基于 word2vec 商城推荐系统的设计与实现
今天在整理磁盘空间时,无意中找到了 2018 年写的毕业论文对应的 Word 文档,翻看了一下,感觉还有点价值,所以决定将其搬运到公众号上,希望对有需要的读者朋友有所帮助。
内容概述:通过 NLP 中词向量相关的技术:Word2Vec 实现电商推荐系统,核心思想是用户浏览轨迹数据与文本数据在统计概率上有相似性,所以可以尝试使用 NLP 相关的技术进行相应的处理。

第一章 引言
1.1 选题背景与意义
随着信息文明的发展,我们已经被卷入信息的海洋中,每天都会有庞大的信息向我们涌来,在这茫茫的信息海洋中,我们已经不再会面临信息匮乏的问题了,反而是信息过载,缺乏一种有效提取对自身有意义信息的方法,就像宇宙中充满了暗能量,对我们来说,信息世界中也充满了暗信息,这些信息虽然充斥在我们身边,但如果不通某种手段进行挖掘,我们就发现不了它。
十年前搜索引擎技术快速发展,出现了很多优秀的搜索引擎公司,如 Google、百度,它能一定程度的帮助我们挖掘需要的信息,缓解上面的问题,但这还远远不够,因为搜索引擎永远都是被动的提供信息,需要用户输入关键字,永远无法主动的提供信息,而且对于不同的人搜索相同的关键字会给予相同的搜索结果,忽略了人与人之间的差异性,完全没有个性化,有时人们对于想要的内容无法通过关键字来描述,这时搜索引擎的作用就大打折扣,而这些缺陷都可以使用推荐技术来解决,而推荐系统就是推荐技术的具体实现,是人们在解决信息大爆炸问题的上进一步的探索。
推荐系统是信息文明发展到一定程度的必然产物,它可以通过用户的各种行为信息对用户所需要、所感兴趣的信息进行主动、个性化的推荐,不需要用户输入关键字。随着大数据和云计算的兴起,推荐系统也有了更大的发展空间。
本论文选择这一重要且有前景的方向进行研究,并采用自然语言处理方面的技术进行推荐系统的设计与实现,希望可以弥补使用传统技术实现的推荐系统某些方面的不足。
1.2 国内外研究现状和相关工作
近几年来,随着大数据技术的发展和机器学习算法的逐步成熟,越来越多研究人员尝试将大数据和机器学习有机的结合到推荐系统中,从而增加推荐系统的查准率和召回率,传统的推荐系统实现方法逐渐成为辅助手段,如基于协同过滤、Tag 或者其他使用集体智慧的方式。也有研究人员尝试使用用户在社交网络上的信息来辅助传统方式实现的推荐系统,或者通过自然语言处理的方式对商品描述信息进行数学建模,从而缓解推荐系统在冷启动过程中遇到的问题。除了对推荐系统本身的研究,还有部分研究人员对推荐系统的可信度和可移植性进行研究,对推荐系统中用户信息获取、建模与用户的交互进行研究等。
1.3 本文研究内容和主要工作
本文主要研究 word2vec 在推荐系统上的使用,并且基于 word2vec 设计和实现一个简单的商城推荐系统,为了可以弥补传统推荐系统的不足。虽然已经有研究人员使用 word2vec 来研究推荐系统,但是其使用的对象一般都是商品信息和用户的评论等信息,而本篇论文尝试使用电子商城上用户浏览商品的轨迹作为研究对象,尝试对用户在商城上浏览不同商品的轨迹进行分析和数据建模,从而获得一个推荐系统模型可以用来对不同的用户推荐商品。
研究以亚马逊为主,获取用户在亚马逊上浏览商品轨迹的数据,对数据进行清洗并通过 word2vec 对这些数据进行训练和建模,从而获得商品的高维向量,后期通过 Django 搭建 web 系统将获得的模型进行有机的整合从而获得一个简单的推荐系统。
1.4 论文结构与章节安排
本文总共分为五章,章节内如下: 第一章为引言,主要从选题背景与意义、国内外研究现状、相关工作和本文研究内容与主要工作这几个方法简单介绍一下本篇论文要研究的内容和推荐系统国内外的现状。
第二章主要讨论自然语言处理中 word2vec 的运用,分别从自然语言处理中的词向量、word2vec 的理念、Word2vec 的模型结构、word2vec 生成词向量等几个方面来探讨一下 word2vec 自身的理念、架构和当下 word2vec 主要使用的方向和解决的问题。
第三章主要讨论传统的推荐系统,分别从协同过滤、传统推荐算法等两个方面来探讨传统推荐系统常用的算法和实现的方式,并提出其中的不足。
第四章主要讨论 word2vec 实现推荐系统,分别从 Word2vec 实现推荐系统的理论支撑、用户浏览商品的数据结构、word2vec 训练数据生成推荐模型和实现 Word2vec 推荐系统等几个方面来探讨通过 word2vec 训练用户浏览数据构建推荐系统的合理性和准确性,并从结果直观的分析该推荐系统的效果。
第五章为总结与展望,主要是对前面工作的总结和思考,同时对 word2vec 在推荐系统上的运用进行简单的分析,并讨论未来推荐系统研究的主要方向
第二章 自然语言处理中 word2vec 的运用
word2vec 是 Google 在 2013 年开源的一款用于生成词向量的计算模型,因为 word2vec 可以在上亿数据集进行高效的训练且通过 word2vec 训练后获得的词向量可以很好的度量不同词之间的相似性,从而得到工业界和学术界的广泛关注,本章节就从各个不同的角度来看 word2vec 在自然语言处理中的运用。
2.1 自然语言处理中的词向量
为了让计算机明白人类的语言,在 NLP 中要做的第一步就是将语言抽象成一个高维词向量,如同一个翻译的过程,将人类的语言翻译成计算机的语言,那么在词向量保留人类语言中的意义就是非常重要了。
NLP 中词向量大致分两种,分别是 one-hot Representation 与 Distributed Representation。
