用通俗易懂的方式讲解:逻辑回归模型及案例(Python 代码)
目录
-
- 1 简介
- 2 优缺点
- 3 适用场景
- 加入方式
- 4 案例:客户流失预警模型
-
- 4.1 读取数据
- 4.2 划分特征变量和目标变量
- 4.3 模型搭建与使用
-
- 4.3.1 划分训练集与测试集
- 4.3.2 模型搭建
- 4.3.3 预测数据结果及准确率
- 4.3.4 预测概率
- 5 获取逻辑回归系数
- 6 代码汇总
- 7 模型评估方法:ROC曲线与KS曲线
-
- 7.1 ROC曲线
-
- 7.1.1 ROC介绍
- 7.1.2 混淆矩阵的Python代码实现
- 7.1.3 案例:用ROC曲线评估客户流失预警模型
- 7.1.4 阈值的取值方法
- 7.2 KS曲线
-
- 7.2.1 KS介绍
- 7.2.2 案例:用KS曲线评估客户流失预警模型
1 简介
逻辑回归也被称为广义线性回归模型,它与线性回归模型的形式基本上相同,最大的区别就在于它们的因变量不同,如果是连续的,就是多重线性回归;如果是二项分布,就是Logistic回归。
Logistic回归虽然名字里带“回归”,但它实际上是一种分类方法,主要用于二分类问题(即输出只有两种,分别代表两个类别),也可以处理多分类问题。
线性回归是用来预测连续变量的,其取值范围(-∞,+∞),而逻辑回归模型是用于预测类别的,例如,用逻辑回归模型预测某物品是属于A类还是B类,在本质上预测的是该物品属于A类或B类的概率,而概率的取值范围是0~1,因此不能直接用线性回归方程来预测概率,此时就涉及到Sigmoid函数,可将取值范围为(-∞,+∞)的数转换到(0,1)之间。如下图所示。
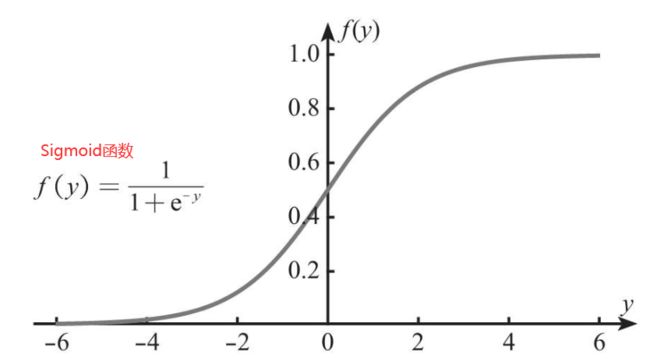
总结来说,逻辑回归模型本质就是将线性回归模型通过Sigmoid函数进行了一个非线性转换,得到一个介于0~1之间的概率值,对于二分类问题(分类0和1)而言,其预测分类为1(或者说二分类中数值较大的分类)的概率可以用如下所示的公式计算。

