跑实验_word2vector词向量实现_基于搜狗新闻预料+维基百科
这篇博客只是记录一下如何解决 跑别人的代码没通的过程。
文章目录
- 1 运行代码
- 0设备环境
- 1.获取语料库
- 2.语料库预处理
- 3.训练
- 4.开动!使用词向量
- 近义词
- 获取某个词语的词向量
- 计算句子相似度
- 词向量加减运算
- 选出集合中不同类的词语
- 2总结一下经验
- 3补充
1 运行代码
最经在学CS224课程,理论上了解了一个大概,但是仍然没什么感觉,想要跑一跑word2vecd代码,于是在g站找到了下面这个仓库:中文word2vector词向量实现
0设备环境
台式机 AMD 3600X CPU @ 3.80GHz × 12 , 8G RAM
ubuntu18.04LTS 独立系统,
python 3.6.1
依赖:numpy, scipy, gensim, opencc, jieba
1.获取语料库
1.1维基百科【直接下载】
下载地址https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
原始语料文件:zhwiki-latest-pages-articles.xml.bz2 2.1G
1.2 SogouCA 全网新闻数据(SogouCA)【需要实名获取数据,网络资源也不太好找】
官方下载地址http://www.sogou.com/labs/resource/ca.php
原始语料文件:‘news_tensite_xml.full.tar.gz’ 746.3 M
2.语料库预处理
2.1 搜狗新闻语料处理
来自若干新闻站点2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL和正文信息 格式说明: 数据格式为 页面URL 页面ID 页面标题 页面内容 注意:content字段去除了HTML标签,保存的是新闻正文文本
刚下下来的语料是用gbk编码的,在mac或linux上都会呈乱码形式,需要将之转换为utf-8编码。而且我们只需要里面的内容。因此先转换编码和获取content内容
cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "" > corpus.sogou.txt
(有的网友可能直接给出了tensite_xml.dat文件,我曾在网盘中见过)
生成 corpus.sogou.txt 1.9 2.2G 分词-用空格隔开 用时40分钟
python3 sogou_corpus_seg.py data/corpus.sogou.txt data/corpus_sogou_seg.txt
生成 corpus_sogou_seg.txt 2.22.6 G
2.2 维基百科语料处理
-gensim解析bz2语料
python3 parse_wiki_xml2txt.py data/zhwiki-latest-pages-articles.xml.bz2 data/corpus.zhwiki.txt
生成 corpus.zhwiki.txt 1.11.4 G 用时40分钟
简繁体转换(opencc) 把语料中的繁体转换成简体 用时1 分钟
我是在conda虚拟环境中安装opencc
sudo apt-get install opencc opencc -i data/corpus.zhwiki.txt -o data/corpus.zhwiki.simplified.txt -c ~~zht2zhs.ini~~
sudo apt-get install opencc opencc -i data/corpus.zhwiki.txt -o data/corpus.zhwiki.simplified.txt -c t2s.json
去除英文和空格 文档中还是有很多英文的,一般是文章的reference。里面还有些日文,罗马文等,这些对模型影响效果可以忽略, 只是简单的去除了空格和英文。用时1分钟
python3 remove_en_blank.py data/corpus.zhwiki.simplified.txt data/corpus.zhwiki.simplified.done.txt
生成 corpus.zhwiki.simplified.done.txt (1.4G)
分词 这里以空格做分割符 -d ’ ’
pip install jieba
python3 -m jieba -d ' ' data/corpus.zhwiki.simplified.done.txt > data/corpus_zhwiki_seg.txt
生成 corpus.zhwiki.seg.txt 1.4G 用时30分钟
2.3 将百科数据和搜狗数据和并到一个文件
用时2分钟
cat data/corpus_zhwiki_seg.txt data/corpus_sogou_seg.txt > data/corpus_seg.txt
此时我的data文件夹:
3.训练
python3 train_word2vec_model.py data/corpus_seg.txt model/word2vec.model model/corpus.vector
详细api参考:http://radimrehurek.com/gensim/models/word2vec.html
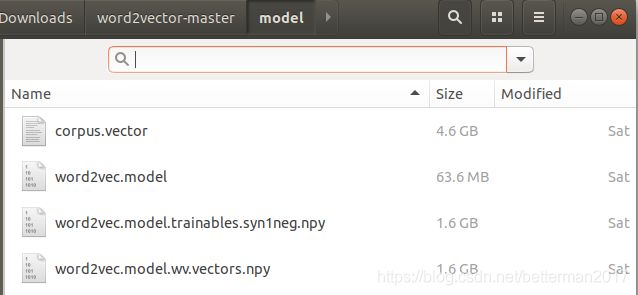
生成 word2vec.model 63.6M corpus.vector 4.6G 用时426分钟
就在这一步,每次训练完5个EPOCH我都保存不了模型!!!