one-hot Representation 比较简单,将语料库的大小作为向量的维度,一个词在语料库中出现一次就在向量的相应位置标志为 1,其他标志为 0,比如你的字典里有 1000 个词,那么这个向量长为 1000,字典中的每个词,都在相应的位置上标 1,其他位置都标 0。
美丽 [0,0,1,0,0,0,0,0,0,0,….,0]
漂亮 [0,0,0,1,0,0,0,0,0,0,….,0]
好看 [0,0,0,0,1,0,0,0,0,0,….,0]
one-hot Representation 会有两个严重的问题:
1. 维数灾难,一般公司的语料库都会是 TB 级别的,要创建这么长的向量其实不合适,对内存要求很大同时计算这么大维度的巨稀向量也非常困难
2. 词汇鸿沟,词与词之间没有任何联系,实质上词汇之间是有关联性的
Distributed Representation 解决了上面的问题,通过分布式的方式构建一个高维词向量,将一件事情通过不同的特征表示出来,如表示汽车
one-hot Representation 的形式如下
红色的大型卡车 [1,0,0,0,0...0]
白色的中型轿车 [0,1,0,0,0...0]
蓝色的小型电动车 [0,0,1,0,0...0]
Distributed Representation 的形式如下:
一句话 = 颜色 x 型号 x 车型
Distributed Representation 在表示词汇上,它的核心就是用一个词附近的其他词分布式的表示该词,使用 Distributed Representation 的词向量保存了词与词之间的联系,从而可以分析挖掘出词与词之间的具体关系。
word2vec 使用了 Distributed Representation 作为词向量的表示方式,除了 word2vec 外还有很多神经网络框架以这种形式的词向量作为输入,如 RNN、LSTM
2.2 word2vec 的理念
word2vec 不单只是一个工具,而且还是一种思想,word2vec 将语料库中的词汇通过滑动窗口逐个输入进行训练,当 word2vec 将语料库中的所有词汇都训练完后,就可以获得一个粘稠的词汇向量,它有两种生成方式,分别是通过周围的词来描述某个词,或者是通过某个词来描述它周围的词,就如同不了解你的人想要了解你是个怎么样的人就可以通过你周围的朋友从而知道你是个怎么样的人。
通过周围的词可以描述该词也是统计语言学中的思想,word2vec 通过对语料的训练来实现这个思想,延伸来讲,如果一份数据符合可以通过周围的数据来描述具体某个数据,那么都可以使用 word2vec 将这些数据转化成高维粘稠的向量。
使用 word2vec 对语料进行训练,然后将训练出来的向量映射到高维空间就可以看出词汇之间的关系,如 man 与 woman 的分布与 king 和 queen 的分布类似,其实就可以得到 king-queen≈man-woman 这条经典的等式。
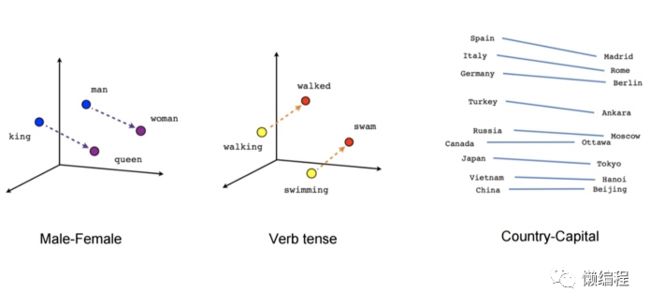
在不同语言中相似含义的词汇也会有类似的空间分布,通过这个特性,Google 的 TomasMikolov 团队开发了一种词典和术语表的自动生成技术,该技术通过向量空间,把一种语言转变成另一种语言,下图就是英文转成西班牙语。

因为语言符合统计规律,不同的语言中的词汇都可以通过周围的词汇来描述自身,所以不同语言对 word2vec 而言应该生成类似的向量空间,这也说明,主要符合这种统计规律的数据都可以通过 word2vec 进行训练从而获得有价值的高维向量。
2.3 word2vec 的模型结构
word2vec 基于 NNLM 模型,将 NNLM 模型中所有多余的运算全部去除,从而达到训练大数据集时依旧保持速度的目的,NNLM 模型是一个简单的神经网络模型。

这个结构比较简单,从下到上,分别是输入层、映射层、隐藏层和输出层,很常见的神经网络的结构。
NNLM 要做的事情和目标
假设现在有一个语料库,其中有 10w 个词,那么:
NNLM 要做的事情:定义一个滑动窗口,比如这个滑动窗口大小是 3,滑动窗口会遍历整个语料库,每次输入 3 个词,然后预测下个词。
结合上面 NNLM 的模型图,输入的 3 个词分别就是:
预测的词就是:
NNLM 的目标:将语料库中的 10w 个词通过稠密的向量矩阵来表示,这个稠密向量矩阵在 NNLM 模型图中就是:
一般的神经网络训练数据时通过反向传播算法优化神经网络中的参数,从而让输出层输出预期结果,而 NNLM 不同,最终需要的结果是神经网络训练时通过反向传播算法优化的这些参数,这些参数就是语料库中词的词向量。
严格说,NNLM 训练语料库的结果其实不错,但是因为进行了大量的运算导致这个模型训练语料库时训练速度太慢。
word2vec 中有两个模型,分别是 CBOW 和 Skip-Gram,这两个模型的结构更为简单,将 NNLM 中没有必要的运算全部去除,从而大大提升运算效率。

CBOW 的核心就是通过一个词周围的词来描述该词,Skip-Gram 正好相反,它的核心是通过一个词来描述该词周围的词。
CBOW 和 Skip-Gram 的训练语料库的流程也很简洁,下面是 CBOW 训练语料库的流程
1. 使用双向的滑动窗口获得词的稠密向量,这个稠密向量一开始随机初始化,在训练的过程中优化它
2. 去掉 NNLM 中的投影层和隐藏层,对输入层输入的稠密向量进行简单的求和或者求平均
3. 与输出层进行全连接,通过层次的 softmax 将输出层的数据转换为概率分布,与真实的概率进行对比,优化 CBOW 模型的输入,最小化两个概率分布的差距(损失)
