机器学习-集成学习-梯度提升决策树(GBDT)
目录
1. GBDT算法的过程
1.1 Boosting思想
1.2 GBDT原理
需要多少颗树
2. 梯度提升和梯度下降的区别和联系是什么?
3. GBDT的优点和局限性有哪些?
3.1 优点
3.2 局限性
4. RF(随机森林)与GBDT之间的区别与联系
5. GBDT与XGBoost之间的区别与联系
6. 代码实现
1. GBDT算法的过程
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,或GBRT(Gradient Boosting Regressor Tree)梯度提升回归树,使用的是Boosting(提升)的思想。
1.1 Boosting思想
提升树(Boosting Tree)是以分类树或者回归树位基本分类器到提升方法,提升树被认为是统计学习中性能最好的方法之一
Boosting方法训练基分类器时采用串行的方式,各个基分类器之间有依赖。它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重(Ada Boosting),或者让新的预测器对前一个预测器到残差进行拟合(GBDT)。预测时,根据各层分类器的结果的加权得到最终结果。
Bagging与Boosting的串行训练方式不同,Bagging方法在训练过程中,各基分类器之间无强依赖,可以进行并行训练。
1.2 GBDT原理
GBDT的原理很简单,首先,在训练集上拟合一个DecisonTreeRegressor;
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)然后针对第一个预测器到残差,训练第二个DecisonTreeRegressor;
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)然后针对针对第二个预测器到残差,训练第三个DecisonTreeRegressor;
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg3.fit(X, y3)现在我们有一个包含三颗树到机场,将这三颗树到预测结果相加,从而对新的实例进行预测。
y_pred = tree_reg1 + tree_reg2 + tree_reg3单个预测器是弱分类器,可以通过弱分类器构建强分类器,就是所有弱分类器的结果相加等于预测值,它里面的弱分类器的表现形式就是各棵树。
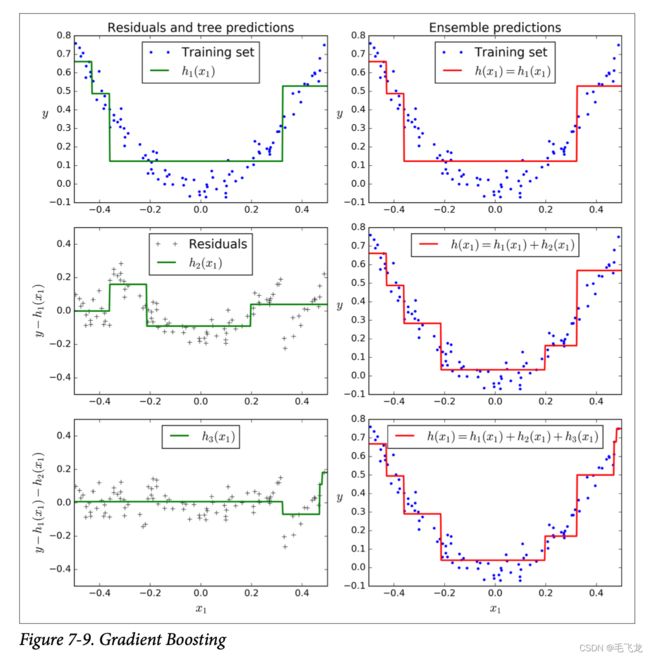
下图7-9是GBDT的一个例子,左边表示三颗树单独到预测,右边表示集成预测。第一行集成只有一颗树,因此它的预测与第一颗树完全相同。第二行左侧是在第一颗树残差上训练的一颗新树,由侧的继承预测则是前面两颗树之和。类似的,左侧第三行树又是在第二颗树的残差上训练的新树,集成预测随着新数的增加越来越好。
举另外一个例子,比如我今年30岁了,但计算机或者模型GBDT并不知道我今年多少岁,那GBDT咋办呢?
