Node.js学习笔记 更新完毕 2022 coderwhyWEB前端体系课
一 Node.js是什么
官方对Node.js的定义:
Node.js是一个基于V8 JavaScript引擎的JavaScript运行时环境
Node.js is a JavaScript runtime built on Chrome's V8 JavaScript engine
也就是说Node.js基于V8引擎来执行JavaScript的代码,但是不仅仅只有V8引擎:
V8可以嵌入到任何C++应用程序中,事实上都是嵌入了V8引擎来执行JavaScript代码
在谷歌浏览器中,需要 解析 渲染HTML CSS等相关渲染引擎,另外还需要提供支持浏览器操作的API 浏览器自己的事件循环等
另外在Node.js中我们也需要进行一些额外的操作 如 文件系统读/写 网络I/O 加密 压缩解压文件等操作.
浏览器和Node.js架构区别
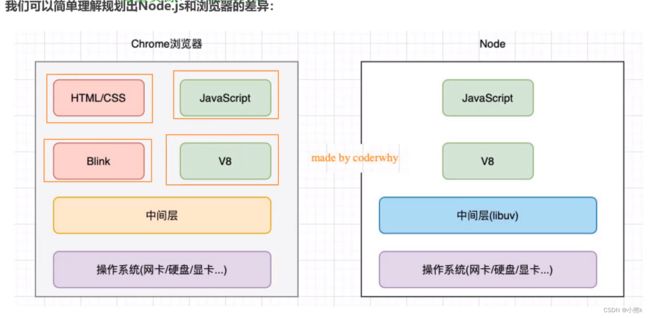
Node.js架构

2 Node.js的应用场景
对于高级前端工程师来说,Node.js是必不可少的技能
应用一:目前 前端开发的库都是以node包的形式进行管理的;
应用二:npm yarn pnpm 工具成为前端开发使用最多的工具
应用三:越来越多的公司 使用Node.js作为web服务器开发 中间件 代理服务器
应用四:大量项目需要借助Node.js完成前后端渲染的同框应用
应用五:资深前端工程师需要为项目编写脚本工具(前端工程师写脚本经常会使用JavaScript而不是python或shell)
应用六:很多企业在使用Electron来开发桌面应用程序
3 Node的安装和管理
Node的安装
Node.js是在2009年诞生
LTS版:(长期支持)相对稳定一些,推荐线上环境使用该版本
Current版:最新Node版本,包含很多新特性
Node的版本工具
想要电脑存有多个版本的Node可以用另外一个工具来管理版本. n(TJ写的)/nvm (不支持window)
Window怎么办?
针对nvm 在github上有提供对应的window版本
通过nvm install latest安装最新的node版本
通过nvm list 展示目前安装的所有版本
通过nvm use 切换版本
4 Javascript代码执行
console.log('aaa');
console.log('bbb');
console.log('ccc');
操作=> 当前目录下 使用 node 文件名Node输入和输出
// 1 输出
console.log("Hello World")
const num1 = 100
const num2 = 200
console.log(num1+num2);
// 2 给程序输入内容
console.log(process.argv)
// 在控制台打印 node .\文件名 num1=20 num2=40Node程序传递参数
正常情况下执行一个node程序,直接跟上我们对应的文件即可: node index.js
但是在某些情况下执行node程序的过程中,我们希望能给node传递一些参数 node index.js env=development coderwhy
如果我们这样来使用程序 ,我们就需要在程序中获取到传递的参数
获取参数其实可以在process的内置对象中的
如果直接打印这个内置对象 里面包含了特别的信息 => 比如 版本 操作系统 等大家可以自行查看
现在我们先找到其中的argv属性:
可以发现他是一个数组,里面包含了我们需要的参数
5 Node的输入和输出
Node的输出
console.log => 最常用的输入内容的方式: console.log
console.clear => 清空控制台 console.clear
console.trace => 打印函数的调用栈
6 Node的全局对象
常见的全局对象

Node中给我们提供了一些全局对象 方便进行操作.
process对象:process提供了Node进程中相关的信息==> Node的运行环境 参数信息等
定时器函数:在Node中使用定时器有好几种方式:
setTimeout(callback,delay[,...args]):callback在delay毫秒后执行
setInterval(callback,delay[,...args]):callback每delay毫秒重复执行一次
setImmediate(callback[,...args]):callback I./O事件后的回调的"立即执行"
process.nextTick(callback[,...args]):添加到下一次tick队列中
特殊的全局对象
为什么称为特殊的全局对象?
