医学图像分割
作者:
Zeynettin Akkus & Alfiia Galimzianova & Assaf Hoogi & Daniel L. Rubin & Bradley J. Erickson
时间:2017
Abstract
这篇综述的目的是提供关于最近基于深度学习的分割方法对脑部MRI(磁共振成像)定量分析的概述。首先我们看一下最新用来分割脑部解剖结构和脑部损伤的深度学习框架。接下来总结和讨论了深度学习方法的表现,速度,和特性。最后给出了当前状况的关键性评价,并且确定了可能的未来发展和趋势。
Background
脑功能成像一般选择MRI,有几个原因:MRI生成的医学图像对软组织有高对比度和空间分别率,没有已知的健康损伤。尽管CT(计算机断层扫描)和PET(正电子成像)也可以用来研究大脑,MRI仍然是最流行的,本片论文针对MRI。脑部MRI定量分析已经被广泛应用到很多脑部疾病特征分析。为了定量组织萎缩,分割,相应的大脑组织测量都是必须的。相应的,脑部结构变化的定量,要求对在不同时间点获取的MRI分割。除此之外,非正常组织和周围正常结构的检测和精确定位对于诊断,手术规划,术后分析,化疗/放疗计划是至关重要的。正常和病变组织的定量定性特征,包括时间和空间,经常是临床试验的一部分,通过一组病人和正常组来研究治疗效果。
神经性疾病和状况一般都需要脑部磁共振图像的定量分析。2D和3D的分割和打标签都是定量分析的重要组成。手动分割是活体图像的金标准。然而,这要求一张一张画出组织结构,不仅昂贵和冗长乏味,而且由于人工错误而不精确。因此有必要使用一种自动分割方法,并且拥有专家级别的精度和高度一致性。
3D,4D图像越来越普及,且生理功能成像越来越多,医学图像在数量和复杂度方面都在增加。机器学习是一系列算法技术,能够使计算机系统从大数据进行数据驱动预测。这些技术有许多可以被应用到医学领域。
迄今为止,已经在MRI脑部图像正常(白质和灰质)和非正常(脑肿瘤)分割的经典机器学习算法上投入了很多研究。然而使得能够分割的图像特征的产生要求熟练的工程和专业知识。更重要的是,传统的机器学习算法并不好用。尽管医学图像搜索社区付出了显著的努力,大脑组织的自动分割和异常区的检测任然没有解决,由于脑部形态正常解剖变异,获取设置和核磁共振成像扫描仪的变化,图像采集的缺陷,病理学表现的异常。
深度学习在医学图像分析的很多领域已经得到了广泛的应用,比如,电脑辅助检测乳腺病变,电脑辅助诊断乳腺病变和肺结节,组织病理学诊断。这篇论文概述了在脑部磁共振图像分割的最好深度学习技术,并且讨论了通过使用深度学习技术任然能够提高的距离。
Deep Learning
已经有很多深度学习方法被开发使用到不同目的,比如,图像的目标检测和分割,语音识别,基因型/表型检测,疾病分类。一些已知深度学习算法有堆叠式自动编码器,深层玻尔兹曼机,深度神经网络,卷积神经网络。卷积神经网络是被用到图像分割和分类的最多的一种。
Review
我们将论文分为两类:关于正常组织和脑损伤。这两组里不同的深度学习架构被介绍来处理领域内特定的问题。基于它们的架构风格,我们又进行了更细的分类:patch-wise, semantic-wise, or cascaded architectures。在接下来的部分,我们将展示:评价和验证方法,最近的深度学习方法中的预处理方法,最近深度学习架构风格,深度学习算法在脑组织和病变区量化的表现。
Training, Validation and Evaluation
