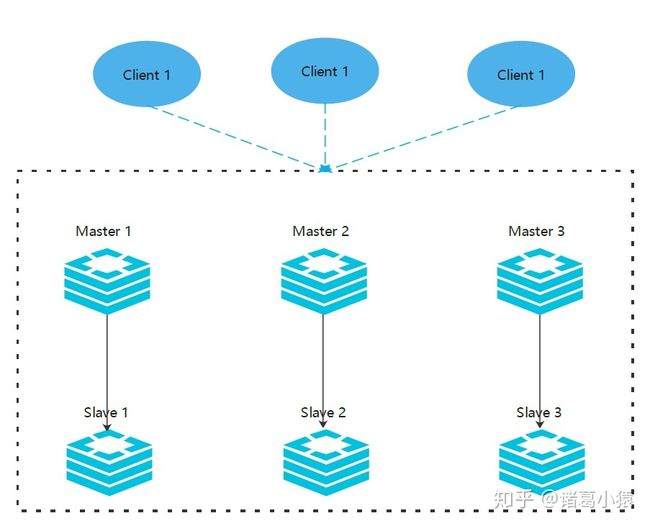
这里的6台redis两两之间并不是独立的,每个节点都会通过集群总线(cluster bus),与其他的节点进行通信。通讯时使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点儿像浏览器页面的302 redirect跳转。
根据官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。测试时,也可以在一台机器上部署这六个实例,通过端口区分出来。
3.4.运行机制
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383,可以从上面redis-trib.rb执行的结果看到这16383个slot在三个master上的分布。还有一个就是cluster,可以理解为是一个集群管理的插件,类似的哨兵。
当我们的存取的 Key到达的时候,Redis 会根据 crc16的算法对计算后得出一个结果,然后把结果和16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
当数据写入到对应的master节点后,这个数据会同步给这个master对应的所有slave节点。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点。当其它主节点ping主节点master 1时,如果半数以上的主节点与master 1通信超时,那么认为master 1宕机了,就会启用master 1的从节点slave 1,将slave 1变成主节点继续提供服务。
如果master 1和它的从节点slave 1都宕机了,整个集群就会进入fail状态,因为集群的slot映射不完整。如果集群超过半数以上的master挂掉,无论是否有slave,集群都会进入fail状态。
redis-cluster采用去中心化的思想,没有中心节点的说法,客户端与Redis节点直连,不需要中间代理层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
注:
对redis集群的扩容就是向集群中添加机器,缩容就是从集群中删除机器,并重新将16383个slots分配到集群中的节点上(数据迁移)。
3.8.集群模式的优缺点
优点
采用去中心化思想,数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布;
可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除;
高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升;
降低运维成本,提高系统的扩展性和可用性。
缺点
1.Redis Cluster是无中心节点的集群架构,依靠Goss协议(谣言传播)协同自动化修复集群的状态
但 GosSIp有消息延时和消息冗余的问题,在集群节点数量过多的时候,节点之间需要不断进行 PING/PANG通讯,不必须要的流量占用了大量的网络资源。虽然Reds4.0对此进行了优化,但这个问题仍然存在。
2.数据迁移问题
Redis Cluster可以进行节点的动态扩容缩容,这一过程,在目前实现中,还处于半自动状态,需要人工介入。在扩缩容的时候,需要进行数据迁移。
而 Redis为了保证迁移的一致性,迁移所有操作都是同步操作,执行迁移时,两端的 Redis均会进入时长不等的阻塞状态,对于小Key,该时间可以忽略不计,但如果一旦Key的内存使用过大,严重的时候会接触发集群内的故障转移,造成不必要的切换。
四、总结
主从模式:master节点挂掉后,需要手动指定新的master,可用性不高,基本不用。
哨兵模式:master节点挂掉后,哨兵进程会主动选举新的master,可用性高,但是每个节点存储的数据是一样的,浪费内存空间。数据量不是很多,集群规模不是很大,需要自动容错容灾的时候使用。
集群模式:数据量比较大,QPS要求较高的时候使用。 Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis怎么实现的点赞(项目)
step1: 参数校验:对传入的参数进行null值判断
step2:逻辑校验:对于用户点赞,用户不能重复点赞相同的文章
对于取消点赞,用户不能取消未点赞的文章
step3:存入Redis:
存入的数据主要有所有文章的点赞数,某篇文章的点赞数,用户点赞的文章
step4:定时任务
通过定时任务(1小时执行一次),从Redis读取数据持久化到MySQL中
Redis的应用
- 缓存,速度快,提升服务器性能
- 排行榜,在使用传统的关系型数据库来做这个事情,非常的麻烦,利用Redis的SortSet(有序集合)数据结构可以简单搞定
- 计数器:利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力
- 好友关系:利用集合的一些命令,比如求交集,并集,差集等。可以方便搞定一些共同好友,共同爱好值之类的功能。
- 简单消息队列:除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知,邮件发送之类的需求。
- Session共享:以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
- 一些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis 是放在内存中的可以很高效的访问
Redis的String应用场景:
-
计数器
INCR article:readcount:{文章id}
GET article:readcount:{文章id}
-
web集群session共享(不同的访问请求映射到不同服务器上的问题)
spring session +redis实现session共享
-
分布式系统全局序列号
INCRBY orderid 1000
Redis的一些问题
(https://blog.csdn.net/qq_28827039/article/details/81183888)
kaflka知识
消息中间件面试题
消息中间件面试题:消息队列的优缺点,区别
消息中间件面试题:消息丢失怎么办
消息中间件面试题:消息中间件的高可用
消息中间件面试题:如何保证消息的顺序性
消息中间件面试题:如何保证消息不被重复消费
消息中间件面试题:如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时呢?
基本概念
kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
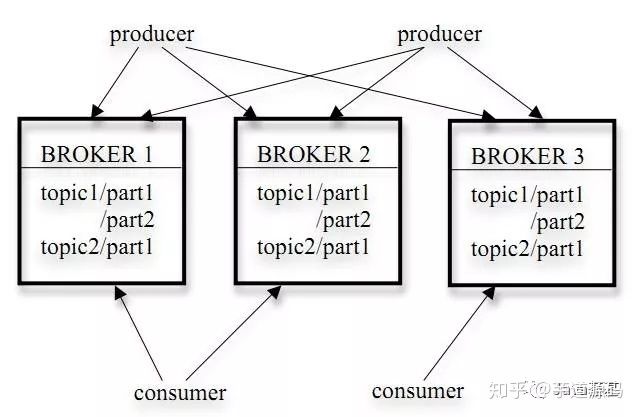
kafka对外使用topic的概念,生产者往topic里写消息,消费者从读消息。为了做到水平扩展,一个topic实际是由多个partition组成的,遇到瓶颈时,可以通过增加partition的数量来进行横向扩容。单个parition内是保证消息有序。
每新写一条消息,kafka就是在对应的文件append写,所以性能非常高。
消息系统本质其实就是一个模拟缓存 ,且仅仅是起到了缓存的作用 而并不是真正的缓存,数据仍然是存储在磁盘上面而不是内存。
kafka架构
Kafka—>Broker----->Topic----->Partition------>Segment
kafka中有多个Broker,Broker中有多个Topic,Topic中有多个Partition,Partition中有多个Segment
它的架构包括以下组件:
-
话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。
-
Partition:
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
-
生产者(Producer):是能够发布消息到话题的任何对象。
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
-
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
-
消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
-
Consumer Group:
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
-
Leader:
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition
-
Follower:
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Topic和Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据。
因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高Kafka性能无关。选择怎样的删除策略只与磁盘以及具体的需求有关。另外,Kafka会为每一个Consumer Group保留一些metadata信息——当前消费的消息的position,也即offset。这个offset由Consumer控制。正常情况下Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由Consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
kafka 交付担保(Kafka delivery guarantee)
Kafka支持三种消息投递语义
- At most once 消息可能会丢,但绝不会重复传递
- At least one 消息绝不会丢,但可能会重复传递
- Exactly once 每条消息肯定会被传输一次且仅传输一次(理想情况)
接收到消息之后先commit还是先处理消息?
consumer(消息的消费者)在从broker(消息的存储者)读取消息后,可以选择commit,该操作会在Zookeeper中存下该consumer在该partition下读取的消息的offset,该consumer下一次再读该partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。
1.先commit:At most once
读完消息先commit再处理消息。这种模式下,如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once。
2.先处理消息:At least once
读完消息先处理再commit消费状态(保存offset)。这种模式下,如果在处理完消息之后commit之前Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了,这就对应于At least once。
3.Exactly once:两阶段提交
如果一定要做到Exactly once,就需要协调offset和实际操作的输出。经典的做法是引入两阶段提交,但由于许多输出系统不支持两阶段提交,更为通用的方式是将offset和操作输入存在同一个地方。比如,consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once。(目前就high level API而言,offset是存于Zookeeper中的,无法存于HDFS,而low level API的offset是由自己去维护的,可以将之存于HDFS中)。
Kafka默认:At least once
Kafka默认保证At least once,并且允许通过设置producer异步提交来实现At most once,而Exactly once要求与目标存储系统协作,Kafka提供的offset可以较为容易地实现这种方式。
Kafka的高可用
Leader Election
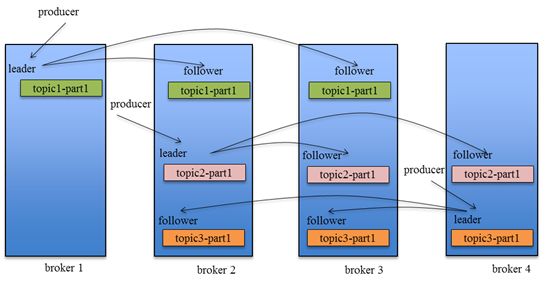
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
因为需要保证同一个Partition的多个Replica之间的数据一致性(其中一个宕机后其它Replica必须要能继续服务并且即不能造成数据重复也不能造成数据丢失)。如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证,大大增加了Replication实现的复杂性,同时也增加了出现异常的几率。而引入Leader后,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),系统更加简单且高效。
消息同步传递策略
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
Kafka Replication的数据流如下图所示:
Kafka特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
kafka的优点:
- 解耦
- 冗余:有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
- 扩展性:因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
- 灵活性&峰值处理能力
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
常用的MQ组件:
- RabbitMQ
- Redis
- ZeroMQ
- ActiveMQ
- Kafka/Jafka
Kafka的使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦生产者和消费者、缓存消息等。
-
消息系统介绍:
一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需关注于数据,无需关注数据在两个或多个应用间是如何传递的。分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka面试题
Kafka中ISR、AR又代表什么?ISR的伸缩又指什么
ISR:In-Sync Replicas 副本同步队列
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟,任意一个超过延迟阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
Kafka中的broker是干什么
broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
kafka中的zookeeper起到什么作用,可以不用zookeeper么
zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,
但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
kafka follower如何与leader同步数据
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
什么情况下一个broker会从isr中踢出去
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护 ,如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除 。
kafka为什么这么快
- Cache Filesystem Cache PageCache缓存
- 顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
- Zero-copy 零拷技术减少拷贝次数
- Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
- Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
kafka producer 如何优化打入速度
- 增加线程
- 提高 batch.size
- 增加更多 producer 实例
- 增加 partition 数
- 设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
- 跨数据中心的传输:增加 socket 缓冲区设置以及 OS tcp 缓冲区设置。
kafka producer打数据,ack为0,1,-1的时候代表啥,设置为-1的时候,什么情况下,leader会认为一条消息commit了
- 1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
- 0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
kafka unclean 配置代表啥,会对 spark streaming 消费有什么影响
unclean.leader.election.enable 为true的话,意味着非ISR集合的broker 也可以参与选举,这样有可能就会丢数据,spark streaming在消费过程中拿到的 end offset 会突然变小,导致 spark streaming job挂掉。如果unclean.leader.election.enable参数设置为true,就有可能发生数据丢失和数据不一致的情况,Kafka的可靠性就会降低;而如果unclean.leader.election.enable参数设置为false,Kafka的可用性就会降低。
如果leader crash时,ISR为空怎么办
kafka在Broker端提供了一个配置参数:unclean.leader.election,这个参数有两个值:
true(默认):允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。
false:不允许不同步副本成为leader,此时如果发生ISR列表为空,会一直等待旧leader恢复,降低了可用性。
kafka的message格式是什么样的
一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成,header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。当magic的值为1的时候,会在magic和crc32之间多一个字节的数据:attributes(保存一些相关属性,比如是否压缩、压缩格式等等);如果magic的值为0,那么不存在attributes属性,body是由N个字节构成的一个消息体,包含了具体的key/value消息。
kafka中consumer group 是什么概念
同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)。
Kafka中的消息是否会丢失和重复消费?
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1、消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
- 0—表示不进行消息接收是否成功的确认;
- 1—表示当Leader接收成功时确认;
- -1—表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2、消息消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
- Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
- High-level API:封装了对parition和offset的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来、并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就“诡异”的消失了;
解决办法:
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
消息重复消费及解决参考:https://www.javazhiyin.com/22910.html
为什么Kafka不支持读写分离?
在 Kafka 中,生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,从 而实现的是一种主写主读的生产消费模型。
Kafka 并不支持主写从读,因为主写从读有 2 个很明 显的缺点:
- (1)数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
- (2)延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
Kafka中是怎么体现消息顺序性的?
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
offset+1
计算机网络知识
TCP的主要特点
-
TCP 是面向连接的。(就好像打电话一样,通话前需要先拨号建立连接,通话结束后要挂机释放连接);
-
每一条 TCP 连接只能有两个端点,每一条 TCP 连接只能是点对点的(一对一);
-
TCP 提供可靠交付的服务。通过 TCP 连接传送的数据,无差错、不丢失、不重复、并且按序到达;
-
TCP 提供全双工通信。TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据;
-
面向字节流。TCP 中的“流”(Stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
UDP的主要特点
-
UDP 是无连接的;
-
UDP 使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态(这里面有许多参数);
-
UDP 是面向报文的;
-
UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 直播,实时视频会议等);
-
UDP 支持一对一、一对多、多对一和多对多的交互通信;
-
UDP 的首部开销小,只有 8 个字节,比 TCP 的 20 个字节的首部要短。
TCP和UDP的区别?
TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的运输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。
UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如:QQ 语音、 QQ 视频 、直播等等。
TCP三次握手
参考文章:https://blog.csdn.net/qq_38950316/article/details/81087809
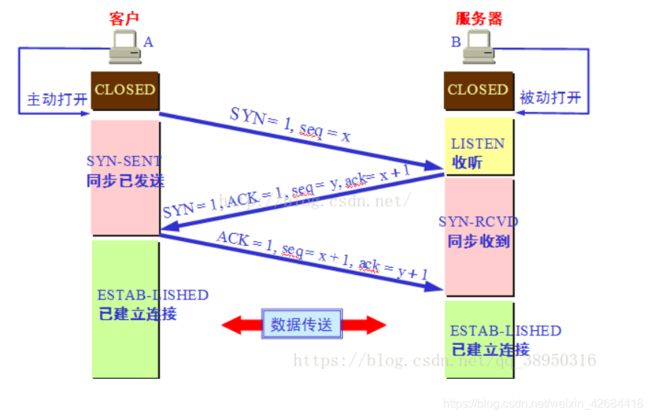
第一次握手:主机A发送位码为SYN=1,随机产生seq number=1234567的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
第二次握手:主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1),SYN=1,ACK=1,随机产生seq=7654321的包;
第三次握手:主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ACK是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ACK=1,主机B收到后确认seq值与ACK=1则连接建立成功。
TCP四次挥手
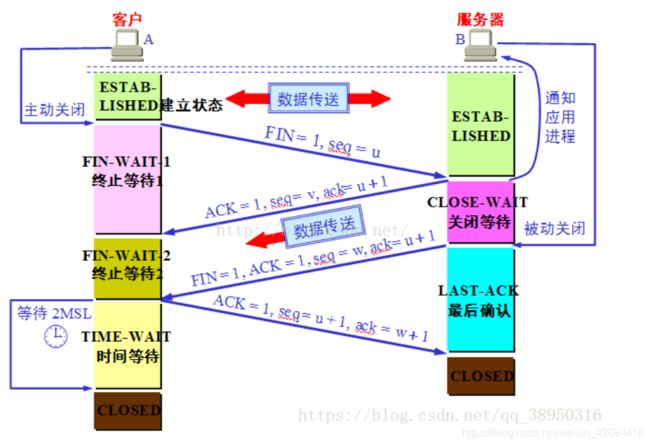
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
为什么两次握手不可以
为了防止已经失效的连接请求报文段突然又传送到了 B,因而产生错误。比如下面这种情况:A 发出的第一个连接请求报文段并没有丢失,而是在网路结点长时间滞留了,以致于延误到连接释放以后的某个时间段才到达 B。本来这是一个早已失效的报文段。但是 B 收到此失效的链接请求报文段后,就误认为 A 又发出一次新的连接请求。于是就向 A 发出确认报文段,同意建立连接。
对于上面这种情况,如果不进行第三次握手,B 发出确认后就认为新的运输连接已经建立了,并一直等待 A 发来数据。B 的许多资源就这样白白浪费了。
如果采用了三次握手,由于 A 实际上并没有发出建立连接请求,所以不会理睬 B 的确认,也不会向 B 发送数据。B 由于收不到确认,就知道 A 并没有要求建立连接。
为什么不需要四次握手?
有人可能会说 A 发出第三次握手的信息后在没有接收到 B 的请求就已经进入了连接状态,那如果 A 的这个确认包丢失或者滞留了怎么办?
我们需要明白一点,完全可靠的通信协议是不存在的。在经过三次握手之后,客户端和服务端已经可以确认之前的通信状况,都收到了确认信息。所以即便再增加握手次数也不能保证后面的通信完全可靠,所以是没有必要的。
为什么 TIME-WAIT 状态必须等待 2MSL 的时间呢?
2MSL:maximum segment lifetime (最大分节生命周期),这是一个IP数据包在互联网上生存的最长时间,超过这个时间IP数据包将在网络中消失,MSL 在 RFC 1122上建议是2分钟,而源自berkeley的TCP实现传统上使用30秒。
-
为了保证 A 发送的最后一个 ACK 报文段能够到达 B。这个 ACK 报文段有可能丢失,因而使处在 LAST-ACK 状态的 B 收不到对已发送的 FIN + ACK 报文段的确认。B 会超时重传这个 FIN+ACK 报文段,而 A 就能在 2MSL 时间内(超时 + 1MSL 传输)收到这个重传的 FIN+ACK 报文段。接着 A 重传一次确认,重新启动 2MSL 计时器。最后,A 和 B 都正常进入到 CLOSED 状态。如果 A 在 TIME-WAIT 状态不等待一段时间,而是在发送完 ACK 报文段后立即释放连接,那么就无法收到 B 重传的 FIN + ACK 报文段,因而也不会再发送一次确认报文段,这样,B 就无法按照正常步骤进入 CLOSED 状态。
-
防止已失效的连接请求报文段出现在本连接中。A 在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个连接中不会出现这种旧的连接请求报文段。
五层协议框架
计算机五层网络体系中涉及的协议非常多,下面就常用的做了列举:
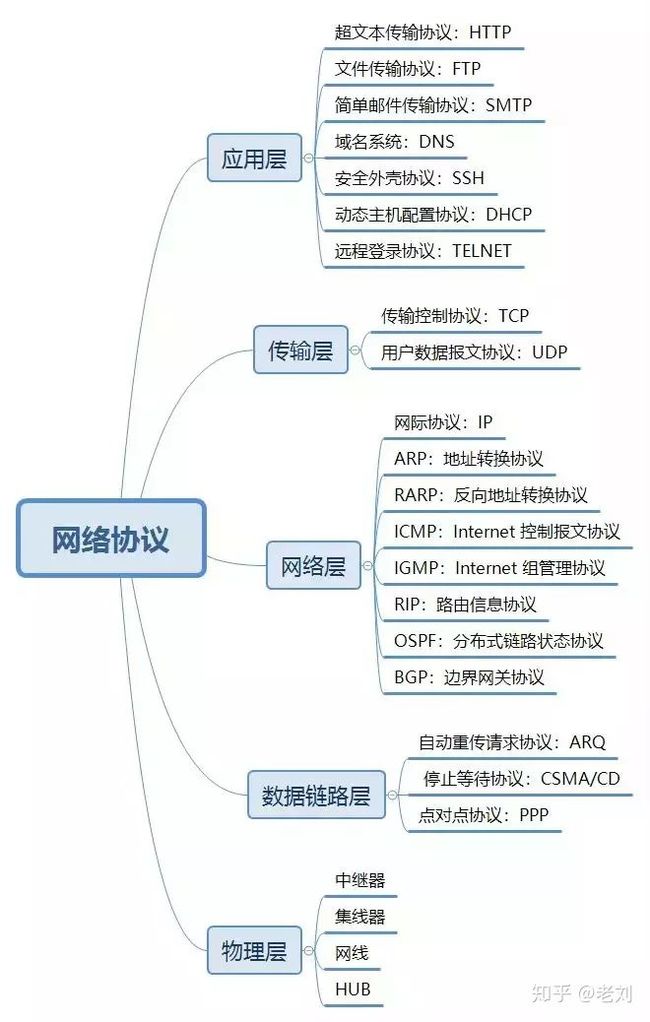
物理层:实现两台计算机之间点对点的比特流透明传输
数据链路层:两台计算机之间的数据传输,总是在一段一段的链路上传输的,这就需要使用专门的链路层协议
网络层:在计算机网络中进行通信的两个计算机可能会经过很多个数据链路,也可能还要经过很多通信子网,网络层的任务就是选择合适的网间路由和交换节点,确保数据及时传送。
传输层:主要任务就是向两台主机进程之间的通信提供通用的数据传输服务。
应用层:通过应用进程间的交互来完成特定网络应用。
ARP协议的工作原理
功能:完成了IP地址与MAC地址的映射
具体实现:首先,每台主机都会在自己的 ARP 缓冲区中建立一个 ARP 列表,以表示 IP 地址和 MAC 地址的对应关系。当源主机需要将一个数据包要发送到目的主机时,会首先检查自己 ARP 列表中是否存在该 IP 地址对应的 MAC 地址:如果有,就直接将数据包发送到这个 MAC 地址;如果没有,就向本地网段发起一个 ARP 请求的广播包,查询此目的主机对应的 MAC 地址。此 ARP 请求数据包里包括源主机的 IP 地址、硬件地址、以及目的主机的 IP 地址。网络中所有的主机收到这个 ARP 请求后,会检查数据包中的目的 IP 是否和自己的 IP 地址一致。如果不相同就忽略此数据包;如果相同,该主机首先将发送端的 MAC 地址和 IP 地址添加到自己的 ARP 列表中,如果 ARP 表中已经存在该 IP 的信息,则将其覆盖,然后给源主机发送一个 ARP 响应数据包,告诉对方自己是它需要查找的 MAC 地址;源主机收到这个 ARP 响应数据包后,将得到的目的主机的 IP 地址和 MAC 地址添加到自己的 ARP 列表中,并利用此信息开始数据的传输。如果源主机一直没有收到 ARP 响应数据包,表示 ARP 查询失败。
IP地址分类
功能:为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。IP 地址编址方案将 IP 地址空间划分为 A、B、C、D、E 五类,其中 A、B、C 是基本类,D、E 类作为多播和保留使用,为特殊地址。
每个 IP 地址包括两个标识码(ID),即网络 ID 和主机 ID。同一个物理网络上的所有主机都使用同一个网络 ID,网络上的一个主机(包括网络上工作站,服务器和路由器等)有一个主机 ID 与其对应。A~E 类地址的特点如下:
A 类地址:以 0 开头,第一个字节范围:0~127;
B 类地址:以 10 开头,第一个字节范围:128~191;
C 类地址:以 110 开头,第一个字节范围:192~223;
D 类地址:以 1110 开头,第一个字节范围为 224~239;
E 类地址:以 1111 开头,保留地址
TCP 和 UDP 分别对应的常见应用层协议有哪些?
1. TCP 对应的应用层协议
FTP:定义了文件传输协议,使用 21 端口。常说某某计算机开了 FTP 服务便是启动了文件传输服务。下载文件,上传主页,都要用到 FTP 服务。
Telnet:它是一种用于远程登陆的端口,用户可以以自己的身份远程连接到计算机上,通过这种端口可以提供一种基于 DOS 模式下的通信服务。如以前的 BBS 是-纯字符界面的,支持 BBS 的服务器将 23 端口打开,对外提供服务。
SMTP:定义了简单邮件传送协议,现在很多邮件服务器都用的是这个协议,用于发送邮件。如常见的免费邮件服务中用的就是这个邮件服务端口,所以在电子邮件设置-中常看到有这么 SMTP 端口设置这个栏,服务器开放的是 25 号端口。
POP3:它是和 SMTP 对应,POP3 用于接收邮件。通常情况下,POP3 协议所用的是 110 端口。也是说,只要你有相应的使用 POP3 协议的程序(例如 Fo-xmail 或 Outlook),就可以不以 Web 方式登陆进邮箱界面,直接用邮件程序就可以收到邮件(如是163 邮箱就没有必要先进入网易网站,再进入自己的邮-箱来收信)。
HTTP:从 Web 服务器传输超文本到本地浏览器的传送协议。
2. UDP 对应的应用层协议
DNS:用于域名解析服务,将域名地址转换为 IP 地址。DNS 用的是 53 号端口。
SNMP:简单网络管理协议,使用 161 号端口,是用来管理网络设备的。由于网络设备很多,无连接的服务就体现出其优势。
TFTP(Trival File Transfer Protocal):简单文件传输协议,该协议在熟知端口 69 上使用 UDP 服务。
UDP和TCP的数据包长度
在应用程序中我们用到的Data的长度最大是多少,直接取决于底层的限制。
我们从下到上分析一下:
1.在链路层,由以太网的物理特性决定了数据帧的长度为(46+18)-(1500+18),其中的18是数据帧的头和尾,也就是说数据帧的内容最大为1500(不包括帧头和帧尾),即MTU(Maximum Transmission Unit)为1500;
2.在网络层,因为IP包的首部要占用20字节,所以这的MTU为1500-20=1480;
3.在传输层,对于UDP包的首部要占用8字节,所以这的MTU为1480-8=1472; TCP 包的大小就应该是 1500 - IP头(20) - TCP头(20) = 1460 (Bytes)
所以,在应用层,你的Data最大长度为1472。当我们的UDP包中的数据多于MTU(1472)时,发送方的IP层需要分片fragmentation进行传输,而在接收方IP层则需要进行数据报重组,由于UDP是不可靠的传输协议,如果分片丢失导致重组失败,将导致UDP数据包被丢弃。
从上面的分析来看,在普通的局域网环境下,UDP的数据最大为1472字节最好(避免分片重组)。
但在网络编程中,Internet中的路由器可能有设置成不同的值(小于默认值),Internet上的标准MTU值为576,所以Internet的UDP编程时数据长度最好在576-20-8=548字节以内。
- MTU: Maxitum Transmission Unit 最大传输单元
- MSS: Maxitum Segment Size 最大分段大小,MSS就是TCP数据包每次能够传输的最大数据分段。
3、TCP、UDP数据包最小值的确定
在用UDP局域网通信时,经常发生“Hello World”来进行测试,但是“Hello World”并不满足最小有效数据(64-46)的要求,为什么小于18个字节,对方仍然可用收到呢?因为在链路层的MAC子层中会进行数据补齐,不足18个字节的用0补齐。但当服务器在公网,客户端在内网,发生小于18个字节的数据,就会出现接收端收不到数据的情况。
以太网EthernetII规定,以太网帧数据域部分最小为46字节,也就是以太网帧最小是6+6+2+46+4=64。除去4个字节的FCS,因此,抓包时就是60字节。当数据字段的长度小于46字节时,MAC子层就会在数据字段的后面填充以满足数据帧长不小于64字节。由于填充数据是由MAC子层负责,也就是设备驱动程序。不同的抓包程序和设备驱动程序所处的优先层次可能不同,抓包程序的优先级可能比设备驱动程序更高,也就是说,我们的抓包程序可能在设备驱动程序还没有填充不到64字节的帧的时候,抓包程序已经捕获了数据。因此不同的抓包工具抓到的数据帧的大小可能不同。下列是本人分别用wireshark和sniffer抓包的结果,对于TCP 的ACK确认帧的大小一个是54字节,一个是60字节,wireshark抓取时没有填充数据段,sniffer抓取时有填充数据段。
4、实际应用
用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) - UDP头(8)=65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。
用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
保活计时器的作用?
除时间等待计时器外,TCP 还有一个保活计时器(keepalive timer)。设想这样的场景:客户已主动与服务器建立了 TCP 连接。但后来客户端的主机突然发生故障。显然,服务器以后就不能再收到客户端发来的数据。因此,应当有措施使服务器不要再白白等待下去。这就需要使用保活计时器了。
服务器每收到一次客户的数据,就重新设置保活计时器,时间的设置通常是两个小时。若两个小时都没有收到客户端的数据,服务端就发送一个探测报文段,以后则每隔 75 秒钟发送一次。若连续发送 10个 探测报文段后仍然无客户端的响应,服务端就认为客户端出了故障,接着就关闭这个连接。
TCP 协议是如何保证可靠传输的?
-
数据包校验:目的是检测数据在传输过程中的任何变化,若校验出包有错,则丢弃报文段并且不给出响应,这时 TCP 发送数据端超时后会重发数据;
-
对失序数据包重排序:既然 TCP 报文段作为 IP 数据报来传输,而 IP 数据报的到达可能会失序,因此 TCP 报文段的到达也可能会失序。TCP 将对失序数据进行重新排序,然后才交给应用层;
-
丢弃重复数据:对于重复数据,能够丢弃重复数据;
-
应答机制:当 TCP 收到发自 TCP 连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒;
-
超时重发:当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段;
-
流量控制:TCP 连接的每一方都有固定大小的缓冲空间。TCP 的接收端只允许另一端发送接收端缓冲区所能接纳的数据,这可以防止较快主机致使较慢主机的缓冲区溢出,这就是流量控制。TCP 使用的流量控制协议是可变大小的滑动窗口协议。
TCP的四种拥塞控制算法
- 慢开始
- 拥塞避免
- 快重传
- 快恢复
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SKyqFsYl-1661411816871)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200812161626363.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gNYZhLvt-1661411816872)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200812162348903.png)]
TCP发送方一开始使用 慢开始 算法,让拥塞窗口cwnd的值从1开始指数增长,当拥塞窗口cwnd的值增长到初始的慢开始门限值ssthresh值时,停止使用慢开始算法,转而执行拥塞避免算法,拥塞避免算法让cwnd的值按线性增长,当发生超时重传时,就判断网络可能出现了拥塞,这是会将慢开始门限值更新到当前拥塞窗口值cwnd的一半,并将cwnd的值置为1,重新开始慢开始算法,和拥塞避免算法。
注意:慢开始是指一开始向网络中注入的报文段少,并不是指拥塞窗口cwnd增长速度慢
拥塞避免并非指完全能够避免拥塞,而是指在拥塞避免阶段将拥塞窗口控制在线性规律增长,使网络不容易出现拥塞。
有时网络中只是个别报文段会在网络中丢失,但实际上网络并未发生拥塞,这将导致发送方超时重传,并误认为网络发生了拥塞;发送发错误地启动了慢开始算法,并把拥塞窗口的cwnd值设置为1,因而降低了传输效率。为了解决这个问题,出现了快重传和快恢复算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JsSnIAgs-1661411816872)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200812164507012.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WTuLLbVF-1661411816873)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200812164701894.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wrUnOtT8-1661411816873)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200812164902874.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sn4YRKcH-1661411816874)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200812164932343.png)]
TCP发送方一开始使用 慢开始 算法,让拥塞窗口cwnd的值从1开始指数增长,当拥塞窗口cwnd的值增长到初始的慢开始门限值ssthresh值时,停止使用慢开始算法,转而执行拥塞避免算法,拥塞避免算法让cwnd的值按线性增长,当发生超时重传时,就判断网络可能出现了拥塞,这是会将慢开始门限值更新到当前拥塞窗口值cwnd的一半,并将cwnd的值置为1,重新开始慢开始算法,让拥塞窗口cwnd的值从1开始指数增长,当拥塞窗口cwnd的值增长到新的慢开始门限值ssthresh值时,停止使用慢开始算法,转而执行拥塞避免算法,拥塞避免算法让cwnd的值按线性增长。这时如果网络中出现了个别保文的丢失,并收到三个重复确认时,就执行快重传和快恢复算法,将慢开始门限值ssthresh值和拥塞窗口cwnd值调整为当前窗口一半,开始执行拥塞避免算法
什么是粘包
在进行 Java NIO 学习时,可能会发现:如果客户端连续不断的向服务端发送数据包时,服务端接收的数据会出现两个数据包粘在一起的情况。
-
TCP 是基于字节流的
-
TCP 的首部没有表示数据长度的字段。
一个数据包中包含了发送端发送的两个数据包的信息,这种现象即为粘包。
接收端收到了两个数据包,但是这两个数据包要么是不完整的,要么就是多出来一块,这种情况即发生了拆包和粘包。拆包和粘包的问题导致接收端在处理的时候会非常困难,因为无法区分一个完整的数据包。
TCP 黏包是怎么产生的?
