Hive-SQL -DDL操作

Hive-SQL -DDL操作
用到的数据我会打包上传,放到本文末尾
一、创建数据库
1. 创建数据库语句
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
2.数据库创建举例
2.1 创建一个数据库,数据库在HDFS上的存储路径是/test.db。
create database test
comment "Just for test"
location "/test.db"
with dbproperties("aaa" = "bbb");
2.2 显示数据库
show databases;
2.3 过滤显示查询的数据库
show databases like 'te*';
2.4 查看数据库详情
显示数据库信息
desc database test;
显示数据库详细信息,extended
database extended test;
2.5 切换当前数据库
use test;
二、创建表
1. 创建数据库表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
2. 创建普通表
2.1 创建数据库表
create table test
(id int comment "ID", name string comment "Name")
comment "Test Table"
row format delimited fields terminated by "\t"
location "/test.db/test.tb"
tblproperties("aaa" = "bbb");
2.2 查询数据库表
查询
desc test;
详细查询
desc formatted test;
2.2 修改数据库表
修改一列的类型
alter table test change id id string;
增加一列
alter table test add columns(class string comment "增加一列class");
用以下替换原来的列(如果原来有三列,替换后为两列)
alter table test replace columns(id double, name string);
删除表
drop table test;
3. 外部表
创建外部表可以让hdfs上数据不随着表的删除而删除
3.1 创建一个外部表
create external table test
(id int, name string)
row format delimited fields terminated by "\t";
导入数据
load data local inpath "/opt/module/datas/student.txt" into table test;
删除外部表
drop table test;
可以看到外部表删除了,hdfs上数据并没有删除

3.2 外部表和内部表的转换
建立一个内部表(实际应该建立外部表)
create table test
(id int, name string)
row format delimited fields terminated by "\t";
转换为外部表
alter table test set tblproperties("EXTERNAL" = "TRUE");
转换为内部表
alter table test set tblproperties("EXTERNAL" = "FLASE");
4. 分区表
4.1 建立一张分区表
create table stu_par
(id int, name string)
partitioned by (class string)
row format delimited fields terminated by "\t";
4.2 向表中插入数据
load data local inpath "/opt/module/datas/student.txt" into table stu_par
partition (class="01");
load data local inpath "/opt/module/datas/student.txt" into table stu_par
partition (class="02");
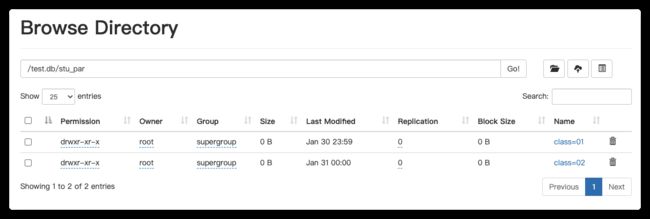
4.3 查询时,选择分区,可以减少数据扫描量
SELECT * from stu_par where class="01";
4.4 查询分区表的分区
show partitions stu_par;
4.4 如果提前准备数据,但是没有元数据,修复方式
根据,下图手动添加了数据,但是hive并没有元数据



方式1. 添加分区
alter table stu_par add partition(class="03");
方式2. 直接修复

msck repair table stu_par;
方式3. 上传时候带分区
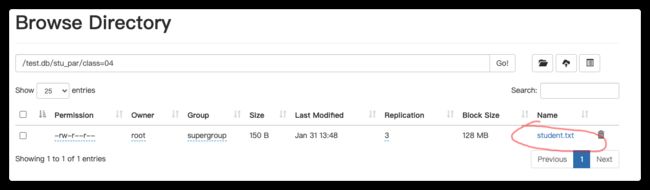
load data local inpath "/opt/module/datas/student.txt" into table stu_par
partition(class="04");
上传后如图:
4.5 分区的增删改查
增加一个分区
alter table stu_par add partition(class="05");
增加多个分区
alter table stu_par add partition(class="06") partition(class="07");
删除一个分区
alter table stu_par drop partition(class="05");
删除多个分区
alter table stu_par drop partition(class="06"),partition(class="07");
5. 二级分区表
5.1 建立二级分区表
create table stu_par2
(id int, name string)
partitioned by (grade string, class string)
row format delimited fields terminated by "\t";
5.2 插入数据,指定到二级分区
load data local inpath "/opt/module/datas/student.txt" into table stu_par2
partition (grade="01", class="03");
6. 用查询结果建表
create table stu_result as select * from stu_par where id=1001;

版权声明:
作者:十下
链接:http://blog.edkso.cn/?p=211
来源:十下博客
文章版权归作者所有,未经允许请勿转载。
三、附件包
链接: https://pan.baidu.com/s/1D4G5WkuVQSRnhLv3ic3tlg 密码: uaho加粗样式