当数据有限,就使用交叉验证方法。由于使用监督方法,需要标签。数据一般通过专家对脑部组织和病变区域分割认为标定。虽然这对于学习和评估是一个金标准,但非常繁琐和辛苦,还包含了主观性。Mazzara等人(Brain tumor target volume determination for radiation treatment planning through automated MRI segmentation)报告,对于手动分割脑肿瘤图像,国内专家有20 ± 15%的变化,国际专家有28 ± 12%的变化。为了减小这种变化,通过使用标签融合算法(STAPLE,Simultaneous truth and performance level estimation (STAPLE): An algorithm for the validation of image segmentation,A logarithmic opinion pool based STAPLE algorithm for the fusion of segmentations with associated reliability weights),多个专家的分割图像被以最佳的方式被结合。对于脑部损伤的分类任务,标定过的真实数据通过活检和病理检查来得到。
为了评定一个新的开发的深度学习方法的效果,有必要将它与现在最好的方法作比较。这里提到很多数据集,https://www.nitrc.org/projects/msseg,brain MRI are Brain Tumor Segmentation (BRATS), Ischemic Stroke Lesion Segmentation(ISLES), Mild Traumatic Brain Injury Outcome Prediction(mTOP), Multiple Sclerosis Segmentation (MSSEG), Neonatal Brain Segmentation (NeoBrainS12), and MR Brain Image Segmentation (MRBrainS)。
Brats 这个脑肿瘤图像分割挑战联合MICCAI会议,自从2012年开始每年举办,为了评估现在最好的脑部肿瘤分割方法,并且比较不同方法。为此,很多的数据集被公开,有5类label:脑部健康组织,坏死区,水肿区,肿瘤的加强和非加强区。并且训练集每年都在增长。最近的Brats 2015–2016比赛中训练集包含220个高等级子集和54个低等级子集,测试集包含53个混合子集。所有的数据集被校准为同样的解剖模板,并且被插值为1 mm 3的分辨率。每个数据集包含增强前T1和增强后T1,T2,T2磁共振成像液体衰减反转恢复序列MRI体素。联合配准,头骨分离,标注的训练集,算法的评价结果可以通过Virtual Skeleton Database (https://www.virtualskeleton.ch/)来获取.
Isles 这个挑战被组织来评估,在精确MRI扫描图像中,中风病变及临床结果预测。提供了包含大量的精确中风样例和相关临床参数的MRI扫描。联合的被标记的真实数据是最终损伤的区域(任务一),用了3到9个月的跟踪扫描来人工标记,和表示残疾度的临床mRM得分(任务二)。在ISLES2016比赛中,35个训练集和40个测试集通过SMIR平台公开。(https://www.smir.ch/ISLES/Start2016). 亚急性缺血性卒中病变分割的获胜者的算法结果为0. 59±0.31(骰子相似性系数,DSC)和37.88±30.06(豪斯多夫距离,HD)。
mTOP 这个挑战要求算法找到健康组织和外伤性脑损伤(TBI)病人的差异,并且使用非监督方法将给定的数据分为明显不同的类。开源MRI数据在https://tbichallenge.wordpress.com/data下载。
MSSEG 这个挑战的目的是从MS数据的参赛者中评定最好的最新的分割方法,为此他们评估了在一个在多中心临床数据库(4个数据中心的38个病人,为1.5T或者3T的图像,每个病人被7个专家手动标记)上的损伤区域检测(多少个病变区被检测出)和分割(被勾出的损伤区精确度如何)。除了这个经典的评估外,他们提供了一个共同的基础设施来评价算法,比如运行时间和自动化度的比较。数据可以从https://portal.fli-iam.irisa.fr/msseg-challenge/data下载。