- 发送方产生粘包
采用 TCP 协议传输数据的客户端与服务器经常是保持一个长连接的状态(一次连接发一次数据不存在粘包),双方在连接不断开的情况下,可以一直传输数据。但当发送的数据包过于的小时,那么 TCP 协议默认的会启用 Nagle 算法,将这些较小的数据包进行合并发送(缓冲区数据发送是一个堆压的过程);这个合并过程就是在发送缓冲区中进行的,也就是说数据发送出来它已经是粘包的状态了。
- 接收方产生粘包
接收方采用 TCP 协议接收数据时的过程是这样的:数据到接收方,从网络模型的下方传递至传输层,传输层的 TCP 协议处理是将其放置接收缓冲区,然后由应用层来主动获取(C 语言用 recv、read 等函数);这时会出现一个问题,就是我们在程序中调用的读取数据函数不能及时的把缓冲区中的数据拿出来,而下一个数据又到来并有一部分放入的缓冲区末尾,等我们读取数据时就是一个粘包。(放数据的速度 > 应用层拿数据速度)
怎么解决拆包和粘包?
分包机制一般有两个通用的解决方法:
-
特殊字符控制;
-
在包头首都添加数据包的长度。
如果使用 netty 的话,就有专门的编码器和解码器解决拆包和粘包问题了。
tips:UDP 没有粘包问题,但是有丢包和乱序。不完整的包是不会有的,收到的都是完全正确的包。传送的数据单位协议是 UDP 报文或用户数据报,发送的时候既不合并,也不拆分。
HTTP状态码
- 1XX 信息
- 100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
- 2XX 成功
-
200 OK
-
204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
-
206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
- 3XX 重定向
-
301 Moved Permanently :永久性重定向;
-
302 Found :临时性重定向;
-
303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
-
304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
-
307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
- 4XX 客户端错误
-
400 Bad Request :请求报文中存在语法错误。
-
401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
-
403 Forbidden :请求被拒绝。
-
404 Not Found
- 5XX 服务器错误
-
500 Internal Server Error :服务器正在执行请求时发生错误;
-
503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
HTTP 状态码 301 和 302 代表的是什么?有什么区别?
301,302 都是 HTTP 状态的编码,都代表着某个 URL 发生了转移。
- 区别:
301 redirect: 301 代表永久性转移(Permanently Moved)
302 redirect: 302 代表暂时性转移(Temporarily Moved)
forward 和 redirect 的区别?
Forward 和 Redirect 代表了两种请求转发方式:直接转发和间接转发。
直接转发方式(Forward):客户端和浏览器只发出一次请求,Servlet、HTML、JSP 或其它信息资源,由第二个信息资源响应该请求,在请求对象 request 中,保存的对象对于每个信息资源是共享的。
间接转发方式(Redirect):实际是两次 HTTP 请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个 URL 发出请求,从而达到转发的目的。
- 举个通俗的例子:
直接转发就相当于:“A 找 B 借钱,B 说没有,B 去找 C 借,借到借不到都会把消息传递给 A”;
间接转发就相当于:“A 找 B 借钱,B 说没有,让 A 去找 C 借”。
HTTP 方法有哪些?
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
- GET:获取资源,当前网络中绝大部分使用的都是 GET;
- HEAD:获取报文首部,和 GET 方法类似,但是不返回报文实体主体部分;
- POST:传输实体主体
- PUT:上传文件,由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
- PATCH:对资源进行部分修改。PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
- OPTIONS:查询指定的 URL 支持的方法;
- CONNECT:要求在与代理服务器通信时建立隧道。使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
- TRACE:追踪路径。服务器会将通信路径返回给客户端。发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
HTTP报文格式
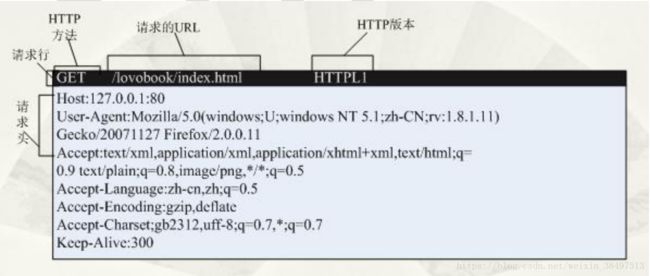
请求报文
-
请求行:请求方法 url 版本号
-
请求头:
Host:接收请求的服务器地址,可以是ip也可以是端口号
User-Agent:发送请求的应用程序名称
Connection:指定与连接相关的属性,Connection:Keep-Alive
Accept-Charset:指定可接收的编码格式
Accept-Encoding:指定可接收的数据压缩格式
Accept-Language:指定可以接收的语言
-
空行:表示请求头结束
-
请求正文:可选,get就没有请求正文
响应报文
-
响应行:协议版、状态码,状态描述
-
响应头:
Content-Type:相应正文的类型(是图片还是二进制)
Content-Length:相应正文的长度
Content-Charset:相应正文的使用编码
Content-Encoding:相应正文使用的数据压缩格式
Content-Language:相应正文使用的语言
-
空行:表示响应头结束
-
响应正文:

说下 GET 和 POST 的区别?
GET 和 POST 本质都是 HTTP 请求,只不过对它们的作用做了界定和适配,并且让他们适应各自的场景。
本质区别:GET 只是一次 HTTP请求,POST 先发请求头再发请求体,实际上是两次请求。
-
从功能上讲,GET 一般用来从服务器上获取资源,POST 一般用来更新服务器上的资源;
-
从 REST 服务角度上说,GET 是幂等的,即读取同一个资源,总是得到相同的数据,而 POST 不是幂等的,因为每次请求对资源的改变并不是相同的;进一步地,GET 不会改变服务器上的资源,而 POST 会对服务器资源进行改变;
-
从请求参数形式上看,GET 请求的数据会附在 URL 之后,即将请求数据放置在 HTTP 报文的 请求头 中,以 ? 分割 URL 和传输数据,参数之间以 & 相连。特别地,如果数据是英文字母/数字,原样发送;否则,会将其编码为 application/x-www-form-urlencoded MIME 字符串(如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用 BASE64 加密,得出如:%E4%BD%A0%E5%A5%BD,其中 %XX 中的 XX 为该符号以 16 进制表示的 ASCII);而 POST 请求会把提交的数据则放置在是 HTTP 请求报文的 请求体 中;
-
就安全性而言,POST 的安全性要比 GET 的安全性高,因为 GET 请求提交的数据将明文出现在 URL 上,而且 POST 请求参数则被包装到请求体中,相对更安全;
-
从请求的大小看,GET 请求的长度受限于浏览器或服务器对 URL 长度的限制,允许发送的数据量比较小,而 POST 请求则是没有大小限制的。
在浏览器中输入URL地址到显示主页的过程:
DNS解析------->TCP链接--------->发送HTTP请求---------->服务器处理请求并返回HTTP报文------->浏览器解析报文并渲染页面--------->连接结束
1.根据域名到DNS中找到IP
2.根据IP建立TCP连接(三次握手)
3.连接建立成功发起http请求
4.服务器响应http请求
5.浏览器解析HTML代码并请求html中的静态资源(js,css)
6.关闭TCP连接(四次挥手)
7.浏览器渲染页面
过程中使用到的协议:UDP协议,TCP协议,IP协议,ARP协议,SOFP协议
DNS解析的过程
以一个例子来说明:
假设域名m.xyz.com的主机想知道另一个主机y.abc.com的IP地址.那么DNS解析过程如下:
1.首先主机先向本地域名服务器发起查询
2.若本地域名服务器没有缓存该域名对应的IP地址,则向根域名服务器查询
3.根域名服务器告诉本地服务器,应该向哪一个顶级域名服务器去查询
4.然后本地域名服务器向顶级域名服务器发起查询
5.顶级域名服务器告诉本地域名服务器,下一步应该查询的权限服务器的IP地址
6.本地域名服务器向权限域名服务器发起查询
7.权限域名服务器告诉本地域名服务器所查询网址的IP地址
8.本地域名服务器将该IP发送给主机。
HTTP 长连接和短连接
Connection:keep-alive
操作系统
操作系统 内存分配与回收
操作系统 内存分配与回收
操作系统内存管理
内存管理方法
内存管理主要包括虚地址、地址变换、内存分配和回收、内存扩充、内存共享和保护等功能
连续分配存储管理方式
-
单一连续存储管理
在这种管理方式中,内存被分为两个区域:系统区和用户区。应用程序装入到用户区,可使用用户区全部空间。其特点是,最简单,适用于单用户、单任务的操作系统。CP/M和 DOS 2.0以下就是采用此种方式。这种方式的最大优点就是易于管理。但也存在着一些问题和不足之处,例如对要求内存空间少的程序,造成内存浪费;程序全部装入,使得很少使用的程序部分也占用—定数量的内存。
-
分区式存储管理
- 固定分区
- 动态分区
- 伙伴系统
简单Java基础
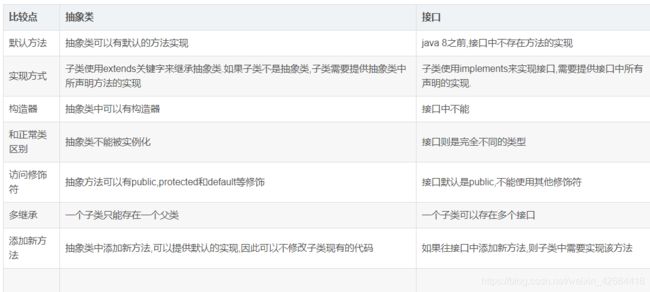
接口和抽象类的区别
最大的区别在于:
接口是对象功能的抽象,抽象类是对象本质的抽象。这个是最大区别
StringBuilder和StringBuffer
主要有线程安全、缓冲区、性能三方面的区别
-
线程安全方面
StringBuffer:线程安全的。StringBuilder:线程不安全。因为StringBuffer的所有公开方法都是synchronized修饰的,而StringBuilder并没有sychronized修饰。
-
缓冲区方面
StringBuffer每次获取toString都会直接使用缓存区的toStringCache值来构造一个字符串。StringBuilder则每次都需要复制一次字符数组,再构造一次字符串所以、
StringBuffer对缓冲区进行了优化。 -
性能方面
由于
StringBuilder没有加锁,所以性能要优于StringBuffer -
总结:
StringBuffer适用于多线程操作同一个StringBuffer的场景,StringBuilder在单线程场景下更为合适
Java创建对象的几种方式
- 通过new关键字来创建
- 通过反射来创建
- 通过clone()方法来创建
- 通过序列化机制来创建
为什么要重写equals方法
因为Object对象中equals方法(源码)中是比较两个对象是否相同,必须两个引用指向统一地址的才会返回true,而一般我们用equals方法来比较对象的内容是否相同,所以一般我们需要重写equals方法。
public class Object {
......
public boolean equals(Object obj) {
return (this == obj);
}
......
}
解决Hash冲突的方法
-
开放定址法:
就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
-
拉链法
每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来
-
再哈希法
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数
-
建立公共溢出区法
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
深拷贝和浅拷贝
参考链接:(91条消息) 深拷贝和浅拷贝的区别_crystal_hhj的博客-CSDN博客_深拷贝和浅拷贝的区别
- 浅拷贝:被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象.换言之,浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象.
- 深拷贝:被复制对象的所有变量都含有与原来的对象相同的值.而那些引用其他对象的变量将指向被复制过的新对象.而不再是原有的那些被引用的对象.换言之.深拷贝把要复制的对象所引用的对象都复制了一遍.
final有哪些用法
- final修饰的类不可以被继承,例如String类
- final修饰的方法不可以被重写
- final修饰的成员变量不可以被改写,如果修饰应用,那么表示引用的指向不可变,指向的内容可变
Java中的异常
Error:
是程序中无法处理的错误,表示运行应用程序中出现了严重的错误。此类错误一般表示代码运行时JVM出现问题。通常有Virtual MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)等。比如说当jvm耗完可用内存时,将出现OutOfMemoryError。此类错误发生时,JVM将终止线程。非代码性错误。因此,当此类错误发生时,应用不应该去处理此类错误。
Exception:
程序本身可以捕获并且可以处理的异常。
-
运行时异常(不受捡异常):
RuntimeException类极其子类表示JVM在运行期间可能出现的错误。编译器不会检查此类异常,并且不要求处理异常,比如用空值对象的引用(NullPointerException)、数组下标越界(ArrayIndexOutBoundException)。此类异常属于不可查异常,一般是由程序逻辑错误引起的,在程序中可以选择捕获处理,也可以不处理。
-
非运行异常(受检异常):
Exception中除RuntimeException极其子类之外的异常。编译器会检查此类异常,如果程序中出现此类异常,比如说IOException,必须对该异常进行处理,要么使用try-catch捕获,要么使用throws语句抛出,否则编译不通过。
ThreadLocal特性
ThreadLocal和Synchronized都是为了解决多线程中相同变量的访问冲突问题,不同的点是
- Synchronized是通过线程等待,牺牲时间来解决访问冲突
- ThreadLocal是通过每个线程单独一份存储空间,牺牲空间来解决冲突,并且相比于Synchronized,ThreadLocal具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问到想要的值。
正因为ThreadLocal的线程隔离特性,使他的应用场景相对来说更为特殊一些。在android中Looper、ActivityThread以及AMS中都用到了ThreadLocal。当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑采用ThreadLocal。
Java assert关键字
Java assert关键字
CAS原理
CAS原理
AQS原理
什么是CAS、什么是AQS - 知乎 (zhihu.com)
AQS:AbstractQuenedSynchronizer抽象的队列式同步器。是除了java自带的synchronized关键字之外的锁机制。
AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包
AQS的核心思想:,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并将共享资源设置为锁定状态,如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列,虚拟的双向队列即不存在队列实例,仅存在节点之间的关联关系。
AQS是将每一条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node),来实现锁的分配。
用大白话来说,AQS就是基于CLH队列,用volatile修饰共享变量state,线程通过CAS去改变状态符,成功则获取锁成功,失败则进入等待队列,等待被唤醒。
**注意:AQS是自旋锁:**在等待唤醒的时候,经常会使用自旋(while(!cas()))的方式,不停地尝试获取锁,直到被其他线程获取成功
实现了AQS的锁有:自旋锁、互斥锁、读锁写锁、条件产量、信号量、栅栏都是AQS的衍生物、
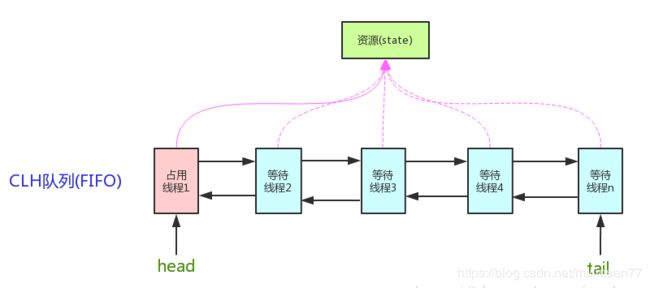
如图示,AQS维护了一个volatile int state和一个FIFO线程等待队列,多线程争用资源被阻塞的时候就会进入这个队列。state就是共享资源,其访问方式有如下三种:
getState();setState();compareAndSetState();
AQS 定义了两种资源共享方式:
1.Exclusive:独占,只有一个线程能执行,如ReentrantLock
2.Share:共享,多个线程可以同时执行,如Semaphore、CountDownLatch、ReadWriteLock,CyclicBarrier
不同的自定义的同步器争用共享资源的方式也不同。
AQS底层使用了模板方法模式
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
- 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
- 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
自定义同步器在实现的时候只需要实现共享资源state的获取和释放方式即可,至于具体线程等待队列的维护,AQS已经在顶层实现好了。自定义同步器实现的时候主要实现下面几种方法:
isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
ReentrantLock为例,(可重入独占式锁):state初始化为0,表示未锁定状态,A线程lock()时,会调用tryAcquire()独占锁并将state+1.之后其他线程再想tryAcquire的时候就会失败,直到A线程unlock()到state=0为止,其他线程才有机会获取该锁。A释放锁之前,自己也是可以重复获取此锁(state累加),这就是可重入的概念。
注意:获取多少次锁就要释放多少次锁,保证state是能回到零态的。
以CountDownLatch为例,任务分N个子线程去执行,state就初始化 为N,N个线程并行执行,每个线程执行完之后countDown()一次,state就会CAS减一。当N子线程全部执行完毕,state=0,会unpark()主调用线程,主调用线程就会从await()函数返回,继续之后的动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
在acquire() acquireShared()两种方式下,线程在等待队列中都是忽略中断的,acquireInterruptibly()/acquireSharedInterruptibly()是支持响应中断的。
反射:
反射就是把Java类中的各个成分映射成一个个的Java对象。即在运行状态中,对于任意一个类,都能够知道这个类的所以属性和方法;对于任意一个对象,都能调用它的任意一个方法和属性。这种动态获取信息及动态调用对象方法的功能叫Java的反射机制。
1. 反射机制的功能
Java反射机制主要提供了以下功能:
- 在运行时判断任意一个对象所属的类。
- 在运行时构造任意一个类的对象。
- 在运行时判断任意一个类所具有的成员变量和方法。
- 在运行时调用任意一个对象的方法。
- 生成动态代理。
2. 实现反射机制的类
Java中主要由以下的类来实现Java反射机制(这些类都位于java.lang.reflect包中):
-
Class类:代表一个类。 Field类:代表类的成员变量(成员变量也称为类的属性)。
-
Method类:代表类的方法。
-
Constructor类:代表类的构造方法。
-
Array类:提供了动态创建数组,以及访问数组的元素的静态方法。
注解
Java基础
深入理解new String()
(91条消息) 深入了解new String()_小胖java攻城狮的博客-CSDN博客_new string
HashMap
数据结构:
HashMap内部使用链表+数组+红黑树的结构。
插入元素的流程
- 判断数组是否为空,为空进行初始化;
- 不为空,计算 k 的 hash 值,通过
(n - 1) & hash计算应当存放在数组中的下标 index; - 查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
- 存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
- 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了)
- 如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
- 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
HashMap怎么设定初始容量大小:
默认大小是16,负载因子是0.75, 如果自己传入初始大小k,初始化大小为 大于k的 2的整数次方,例如如果传10,大小为16
hash函数如何设计
hash函数是先拿到 key 的hashcode,是一个32位的int值,然后让hashcode的高16位和低16位进行异或操作。
为什么这么设计:
因为key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围为**-2147483648~2147483647**,前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,如果HashMap数组的初始大小才16,用之前需要对数组的长度取模运算,得到的余数才能用来访问数组下标。
源码中模运算就是把散列值和数组长度-1做一个"与"操作,位运算比取余%运算要快。
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length) {
return h & (length-1);
}
顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整数幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,如果正好让最后几个低位呈现规律性重复,就无比蛋疼。
右移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
为什么这么设计:
- 一定要尽可能降低hash碰撞,越分散越好;
- 算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
Java1.8对HashMap做了什么改进
- 数组+链表改成了数组+链表或红黑树;
- 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;
- 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
为什么要改进
-
防止发生hash冲突,链表长度过长,将时间复杂度由
O(n)降为O(logn); -
因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;
A线程在插入节点B,B线程也在插入,遇到容量不够开始扩容,重新hash,放置元素,采用头插法,后遍历到的B节点放入了头部,这样形成了环,如下图所示:
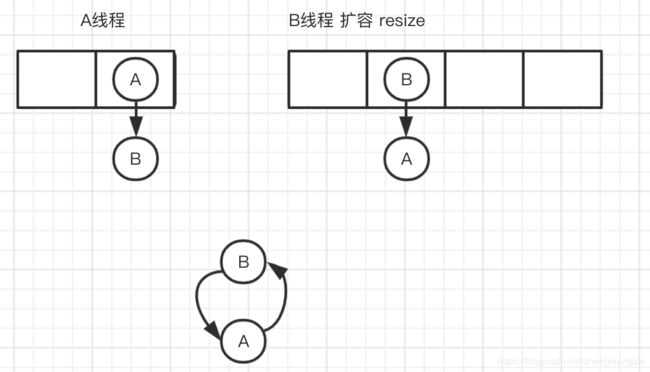
扩容的时候为什么1.8 不用重新hash就可以直接定位原节点在新数据的位置呢?
这是由于扩容是扩大为原数组大小的2倍,用于计算数组位置的掩码仅仅只是高位多了一个1,怎么理解呢?
扩容前长度为16,用于计算(n-1) & hash 的二进制n-1为0000 1111,扩容为32后的二进制就高位多了1,为0001 1111。
因为是& 运算,1和任何数 & 都是它本身,那就分二种情况,如下图:原数据hashcode高位第4位为0和高位为1的情况;
第四位高位为0,重新hash数值不变,第四位为1,重新hash数值比原来大16(旧数组的容量)
那1.8后HashMap是线程安全的吗?
安琪拉: 不是,在多线程环境下,1.7 会产生死循环、数据丢失、数据覆盖的问题,1.8 中会有数据覆盖的问题,以1.8为例,当A线程判断index位置为空后正好挂起,B线程开始往index位置的写入节点数据,这时A线程恢复现场,执行赋值操作,就把A线程的数据给覆盖了;还有++size这个地方也会造成多线程同时扩容等问题。
LinkedList和ArrayList的区别
ArrayList底层是基于数组实现的,查询效率较高,增删改查的效率较低。
LinkedList底层是基于链表实现的,查询效率较低,增删速度较快
两者都不是线程安全的。
concurrentHashMap
ConcurrentHashMap成员变量使用volatile 修饰,免除了指令重排序,同时保证内存可见性,另外使用CAS操作和synchronized结合实现赋值操作,多线程操作只会锁住当前操作索引的节点。
因为在多线程环境下,使用HashMap进行put操作可能会引起死循环,导致cpu利用率接近100%,所以在并发情况下不能使用HashMap
因此针对这一问题:出现了Hashtable 和concurrentHashMap
-
hashtable
Hashtable使用synchronized来保证线程安全,但在线程竞争激烈的情况下,hashtable的效率非常低下。因为在同一时刻只能有一个线程占有资源,其他线程都处于等待状态。
-
concurrentHashMap
concurrentHashMap采用分段锁的思想,将数据分成一段一段存储,然后给每一段数据配上一把锁,当一个线程占用锁访问其中一段数据时,其他线程也可以访问别的段数据。
-
总结
Hashtable的任何操作都会把整个表锁住,是阻塞的。好处是总能获取最实时的更新,比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。坏处是所有调用都要排队,效率较低。
ConcurrentHashMap 是设计为非阻塞的。在更新时会局部锁住某部分数据,但不会把整个表都锁住。同步读取操作则是完全非阻塞的。好处是在保证合理的同步前提下,效率很高。坏处是严格来说读取操作不能保证反映最近的更新。例如线程A调用putAll写入大量数据,期间线程B调用get,则只能get到目前为止已经顺利插入的部分数据。
应该根据具体的应用场景选择合适的HashMap。
sychronized和ReentrantLock
Synchronized
Java的关键字
为对象,代码块,方法提供线程安全的操作
属于独占式的悲观锁,同时属于可重入锁。
Java中每个对象都有一个monitor对象,加锁就是在竞争monitor对象。对代码块进行加锁是通过在前后分别加上monitorenter和monitorexit来实现的
Synchronized的作用范围
synchronized作用于成员变量和静态方法时,锁住的是对象的实例,即this对象synchronized作用于静态方法时,锁住的是class实例,因为静态方法属于类synchronized作用于一个代码块时,锁住的是所有代码块中配置的对象
ReentrantLock
Lock接口的实现类,是一个可重入的独占锁
可重入锁指的是允许一个线程对同一资源执行多次加锁操作。
ReentrantLock支持公平锁和非公平锁的实现
ReentrantLock不仅提供了synchronized对锁的操作功能,**还提供了可响应中断锁,可轮询锁请求,定时锁等避免多线程死锁的方法。
sychronized关键字原理
在synchronized内部包括ContentionList、EntryList、WaitSet、OnDeck、Owner、!Owner这6个区域,每个区域都代表锁的不同状态。
-
ContentionList:锁竞争队列,所有请求锁的线程都被放在竞争队列中
-
EntryList竞争候选列表,在
ContentionList中有资格成为候选者来竞争锁资源的线程被移动到了EntryList中 -
WaitSet等待集合,调用
wait方法后被阻塞的线程将被放在WaitSet中 -
OnDeck竞争候选者,在同一时刻最多只有一个线程在竞争锁资源,该线程的状态被称为
OnDeck -
Owner竞争到锁资源的线程被称为
Owner状态线程 -
!Owner在
Owner线程释放后,会从Owner的状态变成!Owner。
synchronized在收到新的锁请求时首先自旋,如果通过自旋也没有获取锁资源,则将被放入锁竞争队列ContentionList中,Owner
会在释放锁资源的时候,将ContentionList中的部分线程移动到EntryList中,然后将EntryList中的某个线程(一般遵循先进先出规则)设为OnDeck线程。
值得注意的是,Owner并没有将锁资源直接交给OnDeck线程,而是把锁竞争的权利交给OnDeck线程,让OnDeck线程重新竞争锁,该操作牺牲了公平性,但提高了性能。
获取到锁资源的OnDeck线程会变成Owner线程,而未获取到锁资源的线程仍然停留在EntryList中。
Owner线程在被wait方法阻塞后,会被移动到WaitSet队列,直到notify方法或者notifyAll方法通知后被唤醒,从而进入到EntryList,重新竞争锁资源。
ReentrantLock实现原理
ReentrantLock是一个可重入的锁,内部采用AQS来实现
首先看一下AQS中比较重要的属性
exclusiveOwnerThread:独占锁线程,指向了当前获取到锁的线程
state:AQS的核心,AQS就是用这个字段来实现锁的获取和重入,在没有线程获取到锁的时候,锁的状态为0,获取的时候,通过cas对其进行+1,并且每重入一次再 +1,释放一次 -1,具体的后面代码展示
head,tail:AQS维护了一个内部类Node的双向队列,由未获取到锁的线程包装成的Node节点组成,也就是获取锁失败加入队列尾部。
AQS的获取锁过程分析
线程通过CAS将state从0设置为1,如果设置成功,说明获取锁成功,并且将exclusiveOwnerThread指向自己;
当调用lock方法时,公平锁和非公平锁的实现有区别
非公平锁的实现:线程会直接进行CAS操作去设置state,如果成功就获取到锁,如果失败,继续调用NonFairSync的acquire(1)方法
公平锁的实现:线程会直接调用FairSync的accquire(1)方法,这两个方法都调用了AQS的方法
公平锁与非公平锁的区别:
- //差别就在这里,多了一个hasQueuedPredecessors方法,这是跟非公平锁唯一的区别
- //也就是为什么叫公平锁体现在这里。
- //这里判断有没有别的线程比他更早来,如果返回true说明有,肯定就直接获取失败了
- //如果没有别他更早来的线程,那么自己就可以去尝试获取锁了
总结一下,AQS中维护了一堆wait线程组成的等待队列,凡是进入了这个队列的线程,之后就会按顺序一个一个获取到锁,执行逻辑,也就是将他们串行化了,那么公平和非公平体现在什么地方呢?