Skip-Gram 的流程与 CBOW 相反,一般而言 CBOW 适用于小型数据集,而 Skip-Gram 适用于大型数据集。
word2vec 除了模型上的简化,在模型的输出层还使用了 Hierarchical Softmax 和负例采样来增加运算速度。Hierarchical Softmax 利用了 Huffman 编码树来编码输出层向量,这样在计算某个词时就只需要计算路径上所有非叶子节点词向量的权重则可,将计算量降为树的深度,而负例采样在保证频次越高的词应该越容易被采样到的原则下减少需要训练的数据量。
2.4 word2vec 生成词向量
本章使用 word2vec 对中文维基百科语料进行词向量的训练,直观的体会 word2vec 的训练数据的过程。
中文维基百科的语料数据是开源的,可以从 http://download.wikipedia.com/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2 下载。
最新语料的大小为 1.51G,格式为 xml,接着可以使用 Wikipedia Extractor 抽取 xml 中的正文,使用方式如下
git clone https://github.com/attardi/wikiextractor.git wikiextractor
cd wikiextractor
python WikiExtractor.py -b 1024M -o extracted zhwiki-latest-pages-articles.xml.bz2
通过上面命令就可以将正文提取并且按 1024M 为单位对提取的内容进行切分同时保持到 extracted 文件夹中,这样就获得了 wiki_00 和 wiki_01 这两个文件,大小分别是 1024M 和 110M。
因为中文维基百科中的内容是繁体简体混杂的,所以接着就要将繁体转化为简体,一般的做法就是构建一个繁体转简体的字典,当遇到繁体字时就去查这个字典获得对应的简体,opencc 这个开源项目已经完成了这个工作了,它可以在多个平台上使用 opencc Github。
opencc -i wiki_00 -o zh_wiki_00 -c t2s.json
opencc -i wiki_01 -o zh_wiki_01 -c t2s.json
这也就将 wiki_00 和 wiki_01 中的繁体转化为了简体,使用了 opencc 中的 t2s.json 这个配置文件,从而获得转化后的文件 zh_wiki_00 和 zh_wiki_01
为了进一步完善语料,接着可以将语料中的特殊符号剔除,剔除的方式非常简单,通过 python 中的 re 库使用正则表达式进行语料中特殊符号的替换
# -*- coding: utf-8 -*-
import re
import sys
import codecs
def clearwiki(file):
p1 = re.compile(ur'-\{.*?(zh-hans|zh-cn):([^;]*?)(;.*?)?\}-')
p2 = re.compile(ur'[(\(][,;。?!\s]*[)\)]')
p3 = re.compile(ur'[「『]')
p4 = re.compile(ur'[」』]')
f = codecs.open('std_' + file, 'w', 'utf-8')
with codecs.open(file, 'r', 'utf-8') as f:
for line in f:
line = p1.sub(ur'\2', line)
line = p2.sub(ur'', line)
line = p3.sub(ur'“', line)
line = p4.sub(ur'”', line)
outfile.write(line)
outfile.close()
if __name__ == '__main__':
if len(sys.argv) != 2:
print "需要输入要处理的文件,如:python clear.py zh_wiki_00"
sys.exit()
reload(sys)
sys.setdefaultencoding('utf-8')
file = sys.argv[1]
clearwiki(file)
运行一下
python format.py zh_wiki_00
python format.py zh_wiki_01
这样就获得了删除了特殊符号的语料,std_zh_wiki_00 和 std_zh_wiki_01
因为 word2vec 是针对词来进行训练,将语言中的词转换为高维的词向量,所以需要将语料进行分词,分词工具有很多,这里使用 jieba 工具进行中文分词 jieba Github
打开 shell 进入到 std_zh_wiki_00 所在的目录,运行下面命令
python -m jieba -d " " ./std_zh_wiki_00 > ./cut_std_zh_wiki_00
python -m jieba -d " " ./std_zh_wiki_01 > ./cut_std_zh_wiki_01
语料中的词汇以空格作为分割,分割后得到 cut_std_zh_wiki_00 和 cut_std_zh_wiki_01 两个文件,这两个文件因为插入了许多空格,所以明显比之前的文件大
接着就可以使用 word2vec 模型对处理后的中文维基百科的语料进行训练了,我们可以先用小文件来进行 word2vec 训练的测试,看看具体的效果,这里直接使用所有语料进行训练,通过 cat 命令将 cut_std_zh_wiki_00 和 cut_std_zh_wiki_01 两个文件整合成 zh.wiki 文件