NeoBrainS12 这个比赛的的目的是,通过使用脑部T1和T2的MRI图像,来比较新生脑组织分割算法和对应大小的测量。在以下结构比较:皮质和中央灰质,无髓有髓白质,脑干和小脑,脑室和脑外间隙脑脊液。训练数据包括两个30周到40周大小的婴儿的T1和T2MR图像。测试集包括5个婴儿的T1和T2 MRI图像。数据和算法的评估结果已经被提交,可以从http://neobrains12.isi.uu.nl/下载。
MRBrainS 这个评估架构的目的是比较脑部多序列(T1加权,T1加权反转恢复,磁共振成像液体衰减反转恢复序列,FLAIR)3T MRI图像,灰质,白质,脑脊髓液的分割算法。训练集包括5个手动分割的脑部MRI图像,测试集包括15份MRI图像。数据可以从http://mrbrains13.isi.uu.nl下载。在这个数据集上的获胜者的算法的结果(骰子相似系数,DSC):灰质86.15%,白质89.46%,脑脊髓液84.25%。
表1是最常见的用来评估脑部MRI分割方法的定量方法。通常正常组织和肿瘤的分割方法包括每个像素度量(比如:骰子相似系数,真阳率,阳性预测值),病灶表面度量(比如:豪斯多夫距离,平均对称面距离)。
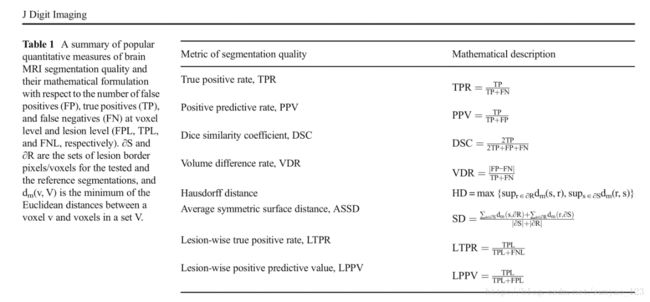
另一方面,多灶性脑病变方法经常包括病灶度量(病灶真阳率,病灶阳性预测率)。精确度和特异性等方法在病灶分割内容面趋于避免使用,因为当病目标(灶)比背景(正常大脑组织)小很多时,这些方法不能区分不同的分割输出。除此之外,通常还包括临床相关性测量方法。这些方法包括总共的损伤区的相关性分析,自动或手动分割和体积或体积改变相关计数。显著性检验通常伴随着建立或比较其它方法,大多数是非常数检验,比如威尔科克森符号秩检验。
Image Preprocessing
MR图像自动分割是一个富于挑战的问题,由于强度不均匀性,强度范围和对比的变化,噪声。因此,在自动分割之前,要求特定的步骤来使得图像看起来更相似,这些步骤一般被称为预处理。典型的功能脑成像预处理步骤包括以下几个步骤:
Registration 配准是将图像到常见解剖空间的空间对齐。病人自己的图像配准辅助将MR图像标准化到立体空间,通常是MNI (加拿大蒙特利尔神经研究所)or ICBM。(MNI和ICBM是一系列3D大脑模型)病人间的配准目的是对齐不同序列的图像,比如T1和T2之间,为了获得大脑每个区域的多通道表达。
Skull Stripping 头骨剥离是是将头骨从图像中去除,目的是将注意力集中在头颅中间的组织。用于这个目的的最常用的方法为BET,Robex,SPM。
Bias Field Correction 偏场校正图像对比度变化的纠正,由于磁场多向性。最常见的方法是N4偏场校正。
Intensity Normalization 灰度归一化是将所有图像的灰度映射到一个标准或基准标度,比如,0到4095。由Nyul等人提出的算法是将图像灰度按像素线性映射到基准,是最常用的一种正则化技术。在深度学习框架的背景下,z-scores(将图像中的每个像素减去所有像素的平均值,然后除以标准差)是另一种常见的正则化技术。
Noise Reduction 降噪是减小MR图像里边局部变量赖斯噪声。
随着深度学习的到来,一些预处理步骤对于最后的分割结果的重要性越来越小。比如偏置矫正,基于分位数的灰度归一化一般被z-score单独代替。然而另一项工作表明:在应用深度学习之前进行归一化会对结果有提高。同时,新的预处理方法也被提出来,包括基于校准,头骨去除,噪声去除的深度学习。
Current CNN Architecture Styles
Patch-Wise CNN Architecture(按块训练的CNN架构) 有一个简单的方法训练CNN算法来分割。一个N*N大小的图片块从给定图像提取出来,模型用这些图片块训练,然后将label给正确的标识类,比如正常大脑,肿瘤。所设计的网络包含多层卷积,激活函数,池化,全连接层。大多数想在流行的框架都使用这种方法。为了提高按块训练框架的表现,多尺度CNN使用多种途径,每种途径使用不同大小的patch。这些途径的输出被一个神经网络结合起来,模型被训练来给出正确的label。
