torchvision.transforms.ToTensor()不缩放问题
在加载MNIST数据集时,发现即便传入了transform参数,img并未像预期那样被压缩到(0,1),仔细研究一番,终于找到问题。在这个过程中,发现许多“技术博客”人云亦云,不求甚解,因此分享出来,若有错误,也望指正。
1. 疑问
通常我们这样来加载MNIST数据集:
# 训练集
train_data = torchvision.datasets.MNIST(
root = r'D:\backup\Desktop\cnn',
train = True, # True为下载训练集,False为下载测试集
transform = torchvision.transforms.ToTensor(), # 预处理
download = False # 是否需要下载
)
其中,对于torchvision.transforms.ToTensor()的介绍,大多是:
“把PIL.Image或者numpy.narray数据类型转变为torch.FloatTensor类型,shape是CHW,数值范围缩小为[0.0, 1.0]”
然而,经过实验发现img的scale并无变化,具体如下:
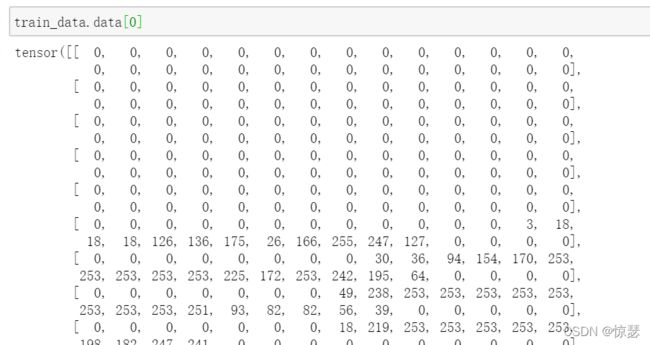
可以看出,img的范围依然是(0,255)。
2. 溯源
从源头排查原因,先看下MNIST类中关于data的定义:
if self._check_legacy_exist():
self.data, self.targets = self._load_legacy_data()
return
进一步查看_load_legacy_data():
def _load_legacy_data(self):
# This is for BC only. We no longer cache the data in a custom binary, but simply read from the raw data
# directly.
data_file = self.training_file if self.train else self.test_file
return torch.load(os.path.join(self.processed_folder, data_file))
可以看出,直接return了数据集本身,并没有经过特别处理,所见即所得,说好的transform呢?
再回头查看MNIST类,发现其有一个_getitem_()函数:
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], int(self.targets[index])
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
从函数中可以看出,若transform不为空,则将img传入transform函数,最后连同标签一起return。值得注意的是,在img传入transform前为Image类型,并不是torch类型,经过transform后变为torch类型。测试一下:
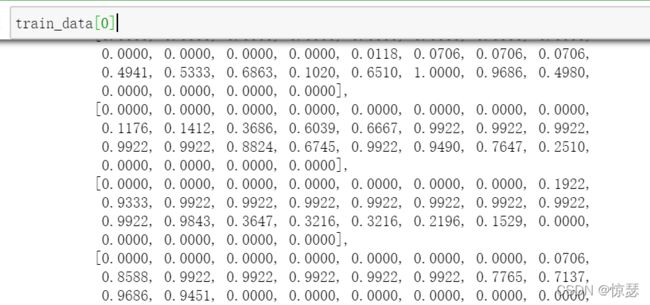
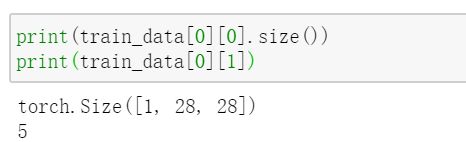
果然,此时的img是被归一化了的。需要注意的是,train_data[0]是一个长度为2的tuple,第一个是img,第二个是target:
我们再测试一下加载数据集时不传入transform参数:
train_data = torchvision.datasets.MNIST(
root = r'D:\backup\Desktop\cnn',
train = True, # True为下载训练集,False为下载测试集
# transform = torchvision.transforms.ToTensor(), # 预处理
download = False # 是否需要下载
)
再查看train_data[0]:

发现此时img果然还是Image类型。
3. 结论
- train_data.data是通过torch.load()加载的原始数据集,无论实例化时是否传入了transform参数,它都不会对数据做任何改变。
- train_data[n](因为MNIST类中定义了__getitem__才允许通过这种方式加载数据)是长度为2的tuple类型,其中第一个是img,第2个是target。若实例化的时候传入了transform参数,则img为归一化处理的tensor类型数据,反之img为未经任何处理的Image类型数据。