这些全局对象实际上是 模块中的变量 只是 每个模块都有,看来像是全局变量;
在命令行交互中是不可以使用的; 包括:__dirname __filename exports module require()
__dirname => 获取当前文件所在的路径:
__filename => 获取当前文件所在的路径和文件名称
global对象
我们之前讲过:在新的标准中还有一个globalThis 也是指向全局对象的;类似于浏览器中window
面试题:global和window的区别
在浏览器中 全局变量都是在window上的,如 document setInterval setTimeout等等
在Node中也有一个global属性 并且看起来它里面有很多其他对象
但是在浏览器中执行Javascript代码,如果我们在顶级范围内通过var定义的一个属性 默认会被添加到window对象上,但是在Node中 通过var定义一个变量 他只会在当前模块中的变量 不会放到全局中
二 JavaScrpt模块化开发
1 认识模块化
什么是模块化?
模块化开发最终的目的是将程序划分成一个个小的结构;
这个结构中编写属于 自己的逻辑代码 有自己的作用域 定义变量名称时不会影响到其他的结构
这个结构可以将自己希望暴露的变量 函数 对象 等导出给其他 结构使用
也可以通过某种方式 导入 另外结构中的变量 函数对象 等
上面提到的结构 就是模块 按照这种结构划分开发程序的过程 就是模块化开发的过程
2 CommonJS和Node
CommonJS规范和Node关系
CommonJS是一个规范 可以简称为CJS
Node是CommonJS在服务器端一个具有代表性的实现
Borowserify是CommonJS在浏览器中的一种实现
webpack打包工具 具备对CommonJS的支持和转换
Node中对CommonJS进行了支持和实现 在Node中每一个js文件都是一个单独的模块 在这个模块中包括CommonJS规范的核心变量:exports.exports require 我们可以使用这些变量来方便进行模块化开发
exports和module.exports可以负责对模块中的内容进行导出;
require函数 可以帮助我们导入其他模块(自定义模块 系统模块 第三方模块)中的内容
exports导出
exports是一个对象 可以给对象添加很多个属性 添加的属性可以被导出
exports.name = name;
exports.age = age;
exports.sayHello = sayHello另一个文件导入:
const bar = require('./bar')main中的bar变量等于 exports对象
也就是 require通过各种查找方式 最终找到了exports对象
并且将这根exports对象赋值给了bar变量;
bar变量就是exports对象.
module.exports 导出
在Node中我们经常导出东西的时候,又是通过module.exports导出的:
module.exports和exports有什么关系或者区别呢?
CommonJS中没有module.exports的概念的;
为了实现模块的导出,Node中使用的是Module的类,每一个模块都是Module的一个实例,也就是module;
在Node中真正用于导出的其实 根本不是exports 而是module.exports
module才是导出的真正实现者.
为什么exports也可以导出?
module对象的exports属性是exports对象的一个引用.
3 require函数解析
require细节
require是一个函数,帮助我们引入一个文件(模块)中导出对象
require的查找规则:
导入格式如下:require(X)
情况一:X是一个Node核心模块 如 path http
直接返回核心模块 且停止查找
// 2 导入node提供的内置模块
// require('内置模块的名称')
const path = require('path')
const http = require('path')
console.log(path,http);情况二:X是以./或../ 或/ (根目录)开头的
1:将X当做一个文件在对应的目录下查找:
1.1 如果有后缀名,按照后缀名的格式查找对应的文件 1.2 如果没有后缀名,会按照如下顺序:
1.2.1 直接查找文件X
1.2.1 查找X.js文件
1.2.1 查找X.json文件
1.2.1 查找X.node文件
const foo = require('./foo')2:没有找到对应的文件,将X作为一个目录
2.1 查找目录下面的index文件
2.1.1 查找X/index.js文件
2.1.2 查找X/index.json文件
2.1.3 查找X/index.node文件
如果都没有找到就报错! Not found
情况三:直接是一个X(没有路径),并且X不是一个核心模块
模块的加载工程
结论一:模块在被第一次引入时,模块中的js代码会被运行一次
结论二:模块被多次引入时,会缓存,最终只加载(运行)一次
为什么只会加载运行一次呢?