cat cut_std_zh_wiki_00 cut_std_zh_wiki_01 >> zh.wiki
因为 word2vec 经常被用于词向量的训练,所以也已经有工具将 word2vec 的具体代码实现好了,直接使用 gensim 库下的 word2vec 对 zh.wiki 进行训练
from gensim.models import word2vec
sentences = word2vec.LineSentence(u'./zh.wiki')
model = word2vec.Word2Vec(sentences,size=400,window=5,min_count=5,workers=4)
model.save('./WikiModel')
在代码中,我们设置了词向量的维度为 400 维,一个词最小要出现 5 词,避免一些错别字或者极少使用的词,当训练完后,就会获得 WikiModel 这个模型,我们使用一些 WikiModel

在代码中,可以查找两个词的相似度,如男人和女人,也可以查找与某个词最相近的几个词 "推荐" 这个词,发现与之最相近的是引荐、举荐等几个近义词,从这里已经可以看出推荐系统的影子,有没有可能输入一件商品,得到与该商品最相关的几件商品呢?在第四章会进行详细的讨论
第三章 传统的推荐系统
本章会从协同过滤、传统的推荐算法等方面来探讨传统推荐系统,理解其大概的实现方式,发现通过这种方式实现推荐系统的不足。
3.1 协同过滤
传统推荐系统中使用的最多的就是协同过滤。协同过滤一般就是从海量的用户中挖掘出与你兴趣、品味类似的一小部分用户,这些用户就是你的邻居,然后通过他们所喜欢的其他商品组织成一个列表排序后推荐给你。
协同过滤又分为三大类,分别是基于用户的协同过滤 UserCF、基于物品的协同过滤 ItemCF 和基于模型的系统过滤 ModelCF。
UserCF
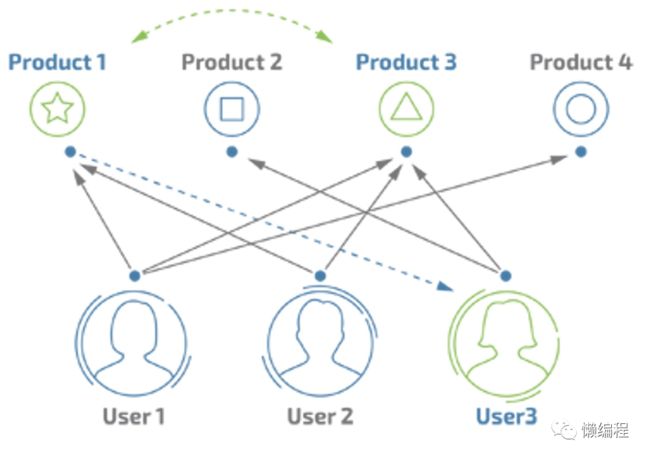
UserCF 通过不同的用户对不同商品进行评分来推测用户之间的相似性,如果用户 A 对商品 A、商品 B、商品 C 给给予了比较高的评分,用户 B 同样对商品 A、商品 B、商品 C 给给予了比较高的评分,那么就可以判断用户 A 与用户 B 具有相似的品味,推荐系统就可以基于用户之间的相似性对不同用户做出推荐,如用户 A 此时购买了新的商品 D,因为用户 A 与用户 B 相似,那么就可以将商品 D 推荐给用户 B。
计算上,可以将每个用户对应商城中所有商品的偏好作为一个向量来单独表示这个用户,这样不同用户之间的相似度就可以通过计算高维向量之间的距离来表示。
如图有三个用户,User1 和 User3 被判断为相似用户,那么就可以将 User1 购买的 Product1 和 Product4 推荐给 User3。

ItemCF
ItemCF 通过用户对不同物品的评分来推测物品之间的相似度,如商品 A 被用户 A、用户 B 评予了高分,商品 B 同样被用户 A 和用户 B 评予了高分,那么就可以判断商品 A 与商品 B 具有相似性,推荐系统就可以基于商品之间的相似度对不同用户做推荐,如用户 C 在浏览商品 A,那么为了方便该用户进行类似商品的比较,就可以向其推荐商品 B。
如图四件商品,其中 Product1 和 Product3 被认为是相似的商品,那么 User3 购买 Product3 时就可以向其推荐 Product1。
虽然 UserCF 与 ItemCF 核心思想一致,但是在电子商务网站中大多使用 ItemCF,因为 UserCF 共现矩阵计算代价比 ItemCF 高,而且当用户购买一些个性化比较强的商品时 UserCF 很难为用户推荐合适的商品。
ModelCF
ModelCF 也是目前比较主流的推荐算法,基于机器学习算法来训练推荐模型,通过对已有数据进行分类、聚类、关联规则挖掘等分析后建立模型,比如最常见的 SVD 推荐系统就是使用 SVD 算法处理数据获得模型。
UserCF 和 ItemCF 依赖共现矩阵间简单的相似性度量来匹配相似的用户或物品,无法量化一个用户有多喜欢某件商品,而 ModelCF 则尝试通过机器学习算法来训练物品向量 (针对一个用户) 或者用户向量 (针对一个物品) 从而获得模型,通过模型来量化一个用户会有多喜欢某件商品,将数值比较大的商品推荐给该用户,其实质就是一个粘稠的共现矩阵。
协同过滤算法的主要问题就是推荐质量较低,而造成这个问题的一个主要原因就是协同过滤训练使用的数据集非常稀疏,因为很少有用户会浏览或购买商城所有的商品、很少有商品会被所有的用户浏览或购买,虽然可以通过 SVD 等算法来降低矩阵的维度,让矩阵更加粘稠,但是这就会导致一些信息的损失。
3.2 传统推荐算法
协同过滤算法其实也算是传统的推荐算法,而且使用非常普遍,当然除了协同过滤算法,还是多种传统的推荐算法。
热度排行推荐
这是非常简单的一种推荐算法,在传统电商中也很常见,热度排列推荐顾名思义就是将最受用户喜欢的商品推荐给用户,这种方式不需要知道具体某个用户的情况,只需要知道大致的趋势就可以了,将热门商品推荐给用户。
热度排行推荐算法虽然实现简单,但是会造成商品的马太效应,因为推荐系统总是推荐热门商品,那么热门商品会变得更加热门,那么新的商品或者比较小众的商品就永远不会被推荐,虽然有这样的缺点,但是热门排行推荐依旧常用在电商首页,在当下,商品热度依旧是影响用户购买行为的重要因素。
基于内容的推荐
基于内容的推荐通常使用文本挖掘技术,挖掘商品描述或者评论中的关键词,通过这些关键词可以训练出与商品有关的模型,如可以使用 TF-IDF 算法来获得商品描述中的关键字,将关键字与商品映射在一起进行模型的训练。