报错的代码如下:
TypeError:file must have a ‘write’ attribute
以及
FileNotFoundError:[Errno 2] no such file or directory

仓库中的保存代码为:
inp为训练数据
outp1为保存可训练的、完整模型的路径
outp2为保存不可再训练的模型的路径
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5,
workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
toc = time.process_time()
print("\nComputation time = " + str((toc - tic)/60) + "min")
我尝试过一下方式:
- 将读写方式wb修改为w ,因为有一篇文字建议了这中方案,且报错提示对应的文件有个地方写了“wb is needed in windows”【不建议采用这种方式,万一改不回来就麻烦了】
- 将outp1改成如下形式–使用get_tmpfile函数,oupt2也是这个改法【这个方案开始也是报错no such file,后来可以采用】
from gensim.test.utils import get_tmpfile
path1 = get_tmpfile(outp1)
model.save(path1)
- 使用绝对路经:直接写
oupt1 = "/home/USERNAME/Downloads/word2vector-master/model/word2vec.model"
然而上面的方法都不奏效。
痛定思痛,找来外援。
原先的代码都是在Terminal运行,后来改完之后,能够在pycharm中使用run debug来运行,修改后主体代码如下:
if __name__ == '__main__':
tic = time.process_time()
program = os.path.basename('train_word2vec_model.py')
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# 改动1
# check and process input arguments
# if len(sys.argv) < 4:
# print(globals()['__doc__'] % locals())
# sys.exit(1)
# inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence('data/corpus_seg.txt'), size=400, window=5, min_count=5,
workers=multiprocessing.cpu_count())
#改动2
#path_model = "/home/surrender/Downloads/word2vector-master/model/word2vec.model"
path_model = get_tmpfile("/home/surrender/Downloads/word2vector-master/model/word2vec.model") #trainable
#model.save(path_model) #save the whole model
model.save(path_model)
#path_modelWV = "/home/surrender/Downloads/word2vector-master/model/corpus.vector"
path_modelWV = get_tmpfile("/home/surrender/Downloads/word2vector-master/model/corpus.vector") #untrainable
#model.wv.save(path_modelWV, binary=False)
model.wv.save_word2vec_format(path_modelWV, binary=False)
#model.wv.save_word2vec_format(outp2, binary=False) #https://blog.csdn.net/shuihupo/article/details/85156544
toc = time.process_time()
print("\nComputation time = " + str((toc - tic)/60) + "min")
debug的方式训练之后的日志如下:
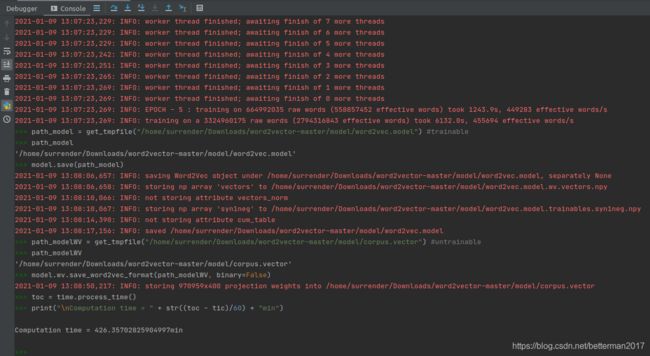
保存的模型文件为:
4.开动!使用词向量
在Terminal中输入python3 word2vec_test.py
效果还可以

如果是在pycharm中直接run就输入不了中文(暂未解决),效果如下:
/home/USERNAME/miniconda3/envs/nlp/bin/python /home/surrender/Downloads/word2vector-master/word2vec_test.py
请输入测试词:xuexiao
Process finished with exit code 137 (interrupted by signal 9: SIGKILL)
import gensim
model = gensim.models.Word2Vec.load(“model/word2vec.model”)
近义词
>>> import gensim
>>> model = gensim.models.Word2Vec.load("model/word2vec.model")
>>> model.most_similar(['淘宝'])