因为每个模块对象module都有一个属性loaded
为false表示没加载 true表示已加载
结论三:如果有循环引入 那么加载顺序是什么?
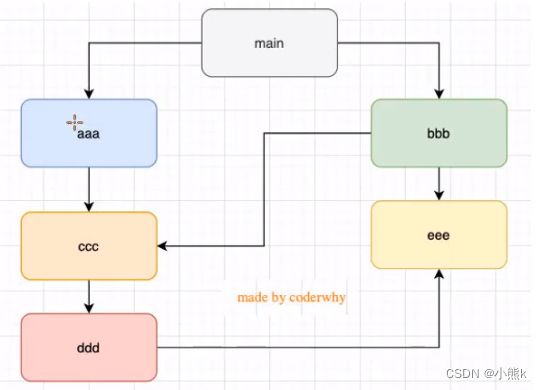
Node采用的是深度优先算法:main=>aaa=>ccc=>ddd=>eee=>bbb
CommonJS规范缺点:
CommonJS加载模块是同步的:
只有等到对应的模块加载完毕,当前模块中的内容才能被运行
在服务器中不会有什么问题,因为服务器 加载的js文件都是本地文件 加载速度非常快
将它应用于浏览器中?
浏览器加载js文件需要先从服务器将文件下载下来,之后 再加载运行
采用同步的就意味着后续的js代码都无法正常运行,即便是一些简单的DOM操作
在浏览器中,通常不使用CommonJS规范
4 ESModule用法详解
export关键字
将一个模块中的变量 函数 类等导出
有三种方式将内容导出:
方式一:在语句声明的前面直接加上export关键字
export const name = 'zb'
export const age = 18方式二:将所有需要导出的标识符,放到export后面的{}中
这里的{}里面不是ES6的对象字面量的增强写法,{}也不是表示一个对象的
所以:export{name:name} 是错误的写法
export {
name,
age,
sayHello
}方式三:导出时 给表示符起一个别名
通过as关键字起别名
export {
name as fname,
age,
sayHello
}import关键字
import关键字负责从另外一个模块中导入内容
导入内容的方式:
方式一:importi{标识符列表} from '模块';
注: 这里的{}不是一个对象,里面只是存放导入的标识符列表内容
import {name,age,sayHello} from "./foo.js"方式二:导入时给标识符起别名
通过as关键字起别名
import {name as fname ,age,sayHello} from "./foo.js"方式三: 通过 * 将模块功能放到一个模块功能对象(a module object)上
导入时 可以给整个模块起别名
import * as foo from "./foo.js"export和import结合使用(相对高级写法)
补充:export和import可以结合使用
export { formatCount,formatDate } from './format.js'为什么曜这样做呢
在开发和封装一个一个功能库时 希望将暴露的所有接口放到一个文件中
方便指定统一的接口规范 也方便阅读
我们就可以使用export和import结合使用
default用法
导出功能的都是 有名字的导出(named exports):
在导出export时指定了名字
在导入import时需要知道具体的名字
一种导出叫 默认导出(default export)
默认导出export时 不需要指定名字
在 导入时 不需要使用{} 并且可以自己来指定名字
它也方便我们和现有的CommonJS等规范相互操作
注:在一个模块中 只能有一个默认导出(default export)
import函数
通过import加载一个模块 是不可以在其放到逻辑代码中的 如:
// // 在导入的时候 必须放到顶层
import {name,age,sayHello} from "./foo.js"// 不允许在逻辑代码中编写import 是不允许这样做的
let flag = true
if(flag){
import {name,age,sayHello} from "./foo.js"
console.log(name,age);
}在某些情况下,确实希望动态的来加载某个模块
这个时候 我们就需要使用import()函数来动态加载
import函数返回一个Promise,可以通过then获取结果
let flag = true
if(flag){
// 如果确实是逻辑成立时 才需要导入某个模块
// import函数
const importPromise = import("./foo.js")
importPromise.then(res=>{
console.log(res);
})
console.log("================");
}但是上面这种写法 又比较麻烦,真实开发中是这样写的
let flag = true
if(flag){
import("./foo.js").then(res=>{
console.log(res);
})
console.log("================");
}为什么会出现这个情况?