就是tryAcquire这里,公平锁是说新线程进来对于队列中的线程是公平的,如果队列中有等待线程,它就直接往后排,而非公平锁是,新线程对于队列中的等待线程是不公平的,可能存在队列中的头节点释放掉锁之后唤醒下一个线程,结果有一个新的线程进来同时获取锁,这个时候他们机会是平等的,因此说这是非公平锁。
具体的链接:https://blog.csdn.net/yanyan19880509/article/details/52345422
sychronized和lock共同点和区别
sychronized和ReentrantLock的共同点如下:
-
都用于控制多线程对共享对象的访问
-
都是可重用锁
-
都保证了可见性和互斥性
区别:
-
底层实现:sychronized是Java中的关键字,是由JVM来维护的,是JVM层面的锁 lock是一个类,是java代码层面的锁底层实现的
-
使用方式不同:sychronized在使用时候,获取锁和释放锁,都是由系统维护的。而使用lock的需要手动获取锁,手动释放锁。
-
异常的处理方式:sync在线程发生异常时会自动释放锁,不会发生异常死锁,Lock异常时不会自动释放锁,所以需要在finally中实现释放锁。
-
等待是否可中断:sychronized是不可中断的,除非抛出异常或者正常运行完成,Lock是可以中断的,中断方式有:
- 调用设置超时方法
tryLock(long timeout,timeUnit unit) - 调用
lockInterruptibly()放到代码块中,然后调用interrupt()方法可以中断
- 调用设置超时方法
-
加锁的时候是否可以公平:sync是非公平锁,lock既可以公平也可以不公平
-
锁可以绑定多个条件:
sync:要么随机唤醒一个线程,要么是唤醒所有等待的线程
lock:用来实现分组唤醒所需要唤醒的线程,可以精确的唤醒线程。
-
从锁的实现机制来看:
sync采用的是独占锁,也就是悲观锁的机制
lock采用的是乐观锁,所谓乐观锁就是每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。
volatile关键字
volatile,用来将变量的更新操作通知到其他线程,当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将改变量上的操作与其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
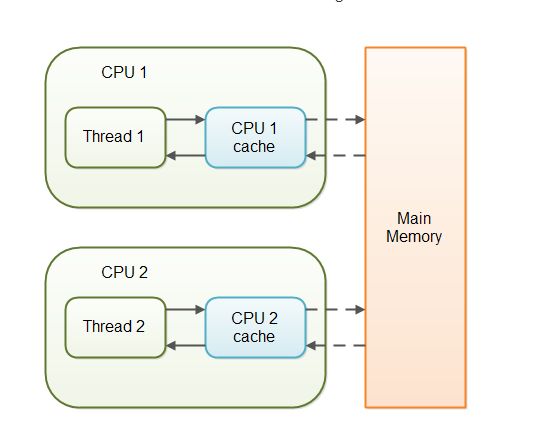
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到CPU缓存中。如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。
而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步。
当一个变量定义为volatile之后,将具备两种特性:
1.保证此变量对所有的线程的可见性,这里的“可见性”,如本文开头所述,当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,
2.禁止指令重排序优化。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置),只有一个CPU访问内存时,并不需要内存屏障;(什么是指令重排序:是指CPU采用了允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理)。
volatile 性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
线程池
线程池的结构:
- 线程池管理器
- 工作线程
- 任务接口
- 任务队列
线程池刚被创建时,只是向系统申请一个用于执行线程队列和管理线程池的线程资源,在调用execute()添加一个任务时,线程池会按照以下流程执行任务:
(1): 如果正在运行的线程数量小于corePoolSize(核心线程数量),线程池就会立刻创建线程并执行该线程任务
(2):如果正在运行的线程数量大于等于corePoolSize,该任务就将被放入阻塞队列中。
(3):在阻塞队列已满且正在运行的线程数量少于maximumPoolSize时,线程池会创建非核心线程立刻执行该线程任务
(4):在阻塞队列已满且正在运行的线程数量大于等于maximumPoolSize时,线程池将拒绝执行该线程任务并抛出RejectExecutionException异常
(5):在线程执行任务完毕后,该任务将被从线程池队列中移除,线程池将从队列中取下一个线程任务继续执行。
(6):在线程处于空闲状态的时间超过keepAliveTime时间时,正在运行的线程数量超过corePoolSize,该线程将会被认定为空闲线程并停止。因此在线程池中所有线程任务都执行完毕后,线程池会收缩到corePoolSize大小。
线程池的拒绝策略:
- AbortPolicy:直接抛出异常,阻止线程正常运行
- CallerRunsPolicy:如果被丢弃的线程未关闭,则执行该线程任务
- DiscardOldestPolicy: 移除线程队列中最早的一个线程任务,并尝试执行当前任务
- DiscardPolicy:丢弃当前任务而不做任何处理
- 自定义拒绝策略:继承RejectedExecutionHandler接口
五种常用的线程池:
- newCachedThreadPool:可缓存的线程池
- newFixedThreadPool:固定大小的线程池
- newScheduledThreadPool: 可做任务调度的线程池
- newSingleThreadExecutor: 单个线程的线程池
- newWorkStealingPool: 足够大小的线程池
Java线程的创建方式
-
继承Thread类
-
实现Runnable接口
-
通过ExecutorService和Callable实现有返回值的线程
Java中线程调度
两种线程的调度模式:
抢占式调度:
抢占式调度指的是每条线程执行的时间、线程的切换都由系统控制,系统控制指的是在系统某种运行机制下,可能每条线程都分同样的执行时间片,也可能是某些线程执行的时间片较长,甚至某些线程得不到执行的时间片。在这种机制下,一个线程的堵塞不会导致整个进程堵塞。
协同式调度:
协同式调度指某一线程执行完后主动通知系统切换到另一线程上执行,这种模式就像接力赛一样,一个人跑完自己的路程就把接力棒交接给下一个人,下个人继续往下跑。线程的执行时间由线程本身控制,线程切换可以预知,不存在多线程同步问题,但它有一个致命弱点:如果一个线程编写有问题,运行到一半就一直堵塞,那么可能导致整个系统崩溃。
JVM的实现:
JVM规范中规定每个线程都有优先级,且优先级越高越优先执行,但优先级高并不代表能独自占用执行时间片,可能是优先级高得到越多的执行时间片,反之,优先级低的分到的执行时间少但不会分配不到执行时间。
java使用的线程调度式抢占式调度
Java中线程会按优先级分配CPU时间片运行
线程让出cpu的情况:
-
当前运行线程主动放弃CPU,JVM暂时放弃CPU操作(基于时间片轮转调度的JVM操作系统不会让线程永久放弃CPU,或者说放弃本次时间片的执行权),例如调用yield()方法。
-
当前运行线程因为某些原因进入阻塞状态,例如阻塞在I/O上。
-
当前运行线程结束,即运行完run()方法里面的任务。
进程调度算法
- 优先调度算法
- 先来先服务调度算法
- 短作业(进程)优先调度算法
- 高优先权优先调度算法
- 抢占式优先调度算法
- 非抢占式优先调度算法
- 高响应比优先调度算法
- 时间片的轮转调度算法
- 时间片轮转法
- 多级反馈队列调度算法
JVM内存结构介绍
- 虚拟机栈:线程私有的内存区域,每创建一个线程都会对应创建一个Java栈,这个栈中又会对应多个栈帧,栈帧是用来存储方法数据和部分过程结果的数据结构,每调用一个方法就会往栈中创建并压入一个栈帧,每一个方法从调用到最终返回结果的过程,就对应一个栈帧从入栈到出栈的过程。
- 程序计数器:保存着当前线程执行的虚拟机字节码指令的内存地址。每个线程都会设立一个程序计数器,程序计数器是线程私有的内存区域
- 本地方法栈:和虚拟机栈的作用相似,不过虚拟机栈是为Java方法服务的,而本地方法栈是为Native方法服务的。
- 方法区:方法区(Method Area)是用于存储类结构信息的地方,包括常量池、静态变量、构造函数等类型信息,类型信息是由类加载器在类加载时从类文件中提取出来的。方法区同样存在垃圾收集,因为用户通过自定义加载器加载的一些类同样会成为垃圾,JVM会回收一个未被引用类所占的空间,以使方法区的空间达到最小。方法区中还存在着常量池,常量池包含着一些常量和符号引用(加载类的连接阶段中的解析过程会将符号引用转换为直接引用)。方法区是线程共享的。
- 堆:堆(heap)是存储java实例或者对象的地方,是GC的主要区域,同样是线程共享的内存区域。
总结:
-
所有线程共享的内存数据区:方法区,堆。而虚拟机栈,本地方法栈和程序计数器都是线程私有的。
-
存放于栈中的东西如下:
- 每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象)。对象都存放在堆区中。
- 每个栈中的数据(基础数据类型和对象引用)都是私有的,其他栈不能访问。
- 方法的形式参数,方法调用完后从栈空间回收
- 引用对象的地址,引用完后,栈空间地址立即被回收,堆空间等待GC
-
存放于堆中的东西如下:
- 存储的全部是对象,每个对象包含一个与之对应的class信息
- Jvm只有一个堆区(heap)被所有线程共享,堆区中不存放基本类型和对象引用,只存放对象本身
-
存放于方法区中的东西如下:
- 存放线程所执行的字节码指令
- 跟堆一样.被所有线程共享.方法区包含:所有的class和static变量
- 常量池位于方法区中
垃圾回收算法
新生代的垃圾回收算法:
- Serial:单线程复制算法
- ParNew:多线程复制算法:默认开启与CPu同等数量的线程进行垃圾回收
- Parallel Scavenge:多线程复制算法:提供了三个参数用于调节、控制垃圾回收的停顿时间及吞吐量,分别是控制最大垃圾收集停顿时间、控制吞吐量的大小、控制自适应调节策略开启与否的参数。
老年代的垃圾回收算法:
- CMS:多线程标记清除算法
- Serial Old:单线程标记整理算法
- Parallel Old:多线程标记整理算法:在设计上优先考虑吞吐量,其次考虑停顿时间等因素
全区收集算法:
- G1:多线程标记整理算法
CMS垃圾收集器介绍:
CMS主要目的是达到最短的垃圾回收停顿时间,基于线程的标记清除算法实现。
四个阶段:
- 初始标记:只标记和GC Roots直接关联的对象,速度很快,需要暂停所有工作线程
- 并发标记:标记GC Root间接关联的对象,不需要暂停工作线程
- 重新标记:在并发标记过程中用户线程继续执行使得部分对象的状态发生了变化,需要重新标记,需要暂停所有工作线程
- 并发清除:清除GC Roots 不可达的对象。
引用计数和可达性分析
引用计数法:在为对象添加一个引用时,引用计数加1,在为对象删除一个引用时,引用计数减1,如果引用计数为0,说明此刻该对象没有被引用,可以被回收。引用计数法容易产生循环引用的问题,使得对象不能被回收。
可达性分析:首先定义一些GC Roots对象,然后以这些GC Roots对象作为起点向下搜索,如果在GC Roots和一个对象之间没有可达路径,则称该对象是不可达的,不可达的对象至少经过两次标记才能判断其是否可以被回收,如果在两次标记后,该对象任然不可达的,则将被垃圾回收器回收。
Java内存溢出(OOM)异常排查
OOM:java heap space
**原因1:**当应用程序试图向堆空间添加更多的数据,但堆却没有足够的空间来容纳这些数据时,将会触发OOM: Java heap space异常。需要注意的是:即使有足够的物理内存可用,只要达到堆空间设置的大小限制,此异常仍然会被触发。可以使用参数-Xmx和-XX:MaxPermSize设置堆空间的大小
**原因2:**流量/数据量峰值:应用程序在设计之初均有用户量和数据量的限制,某一时刻,当用户数量或数据量突然达到一个峰值,并且这个峰值已经超过了设计之初预期的阈值,那么以前正常的功能将会停止,并触发OOM: Java heap space异常。
**原因3:**内存泄漏:特定的编程错误会导致你的应用程序不停的消耗更多的内存,每次使用有内存泄漏风险的功能就会留下一些不能被回收的对象到堆空间中,随着时间的推移,泄漏的对象会消耗所有的堆空间,最终触发OOM: Java heap space错误。
OOM:GC overhead limit exceeded
**原因:**当应用程序花费超过98%的实践用来做GC并且回收了不到2%的堆内存时,会抛出OOM:GC overhead limit exceeded错误,具体表现就是你的应用几乎耗尽所有可用内存,并且GC多次均未能清理干净。
OOM:Permgen space
Java1.7中会出现这个错误,Java1.8已经采用元空间(MetaSpace)来取代,不会出现这种错误。
Java中堆空间是JVM管理的最大一块内存空间,可以在JVM启动时指定堆空间的大小,其中堆被划分成两个不同的区域:新生代(Young)和老年代(Tenured),新生代又被划分为3个区域:Eden、From Survivor、To Survivor
java.lang.OutOfMemoryError: PermGen space错误就表明持久代所在区域的内存已被耗尽。
**原因:首先需要理解Permanent Generation Space的用处是什么。持久代主要存储的是每个类的信息,比如:类加载器引用、运行时常量池(所有常量、字段引用、方法引用、属性)、字段(Field)数据、方法(Method)数据、方法代码、**方法字节码等等。我们可以推断出,PermGen的大小取决于被加载类的数量以及类的大小。因此,我们可以得出出现java.lang.OutOfMemoryError: PermGen space错误的原因是:太多的类或者太大的类被加载到permanent generation(持久代)。
解决方案:
-
1.解决初始化时的OOM
当在应用程序启动期间触发由于
PermGen耗尽引起的OutOfMemoryError时,解决方案很简单。 应用程序需要更多的空间来加载所有的类到PermGen区域,所以我们只需要增加它的大小。 为此,请更改应用程序启动配置,并添加(或增加,如果存在)-XX:MaxPermSize参数,类似于以下示例:java -XX:MaxPermSize=512m com.yourcompany.YourClass -
2.解决Redeploy时的OOM
分析dump文件:首先,找出引用在哪里被持有;其次,给你的web应用程序添加一个关闭的hook,或者在应用程序卸载后移除引用。你可以使用如下命令导出dump文件:
jmap -dump:format=b,file=dump.hprof如果是你自己代码的问题请及时修改,如果是第三方库,请试着搜索一下是否存在"关闭"接口,如果没有给开发者提交一个bug或者issue吧。
-
3.解决运行时OOM
首先你需要检查是否允许GC从
PermGen卸载类,JVM的标准配置相当保守,只要类一创建,即使已经没有实例引用它们,其仍将保留在内存中,特别是当应用程序需要动态创建大量的类但其生命周期并不长时,允许JVM卸载类对应用大有助益,你可以通过在启动脚本中添加以下配置参数来实现:-XX:+CMSClassUnloadingEnabled默认情况下,这个配置是未启用的,如果你启用它,GC将扫描
PermGen区并清理已经不再使用的类。但请注意,这个配置只在UseConcMarkSweepGC的情况下生效,如果你使用其他GC算法,比如:ParallelGC或者Serial GC时,这个配置无效。所以使用以上配置时,请配合:-XX:+UseConcMarkSweepGC如果你已经确保JVM可以卸载类,但是仍然出现内存溢出问题,那么你应该继续分析dump文件,使用以下命令生成dump文件:
jmap -dump:file=dump.hprof,format=b当你拿到生成的堆转储文件,并利用像Eclipse Memory Analyzer Toolkit这样的工具来寻找应该卸载却没被卸载的类加载器,然后对该类加载器加载的类进行排查,找到可疑对象,分析使用或者生成这些类的代码,查找产生问题的根源并解决它。
OOM:Metaspace
**原因:**太多的类或太大的类加载到元空间。
**解决方法:**扩大MetaSpace的空间
OOM:Unable to create new native thread
JVM中的线程完成自己的工作也是需要一些空间的,当有足够多的线程却没有那么多的空间时就会像这样:
OOM:Out of swap space
Java应用程序在启动时会指定所需要的内存大小,可以通过-Xmx和其他类似的启动参数来指定。在JVM请求的总内存大于可用物理内存的情况下,操作系统会将内存中的数据交换到磁盘上去。Out of swap space?表示交换空间也将耗尽,并且由于缺少物理内存和交换空间,再次尝试分配内存也将失败。
OOM:Requested array size exceeds VM limit
Java对应用程序可以分配的最大数组大小有限制。不同平台限制有所不同,但通常在1到21亿个元素之间。
OOM:Out of memory:Kill process or sacrifice child
为了理解这个错误,我们需要补充一点操作系统的基础知识。操作系统是建立在进程的概念之上,这些进程在内核中作业,其中有一个非常特殊的进程,名叫“内存杀手(Out of memory killer)”。当内核检测到系统内存不足时,OOM killer被激活,然后选择一个进程杀掉。
OOM:kill process or sacrifice child
为了理解这个错误,我们需要补充一点操作系统的基础知识。操作系统是建立在进程的概念之上,这些进程在内核中作业,其中有一个非常特殊的进程,名叫“内存杀手(Out of memory killer)”。当内核检测到系统内存不足时,OOM killer被激活,然后选择一个进程杀掉。哪一个进程这么倒霉呢?选择的算法和想法都很朴实:谁占用内存最多,谁就被干掉。
怎么排查线程问题
1. 通过top命令查看当前系统CPU使用情况,定位CPU使用率超过100%的进程ID;
2. 通过ps aux | grep PID命令进一步确定具体的线程信息;
3. 通过ps -mp pid -o THREAD,tid,time命令显示线程信息列表,然后找到耗时的线程ID;
4. 将需要的线程ID转换为16进制格式:printf "%x\n" tid
5. 最后找到线程堆栈信息:jstack pid |grep tid ,其中tid是上面转换后的16进制的线程ID
虚拟机性能监控和故障处理工具
虚拟机进程状况工具 (jps)
jps :JVM Process Status Tool
功能: 列出正在运行的虚拟机进程,并显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一ID
虚拟机统计信息监视工具(jstat)
jstat : JVM Statistics Monitoring Tool
功能:用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程的类装载、内存、垃圾回收、JIT编译等运行数据。
例子:假如需要每250毫秒查询一次进程2764的垃圾收集状况,一共查询20次,那么命令应该是
jstat -gc 2764 250 20
jinfo: Java配置信息工具
功能:实时查看和调整虚拟机各项参数。
jmap: Java内存映像工具
功能:用于生成堆转储快照。如果不想使用jmap命令,要想获得堆转储快照,还有其他方法:
- 用 -XX:+HeapDumpOnOutOfMemoryError参数,可以让虚拟机在OOM异常出现之后自动生成dump文件
- 用 -XX:+HeapDumpOnCtrlBreak参数,可以使用[ctrl]+[break]键让虚拟机生成dump文件。
- 又或者在Linux系统下通过 Kill -3 命令发送进程退出信号“吓唬”一下虚拟机,也能拿到dump文件。
jmap的作用并不仅仅是为了获取dump文件,还可以查询finalize执行队列、Java堆和永久代的详细信息、如空间使用率、当前使用的时哪种收集器等。
jhat: 虚拟机堆转储快照分析工具
功能:配合jmap使用,分析dump文件,但一般不用,因为有比其更优秀的分析工具。
jstack:Java堆栈跟踪工具
jstack命令用于生成虚拟机当前时刻的线程快照(一般称为threaddump或者javacore文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。生成快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁,死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的常见原因。
死锁出现的原因
什么是死锁、产生死锁的原因、解决死锁的基本办法、避免死锁、预防死锁、死锁检测、解除死锁
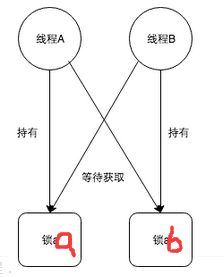
所谓死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。 因此我们举个例子来描述,如果此时有一个线程A,按照先锁a再获得锁b的的顺序获得锁,而在此同时又有另外一个线程B,按照先锁b再锁a的顺序获得锁。如下图所示:
可以归结为两点:
-
竞争资源
-
可剥夺资源,是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU和主存均属于可剥夺性资源;
-
另一类资源是不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
-
产生死锁中的竞争资源之一指的是竞争不可剥夺资源(例如:系统中只有一台打印机,可供进程P1使用,假定P1已占用了打印机,若P2继续要求打印机打印将阻塞)
-
产生死锁中的竞争资源另外一种资源指的是竞争临时资源(临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
-
-
进程间顺序推进法
- 若P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁
- 例如,当P1运行到P1:Request(R2)时,将因R2已被P2占用而阻塞;当P2运行到P2:Request(R1)时,也将因R1已被P1占用而阻塞,于是发生进程死锁
死锁的必要条件
产生死锁的必要条件:
- 1.互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 2.请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 3.不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 4.环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
死锁的避免
预防死锁的四点解决办法:
- 1.资源一次性分配:一次性分配所有资源,这样就不会再有请求了:(破坏请求条件)
- 2.只要有一个资源的不到分配,也不给这个进程分配其他的资源:(破坏请求保持条件)
- 3.可剥夺资源:即当某进程获得了部分资源,但得不到其他资源,则释放已占有的资源(破坏不可剥夺条件)
- 4.资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
避免死锁:
- 预防死锁的几种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从而获得 较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因而,系统在进行资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进入不安全的状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银行家算法。
- 银行家算法:首先需要定义状态和安全状态的概念。系统的状态是当前给进程分配的资源情况。因此,状态包含两个向量Resource(系统中每种资源的总量)和Available(未分配给进程的每种资源的总量)及两个矩阵Claim(表示进程对资源的需求)和Allocation(表示当前分配给进程的资源)。安全状态是指至少有一个资源分配序列不会导致死锁。当进程请求一组资源时,假设同意该请求,从而改变了系统的状态,然后确定其结果是否还处于安全状态。如果是,同意这个请求;如果不是,阻塞该进程知道同意该请求后系统状态仍然是安全的。
JVM类加载机制
java文件通过编译器变成了.class文件,接下来类加载器又将这些.class文件加载到JVM中。其中类装载器的作用其实就是类的加载,类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个 java.lang.Class对象,用来封装类在方法区内的数据结构。
在什么时候才会启动类加载器?
其实,类加载器并不需要等到某个类被“首次主动使用”时再加载它,JVM规范允许类加载器在预料某个类将要被使用时就预先加载它,如果在预先加载的过程中遇到了.class文件缺失或存在错误,类加载器必须在程序首次主动使用该类时才报告错误(LinkageError错误)如果这个类一直没有被程序主动使用,那么类加载器就不会报告错误。
从哪个地方去加载.class文件
在这里进行一个简单的分类。例举了5个来源
(1)本地磁盘
(2)网上加载.class文件(Applet)
(3)从数据库中
(4)压缩文件中(ZAR,jar等)
(5)从其他文件生成的(JSP应用)
JVM的类的生命周期
类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
-
加载:
JVM读取class文件,并且根据class文件描述创建java.lang.Class对象的过程
-
验证:
用于确保Class文件符合当前虚拟机的要求,保障JVM自身的安全
-
准备:
主要工作是在方法区中为类变量分配内存空间并设置类中变量的初始值,非final类型的变量会设置为不同数据类型的默认值,在初始化阶段的时候再赋予真实值,final类型的变量会根据实际值在准备阶段就赋予了真实值。
-
解析:
会将常量池中的符号引用替换为直接引用
-
初始化:
这是类加载机制的最后一步,在这个阶段,java程序代码才开始真正执行。我们知道,在准备阶段已经为类变量赋过一次值。在初始化阶端,程序员可以根据自己的需求来赋值了。一句话描述这个阶段就是执行类构造器< client>()方法的过程。
在初始化阶段,主要为类的静态变量赋予正确的初始值,JVM负责对类进行初始化,主要对类变量进行初始化。在Java中对类变量进行初始值设定有两种方式:
①声明类变量是指定初始值
②使用静态代码块为类变量指定初始值
JVM初始化步骤
1、假如这个类还没有被加载和连接,则程序先加载并连接该类
2、假如该类的直接父类还没有被初始化,则先初始化其直接父类
3、假如类中有初始化语句,则系统依次执行这些初始化语句
类初始化时机:只有当对类的主动使用的时候才会导致类的初始化,类的主动使用包括以下六种:
- 创建类的实例,也就是new的方式
- 访问某个类或接口的静态变量,或者对该静态变量赋值
- 调用类的静态方法
- 反射(如 Class.forName(“com.shengsiyuan.Test”))
- 初始化某个类的子类,则其父类也会被初始化
-
使用
-
卸载
类加载器
-
Bootstrap ClassLoader:
最顶层的加载类,主要加载核心类库,也就是我们环境变量下面%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等
-
Extention ClassLoader:
扩展的类加载器,加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件
-
AppClassLoader:
也称为SystemAppClass。 加载当前应用的classpath的所有类。
-
自定义类加载器
类加载的三种方式。
(1)通过命令行启动应用时由JVM初始化加载含有main()方法的主类。
(2)通过Class.forName()方法动态加载,会默认执行初始化块(static{}),但是Class.forName(name,initialize,loader)中的initialze可指定是否要执行初始化块。
(3)通过ClassLoader.loadClass()方法动态加载,不会执行初始化块。
双亲委派原则
当一个类加载器收到类加载任务,会先交给其父类加载器去完成,因此最终加载任务都会传递到顶层的启动类加载器,只有当父类加载器无法完成加载任务时,才会尝试执行加载任务。
采用双亲委派的好处:
- 是比如加载位于rt.jar包中的类java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。
- 双亲委派原则归纳一下就是:可以避免重复加载,父类已经加载了,子类就不需要再次加载更加安全,很好的解决了各个类加载器的基础类的统一问题,如果不使用该种方式,那么用户可以随意定义类加载器来加载核心api,会带来相关隐患。
BIO NIO AIO
BIO 阻塞IO
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待完成。
采用 BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在 while(true) 循环中服务端会调用 accept() 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,通过多线程来支持多个客户端的连接。
当线程数量过多,就会使cpu负载过重,占用大量的资源,不过可以通过 线程池机制 改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M)
NIO 阻塞IO
NIO使用了多路复用器机制,以socket使用来说,多路复用器(Selector)通过不断轮询各个连接的状态,只有在socket有流可读或者可写时,应用程序才需要去处理它,在线程的使用上,就不需要一个连接就必须使用一个处理线程了,而是只是有效请求时(确实需要进行I/O处理时),才会使用一个线程去处理,这样就避免了BIO模型下大量线程处于阻塞等待状态的情景。
相对于BIO的流,NIO抽象出了新的通道(Channel)作为输入输出的通道,并且提供了缓存(Buffer)的支持,在进行读操作时,需要使用Buffer分配空间,然后将数据从Channel中读入Buffer中,对于Channel的写操作,也需要现将数据写入Buffer,然后将Buffer写入Channel中。
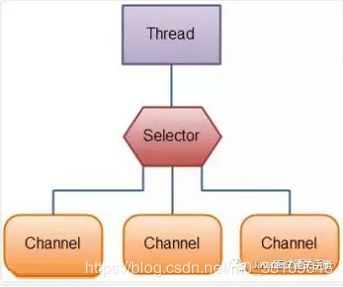
NIO 包含下面几个核心的组件:
- Channel(通道)
- Buffer(缓冲区)
- Selector(选择器)
整个NIO体系包含的类远远不止这三个,只能说这三个是NIO体系的“核心API”。我们上面已经对这三个概念进行了基本的阐述,这里就不多做解释了。
AIO 异步IO
Linux操作系统中的五种操作模型
-
阻塞IO模型
阻塞 I/O 是最简单的 I/O 模型,一般表现为进程或线程等待某个条件,如果条件不满足,则一直等下去。条件满足,则进行下一步操作。
举个例子:我们什么也不做,双手一直把着鱼竿,就静静的等着鱼儿咬钩。一旦手上感受到鱼的力道,就把鱼钓起来放入鱼篓中。然后再钓下一条鱼。
-
非阻塞IO模型
应用进程与内核交互,目的未达到之前,不再一味的等着,而是直接返回。然后通过轮询的方式,不停的去问内核数据准备有没有准备好。如果某一次轮询发现数据已经准备好了,那就把数据拷贝到用户空间中。
我们钓鱼的时候,在等待鱼儿咬钩的过程中,我们可以做点别的事情,比如玩一把王者荣耀、看一集《延禧攻略》等等。但是,我们要时不时的去看一下鱼竿,一旦发现有鱼儿上钩了,就把鱼钓上来。
-
IO复用模型
多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。
我们钓鱼的时候,为了保证可以最短的时间钓到最多的鱼,我们同一时间摆放多个鱼竿,同时钓鱼。然后哪个鱼竿有鱼儿咬钩了,我们就把哪个鱼竿上面的鱼钓起来。
-
信号驱动IO模型
应用进程在读取文件时通知内核,如果某个 socket 的某个事件发生时,请向我发一个信号。在收到信号后,信号对应的处理函数会进行后续处理。
我们钓鱼的时候,为了避免自己一遍一遍的去查看鱼竿,我们可以给鱼竿安装一个报警器。当有鱼儿咬钩的时候立刻报警。然后我们再收到报警后,去把鱼钓起来。
-
异步IO模型
应用进程把IO请求传给内核后,完全由内核去操作文件拷贝。内核完成相关操作后,会发信号告诉应用进程本次IO已经完成。
我们钓鱼的时候,采用一种高科技钓鱼竿,即全自动钓鱼竿。可以自动感应鱼上钩,自动收竿,更厉害的可以自动把鱼放进鱼篓里。然后,通知我们鱼已经钓到了,他就继续去钓下一条鱼去了。
Java中的代理模式
1、什么是代理模式
代理模式:就是为其他对象提供一种代理以控制对这个对象的访问。
代理可以在不改动目标对象的基础上,增加其他额外的功能(扩展功能)。
2 静态代理
静态代理在使用时,需要定义接口或者父类,被代理对象(目标对象)与代理对象(Proxy)一起实现相同的接口或者是继承相同父类。
静态代理总结:
可以实现在不修改目标对象的基础上,对目标对象的功能进行扩展。
但是由于代理对象需要与目标对象实现一样的接口,所以会有很多代理类,类太多.同时,一旦接口增加方法,目标对象与代理对象都要维护.
可以使用动态代理方式来解决。
动态代理
1.代理对象,不需要实现接口
2.代理对象的生成,是利用JDK的API,动态的在内存中创建代理对象(需要我们指定创建代理对象/目标对象实现的接口的类型)
3.动态代理也叫做:JDK代理,接口代理
Cglib代理
JDK的动态代理机制只能代理实现了接口的类,而不能实现接口的类就不能实现JDK的动态代理,cglib是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。
Cglib代理,也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展
Cglib子类代理实现方法:
1.需要引入cglib的jar文件,但是Spring的核心包中已经包括了Cglib功能,所以直接引入Spring-core.jar即可.