因为概率和为1,则分类为0(或者说二分类中数值较小的分类)的概率为1-P。
逻辑回归模型的本质就是预测属于各个分类的概率,有了概率之后,就可以进行分类了。
2 优缺点
优点:速度快,适合二分类问题;简单、易于理解,可以直接看到各个特征的权重;能容易地更新模型吸收新的数据。
缺点:对数据和场景的适应能力有局限性,不如决策树算法适应性强。
3 适用场景
·寻找危险因素:寻找某一疾病的危险因素等;
·预测:根据模型,预测在不同的自变量情况下,发生某种疾病或某种情况的概率有多大;
·判别:实际上跟预测有些类似,也是根据模型,判断某人属于某种疾病或属于某种情况的概率有多大。
加入方式
喜欢本文点赞、关注、收藏。本文来自技术群小伙伴分享,完整版代码、技术交流都欢迎入群获取
目前开通了技术交流群,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到更快获取资料、入群
方式①、添加微信号:dkl88191,备注:来自CSDN+加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
4 案例:客户流失预警模型
4.1 读取数据
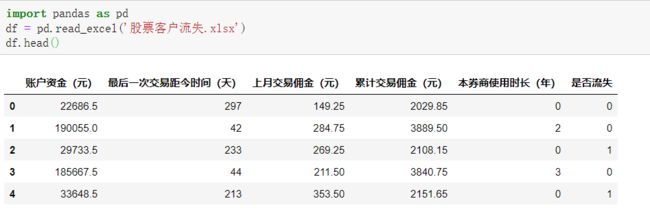
df中共有约7000组历史数据,其中约2000组为流失客户,约5000组为未流失客户。
将“是否流失”作为目标变量,其他字段作为特征变量,通过一个客户的一些基本情况和交易记录来预测他是否会流失,或者说判断流失的概率大小。
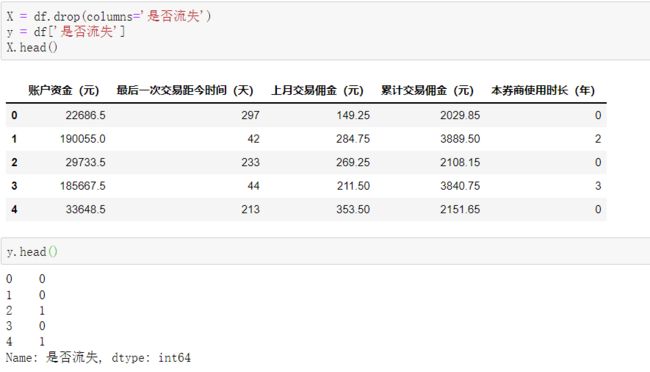
4.2 划分特征变量和目标变量
4.3 模型搭建与使用
4.3.1 划分训练集与测试集
训练集用于训练数据和搭建模型,测试集则用于检验训练后所搭建模型的效果。
划分训练集和测试集的**目的:**一是为了对模型进行评估,二是可以通过测试集对模型进行调优。
划分训练集和测试集在某种程度上也是为了检查模型是否出现过拟合。
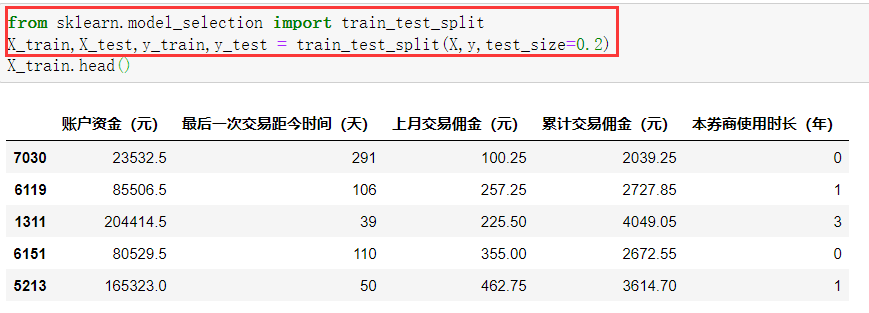
用**train_test_split()**函数划分训练集和测试集,X_train、y_train为训练集的特征变量和目标变量数据,X_test、y_test则为测试集的特征变量和目标变量数据。train_test_split()函数的参数中,X和y便是之前划分的特征变量和目标变量;test_size则是测试集数据所占的比例,这里选择的是0.2,即20%。
每次运行程序时,train_test_split()函数都会随机划分数据,如果想要让每次划分数据的结果保持一致,可以设置random_state参数,代码如下。
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1)
为random_state参数赋值为1,该数字没有特殊含义,可以换成其他数字,它相当于一个种子参数,使得每次划分数据的结果一致。
4.3.2 模型搭建

