欺诈检测中的不平衡分类
文章目录
-
- 介绍
- 为什么模型可解释性很重要?
- 有哪些方法?
- 倾斜的数据分布
- 平衡数据分布
- 平衡算法
- 评估指标
- Precision-Recall 权衡在欺诈检测中的意义
- 关于权衡的结论
- 使用不平衡数据集进行训练和测试拆分
- 结果
- 平衡效果
- 最好的结果
介绍
对于一些经典的机器学习方法来说,使用不平衡的数据集可能是一个问题,但是,在某些情况下,类之间的数据自然分布并不相等。这是典型的欺诈检测问题。使用来自 Kaggle 的数据集,我们可以看到有很多合法交易,只有0.17%的总数据是欺诈. 在数据分布不平衡的分类问题中,研究通常侧重于识别稀有数据。机器学习模型的性能应该主要根据少数类别的预测结果来衡量。它将展示如何选择正确的指标来验证模型以及在我们的情况下Precision-Recall权衡的实际意义。 最后,将重点介绍如何处理倾斜的类分布,并查看使用不同机器学习算法获得的结果。
为什么模型可解释性很重要?
在欺诈检测中,不仅最终的预测很重要,而且导致系统得出该结论的原因也重要。银行可以使用自动欺诈分类系统来检测可疑情况。发出警报后,银行员工可能会分析导致我们的系统识别假想欺诈的原因,并由专家做出最终决定。如果一个模型不能解释原因,它就永远不能被当局使用或用于法律目的。
当然,它并不总是那么重要,但是拥有一个可以解释分类原因的模型可能非常重要。
有哪些方法?
可以使用不同的方法检测欺诈行为。各种研究显示了基于神经/深度网络或经典机器学习算法的解决方案。
像神经网络这样的工具通常是黑盒模型。因此,试图获取规则或交易被神经网络以某种方式分类的原因可能非常困难,尽管如前所述,这些信息在欺诈检测中可能非常重要。像决策树这样经过训练的基于树的模型可以让我们了解系统为每个分类标签(欺诈或非欺诈)推断出的规则)。这很容易,您只需按照分类树从根到叶的路径即可了解分类标准。最后,神经网络是非常强大的方法,但有时不需要使用此类工具,经典的机器学习方法可能足以获得良好的结果。我们将训练和测试以下方法:
- 决策树
- 随机森林
- Xgboost
- 逻辑回归
- 支持向量机
- K-NN

倾斜的数据分布
分类器对偏度可能是健壮的,也可能不是。少数类可以作为不平衡数据集中统计模型的异常值,并且异常值会对模型的性能产生不利影响。一些模型足够健壮,可以处理异常值,但总的来说,问题是受限于使用哪个模型。处理不平衡数据集的挑战在于,机器学习技术通常会忽略它们,总而言之,它会导致少数类的表现不佳,尽管通常它应该是最重要的结果。关于这个问题,最佳实践可能是平衡数据并进行偏度消除过程。在不平衡的数据集上训练机器学习模型会影响我们的模型。
平衡数据分布
这个问题可以通过将数据集转换为具有相同数量的不同类元素的新数据集来解决。有两种可能的解决方案:
- 对多数类进行欠采样。
- 通过创建合成样本对少数类进行过采样。
- 第三种混合方式可以同时应用这两种方法:过采样和欠采样。
为什么这些策略有效?使用欠采样策略,假设多数类的一些记录是冗余的,但是,这种方法的局限性在于,通过删除数据,我们可以删除相关信息。使用过采样策略,创建少数类的合成示例,直到类之间的数据分布相同。这可以平衡类分布,但不会为模型提供任何附加信息。风险是过拟合少数类。
平衡算法
Random under/over-sample:最简单(但效率较低)的方法是删除多数类的随机记录并复制少数类的随机示例。
SMOTE:它通过选择特征空间中接近的示例来工作,首先选择来自少数类的随机示例。然后找到该示例中最近的k个邻居(通常为k=5)。在所选示例与k个邻居中的每一个之间的线上的随机选择点处创建合成示例。该方法是有效的,因为来自少数类的新合成示例在特征空间中与来自少数类的现有示例相对接近。