2.引入功能包后,就可以在内存中动态构建子类
3.代理的类不能为final,否则报错
4.目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法.
countDownLatch CyclicBarrier 信号量
countDownLatch
- countDownLatch这个类使一个线程等待其他线程各自执行完毕后再执行。
- 是通过一个计数器来实现的,计数器的初始值是线程的数量。每当一个线程执行完毕后,计数器的值就-1,当计数器的值为0时,表示所有线程都执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
CountDownLatch和CyclicBarrier区别:
- countDownLatch是一个计数器,线程完成一个记录一个,计数器递减,只能只用一次
- CyclicBarrier的计数器更像一个阀门,需要所有线程都到达,然后继续执行,计数器递增,提供reset功能,可以多次使用
信号量
你可以认为信号量是一个可以递增或递减的计数器。你可以初始化一个信号量的值为5,此时这个信号量可最大连续减少5次,直到计数器为0。当计数器为0时,你可以让其递增5次,使得计数器值为5。在我们的例子中,信号量的计数器始终限制在[0~5]之间。
显然,信号量并不仅仅是计数器。当计数器值为0时,它们可以使线程等待,即它们是具有计数器功能的锁。
就多线程而言,当一个线程要访问共享资源(由信号量保护)时,首先,它必须获得信号量。如果信号量的内部计数器大于0时,信号量递减计数器,并允许访问共享资源。否则,如果信号量的计数器为0,则信号量将线程置于休眠状态,直到计数器大于0。计数器中的值为0意味着所有共享资源都被其他线程使用,因此希望使用共享资源的线程必须等到有线程空闲(释放信号量)。
java开发设计—七大原则
-
开闭原则
当应用需求改变时,在不修改软件实体的源代码或者二进制代码的前提下可以扩展模块的功能,使其满足新的需求。
-
里氏替换原则
子类可以扩展父类的功能,但不能改变父类原有的功能。也就是说:子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
-
依赖倒置原则
要面向接口编程,不要面向具体的实现编程。
-
单一职责原则
一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分。
-
接口隔离原则
要为各个类建立它们所需要的专用接口,而不要试图建立一个很庞大的接口供所有依赖它的类去调用。
-
迪米特原则
只与你的直接朋友交谈,不跟“陌生人”说话。其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
-
合成复用原则
他要求在软件复用的时候,要尽量使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
阻塞 非阻塞 同步 异步
IO操作
IO分两阶段(一旦拿到数据后就变成了数据操作,不再是IO):
1.数据准备阶段
2.内核空间复制数据到用户进程缓冲区(用户空间)阶段
在操作系统中,程序运行的空间分为内核空间和用户空间。
应用程序都是运行在用户空间的,所以它们能操作的数据也都在用户空间。
阻塞IO和非阻塞IO的区别在于第一步发起IO请求是否会被阻塞:
如果阻塞直到完成那么就是传统的阻塞IO,如果不阻塞,那么就是非阻塞IO。
一般来讲:
阻塞IO模型、非阻塞IO模型、IO复用模型(select/poll/epoll)、信号驱动IO模型都属于同步IO,因为阶段2是阻塞的(尽管时间很短)。
同步IO和异步IO的区别就在于第二个步骤是否阻塞:
如果不阻塞,而是操作系统帮你做完IO操作再将结果返回给你,那么就是异步IO
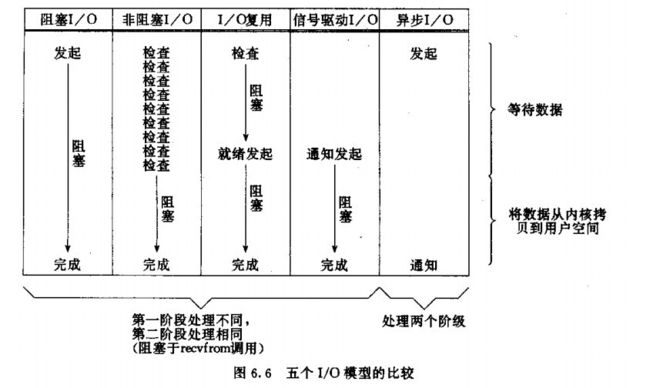
同步和异步IO 阻塞和非阻塞IO
同步和异步IO的概念:
同步是用户线程发起I/O请求后需要等待或者轮询内核I/O操作完成后才能继续执行
异步是用户线程发起I/O请求后仍需要继续执行,当内核I/O操作完成后会通知用户线程,或者调用用户线程注册的回调函数
阻塞和非阻塞IO的概念:
阻塞是指I/O操作需要彻底完成后才能返回用户空间
非阻塞是指I/O操作被调用后立即返回一个状态值,无需等I/O操作彻底完成
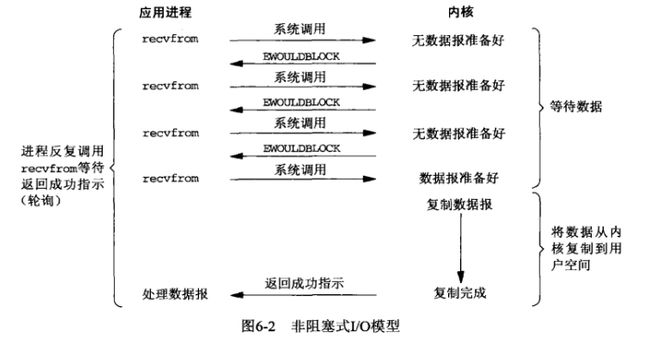
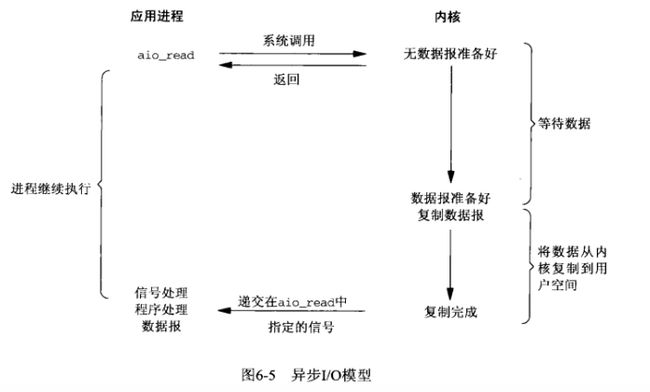
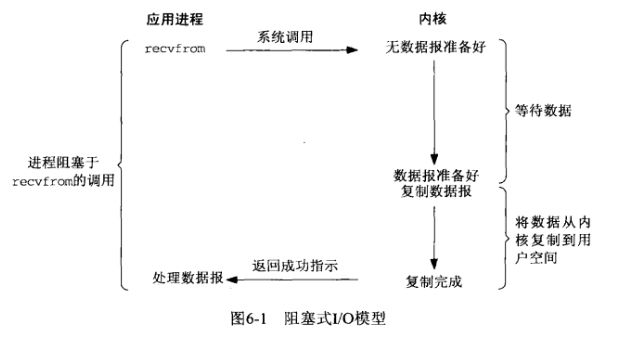
同步与异步(线程间调用)
同步与异步是对应于调用者与被调用者,它们是线程之间的关系,两个线程之间要么是同步的,要么是异步的
同步操作时,调用者需要等待被调用者返回结果,才会进行下一步操作
而异步则相反,调用者不需要等待被调用者返回结果,即可进行下一步操作,被调用者通常依靠事件、回调等机制来通知调用者结果
阻塞和非阻塞(线程内调用)
阻塞与非阻塞是对同一个线程来说的,在某个时刻,线程要么处于阻塞,要么处于非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态:
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
数据库基础
Mysql常用的存储引擎
MyISAM是MySQL存储引擎之一,不支持数据库事务、行级锁、和外键。因此在INSERT或UPDATE数据即写操作时需要锁定整个表,效率会很低
InnoDB为MySQL提供了事务支持、回滚、崩溃修复能力、多版本并发控制、事务安全的操作。
InnoDB有什么特性
InnoDB引擎特点
1.支持事务,支持4个事务隔离级别,支持多版本读。
2.行级锁定(更新时一般是锁定当前行),通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。
3.读写阻塞与事务隔离级别相关。
4.具有非常高效的缓存特性:能缓存索引,也能缓存数据。
5.整个表和主键以Cluster方式存储,组成一个平衡树。
6.所有Secondary Index都会保存主键信息。
7.支持分区,表空间,类似oracle数据库。
8.支持外键约束,5.5之前不支持全文索引,5.5之后支持外键索引。
小结:supports transactions,row-level locking。and foreign keys
9.和Myisam引擎比,Innodb对硬件资源要求比较高。
MySQL引擎之innodb引擎应用场景及调优
Innodb引擎适用的生产场景
1、需要事务支持的业务(具有较好的事务特性)
2、行级锁定对高并发有很好的适应能力,但需要确保查询时通过索引完成。
3、数据读写及更新都较为频繁的场景,如:bbs,sns,微博,微信等。
4、数据一致性要求较高的业务,例如:充值转账,银行卡转账。
5、硬件设备内存较大,可以利用Innodb较好的缓存能力来提高内存利用率,尽可能减少磁盘IO。
redolog 和binlog的区别
-
redolog
redo log又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
-
binlog
binlog记录了对MySQL数据库执行更改的所有操作,但是不包括SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改。然后,若操作本身例如update操作并没有导致数据库发生变化,那么该操作也会写入二进制日志。
-
undolog
Undo Log是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用UndoLog来实现多版本并发控制(简称:MVCC)。Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为UndoLog)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用UndoLog中的备份将数据恢复到事务开始之前的状态。除了可以保证事务的原子性,Undo Log也可以用来辅助完成事务的持久化(即在事务执行的过程中断电了,恢复后我们依然可以进行回滚操作)。
-用Undo Log实现原子性和持久化的事务的简化过程
假设有A、B两个数据,值分别为1,2。
A.事务开始.
B.记录A=1到undolog.
C.修改A=3.
D.记录B=2到undolog.
E.修改B=4.
F.将undolog写到磁盘。
G.将数据写到磁盘。
H.事务提交
这里有一个隐含的前提条件:‘数据都是先读到内存中,然后修改内存中的数据,最后将数据写回磁盘’。
之所以能同时保证原子性和持久化,是因为以下特点:
A.更新数据前记录Undo log。
B.为了保证持久性,必须将数据在事务提交前写到磁盘。只要事务成功提交,数据必然已经持久化。
C.Undo log必须先于数据持久化到磁盘。如果在G,H之间系统崩溃,undo log是完整的,可以用来回滚事务。D.如果在A-F之间系统崩溃,因为数据没有持久化到磁盘。所以磁盘上的数据还是保持在事务开始前的状态。
缺陷:每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。
如果能够将数据缓存一段时间,就能减少IO提高性能。但是这样就会丧失事务的持久性。因此引入了另外一种机制来实现持久化,即RedoLog -
Redo log记录的是新数据的备份。在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是RedoLog已经持久化。系统可以根据RedoLog的内容,将所有数据恢复到最新的状态。
-Undo+Redo事务的简化过程
假设有A、B两个数据,值分别为1,2.
A.事务开始.
B.记录A=1到undolog.
C.修改A=3.
D.记录A=3到redolog.
E.记录B=2到undolog.
F.修改B=4.
G.记录B=4到redolog.
H.将redolog写入磁盘。
I.事务提交-Undo+Redo事务的特点
A.为了保证持久性,必须在事务提交前将RedoLog持久化。
B.数据不需要在事务提交前写入磁盘,而是缓存在内存中。
C.RedoLog保证事务的持久性。
D.UndoLog保证事务的原子性。
E.有一个隐含的特点,数据必须要晚于redolog写入持久存
选择binlog日志作为replication我想主要原因是MySQL的特点就是支持多存储引擎,为了兼容绝大部分引擎来支持复制这个特性,那么自然要采用MySQL Server自己记录的日志而不是仅仅针对InnoDB的redo log
binlog属于逻辑日志,是逻辑操作。innodb redo属于物理日志,是物理变更。
binlog作用
1.恢复使能够最大可能地更新数据库,因为二进制日志包含备份后进行的所有更新。
2.在主复制服务器上记录所有将发送给从服务器的语句。
MVCC(多版本并发控制)
MVCC(Mutil-Version Concurrency Control),就是多版本并发控制。MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问。
在Mysql的InnoDB引擎中就是指在已提交读(READ COMMITTD)和可重复读(REPEATABLE READ)这两种隔离级别下的事务对于SELECT操作会访问版本链中的记录的过程。
这就使得别的事务可以修改这条记录,反正每次修改都会在版本链中记录。SELECT可以去版本链中拿记录,这就实现了读-写,写-读的并发执行,提升了系统的性能。
我们来具体看看是如何实现的。
版本链
我们先来理解一下版本链的概念。在InnoDB引擎表中,它的聚簇索引记录中有两个必要的隐藏列:
trx_id这个id用来存储的每次对某条聚簇索引记录进行修改的时候的事务id。
roll_pointer每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)
![]()
比如现在有个事务id是60的执行的这条记录的修改语句
此时在undo日志中就存在版本链

ReadView
说了版本链我们再来看看ReadView。已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
ReadView中主要就是有个列表来存储我们系统中当前活跃着的读写事务,也就是begin了还未提交的事务。通过这个列表来判断记录的某个版本是否对当前事务可见。假设当前列表里的事务id为[80,100]。
如果你要访问的记录版本的事务id为50,比当前列表最小的id80小,那说明这个事务在之前就提交了,所以对当前活动的事务来说是可访问的。如果你要访问的记录版本的事务id为70,发现此事务在列表id最大值和最小值之间,那就再判断一下是否在列表内,如果在那就说明此事务还未提交,所以版本不能被访问。如果不在那说明事务已经提交,所以版本可以被访问。如果你要访问的记录版本的事务id为110,那比事务列表最大id100都大,那说明这个版本是在ReadView生成之后才发生的,所以不能被访问。这些记录都是去版本链里面找的,先找最近记录,如果最近这一条记录事务id不符合条件,不可见的话,再去找上一个版本再比较当前事务的id和这个版本事务id看能不能访问,以此类推直到返回可见的版本或者结束。
举个例子 ,在已提交读隔离级别下:
比如此时有一个事务id为100的事务,修改了name,使得的name等于小明2,但是事务还没提交。则此时的版本链是

那此时另一个事务发起了select 语句要查询id为1的记录,那此时生成的ReadView 列表只有[100]。那就去版本链去找了,首先肯定找最近的一条,发现trx_id是100,也就是name为小明2的那条记录,发现在列表内,所以不能访问。
这时候就通过指针继续找下一条,name为小明1的记录,发现trx_id是60,小于列表中的最小id,所以可以访问,直接访问结果为小明1。
那这时候我们把事务id为100的事务提交了,并且新建了一个事务id为110也修改id为1的记录,并且不提交事务
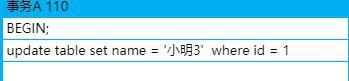
这时候版本链就是
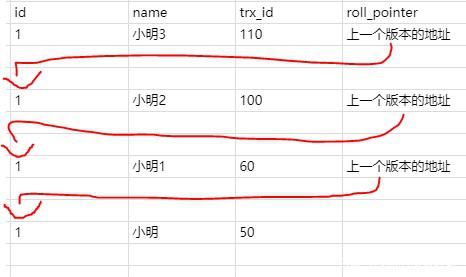
这时候之前那个select事务又执行了一次查询,要查询id为1的记录。
这个时候关键的地方来了
如果你是已提交读隔离级别,这时候你会重新一个ReadView,那你的活动事务列表中的值就变了,变成了[110]。
按照上的说法,你去版本链通过trx_id对比查找到合适的结果就是小明2。
如果你是**可重复读隔离级别,这时候你的ReadView还是第一次select时候生成的ReadView,**也就是列表的值还是[100]。所以select的结果是小明1。所以第二次select结果和第一次一样,所以叫可重复读!
也就是说已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
这就是Mysql的MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同实现不同的隔离级别。
删除重复的邮件地址
mysql删除重复数据保留id最小(最大)的数据:
DELETE p1
FROM
Person p1,
Person p2
WHERE
p1.Email = p2.Email
AND p1.Id > p2.Id
事务四大特性
原子性,要么执行,要么不执行
隔离性,所有操作全部执行完以前其它会话不能看到过程
一致性,事务前后,数据总额一致
持久性,一旦事务提交,对数据的改变就是永久的
事务的隔离级别
读未提交 读已提交 可重复读 序列化
读已提交解决脏读问题
可重复读解决不可重复读问题
序列化解决幻读问题。
MySQL的默认隔离级别是可重复读Oracle的默认隔离级别是读已提交SQL Server的默认隔离级别是读已提交多个事务读可能会道理以下问题
脏读:事务B读取事务A还没有提交的数据
不可重复读:,一行被检索两次,并且该行中的值在不同的读取之间不同时
幻读:当在事务处理过程中执行两个相同的查询,并且第二个查询返回的行集合与第一个查询不同时
这两个区别在于,不可重复读重点在一行,幻读的重点 ,返回 的集合不一样
聚集索引和非聚集索引
- 聚集索引:数据按索引顺序存储,子节点存储真实的物理数据
- 非聚簇索引:存储指向真正数据行的指针
索引的优缺点,什么时候使用索引?
索引最大的好处是提高查询速度,
缺点是更新数据时效率低,
因为要同时更新索引 对数据进行频繁查询宜建立索引
如果要频繁更改数据不建议使用索引。
Sql语句的优化
- 子查询变成left join
- limit 分布优化,先利用ID定位,再分页
- or条件优化,多个or条件可以用union all对结果进行合并(union all结果可能重复)
- 不必要的排序
- where代替having,having 检索完所有记录,才进行过滤
- 避免嵌套查询 对多个字段进行等值查询时,联合索引
索引最左前缀问题
最左匹配原则是针对索引的
举例来说:两个字段(name,age)建立联合索引,如果where age=12这样的话,是没有利用到索引的,这里我们可以简单的理解为先是对name字段的值排序,然后对age的数据排序,如果直接查age的话,这时就没有利用到索引了,
查询条件where name=‘xxx’ and age=xx 这时的话,就利用到索引了,再来思考下where age=xx and name=’xxx‘ 这个sql会利用索引吗,
按照正常的原则来讲是不会利用到的,但是优化器会进行优化,把位置交换下。这个sql也能利用到索引了
如果对三个字段建立联合索引,如果第二个字段没有使用索引,第三个字段也使用不到索引了
数据库索引的实现原理
| 树 | 区别 |
|---|---|
| 红黑树 | 增加,删除,红黑树会进行频繁的调整,来保证红黑树的性质,浪费时间 |
| B树也就是B-树 | B树,查询性能不稳定,查询结果高度不致,每个结点保存指向真实数据的指针,相比B+树每一层每屋存储的元素更多,显得更高一点。 |
| B+树 | B+树相比较于另外两种树,显得更矮更宽,查询层次更浅 |
B+树的实现:
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素
为什么使用B+ Tree
索引查找过程中就要产生磁盘I/O消耗,主要看IO次数,和磁盘存取原理有关。 根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理, 将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入 局部性原理与磁盘预读
创建索引有什么技巧吗
-
经常检索排序大表中30% 或非排序表7%的行,建议建索引;
-
为了改善多表关联,索引列用于联结;
-
列中的值比较惟一;
-
列中有许多空值,不适合建立索引;
-
经常一起使用多个字段检索记录,组合索引比单索引更有效;
-
不要索引大型字段;
-
不要索引常用的小型表,尤其假如它们有频繁的插入和删除操作;
-
不能真正使用到索引的情形:在索引列上使用函数查询,使用模式匹配LIKE,使用IN子查询;
索引的类型,怎么判断是否走索引
索引类型:
- 普通索引:仅加速查询
- 唯一索引:加速查询+列值唯一(可以为null)
- 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 全文索引:对文本的内容进行分词,进行搜索
- 索引合并,使用多个单列索引组合搜索
- 覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖*
查看sql是否用了索引:
可以在查询的sql前面增加explain命令,以此可以查看到sql的运行状态
当extra出现Using filesort和Using temproary这两个时,表示无法使用索引,必须尽快做优化。
当type出现index和all时,表示走的是全表扫描没有走索引,效率低下,这时需要对sql进行调优。
当type出现ref或者index时,表示走的是索引,index是标准不重复的索引,ref表示虽然使用了索引,但是索引列中有重复的值,但是就算有重复值,也只是在重复值的范围内小范围扫描,不造成重大的性能影响。
索引失效的7种情况
-
1.有or必没有索引
select * from `order` where id=780 //没有or的情况下,走的是主键索引 select * from `order` where id=780 or user_id=12 //条件中有or,则索引无效注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
-
2.复合索引未引用左列字段
-
3.like以%开头
select * from `order` where user_name like 'w%' //以%结尾:索引可以使用 select * from `order` where user_name like '%w' //以%开头 :索引失效 -
4.需要类型转换
存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
select * from 'order' where user_name='123' // 查询字段加有引号:索引可用 select * from 'order' where user_name=123 //查询字段没有引号,会将数字隐式转换为字符串,索引失效 -
5.where中索引列有运算
select * from RULE_INFO where id=1 select * from RULE_INFO where id=id+1 //索引失效 -
6.where中索引列使用了函数
select * from RULE_INFO where id=1 select * from RULE_INFO where ABS(id)=1 -
7.如果mysql觉得全表扫描更快时(数据少的情况下)
什么时候没必要用索引
1.唯一性差
比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描。
2.频繁更新的字段不用(更新索引消耗性能)
比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。
3.where中不用的字段
只有在where语句出现,mysql才会去使用索引
4.索引使用<> 不等号 时,索引效果一般,不建议使用
数据库的主从复制
| 复制方式 | 操作 |
|---|---|
| 异步复制 | 默认异步复制,容易造成主库数据和从库不一致,一个数据库为Master,一个数据库为slave,通过Binlog日志,slave两个线程,一个线程去读master binlog日志,写到自己的中继日志一个线程解析日志,执行sql,master启动一个线程,给slave传递binlog日志 |
| 半同步复制 | 只有把master发送的binlog日志写到slave的中继日志,这时主库,才返回操作完成的反馈,性能有一定降低 |
| 并行操作 | slave 多个线程去请求binlog日志 |
数据库中join的left join 、inner join 、cross join
1.以A,B两张表为例
A left join B
选出A的所有记录,B表中没有的以null 代替
right join 同理2.inner join
A,B有交集的记录3.cross join (笛卡尔积)
A中的每一条记录和B中的每一条记录生成一条记录
例如A中有4条,B中有4条,cross join 就有16条记录
关系型数据库和非关系型数据库的区别
优点
1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率;
4、支持SQL,可用于复杂的查询。
5.支持事务
缺点
1、为了维护一致性所付出的巨大代价就是其读写性能比较差;
2、固定的表结构;
3、不支持高并发读写需求;
4、不支持海量数据的高效率读写
数据库的三大范式
1.第一范式:确保每一列保持原子性
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。作用:提高数据库性能
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。 作用:减小数据库的冗余
3.第三范式(确保每列都和主键直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。作用:减小数据冗余
MySQL有几种锁
行级锁
(1) 描述
行级锁是mysql中锁定粒度最细的一种锁。表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突,其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁
(2) 特点
开销大,加锁慢,会出现死锁。发生锁冲突的概率最低,并发度也最高。
其实行级锁和页级锁之间还有其他锁粒度的锁,就是间隙锁和临键锁。
InnoDB有三种行锁的算法:
1,Record Lock(记录锁):单个行记录上的锁。这个也是我们日常认为的行锁。
2,Gap Lock(间隙锁):间隙锁,锁定一个范围,但不包括记录本身(只不过它的锁粒度比记录锁的锁整行更大一些,他是锁住了某个范围内的多个行,包括根本不存在的数据)。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。该锁只会在隔离级别是RR或者以上的级别内存在。间隙锁的目的是为了让其他事务无法在间隙中新增数据。
3,Next-Key Lock(临键锁):它是记录锁和间隙锁的结合,锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。next-key锁是InnoDB默认的锁
上面这三种锁都是排它锁(X锁)
next-key lock的效果相当于一个记录锁加一个间隙锁。当next-key lock加在某索引上,则该记录和它前面的区间都被锁定。
假设有记录1, 3, 5, 7,现在记录5上加next-key lock,则会锁定区间(3, 5],任何试图插入到这个区间的记录都会阻塞。
注意,由于其效果相当于(3, 5)上的gap lock加5上的record lock,而且gap lock是****可重入的****,相互不阻塞的(上文讲过),当其它事务试图获取(3, 5)的gap lock时,不会被阻塞;但如果要获取5上的record lock,就会阻塞;如果要获取5上的next-key lock,同样会阻塞。
record lock、gap lock、next-key lock,都是加在索引上的。假设有记录1,3,5,7,则5上的记录锁会锁住5,5上的gap lock会锁住(3,5),5上的next-key lock会锁住(3,5]。
表级锁
(1) 描述
表级锁是mysql中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分mysql引擎支持。最常使用的MyISAM与InnoDB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)
(2) 特点
开销小,加锁快,不会出现死锁。发生锁冲突的概率最高,并发度也最低。
- LOCK TABLE my_table_name READ; 用读锁锁表,会阻塞其他事务修改表数据。
- LOCK TABLE my_table_name WRITE; 用写锁锁表,会阻塞其他事务读和写。
****MyISAM****在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此,用户一般不需要直接用LOCK TABLE命令给MyISAM表显式加锁。
但是在InnoDB中如果需要表锁就需要显式地声明了。
页级锁
(1) 描述
页级锁是 MySQL 中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。因此,采取了折中的页级锁,一次锁定相邻的一组记录。BDB 支持页级锁。
(2) 特点
开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
自增锁
自增锁是一种特殊的表级锁,主要用于事务中插入自增字段,也就是我们最常用的自增主键id。通过innodb_autoinc_lock_mode参数可以设置自增主键的生成策略。防止并发插入数据的时候自增id出现异常。
当一张表的某个字段是自增列时,innodb会在该索引的末位加一个排它锁。为了访问这个自增的数值,需要加一个表级锁,不过这个表级锁的持续时间只有当前sql,而不是整个事务,即当前sql执行完,该表级锁就释放了。其他session无法在这个表级锁持有时插入任何记录。
mysql有关权限的表都有哪几个
MySQL服务器通过权限表来控制用户对数据库的访问,权限表存放在mysql数据库里,由mysql_install_db脚本初始化。这些权限表分别user,db,table_priv,columns_priv和host。下面分别介绍一下这些表的结构和内容:
- user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
- db权限表:记录各个帐号在各个数据库上的操作权限。
- table_priv权限表:记录数据表级的操作权限。
- columns_priv权限表:记录数据列级的操作权限。
- host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和REVOKE语句的影响。
Mysql执行计划
当我们的系统上线后数据库的记录不断增加,之前写的一些SQL语句或者一些ORM操作效率变得非常低。我们不得不考虑SQL优化,SQL优化大概是这样一个流程:1.定位执行效率低的SQL语句(定位),2.分析为什么这段SQL执行的效率比较低(分析),3.最后根据第二步分析的结构采取优化措施(解决)。而EXPLAIN命令的作用就是帮助我们分析SQL的执行情况,属于第二步。说的规范一点就是:EXPLAIN命令是查看查询优化器如何决定执行查询的主要的方法。学会解释EXPLAIN将帮助我们了解SQL优化器是如何工作的。执行计划可以告诉我们SQL如何使用索引,连接查询的执行顺序,查询的数据行数。
下面是一个简单EXPLAIN的结果

ID列
是一位数字,表示执行SELECT语句的顺序
id值相同执行顺序从上到下
id值不同时id值大的先执行
SELECT_TYPE
TABLE
输入数据行所在的表名称
PARTITIONS
对于分区表,显示查询的分区ID,对于非分区表,显示为NULL
TYPE
EXTRA
POSSIBLE_KEYS
指出MySQL能使用哪些索引来优化查询,查询所涉及的列上的索引都会被列出,但不一定会被使用
KEY
查询优化器优化查询实际所使用的索引,如果没有可用的索引,则显示为NULL,如查询使用了覆盖索引,则该索引仅出现在Key列中
KEY_LEN
表示索引字段的最大可能长度,KEY_LEN的长度由字段定义计算而来,并非数据的实际长度
REF
表示哪些列或常量被用于查找索引列上的值
ROWS
表示MySQL通过哪些列或常量被用于查找索引列上的值,ROWS值的大小是个统计抽样结果,并不十分准确
Filtered
表示返回结果的行数占需读取行数的百分比,Filter列的值越大越好



MySQL覆盖索引与回表
mysql覆盖索引与回表
SQL语句执行的很慢的原因有哪些
大多数情况是正常的,只是偶尔出现很慢的情况
-
数据库在刷新脏页
当我们要往数据库插入一条数据、或者要更新一条数据的时候,我们知道数据库会在内存中把对应字段的数据更新了,但是更新之后,这些更新的字段并不会马上同步持久化到磁盘中去,而是把这些更新的记录写入到 redo log 日记中去,等到空闲的时候,在通过 redo log 里的日记把最新的数据同步到磁盘中去。
不过,redo log 里的容量是有限的,如果数据库一直很忙,更新又很频繁,这个时候 redo log 很快就会被写满了,这个时候就没办法等到空闲的时候再把数据同步到磁盘的,只能暂停其他操作,全身心来把数据同步到磁盘中去的,而这个时候,就会导致我们平时正常的SQL语句突然执行的很慢,所以说,数据库在在同步数据到磁盘的时候,就有可能导致我们的SQL语句执行的很慢了。
-
拿不到锁
这个就比较容易想到了,我们要执行的这条语句,刚好这条语句涉及到的表,别人在用,并且加锁了,我们拿不到锁,只能慢慢等待别人释放锁了。或者,表没有加锁,但要使用到的某个一行被加锁了,这个时候,我也没办法啊。如果要判断是否真的在等待锁,我们可以用 show processlist这个命令来查看当前的状态哦,这里我要提醒一下,有些命令最好记录一下,反正,我被问了好几个命令,都不知道怎么写,呵呵。
针对一直都这么慢的情况
-
查询的字段没有索引
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; select * from t where 100 <c and c < 100000; -
字段有索引,但却没有用索引
假如给C字段建立了索引,但sql语句是这样的也解决不了问题
select * from t where c - 1 = 1000;我想问大家一个问题,这样子在查询的时候会用索引查询吗?
答是不会,如果我们在字段的左边做了运算,那么很抱歉,在查询的时候,就不会用上索引了,所以呢,大家要注意这种字段上有索引,但由于自己的疏忽,导致系统没有使用索引的情况了。
正确的查询应该如下
select * from t where c = 1000 + 1;
总结
一个 SQL 执行的很慢,我们要分两种情况讨论:
1、大多数情况下很正常,偶尔很慢,则有如下原因
(1)、数据库在刷新脏页,例如 redo log 写满了需要同步到磁盘。
(2)、执行的时候,遇到锁,如表锁、行锁。
2、这条 SQL 语句一直执行的很慢,则有如下原因。
(1)、没有用上索引:例如该字段没有索引;由于对字段进行运算、函数操作导致无法用索引。
(2)、数据库选错了索引。
MySQL中使用LIMIT进行分页的方法
一、分页需求:
客户端通过传递start(页码),pageSize(每页显示的条数)两个参数去分页查询数据库表中的数据,那我们知道MySql数据库提供了分页的函数limit m,n,但是该函数的用法和我们的需求不一样,所以就需要我们根据实际情况去改写适合我们自己的分页语句,具体的分析如下:
比如:
查询第1条到第10条的数据的sql是:select * from table limit 0,10; ->对应我们的需求就是查询第一页的数据:select * from table limit (1-1)*10,10;
查询第11条到第20条的数据的sql是:select * from table limit 10,10; ->对应我们的需求就是查询第二页的数据:select * from table limit (2-1)*10,10;
查询第21条到第30条的数据的sql是:select * from table limit 20,10; ->对应我们的需求就是查询第三页的数据:select * from table limit (3-1)*10,10;
二、总结:
通过上面的分析,可以得出符合我们需求的分页sql格式是:select * from table limit (start-1)*pageSize,pageSize; 其中start是页码,pageSize是每页显示的条数。
Spring框架
什么是Bean:可重用组件,在java中javabean:用java语言编写的可重用组件。
Spring容器就是通过配置文件来获取我们的bean对象的。(通过读取配置文件的内容,通过反射来创建对象)
Spring IOC就是把创建对象的主动权交给Spring 容器(即BeanFactory或者ApplicationContext),把创建对象和管理对象、注入对象的权力交给了容器。从而是程序解耦,降低程序间的依赖关系。
ApplicationContext (容器接口)的三个常用实现类:
ClassPathXmlApplicationContext: 它可以加载类路径下的配置文件,要求配置文件必须在类路径下。不存在的话,加载不了
FileSystemXmlApplicationContext:它可以加载磁盘任意路径的配置文件(文件必须有访问权限)
AnnotationConfigApplicationContext:它是用于读取注解来创建容器的。
核心容器的两个接口引发出的问题:
ApplicationContext: 它在构建核心容器时,创建对象采取的策略是立即加载的方式。也就是说,只要一读取完配置文件就立即创建对象。(单例模式适用)
BeanFactory:创建对象采取的策略是延迟加载的策略。就是当根据id获取对象时,才创建对象。(多例对象适用)
其实我们也可以采用配置的不同(singleton、prototype)来采取不同的创建对象方式
创建Bean的三种方式
第一种:使用默认构造函数方式创建,在spring的配置文件中使用bean标签,配以id和class属性后,且没有其他属性和标签时,采用的就是默认构造函数创建bean对象,若类中没有构造函数,则无法创建bean对象。
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl">bean>
....
....
第二种:使用普通工厂中的方法来创建对象。下面就是采用InstanceFactory中的getAccountService方法来创建accountService对象
<bean id="instanceFactory" class="com.itheima.factory.InstanceFactory">bean>
<bean id="accountService" factory-bean="instanceFactory" factory-method="getAccountService">bean>
....
....