4.3.3 预测数据结果及准确率
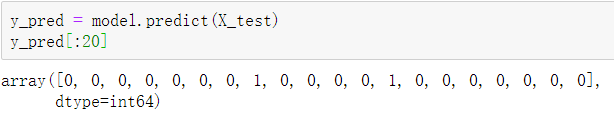
y_pred是一个numpy.ndarray类型的一维数组结构,y_test为Series类型的一维序列结构,用list()函数将它们都转换为列表,再将它们集成到一个DataFrame中,代码如下。
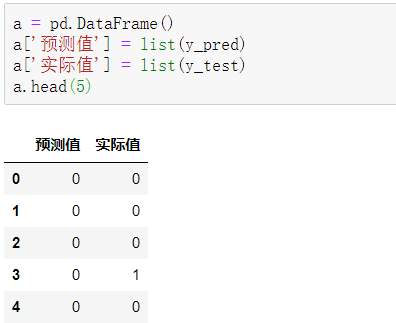
可以看到,前5项的预测准确度为80%。
如果想查看所有测试集数据的预测准确度,可以使用如下代码。
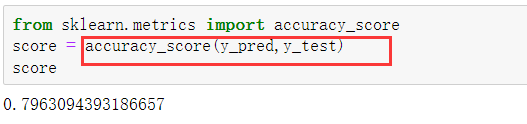
除了使用accuracy_score()函数,还可以使用模型自带的score()函数来计算预测准确度,代码如下,其结果同样为0.7963。
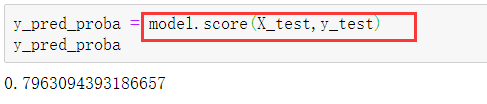
4.3.4 预测概率
逻辑回归模型的本质是预测概率,而不是直接预测具体类别。通过如下代码就可以获取概率值。
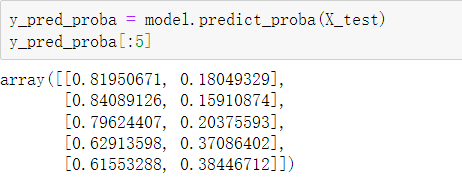
通过打印y_pred_proba[0:5]查看结果的前5项,结果是一个二维数组,数组左列是不流失(分类为0)概率,右列是流失(分类为1)概率。或者这样显示:

5 获取逻辑回归系数
逻辑回归模型在本质上是将线性回归模型通过Sigmoid函数进行非线性转换。本案例共有5个特征变量,所以预测y=1(流失)的概率P的公式如下。

通过coef_属性可以获取特征变量前的系数ki,通过intercept_属性可以获取截距项k0。

6 代码汇总
# 1.读取数据
import pandas as pd
df = pd.read_excel('股票客户流失.xlsx')
# 2.划分特征变量与目标变量
X = df.drop(columns='是否流失')
y = df['是否流失']
# 3.划分数据集与测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
# 4.模型搭建
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train,y_train)
# 5.预测分类结果
y_pred = model.predict(X_test)
y_pred[:20]
# 6.预测概率
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[:5]
# 7.模型准确率
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_pred,y_test)
# 或者
y_pred_accuracy = model.score(X_test,y_test)
7 模型评估方法:ROC曲线与KS曲线
模型搭建完成后,还需要对模型的优劣进行评估。
对于二分类模型来说,主流的评估方法有ROC曲线和KS曲线两种。
7.1 ROC曲线
7.1.1 ROC介绍
在商业实战中,更关心下表中的两个指标。

其中TP、FP、TN、FN的含义见下表,这个表也被称为混淆矩阵。

以上述案例为例,7000个客户中实际有2000个客户流失,假设模型预测所有客户都不会流失,那么模型的假警报率(FPR)为0,即没有误伤一个未流失客户,但是此时模型的命中率(TPR)也为0,即没有揪出一个流失客户,见下表。