Semantic-Wise CNN Architecture(按语义训练的CNN架构) 这种架构对输入的整张图像的每个像素进行预测,比如语义分割。和自编码器类似,它们包括编码部分(提取特征)和解码部分(降采样或去卷积从编码器得到的高维特征)和组合从编码部分得到的高维特征来分类像素。通过减少损失函数将输入图片映射到分割label。
Cascaded CNN Architecture(级联CNN架构) 这种架构结合两歌CNN架构。第一个CNN的输出是第二个CNN的输入来获得分类结果。第一个CNN用来训练得到初始预测分类标签,第二个CNN用来更深的调整第一个CNN的结果。
Segmentation of Normal Brain Structure
在很多研究中,MRI脑结构的精确自动分割,比如:白质(WM),灰质(GM),脑脊髓液(CSF),对于研究婴儿早期脑发展,脑组织和颅内容积的定量评估是很重要的。Atlas-based方法(匹配一个atlas和目标的灰度信息),模式识别方法(依据一系列局部灰度信息分类组织)是脑组织分割的传统方法。近些年,CNN已经被用于脑组织分割,这避免了空间和灰度特征的明确定义,比传统方法表现更好,我们接下来会讨论。如下图:
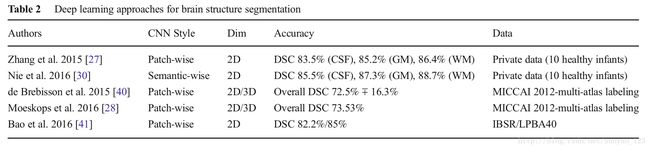
Zhang等人提出了一个从婴儿的多模态(T1,T2, 各向异性分数(弥散张量成像))MR图像的2D patch-wise CNN方法来分割白质,灰质,和脑脊液。他们表明他们的CNN方法比先前的方法,基于SVM,随机森林的传统的机器学习好。Nie等人提出了semantic-wise全卷积网络,分割和zhang等人一样的数据集的婴儿大脑图像。Nie等人的结果更好。De Brebisson等人提出一个2D和3D的patch-wise CNN方法,将人脑按照解剖区域分割。作为第一此CNN方法应用到这个挑战,他们在MICCAI 2012 multi-atlas labeling挑战获得非常有竞争力的结果。Moeskops等人提出了一个multi-scale patch-wise CN方法,来分割婴儿和年轻成年人大脑图片。Bao等人也提出了一个multi-scale(块大小不一) patch-wise CNN方法,使用随机动力抖动伴随感兴趣区域下降,来获得在IBSR数据集和LPBA40数据集上,皮层下结构的光滑分割。基于卷积神经网络的深度学习方法已经在NeoBrainS12 and MRBrainS挑战获得了最好成绩。在测试阶段,他们的计算时间也比传统的机器学习方法要快。
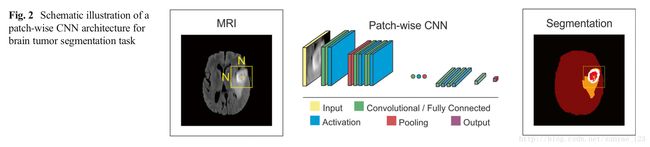
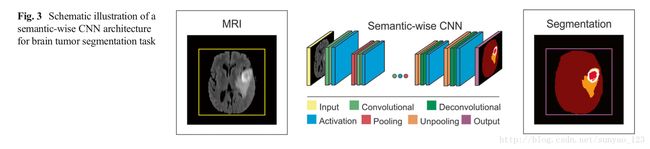
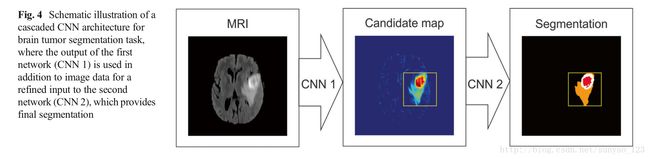
Segmentation of Brain Lesions
脑损伤的定量分析包括建立成像生物标志物的测量,比如最大直径,体积,计数,连续,来量化相关性疾病治疗结果,比如脑癌,多发性硬化,中风。这些生物标志的可靠提取依赖于先前的精确分割。尽管在脑损伤分割的很多努力和高级的图像处理计数,脑部损伤的精确分割仍然是个挑战。许多自动方法已经被提出来用于损伤分割问题,包括非监督模型方法(目的是自适应图像数据),监督机器学习方法(给定一个具有代表性数据集,学习损伤区的纹理和外观特性),atlas-based方法(通过配准有标签数据或者cohort data到常见的解剖空间,将监督和非监督方法结合为统一管道)。一些综述提供脑部肿瘤分割,MS损伤分割的传统方法。
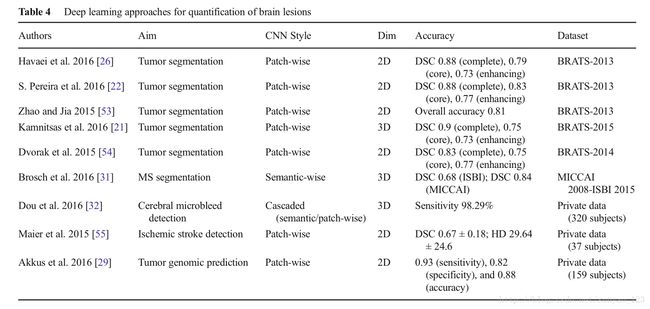