因为ES Module在被JS引擎解析时 就必须知道它的依赖关系.
由于这个时候js代码没有任何的运行,所以无法进行类似于if判断中根据代码的执行情况.
甚至 拼接路径的写法也是错误的,因为我们必须到运行时能确定path值
(扩展)import meta
import.meta是一个给JavaScript模块暴露特定上下文的元数据属性的对象
它包含了这个模块的信息,如这个模块的URL
在ES11 (ES2020)中新增的特性
5 ESModule运行原理
ES Module的解析流程
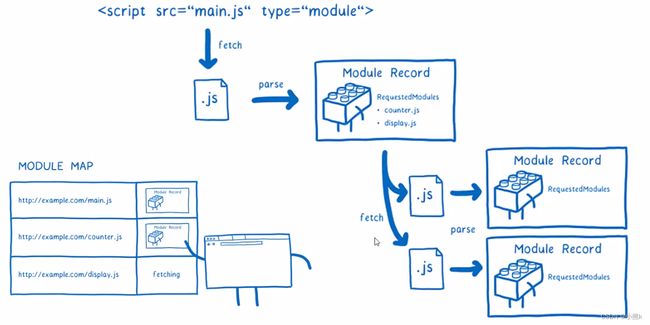
ES Module的解析过程可以划分为三个阶段:
一:构建(Constuction),根据地址查找js文件并下载,将其解析成模块记录(Module Record)
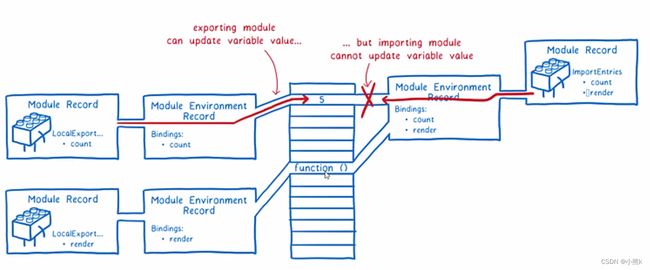
二:实例化(Instantiation),对模块记录进行实例化,并分配内存空间,解析模块的导入和导出语句,把模块指向对应的内存地址
三:运行(Evaluation)运行代码,计算值.并且将值填充到内存地址中
阶段一:构建过程
阶段二:实例化阶段 求值阶段
三 包管理工具详解npm yarn cnpm npx pnpm
1 npm包管理工具
包管理工具npm
Node Package Manager 就是Node包管理器
目前已经不仅仅是Node包管理器 在前端项目中 我们也在使用它来管理依赖的包
如 vue vue-router vuex express koa react react-dom axions babel webpack
npm的配置文件
我们每一个项目都会有一个对应的配置文件,无论是前端还是后端
这个配置文件会记录着你项目的名称,版本号,项目描述等
也会记录项目所依赖的其他库的信息和依赖库的版本号
=> 这个文件就是package.json
常见的属性
必须填写的属性:name version
| name |
项目的名称 |
| version |
当前项目的版本号 |
| description |
描述信息,项目的基本描述 |
| author |
作者相关信息 |
| license |
开源协议 |
| private |
记录当前的项目是否私有,为true时 npm不能发布它,防止私有项目或模块发布出去的方式 |
| main |
程序的入口,我们使用axios模块,如果有main属性 实际上是找到对应的main属性查找文件 |
| scripts |
配置一些脚本命令 以键值对的形式存在;配置后可以通过npm run命令的key来执行 |
| dependencies |
指定无论开发环境还是生成环境都需要依赖的包 我们项目实际开发用到的一些苦的模块 vue vuex vue-router react react-dom axios等 与之对应的是 devDependencies |
| devDependencies |
一些包在生成环境是不需要的 如 webpack babel等 我们可以通过 npm install webpack --save-dev将它安装到 这个属性中 |
| peerDependencies |
还有一种项目依赖关系是对等依赖,就是 你依赖的一个包,它必须是以另外一个宿主包为前提的,如 element-plus是依赖于vue3的 ant design是依赖于 react react-dom |
| engines |
指定Node和NPM的版本号 在安装过程中 会先检查对应的引擎版本 如果不符合就报错 |
依赖的版本管理
我们会发现安装的依赖版本会出现: ^2.2.2或~2.2.2 是什么意思呢?