[('淘宝网', 0.7126708030700684), ('网店', 0.6056931614875793), ('天猫', 0.5621883273124695), ('网购', 0.5159996151924133), ('卖家', 0.510840654373169), ('当当', 0.4999154508113861), ('电商', 0.4877896308898926), ('当当网', 0.48619556427001953), ('京东', 0.4859452247619629), ('实体店', 0.4829680621623993)]
>>> model.most_similar(['法院'])
[('法庭', 0.6948547959327698), ('人民法院', 0.6690840125083923), ('法官', 0.6545068025588989), ('检察院', 0.6497205495834351), ('地方法院', 0.625424325466156), ('中级法院', 0.6127371788024902), ('中院', 0.6058658957481384), ('高院', 0.58973228931427), ('高等法院', 0.5886581540107727), ('区法院', 0.583966851234436)]
>>> model.most_similar(['小偷'])
[('窃贼', 0.6949888467788696), ('扒手', 0.6544720530509949), ('偷车贼', 0.6358408331871033), ('蟊贼', 0.6201199889183044), ('盗贼', 0.6131513118743896), ('醉汉', 0.6056065559387207), ('贼', 0.5937567353248596), ('骗子', 0.5754663944244385), ('歹徒', 0.5747430324554443), ('劫匪', 0.5714036226272583)]
获取某个词语的词向量
>>> print(model ['马云'])
[ 1.87035933e-01 1.01671422e+00 1.15123880e+00 2.93865710e-01
4.87820387e-01 -3.77443939e-01 -6.07039273e-01 1.24161768e+00
-3.89328241e-01 -2.65779853e-01 -1.06567919e+00 3.73572677e-01
...400维啊
计算句子相似度
参考了这里
这里使用的句子需要经过分词、去停用词这些基本操作
>>> sent1 = ['奇瑞', '新能源', '运营', '航天', '汽车', '平台', '城市', '打造', '技术', '携手']
>>> sent2 = ['新能源', '奇瑞', '新能源汽车', '致力于', '支柱产业', '整车', '汽车', '打造', '产业化', '产业基地']
>>> sent2 = ['新能源', '奇瑞', '汽车', '致力于', '支柱产业', '整车', '汽车', '打造', '产业化', '产业基地']
>>> print('sim1',model.wv.n_similarity(sent1,sent2))
sim1 0.8330718
词语相似度也能算,新闻预料不懂感情,测试效果一般:
>>> model.similarity("计算机", "电脑")
0.65988
>>> model.similarity("华夏", "中国")
0.20884971
>>> model.similarity("讨厌", "喜欢")
0.7446403
>>> model.similarity("爱", "喜欢")
0.5453164
词向量加减运算
用法:model.most_similar(positive=["", “”], negative=[""])
英文词类比中最有名的一个例子大概就是: king - man + woman = queen,即model.most_similar(positive=['woman', 'king'], negative=['man'])
试试中文版的:model.most_similar(positive=["国王","女"], negative=["男"])
[('王后', 0.5297636985778809), ('王室', 0.4960938096046448), ('摄政王', 0.49378159642219543), ('红衣主教', 0.4880385398864746), ('王储', 0.48675432801246643), ('君主', 0.48583078384399414), ('西吉斯蒙德', 0.48436546325683594), ('普密蓬', 0.47862792015075684), ('萨帕', 0.4706542193889618), ('查理一世', 0.46831080317497253)]
有的博客说这样的例子很少??也许是语料不够吧,请看:
>>> model.most_similar(positive=["中国","东京"], negative=["北京"])
[('日本', 0.609093427658081), ('亚洲', 0.4618649184703827), ('欧洲', 0.43291836977005005), ('美国', 0.4302576184272766), ('韩国', 0.42686909437179565), ('本国', 0.41886287927627563), ('俄罗斯', 0.3964774012565613), ('读卖新闻', 0.3759959936141968), ('印度', 0.37468191981315613), ('欧州', 0.37173062562942505)]
>>> model.most_similar(positive=["妈妈","男"], negative=["女"])