基于内容的推荐可以推荐出一些比较小众的商品,具有比较好的解释性,但是也存在一定的问题 ,如很难从商品描述或用户评论中抽取出有意义的特征,很难将不同商品的特征组合在一起使用等,基于内容的推荐常用于商品项目的冷启动中,刚启动的商城没有多少用户和商品,也就没有什么用户和商品的数据,此时使用基于内容的推荐系统不失为不错的选择。
混合方法推荐
混合方法推是目前电商中大范围使用的方式,因为每种推荐算法都有它的优势和弱势,所以综合使用这些推荐算法,对每种推荐算法都取其长处去其短处,为不同的推荐算法推荐的结果设置权重,最终计算出权重最大的商品推荐给用户,如商城项目冷启动时,给基于内容的推荐系统一个比较大的权重,当商城渐渐有了用户后,再将基于内容推荐的权重设小,加大协同过滤的权重,除了加权方面的组合,还可以混合不同推荐算法抽象出来的商品特征,从而得到该商品的总特征。
混合方法推荐效果虽然好,但是实现比较复杂,不仅需要先实现要进行混合的推荐算法,还要在这些推荐算法的理论效果和实际可行性之间做权衡。
第四章 word2vec 实现推荐系统
了解了 word2vec 在自然语言上的运用和传统推荐系统的各各方面,本章尝试通过 word2vec 实现一个的推荐系统,不仅从理论上辩论这种方法的可行性同时通过对亚马逊用户浏览轨迹数据的训练来实现推荐系统。
4.1 word2vec 实现推荐系统的理论支撑
在传统的推荐系统中,有常见的 User CF、Item CF 和 Model CF 三种不同的协同过滤方式,它们都尝试通过用户和商品之间的关系来达到推荐的目的,三种的核心都是利用共现矩阵来实现推荐,是否可以使用商品来描述商品本身呢?
当我们使用 word2vec 训练语料库时简单说就是通过一个词周围的词来描述它,或者反过来,一个词来描述周围的词,因为人类的语言是有统计规律的,所以使用 word2vec 进行训练就可以获得有意义的高维粘稠的词向量,通过这些词向量可以获得词语间的空间关系。如果用户浏览商品的轨迹也是符合类似的统计规律,同样也就可以使用 word2vec 对浏览轨迹数据进行训练获得有意义的高维空间向量。其实用户浏览商品的轨迹是符合这个统计规律的,就如在语言中,词汇出现是有规律的,词 A 一般都出现到词 B、词 C 或者词 D 后,商品出现在用户浏览数据中也是有规律的,商品 A 一般在用户浏览完商品 B、商品 C 或者商品 D 后进行浏览。
举个具体的例子来论证商品在用户浏览数据中是有规律的,假设现在有两个用户,分别是用户 A 和用户 B,他们都在商城上浏览牛仔裤这一类商品。
用户A浏览商品的轨迹:A-->C-->D-->E-->P-->W
用户B浏览商品的轨迹:I-->A-->C-->D-->E-->E
那么对于两位用户来说,他们都想购买牛仔裤,然后在商城上浏览,产生了如上的浏览轨迹,通过用户 A 浏览商品轨迹顺序说明用户喜欢某个商品的程度,比如他更先浏览商品 A 然后才看商品 C,说明商品 A 对他的吸引比商品 C 大,同时也说明商品 A、C、D、E、P、W 都满足用户 A 对牛仔裤的要求,对用户 A 而言,这几件商品都比较类似,用户 A 在这些商品中做比较,那么对于用户 B 的浏览轨迹而言也有相同的意义,可以得出结论:浏览的商品的浏览的顺序和出现的位置都是有意义的,它就像经过分词处理后的句子一样,一句话中词汇出现的顺序和位置与浏览轨迹中商品出现的顺序为位置一样都是有统计规律的,在大语料库上看,词汇 A 经常与词汇 B、词汇 C、词汇 D 一起出现使用,那么就可以通过词汇 B、词汇 C、词汇 D 分布式来表述词汇 A,当我们拥有大量的用户浏览轨迹数据后,也可以发现这样的规律,商品 C 经常与商品 A、商品 D、商品 E 一起出现,这就说明对大部分用户来说,这几种商品是类似的,经常被一起浏览做比较,所以我们同样可以通过商品 A、商品 D、商品 E 分布式表示商品 C,简单说就是使用 word2vec 对用户浏览数据进行训练获得商品的高维空间向量,从而可以通过计算不同商品间的空间距离,距离越近的商品也就是越相似。
通过 word2vec 我们就可以实现出利用商品来描述商品本身的推荐系统,与使用协同过滤的传统推荐系统有较大的不同,从某些方面弥补了推荐系统的不足。
4.2 处理用户浏览商品的数据
用户浏览商城中商品的轨迹数据是隐式的,无法通过爬虫抓取,而亚马逊开源了从 1996 年 5 月到 2014 年 7 月的用户浏览数据,当然除了用户浏览数据外还有用户评论数据、产品信息数据等,直接下载亚马逊按产品类型分类好的数据到本地。

我将数据分别放到了 2 个不同的文件夹中,为了测试编写的代码是否可以正常运行,所以放置了一小部分数据到 data 文件夹中。
当然,亚马逊本身还提供了没有按产品类型分类的完整数据供我们下载,同样将其下载到本地,并解压,metadata.json 大小为 10.54GB。
读取 metadata.json 中的数据,数据的格式如下:
{'asin': '0061733032',
'categories': [['Books']],
'description': "Illustrators Olga and...",
'title': 'Mia and the...',
'price': 14.5,
'salesRank': {'Books': 214153},
'imUrl': 'http://ecx.images-amazon.com/images/I/51oV8TgbbrL.jpg',
'related': {