npm的包通常需要遵从semver版本规范
semver版本规范是X.Y.Z:
X主版本号:当你做了不兼容的API修改(可能不兼容之前的版本)
Y次版本号:当你做了向下兼容的g功能性新增(新功能增加,但是兼容之前的版本)
Z修订号:当你做了向下兼容的问题 修正(没有新功能 修复了之前的版本bug)
^和~的区别:
x.y.z:表示 一个明确的版本号
^x.y.z: 表示x是保持不变的,y和z永远安装最新的版本
~x.y.z: 表示x和y保持不变,z永远安装最新的版本
2 npm install 原理
Npm install 命令
安装npm包分两种情况:
全局安装:npm i webpack -g
局部安装:npm i webpack
全局安装
全局安装是直接将某个包安装到全局;比如全局安装yarn;
npm i yarn -g通常使用 npm全局安装的包 都是一些工具包 如: yarn webpack等
并不是类似于axios express koa等库文件
所以全局安装了之后并不能让我们在所有的项目中使用axios等库
项目安装
项目安装会在当前目录下生成一个node_modules文件夹
局部安装分为开发时依赖和生产时依赖
# 默认安装开发和生产依赖
npm i axios
# 开发依赖
npm i webpack -D
# 根据package.json中的依赖包
npm installnpm install 原理
Npm install
执行 npm install 他背后帮助我们完成了什么操作?
会发现一个称为package-lock.json文件 它的作用是什么?
从npm5开始 npm支持缓存策略(来自yarn的压力)缓存有什么用?
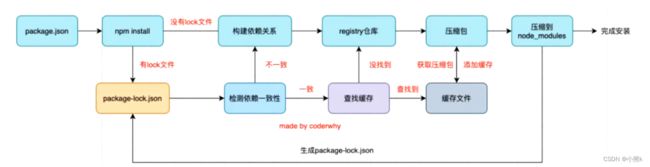
Npm install 原理图解析
npm install 检测是否有package-lock.json文件:
没有lock文件
分析依赖关系,因为包可能会依赖其他的包 并且多个包之间会产生相同依赖关系
从registry仓库下载压缩包(设置了镜像 会从镜像服务器中瞎子啊)
获取到压缩包后会对压缩包进行缓存(npm5开始有)
将压缩包解压到项目的node_modules文件夹中(require的查找顺序会在该包下面查找)
有lock文件:
检测lock中包版本是否跟package.json一致(会按照semver版本规范)
不一致-> 会重新构建依赖关系,直接走顶层的流程
一致的-> 会优先查找缓存 要是没找到 会从registry仓库下载 直接走的顶层流程
查找到.会获取缓存中的压缩文件,并将压缩文件解压到node_modules文件夹中
package-lock.json
package-lock.json文件解析:
name:项目名称
version:项目的版本
lockfileVersion:lock文件的版本
requires:使用requires来跟踪模块的依赖关系
当前项目依赖axios 但是axios依赖follow-redireacts