Havae等人提出了一个2D的patch-wise架构(33 × 33 pixels),使用局部和全局的CNN路径,可以探索脑肿瘤像素局部和全局的语境特征。局部路径包括2个卷积层,核大小为7 × 7和5 × 5,相应的,全局路径包括一个卷积层,核大小为11 × 11。为了处理肿瘤和正常脑组织的不平衡问题(正常脑组织占了整个图像的90%),他们提出了两阶段训练,第一,处理等类别概率的数据,然后处理不平衡数据输出层(保持其它层权重不变)。他们还探索了多级联架构。他们说他们的CNN方法比BRATS 2013比赛的获胜者好,而且测试时间更快。
在另一项研究中,Havaei等人写了用深度学习方法分割脑肿瘤的综述,也描述了级联架构。Pereira等人提出一个2D patch-wise架构,但与Havaei等人不同,他们使用小一点的3 × 3卷积核,允许使用更深的架构,patch intensity正则化,通过旋转patches来进行数据增强。他们设计了两个分离的模型分别对高级肿瘤和低级肿瘤分割。分割高级肿瘤的模型包括6个卷积层和3个全链接层;分割低级肿瘤的模型包含4个卷积层和3个全链接层。他们使用leaky ReLU作为激活函数,允许gradient flow,而rectified linear units则让所有负数为0. 在Brats 2013中他们的方法表现最好。在2015 data,他们第二。Zhao and Jia使用patch-wise CNN架构,使用三平面(横断面,矢状面,冠状面)2D切片来分割脑肿瘤。在Brats2013,他们得到了有竞争力的结果。Kamnitsas等人提出了一个3D的dense-inference patch-wise and multi-scale的CNN架构,使用3D(3 × 3 × 3 pixels)卷积核和两条通路和上面提到的Pereira等人的相似。他们还使用了一个3D的全链接条件随机场来有效的去掉假阳性,这是一个在先前的研究中重要的后续处理步骤。在Brats 2015,他们获得最佳表现。Dvorak等人提出了一个2D的patch-wise卷积方法,将输入的patches映射到n组有结构的局部预测,考虑相邻像素的label。在过去的两次MICCAI会议,大多数这些研究被发表出来,作为BRATS挑战的一部分。
基于CNN的深度学习架构已经被用来中风和多发性硬化(MS)损伤分割,脑微出血检测,治疗效果的预测。Brosch等人提出了一个3D的semantic-wise CNN来从MRI中分割MS损伤。他们在两个公开的不同数据集上评估他们的方法,MICCAI 2008 and ISBI 2015挑战。Dou等人提出了一个级联架构,包括3D semantic-wise CNN and a 3D patch-wise CNN来从MRI中检测脑微出血(CM)。Maier等人发表了一个比较研究,评估和比较了9个用来分割缺血性中风损伤的分割方法,(比如天真贝叶斯,随机森林,CNN)。表明级联CNN和随机决策树方法优于其它所有方法。Akkus等人展示了使用2D patch-wise and multi-scale CNN 1p19q染色体共同缺失预测,这和治疗的好的结果有关(在低级别脑胶质瘤MRI中)。
Discussion
文献报道最新的方法表明,深度学习技术在定量脑部MR图像分析中有巨大的潜能。虽然深度学习方法只是最近被用于脑部MRI,但看起来比先前最好的机器学习方法,变得越来越成熟。由于复杂的脑解剖和它表现的多样性,由于成像协议的不同而导致的非标准的MR灰度,图像采集的缺陷,病理的从在,对于计算机辅助技术,脑图象分析一直是一个巨大的挑战。那么就需要像深度学习这样处理这些变异的更加泛化的技术。
尽管是一个有意义的突破,但深度学习的潜能仍然被限制,因为医学图像数据集相对小,这就限制了这种方法的能力,不能显示它的全部能力,这种能力已经在大的数据集上显示。尽管有作者报道他们的监督学习架构要求仅仅一个训练样本,但大多数作者报告他们的结果随着数据集的增加而稳定提高。对于深度学习方法的有效应用急需大规模的数据集。或者数据集的数量可以通过对原始数据的随机变换,比如抖动,旋转,变换,变形等来有效增加。机器学习算法中经常使用这种办法,被称为数据增强。数据增强帮助增加训练样本的个数,并且通过引入原始数据的随机变换来减小过拟合。多个研究报告数据增强在他们的研究中非常有用。