第三种:使用工厂中的静态方法创建bean对象
<bean id="accountService" class="com.itheima.factory.StaticFactory" factory-method="getAccountService">bean>
bean对象的作用范围
bean标签的scope属性:
作用:用于指定bean的作用范围
取值:
singleton : 单例的
prototype :多例的
request : 作用于web应用的请求范围
session :作用于web应用的会话范围
global-session :作用于集群环境的会话范围(全局会话范围),当不是集群环境时,作用相当于session
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl" scope="singleton">bean>
bean对象的生命周期
init-method:在对象创建时执行的方法
destory-method :在对象销毁时执行的方法
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl"
scope="singleton" init-method="init" destory-method="destory">bean>
单例对象
出生:当容器创建时,对象出生
活着:只要容器在,对象就在
死亡:容器销毁,对象也销毁了
总结:生命周期和容器相同
多例对象
出生:当使用对象时,对象出生
活着:使用过程中一直活着
死亡:当对象长时间不用时,且没有别的对象引用时,由Java垃圾回收器回收
spring的依赖注入
依赖注入:Dependency Injection
IOC的作用:降低程序间的耦合(依赖关系)
依赖关系的管理:以后交给Spring来维护、在当前类需要其他类的对象时,由Spring为我们提供,我们只需要在配置文件中说明即可
依赖注入能注入的数据:
基本类型和String
其他bean类型(在配置文件中或者注解中配置过bean)
复杂类型/集合类型
依赖注入注入的方式:使用构造函数注入,使用set方法注入,使用注解注入。
1.使用构造函数提供
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl" >
<constructor-arg name="name" value="jjp">constructor-arg>
<constructor-arg name="age" value="18">constructor-arg>
<constructor-arg name="birthday" ref="now">constructor-arg>
bean>
<bean id="now" class="java.util.Date">bean>
2.使用set方法提供
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl" >
<property name="name" value="jjp">property>
<property name="age" value="age">property>
<property name="birthday" ref="now">property>
bean>
<bean id="now" class="java.util.Date">bean>
复杂类型的注入/集合类型的注入
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl" >
<property name="myStrs">
<array>
<value>AAAvalue>
<value>BBBvalue>
<value>CCCvalue>
array>
property>
<property name="myList">
<list>
<value>AAAvalue>
<value>BBBvalue>
<value>CCCvalue>
list>
property>
<property name="mySet">
<set>
<value>AAAvalue>
<value>BBBvalue>
<value>CCCvalue>
set>
property>
<property name="myMap">
<map>
<entry key="testA" value="aaa">entry>
<entry key="testB" value="bbb">entry>
<entry key="testC" value="ccc">entry>
map>
property>
<property name="myProps">
<props>
<prop key="testA">aaaprop>
<prop key="testB">bbbprop>
props>
property>
bean>
<bean id="now" class="java.util.Date">bean>
spring ioc中的常用注解
用于创建对象的:
它们的作用和Spring中bean标签的作用是一致的
@Component :
把当前对象存入spring容器中
属性值:value:用于指定bean的id、当我们不写时,他的默认值是当前类名,且首字母小写
@Controller:用于表现层的、与Component注解功能一致
@Service:用于业务层、与Component注解功能一致
@Repository:用于持久层、与Component注解功能一致
用于注入对象的
它们的作用和在bean标签内部使用property标签注入对象和基本类型数据或者集合时的功能是一样的。
@Autowired:
自动按照类型注入、只要容器中有唯一的一个bean对象类型和要注入的变量类型匹配,就可以注入成功
出现位置:可以是变量上,也可以是方法上。
@Qulifier:
在按照类型中注入的基础之上再按照名称注入。它在给类成员注入时不能单独使用(要和Autowired联合使用)。但在给方法参数注入时可以单独使用
属性:value:用于指定注入bean的id
@Resource:
直接按照bean的id注入、可以直接使用
属性: name:用于指定bean的id。
以上三个注解注入其他bean类型的数据,而基本类型和String类型无法使用上述注解实现、另外集合类型的注入只能通过xml实现
@Value:
用于注入基本类型和String类型的数据
属性:
value:用于指定数据的值、它可以使用Spring中的El表达式SpEL 写法:${表达式}
用于改变作用范围的
它们的作用和在bean标签中使用scope属性实现的功能是一样的
@Scope:
作用:用于指定bean的作用范围
属性:value:常用取值 : singleton prototype
和生命周期相关的
它们的作用和bean标签中使用init-method和destory-method的作用是一样的。
@PostConstructor:用于指定初始化的方法
@PreDestory:用于指定销毁之前执行的方法
Spring IOC 新注解
@Configuration: 指定当前类为一个配置类
@ComponentScan: 用于通过注解指定Spring在创建容器时要扫描的包
属性:value:指定要扫描的包,例如:com.itheima
basepackages:和value一样的功能
使用ComponentScan等同于
<context:component-scan base-package="com.itheima">context:component-scan>
@Bean: 把当前方法的返回值作为bean对象存入spring的ioc容器中
属性:name:用于指定bean的id。当不写时,默认值是当前方法的名称
@Import :用于导入其他配置类
属性:value:指定其他配置类的字节码、当我们使用Import注解之后,有Import注解的类就是主配置类。
@PropertySource: 用于指定properties文件的位置
属性:value:指定文件名称。
@RunWith
@ContextConfiguration
spring AOP
动态代理:
特点:字节码随用随创建,随用随加载
作用:不修改源码的基础上对方法进行加强
分类:
基于接口的动态代理
基于子类的动态代理
基于接口的动态代理
涉及的类:Proxy
提供者:JDK官方
如何创建代理对象:
使用Proxy类中的newProxyInstance方法
创建代理对象的要求:
被代理类至少实现一个接口、如果没有则不能使用
newProxyInstance方法的参数:
ClassLoader: 类加载器:它是用于加载代理对象字节码的类加载器
Class[]:字节码数组:用于让代理对象和被代理对象有相同方法
InvocationHandler: 用于提供增强的方法、如何代理。
基于子类的动态代理:
《待续》
什么是AOP
面向切面编程:把程序中的重复代码抽取出来、在需要执行的时候、使用动态代理技术,在不修改源码的基础上,对我们已有方法进行增强。
AOP的作用和优势:
在程序运行期间、不修改源代码对已有方法进行增强。
AOP相关术语
Jointpoint:连接点:所谓连接点是指哪些被拦截到得的点。在spring中、这些点值得是方法、是因为spring只支持方法类型的连接点
Pointcut:切入点:所谓切入点是指我们要对哪些Jointpoint进行拦截的定义。
Advice:通知:拦截后要做的事情,分为:前置通知、后置通知、异常通知、最终通知、环绕通知。
AOP的Spring配置(XML)
<bean id="accountService" class="com.itheima.service.impl.AccountServiceImpl">bean>
<bean id="logger" class="com.itheima.utils.Logger">bean>
<aop:config>
<aop:pointcut id="pt1" expression=”execution(* com.itheima.service.impl.*.*(..))“>aop:pointcut>
<aop:aspect id="logAdvice" ref="logger">
<aop:before method="printLog" pointcut-ref="pt1">aop:before>
<aop:after-returning method="printLog" pointcut-ref="pt1">aop:after-returning>
<aop:after-throwing method="printLog" pointcut-ref="pt1">aop:after-throwing>
<aop:after method="printLog" pointcut-ref="pt1">aop:after>
<aop:around method="printLog" pointcut-ref="pt1">aop:around>
aop:aspect>
aop:config>
AOP的Spring注解
@Aspect:表示当前通知是一个切面类
@Before:前置通知
@AfterReturning:后置通知
@AfterThrowing:异常通知
@After:最终通知
@PointCut:切入点表达式
@Around:环绕通知
Spring 中JdbcTemplate的使用
JdbcTemplate的作用:和数据库进行交互,实现对表的curd操作
Spring声明式事务控制
Spring中事务控制的API介绍
PlatformTransactionManager: 此接口是spring的事务管理器,它里面提供了我们常用的事务操作方法。
实现类有:
DataSourceTranscationManager
HibernateTransactionManager
TransactionDefinition:它是事务的定义信息对象
BeanFactory和ApplicationContext有什么区别
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
依赖关系
BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。
ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
- 继承MessageSource,因此支持国际化。
- 统一的资源文件访问方式。
- 提供在监听器中注册bean的事件。
- 同时加载多个配置文件。
- 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
加载方式
BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
Spring 如何设计容器的,BeanFactory和ApplicationContext的关系详解
BeanFactory 简单粗暴,可以理解为就是个 HashMap,Key 是 BeanName,Value 是 Bean 实例。通常只提供注册(put),获取(get)这两个功能。我们可以称之为 “低级容器”。
ApplicationContext 可以称之为 “高级容器”。因为他比 BeanFactory 多了更多的功能。他继承了多个接口。因此具备了更多的功能。例如资源的获取,支持多种消息(例如 JSP tag 的支持),对 BeanFactory 多了工具级别的支持等待。所以你看他的名字,已经不是 BeanFactory 之类的工厂了,而是 “应用上下文”, 代表着整个大容器的所有功能。该接口定义了一个 refresh 方法,此方法是所有阅读 Spring 源码的人的最熟悉的方法,用于刷新整个容器,即重新加载/刷新所有的 bean。
为了更直观的展示 “低级容器” 和 “高级容器” 的关系,这里通过常用的 ClassPathXmlApplicationContext 类来展示整个容器的层级 UML 关系。

有点复杂? 先不要慌,我来解释一下。
最上面的是 BeanFactory,下面的 3 个绿色的,都是功能扩展接口,这里就不展开讲。
看下面的隶属 ApplicationContext 粉红色的 “高级容器”,依赖着 “低级容器”,这里说的是依赖,不是继承哦。他依赖着 “低级容器” 的 getBean 功能。而高级容器有更多的功能:支持不同的信息源头,可以访问文件资源,支持应用事件(Observer 模式)。
通常用户看到的就是 “高级容器”。 但 BeanFactory 也非常够用啦!
左边灰色区域的是 “低级容器”, 只负载加载 Bean,获取 Bean。容器其他的高级功能是没有的。例如上图画的 refresh 刷新 Bean 工厂所有配置,生命周期事件回调等。
小结
说了这么多,不知道你有没有理解Spring IoC? 这里小结一下:IoC 在 Spring 里,只需要低级容器就可以实现,2 个步骤:
加载配置文件,解析成 BeanDefinition 放在 Map 里。
调用 getBean 的时候,从 BeanDefinition 所属的 Map 里,拿出 Class 对象进行实例化,同时,如果有依赖关系,将递归调用 getBean 方法 —— 完成依赖注入。
上面就是 Spring 低级容器(BeanFactory)的 IoC。
至于高级容器 ApplicationContext,他包含了低级容器的功能,当他执行 refresh 模板方法的时候,将刷新整个容器的 Bean。同时其作为高级容器,包含了太多的功能。一句话,他不仅仅是 IoC。他支持不同信息源头,支持 BeanFactory 工具类,支持层级容器,支持访问文件资源,支持事件发布通知,支持接口回调等等。
常见的ApplicationContext实现类
FileSystemXmlApplicationContext :此容器从一个XML文件中加载beans的定义,XML Bean 配置文件的全路径名必须提供给它的构造函数。
ClassPathXmlApplicationContext:此容器也从一个XML文件中加载beans的定义,这里,你需要正确设置classpath因为这个容器将在classpath里找bean配置。
WebXmlApplicationContext:此容器加载一个XML文件,此文件定义了一个WEB应用的所有bean。
什么是Spring IOC
控制反转IoC是一个很大的概念,可以用不同的方式来实现。其主要实现方式有两种:依赖注入和依赖查找
依赖注入:相对于IoC而言,依赖注入(DI)更加准确地描述了IoC的设计理念。所谓依赖注入(Dependency Injection),即组件之间的依赖关系由容器在应用系统运行期来决定,也就是由容器动态地将某种依赖关系的目标对象实例注入到应用系统中的各个关联的组件之中。组件不做定位查询,只提供普通的Java方法让容器去决定依赖关系。
依赖注入的基本原则
依赖注入的基本原则是:应用组件不应该负责查找资源或者其他依赖的协作对象。配置对象的工作应该由IoC容器负责,“查找资源”的逻辑应该从应用组件的代码中抽取出来,交给IoC容器负责。容器全权负责组件的装配,它会把符合依赖关系的对象通过属性(JavaBean中的setter)或者是构造器传递给需要的对象。
依赖注入有什么优势
依赖注入之所以更流行是因为它是一种更可取的方式:让容器全权负责依赖查询,受管组件只需要暴露JavaBean的setter方法或者带参数的构造器或者接口,使容器可以在初始化时组装对象的依赖关系。其与依赖查找方式相比,主要优势为:
查找定位操作与应用代码完全无关。
不依赖于容器的API,可以很容易地在任何容器以外使用应用对象。
不需要特殊的接口,绝大多数对象可以做到完全不必依赖容器。
有哪些不同类型的依赖注入的实现方式
依赖注入是时下最流行的IoC实现方式,依赖注入分为接口注入(Interface Injection),Setter方法注入(Setter Injection)和构造器注入(Constructor Injection)三种方式。其中接口注入由于在灵活性和易用性比较差,现在从Spring4开始已被废弃。
构造器依赖注入:构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖。
Setter方法注入:Setter方法注入是容器通过调用无参构造器或无参static工厂 方法实例化bean之后,调用该bean的setter方法,即实现了基于setter的依赖注入。
构造器依赖注入和 Setter方法注入的区别
| 构造函数注入 | setter方法注入 |
|---|---|
| 没有部分注入 | 有部分注入 |
| 不会覆盖setter属性 | 会覆盖setter属性 |
| 任意修改都会创建一个新实例 | 任意修改不会创建一个新实例 |
| 适用于设置很多属性 | 适用于设置少量属性 |
两种依赖方式都可以使用,构造器注入和Setter方法注入。最好的解决方案是用构造器参数实现强制依赖,setter方法实现可选依赖。
Spring Security
什么是Spring Security
Spring Security是基于Spring AOP和Servlet过滤器的安全框架。它提供全面的安全性解决方案,同时再web请求级和方法调用级处理身份确认和授权。
Security的核心功能
- 1.认证(你是谁,用户/设备/系统)
- 2.验证(你能干什么、权限管理)
- 3.攻击防护(防止伪造身份)
Security和shiro的区别
优势
- 1.Spring Security是基于Spring开发、配合Spring会更加方便
- 2.功能比shiro更加丰富,例如安全防护方面
- 3.社区资源相对丰富
- 4.如果使用的是springboot,springcloud的话,三者可以无缝集成
劣势
- shiro的配置和使用相对简单,security上手较为复杂
- shiro依赖性低,不需要任何框架和容器,可以独立运行,而security依赖spring容器
基本的整合过程
添加依赖包
spring-boot-starter-web
spring-boot-starter-security
就可以使用spring security了
取消SpringBoot Security的自动配置
@SpringBootApplication(exclude=SecurityAutoConfiguration)
自定义用户名和密码
在application.properties里面
spring.security.user.name=admin
spring.security.user.password=123456
基于内存的认证信息
我们如果要在内存中初始化我们的认证信息的话,那么需要重写 WebSecurityConfigurerAdapter类中的configure方法
configure(AuthenticationManagerBuilder auth)
然后通过auth对象的inMemoryAuthentication()方法指定认证信息:
auth.inMemoryAuthentication().passwordEncoder(new BCryptPasswordEncoder()).WithUser("admin").password(new BCryptPasswordEncoder().encode("123456")).roles();
也可以通过@Bean方式来指定密码加密方式
@Bean //注入PasswordEncoder
public PasswordEncoder passwordEncoder()
{
return new BCryptPasswordEncoder();
}
基于内存的角色授权
通过AuthenticationManagerBuilder的roles方法,就可以指定角色
auth.inMemoryAuthentication().withUser("admin").password(passwordEncoder().encode("123456")).roles("beijingAdmin","shanghaiAdmin")
如何开启方法级别的安全控制
在已经添加了@Configuration注解的类上再添加@EnableGlobalMethodSecurity注解即可
举个例子
@EnableGlobalMethodSecurity(prePostEnabled=true) //会拦截注解了@PreAuthrize注解的配置
基于数据库的身份认证和角色授权
Spring 循环依赖
-
什么是循环依赖
A类对象的创建需要B对象
B类对象的创建需要A对象
那么就会产生循环依赖
-
怎么解决循环依赖
构造器的循环依赖spring解决不了
setter方法的循环依赖,spring采用三级缓存来解决。
-
spring为什么用三级缓存来解决循环依赖
spring解决
循环依赖的做法是未等bean创建完就先将实例曝光出去,方便其他bean的引用。同时还提到了三级缓存,最先曝光到第三级缓存singletonFactories中。spring怎么解决循环依赖的问题
总结一下循环依赖,spring只能解决setter注入单例模式下的循环依赖问题。要想解决循环依赖必须要满足2个条件:
- 需要用于
提前曝光的缓存 - 属性的
注入时机必须发生在提前曝光动作之后,不管是填充还是初始化都行,总之不能在实例化,因为提前曝光动作在实例化之后
理解了这2点就可以轻松驾驭循环依赖了。比如构造器注入是不满足第二个条件,曝光时间不对。而原型模式则是缺少了第一个条件,没有提前曝光的缓存供使用
- 需要用于
Spring框架中事件的种类
Spring 提供了以下5种标准的事件:
(1)上下文更新事件(ContextRefreshedEvent):在调用ConfigurableApplicationContext 接口中的refresh()方法时被触发。
(2)上下文开始事件(ContextStartedEvent):当容器调用ConfigurableApplicationContext的Start()方法开始/重新开始容器时触发该事件。
(3)上下文停止事件(ContextStoppedEvent):当容器调用ConfigurableApplicationContext的Stop()方法停止容器时触发该事件。
(4)上下文关闭事件(ContextClosedEvent):当ApplicationContext被关闭时触发该事件。容器被关闭时,其管理的所有单例Bean都被销毁。
(5)请求处理事件(RequestHandledEvent):在Web应用中,当一个http请求(request)结束触发该事件。
如果一个bean实现了ApplicationListener接口,当一个ApplicationEvent 被发布以后,bean会自动被通知。
Spring事务方式和种类
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。真正的数据库层的事务提交和回滚是通过binlog或者redo log实现的。
(1)Spring事务的种类:
spring支持编程式事务管理和声明式事务管理两种方式:
①编程式事务管理使用TransactionTemplate。
②声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
声明式事务最大的优点就是不需要在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明或通过@Transactional注解的方式,便可以将事务规则应用到业务逻辑中。
声明式事务管理要优于编程式事务管理,这正是spring倡导的非侵入式的开发方式,使业务代码不受污染,只要加上注解就可以获得完全的事务支持。唯一不足地方是,最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。
spring事务的7种传播行为
-
PROPAGATION_REQUIRED (Spring 默认传播级别)
如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
-
PROPAGATION_SUPPORTS
如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。
-
PROPAGATION_MANDATORY
如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
-
PROPAGATION_REQUIRES_NEW
使用PROPAGATION_REQUIRES_NEW,需要使用 JtaTransactionManager作为事务管理器。 它会开启一个新的事务。如果一个事务已经存在,则先将这个存在的事务挂起。
-
PROPAGATION_NOT_SUPPORTED
PROPAGATION_NOT_SUPPORTED 总是非事务地执行,并挂起任何存在的事务。使用PROPAGATION_NOT_SUPPORTED,也需要使用JtaTransactionManager作为事务管理器。
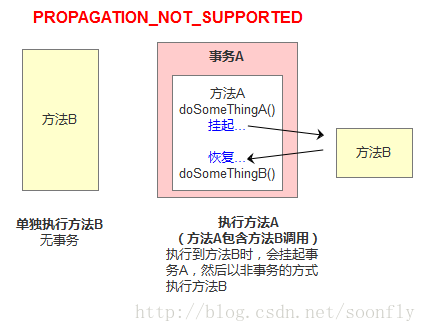
-
PROPAGATION_NEVER
总是非事务地执行,如果存在一个活动事务,则抛出异常。
-
PROPAGATION_NESTED
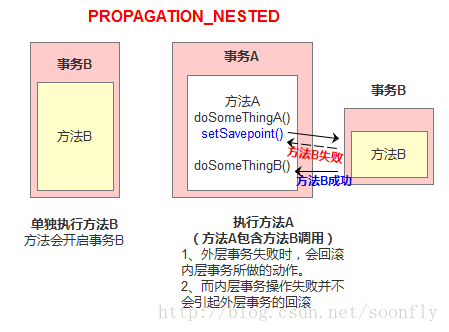
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:
它们非常类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。 使用 PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。
spring事务隔离级别
spring默认的事务隔离级别就是数据库的事务隔离级别。
1.首先说明一下事务并发引起的三种情况:
1) Dirty Reads 脏读
一个事务正在对数据进行更新操作,但是更新还未提交,另一个事务这时也来操作这组数据,并且读取了前一个事务还未提交的数据,而前一个事务如果操作失败进行了回滚,后一个事务读取的就是错误数据,这样就造成了脏读。
2) Non-Repeatable Reads 不可重复读
一个事务多次读取同一数据,在该事务还未结束时,另一个事务也对该数据进行了操作,而且在第一个事务两次次读取之间,第二个事务对数据进行了更新,那么第一个事务前后两次读取到的数据是不同的,这样就造成了不可重复读。
3) Phantom Reads 幻像读
第一个数据正在查询符合某一条件的数据,这时,另一个事务又插入了一条符合条件的数据,第一个事务在第二次查询符合同一条件的数据时,发现多了一条前一次查询时没有的数据,仿佛幻觉一样,这就是幻像读。
非重复度和幻像读的区别:
非重复读是指同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生非重复读。
幻像读是指同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻像读。
表面上看,区别就在于非重复读能看见其他事务提交的修改和删除,而幻像能看见其他事务提交的插入。
Spring创建bean的流程
首先说一下Servlet的生命周期:实例化,初始化init,接收请求service,销毁destory;
Spring上下文中的Bean生命周期也类似,如下:
(1):实例化Bean:
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有Bean。
(2):设置对象属性(依赖注入)
实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息以及通过BeanWrapper提供的设置属性的接口完成依赖注入。
(3)处理Aware接口:
接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean:
①如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的就是Spring配置文件中Bean的id值;
②如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory()方法,传递的是Spring工厂自身。
③如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文;
(4)BeanPostProcessor:
如果想对Bean进行一些自定义的处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。
(5)InitializingBean 与 init-method:
如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
(6)如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了。
(7)DisposableBean:
当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用其实现的destroy()方法;
(8)destroy-method:
最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
Spring如何处理线程并发问题
在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域,因为Spring对一些Bean中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。
ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。同步机制采用了“时间换空间”的方式,仅提供一份变量,不同的线程在访问前需要获取锁,没获得锁的线程则需要排队。而ThreadLocal采用了“空间换时间”的方式。
ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
Spring框架中用到了哪些设计模式
(1)工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例
(2)单例模式:Bean默认为单例模式
(3)代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术
(4)模板方法:用来解决代码重复问题,比如。RestTemplate,JmsTemplate,JpaTemplat
(5)观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制定更新,如Spring中Listener的实现:ApplicationListener。
SpringBoot框架
自动装配原理
Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。
SpringBootApplication组合注解
SpringBootConfiguration:
读取springboot的配置文件application.properties,对于没有设定的内容默认配置。
EnableAutoConfiguration:
根据依赖的jar包,将SpringBoot工程需要的其他内容进行自动配置。
ComponentScan:
启动类所在的包路径的同级包和下级包中所有Spring需要加载,启动的注解一旦存在,将会自动在Spring容器启动时,加载到内存中,等待注入和使用。
SpringMVC
SpringMVC八大注解
@Controller:
用于标记在一个类上,使用它标记的类就是一个SpringMVC Controller 对象。分发处理器将会扫描使用了该注解的类的方法,并检测该方法是否使用了@RequestMapping 注解。@Controller 只是定义了一个控制器类,而使用@RequestMapping 注解的方法才是真正处理请求的处理器。
@RequestMapping:
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
RequestMapping注解有六个属性,下面我们把她分成三类进行说明(下面有相应示例)。
1、 value, method;
value: 指定请求的实际地址,指定的地址可以是URI Template 模式(后面将会说明);
method: 指定请求的method类型, GET、POST、PUT、DELETE等;
2、consumes,produces
consumes: 指定处理请求的提交内容类型(Content-Type),例如application/json, text/html;
produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回;
3、params,headers
params: 指定request中必须包含某些参数值是,才让该方法处理。
headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求。
@Resource 和 @AutoWired
@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入。
区别:
@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用。
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不制定name也不制定type属性,这时将通过反射机制使用byName自动注入策略。
@PathVariable:
用于将请求URL中的模板变量映射到功能处理方法的参数上,即取出uri模板中的变量作为参数。
@requestParam:
@requestParam主要用于在SpringMVC后台控制层获取参数,类似一种是request.getParameter(“name”),它有三个常用参数:defaultValue = “0”, required = false, value = “isApp”;defaultValue 表示设置默认值,required 铜过boolean设置是否是必须要传入的参数,value 值表示接受的传入的参数类型。
@ResponseBody:
作用: 该注解用于将Controller的方法返回的对象,通过适当的HttpMessageConverter转换为指定格式后,写入到Response对象的body数据区。
使用时机:返回的数据不是html标签的页面,而是其他某种格式的数据时(如json、xml等)使用;
MyBatis框架
MyBatis简介
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis,是一个基于Java的持久层框架。
- 持久层: 可以将业务数据存储到磁盘,具备长期存储能力,只要磁盘不损坏,在断电或者其他情况下,重新开启系统仍然可以读取到这些数据。
- 优点: 可以使用巨大的磁盘空间存储相当量的数据,并且很廉价****灵活,几乎可以代替 JDBC,同时提供了接口编程。
- 缺点:慢(相对于内存而言)
为什么使用MyBatis
在我们传统的 JDBC 中,我们除了需要自己提供 SQL 外,还必须操作 Connection、Statment、ResultSet,不仅如此,为了访问不同的表,不同字段的数据,我们需要些很多雷同模板化的代码,闲的繁琐又枯燥。
而我们在使用了 MyBatis 之后,只需要提供 SQL 语句就好了,其余的诸如:建立连接、操作 Statment、ResultSet,处理 JDBC 相关异常等等都可以交给 MyBatis 去处理,我们的关注点于是可以就此集中在 SQL 语句上,关注在增删改查这些操作层面上。
并且 MyBatis 支持使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
Mybatis中的${ }和#{ }有什么区别
#{}是预编译处理,${}是字符串替换。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理 时,就是把 {}时,就是把 时,就是把{}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
更简单一些:
- #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by “111”, 如果传入的值是id,则解析成的sql为order by “id”.
- $将传入的数据直接显示生成在sql中。如:order by u s e r i d user_id userid,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
-
使用#{}格式的语法在mybatis中使用Preparement语句来安全的设置值,执行sql类似下面的:
PreparedStatement ps = conn.prepareStatement(sql); ps.setInt(1,id); -
不过有时你只是想直接在 SQL 语句中插入一个不改变的字符串。比如,像 ORDER BY,你可以这样来使用:
ORDER BY ${columnName}
此时MyBatis 不会修改或转义字符串。
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery(sql);
这种方式的缺点是: 以这种方式接受从用户输出的内容并提供给语句中不变的字符串是不安全的,会导致潜在的 SQL 注入攻击,因此要么不允许用户输入这些字段,要么自行转义并检验。
参考文章
PrepareStatement和Statement的区别
- Statement不对sql语句作处理,直接交给数据库;而PreparedStatement支持预编译,会将编译好的sql语句放在数据库端,相当于缓存。对于多次重复执行的sql语句,使用PreparedStatement可以使得代码的执行效率更高。(语句在被DB的编译器编译后的执行代码被缓存下来,那么下次调用时只要是相同的预编译语句就不需要编译,只要将参数直接传入编译过的语句执行代码中(相当于一个涵数)就会得到执行.这并不是说只有一个Connection中多次执行的预编译语句被缓存,而是对于整个DB中,只要预编译的语句语法和缓存中匹配.那么在任何时候就可以不需要再次编译而可以直接执行.而statement的语句中,即使是相同一操作,而由于每次操作的数据不同所以使整个语句相匹配的机会极小,几乎不太可能匹配.)
- Statement的sql语句使用字符串拼接的方式,容易导致出错,且存在sql注入的风险;PreparedStatement使用“?”占位符提升代码的可读性和可维护性,并且这种绑定参数的方式,可以有效的防止sql注入。(prepareStatement对象防止sql注入的方式是把用户非法输入的单引号用\反斜杠做了转义,从而达到了防止sql注入的目的)
参考文章
MyBatis是什么?
MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
ORM是什么
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
传统JDBC开发存在的问题
- 频繁创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池解决这个问题。但是使用jdbc需要自己实现连接池。
- sql语句定义、参数设置、结果集处理存在硬编码。实际项目中sql语句变化的可能性较大,一旦发生变化,需要修改java代码,系统需要重新编译,重新发布。不好维护。
- 使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。
- 结果集处理存在重复代码,处理麻烦。如果可以映射成Java对象会比较方便。
JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
1、数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。
解决:在mybatis-config.xml中配置数据链接池,使用连接池管理数据库连接。
2、Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
3、向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。
4、对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
Mybatis优缺点
优点
与传统的数据库访问技术相比,ORM有以下优点:
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护
- 能够与Spring很好的集成
缺点
-
SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求
-
SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
Hibernate 和 MyBatis 的区别
相同点
都是对jdbc的封装,都是持久层的框架,都用于dao层的开发。
不同点
映射关系
- MyBatis 是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单
- Hibernate 是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂
SQL优化和移植性
- Hibernate 对SQL语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
- MyBatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优化容易。
开发难易程度和学习成本
- Hibernate 是重量级框架,学习使用门槛高,适合于需求相对稳定,中小型的项目,比如:办公自动化系统
- MyBatis 是轻量级框架,学习使用门槛低,适合于需求变化频繁,大型的项目,比如:互联网电子商务系统
总结
MyBatis 是一个小巧、方便、高效、简单、直接、半自动化的持久层框架,
Hibernate 是一个强大、方便、高效、复杂、间接、全自动化的持久层框架。
MyBatis的解析和运行原理
1、 创建SqlSessionFactory
2、 通过SqlSessionFactory创建SqlSession
3、 通过sqlsession执行数据库操作
4、 调用session.commit()提交事务
5、 调用session.close()关闭会话
MyBatis的工作原理
1)读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
2)加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
3)构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
4)创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
5)Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
6)MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
7)输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
8)输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
为什么需要预编译
- 定义:
SQL 预编译指的是数据库驱动在发送 SQL 语句和参数给 DBMS 之前对 SQL 语句进行编译,这样 DBMS 执行 SQL 时,就不需要重新编译。 - 为什么需要预编译
JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。预编译阶段可以优化 SQL 的执行。预编译之后的 SQL 多数情况下可以直接执行,DBMS 不需要再次编译,越复杂的SQL,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。同时预编译语句对象可以重复利用。把一个 SQL 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个SQL,可以直接使用这个缓存的 PreparedState 对象。Mybatis默认情况下,将对所有的 SQL 进行预编译。
Mybatis都有哪些Executor执行器?
Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
Mybatis延迟加载?