- 它会在第一个弱分类器(或第一棵树中)随便用一个年龄比如20岁来拟合,然后发现误差有10岁;
- 接下来在第二棵树中,用6岁去拟合剩下的损失,发现差距还有4岁;
- 接着在第三棵树中用3岁拟合剩下的差距,发现差距只有1岁了;
- 最后在第四课树中用1岁拟合剩下的残差,完美。
- 最终,四棵树的结论加起来,就是真实年龄30岁(实际工程中,gbdt是计算负梯度,用负梯度近似残差)。
为何GBDT可以用负梯度近似残差呢?
回归任务下,GBDT 在每一轮的迭代时对每个样本都会有一个预测值,此时的损失函数为均方差损失函数,
![]()
那此时的负梯度是这样计算的
![]()
所以,当损失函数选用均方差函数时,负梯度就是残差。
训练过程
简单起见,假定训练集只有4个人:A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图所示结果:
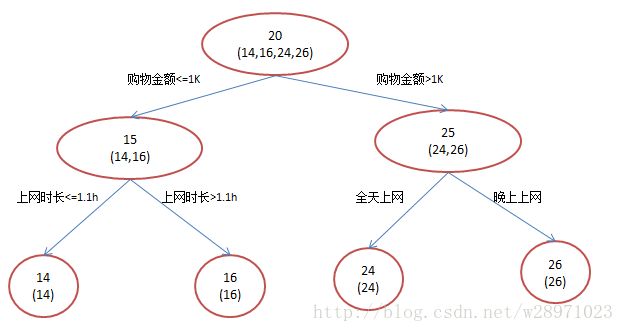
现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图所示结果:
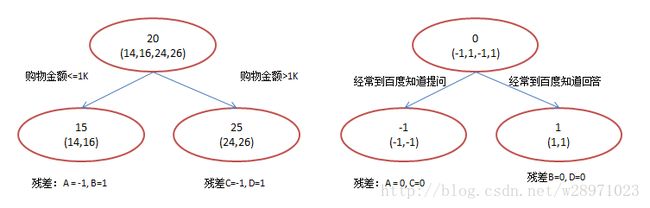
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为左右两拨,每拨用平均年龄作为预测值。
- 此时计算残差(残差的意思就是:A的实际值 - A的预测值 = A的残差),所以A的残差就是实际值14 - 预测值15 = 残差值-1。
- 注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值。
然后拿它们的残差-1、1、-1、1代替A B C D的原值,到第二棵树去学习,第二棵树只有两个值1和-1,直接分成两个节点,即A和C分在左边,B和D分在右边,经过计算(比如A,实际值-1 - 预测值-1 = 残差0,比如C,实际值-1 - 预测值-1 = 0),此时所有人的残差都是0。残差值都为0,相当于第二棵树的预测值和它们的实际值相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!
- A: 14岁高一学生,购物较少,经常问学长问题,预测年龄A = 15 – 1 = 14
- B: 16岁高三学生,购物较少,经常被学弟问问题,预测年龄B = 15 + 1 = 16
- C: 24岁应届毕业生,购物较多,经常问师兄问题,预测年龄C = 25 – 1 = 24
- D: 26岁工作两年员工,购物较多,经常被师弟问问题,预测年龄D = 25 + 1 = 26
所以,GBDT需要将多棵树的得分累加得到最终的预测得分,且每一次迭代,都在现有树的基础上,增加一棵树去拟合前面树的预测结果与真实值之间的残差。
需要多少颗树
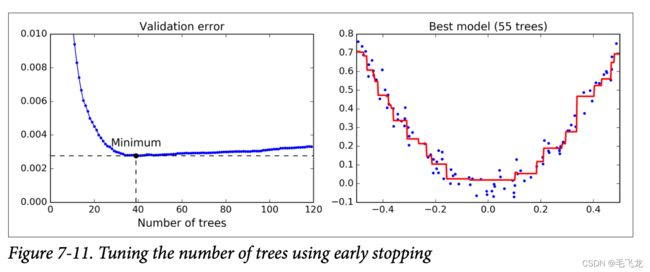
树的数目太少了容易拟合不足,数量太大容易过拟合。要寻找树的最佳数量,可以使用早期停止法。实现方法是使用staged_predict()方法:在训练的每个阶段(一棵树时、两颗树时,等等)对集成预测返回一个迭代器,然后测量每个阶段的验证集误差,当连续5次迭代未改善时,当前的树都数量就是一个合适的数量。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=49)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120, random_state=42)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors) + 1
gbrt_best = GradientBoostingRegressor(max_depth=2, n_estimators=bst_n_estimators, random_state=42)
gbrt_best.fit(X_train, y_train)下图为训练120颗树验证集误差随着树数量的变化,从误差上可以找到树的最佳数量。
2. 梯度提升和梯度下降的区别和联系是什么?