axios中的属性如下:
Version 表示实际安装的axios版本
Resolved 用来记录下载的地址 registry仓库中的位置
requires/dependencies 记录当前模块的依赖
Integrity 用来从缓存中获取索引 在通过索引去获取压缩包文件
npm其他命令
卸载某个依赖包
Npm uninstall package
Npm uninstall package --savs-dev
Npm uninstall package -D
强制重新bulid(重新构建)
Npm rebuild(很少用)
清除缓存
Npm cache clean
3 yarn cnpm npx
yarn工具
另一个node包管理工具yarn:
yarn是由 Facebook Google Exponent 和 Tilde 联合推出一个新的JS包管理工具
yarn是为了弥补早期npm的一些缺陷而出现的
早期的npm存在许多缺陷,如 安装依赖速度慢 版本依赖混乱等
虽然从npm5版本开始 进行了很多的升级改改进 但是依然很多人喜欢使用yarn

cnpm工具
由于一些特殊原因,没办法很好的从https://registry.npmjs.org下载需要的包
查看npm镜像:
Npm config get registry # npm config get registry
我们可以直接设置nom的镜像:
Npm config set registry https://registry.npn.taobao.org
大多数人来说 并不希望将npm镜像修改
第一:不太希望随意修改npm原本从官方下来包的渠道
第二:担心某天淘宝的镜像不维护了,又要改来改去
4 发布自己的包
Npm 发布自己的包
注册npm账号:
https://www.npmjs.com/
选择sign up
命令行登录:
Npm login
修改package.json
发布到npm registry上
Npm publish
更新仓库:
1 修改版本号(最好符合semver规范)
2 重新发布
删除发布的包
Npm unpublish
让发布的包过期
Npm deprecate
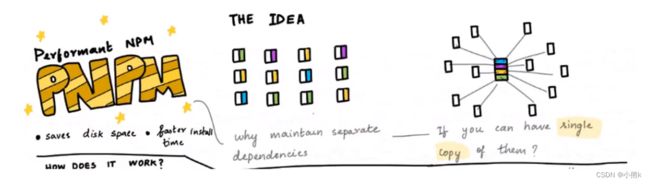
5 pnpm使用和原理
pnpm解决了 不用每个项目都有一个(节省磁盘空间)
什么是pnpm呢?
pnpm:理解为 performant npm 缩写;
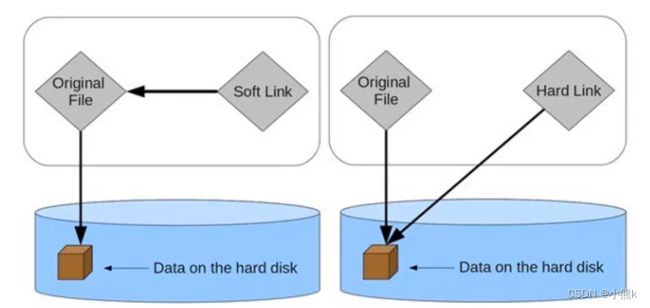
硬链接和软链接的概念
硬链接(hard link):
硬链接:电脑文件系统中的多个文件平等地共享同一个文件存储单元
删除一个文件名字后,还可以用其他名字继续访问该文件
符号链接(软链接soft link Symbolic link)
符号链接 是一类 特殊的文件
包含有一条以绝对路径或者相对路径的形式指向其他文件或者目录的引用
(左图:符号链接 右图:硬链接)
pnpm到底做了什么呢?