'also_bought': ['0061733059', '0061733016'],
'bought_together': ['0061733059', '0061733016'],
'buy_after_viewing': ['0062086820', '0061733016'],
'also_viewed': ['0062208985', '0062120336']}}
数据中字段的具体含义:
1.asin - 产品ID
2.title - 产品的名称
3.price - 产品价格,单位是美元
4.imurl - 产品图片的url
5.related:相关产品,下面有4类,分别是:
a.also_bought - 购买了该商品,同样购买的其他商品
b.also_viewed - 浏览了该商品,同样浏览的其他商品
c.bought_together - 购买了该商品,一同购买的其他商品
d.buy_after_viewing - 购买了这个商品后,继续看的商品
6.salesRank - 销售排名信息
7.brand - 品牌名称
8.category - 产品所属类别列表
因为要通过 Django 搭建一个 web 系统,需要显示产品的一些信息,如产品的图片、产品的 ID、产品的标题等,所以需要将数据存到数据库中,方便 Django 从数据库中获取数据并显示在 web 界面中。
首先创建一个 Django 项目,名为 wmrs (Word2vec Mysql Recommended system),项目结构如下
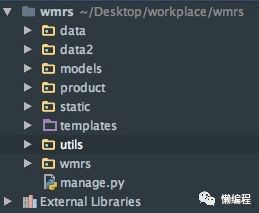
data、data2 用于存放亚马逊提供的数据,product 是 Django 应用,static 用于存放资源文件,templates 存放静态文件,utils 用于存放我们编写的一些工具代码,wmrs 存放 Django 项目的配置文件和路径文件等。
将读取 metadata.json.gz 数据到数据库中的代码放到 utils 文件夹中,具体代码如下:
import gzip
import json
import pymysql
def parse(path):
g = gzip.open(path, 'r')
for l in g:
yield json.dumps(eval(l))
db = pymysql.connect('localhost', 'MySQL账号', 'MySQL密码', 'wmrsdb')
cursor = db.cursor()
path = '/Users/ayuliao/Desktop/workplace/word2vec-recommender/data/metadata.json.gz'
i = 0
for l in parse(path):
l = eval(l)
sql = 'INSERT INTO product_productinfo(asin,imUrl, price, title) VALUES ("%s", "%s", "%f", "%s")' % \
(l.get('asin',''), l.get('imUrl',''), l.get('price',0), l.get('title',''))
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
print(i)
i = i+1
db.close()
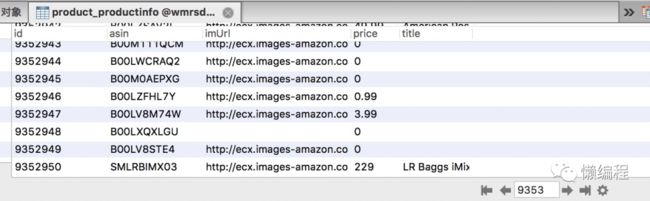
因为要读入的数据比较大,所以使用 python 的生成器来读取。上面代码将 metadata.json.gz 中的 asin、imUrl、price、title 读入到 wmrsdb 数据库中,通过 navicat 来显示数据。
4.3 word2vec 训练数据生成推荐模型
因为是要根据用户的轨迹进行商品的推荐,那么我们只需要 also_bought、also_viewed、bought_together、buy_after_viewing 等数据就好了,将 also_bought、also_viewed、bought_together、buy_after_viewing 这些数据组合成一个 list 交给 word2vec 进行训练,word2vec 会将其看做一个句子
通过生成器读入 data 和 data2 文件夹下的所有数据,然后自定义一个迭代器类,重写其中的__iter__() 方法,将将 also_bought、also_viewed、bought_together、buy_after_viewing 这些数据组合成一个 list,通过 yield 关键字返回给 word2vec
# -*- coding: utf-8 -*-
import gensim
import gzip
import json
import os
def parse(path):
g = gzip.open(path, 'r')
for l in g:
yield json.dumps(eval(l))
class MySentences(object):
def __init__(self,path):
# metadata元数据的路径
self.path = path
def __iter__(self):
i = 0
for l in parse(self.path):
l = eval(l)
asin = l.get('asin', '')
related = l.get('related', {})
if related:
also_bought = related.get('also_bought', [])