[('爸爸', 0.6887754201889038), ('奶奶', 0.5791643857955933), ('爸妈', 0.5388244390487671), ('爸爸妈妈', 0.5221832990646362), ('老爸', 0.5215718150138855), ('老公', 0.5198255777359009), ('母亲', 0.507635235786438), ('爷爷', 0.504549503326416), ('爸', 0.5041152834892273), ('老婆', 0.4923633933067322)]
>>> model.most_similar(positive=["丈夫","女"], negative=["男"])
[('妻子', 0.7030019760131836), ('母亲', 0.6272106170654297), ('父亲', 0.5711972713470459), ('女儿', 0.5403319001197815), ('前夫', 0.5340036749839783), ('家人', 0.5202281475067139), ('继女', 0.5151687264442444), ('父母', 0.51038658618927), ('未婚夫', 0.5073105692863464), ('前妻', 0.4995160698890686)]
>>> model.most_similar(positive=["外公","女"], negative=["男"])
[('外婆', 0.6082624793052673), ('侄女', 0.5652750730514526), ('祖母', 0.564604640007019), ('外甥女', 0.5449337959289551), ('孙女', 0.5420289039611816), ('母亲', 0.5396161079406738), ('婶婶', 0.5352175235748291), ('伯母', 0.5309367775917053), ('姑姑', 0.5293379426002502), ('养母', 0.5272255539894104)]
>>> model.most_similar(positive=["小偷","贩毒"], negative=["偷盗"])
[('毒犯', 0.49822568893432617), ('毒贩', 0.49750933051109314), ('毒枭', 0.48657774925231934), ('扒手', 0.4452968239784241), ('贩毒集团', 0.4351158142089844), ('逃犯', 0.41847944259643555), ('毒友', 0.4097750782966614), ('偷车贼', 0.40736186504364014), ('贩毒分子', 0.40410715341567993), ('瘾君子', 0.40168657898902893)]
也有翻车的
model.most_similar(positive=["杨过","女"], negative=["男"])
[('张无忌', 0.6441185474395752), ('周伯通', 0.6398254632949829), ('郭靖', 0.6373114585876465), ('李莫愁', 0.6370526552200317), ('欧阳锋', 0.6249241828918457), ('杨康', 0.6242249011993408), ('令狐冲', 0.6217637062072754), ('周芷若', 0.6029422283172607), ('任盈盈', 0.5994747281074524), ('洪七公', 0.5925484895706177)]
model.most_similar(positive=["前夫","女"], negative=["男"])
[('丈夫', 0.6005719900131226), ('前妻', 0.5966292023658752), ('继女', 0.5790506601333618), ('妻子', 0.5659573674201965), ('未婚夫', 0.5637686252593994), ('私生女', 0.5458118915557861), ('继母', 0.5406439304351807), ('未婚妻', 0.53529953956604), ('其妹', 0.528799295425415), ('养女', 0.5243291258811951)]
选出集合中不同类的词语
>>> model.doesnt_match("我 好人 男人 好男人 老虎".split())
'老虎'
>>> model.doesnt_match("我 好人 男人 好男人 学霸".split())
'学霸'
>>> model.doesnt_match("我 好人 男人 好男人 学渣".split())
'学渣'
>>> model.doesnt_match("我 好人 男人 好男人 螃蟹".split())
'螃蟹'
>>> model.doesnt_match("我 好人 男人 好男人 总经理".split())
'总经理'
>>> model.doesnt_match("我 好人 男人 好男人 老实人 备胎 高富帅 ".split())
'备胎'
2总结一下经验
1 要手动创建model文件夹
2 将只能在Terminal运行的方式改为pycharm中可run 可dubug的代码(debug超级实用)
3 前几次跑代码不要直接上全部数据集,而是先跑一下小的数据集检测代码是否可行(环境是否配置好,代码是否报错、能否保存模型/输出结果)
当前这个词向量的代码中可以使用 corpus_zhwiki_seg.txt1.4G ,而全部的数据集有4G!
3补充
未考虑:
1、增量训练
可以参考CSDN其他博客。
2、训练时数据按行喂给模型,避免内存占用过大
作者没处理,我也暂时没研究,有空再补充。
最后感谢以下博主及文章:
中文word2vector词向量实现
python work2vec词向量应用方法汇总
word2vec模型训练保存加载及简单使用