Fairlearn 快速入门
前言
Fairlearn 是一个旨在帮助数据科学家提高人工智能系统公平性的开源项目。目前国内并没有相关教程来讲解这个库的使用方式,所以笔者用一系列博客尽可能详细地教学 Fairlearn 库的使用方法。「在官网教程的基础上加入自己的个人见解。」
Fairlearn 官网
本篇博客是此系列的第一篇,将帮助读者快速入门。
1. Fairlearn 是什么?
Fairlearn 是一个旨在帮助数据科学家提高人工智能系统公平性的开源项目,可以帮助评估和缓解机器学习模型中的不公平。
Fairlearn 库由两个主要部分组成:
-
fairlearn.metrics:用于评估哪些群体的权益受到了侵害,并根据各种公平性规则比较模型的各个指标「例如真阳性率,选择率等等」。 -
去偏算法:去偏算法在 Fairlearn 中有三个具体的包:
fairlearn.postprocessing、fairlearn.preprocessing和fairlearn.reductions,分别对应去偏作用的不同时机。
2. Fairlearn 的安装
FairLearn 的安装支持 pip 和 conda 两种方式。
pip 安装方式
pip install fairlearn
conda 安装方式
conda install -c conda-forge fairlearn
只要能在代码块中 import fairlearn 就表示安装成功。
3. Fairlearn 的快速入门
创建一个 quick_start.ipynb 文件,开始我们的 Fairlearn 快速入门吧~
3.1 导入数据集
这里我们使用 UCI adult 数据集,该数据集可以用于预测个人的年收入是否大于 50K 。
数据集既可以从 sklearn.datasets 获取,也可以从 fairlearn.datasets 得到。
在 notebook 中新建一个单元格,输入以下代码:
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
data = fetch_openml(data_id=1590, as_frame=True) # as_frame 用于确保数据是 Pandas DataFrame
x = pd.get_dummies(data.data) # 对数据进行单热编码
y_true = (data.target == '>50K') * 1 # 大于 50K 为 1,否则为 0
sex = data.data['sex'] # 将 sex 列分离出来
sex.value_counts() # 男性群体和女性群体的数量
运行单元格,我们可以得到以下结果:

从数据可以看出,UCI adult 数据集是一个不平衡的数据集,男性样本数量是女性样本数量的两倍。
3.2 评估模型的公平性
Fairlearn 中提供了和公平相关的指标,可以在不同群体间或者真个数据集上进行比较。
新建一个单元格,在这个单元格中,我们用决策树得到一个模型,然后验证该模型的公平性指标。
from fairlearn.metrics import MetricFrame
# 导入评价指标
from sklearn.metrics import accuracy_score # 预测精度
from sklearn.tree import DecisionTreeClassifier # 决策树
classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4)
classifier.fit(x, y_true) # 训练模型
运行单元格,得到训练好的模型 classifier,接着我们用该模型得到预测结果,评估模型的公平性。
y_pred = classifier.predict(x) # 得到预测结果
gm = MetricFrame(metrics=accuracy_score, y_true=y_true, y_pred=y_pred, sensitive_features=sex)# 根据 sensitive_features 将数据集划分为不同的组
print(gm.overall) # 获取整个数据集的预测精度
print(gm.by_group) # 获取各个群体的预测精度

可以看到,总体预测精度是 0.8443,而女性群体的预测精度是 0.9251,男性群体的预测精度是 0.8042。
在上述代码中,MetricFrame 的第一个参数 metrics 的意思是评估方法,我们选用了 accuracy_score,即预测精度。我们也可以使用其他评估方法,如 selection rate「被预测为正的样本占总样本的比例」,recall_rate**「召回率」**等等。
# selection_rate 是选择为正率 意思是群体中被预测为正的个体占总数的比例
from fairlearn.metrics import selection_rate
sr = MetricFrame(metrics=selection_rate, y_true=y_true, y_pred=y_pred, sensitive_features=sex)
sr.by_group

当我们选择评估方法为选择率时,模型依旧是不平衡的。
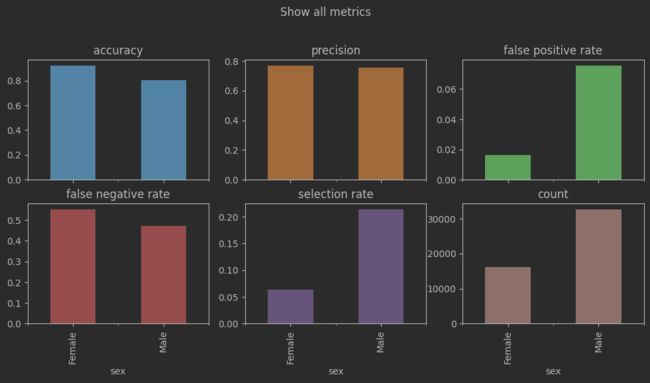
3.3 绘制评估结果图
前面说到,评估方法有很多种。当我们想知道模型在哪些指标上不平衡时,可以直接绘制评估结果图。
from sklearn.metrics import precision_score
from fairlearn.metrics import false_negative_rate
from fairlearn.metrics import false_positive_rate
from fairlearn.metrics import count
metrics = {
"accuracy": accuracy_score, # 精度
"precision": precision_score, # 真阳性/(真阳性+假阳性)
"false positive rate": false_positive_rate, # 假阳性率
"false negative rate": false_negative_rate, # 假阴性率
"selection rate": selection_rate, # 选择率
"count": count # 统计各群体中样本的数量
}
metric_frame = MetricFrame(metrics=metrics, y_true=y_true, y_pred=y_pred, sensitive_features=sex)
metric_frame.by_group.plot.bar(
subplots = True,
layout=[3,3],
legend = False,
figsize =[12,8],
title ="Show all metrics",
)
3.4 消除偏见
当我们发现模型中存在偏见后,可以调用 fairlearn 中自带的去偏方法消除偏见。在本案例中,我们使用的是fairlearn.reductions 下的指数梯度缓解技术,该技术适用于以人口平价为目标所提供的分类器
from fairlearn.reductions import ExponentiatedGradient,DemographicParity
np.random.seed(0) # 设置随机数种子
constraint = DemographicParity() # 公平性约束为人口平价
classifier = DecisionTreeClassifier(min_samples_leaf=10,max_depth=4)
mitigator = ExponentiatedGradient(classifier,constraint) # 指数梯度缓解技术
mitigator.fit(x,y_true,sensitive_features=sex) # 重新训练模型
使用指数梯度缓解技术重新训练模型后,我们重新评估 selection_rate
y_pred_mitigated = mitigator.predict(x)
sr_mitigated = MetricFrame(metrics=selection_rate,y_true=y_true,y_pred=y_pred_mitigated,sensitive_features=sex)
print(sr_mitigated.overall)
print(sr_mitigated.by_group)

对比 3.2 小节中的选择率,这里男性群体和女性群体的选择率相差只有 0.02。