《深度学习进阶 自然语言处理》第一章:神经网络的复习
第一章:神经网络的复习
关于本书第一章内容,主要是对《深度学习入门:基于Python的理论与实现》一书的精炼性概括。
如果你是刚入门且没有看过这本书的新同学,强烈建议阅读一遍,以下是之前整理这本书的链接,供君参考:
- 开篇介绍:《深度学习入门-基于Python的理论与实现》书籍介绍
- 第一章:《深度学习入门-基于Python的理论与实现》第一章带读
- 第二章:《深度学习入门-基于Python的理论与实现》第二章带读 – 感知机
- 第三章:深度学习入门-基于Python的理论与实现》第三章带读 – 神经网络
- 第四章:《深度学习入门-基于Python的理论与实现》第四章带读 – 神经网络的学习
- 第五章:《深度学习入门-基于Python的理论与实现》第五章带读 – 误差反向传播
- 第六章:《深度学习入门-基于Python的理论与实现》第六章带读 – 训练方法介绍
- 第七章:《深度学习入门-基于Python的理论与实现》第七章带读 – CNN介绍
- 第八章:《深度学习入门-基于Python的理论与实现》第八章带读 – 深度学习的高速化
如果你已经在AI领域入门,并且有一定的理论基础,那么也可以通过这一章节快速对一些基础知识进行复习,方便后面更加高效的学习。
接下来我们一起看一下第一章所讲内容。
1.1 数学和Python的复习
该节主要讲解了神经网络中向量、矩阵等内容。
1.1.1 向量和矩阵
我们知道向量是同时拥有大小和方向的量。
- 向量可以表示为排成一排的数字集合,在Python实现中可以处理为一维数组。
- 与此相对,矩阵是排成二维形状(长方阵)的数字集合。
向量和矩阵的例子如下图所示:
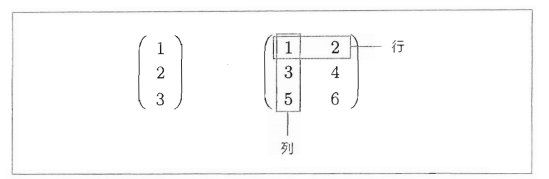
将向量和矩阵扩展到N维的数据集合,就是张量。
1.1.2 矩阵的对应元素的运算
矩阵对应元素的运算,直接在每个元素中相应运算
>>> W = np.array([[1, 2, 3], [4, 5, 6]])
>>> X = np.array([[0, 1, 2], [3, 4, 5]])
>>> N + X
array([[ 1, 3, 5],
[7, 9, 11]])
>>> W * X
array([[0, 2, 6],
[12, 20, 30]])
1.1.3 广播机制
举例一:针对数字的广播机制
>>> A = np.array([[1, 2], [3, 4]])
>>> A * 10
array([[10, 20],
[30, 49]])
举例二:不同形状之间的广播
>>> k = np.array([[1, 2], [3, 4]])
>>> b = np.array([10, 20])
>>> k* b
array([[10, 40],
[30, 80]])
1.1.4 向量内积和矩阵乘积
- 向量内积是两个向量对应元素的乘积之和。
- 矩阵乘积通过“左侧矩阵的行向量(水平方向)”和“右侧矩阵的列向量(垂直方向)”的内积(对应元素的乘积之和)计算得出。

通过如下举例可以看出他们之间的区别
# 向量内积
>>> a = np.array([1, 2, 3])
>>> b = np.array([4, 5, 6])
>>> np.dot (a, b)
32
# 矩阵乘积
>>> A = np.array([[1, 2], [3, 4]])
>>> B = np.array([[5, 6], [7, 8]])
>>> np.dot (A, B)
array([[19, 22],
[43, 50]]
1.1.5 矩阵形状检查
矩阵计算过程中,一定要注意对应维度的元素个数一致。
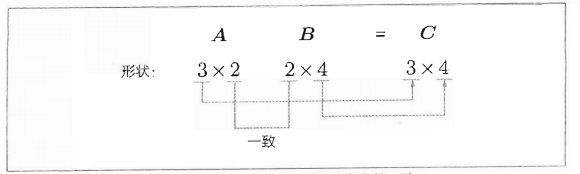
在矩阵乘积等计算中,注意矩阵的形状并观察其变化的形状检查非常重要。据此,神经网络的实现可以更顺利地进行。
1.2 神经网络的推理
神经网络推理全貌图:

在上图,用O表示神经元,用箭头表示它们的连接。此时,在箭头上有权重,这个权重和对应的神经元的值分别相乘,其和(严格地讲,是经过激活函数变换后的值)作为下一个神经元的输人。另外,此时还要加上一个不受前一层的神经元影响的常数,这个常数称为偏置。因为所有相邻的神经元之间都存在由箭头表示的连接。
1.3 神经网络的学习
不进行神经网络的学习,就做不到“好的推理”。因此,常规的流程是,首先进行学习,然后再利用学习好的参数进行推理。
所谓推理,就是对需要求解的问题给出回答的任务。而神经网络的学习的任务是寻找最优参数。
1.3.1 损失函数
计算神经网络的损失要使用损失函数(loss function)。进行多类别分类的神经网络通常使用交叉滴误差(cross entropy error)作为损失函数。此时,交叉熵误差由神经网络输出的各类别的概率和监督标签求得。
以下为使用了损失函数的神经网络的层结构:

在上图中,X是输人数据,t是监督标签,L是损失。
此时,Softmax层的输出是概率,该概率和监督标签被输人Cross Entropy Error层。
1.3.2 链式法则
学习阶段的神经网络在给定学习数据后会输出损失。这里我们想得到的是损失关于各个参数的梯度。只要得到了它们的梯度,就可以使用这些梯度进行参数更新。那么,神经网络的梯度怎么求呢?
此时就轮到误差反向传播法出场了。理解误差反向传播法的关键是链式法则。
链式法则是复合函数的求导法则,其中复合函数是由多个函数构成的函数。然后对该函数进行链式求导。
1.4 计算的高速化
神经网络的学习和推理需要大量的计算。因此,如何高速地计算神经网络是一个重要课题。本节将简单介绍一下可以有效加速神经网络的计算的位精度和GPU的相关内容。
1.4.1 位精度
在神经网络的计算中,数据传输的总线带宽有时会成为瓶颈。在这种情况下,毫无疑问数据类型也是越小越好。再者,就计算速度而言,32位浮点数也能更高速地进行计算(浮点数的计算速度依赖于CPU或GPU的架构)。所以数据的位精度就是我们在进行计算的时候需要关注的指标。
1.4.2 GPU(CuPy)
深度学习的计算由大量的乘法累加运算组成。这些乘法累加运算的绝大部分可以并行计算,这是GPU比CPU擅长的地方。因此,一般的深度学习框架都被设计为既可以在CPU上运行,也可以在GPU上运行。
如果我们的代码环境中有GPU,那么推荐计算的时候,优先使用GPU。
1.5 小结
本章中主要复习了神经网络的基础知识。掌握了这些基础知识后,从下一章开始,我们就要真正不如NLP知识的殿堂。