延迟加载也叫作懒加载,比方说有数据库中存储着两张表(studentclass和student),并且这两张表形成了一对多的关系,如果不采用延迟加载(立即加载),查询时会将这两张表同时查询出来;如果想要 暂时只查询一的一方,而多的一方先不查询,而是在需要时再查询,那么这种就是延迟加载。
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
#{}和${}的区别
- #{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
- Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
- Mybatis在处理时,是原值传入,就是把{}时,是原值传入,就是把时,是原值传入,就是把{}替换成变量的值,相当于JDBC中的Statement编译
- 变量替换后,#{} 对应的变量自动加上单引号 ‘’;变量替换后,${} 对应的变量不会加上单引号 ‘’
- #{} 可以有效的防止SQL注入,提高系统安全性;${} 不能防止SQL 注入
- #{} 的变量替换是在DBMS 中;${} 的变量替换是在 DBMS 外
模糊查询like语句该怎么写
(1)’%${question}%’ 可能引起SQL注入,不推荐
(2)“%”#{question}“%” 注意:因为#{…}解析成sql语句时候,会在变量外侧自动加单引号’ ',所以这里 % 需要使用双引号" ",不能使用单引号 ’ ',不然会查不到任何结果。
(3)CONCAT(’%’,#{question},’%’) 使用CONCAT()函数,推荐
(4)使用bind标签
<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User">
<bind name="pattern" value="'%' + username + '%'" />
select id,sex,age,username,password from person where username LIKE #{pattern}
select>
在mapper中如何传递多个参数
方法1:顺序传参法
public User selectUser(String name, int deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{0} and dept_id = #{1}
select>
#{}里面的数字代表传入参数的顺序。这种方法不建议使用,sql层表达不直观,且一旦顺序调整容易出错。
方法2:@Param注解传参法
public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
select>
#{}里面的名称对应的是注解@Param括号里面修饰的名称。这种方法在参数不多的情况还是比较直观的,推荐使用。
方法3:Map传参法
public User selectUser(Map<String, Object> params);
<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
select>
#{}里面的名称对应的是Map里面的key名称。这种方法适合传递多个参数,且参数易变能灵活传递的情况。
方法4:Java Bean传参法
public User selectUser(User user);
<select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
select>
#{}里面的名称对应的是User类里面的成员属性。这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。
排序算法
快速排序
import javax.naming.PartialResultException;
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
int[] a=new int[]{4,4,6,5,3,2,8,1};
quickSort(a,0, a.length-1);
System.out.println(Arrays.toString(a));
}
private static void quickSort(int[] arr,int startIndex,int endIndex)
{
if(startIndex>=endIndex)
return;
int baseIndex=Partition(arr,startIndex,endIndex);
quickSort(arr,startIndex,baseIndex-1);
quickSort(arr,baseIndex+1,endIndex);
}
private static int Partition(int[] arr,int startIndex,int endIndex)
{
int base=arr[startIndex];
int left=startIndex;
int right=endIndex;
while(left<right)
{
while (left<right&&arr[right]>base)
right--;
while (left<right&&arr[left]<=base)
left++;
if(left<right)
{
int temp=arr[right];
arr[right]=arr[left];
arr[left]=temp;
}
}
arr[startIndex]=arr[left];
arr[left]=base;
return left;
}
}
堆排序
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
int[] arr=new int[]{1,3,2,6,5,7,8,9,10,0};
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
private static void heapSort(int[] array)
{
//把无序数组构建成最大堆
for(int i=(array.length-2)/2;i>=0;i--)
{
downAdjust(array,i,array.length);
}
System.out.println(Arrays.toString(array));
for(int i=array.length-1;i>0;i--)
{
int temp=array[i];
array[i]=array[0];
array[0]=temp;
downAdjust(array,0,i);
}
}
private static void downAdjust(int[] array,int parentIndex,int length)
{
//保存父节点值,用于最后赋值
int temp=array[parentIndex];
int childIndex=2*parentIndex+1;
while (childIndex<length)
{
//如果有右孩子,且右孩子大于左孩子的值,则定位到右孩子
if(childIndex+1<length&&array[childIndex+1]>array[childIndex])
{
childIndex++;
}
//如果父节点大于任何一个孩子的值
if(temp>array[childIndex])
break;
//无须真正交换,单向赋值即可
array[parentIndex]=array[childIndex];
parentIndex=childIndex;
childIndex=2*childIndex+1;
}
array[parentIndex]=temp;
}
}
冒泡排序
import java.util.Arrays;
public class bubbleSort {
public static void main(String[] args) {
int[] arr=new int[]{1,3,2,6,5,7,8,9,10,0};
bubbleSort(arr);
System.out.println(Arrays.toString(arr));
}
private static void bubbleSort(int[] arr)
{
int length=arr.length;
for(int i=0;i<length-1;i++)
{
for(int j=0;j<length-i-1;j++)
{
if(arr[j]>arr[j+1])
{
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}
}
插入排序
private static void insertSort(int[] arr)
{
int length=arr.length;
int insertNum;
for(int i=1;i<length;i++)
{
insertNum=arr[i];
int j=i-1;
while (j>=0&&arr[j]>insertNum)
{
arr[j+1]=arr[j];
j--;
}
arr[j+1]=insertNum;
}
}
简单排序算法
private static void selectSort(int[] a)
{
int length=a.length;
for(int i=0;i<a.length;i++)
{
int min=a[i];
int position=i;
for(int j=i+1;j<a.length;j++)
{
if(min>a[j])
{
min=a[j];
position=j;
}
}
a[position]=a[i];
a[i]=min;
}
}
归并排序
private static void mergeSort(int[] arr,int start,int end)
{
if(start<end)
{
int mid=(start+end)/2;
mergeSort(arr,start,mid);
mergeSort(arr,mid+1,end);
merge(arr,start,mid,end);
}
}
private static void merge(int[] arr,int start,int mid,int end)
{
int[] temp=new int[end-start+1];
int i=start;
int j=mid+1;
int k=0;
while (i<=mid&&j<=end)
{
if(arr[i]<arr[j])
{
temp[k++]=arr[i++];
}else
{
temp[k++]=arr[j++];
}
}
while (i<=mid)
{
temp[k++]=arr[i++];
}
while(j<=end)
{
temp[k++]=arr[j++];
}
for(int t=0;t<temp.length;t++)
{
arr[t+start]=temp[t];
}
}
将单链表按照奇偶位置拆分成两个链表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-arFwKIQU-1661411816886)(C:\Users\jjp-god\Desktop\笔记\Java学习\picture\image-20200815111151097.png)]
905. 按奇偶排序数组
给定一个非负整数数组 A,返回一个数组,在该数组中, A 的所有偶数元素之后跟着所有奇数元素。
你可以返回满足此条件的任何数组作为答案。
删除链表中重复的节点
public class Solution {
public ListNode deleteDuplication(ListNode pHead)
{
ListNode newHead = new ListNode(0); //解决删除头节点的可能
newHead.next=pHead;
ListNode preNode=newHead;
ListNode curNode=pHead;
while (curNode!=null){
if(curNode.next!=null&&curNode.val==curNode.next.val){
while (curNode.next!=null&&curNode.val==curNode.next.val){
curNode=curNode.next;
}
preNode.next=curNode.next;
}
else
{
preNode=curNode;
}
curNode=curNode.next;
}
return newHead.next;
}
}
链表中环的入口结点
/*
两个结论:
1、设置快慢指针,假如有环,他们最后一定相遇。
2、两个指针分别从链表头和相遇点继续出发,每次走一步,最后一定相遇与环入口。
*/
public class Solution {
public ListNode EntryNodeOfLoop(ListNode head)
{
if(head==null){
return null;
}
ListNode fastNode=head;
ListNode slowNode=head;
while (fastNode!=null&&fastNode.next!=null){
fastNode=fastNode.next.next;
slowNode=slowNode.next;
if(fastNode==slowNode){
fastNode=head;
while (slowNode!=fastNode){
slowNode=slowNode.next;
fastNode=fastNode.next;
}
return slowNode;
}
}
return null;
}
}
圆圈中最后剩下的结点
//采用数组模拟环的方式
import java.util.ArrayList;
public class Solution {
public int LastRemaining_Solution(int n, int m) {
if(n==0 || m==0){
return -1;
}
//这里为了方便直接使用Java中的容器类了
ArrayList<Integer> list = new ArrayList<>();
//将所有孩子的编号添加到数组中
for(int i=0;i<n;i++){
list.add(i);
}
int index=-1;
while(list.size()>1){
index = (index+m)%list.size();
list.remove(index);
//由于编号是从0开始的
index--;
}
return list.get(0);
}
}
两个链表的第一个公共结点
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
ListNode list1=pHead1;
ListNode list2=pHead2;
while(list1!=list2)
{
list1=(list1==null)?pHead2:list1.next;
list2=(list2==null)?pHead1:list2.next;
}
return list1;
}
}
复杂链表的复制
public class Solution {
public RandomListNode Clone(RandomListNode head)
{
if(pHead==null) return null;
RandomListNode node=pHead;
while(node!=null){
RandomListNode copy = new RandomListNode(node.label);
copy.next=node.next;
node.next=copy;
node=copy.next;
}
node=pHead;
while(node!=null){
if(node.random!=null){
node.next.random=node.random.next;
}
node=node.next.next;
}
node=pHead;
RandomListNode root=pHead.next;
RandomListNode tmp=root;
while(node!=null){
node.next=tmp.next;
tmp.next=node.next==null?null:node.next.next;
node=node.next;
tmp=tmp.next;
}
return root;
}
}
链表中倒数第K个结点
public class Solution {
public ListNode FindKthToTail(ListNode head,int k) {
if(head==null||k<=0){
return null;
}
ListNode fastNode=head;
ListNode slowNode=head;
for(int i=0;i<k-1;i++){
fastNode=fastNode.next;
if(fastNode==null){
return null;
}
}
while (fastNode.next!=null){
fastNode=fastNode.next;
slowNode=slowNode.next;
}
return slowNode;
}
}
从尾到头打印链表
import java.util.ArrayList;
public class Solution {
ArrayList<Integer> arrayList=new ArrayList<>();
public ArrayList<Integer> printListFromTailToHead(ListNode node){
if(node==null)
return arrayList;
printListFromTailToHead(node.next);
arrayList.add(node.val);
return arrayList;
}
}
两两交换链表中得结点
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
// Dummy node acts as the prevNode for the head node
// of the list and hence stores pointer to the head node.
ListNode dummy = new ListNode(-1);
dummy.next = head;
ListNode prevNode = dummy;
while ((head != null) && (head.next != null)) {
// Nodes to be swapped
ListNode firstNode = head;
ListNode secondNode = head.next;
// Swapping
prevNode.next = secondNode;
firstNode.next = secondNode.next;
secondNode.next = firstNode;
// Reinitializing the head and prevNode for next swap
prevNode = firstNode;
head = firstNode.next; // jump
}
// Return the new head node.
return dummy.next;
}
}
K个一组翻转链表
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dummy=new ListNode(0);
dummy.next=head;
ListNode pre=dummy;
ListNode end=dummy;
while(end.next!=null){
for(int i=0;i<k&&end!=null;i++){
end=end.next;
}
if(end==null){
break;
}
ListNode next=end.next;
ListNode start=pre.next;
end.next=null;
pre.next=reverse(start);
start.next=next;
pre=start;
end=pre;
}
return dummy.next;
}
private static ListNode reverse(ListNode head)
{
ListNode pre=null;
ListNode cur=head;
while(cur!=null)
{
ListNode next=cur.next;
cur.next=pre;
pre=cur;
cur=next;
}
return pre;
}
}
项目
项目的可优化之处
- 项目调度的总体思想,可采用DAG的形式来实现,即有向无环图。
任务调度组件的核心使命是让任务按照既定的执行计划去执行。对于复杂的任务,是由多个任务组成一个任务组,它们之间存在依赖关系,一个任务执行的条件,必须是它的前置任务已经执行成功(或者没有前置任务),它才可以执行。
网络编程
socket的一些问题
-
首先关于解析和使用数据包的问题
我们先开始采用固定长度大小的socket接收长度来收取数据,发现后来很多数据对不上,然后才发现是对方给我发的包的大小是不一样的,有的我对包的大小进行了截断,导致接收的数据不正确。后来我们采用固定大小(采用对方发来的包的最大长度)来作为截断长度,但这样做法太消耗资源。后来我们采用了先收取一个固定大小的包头信息,接着根据包头里面指定的包体大小来收取包体大小。的做法
-
关于ip和端口号是之前是在程序写死的,后来我采用了从xml文档读取的方式,便于了调试和后期的维护
-
心跳包机制,为了维持一个tcp连接的正常,通常一个连接长时间没有数据来往会被系统的防火墙关闭。这个时候,如果再想通过这个连接发送数据就会出错,所以需要通过心跳机制来维持。先假设每隔30秒给对端发送一个心跳数据包,这样需要开启一个定时器,定时器是每过30秒发送一个心跳数据包。
-
在我早些年的软件开发生涯中,我用connect函数连接一个对端,如果连接不上,那么我会再次重试,如果还是连接不上,会接着重试。如此一直反复下去,虽然这种重连动作放在一个专门的线程里面(对于客户端软件,千万不要放在UI线程里面,不然你的界面将会卡死)。但是如果对端始终连不上,比如因为网络断开。这种尝试其实是毫无意义的,不如不做。其实最合理的重连方式应该是结合下面的两种方案:
- 如果connect连接不上,那么n秒后再重试,如果还是连接不上2n秒之后再重试,以此类推,4n,8n,16n…
但是上述方案,也存在问题,就是如果当重试间隔时间变的很长,网络突然畅通了,这个时候,需要很长时间才能连接服务器,这个时候,就应该采取方法2。
- 在网络状态发生变化时,尝试重连。比如一款通讯软件,由于网络故障现在处于掉线状态,突然网络恢复了,这个时候就应该尝试重连。windows下检测网络状态发生变化的API是IsNetworkAlive。示例代码如下:
文档的一些问题
从文档中加载一些固定的参数,比在代码中写死要好很多
日志问题
日志功能,能让我们更好的定位问题
多用事件和回调
WPF Binding绑定机制其自身就维护者一个绑定注册表,这个注册表中将源与目标一一对应了起来。Target<---->Source。每当UI的属性值发生改变时,WPF系统将会自动调用一个全局的委托事件处理函数,可能就是public event PropertyChangedEventHandler PropertyChanged。在这个事件中,会使用刚才提到的绑定注册表,从而维护绑定目标和绑定数据源之间的数据同步机制
Binding接收到事件后,事件消息会告诉他是哪个属性发生了改变,于是就会通知Binding目标端的UI元素属性显示新的值。
依赖属性和路由事件都是通过注册的方式来实现的,而不是通过直接new方法来实例化得到的。也就是说在类中维护着一个依赖属性注册表和路由事件注册表。而这也是WPF依赖属性和路由事件实现附加功能的幕后机制的基础。
依赖属性的更改通知:
当我们使用绑定机制实现UI元素与依赖属性绑定之后,当UI元素的Property发生改变或者是依赖属性的值发生了改变,都会激发一个PropertyChanged的事件,WPF会响应这个事件实现UI元素与依赖属性的同步。而我们知道,UI元素也是依赖属性。
设计模式
生产者消费者设计模式
生产者消费者模式并不是GOF提出的23种设计模式之一,23种设计模式都是建立在面向对象的基础之上的,但其实面向过程的编程中也有很多高效的编程模式,生产者消费者模式便是其中之一,它是我们编程过程中最常用的一种设计模式。
在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
单单抽象出生产者和消费者,还够不上是生产者/消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。大概的结构如下图。

为了不至于太抽象,我们举一个寄信的例子(虽说这年头寄信已经不时兴,但这个例子还是比较贴切的)。假设你要寄一封平信,大致过程如下:
1、你把信写好——相当于生产者制造数据
2、你把信放入邮筒——相当于生产者把数据放入缓冲区
3、邮递员把信从邮筒取出——相当于消费者把数据取出缓冲区
4、邮递员把信拿去邮局做相应的处理——相当于消费者处理数据
观察者设计模式
先举个小栗子来了解一下观察者是干啥的~~
当我们在打团队游戏时,当你受到攻击需要队友帮忙时该怎么办?
这时候就需要给你所有的队友发送一条你正在被攻击的消息。所有的队友会根据你发送的消息作出相应的动作。比如有团队意识来帮你,或者不帮你继续玩自己的。
这里面的队员就是该设计模式名字中的观察者。那么受到攻击的自己的是什么呢。被观察者?不,准确的我们称之为目标或者主题。
所以整个流程大概就是:当目标(主题)的状态发送改变时就会通知观察者,观察者根据自己的情况做出相应的动作。
如何设计一个高并发系统
这道面试题涉及的知识点比较多,主要考察的是面试者的综合技术能力。高并发系统的设计手段有很多,主要体现在以下五个方面。
1、前端层优化
① 静态资源缓存:将活动页面上的所有可以静态的元素全部静态化,尽量减少动态元素;通过 CDN、浏览器缓存,来减少客户端向服务器端的数据请求。
② 禁止重复提交:用户提交之后按钮置灰,禁止重复提交。
③ 用户限流:在某一时间段内只允许用户提交一次请求,比如,采取 IP 限流。
2、中间层负载分发
可利用负载均衡,比如 nginx 等工具,可以将并发请求分配到不同的服务器,从而提高了系统处理并发的能力。
nginx 负载分发的五种方式:
**① 轮询(默认)**每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器不能正常响应,nginx 能自动剔除故障服务器。
**② 按权重(weight)**使用 weight 参数,指定轮询几率,weight 和访问比率成正比,用于后端服务器性能不均的情况,配置如下:
**③ IP 哈希值(ip_hash)**每个请求按访问 IP 的哈希值分配,这样每个访客固定访问一个后端服务器,可以解决 session 共享的问题,配置如下:
**④ 响应时间(fair)**按后端服务器的响应时间来分配请求,响应时间短的优先分配,配置如下:
**⑤ URL 哈希值(url_hash)**按访问 url 的 hash 结果来分配请求,和 IP 哈希值类似。
3、控制层(网关层)优化
限制同一个用户的访问频率,限制访问次数,防止多次恶意请求。
4、服务层优化
① 业务服务器分离:比如,将秒杀业务系统和其他业务分离,单独放在高配服务器上,可以集中资源对访问请求抗压。
**② 采用 MQ(消息队列)**缓存请求:MQ 具有削峰填谷的作用,可以把客户端的请求先导流到 MQ,程序在从 MQ 中进行消费(执行请求),这样可以避免短时间内大量请求,导致服务器程序无法响应的问题。
③ 利用缓存应对读请求,比如,使用 Redis 等缓存,利用 Redis 可以分担数据库很大一部分压力。
5、数据库层优化
读写分离,分库分表。
① 合理使用数据库引擎 ② 合理设置事务隔离级别,合理使用事务 ③ 正确使用数据库索引
- 尽量使用主键查询,而非其他索引,因为主键查询不会触发回表查询。
- 不做列运算,把计算都放入各个业务系统实现
- 查询语句尽可能简单,大语句拆小语句,减少锁时间
- 不使用 select * 查询
- or 查询改写成 in 查询
- 不用函数和触发器
- 避免 %xx 查询
- 少用 join 查询
- 使用同类型比较,比如 ‘123’ 和 ‘123’、123 和 123
- 尽量避免在 where 子句中使用 != 或者 <> 操作符,查询引用会放弃索引而进行全表扫描
- 列表数据使用分页查询,每页数据量不要太大
- 用 exists 替代 in 查询
- 避免在索引列上使用 is null 和 is not null
- 尽量使用主键查询
- 避免在 where 子句中对字段进行表达式操作
- 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型
④ 合理分库分表 ⑤ 使用数据库中间件实现数据库读写分离 ⑥ 设置数据库主从读写分离
Linux
Java开发中常用的Linux命令
pwd 查看当前路径
cd 进入到当前用户默认路径下
ls -a 查看文件及属性
ps -ef|grep tomcat 查看tomcat进程
netstat -anop|grep [进程号] 查看集成号端口信息
su root 切换root用户
sz [filename] 下载文件
tail -f catalina.out 输出打印
cat catalina.out |grep “xxxxx” 查询文件中的字符
grep -n “业务有关的关键字” catalina.out 查看关键字行号
sed -n ‘开始行数,结束行数p’ 待截取的文件 >> 保存的新文件
mkdir 新建文件夹
cp 复制文件夹
硬盘
硬盘设备是由大量的扇区组成的。以 MBR 分区为例。每个扇区的容量为 512 字节。其中第一个扇区最重要。它里面保存着主引导记录与分区表信息。就第一个扇区来讲,主引导记录需要占用 446 字节,分区表为 64 字节,结束符占用 2 字节。其中分区表每记录一个分区信息就需要 16 字节,这样一来,最多就只有4个分区信息可以写到第一扇区中,这4个分区就是4个主分区。
第一个扇区最多只能创建出4个分区 ?
为了解决分区个数不够的问题,可以将第一个扇区的分区表中16个字节(原本要写入主分区信息)的空间(称之为扩展分区)拿出来指向另一个分区。
也就是说,扩展分区并不是一个真正的分区,而像是有一个占用 16 字节的分区表空间的指针,一个指向另外一个分区的指针。这样一来,用户一般会选择使用3个主分区+1个扩展分区的方法,然后在扩展分区中创建无数个逻辑分区,从而来满足多分区(大于4个)的需求。
Linux 系统中有一个名为 superblock 的 “硬盘地图”。 Linux 并不是把文件内容直接写入到 superblock 中,而是在里面记录着整个文件系统的信息。
Linux 把每个文件的权限与属性记录在 inode("索引节点:index node ") 中,而且每个文件占用一个独立的 inode 表格,该表格的默认大小为 128 字节。
里面记录着如下信息 :
- 文件的访问权限(read、write、execute)
- 该文件的所有者与所属组(owner、group)
- 该文件的大小(size)
- 该文件的创建或内容修改时间(ctime)
- 该文件的最后一次访问时间(atime)
- 该文件的修改时间(mtime)
- 文件的特殊权限(SUID、SGID、SBIT)
- 该文件的真实数据地址(point)。
在 Linux 系统中 ,inode 号才是文件的唯一标识而非文件名。文件名只是为了方便人们的记忆和适用。
文件的实际内容则保存在 block 中(大小可以是 1KB、2KB 或 4KB),一个 inode 的默认大小为 128B (在 Ext3 文件系统中),记录一个 block 则消耗 4B 。当文件的 inode 被写满后,Linux 系统会自动分配出一个 Block 块,专门用于像 innode 那样记录其他 block 块的信息,这样能把各个 block 块的内容串到一起,就能够让用户读到完整的文件内容了。
对于存储文件内容的的 Block 块,有以下两种常见情况,以 4KB 的 block 大小为例说明情况 :
- 文件很小(1KB) , 但依然会占用一个 block ,因此会潜在占用 3kb。
- 文件很大(5kb) , 那么会占用两个 block。
总结 :
superBlock : 存储整个文件系统的信息。
inode : 存储文件的权限与属性。
data block : 真正存储文件内容。
软硬链接
-
硬链接:
可以将它理解为一个 “指向原始文件 inode 的指针”,系统不为它分配独立的 inode 和 文件。所以,硬链接文件与原始文件其实是同一个文件,只是名字不同。我们每添加一个硬链接,该文件的 innode 连接数就会增加 1 ; 而且只有当该文件的 inode 连接数为 0 时,才算彻底被将它删除。因此即便删除原始文件名,依然可以通过硬链接文件来访问。需要注意的是,我们不能跨分区对文件进行链接。
-
软链接(symbolic link) : 等同于 Windows 系统下的快捷方式。仅仅包括所含链接文件的路径名字。因此能链接目录,也能跨文件系统链接。但是,当删除原始文件后,链接文件也将失效。
硬链接占据空间吗 ? 比如我有一个 1G 的文件,现在我给这个文件建了一个硬链接。那么会占据 2G 空间吗?
不会,之前我们说了硬链接是一个指针或者说是文件的引用。只占一点点空间。
硬链接:与普通文件没什么不同,inode都指向同一文件在硬盘中的区块
RPC
基本概念
- RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务
- 本地过程调用:如果需要将本地student对象的age+1,可以实现一个addAge()方法,将student对象传入,对年龄进行更新之后返回即可,本地方法调用的函数体通过函数指针来指定。
- 远程过程调用:上述操作的过程中,如果addAge()这个方法在服务端,执行函数的函数体在远程机器上,如何告诉机器需要调用这个方法呢?
- 首先客户端需要告诉服务器,需要调用的函数,这里函数和进程ID存在一个映射,客户端远程调用时,需要查一下函数,找到对应的ID,然后执行函数的代码。
- 客户端需要把本地参数传给远程函数,本地调用的过程中,直接压栈即可,但是在远程调用过程中不再同一个内存里,无法直接传递函数的参数,因此需要客户端把参数转换成字节流,传给服务端,然后服务端将字节流转换成自身能读取的格式,是一个序列化和反序列化的过程。
- 数据准备好了之后,如何进行传输?网络传输层需要把调用的ID和序列化后的参数传给服务端,然后把计算好的结果序列化传给客户端,因此TCP层即可完成上述过程,gRPC中采用的是HTTP2协议。
上述过程可总结为:
// Client端
// Student student = Call(ServerAddr, addAge, student)
1. 将这个调用映射为Call ID。
2. 将Call ID,student(params)序列化,以二进制形式打包
3. 把2中得到的数据包发送给ServerAddr,这需要使用网络传输层
4. 等待服务器返回结果
5. 如果服务器调用成功,那么就将结果反序列化,并赋给student,年龄更新
// Server端
1. 在本地维护一个Call ID到函数指针的映射call_id_map,可以用Map<String, Method> callIdMap
2. 等待服务端请求
3. 得到一个请求后,将其数据包反序列化,得到Call ID
4. 通过在callIdMap中查找,得到相应的函数指针
5. 将student(params)反序列化后,在本地调用addAge()函数,得到结果
6. 将student结果序列化后通过网络返回给Client
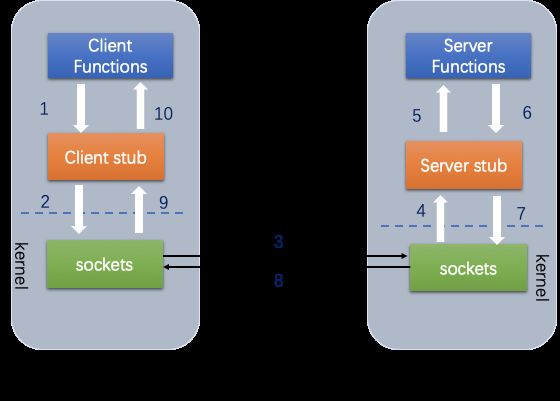
一个 RPC 的核心功能主要有 5 个部分组成,分别是:客户端、客户端 Stub、网络传输模块、服务端 Stub、服务端等。
- 客户端(Client):服务调用方。
- 客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端。
- 服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理。
- 服务端(Server):服务的真正提供者。
- Network Service:底层传输,可以是 TCP 或 HTTP。
- 完整的RPC框架图
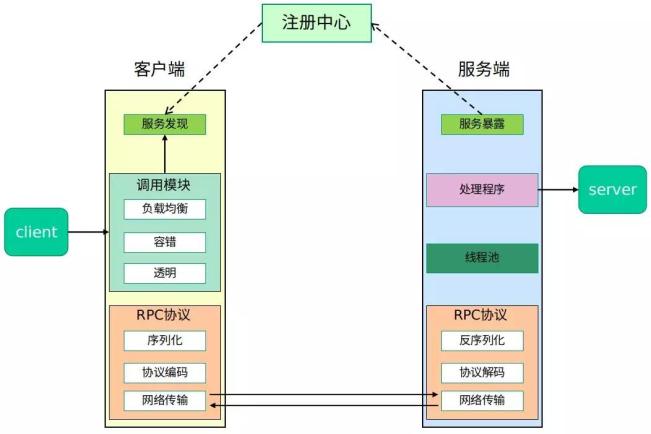
RPC 核心之功能实现
RPC 的核心功能主要由 5 个模块组成,如果想要自己实现一个 RPC,最简单的方式要实现三个技术点,分别是:
- 服务寻址
- 数据流的序列化和反序列化
- 网络传输
服务寻址
服务寻址可以使用 Call ID 映射。在本地调用中,函数体是直接通过函数指针来指定的,但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。
所以在 RPC 中,所有的函数都必须有自己的一个 ID。这个 ID 在所有进程中都是唯一确定的。
客户端在做远程过程调用时,必须附上这个 ID。然后我们还需要在客户端和服务端分别维护一个函数和Call ID的对应表。
当客户端需要进行远程调用时,它就查一下这个表,找出相应的 Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
实现方式:服务注册中心。
要调用服务,首先你需要一个服务注册中心去查询对方服务都有哪些实例。Dubbo 的服务注册中心是可以配置的,官方推荐使用 Zookeeper。
实现案例:RMI(Remote Method Invocation,远程方法调用)也就是 RPC 本身的实现方式。
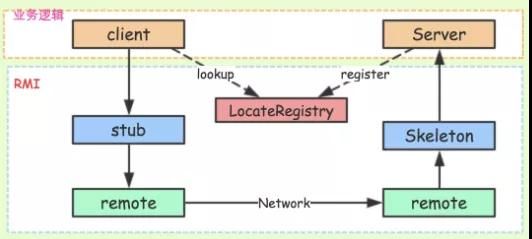
RMI架构图
序列化和反序列化
客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。
但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。
这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。
只有二进制数据才能在网络中传输,序列化和反序列化的定义是:
- 将对象转换成二进制流的过程叫做序列化
- 将二进制流转换成对象的过程叫做反序列化
这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
网络传输
网络传输:远程调用往往用在网络上,客户端和服务端是通过网络连接的。
所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把 Call ID 和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。
只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。
尽管大部分 RPC 框架都使用 TCP 协议,但其实 UDP 也可以,而 gRPC 干脆就用了 HTTP2。
TCP 的连接是最常见的,简要分析基于 TCP 的连接:通常 TCP 连接可以是按需连接(需要调用的时候就先建立连接,调用结束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期持有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接是否存活有效),多个远程过程调用共享同一个连接。
所以,要实现一个 RPC 框架,只需要把以下三点实现了就基本完成了:
- Call ID 映射:可以直接使用函数字符串,也可以使用整数 ID。映射表一般就是一个哈希表。
- 序列化反序列化:可以自己写,也可以使用 Protobuf 或者 FlatBuffers 之类的。
- 网络传输库:可以自己写 Socket,或者用 Asio,ZeroMQ,Netty 之类。
基于 TCP 协议的 RPC 调用
由服务的调用方与服务的提供方建立 Socket 连接,并由服务的调用方通过 Socket 将需要调用的接口名称、方法名称和参数序列化后传递给服务的提供方,服务的提供方反序列化后再利用反射调用相关的方法。
***将结果返回给服务的调用方,整个基于 TCP 协议的 RPC 调用大致如此。
但是在实例应用中则会进行一系列的封装,如 RMI 便是在 TCP 协议上传递可序列化的 Java 对象。
基于 HTTP 协议的 RPC 调用
该方法更像是访问网页一样,只是它的返回结果更加单一简单。
其大致流程为:由服务的调用者向服务的提供者发送请求,这种请求的方式可能是 GET、POST、PUT、DELETE 等中的一种,服务的提供者可能会根据不同的请求方式做出不同的处理,或者某个方法只允许某种请求方式。
而调用的具体方法则是根据 URL 进行方法调用,而方法所需要的参数可能是对服务调用方传输过去的 XML 数据或者 JSON 数据解析后的结果,***返回 JOSN 或者 XML 的数据结果。
由于目前有很多开源的 Web 服务器,如 Tomcat,所以其实现起来更加容易,就像做 Web 项目一样。
两种方式对比
基于 TCP 的协议实现的 RPC 调用,由于 TCP 协议处于协议栈的下层,能够更加灵活地对协议字段进行定制,减少网络开销,提高性能,实现更大的吞吐量和并发数。
但是需要更多关注底层复杂的细节,实现的代价更高。同时对不同平台,如安卓,iOS 等,需要重新开发出不同的工具包来进行请求发送和相应解析,工作量大,难以快速响应和满足用户需求。
基于 HTTP 协议实现的 RPC 则可以使用 JSON 和 XML 格式的请求或响应数据。
而 JSON 和 XML 作为通用的格式标准(使用 HTTP 协议也需要序列化和反序列化,不过这不是该协议下关心的内容,成熟的 Web 程序已经做好了序列化内容),开源的解析工具已经相当成熟,在其上进行二次开发会非常便捷和简单。
但是由于 HTTP 协议是上层协议,发送包含同等内容的信息,使用 HTTP 协议传输所占用的字节数会比使用 TCP 协议传输所占用的字节数更高。
因此在同等网络下,通过 HTTP 协议传输相同内容,效率会比基于 TCP 协议的数据效率要低,信息传输所占用的时间也会更长,当然压缩数据,能够缩小这一差距。
使用 RabbitMQ 的 RPC 架构
-
RabbitMQ在RPC中的角色:
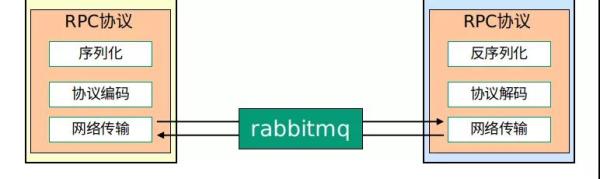
使用 RabbitMQ 的好处:
- 同步变异步:可以使用线程池将同步变成异步,但是缺点是要自己实现线程池,并且强耦合。使用消息队列可以轻松将同步请求变成异步请求。
- 低内聚高耦合:解耦,减少强依赖。
- 流量削峰:通过消息队列设置请求***值,超过阀值的抛弃或者转到错误界面。
- 网络通信性能提高:TCP 的创建和销毁开销大,创建 3 次握手,销毁 4 次分手,高峰时成千上万条的链接会造成资源的巨大浪费,而且操作系统每秒处理 TCP 的数量也是有数量限制的,必定造成性能瓶颈。
RabbitMQ 采用信道通信,不采用 TCP 直接通信。一条线程一条信道,多条线程多条信道,公用一个 TCP 连接。
一条 TCP 连接可以容纳***条信道(硬盘容量足够的话),不会造成性能瓶颈。
更多内容参考链接:https://developer.51cto.com/art/201906/597963.htm
ES(ElasticSearch)
ES的功能:
(1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天某种商品销量前10的商家有哪些,新闻网站,最近一个月访问排名前三的新闻板块是哪些
(2)全文检索,结构化检索,数据分析
全文检索:比如说想搜索商品名称包括牙膏的商品 select * from product where product_name like ‘%牙膏%’
结构化搜索:比如说想搜索商品分类为日化用品的商品有哪些,select * from product where category_id=‘日化用品’
数据分析:我们分析每一个商品分类下有多少个商品:select category_id,count(*) from products group by category_id
(3) 对海量数据进行实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
使用案例
1、将ES作为网站的主要后端系统
比如现在搭建一个博客系统,对于博客帖子的数据可以直接在ES上存储,并且使用ES来进行检索,统计。ES提供了持久化的存储、统计和很多其他数据存储的特性。
注意:但是像其他的NOSQL数据存储一样,ES是不支持事务的,如果要事务机制,还是考虑使用其他的数据库做真实库。
2、将ES添加到现有系统
有些时候不需要ES提供所有数据的存储功能,只是想在一个数据存储的基础之上使用ES。比如已经有一个复杂的系统在运行,但是现在想加一个搜索的功能,就可以使用该方案。
3、将ES作为现有解决方案的后端部分
因为ES是开源的系统,提供了直接的HTTP接口,并且现在有一个大型的生态系统在支持他。比如现在我们想部署大规模的日志框架、用于存储、搜索和分析海量的事件,考虑到现有的工具可以写入和读取ES,可以不需要进行任何开发,配置这些工具就可以去运作。
倒排序索引
正排索引:根据文档ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。

倒排索引:字面意思可以知道他和正序索引是反的。在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(文档要除去一些无用的词,比如’的’这些,剩下的词就是关键词,每个关键词都有自己的ID)
倒排序索引
ZooKeeper
ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。 分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协 调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列 等功能。
应用:
- zookeeper是一个拥有文件系统特点的数据库------>(统一命名服务)
- zookeeper是解决了数据一致性问题的分布式数据库
- zookeeper是一个具有发布和订阅功能的分布式数据库
一致性
-
强一致性
强制要求步骤2读取的时候,一定要读取的是2,不能读取的是1,这种方式要求数据库之间的同步非常迅速或者在步骤2上加锁以等待数据同步完成。
-
弱一致性
允许步骤2读取的时候,可以读取的是1,这种方式叫做弱一致性,其实就是不需要一致。
-
最终一致性
允许步骤2读取的时候,可以先读到1,过一段时间再读到2,这种叫做最终一致性,就是可以等待一段时间才一致。
ZooKeeper保证最终一致性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-spd4wAfC-1661411816891)(C:\Users\jjp-god\Desktop\校招\pic\image-20200907104658087.png)]
CAP
C:Consistency:一致性
A:Availability:可用性
P:Partition Tolerance:分区容错性
一些重要的要素
- 领导(领导者选举机制)
- 过半机制
- 预提交,ack(过半机制),提交(两次提交)
- 同步
设计模式
责任链模式
责任链(chain of responsibility)模式很像异常的捕获和处理,当一个问题发生的时候,当前对象看一下自己是否能够处理,不能的话将问题抛给自己的上级去处理,但是要注意这里的上级不一定指的是继承关系的父类,这点和异常的处理是不一样的。所以可以这样说,当问题不能解决的时候,将问题交给另一个对象去处理,就这样一直传递下去直至当前对象找不到下线了,处理结束。如下图所示,处于同等层次的类都继承自Support类,当当前对象不能处理的时候,会根据预先设定好的传递关系将问题交给下一个人,可以说是“近水楼台先得月”,就看有没有能力了。我们也可以看作是大家在玩一个传谜语猜谜底的小游戏,按照座位的次序以及规定的顺序传递,如果一个人能回答的上来游戏就结束,否则继续向下传,如果所有人都回答不出来也会结束。这样或许才是责任链的本质,体现出了同等级的概念。
单例模式
秒杀系统
秒杀系统的场景
-
1.高并发
-
2.超卖问题
-
3.恶意请求问题
-
4.链接暴漏问题
-
5.数据库崩溃
解决办法:
-
服务单一职责:
把秒杀系统独立出来,这样就算秒杀系统没坑住高并发,数据库崩了,也不会影响到其他的服务
-
秒杀链接加盐:
url暴漏会让恶意攻击者在秒杀系统开发瞬间发送大量请求,造成商品商品全卖给恶意攻击者了,这种情况怎么办呢?