当使用 npm 或Yarn时 如果有100歌项目 且 所有项目都有一个相同的依赖包,那么你在硬盘上就需要存100份该相同依赖包的副本
如果使用pnpm 依赖包将被 存放在一个统一的位置,因此:
如果你对同一依赖包使用相同的版本 那么自盘上只有这个依赖包的一份文件
同一依赖包需要使用 不同版本 则仅有版本之间不同的文件会被存储起来
所有文件都保存再硬盘上的统一位置:
当安装软件包时候 其包含的所有文件都会硬链接到此位置,而不会占用额外的硬盘空间
这让你可以再项目指尖方便地共享相同版本的 依赖包
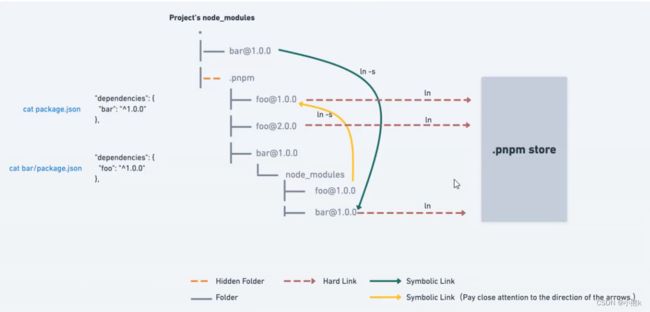
pnpm创建非扁平的node_modules目录
当使用npm或 Yarn Classic安装依赖包时 所有软件包都将被提升到node_modules的根目录下
源码可以访问 本不属于当前项目所设定的依赖包
pnpm的安装和使用
如何安装pnpm?
官网提供了很多种方式来安装pnpm: https://www.pnpm.io/
使用npm
npm install -g pnpm| npm命令 |
pnpm等价命令 |
| Npm install |
Pnpm install |
| Npm install |
Pnpm add |
| Npm uninstall |
Pnpm remove |
| Npm run |
Pnpm |
Pnpm的存储store
在pnpm7.0之前,统一的存储位置是 ~/.pnpm-score中的
在pnpm7.0之后,统一的存储位置进行了改变:
在Linux上 默认是 ~/local/share/pnpm/store
在Windows上: %LOCALAPPDATA%/pnpm/store
在macOS上:~/Library/pnpm/store
我们可以通过一些命令 获取这个目录:获取当前活跃的store目录
Pnpm store path
另外一个非常重要的store命令是 prune(修剪):从store中删除当前未被引用的包来释放store的空间
Pnpm store prune
四 邂逅Webpack和打包过程
内置模块path
path模块用于对 路径和文件 进行处理 提供了很多好用的方法
如果我们在window上使用 \ 来作为分隔符开发了一个应用程序 要部署到linux上面该怎么办
显示路径会出现一些问题 ; 为了屏蔽它们之间的差异,在开发中对于路径的操作我们可以使用path模块
path常见的API
从路径中获取信息
dirname:获取文件的父文件夹
basename:获取文件名
extname:获取文件扩展名
路径的拼接: path.join
拼接绝对路径:path.resolve
path.resolve()方法 把一个路径或路径片段的序列解析为一个绝对路径
给定的路径的序列是从右往左被处理的 后面每个path被依次解析 直到构造完成一个绝对路径
在处理完所有给定path的段之后,还没有生成绝对路径,则使用当前工作目录
生成的路径被规范化并删除尾部斜杠 零长度path段被忽略
如果没有path传递段,path.resolve()将返回当前工作目录的绝对路径
1 认识webpack工具
认识webpack
目前前端的开发已经变得越来越复杂了
如 开发过程中我们需要通过 模块化的方式来开发
如 会使用一些 高级的特性来加快我们的开发效率或者安全性 如ES6+ TS开发脚本逻辑 通过sass less邓方式编写css样式代码
如 开发过程中 还希望 实时的监听文件的变化 并且 反映到浏览器上 提高开发效率
如 开发完成后 还需要将代码进行压缩 合并 以及其他相关优化
但是对于很多的前端开发者来说 不需要思考这些问题 日常开发中 根本没有面临这些问题
因为目前前端开发 通常会直接使用 三大框架来开发:Vue React Angular
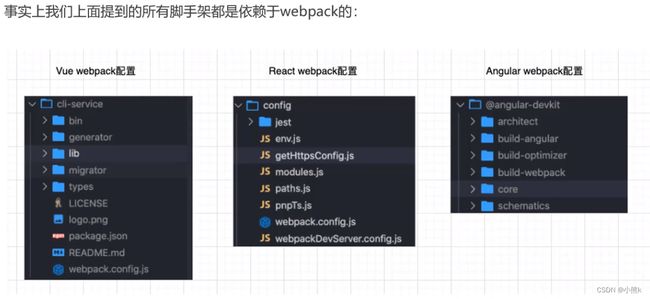
事实上,这三大框架的创建过程 都是借助于脚手架(CLI)的
事实上,Vue-CLI create-react-app Angular-CLI都是基于webpack 来帮助我们支持模块化 less TS 打包优化等
脚手架依赖webpack
Webpack到底是什么呢?