also_viewed = related.get('also_viewed', [])
bought_together = related.get('bought_together', [])
buy_after_viewing = related.get('buy_after_viewing', [])
sents = asin + ' ' + ' '.join(also_bought) + ' ' + ' '.join(also_viewed) + ' ' + ' '.join(bought_together)+ ' ' + ' '.join(buy_after_viewing)
yield sents.split()
else:
continue
print(i)
i +=1
def train(path, model_path):
sentences = MySentences(path)
for name in os.listdir(path):
filepath = path+name
sentences = MySentences(filepath)
gensim.models.Word2Vec.load
model = gensim.models.Word2Vec(sentences, min_count=10, workers=4, negative=10, size=300, sample=1e-4, sg=0,
hs=1, window=10)
model.init_sims(replace=True)
model.save(model_path+'_'+name.split('.')[0])
if __name__ == '__main__':
path = '/Users/ayuliao/Desktop/workplace/wmrs/data2/'
model_path = '/Users/ayuliao/Desktop/workplace/wmrs/models/Model'
train(path, model_path)
解释一下 Word2Vec 方法中设定的几个参数
min_count - 忽略总频率低于此值的所有单词。
sg - 定义了训练算法。默认情况下(
sg = 0),使用 CBOW。否则(sg = 1),使用 skip-gram。negative - 如果大于 0,将使用负采样,int 为负数指定应绘制多少 “噪音词”(通常在 5-20 之间)。默认值是 5, 如果设置为 0,则不使用负面抽样。
sample - 配置较高频率的词,它的随机下采样的阈值。默认值是 1e-3,有用的范围是(0,1e-5)。
hs - 如果等于 1,层次的 softmax 将用于模型训练。如果设置为 0(默认),并且 'negative' 不为零,则将使用负采样。
训练的结果如下:

可以自行验证一下这些模型有无效果
我们没有选择选了 metadata.json.gz,而是训练分类数据,这是因为产品的浏览数据跟真实的语料数据还是有差距的,一个真实的语料数据,可能也会轻易的达到 10 几 G,但互异的词不会特别多,可是产品元数据不同,它拥有 900 多万个互异词 (产品的 ID 都不同),训练时 size 设置为 300,那么就会形成 900 万 * 300 的矩阵,会耗费巨大的内存,所以这里选择按产品类型分类好的数据进行推荐模型的训练
4.4 word2vec 推荐系统效果分析
metadata.json.gz 的数据已经存到 MySQL 数据库中,Word2vec 也训练完了数据并生成的推荐模型,接着就来完善 web 系统,通过 Django 搭建 web 系统比较简单
该 web 系统对应只有 3 个界面
error.html - 没有找到推荐商品显示的界面
index.html - 主页,随机显示数据库中的商品数据
like.html - 推荐商品显示页
先看到主页对应的逻辑代码
class IndexListView(View):
def get(self, request):
five_product = []
for i in range(5):
five_product.append(ProductInfo.objects.get(id=random.randint(5, 9352950)))
product_dict = {}
for product in five_product:
try:
product.imUrl = 'https://images-na.ssl-images-amazon.com/images/'+product.imUrl.split('/images/')[1]
product_dict[product.asin] = [product.imUrl, product.title]
except:
pass
return render(request, 'index.html', context={
'product_dict':product_dict,
})
通过 randint 函数创建随机 ID,并通过这个 ID 获得对应商品的数据,将这些数据显示到主页中,效果如下,会显示 5 个商品,因为商品是通过随机数获得的,所以一般不同。

点击推荐相似商品按钮,可以获得与该商品相似的商品
比如我点击 ID 为 B007OSZYHA 的商品 Tung Oil 桐油,就会有下面的结果

这个页面就是 like.html,它对应的逻辑代码如下:
class Word2vecListView(View):
def get(self, request, asin):