我们需要把URL动态化,就连写代码的人都不知道,你就通过MD5之类的加密算法加密随机的字符串去做url,然后通过前端代码获取url后台校验才能通过。
-
Redis集群
单机的Redis顶不住嘛,那简单多找几个兄弟啊,秒杀本来就是读多写少,那你们是不是瞬间想起来我之前跟你们提到过的,Redis集群,主从同步、读写分离,我们还搞点哨兵,开启持久化直接无敌高可用!
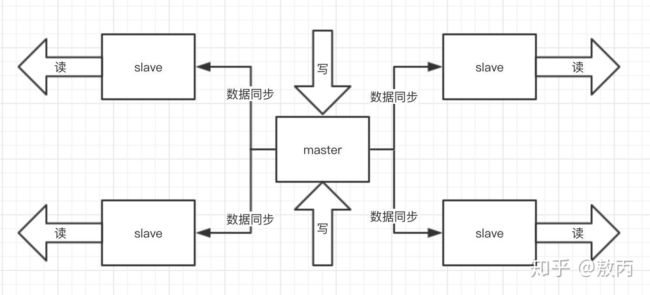
-
Nginx
Nginx大家想必都不陌生了吧,这玩意是高性能的web服务器,并发也随便顶几万不是梦,但是我们的Tomcat只能顶几百的并发呀,那简单呀负载均衡嘛,一台服务几百,那就多搞点,在秒杀的时候多租点流量机。
Tip:据我所知国内某大厂就是在去年春节活动期间租光了亚洲所有的服务器,小公司也很喜欢在双十一期间买流量机来顶住压力。
这样一对比是不是觉得你的集群能顶很多了。
恶意请求拦截也需要用到它,一般单个用户请求次数太夸张,不像人为的请求在网关那一层就得拦截掉了,不然请求多了他抢不抢得到是一回事,服务器压力上去了,可能占用网络带宽或者把服务器打崩、缓存击穿等等。
-
资源静态化
秒杀一般都是特定的商品还有页面模板,现在一般都是前后端分离的,所以页面一般都是不会经过后端的,但是前端也要自己的服务器啊,那就把能提前放入cdn服务器的东西都放进去,反正把所有能提升效率的步骤都做一下,减少真正秒杀时候服务器的压力。
-
按钮控制
大家有没有发现没到秒杀前,一般按钮都是置灰的,只有时间到了,才能点击。
这是因为怕大家在时间快到的最后几秒秒疯狂请求服务器,然后还没到秒杀的时候基本上服务器就挂了。
这个时候就需要前端的配合,定时去请求你的后端服务器,获取最新的北京时间,到时间点再给按钮可用状态。
按钮可以点击之后也得给他置灰几秒,不然他一样在开始之后一直点的。你敢说你们秒杀的时候不是这样的?
-
限流
限流这里我觉得应该分为前端限流和后端限流。
前端限流:这个很简单,一般秒杀不会让你一直点的,一般都是点击一下或者两下然后几秒之后才可以继续点击,这也是保护服务器的一种手段。
后端限流:秒杀的时候肯定是涉及到后续的订单生成和支付等操作,但是都只是成功的幸运儿才会走到那一步,那一旦100个产品卖光了,return了一个false,前端直接秒杀结束,然后你后端也关闭后续无效请求的介入了。
-
库存预热
秒杀的本质,就是对库存的抢夺,每个秒杀的用户来你都去数据库查询库存校验库存,然后扣减库存,撇开性能因数,你不觉得这样好繁琐,对业务开发人员都不友好,而且数据库顶不住啊。
我们都知道数据库顶不住但是他的兄弟非关系型的数据库Redis能顶啊!
那不简单了,我们要开始秒杀前你通过定时任务或者运维同学提前把商品的库存加载到Redis中去,让整个流程都在Redis里面去做,然后等秒杀介绍了,再异步的去修改库存就好了。
但是用了Redis就有一个问题了,我们上面说了我们采用主从,就是我们会去读取库存然后再判断然后有库存才去减库存,正常情况没问题,但是高并发的情况问题就很大了。
这里我就不画图了,我本来想画图的,想了半天我觉得语言可能更好表达一点。
**多品几遍!!!**就比如现在库存只剩下1个了,我们高并发嘛,4个服务器一起查询了发现都是还有1个,那大家都觉得是自己抢到了,就都去扣库存,那结果就变成了-3,是的只有一个是真的抢到了,别的都是超卖的。咋办?
Lua:
之前的文章就简单的提到了他,我今天就多一定点篇幅说一下吧。
Lua 脚本功能是 Reids在 2.6 版本的最大亮点, 通过内嵌对 Lua 环境的支持, Redis 解决了长久以来不能高效地处理 CAS (check-and-set)命令的缺点, 并且可以通过组合使用多个命令, 轻松实现以前很难实现或者不能高效实现的模式。
**Lua脚本是类似Redis事务,有一定的原子性,不会被其他命令插队,可以完成一些Redis事务性的操作。**这点是关键。
知道原理了,我们就写一个脚本把判断库存扣减库存的操作都写在一个脚本丢给Redis去做,那到0了后面的都Return False了是吧,一个失败了你修改一个开关,直接挡住所有的请求,然后再做后面的事情嘛。
-
削峰填谷
采用消息队列来实现。
OPPO面
代码中if—else—过多的问题
方法一:表驱动
对于逻辑表达模式固定的if…else…代码,可以通过某种映射关系,将逻辑表达式用表格的方式表示,再使用表格查找的方式,找到某个输入所对应的处理函数,使用这个处理函数进行运算。
方法二:职责链模式
当if…else…中的条件表达式灵活多变,无法将条件中的数据抽象成表格并用统一的方式进行判断时,这时应将对条件的判断权交给每个功能组件。并用链的形式将这些组件串联起来,形成完整的功能。
方法三:注解驱动
通过Java注解(或其他语言的类似机制)定义执行某个方法的条件。在程序执行时,通过对比注解中定义的条件是否匹配,再决定是否调用此方法。具体实现时,可以采用表驱动或者职责链的方式实现。
适合条件分支很多多,对程序扩展性和易用性均有较高要求的场景。通常是某个系统中经常遇到新需求的核心功能。
方法四:事件驱动
通过关联不同的事件类型和对应的处理机制,来实现复杂的逻辑,同时达到解耦的目的。
适合场景:
从理论角度讲,事件驱动可以看做是表驱动的一种,但从实践角度讲,事件驱动和前面提到的表驱动有多处不同。具体来说:
- 表驱动通常是一对一的关系;事件驱动通常是一对多;
- 表驱动中,触发和执行通常是强依赖;事件驱动中,触发和执行是弱依赖
正是上述两者不同,导致了两者适用场景的不同。具体来说,事件驱动可用于如订单支付完成触发库存、物流、积分等功能。
方法五:有限状态机
有限状态机通常被称为状态机(无限状态机这个概念可以忽略)。先引用维基百科上的定义:
有限状态机(英语:finite-state machine,缩写:FSM),简称状态机,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。
其实,状态机也可以看做是表驱动的一种,其实就是当前状态和事件两者组合与处理函数的一种对应关系。当然,处理成功之后还会有一个状态转移处理。
适用场景
虽然现在互联网后端服务都在强调无状态,但这并不意味着不能使用状态机这种设计。其实,在很多场景中,如协议栈、订单处理等功能中,状态机有这其天然的优势。因为这些场景中天然存在着状态和状态的流转。
Spring IOC加载全过程
下面一段代码可以作为Spring代码加载的入口:
ApplicationContext ac=new ClassPathXmlApplicationContext("spring.xml");
ac.getBean(XXX.class);
ClassPathXmlApplicationContext用于加载CLASSPATH下的Spring配置文件,可以看到,第二行就已经可以获取到Bean的实例了,那么必然第一行就已经完成了对所有Bean实例的加载,因此可以通过ClassPathXmlApplicationContext作为入口。来研究spring加载的过程。
在ClassPathXmlApplicationContext的构造函数中最重要的就是refresh()方法
代码如下:
1 public void refresh() throws BeansException, IllegalStateException {
2 synchronized (this.startupShutdownMonitor) {
3 // Prepare this context for refreshing.
4 prepareRefresh();
5
6 // Tell the subclass to refresh the internal bean factory.
7 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
8
9 // Prepare the bean factory for use in this context.
10 prepareBeanFactory(beanFactory);
11
12 try {
13 // Allows post-processing of the bean factory in context subclasses.
14 postProcessBeanFactory(beanFactory);
15
16 // Invoke factory processors registered as beans in the context.
17 invokeBeanFactoryPostProcessors(beanFactory);
18
19 // Register bean processors that intercept bean creation.
20 registerBeanPostProcessors(beanFactory);
21
22 // Initialize message source for this context.
23 initMessageSource();
24
25 // Initialize event multicaster for this context.
26 initApplicationEventMulticaster();
27
28 // Initialize other special beans in specific context subclasses.
29 onRefresh();
30
31 // Check for listener beans and register them.
32 registerListeners();
33
34 // Instantiate all remaining (non-lazy-init) singletons.
35 finishBeanFactoryInitialization(beanFactory);
36
37 // Last step: publish corresponding event.
38 finishRefresh();
39 }
40
41 catch (BeansException ex) {
42 // Destroy already created singletons to avoid dangling resources.
43 destroyBeans();
44
45 // Reset 'active' flag.
46 cancelRefresh(ex);
47
48 // Propagate exception to caller.
49 throw ex;
50 }
51 }
52 }
每个子方法的功能之后一点一点再分析,首先refresh()方法有几点是值得我们学习的:
1、方法是加锁的,这么做的原因是避免多线程同时刷新Spring上下文
2、尽管加锁可以看到是针对整个方法体的,但是没有在方法前加synchronized关键字,而使用了对象锁startUpShutdownMonitor,这样做有两个好处:
(1)refresh()方法和close()方法都使用了startUpShutdownMonitor对象锁加锁,这就保证了在调用refresh()方法的时候无法调用close()方法,反之亦然,避免了冲突
(2)另外一个好处不在这个方法中体现,但是提一下,使用对象锁可以减小了同步的范围,只对不能并发的代码块进行加锁,提高了整体代码运行的效率
3、方法里面使用了每个子方法定义了整个refresh()方法的流程,使得整个方法流程清晰易懂。这点是非常值得学习的,一个方法里面几十行甚至上百行代码写在一起,在我看来会有三个显著的问题:
(1)扩展性降低。反过来讲,假使把流程定义为方法,子类可以继承父类,可以根据需要重写方法
(2)代码可读性差。很简单的道理,看代码的人是愿意看一段500行的代码,还是愿意看10段50行的代码?
(3)代码可维护性差。这点和上面的类似但又有不同,可维护性差的意思是,一段几百行的代码,功能点不明确,不易后人修改,可能会导致“牵一发而动全身”
-
prepareRefresh方法
这个方法比较简单,顾名思义,准备刷新Spring上下文,其主要功能是:
- 设置一下刷新Spring上下文的时间
- 将active标识设置为true
-
obtainFreshBeanFacrtory方法:
作用:获取刷新Spring上下文的Bean工厂。
Spring AOP理解:
OOP面向对象,允许开发者定义纵向的关系,但并适用于定义横向的关系,导致了大量代码的重复,而不利于各个模块的重用。
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。可用于权限认证、日志、事务处理。
AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
(1)AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
(2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理:
①JDK动态代理只提供接口的代理,不支持类的代理。核心InvocationHandler接口和Proxy类,InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy利用 InvocationHandler动态创建一个符合某一接口的的实例, 生成目标类的代理对象。
②如果代理类没有实现 InvocationHandler 接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
静态代理与动态代理区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。
InvocationHandler 的 invoke(Object proxy,Method method,Object[] args):proxy是最终生成的代理实例; method 是被代理目标实例的某个具体方法; args 是被代理目标实例某个方法的具体入参, 在方法反射调用时使用。
HR面
英文自我介绍:
My name is Jane Jipan. I am studying in The School of Mechanical Engineering of Hohai University as an undergraduate and in the School of Mechanical Engineering of Dalian University of Technology as a postgraduate, and I am engaged in the study and research of robotics.During my study in school, I kept my academic performance in the forefront of my age. I was successively awarded the Excellent Academic Scholarship of Hohai University, The Spiritual Civilization Scholarship of Hohai University, and the first-class postgraduate grant of Dalian University of Technology. In terms of student work, I was awarded the title of Outstanding League Cadre of Hohai University.
In my junior year, I began to join the robot laboratory of the university, engaged in the research and development and learning of photovoltaic robot. During this period, I was responsible for the development of upper computer software of photovoltaic robot system.
During my postgraduate period, I was engaged in the research and development of intelligent logistics distribution system in Dahua Zhongtian Technology Co., LTD., the company cooperated with my tutor.Realize the system’s production dispatching, work scheduling, information acquisition and management functions.
In addition, when I was a graduate student, I also loved technology sharing and set up my own technical blog, which realized the functions of blog display, thumb up, mutual attention, page views, music box, message board and so on.Share what I saw, heard and thought here
In addition, during my postgraduate study, I was also engaged in the building of ROS system in the intelligent robot laboratory. I recognized the position of desktop water cups through visual images, and designed recognition algorithm under OpenCV to guide mobile robots to recognize specific water cups.OpenCV’s morphological design algorithm is used to extract the key corner points of objects on the map.Develop Modbus/TCP based communication interface to realize data exchange between upper computer and robot system.
未来3-5年的职业规划
我目前的打算就是从基层做起,认真摸索并优化自己的工作方法,希望能够尽快的做到对本行业的全面了解;接下来就是可以通过参加培训和请教身边的大牛等任何提高自己能力的方式来不断提升自己的能力水平;最终希望能通过自己的努力,并且取得的成绩在得到认可的情况下上升到管理工作中去。
难忘的一次项目经历
智能物流配送系统:
首先刚开始,由于是学校项目,开始的需求不是很清晰,我们软件这边的工作人员定制的需求很不明确,所以我需要在不耽误工期的前提下,提前开发,尽量将现在现有的需求拆分成小的需求,比如先把通讯模块(不含通讯报文解析)做好,日志模块做好,数据库连接模块做好,还有一些常用的类型转换模块写好。等等,
后来需求明确后,先是通讯协议,由于我们是与新松机器人公司合作完成这个项目,所以各个机器人之间的协议开始的制定并不完全一样,所以由我汇总后,我重新定义了一个兼容这些机器人的通讯协议,利于了后续调试的交流工作,和维护工作。在通讯协议的制定中,我也学到了很多,了解到了一个基本的通讯协议是由:
消息头+消息体构成,消息头构成中有
消息头标识,通讯标志位,命令码,数据长度(不包括消息头),包序,最后一包,消息体的异或校验,保留字,消息头的异或校验:
这样设计有一定的科学:
首先,协议的开头设置消息头标识,我们可以用来判断当前数据包是否合法,为了缓解服务器的压力,我们可以取出当前数据包的前4个字节与我们预先定义的消息头标识进行对比,如果是非法格式,说明这一帧不是不应用程序的消息,就可以跳过,不继续解码。
命令码的设置:体现了动作和业务数据分离的思想,定义code来分门别类的代表不同的业务逻辑。
为了解决数据的粘包和拆包问题,我们设置了数据长度这段字节
另外可能一包数据太大,我们需要分包传输,所以我们设置了包序和最后一包字段
另外还设计了校验位
为了后续的扩展,我们还设置了保留位。
第二个就是类的设计:
由于无论下位机的机器人实现了何种功能,对于上位机来说,与下位机的交流,就两个操作,发送字节流和接收字节流。随意我们对于所有的机器人定义了一个统一的命令发送接收类,基类,所有的机器人都继承这个基类
而后机器人根据自身的属性和状态,拼装要发送的字节流,和解析要发送的字节流。而不需要理会如何发送和接收。
另外,拼接和解析字节流,无非就是 Int 转 byte 或者 Short转byte,或者String 转byte。或者byte转int,byte转short,byte转String等,这些方法我们可以将其封装成一个工具类,这样各个机器类就不需要理会,数据是如何封装和解析的。
系统的哪些运行信息需要进行日志记录:
- 功能模块的启动和结束(完整的系统由多个功能模块组成,每个模块负责不同的功能,因此需要对模块的启动和结束进行监控。是否在需要的时机正常加载该模块?又是否在退出结束的时候正常完成结束操作,正常退出?)
- 用户的登录和退出**(哪位用户在什么时间通过什么IP登录或退出了系统)**
- 系统的关键性操作**(数据库链接信息、网络通信的成功与失败等)**
- 系统运行期间的异常信息**(**NPE、OOM以及其他的超时、转换异常等)
- 关键性方法的进入和退出**(一些重要业务处理的方法,在进入和结束的时候需要有日志信息进行输出)**
请你先自我介绍一下:
主要介绍最强的技能,最深入研究的知识领域,个性中最积极的部分,以及主要的成就,突出积极的个性和做事的能力,说的合情合理企业才会相信
你觉得你有什么缺点
非科班出生,基础可能相较于科班有劣势,另外在做事方面性子急,对于做事效率不高的人,往往会比较着急。但是,平常我会努力平复自己的情绪,学会聆听,慢慢改变自己的急躁
你对薪资待遇有什么要求?
参考1:领导您好,综合我的面试情况,您觉得我能胜任多少薪资呢?谢谢!(适合有经验的求职者,反问HR)
参考2:领导您好,因为我不清楚咱们公司的具体薪酬结构,包括绩效方面,年终福利方面,您可以先简单告知我一下。谢谢!
你对公司加班是怎么看的?
领导您好,如果是个人效率问题,我一定会努力提高效率,在合理的时间内完成工作安排,绝不用加班来弥补自己的工作效率问题;如果是工作需要我会义不容辞加班,我现在单身,没有任何家庭负担,可以全身心的投入工作。但同样,我也会提高工作效率,减少不必要的加班。
3-5年内,你有什么职业规划?
领导您好,3~5年内,我的目标是在工作方面超额完成,让自己在工作领域有所建树;在行业方面,希望自己以后能成为领域行家,根据公司脉络发展进步,能够让自己与公司共同进步,实现双赢。
你对我们公司了解多少
领导您好,我通过简单了解。知道咱们公司的主要产品有XXXX,咱们现有媒介平台是通过XXX,渠道合作方面包括XXXX。
如果公司录用你,你将怎样开展工作
这个问题,你需要展示你工作岗位的专业性。展现你的做事思维以及做事方法,你知道怎么去布局工作,你更知道怎么去执行工作,从而达成工作目标。
你还有什么想要问的吗?
这个问题求职者千万不要什么都不言语,这样你会失去很好的沟通机会。甚至HR觉得你对这场面试不是很重视。你可以问关于岗位的问题,关于公司的产品问题,关于公司的项目问题等等。展示出你对这些的关心和对入职后的工作期待。
和直属领导意见不和怎么办,
第一,首先我会先考量与领导意见不合的原因。
要清楚跟领导意见不合是出发点不一致还是解决思路不一致。
第二,针对意见不合的原因,再做甄别选择。
如果是出发点不一致,我会优先听从领导的。
因为领导站得高看得远,跟他的大局观和视野相提并论,那真是小巫见大巫。
如果是解决思路不一致,我会拿出两套可行性的方案,向领导表达解决难度和结果,最后供领导选择。
第三,领导最终选择什么方案,我都会百分百去执行。
不管领导最终选择听自己,还是选择我的方案,我都会毫不犹豫的去执行。
因为领导会有自己的综合考虑,他站的角度会更加全面。
决策权领导会自己把控,我只需要认真贯彻和执行就好
你的优点和缺点
- 结合自己的项目来说,说出自己的学习能力强,沟通能力强,时间管理能力强,团队和谐性。
- 首先就是性格还是较为急躁,另外就是计算机的思维能力,还有就是高格局思维能力。
华为企业文化
狼性文化,学习,创新,获益,团结。
Cloud bu:云主机,云托管,云计算研发能力,超算,云会议,企业IT等。
为什么能胜任这份工作
1、谈岗位认知,先谈对岗位的认知,首先谈岗位是做什么的,也就是岗位职责、岗位的工作内容,说明自己对岗位了解比较清楚;其次谈对任职资格要求的认知,讲清楚做这个岗位需要具备的知识、能力、素质、持证等各方面的要求,说明自己对岗位要求很了解
2、谈个人与岗位的匹配度,针对岗位任职资格要求,讲自己具备对应的知识、能力、素质、持证,与岗位很匹配,也就是自己能做好这个岗位,具备做好岗位工作的各方面要求
3、谈工作开展计划,进一步阐述如果自己应聘成功,将如何开展工作,比如如何快速转换心态(从学生心态转入工作心态)、快速融入公司文化与团队文化、快速了解企业情况、以及具体岗位的工作计划等等,以此书说明对上岗工作有思考、计划、安排
你对加班的看法?
回答提示:实际上好多公司问这个问题,并不证明一定要加班。 只是想测试你是否愿意为公司奉献。
- 回答样本:如果是工作需要我会义不容辞加班。我现在单身,没有任何家庭负担,可以全身心的投入工作。但同时,我也会提高工作效率,减少不必要的加班
IM项目
雪花算法
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,基本上保持自增的,后面的代码中有详细的注解。
这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。

给大家举个例子吧,比如下面那个 64 bit 的 long 型数字:
- 第一个部分,是 1 个 bit:0,这个是无意义的。
- 第二个部分是 41 个 bit:表示的是时间戳。
- 第三个部分是 5 个 bit:表示的是机房 id,10001。
- 第四个部分是 5 个 bit:表示的是机器 id,1 1001。
- 第五个部分是 12 个 bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的 id 的序号,0000 00000000。
①1 bit:是不用的,为啥呢?
因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
②41 bit:表示的是时间戳,单位是毫秒。
41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
③10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),也可以根据自己公司的实际情况确定。
④12 bit:这个是用来记录同一个毫秒内产生的不同 id。
12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
简单来说,**你的某个服务假设要生成一个全局唯一 id,那么就可以发送一个请求给部署了 SnowFlake 算法的系统,由这个 SnowFlake 算法系统来生成唯一 id。**这个 SnowFlake 算法系统首先肯定是知道自己所在的机房和机器的,比如机房 id = 17,机器 id = 12。接着 SnowFlake 算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个 64 bit 的 long 型 id,64 个 bit 中的第一个 bit 是无意义的。接着 41 个 bit,就可以用当前时间戳(单位到毫秒),然后接着 5 个 bit 设置上这个机房 id,还有 5 个 bit 设置上机器 id。最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成 id 的请求累加一个序号,作为最后的 12 个 bit。最终一个 64 个 bit 的 id 就出来了
实现算法:
public class IdWorker {
//因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
//机器ID 2进制5位 32位减掉1位 31个
private long workerId;
//机房ID 2进制5位 32位减掉1位 31个
private long datacenterId;
//代表一毫秒内生成的多个id的最新序号 12位 4096 -1 = 4095 个
private long sequence;
//设置一个时间初始值 2^41 - 1 差不多可以用69年
private long twepoch = 1585644268888L;
//5位的机器id
private long workerIdBits = 5L;
//5位的机房id
private long datacenterIdBits = 5L;
//每毫秒内产生的id数 2 的 12次方
private long sequenceBits = 12L;
// 这个是二进制运算,就是5 bit最多只能有31个数字,也就是说机器id最多只能是32以内
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 这个是一个意思,就是5 bit最多只能有31个数字,机房id最多只能是32以内
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//记录产生时间毫秒数,判断是否是同1毫秒
private long lastTimestamp = -1L;
public long getWorkerId(){
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
public IdWorker(long workerId, long datacenterId, long sequence) {
// 检查机房id和机器id是否超过31 不能小于0
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(
String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(
String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
// 这个是核心方法,通过调用nextId()方法,让当前这台机器上的snowflake算法程序生成一个全局唯一的id
public synchronized long nextId() {
// 这儿就是获取当前时间戳,单位是毫秒
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf(
"clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
// 下面是说假设在同一个毫秒内,又发送了一个请求生成一个id
// 这个时候就得把seqence序号给递增1,最多就是4096
if (lastTimestamp == timestamp) {
// 这个意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,
//这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围
sequence = (sequence + 1) & sequenceMask;
//当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生ID
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
// 这儿记录一下最近一次生成id的时间戳,单位是毫秒
lastTimestamp = timestamp;
// 这儿就是最核心的二进制位运算操作,生成一个64bit的id
// 先将当前时间戳左移,放到41 bit那儿;将机房id左移放到5 bit那儿;将机器id左移放到5 bit那儿;将序号放最后12 bit
// 最后拼接起来成一个64 bit的二进制数字,转换成10进制就是个long型
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) | sequence;
}
/**
* 当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生ID
* @param lastTimestamp
* @return
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取当前时间戳
private long timeGen(){
return System.currentTimeMillis();
}
/**
* main 测试类
* @param args
*/
public static void main(String[] args) {
System.out.println(1&4596);
System.out.println(2&4596);
System.out.println(6&4596);
System.out.println(6&4596);
System.out.println(6&4596);
System.out.println(6&4596);
// IdWorker worker = new IdWorker(1,1,1);
// for (int i = 0; i < 22; i++) {
// System.out.println(worker.nextId());
// }
}
}
SnowFlake算法的优点:
(1)高性能高可用:生成时不依赖于数据库,完全在内存中生成。
(2)容量大:每秒中能生成数百万的自增ID。
(3)ID自增:存入数据库中,索引效率高。
SnowFlake算法的缺点:
依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成id冲突或者重复。
IM系统
从三个方面来阐述如何构建一个完整可靠的IM系统
- 可靠性
- 安全性
- 存储设计
内容概述
首先讲讲IM(即时通讯)技术可以用来做什么:
1)聊天:qq、微信;
2)直播:斗鱼直播、抖音;
3)实时位置共享、游戏多人互动等等。
可以说几乎所有高实时性的应用场景都需要用到IM技术。
我们搭建的IM服务端实现以下功能:
1)一对一的文本消息、文件消息通信;
2)每个消息有“已发送”/“已送达”/“已读”回执;
3)存储离线消息;
4)支持用户登录,好友关系等基本功能;
5)能够方便地水平扩展。
后端:
1)rpc通信;
2)数据库;
3)缓存;
4)消息队列;
5)分布式、高并发的架构设计;
6)docker部署。
消息通信
文本消息
我们先从最简单的特性开始实现:一个普通消息的发送。
消息格式如下:
message ChatMsg{
id= 1; //消息id
fromId = Alic; //发送者userId
destId = Bob; //接收者userId
msgBody = hello; //消息体
}
如上图,我们现在有两个用户:Alice和Bob连接到了服务器,当Alice发送消息message(hello)给Bob,服务端接收到消息,根据消息的destId进行转发,转发给Bob。
发送回执
那我们要怎么来实现回执的发送呢?