ADASYN:它与SMOTE非常相似。创建这些样本后,它会为这些点添加一个随机的小值,从而使其更加逼真。不是所有样本都与父样本线性相关,而是它们有更多的方差。
SMOTE TOMEK:应用SMOTE对少数类进行过采样。为了减少异常值,Tomek Link 应用于少数类和多数类。Tomek 链接是一个数据清理和异常值删除过程。如果它们中的每一个都更接近另一个类的示例而不是同一类的一个示例,它会删除 2 条不同类的记录。【(a) 原始数据集;(b) 过采样数据集;©Tomek 链接识别;(d) 去除边界和噪声示例。】
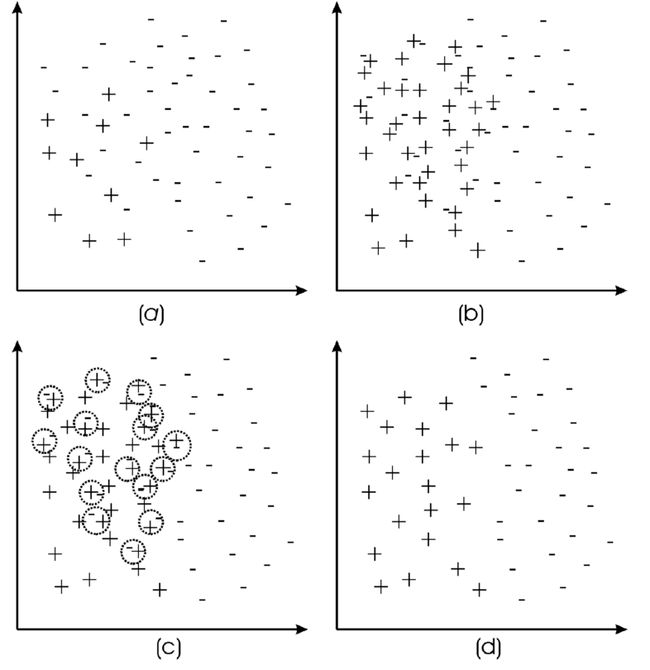
SMOTE ENN:与SMOTE TOMEK一样,清理和异常值检测过程更有效。举个例子,它是基于一个k最近邻的过程来决定是否应该删除一条记录。如果处理过程过于激进,我们可能会丢失重要信息。
评估指标
在机器学习中,有多种评估分类模型的方法。最常用的指标是准确度。它告诉我们在全部记录中正确分类了多少实例。在数据分布偏斜、类间数据不平衡程度较高的场景下,通常使用Precision、Recall、F-score和AUC等指标。
为什么准确性不是正确的指标?如果我们假设在我们的不平衡数据集中有95个正常交易实例并且只有5 个欺诈行为,那么始终预测非欺诈行为的虚拟预测模型将获得95%的准确率,而不会发现任何欺诈行为。这就是为什么当我们使用不平衡的数据集时,模型评估不使用准确性的原因。
Precision 和 Recall都很重要,它们告诉我们预测系统所取得的结果的不同之处,这些指标与Fraud(交易特征)有关,因为这是我们更感兴趣的。
Precision:当一笔交易被归类为欺诈时,精确度的值可以让我们了解系统如何确信如果它预测欺诈,则该交易是真正的欺诈。这是精度公式
![]()
Recall:召回的价值可以让我们了解系统如何有信心抓住所有欺诈行为。这是召回公式:
![]()
Precision-Recall 权衡在欺诈检测中的意义
完美的预测模型应该检测数据集中的所有欺诈行为,并确保每个预测的欺诈行为都是真实的欺诈行为。用我们的指标进行翻译意味着具有高召回率(检测所有欺诈)和高精度(预测为欺诈的交易的错误尽可能少)。Precision-recall 是一种权衡,当你试图优化精度时,召回率的价值会降低,反之亦然。
优化Precision是什么意思?我们将非常有信心预测为欺诈的交易是真正的欺诈,我们将调整分类器的参数,使其仅将很有可能是真正欺诈的交易预测为欺诈。缺点是无法检测到一些欺诈交易,可能是与非欺诈最相似的交易。系统将丢失一些将它们归类为正常的欺诈交易,这可能是一个问题。
优化Recall是什么意思?我们将非常有信心检测到所有欺诈行为,我们将调整分类器的参数,使其能够检测到尽可能多的欺诈行为。缺点是在尝试检测所有欺诈时,与欺诈相似的正常交易也会被归类为欺诈。
关于权衡的结论
Precision-recall是一种权衡,我们更喜欢Precision优化,我们检测到的欺诈更少,我们正在减少recall。更喜欢recall优化,我们检测到更多欺诈,但可能会发生其中一些被错误分类并且精度值会降低的情况。您可以选择一个指标而不是另一个指标,但重要的是始终牢记这两个指标。例如,一个模型达到 99% 的准确率和 15% 的召回率,它就不是一个好的预测器,因为即使它有非常高的准确率,它也无法检测到 85% 的欺诈!
我们不知道哪个指标比另一个更重要,这取决于我们的模型用于特定的用例。在某些情况下,检测所有欺诈行为可能更重要,如果存在误报(召回优化)则无关紧要,在其他情况下,我们更喜欢警报更少但精度更高。
使用不平衡数据集进行训练和测试拆分
使用平衡算法(例如SMOTE),我们将修改原始数据集,我们正在创建新示例,并删除其他示例。如果操作不当,可能会导致数据泄漏,我们希望避免这种情况。训练测试拆分过程必须在数据操作(如平衡)之前完成。这样,测试集将高度不平衡,这没关系,因为我们希望像在真实场景中一样测试我们的模型。我们只想为训练过程平衡数据。
结果
在显示结果之前,我们必须了解我们正在搜索的信息类型。回答一些简单的问题可以帮助我们了解我们的研究可以继续往哪个方向发展。
- 平衡方法有效吗?总是或仅在某些情况下?
- 哪种分类方法最好,性能如何?
平衡效果
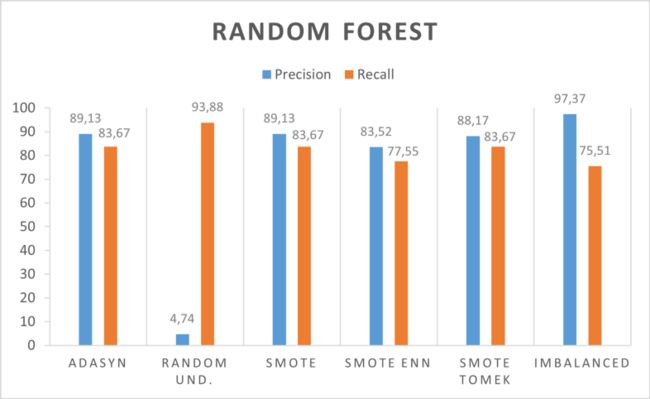
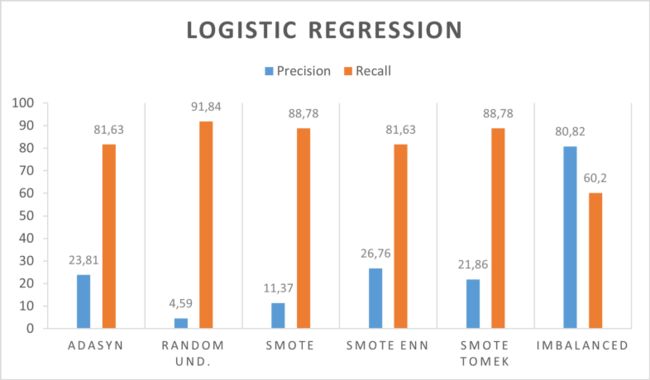
该模型已经使用不同的机器学习算法进行了训练:决策树、随机森林、XGBOOST、SVM、LOGISTIC REGRESSION、K-NN。
平衡过程已使用之前显示的所有方法完成:RANDOM、SMOTE、ADASYN、SMOTE ENN、SMOTE TOMEK、IMBALANCED。
随机森林
决策树