为了提高深度学习方法,一些步骤是非常重要的,包括,数据预处理,数据后处理,网络权重初始化,阻止过拟合。数据预处理扮演了一个关键角色,多重数据预处理已经被应用到最近的研究中。比如,使得输入脑部MR图像灰度在同一个参考比例,并且对对每种形态进行正则化。这避免了在输出模型中由于任何modality和灰度的不同而使得结构的真正pattern被抑制。模型输出的后处理对于精调分割结果非常重要。任何学习方法的目的是得到一个完美的预测,但是图像上总有一些区域会有不同类重叠,被称为部分体积效应,这不可避免的导致了假阳性或假阴性。这些区域要求额外的预处理来精确量化。另一个非常重要的步骤是神经网络合适的网络参数初始化,来保证整个网络的梯度流动,并且能够收敛。不然激活和梯度流动会消失,且导致不收敛和不学习。随机权重初始化已经被用到了大多数最近的研究中。最近,阻止过拟合对于学习图片中正确的信息非常关键,避免提供的特定的训练集过拟合。神经网络特别容易过拟合,因为参数太多,但训练数据有限。一些策略被用来阻止过拟合,比如,引入数据随机变化性来进行数据增强,使用dropout在训练中随机去掉网络节点,L1/L2正则化引入权重惩罚。
Semantic-wise架构接受任何大小的输入,生成分类映射而patch-wise CNN架构接受固定大小的输入,并且产生非空间输出。因此,semantic-wise架构对图像的每个像素产生预测结果比patch-wise架构更快。另一方面,相对于semantic-wise架构的全图训练,在一个数据集上对patches进行随机采样,潜在的促进更快的收敛。Semantic-wise架构易受类别不平衡影响,但这可以通过在损失函数中加权来解决。Cascaded架构,比如patch-wise架构加一个semantic架构,可以解决单独架构的问题,并且提高输出结果。
开发一种通用的深度学习方法,能够适用于从不同机器不同机构产生的数据任然是一个挑战,原因是,有限的训练数据和有label的数据,图像采集协议的不同,每个MRI采集器的不完美,健康和病理脑组织的表现不同。到目前为止,现在可用的方法都是随机初始化,并且在有限数据集上训练。为了提高深度学习架构的一般化,我们可以采用一个表现好的深度学习网络,在一个大的数据集上训练,然后再一个小数据集上针对一个特定问题进行微调,这种方法被称为迁移学习。已经表明,将预训练的好的具有一般性网络的权重转移到新网络,然后在特定数据集上训练的效果比随机初始化网络权重要好。迁移学习的效果和能否成功依赖于数据集之间的相似性。比如,使用拿ImageNet训练的与训练模型,如果没有更深的训练,在医学图像上可能表现不好。Shin等人报告,他们已经使用拿ImageNet预训练的模型,使用迁移学习并通过在淋巴结和肺间质疾病微调,而不是从头开始训练,获得了最好的结果。另一方面,ImageNet数据集实质上与医学图像数据集非常不同,因此使用从ImageNet训练的迁移学习,对于医学图像来说也许不是最好的选择。
Summary
尽管深度学习技术对脑部MRI的定量分析有巨大冲击,任然很难有一个一般性的方法,对于从不同机构和MRI设备上得到的脑部MR图像的不同种类具有鲁棒性。深度学方法的表现高度依赖于一些关键的步骤,比如:预处理,初始化,后处理。当然,要得到一般化的模型,训练数据集相对于ImageNet来说还很小。更重要的是,现在的深度学习架构依赖于监督学习,并且要求手动标记数据,这对于大规模数据集来说是一项繁琐的任务。因此,需要对脑部MRI不同类型具有鲁棒性,或者具有要求少量有标记数据的非监督学习能力的深度学习模型。除此之外,逼真的模拟脑部MRI数据不同类型的数据增强方法可以减轻对数据量的需求。迁移学习可以被用来分享表现好的深度学习模型,这个模型通过脑部图像检索社区,使用正常的和病理的脑部MRI数据训练,也可以用最少的努力,通过数据集来提高这些方法的泛化能力而不是从头开始训练。