多项式回归与模型泛化
1、多项式回归
线性回归的局限性是只能应用于存在线性关系的数据中,但是在实际生活中,很多数据之间是非线性关系,虽然也可以用线性回归拟合非线性回归,但是效果会变差,这时候就需要对线性回归模型进行改进,使之能够拟合非线性数据。多项式回归模型是线性回归模型的一种,此时回归函数关于回归系数是线性的。由于任一函数都可以用多项式逼近,因此多项式回归有着广泛应用。
研究一个因变量与一个或多个自变量间多项式的回归分析方法,称为多项式回归(Polynomial Regression)。如果自变量只有一个时,称为一元多项式回归;如果自变量有多个时,称为多元多项式回归。在一元回归分析中,如果因变量y与自变量x的关系为非线性的,但又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。在这种回归技术中,最佳拟合线不是直线,而是一个用于拟合数据点的曲线。
多项式回归的最大优点是可以通过增加x的高次项对观测点进行逼近,直到满意为止。多项式回归在回归分析中占有重要地位,因为任意函数都可以分段用多项式逼近。
1.1 代码实现多项式回归思路
代码实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1,1)
y = 0.5 * x ** 2 + x * 2 + np.random.normal(0,1, size=len(x))
plt.scatter(x, y)
# 为原有的样本添加一个特征(升维)
X2 = np.hstack([X, X ** 2])
lin_reg = LinearRegression()
lin_reg.fit(X2, y)
y_predict = lin_reg.predict(X2)
# 按照x的顺序画曲线
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
print(lin_reg.coef_)
PCA算法是对数据进行降维处理,而多项式回归算法让数据集升维,在给数据集添加新的特征后使得算法可以更好的拟合高维度的相应的数据。
1.2、scikitlearn中的多项式回归
代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1,1)
y = 0.5 * x ** 2 + x * 2 + np.random.normal(0,1, size=len(x))
# degree要为原本的数据集最多添加几次幂的特征
poly = PolynomialFeatures(degree=2)
poly.fit(X)
X2 = poly.transform(X)
print(X2[:5])
lin_reg = LinearRegression()
lin_reg.fit(X2, y)
y_predict = lin_reg.predict(X2)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='y')
plt.show()
X = np.arange(1, 11).reshape(-1, 2)
print(x)
poly = PolynomialFeatures(degree=2)
poly.fit(X)
# 假设原数据集有x, y两列,degree为2,转换结果共有6列,第一列是0次幂
# 第二列是x,第三列是y,第四列是X的2次幂,第五列是x * y,第六列是y的2次幂
print(poly.transform(X))
1.3 Pipeline
我们在使用多项式回归时大致需要三个过程:多项式的特征(用PolynomialFeatures的方式生成)、数据的归一化(样本特征数据差异较大的情况下)、线性回归。而Pipeline可以帮助我们将这三部合在一起,使得我们每次调用的时候不需要再重复这三步。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1,1)
y = 0.5 * x ** 2 + x * 2 + np.random.normal(0,1, size=len(x))
# 数据按照顺序进入PolynomialFeatures,StandardScaler,LinearRegression
poly_pipe = Pipeline([
('poly', PolynomialFeatures(degree=2)),
('std_standar', StandardScaler()),
('lin_reg', LinearRegression())
])
poly_pipe.fit(X, y)
y_predict = poly_pipe.predict(X)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
多项式回归这样的方式虽然可以非常方便的对非线性的数据进行拟合,但是这个拟合的过程是有陷阱的,可能出现过拟合或者欠拟合的问题。
2、过拟合与欠拟合
一、什么是欠拟合?
欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。
二、如何解决欠拟合?
欠拟合基本上都会发生在训练刚开始的时候,经过不断训练之后欠拟合应该不怎么考虑了。但是如果真的还是存在的话,可以通过增加网络复杂度或者在模型中增加特征,这些都是很好解决欠拟合的方法。
三、什么是过拟合?
过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集"死记硬背"(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
造成原因主要有以下几种:
1、训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2、训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
3、**模型过于复杂。**模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
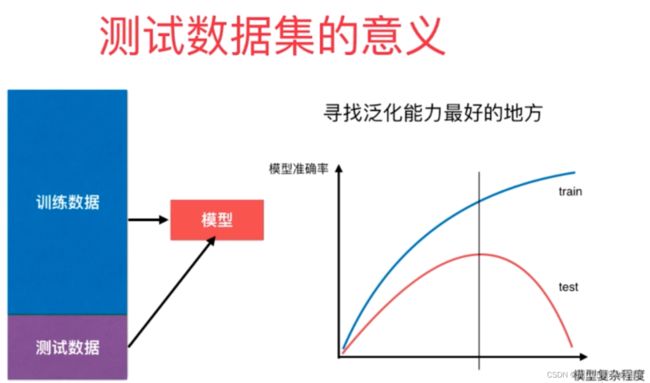
3、学习曲线
一种用来判断训练模型的一种方法,通过观察绘制出来的学习曲线图,我们可以比较直观的了解到我们的模型处于一个什么样的状态,如:过拟合(overfitting)或欠拟合(underfitting)。
编写plot_learning_curve.py文件
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
# 绘制训练集逐渐增加时,训练数据集预测结果和测试数据集预测结果的均方误差
def plot_learning_curve(algo, X_train,X_test,y_train,y_test):
train_score = []
test_score = []
for i in range(1, 71):
algo.fit(X_train[:i], y_train[:i])
y_train_predict = algo.predict(X_train[:i])
y_test_predict = algo.predict(X_test)
train_score.append(mean_squared_error(y_train[:i], y_train_predict))
test_score.append(mean_squared_error(y_test, y_test_predict))
plt.plot([i for i in range(1, 71)], np.sqrt(train_score), label='train')
plt.plot([i for i in range(1, 71)], np.sqrt(test_score), label='test')
plt.legend()
plt.axis([0, len(X_train) + 1, 0, 4])
plt.show()
测试:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from plot_learning_curve import plot_learning_curve
from common.PolynomialRegression import PolynomialRegression
np.random.seed(666)
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1,1)
y = 0.5 * x ** 2 + x * 2 + np.random.normal(0,1, size=len(x))
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)
plot_learning_curve(LinearRegression(), X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test)
poly_reg2 = PolynomialRegression(degree=2)
plot_learning_curve(poly_reg2, X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test)
poly_reg10 = PolynomialRegression(degree=10)
plot_learning_curve(poly_reg10, X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test)
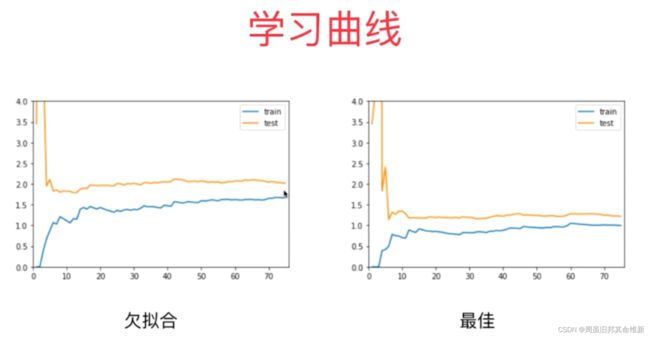
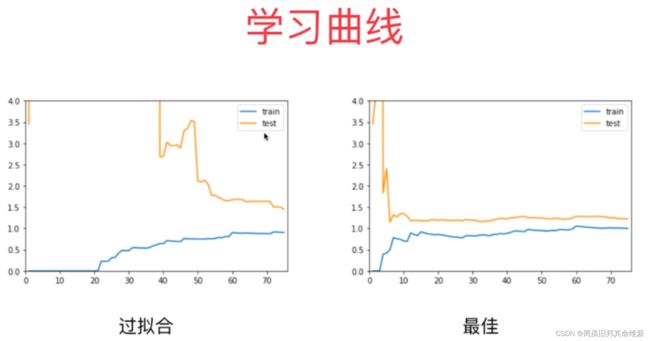
4、交叉验证