我们定义一种回执数据格式ACK,MsgType有三种,分别是sent(已发送),delivered(已送达), read(已读)
消息格式如下:
message AckMsg {
id; //消息id
fromId; //发送者id
destId; //接收者id
msgType; //消息类型
ackMsgId; //确认的消息id
}
enum MsgType {
SENT
DELIVERED;
READ;
}
当服务器接收到Alice发来的消息时:
1.向Alice发送一个sent(hello)表示消息已经被发送到服务器
message AckMsg {
id= 2;
fromId = Alice;
destId = Bob;
msgType = SENT;
ackMsgId = 1;
}
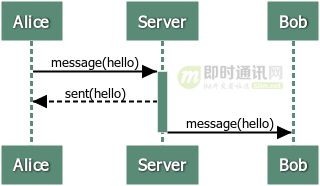
2.服务器把hello转发给Bob后,立刻向Alice发送delivered(hello)表示消息已经发送给Bob:
message AckMsg {
id= 3;
fromId = Bob;
destId = Alice;
msgType = DELIVERED;
ackMsgId = 1;
}
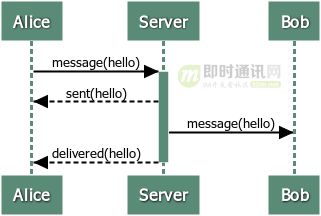
3.Bob阅读消息后,客户端向服务器发送read(hello)表示消息已读:
message AckMsg {
id= 4;
fromId = Bob;
destId = Alice;
msgType = READ;
ackMsgId = 1;
}
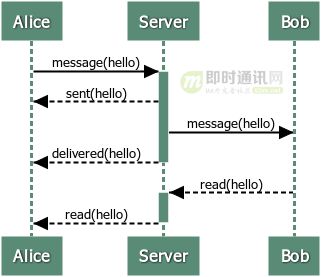
这个消息会像一个普通聊天消息一样被服务器处理,最终发送给Alice。在服务器这里不区分ChatMsg和AckMsg,处理过程都是一样的:解析消息的destId并进行转发。
水平扩展
当用户量越来越大,必然需要增加服务器的数量,用户的连接被分散在不同的机器上。此时,就需要存储用户连接在哪台机器上。我们引入一个新的模块来管理用户的连接信息。
管理用户状态
 】
】
模块叫做user status,共有三个接口:
public interface UserStatusService {
/**
* 用户上线,存储userId与机器id的关系
* @param userId
* @param connectorId
* @return 如果当前用户在线,则返回他连接的机器id,否则返回null
*/
String online(String userId, String connectorId);
/**
* 用户下线
* @param userId
*/
voidoffline(String userId);
/**
* 通过用户id查找他当前连接的机器id
* @param userId
* @return
*/
String getConnectorId(String userId);
}
这样我们就能够对用户连接状态进行管理了,具体的实现应考虑服务的用户量、期望性能等进行实现。此处我们使用redis来实现,将userId和connectorId的关系以key-value的形式存储。
消息转发
除此之外,还需要一个模块在不同的机器上转发消息,如下结构:
此时我们的服务被拆分成了connector和transfer两个模块,connector模块用于维持用户的长链接,而transfer的作用是将消息在多个connector之间转发。现在Alice和Bob连接到了两台connector上,那么消息要如何传递呢?
1)Alice上线,连接到机器[1]上时:
1.1)将Alice和它的连接存入内存中。
1.2)调用user status的online方法记录Alice上线。
2)Alice发送了一条消息给Bob:
2.1)机器[1]收到消息后,解析destId,在内存中查找是否有Bob。
2.2)如果没有,代表Bob未连接到这台机器,则转发给transfer。
3)transfer调用user status的getConnectorId(Bob)方法找到Bob所连接的connector,返回机器[2],则转发给机器[2]。
流程图:
4.3 总结
引入user status模块管理用户连接,transfer模块在不同的机器之间转发,使服务可以水平扩展。为了满足实时转发,transfer需要和每台connector机器都保持长链接。
离线消息
如果用户当前不在线,就必须把消息持久化下来,等待用户下次上线再推送,这里使用mysql存储离线消息。
为了方便地水平扩展,我们使用消息队列进行解耦:
1)transfer接收到消息后如果发现用户不在线,就发送给消息队列入库;
2)用户登录时,服务器从库里拉取离线消息进行推送。
用户登录、好友关系
用户的注册登录、账户管理、好友关系链等功能更适合使用http协议,因此我们将这个模块做成一个restful服务,对外暴露http接口供客户端调用。
至此服务端的基本架构就完成了:
可靠性
什么是可靠性?对于一个IM系统来说,可靠的定义至少是不丢消息、消息不重复、不乱序,满足这三点,才能说有一个好的聊天体验。
不丢消息
- 服务端架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FOst1HmK-1661411816895)(https://mmbiz.qpic.cn/mmbiz/R3InYSAIZkE4TxXsyEdruHlAUNSDtT30tkNyickiaRgGicvfPZdYIWibXqkaFXWu1mHbRV2IN9tGlgV5sWkbxHG3Rw/640?wx_fmt=other)]
我们先从一个简单例子开始思考:当Alice给Bob发送一条消息时,可能要经过这样一条链路:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NIqAMACk-1661411816895)(https://mmbiz.qpic.cn/mmbiz/R3InYSAIZkE4TxXsyEdruHlAUNSDtT30HOZaYu7kRVh6gjdUVtWhjEtHpHGEoCQNc4zfxibVick8icGF0n7XHDjmA/640?wx_fmt=other)]
route
- client–>connecter
- connector–>transfer
- transfer–>connector
- connector–>client
在这整个链路中的每个环节都有可能出问题,虽然tcp协议是可靠的,但是它只能保证链路层的可靠,无法保证应用层的可靠。
例如在第一步中,connector收到了从client发出的消息,但是转发给transfer失败,那么这条消息Bob就无法收到,而Alice也不会意识到消息发送失败了。
如果Bob状态是离线,那么消息链路就是:
- client–>connector
- connector–>transfer
- transfer–>mq
如果在第三步中,transfer收到了来自connector的消息,但是离线消息入库失败, 那么这个消息也是传递失败了。为了保证应用层的可靠,我们必须要有一个ack机制,使发送方能够确认对方收到了这条消息。
具体的实现,我们模仿tcp协议做一个应用层的ack机制。
tcp的报文是以字节(byte)为单位的,而我们以message单位。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0u0oyHrB-1661411816896)(https://mmbiz.qpic.cn/mmbiz/R3InYSAIZkE4TxXsyEdruHlAUNSDtT30qPL31lHYDgvzueAVIGibc7gzKQfuxqvGNakvnehQsc0NJ0ydqEXuicicg/640?wx_fmt=other)]
ack
发送方每次发送一个消息,就要等待对方的ack回应,在ack确认消息中应该带有收到的id以便发送方识别。
**其次,发送方需要维护一个等待ack的队列。**每次发送一个消息之后,就将消息和一个计时器入队。
另外存在一个线程一直轮询队列,如果有超时未收到ack的,就取出消息重发。
超时未收到ack的消息有两种处理方式:
- 和tcp一样不断发送直到收到ack为止。
- 设定一个最大重试次数,超过这个次数还没收到ack,就使用失败机制处理,节约资源。例如如果是
connector长时间未收到client的ack,那么可以主动断开和客户端的连接,剩下未发送的消息就作为离线消息入库,客户端断连后尝试重连服务器即可。
接收方收到消息后完整的处理流程如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YqJMIP0f-1661411816897)(https://mmbiz.qpic.cn/mmbiz/R3InYSAIZkE4TxXsyEdruHlAUNSDtT30F85y0YyfNmV9fxPf9NuQls7KFU1EfxTgNC9an5u86fCVK8LWBwQFAg/640?wx_fmt=other)]
安全性
无论是聊天记录还是离线消息,肯定都会在服务端存储备份,那么消息的安全性,保护客户的隐私也至关重要。**因此所有的消息都必须要加密处理。**在存储模块里,维护用户信息和关系链有两张基础表,分别是im_user用户表和im_relation关系链表。
im_user表用于存放用户常规信息,例如用户名密码等,结构比较简单。im_relation表用于记录好友关系,结构如下:
CREATE TABLE `im_relation` (
`id` bigint(20) COMMENT '关系id',
`user_id1` varchar(100) COMMENT '用户1id',
`user_id2` varchar(100) COMMENT '用户2id',
`encrypt_key` char(33) COMMENT 'aes密钥',
`gmt_create` timestamp DEFAULT CURRENT_TIMESTAMP,
`gmt_update` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `USERID1_USERID2` (`user_id1`,`user_id2`)
);
user_id1和user_id2是互为好友的用户id,为了避免重复,存储时按照user_id1<user_id2的顺序存,并且加上联合索引。encrypt_key是随机生成的密钥。当客户端登录时,就会从数据库中获取该用户的所有的relation,存在内存中,以便后续加密解密。- 当客户端给某个好友发送消息时,取出内存中该关系的密钥,加密后发送。同样,当收到一条消息时,取出相应的密钥解密。
客户端完整登录流程如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GyfbncCX-1661411816897)(https://mmbiz.qpic.cn/mmbiz/R3InYSAIZkE4TxXsyEdruHlAUNSDtT30cYx77EAwhoMPiarv2eBoQRVEFpzYc862U5UgC8CbDS7mdfPGJvPibSibg/640?wx_fmt=other)]
- client调用rest接口登录。
- client调用rest接口获取该用户所有
relation。 - client向connector发送greet消息,通知上线。
- connector拉取离线消息推送给client。
- connector更新用户session。
那为什么connector要先推送离线消息再更新session呢?我们思考一下如果顺序倒过来会发生什么:
- 用户
Alice登录服务器 connector更新session- 推送离线消息
- 此时Bob发送了一条消息给Alice
如果离线消息还在推送的过程中,Bob发送了新消息给Alice,服务器获取到Alice的session,就会立刻推送。这时新消息就有可能夹在一堆离线消息当中推过去了,那这时,Alice收到的消息就乱序了。
而我们必须保证离线消息的顺序在新消息之前。
那么如果先推送离线消息,之后才更新session。在离线消息推送的过程中,Alice的状态就是“未上线”,这时Bob新发送的消息只会入库im_offline,im_offline表中的数据被读完之后才会“上线”开始接受新消息。这也就避免了乱序。
存储设计
存储离线消息
当用户不在线时,离线消息必然要存储在服务端,等待用户上线再推送。理解了上一个小节后,离线消息的存储就非常容易了。增加一张离线消息表im_offline,表结构如下:
CREATE TABLE `im_offline` (
`id` int(11) COMMENT '主键',
`msg_id` bigint(20) COMMENT '消息id',
`msg_type` int(2) COMMENT '消息类型',
`content` varbinary(5000) COMMENT '消息内容',
`to_user_id` varchar(100) COMMENT '收件人id',
`has_read` tinyint(1) COMMENT '是否阅读',
`gmt_create` timestamp COMMENT '创建时间',
PRIMARY KEY (`id`)
);
msg_type用于区分消息类型(chat,ack),content加密后的消息内容以byte数组的形式存储。用户上线时按照条件to_user_id=用户id拉取记录即可。
防止离线消息重复推送
我们思考一下多端登录的情况,Alice有两台设备同时登陆,在这种并发的情况下,我们就需要某种机制来保证离线消息只被读取一次。
这里利用CAS机制来实现:
- 首先取出所有
has_read=false的字段。 - 检查每条消息的
has_read值是否为false,如果是,则改为true。这是原子操作。
update im_offline set has_read = true where id = ${msg_id} and has_read = false
- 修改成功则推送,失败则不推送。
相信到这里,同学们已经可以自己动手搭建一个完整可用的IM服务端了。更多问题欢迎评论区留言~~
Netty
netty的优点:
- 并发高
- 传输快
- 封装好
Netty为什么并发高
Netty是一款基于NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架,对比于BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高。
当一个连接建立之后,他有两个步骤要做,第一步是接收完客户端发过来的全部数据,第二步是服务端处理完请求业务之后返回response给客户端。NIO和BIO的区别主要是在第一步。
在BIO中,等待客户端发数据这个过程是阻塞的,这样就造成了一个线程只能处理一个请求的情况,而机器能支持的最大线程数是有限的,这就是为什么BIO不能支持高并发的原因。
而NIO中,当一个Socket建立好之后,Thread并不会阻塞去接受这个Socket,而是将这个请求交给Selector,Selector会不断的去遍历所有的Socket,一旦有一个Socket建立完成,他会通知Thread,然后Thread处理完数据再返回给客户端——这个过程是不阻塞的,这样就能让一个Thread处理更多的请求了。
Netty为什么传输快
Netty的传输快其实也是依赖了NIO的一个特性——零拷贝。我们知道,Java的内存有堆内存、栈内存和字符串常量池等等,其中堆内存是占用内存空间最大的一块,也是Java对象存放的地方,一般我们的数据如果需要从IO读取到堆内存,中间需要经过Socket缓冲区,也就是说一个数据会被拷贝两次才能到达他的的终点,如果数据量大,就会造成不必要的资源浪费。
Netty针对这种情况,使用了NIO中的另一大特性——零拷贝,当他需要接收数据的时候,他会在堆内存之外开辟一块内存,数据就直接从IO读到了那块内存中去,在netty里面通过ByteBuf可以直接对这些数据进行直接操作,从而加快了传输速度。
传统数据拷贝
零拷贝
为什么说Netty封装好
channel
数据传输流,与channel相关的概念有以下四个,
Channel,表示一个连接,可以理解为每一个请求,就是一个Channel。
ChannelHandler,核心处理业务就在这里,用于处理业务请求。
ChannelHandlerContext,用于传输业务数据。
ChannelPipeline,用于保存处理过程需要用到的ChannelHandler和ChannelHandlerContext。
ByteBuf
- ByteBuf是一个存储字节的容器,最大特点就是使用方便,它既有自己的读索引和写索引,方便你对整段字节缓存进行读写,也支持get/set,方便你对其中每一个字节进行读写,他的数据结构如下图所示:

ByteBuf数据结构
他有三种使用模式:
-
Heap Buffer 堆缓冲区
堆缓冲区是ByteBuf最常用的模式,他将数据存储在堆空间。 -
Direct Buffer 直接缓冲区
直接缓冲区是ByteBuf的另外一种常用模式,他的内存分配都不发生在堆,jdk1.4引入的nio的ByteBuffer类允许jvm通过本地方法调用分配内存,这样做有两个好处
- 通过免去中间交换的内存拷贝, 提升IO处理速度; 直接缓冲区的内容可以驻留在垃圾回收扫描的堆区以外。
- DirectBuffer 在 -XX:MaxDirectMemorySize=xxM大小限制下, 使用 Heap 之外的内存, GC对此”无能为力”,也就意味着规避了在高负载下频繁的GC过程对应用线程的中断影响.
-
Composite Buffer 复合缓冲区
复合缓冲区相当于多个不同ByteBuf的视图,这是netty提供的,jdk不提供这样的功能。
Codec
Netty中的编码/解码器,通过他你能完成字节与pojo、pojo与pojo的相互转换,从而达到自定义协议的目的。
在Netty里面最有名的就是HttpRequestDecoder和HttpResponseEncoder了。
超时、心跳机制、断线重连
为断线重连需要考虑两种情况
- 客户端启动时,服务器端还未启动或已崩掉,需要客户端自动不断发起连接,而不是退出程序
- 服务器端正常,但客户端断开连接,这时也需要自动发起重新连接请求
断线重连的步骤:
- 客户端的连接由同步阻塞改为异步阻塞
- 创建监听类,该类实现ChannelFutureListener接口,在该类中发起重连。
- 在ChannelFuture的实例中增加监听,把我们自定义的监听类添加进去。
超时检测:
超时分三种:读超时,写超时,读写超时
Netty中实现超时检测相当方便,只需要两步工作就能优雅的实现超时检测(客户端,服务端实现步骤一样)
1.在Handler中重写userEventTriggered方法
2.在pipeline中增加IdleStatehandler实例,该实例的构造函数有4个:
- readerIdleTime:读超时,设置为0是,表示不启用
- writeIdleTime:写超时,设置为0是,表示不启用
- allIdleTime:读写超时,设置为0是,表示不启用
- TimeUnit:时间单位,该参数可不设置,默认是秒
ChannelPipeline ChannelHandler ChannelHandlerContext
ChannelHandler,ChannelHandlerContext,ChannelPipeline这三者的关系很特别,相辅相成,一个ChannelPipeline中可以有多个ChannelHandler实例,而每一个ChannelHandler实例与ChannelPipeline之间的桥梁就是ChannelHandlerContext实例,如图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vcPcfzVc-1661411816901)(https://segmentfault.com/img/bVbDQnD/view)]
Channel初始化时,会创建一个ChannelPipeline,ChannelPipeline内部维护这HeadContext和TailContext,ChannelPipeline会添加多个ChannelHandler时,会把ChannelHandler包装成HandlerContext,再与现有的双向链表连接起来。
具体见这篇文章
Netty是什么
Netty 是一个 基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。它极大地简化并优化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。支持多种协议 如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。用官方的总结就是:Netty 成功地找到了一种在不妥协可维护性和性能的情况下实现易于开发,性能,稳定性和灵活性的方法。
Netty的优点
- 统一的 API,支持多种传输类型,阻塞和非阻塞的。
- 简单而强大的线程模型。
- 自带编解码器解决 TCP 粘包/拆包问题。
- 自带各种协议栈。
- 真正的无连接数据包套接字支持。
- 比直接使用 Java 核心 API 有更高的吞吐量、更低的延迟、更低的资源消耗和更少的内存复制。
- 安全性不错,有完整的 SSL/TLS 以及 StartTLS 支持。
- 社区活跃成熟稳定,经历了大型项目的使用和考验,而且很多开源项目都使用到了 Netty, 比如我们经常接触的 Dubbo、RocketMQ 等等。
Netty应用场景
Netty主要用来做网络通信
- 作为RPC框架的网络通信工具
- 实现一个自己的HTTP服务器
- 实现一个即时通讯系统
- 实现消息通讯系统
Netty的核心组件
-
Channel
Channel 接口是 Netty 对网络操作抽象类,它除了包括基本的 I/O 操作,如 bind()、connect()、read()、write() 等。
比较常用的Channel接口实现类是NioServerSocketChannel(服务端)和NioSocketChannel(客户端),这两个 Channel 可以和 BIO 编程模型中的ServerSocket以及Socket两个概念对应上。Netty 的 Channel 接口所提供的 API,大大地降低了直接使用 Socket 类的复杂性。
-
EventLoop
EventLoop 的主要作用实际就是负责监听网络事件并调用事件处理器进行相关 I/O 操作的处理。
Channel 为 Netty 网络操作(读写等操作)抽象类,EventLoop 负责处理注册到其上的Channel 处理 I/O 操作,两者配合参与 I/O 操作。
-
ChannelFuture
Netty 是异步非阻塞的,所有的 I/O 操作都为异步的。
因此,我们不能立刻得到操作是否执行成功,但是,你可以通过 ChannelFuture 接口的 addListener() 方法注册一个 ChannelFutureListener,当操作执行成功或者失败时,监听就会自动触发返回结果。
并且,你还可以通过ChannelFuture 的 channel() 方法获取关联的Channel
另外,我们还可以通过 ChannelFuture 接口的 sync()方法让异步的操作变成同步的。
-
ChannelHandler和ChannelPipeline
ChannelHandler 是消息的具体处理器。他负责处理读写操作、客户端连接等事情。
ChannelPipeline 为 ChannelHandler 的链,提供了一个容器并定义了用于沿着链传播入站和出站事件流的 API 。当 Channel 被创建时,它会被自动地分配到它专属的 ChannelPipeline。
我们可以在 ChannelPipeline 上通过 addLast() 方法添加一个或者多个ChannelHandler ,因为一个数据或者事件可能会被多个 Handler 处理。当一个 ChannelHandler 处理完之后就将数据交给下一个 ChannelHandler 。
-
Bootstrap和ServerBootstrap
Bootstrap 是客户端的启动引导类/辅助类,具体使用方法如下:
EventLoopGroup group=new NioEventLoopGroup(); //I/O线程池 try { Bootstrap bs=new Bootstrap(); //客服端辅助启动类 bs.group(group) .channel(NioSocketChannel.class) //实例化一个channel .remoteAddress(new InetSocketAddress(host,port)) .handler(new ChannelInitializer<SocketChannel>() { //进行通道channel初始化配置 @Override protected void initChannel(SocketChannel socketChannel) throws Exception { socketChannel.pipeline().addLast(new ClinetHelloHandler()); //添加自定义的Handler } }); //连接到远端;等待连接完成 ChannelFuture future=bs.connect().sync(); //发送消息到服务器段,编码格式是utf-8 future.channel().writeAndFlush(Unpooled.copiedBuffer("Hello world", CharsetUtil.UTF_8)); //阻塞操作,closeFuture()开启了一个channel的监听器(这期间channel在进行各项工作),直到链路断开 future.channel().closeFuture().sync(); }finally { group.shutdownGracefully().sync(); }ServerBootstrap 客户端的启动引导类/辅助类,具体使用方法如下:
EventLoopGroup group=new NioEventLoopGroup(); //Netty的Reactor线程池,初始化了一个NioEventLoop数组 try { ServerBootstrap b=new ServerBootstrap(); //用于启动NIO服务 b.group(group) .channel(NioServerSocketChannel.class) //通过工厂方法设计模式实例化一个Channel .localAddress(new InetSocketAddress(port)) //设置监听端口 .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel socketChannel) throws Exception { socketChannel.pipeline().addLast(new ServerHelloHandler()); } }); //绑定服务器,该实例将提供有关I/O操作的结果或状态的信息 ChannelFuture channelFuture=b.bind().sync(); System.out.println("在"+channelFuture.channel().localAddress()+"上开启监听"); //阻塞操作,closeFuture()开启了一个Channel的监听器(这期间Channel在进行各项工作),直到链路断开 channelFuture.channel().closeFuture().sync(); }finally { group.shutdownGracefully().sync(); }
BioEventLoopGroup默认的构造函数会起多少线程
NioEventLoopGroup 默认的构造函数实际会起的线程数为 CPU核心数*2。
Netty线程模型
大部分网络框架都是基于 Reactor 模式设计开发的。
“Reactor 模式基于事件驱动,采用多路复用将事件分发给相应的 Handler 处理,非常适合处理海量 IO 的场景。
在 Netty 主要靠 NioEventLoopGroup 线程池来实现具体的线程模型的 。
我们实现服务端的时候,一般会初始化两个线程组:
bossGroup :接收连接。
workerGroup :负责具体的处理,交由对应的 Handler 处理。下面我们来详细看一下 Netty 中的线程模型吧!
- 单线程模型
一个线程需要执行处理所有的 accept、read、decode、process、encode、send 事件。对于高负载、高并发,并且对性能要求比较高的场景不适用。
//1.eventGroup既用于处理客户端连接,又负责具体的处理。
EventLoopGroup eventGroup = new NioEventLoopGroup(1); //2.创建服务端启动引导/辅助类:
ServerBootstrap ServerBootstrap b = new ServerBootstrap();
boobtstrap.group(eventGroup, eventGroup) //......
- 多线程模型
一个 Acceptor 线程只负责监听客户端的连接,一个 NIO 线程池负责具体处理:accept、read、decode、process、encode、send 事件。满足绝大部分应用场景,并发连接量不大的时候没啥问题,但是遇到并发连接大的时候就可能会出现问题,成为性能瓶颈。
// 1.bossGroup 用于接收连接,workerGroup 用于具体的处理
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
//2.创建服务端启动引导/辅助类:
ServerBootstrap ServerBootstrap b = new ServerBootstrap();
//3.给引导类配置两大线程组,确定了线程模型
b.group(bossGroup, workerGroup)
//......
}

-
主从多线程模型
从一个 主线程 NIO 线程池中选择一个线程作为 Acceptor 线程,绑定监听端口,接收客户端连接的连接,其他线程负责后续的接入认证等工作。连接建立完成后,Sub NIO 线程池负责具体处理 I/O 读写。如果多线程模型无法满足你的需求的时候,可以考虑使用主从多线程模型 。
// 1.bossGroup 用于接收连接,workerGroup 用于具体的处理 EventLoopGroup bossGroup = new NioEventLoopGroup(); EventLoopGroup workerGroup = new NioEventLoopGroup(); try { //2.创建服务端启动引导/辅助类: ServerBootstrap ServerBootstrap b = new ServerBootstrap(); //3.给引导类配置两大线程组,确定了线程模型 b.group(bossGroup, workerGroup) //...... }
Netty服务端和客服端的启动流程
- 服务端
// 1.bossGroup 用于接收连接,workerGroup 用于具体的处理
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
//2.创建服务端启动引导/辅助类:
ServerBootstrap ServerBootstrap b = new ServerBootstrap();
//3.给引导类配置两大线程组,确定了线程模型
// (非必备)打印日志
// 指定 IO 模型
b.group(bossGroup, workerGroup)
.handler(new LoggingHandler(LogLevel.INFO))
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>(){
@Override
public void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
//5.可以自定义客户端消息的业务处理逻辑
p.addLast(new HelloServerHandler());
}
}
);
// 6.绑定端口,调用 sync 方法阻塞知道绑定完成
ChannelFuture f = b.bind(port).sync();
// 7.阻塞等待直到服务器Channel关闭(closeFuture()方法获取Channel 的CloseFuture对象,然后调用sync()方法)
f.channel().closeFuture().sync();
} finally
{
//8.优雅关闭相关线程组资源
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
具体流程:
-
1.首先你创建了两个 NioEventLoopGroup 对象实例:bossGroup 和 workerGroup。
bossGroup : 用于处理客户端的 TCP 连接请求。
workerGroup :负责每一条连接的具体读写数据的处理逻辑,真正负责 I/O 读写操作,交由对应的 Handler 处理。
一般情况下我们会指定 bossGroup 的 线程数为 1(并发连接量不大的时候) ,workGroup 的线程数量为 CPU 核心数 *2 。
-
2.接下来 我们创建了一个服务端启动引导/辅助类:ServerBootstrap,这个类将引导我们进行服务端的启动工作。
-
3.通过 .group() 方法给引导类 ServerBootstrap 配置两大线程组,确定了线程模型。
-
4.通过channel()方法给引导类 ServerBootstrap指定了 IO 模型为NIO
NioServerSocketChannel :指定服务端的 IO 模型为 NIO,与 BIO 编程模型中的ServerSocket对应
NioSocketChannel : 指定客户端的 IO 模型为 NIO, 与 BIO 编程模型中的Socket对应
-
5.通过 .childHandler()给引导类创建一个ChannelInitializer ,然后制定了服务端消息的业务处理逻辑 HelloServerHandler 对象
-
6.调用 ServerBootstrap 类的 bind()方法绑定端口
-
客户端
//1.创建一个 NioEventLoopGroup 对象实例
EventLoopGroup group = new NioEventLoopGroup();
try {
//2.创建客户端启动引导/辅助类:
Bootstrap Bootstrap b = new Bootstrap();
//3.指定线程组
//4.指定 IO 模型
b.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<SocketChannel>()
{
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
// 5.这里可以自定义消息的业务处理逻辑
p.addLast(new HelloClientHandler(message));
}
});
// 6.尝试建立连接
ChannelFuture f = b.connect(host, port).sync();
// 7.等待连接关闭(阻塞,直到Channel关闭)
f.channel().closeFuture().sync();
}
finally {
group.shutdownGracefully();
}
继续分析一下客户端的创建流程:
1.创建一个 NioEventLoopGroup 对象实例
2.创建客户端启动的引导类是 Bootstrap
3.通过 .group() 方法给引导类 Bootstrap 配置一个线程组
4.通过channel()方法给引导类 Bootstrap指定了 IO 模型为NIO
5.通过 .childHandler()给引导类创建一个ChannelInitializer ,然后制定了客户端消息的业务处理逻辑 HelloClientHandler 对象
6.调用 Bootstrap 类的 connect()方法进行连接,这个方法需要指定两个参数:inetHost : ip 地址inetPort : 端口号
connect 方法返回的是一个 Future 类型的对象
也就是说这个方是异步的,我们通过 addListener 方法可以监听到连接是否成功,进而打印出连接信息。具体做法很简单,只需要对代码进行以下改动:
ChannelFuture f = b.connect(host, port).addListener(future -> {
if (future.isSuccess()){
System.out.println("连接成功!");
}else{
System.err.println("连接失败!");
}
}).sync();
Netty解决粘包/拆包问题
使用Netty自带的解码器
- LineBasedFrameDecoder : 发送端发送数据包的时候,每个数据包之间以换行符作为分隔,LineBasedFrameDecoder 的工作原理是它依次遍历 ByteBuf 中的可读字节,判断是否有换行符,然后进行相应的截取。
- DelimiterBasedFrameDecoder : 可以自定义分隔符解码器,LineBasedFrameDecoder 实际上是一种特殊的 DelimiterBasedFrameDecoder 解码器。
- FixedLengthFrameDecoder: 固定长度解码器,它能够按照指定的长度对消息进行相应的拆包。
- LengthFieldBasedFrameDecoder:
自定义序列化编解码器
在 Java 中自带的有实现 Serializable 接口来实现序列化,但由于它性能、安全性等原因一般情况下是不会被使用到的。
通常情况下,我们使用 Protostuff、Hessian2、json 序列方式比较多,另外还有一些序列化性能非常好的序列化方式也是很好的选择:
Netty长连接 心跳机制
-
TCP长连接和短链接
我们知道 TCP 在进行读写之前,server 与 client 之间必须提前建立一个连接。建立连接的过程,需要我们常说的三次握手,释放/关闭连接的话需要四次挥手。这个过程是比较消耗网络资源并且有时间延迟的。
所谓,短连接说的就是 server 端 与 client 端建立连接之后,读写完成之后就关闭掉连接,如果下一次再要互相发送消息,就要重新连接。短连接的有点很明显,就是管理和实现都比较简单,缺点也很明显,每一次的读写都要建立连接必然会带来大量网络资源的消耗,并且连接的建立也需要耗费时间。
长连接说的就是 client 向 server 双方建立连接之后,即使 client 与 server 完成一次读写,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。长连接的可以省去较多的 TCP 建立和关闭的操作,降低对网络资源的依赖,节约时间。对于频繁请求资源的客户来说,非常适用长连接。
-
心跳机制
在 TCP 保持长连接的过程中,可能会出现断网等网络异常出现,异常发生的时候, client 与 server 之间如果没有交互的话,它们是无法发现对方已经掉线的。为了解决这个问题, 我们就需要引入 心跳机制。
心跳机制的工作原理是: 在 client 与 server 之间在一定时间内没有数据交互时, 即处于 idle 状态时, 客户端或服务器就会发送一个特殊的数据包给对方, 当接收方收到这个数据报文后, 也立即发送一个特殊的数据报文, 回应发送方, 此即一个 PING-PONG 交互。所以, 当某一端收到心跳消息后, 就知道了对方仍然在线, 这就确保 TCP 连接的有效性.
TCP 实际上自带的就有长连接选项,本身是也有心跳包机制,也就是 TCP 的选项:SO_KEEPALIVE。但是,TCP 协议层面的长连接灵活性不够。所以,一般情况下我们都是在应用层协议上实现自定义心跳机制的,也就是在 Netty 层面通过编码实现。通过 Netty 实现心跳机制的话,核心类是 IdleStateHandler 。
Netty的零拷贝
“零复制(英语:Zero-copy;也译零拷贝)技术是指计算机执行操作时,CPU 不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。
在 OS 层面上的 Zero-copy 通常指避免在 用户态(User-space) 与 内核态(Kernel-space) 之间来回拷贝数据。而在 Netty 层面 ,零拷贝主要体现在对于数据操作的优化。
Netty 中的零拷贝体现在以下几个方面:
- 使用 Netty 提供的 CompositeByteBuf 类, 可以将多个ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝。
- ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝。
- 通过 FileRegion 包装的FileChannel.tranferTo 实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题.