product_dict = {}
for model in models:
try:
products = model.most_similar(asin)
for p in products:
# p[0]为商品的asin,p[1]为相似度
try:
product = ProductInfo.objects.get(asin=p[0])
product.imUrl = 'https://images-na.ssl-images-amazon.com/images/'+product.imUrl.split('/images/')[1]
product_dict[product.asin] = [product.imUrl, product.title, p[1]]
except:
pass
except: #在model中没有要找的词则会报错
pass
if product_dict:
return render(request, 'like.html', context={
'product_dict': product_dict,
})
else:
return render(request, 'error.html', context={
'error': '该商品没有相似推荐',
})
首先获得前端 url 中传递过来的商品 ID,遍历训练出来的模型,找到与该商品 ID 相似的商品,将商品信息和商品的相似度显示到前端 like.html 上
回到首页
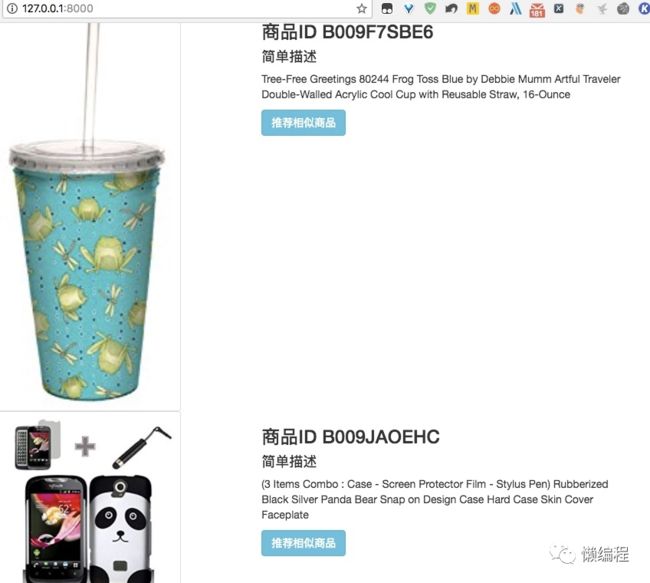
让系统再推荐一个商品,此次推荐 ID 为 B009JAOEHC 的商品,类似手机壳的东西,推荐结果如下

可以看出通过 word2vec 实现的推荐系统效果还是不错的,但是有些比较偏门、比较少人购买的商品,推荐系统就会找不到相似的物品进行推荐,如 ID 为 B009F7SBE6 的商品

因为 word2vec 训练推荐模型时,设置了每个词最少要出现 10 词,不然就会当做噪音忽略,所以有些商品没有相似的推荐商品也是正常现象。
第五章 总结与展望
总结论文所做的讨论和工作,展望未来推荐系统可以的研究方向。
5.1 工作总结
论文介绍了 word2vec 工具、深入的讲解 word2vec 的架构和运用并通过 word2vec 训练了从中文维基百科获得的语料,从而比较全面的理解了 word2vec 在自然语言处理中的用处和 word2vec 核心思想,接着介绍了协同过滤和多种传统的推荐系统算法,讲解了这些算法的用途和面临的问题,为了解决这些问题,尝试从自然语言处理的角度来构建推荐系统,因为用户浏览商品轨迹具有有意义的规律,所以通过 word2vec 训练这些数据可以获得一个有意义的模型,通过该模型就可以像用户推荐相似商品。
因为传统推荐算法都面临着各自的问题,如协同过滤算法因数据集极端稀疏导致推荐质量较低,热度排行算法具有商品马太效应等,虽然使用混合方法推荐可以综合不同推荐算法的优缺点,但是实现复杂较难维护,所以本论文提出通过 word2vec 训练用户浏览数据获得推荐模型的思路,论文中首先从理论上推理这种思路的是具有可行性的,再使用亚马逊提供的用户浏览数据训练出有价值的推荐模型,并且以推荐模型作为核心通过 Django 搭建了一个简单推荐系统,通过该推荐系统可以直观的看到推荐模型可以合理的推荐出相似的商品,从实际上验证了这种方法的可行性。
通过 word2vec 训练用户浏览数据搭建的推荐系统实现起来非常简单,从论文中的代码可以看出,核心代码比较简短,但是获得推荐模型的推荐效果却不错,因为模型使用了商城中所有商品的浏览轨迹数据训练 (300 维的粘稠矩阵),所以解决了协同过滤因数据集过稀疏导致推荐质量较低的问题,同时也因为使用了全商品的数据消减了商品马太效应现象。
5.2 科研展望
虽然通过 word2vec 实现推荐系统是可行的,而且有不错的推荐效果,但是也不是完美的推荐办法,该方法依然面临着一些问题,如对新用户或新商品无法推荐,因为在训练模型时,新用户或新商品的数据根本就不存在,而且对一些很少人浏览的商品 (小于 10 人浏览),推荐系统也无法推荐,因为在训练模型时,为了避免噪音的干扰,将在全数据中出现次数很少的商品都排除了,这很难保证排除的就一定是噪音,而不是一个非常小众的商品。
为了解决这些问题,可以尝试从其他数据源获得用户或商品的数据从而提高推荐系统的准确度,如从社交网络中获取用户相关的数据,对用户进行用户画像,从而量化出用户的喜好,将这些用户特征转移运用到商城中,辅助推荐系统的推荐。
在未来,多方面的收集用户行为信息、言论信息从而更准确的量化出用户是推荐系统研究的重要方向,数据的丰富度和准确度的重要性会渐渐高于推荐算法的重要性,有了对某一用户丰富且准确的数据就算使用最简单的算法也可以获得不俗的效果,但如果使用高级算法去训练一堆没有具体意义的数据而获得的模型肯定也是没有意义的。
参考文献
[1][期刊论文] 张锋,常会友,Zhang Feng, Chang Huiyou - 《计算机研究与发展》 2006 年 4 期
[2]R. He, J. McAuley. Modeling the visual evolution of fashion trends with one-class collaborative filtering. WWW, 2016
[3]J. McAuley, C. Targett, J. Shi, A. van den Hengel. Image-based recommendations on styles and substitutes. SIGIR, 2015