代码实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.4)
best_score, best_p, best_k = 0, 0, 0
for k in range(2,11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=k, p=p)
knn_clf.fit(X_train, y_train)
# cross_val_score交叉验证,cv指定分成几份进行交叉验证
scores = cross_val_score(knn_clf, X_train, y_train)
score = np.mean(scores)
# score = knn_clf.score(X_test, y_test)
if score > best_score:
best_score, best_p, best_k = score, p, k
print(best_score, best_p, best_k)
# knn_clf = KNeighborsClassifier()
# cross_val_score交叉验证
# print(cross_val_score(knn_clf, X_train, y_train))
best_knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=best_k, p=best_p)
best_knn_clf.fit(X_train, y_train)
print(best_knn_clf.score(X_test, y_test))
GridSearchCV使用的就是交叉验证。
留一法(Leave-One-Out-Cross-Validation):
如果数据集D的大小为N,那么用N-1条数据进行训练,用剩下的一条数据作为验证。
LOOCV的优点:首先它不受训训练集和验证集划分(这里指将大训练集划分为训练集和验证集)的影响,因为每一个样本都单独的做过验证集,同时,其用了N-1个样本训练模型,几乎用到了所有样本信息。
LOOCV缺点:计算量过大。
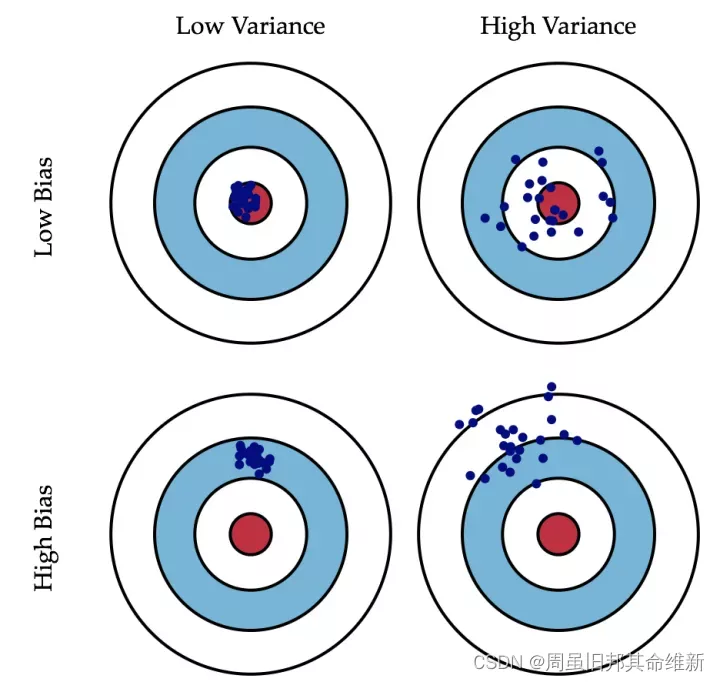
5、偏差方差平衡
**偏差:**描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
**方差:**描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下图右列所示。
偏差过大的主要原因:
对问题本身的假设不正确,如非线性数据使用线性回归,欠拟合(underfitting)就是这样的例子。
方差过大的主要原因:
数据的一点点扰动都会较大的影响模型,通常原因,使用的模型太复杂,如高阶多项式回归,过拟合(overfitting)就是这样的例子。
有一些算法天生是高方差的算法,例如KNN,非参数学习通常都是高方差算法,因为不对数据进行假设。
有一些算法天生是高偏差算法,例如线性回归,参数学习通常都是高偏差算法,因为对数据具有极强的假设。
解决高方差的通常手段:
1.降低模型复杂度
如多项式回归中,可通过较小 degree 来降低模型复杂度;
2.减少数据维度;降噪
方差过大的大部分原因是模型学习的过多的噪音;
3.增加样本数
也就是增大训练数据的规模:有时候算法具有高的方差,是因为模型太过复杂,模型中的参数非常多,而训练模型的样本数不足以支撑计算出这么多复杂的参数。(如:神经网络和深度学习)
使用深度学习的一个非常重要的条件就是数据样本的规模必须足够的大,这样才能发挥深度学习算法的效用,其中的原因就是深度学习算法的模型太过复杂,模型中的参数非常多,而训练模型的样本数不足以支撑计算出这么多复杂的参数。否则的话,使用深度学习的算法在一个小样本上得到的结果,还不如使用简单的模型得到的结果。
4.使用验证集
在评测算法模型指标时需要使用 验证数据集(Validation),因为如果只使用 train_test_split 的方法得到的模型很有可能出现过拟合测试数据集的情况。
5.模型的正则化
6、模型泛化与岭回归
岭回归也叫模型正则化
公式推导:

代码实现,编写RidgeRegression.py文件:
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Ridge
from sklearn.pipeline import Pipeline
def RidgeRegression(degree, alpha):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_standar', StandardScaler()),
# Ridge sklearn提供的岭回归处理类,alpha即公式推导中的a
('ridge_reg', Ridge(alpha=alpha))
])
测试岭回归的均方误差:
import numpy as np
from sklearn.model_selection import train_test_split
from common.RidgeRegression import RidgeRegression
from sklearn.metrics import mean_squared_error
np.random.seed(666)
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1,1)
y = 0.5 * x ** 2 + x * 2 + np.random.normal(0,1, size=len(x))
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=10)
ridge_reg = RidgeRegression(degree=20, alpha=0.1)
ridge_reg.fit(X_train, y_train)
y_predict = ridge_reg.predict(X_test)
print(mean_squared_error(y_test, y_predict))
7、LASSO
我们学习了解决多重共线性的一种方法是对代价函数正则化,其中一种正则化的算法叫岭回归算法(Ridge Regression Algorithm)。下面我们来学习另一种正则化的算法 - Lasso回归算法1(Lasso Regression Algorithm),LASSO的完整名称叫最小绝对值收敛和选择算子算法(least absolute shrinkage and selection operator)。

Lasso用法与Ridge相同。
LASSO趋向于使得一部分theta变为0,所以可作为特征选择用。

8、L1,L2和弹性网络
明可夫斯基距离的定义一样,LP范数不是一个范数,而是一组范数,其定义如下:

p=1即L1范数,也就是LASSO中添加的正则项,p=2即L2范数,也就是岭回归中添加的正则项,通常只会使用L1正则项和L2正则项。
当P=0时,也就是L0范数,由上面可知,L0范数并不是一个真正的范数,它主要被用来度量向量中非零元素的个数。
不幸的是,L0范数的最优化问题是一个NP hard问题(L0范数同样是非凸的)。因此,在实际应用中我们经常对L0进行凸松弛,理论上有证明,L1范数是L0范数的最优凸近似,所以在实际情况中,L0的最优问题会被放宽到L1或L2下的最优化。
弹性网络结合了岭回归和LASSO回归的优势