XGBOOST

支持向量机

逻辑回归
K-NN

一些显示的方法在不平衡和平衡的数据上都达到了良好的效果。决策树和逻辑回归对不平衡数据有很好的效果。SVM受益于平衡过程,精度达到+54%。
一个有趣的结果是使用Random Forest、XGBoost和K-nn获得的结果。平衡过程导致召回率增加,这似乎是合理的。在平衡过程中,我们将增加模型在训练中看到的欺诈数量。通过这种方式,它将获得有关欺诈行为的更多信息,并且会识别出更多信息。
最好的结果
我们将展示使用不同方法获得的最有趣的结果。

使用Random Forest和XGBoost可获得最佳结果。此外,K-NN有有趣的结果,但我们更喜欢其他模型,因为预测模型可以在实时系统中使用,并且由于每个分类的计算复杂性,k-nn 不是最佳解决方案。逻辑回归和SVM有两种不同的行为。第一个在准确率上表现良好,第二个在召回率上表现良好。决策树非常适合处理不平衡的数据,并且结果越来越接近最好的分类器之一。
最好的分类器是随机森林和XGBoost。如前所述,如果我们更喜欢优化一个指标而不是另一个指标,那么平衡过程可能是一个重要的工具。平衡过程导致召回的增加,如果我们想检测更多的欺诈行为,这是一个重要的结果。
机器学习专栏:机器学习入门到大神
公众号:玩转大数据 CSDN:川川菜鸟