总体来说,命中率计算的是所有实际流失(分类为1)的客户中被预测为流失的客户所占的比例,也称真正率或召回率;而假警报率计算的则是所有实际未流失(分类为0)的客户中被预测为流失的客户所占的比例,也称假正率。可通过如下公式来帮助理解并加深记忆。

一个优秀的客户流失预警模型,命中率(TPR)应尽可能高,即能尽量揪出潜在流失客户,同时假警报率(FPR)应尽可能低,即不要把未流失客户误判为流失客户。然而这两者往往成正相关,因为如果调高阈值,例如认为流失概率超过90%才认定为流失,那么会导致假警报率很低,但是命中率也很低;
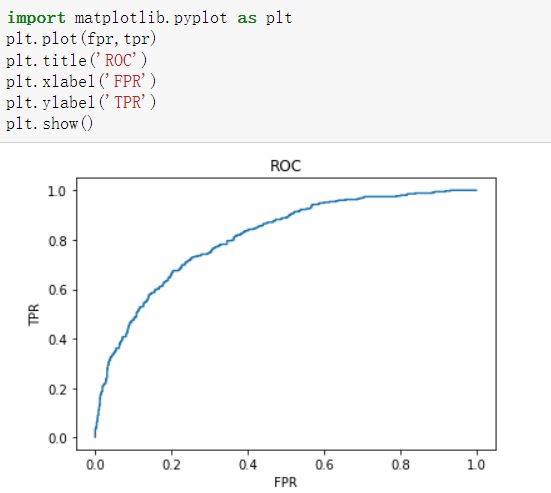
而如果调低阈值,例如认为流失概率超过10%就认定为流失,那么命中率就会很高,但是假警报率也会很高。因此,为了衡量一个模型的优劣,根据不同阈值下的命中率和假警报率绘制了ROC曲线,如下图所示,其中横坐标为假警报率(FPR),纵坐标为命中率(TPR)。

如果把假警报率理解为代价的话,那么命中率就是收益,所以也可以说在阈值相同的情况下,希望假警报率(代价)尽可能小,命中率(收益)尽可能高,该思想反映在图形上就是ROC曲线尽可能地陡峭。
曲线越靠近左上角,说明在相同的阈值条件下,命中率越高,假警报率越低,模型越完善。换一个角度来理解,一个完美的模型是在不同的阈值条件下,假警报率都接近于0,而命中率都接近于1,该特征反映在图形上就是ROC曲线非常接近(0,1)这个点,即曲线非常陡峭。
7.1.2 混淆矩阵的Python代码实现

可以看到,实际流失的348(192+156)人中有156人被准确预测,命中率(TPR)为45%;实际未流失的1061(968+93)人中有93人被误判为流失,假警报率(FPR)为8.8%。需要注意的是,这里的TPR和FPR都是在阈值为50%的条件下计算的。
通过如下代码计算命中率,无须手动计算。
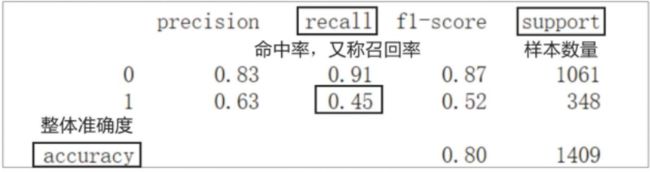
precision(精准率)和f1-score。