两者都是在每 一轮迭代中,利用损失函数相对于模型的负梯度方向的信息来对当前模型进行更 新,只不过在梯度下降中,模型是以参数化形式表示,从而通过对参数的更新来对模型进行更新的。而在梯度提升中,模型并不需要进行参数化表示,而是直接定义在函数空间中,是通过增加模型来对集成模型进行更新。
3. GBDT的优点和局限性有哪些?
3.1 优点
- 预测阶段的计算速度快,树与树之间可并行化计算。
- 在分布稠密的数据集上,泛化能力和表达能力都很好,这使得GBDT在Kaggle的众多竞赛中,经常名列榜首。
- 采用决策树作为弱分类器使得GBDT模型具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系,并且也不需要对数据进行特殊的预处理如归一化等。
3.2 局限性
- GBDT在高维稀疏的数据集上,表现不如支持向量机或者神经网络。
- GBDT在处理文本分类特征问题上,相对其他模型的优势不如它在处理数值特征时明显。
- 训练过程需要串行训练,只能在决策树内部采用一些局部并行的手段提高训练速度。
4. RF(随机森林)与GBDT之间的区别与联系
相同点:
都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:
1. 从模型框架上看,随机森林是bagging,树可以并行生成,而GBDT是boosting,串行生成
2. 从偏差分解的角度来看,随机森林是减少模型的方差,而GBDT是减少模型的偏差

3. 从模型的训练要求上
- 组成随机森林的树可以分类树也可以是回归树,而GBDT只由回归树组成
- 随机森林的结果是多数表决表决的,而GBDT则是多棵树累加之和
- 随机森林对异常值不敏感,而GBDT对异常值比较敏感
- 随机森林不需要进行特征归一化。而GBDT则需要进行特征归一化
5. GBDT与XGBoost之间的区别与联系
XGBoost全名eXtreme Gradient Boosting,在数据竞赛中风靡一时/披荆斩棘,它源于梯度提升框架,但是更加高效,秘诀就在算法能并行计算、近似建树、对稀疏数据的有效处理以及内存使用优化,这使得XGBoost至少比现有梯度提升算法有10倍的速度提升。
也使用与提升树相同的前向分步算法,其区别在于:Xgboost通过结构风险最小化来确定下一个决策树的参数 ,主要区别:
1. 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。例如,xgboost支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)
2. xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
3. 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样(即每次的输入特征不是全部特征),不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
4. 并行化处理:在训练之前,预先对每个特征内部进行了排序找出候选切割点,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行,即在不同的特征属性上采用多线程并行方式寻找最佳分割点。
6. 代码实现
GitHub:ML-NLP/GBDT_demo.ipynb at master · NLP-LOVE/ML-NLP · GitHub
内容整理自
1. ML-NLP/Machine Learning/3.2 GBDT at master · NLP-LOVE/ML-NLP · GitHub
机器学习算法中 GBDT 和 XGBOOST 的区别有哪些? - 知乎 https://www.zhihu.com/question/413543923. Aurelien Geron. Hands-On Machine Learning with Scikit-Learn and TensorFlow
https://www.zhihu.com/question/413543923. Aurelien Geron. Hands-On Machine Learning with Scikit-Learn and TensorFlow
4. GBT、GBDT、GBRT与Xgboost - 知乎https://zhuanlan.zhihu.com/p/57814935