7.1.3 案例:用ROC曲线评估客户流失预警模型
在商业实战中,我们希望在阈值相同的情况下,假警报率尽可能小,命中率尽可能高,该思想反映在图形上,就是ROC曲线非常接近(0,1),即曲线非常陡峭。
用曲线来描述会比较抽象,在数值上可以使用AUC值来衡量模型的好坏。**AUC值(AreaUnder Curve)**指ROC曲线下方的面积,该面积的取值范围通常为0.5~1,0.5表示随机判断,1则代表完美的模型。在商业实战中,因为存在很多扰动因子,AUC值能达到0.75以上就已经可以接受,如果能达到0.85以上,就是非常不错的模型。
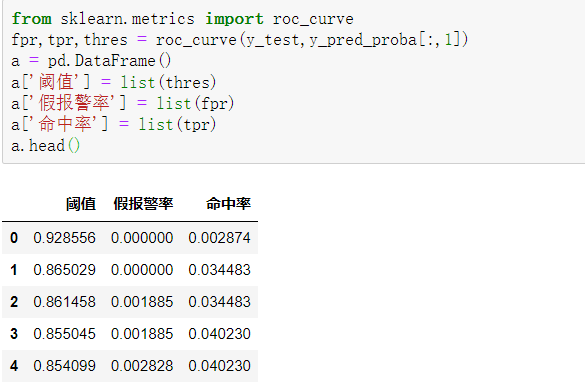
在Python中,通过如下代码就可以求出不同阈值下的命中率(TPR)和假警报率(FPR)的值,从而绘制出ROC曲线。
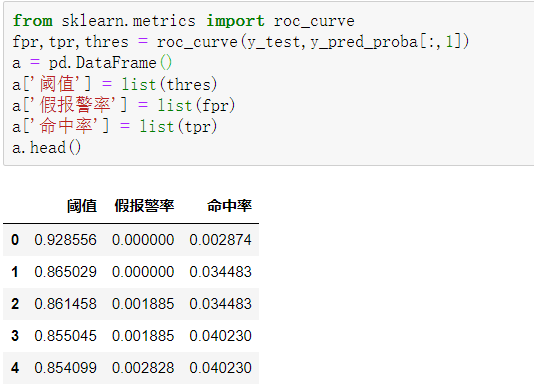
roc_curve()函数返回的是一个含有3个元素的元组,其中默认第1个元素为假警报率,第2个元素为命中率,第3个元素为阈值,所以这里将三者分别赋给变量fpr(假警报率)、tpr(命中率)、thres(阈值)。
通过如下代码则可以快速求出模型的AUC值。
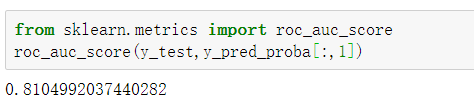
获得的AUC值为0.81,可以说预测效果还是不错的。
7.1.4 阈值的取值方法
在测试样本中,对预测分类为1的概率进行排序,使用sort_values()函数,并设置ascending参数为False进行降序排列。得到如下结果。
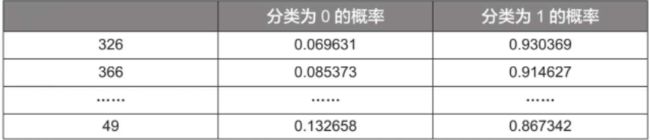
可以看到,序号326的样本其分类为1的概率最高,为0.930369,这个概率就是之前提到的阈值(在之前的表格中,它是除1.930369外最大的阈值)。
所有样本的分类就是根据这个阈值进行的,分类为1的概率小于该阈值的样本都被列为分类0,大于等于该阈值的样本都被列为分类1,因为只有序号326的样本满足分类为1的概率大于等于该阈值,所以只有该样本会被列为分类1(实际上该样本也的确为分类1),其余样本都被列为分类0。由上可知,一共有348个实际分类为1的样本,所以此时命中率(TPR)为1/348=0.002874,与通过程序获得的结果是一致的。
至此,可以得出结论,这些阈值都是各个样本分类为1的概率(其实并没有全部都取,例如,序号366的样本分类为1的概率就没有被取为阈值)。
7.2 KS曲线
7.2.1 KS介绍
KS曲线和ROC曲线在本质上是相同的,同样关注命中率(TPR)和假警报率(FPR),希望命中率(TPR)尽可能高,即尽可能揪出潜在流失客户,同时也希望假警报率(FPR)尽可能低,即不要把未流失客户误判为流失客户。
区别于ROC曲线将假警报率(FPR)作为横坐标,将命中率(TPR)作为纵坐标,KS曲线将阈值作为横坐标,将命中率(TPR)与假警报率(FPR)之差作为纵坐标,如下图所示。
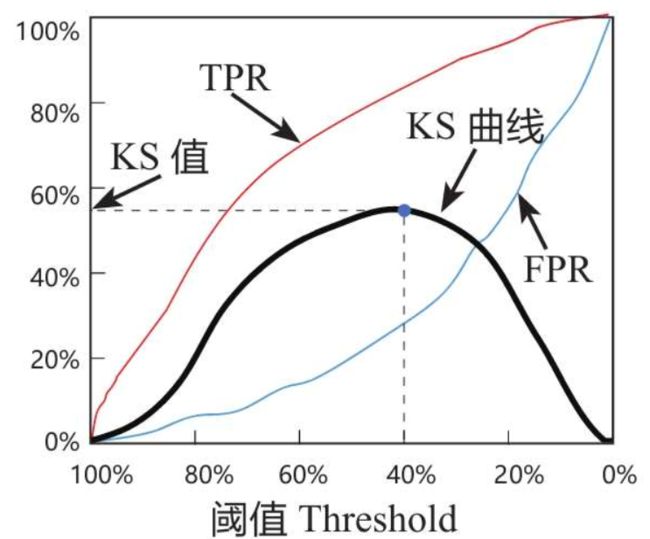
使用KS值来衡量模型预测效果。

KS值就是KS曲线的峰值。 具体来说,每一个阈值都对应一个(TPR-FPR)值,那么一定存在一个阈值,使得在该阈值条件下,(TPR-FPR)值最大,那么此时的(TPR-FPR)值便称为KS值。例如,上图中当阈值等于40%时,命中率(TPR)为80%,假警报率(FPR)为25%,所以(TPR-FPR)值为55%,该值是所有阈值条件下最大的(TPR-FPR)值,因此,这个模型的KS值为55%。
用更通俗易懂的话来说,该模型在阈值为40%时能尽可能地识别坏人,并尽可能地不误伤好人,此时命中率(TPR)减去假警报率(FPR)的差值为55%,即该模型的KS值。
一般情况下,我们希望模型有较大的KS值,因为较大的KS值说明模型有较强的区分能力。
不同取值范围的KS值的含义如下:
·KS值小于0.2,一般认为模型的区分能力较弱;
·KS值在\[0.2,0.3\]区间内,模型具有一定区分能力;
·KS值在\[0.3,0.5\]区间内,模型具有较强的区分能力。
但KS值也不是越大越好,如果KS值大于0.75,往往表示模型有异常。在商业实战中,KS值处于[0.2,0.3]区间内就已经算是挺不错的了。
7.2.2 案例:用KS曲线评估客户流失预警模型
通过如下代码求出在不同阈值下的假警报率(FPR)和命中率(TPR),从这一点也可以看出KS曲线和ROC曲线其实是同根同源的。

第1~3行代码绘制的曲线均以阈值为横坐标,而纵坐标分别为命中率、假警报率及两者之差。因为表格第1行中的阈值大于1,无意义,会导致绘制出的图形不美观,所以通过切片的方式将第1行剔除,其中thres[1:]、tpr[1:]、fpr[1:]都表示从第2个元素开始绘制。
第6行代码反转x轴,即把阈值从大到小排序再绘制KS曲线。具体来说,先用gca()函数(gca代表get current axes)获取坐标轴信息,再用invert_xaxis() 函数反转x轴。
通过如下代码则可以快速求出KS值。
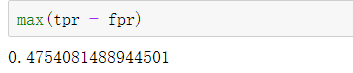
打印输出该KS值,结果为0.4754,在[0.3,0.5]区间内,因此,该模型具有较强的区分能力。