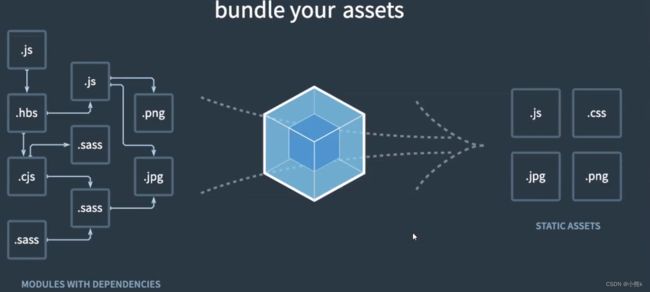
官方解释为:webpack is a static module bundler for modern JavaScript applications
webpack是一个静态的模块化打包工具 为现代的JS应用程序
打包bundler:webpack可以将帮助我们进行打包,所以是一个打包工具
静态的static:最终可以将代码打包成最终的静态资源(部署到静态服务器)
模块化module: webpack默认支持各种模块化开发 ES Module CommonJS AMD等
现在的modern:因为现代前端开发面临各种各样的问题,才催生了webpack的出现和发展
Webpack官方图
Vue项目加载的文件有哪些?
JavaScript的打包:
将ES6转换成ES5的语法;
TypeScript的处理,将其转换成JavaScript
Css的处理:
CSS文件模块的加载 提取;
Less Sass等预处理器的处理
资源文件img font
图片img文件及字体font文件的加载
HTML资源的处理:
打包HTML资源文件
处理vue项目的SFC文件.vue文件;
Webpack的使用前提
webpack官方文档:https://webpack.js.org
中文官方文档:https://webpack.docschina.org
DOCUMENTATION:文档详情,也是我们最关注的!
webpack的运行是依赖Node环境的,所以电脑上必须有Node环境
Webpack的安装
webpack的安装目前分为两个:webpack webpack-cli
它们的关系是什么呢?
执行webpack命令 会执行node_modules下的.bin目录下的webpack
webpack在执行时是依赖webpack-cli的,如果没有安装就会报错
webpack-cli中代码执行时 才是真正利用webpack进行编译和打包的过程
所以安装webpack时 我们需要同时安装webpack-cli(第三方的脚手架事实上是没有使用webpack-cli的 而是类似于自己的vue-service-cli的东西)

2 webpack基本打包
Webpack的默认打包
通过webpack进行打包
在目录下 直接执行 webpack命令
webpack
生成一个dist文件夹,里面存放了一个main.js文件 就是我们打包后的文件;
这个文件中的代码被压缩和丑化
我们发现 代码中存在的ES6语法 如 箭头函数 const等 这是因为默认情况下 webpack并不清楚我们打包后的文件是否需要转成ES5之前的语法 后续我们需要通过babel进来转换和设置
我们发现是可以正常进行打包的,但有一个问题,webpack如何找到我们的入呢?
当我们运行webpack时 webpack会查找当前目录下的 src/index.js作为入口
所以 如果当前项目中没有存在src/index.js文件 那么会报错
当然 我们也可以通过配置 来指定入口和出口
npx webpack --entry ./src/main.js --output-path ./build创建局部的Webpack
前面我们直接执行webpack命令使用的是全局的webpack 如果希望使用局部的按照下面的步骤进行:
1 创建package.json文件 用于管理项目信息 库依赖等
npm init2 安装局部的webpack
npm install webpack webpack-cli -D3 使用局部的webpack
npx webpack4 在package.json中创建scripts脚本,执行脚本打包即可
"scripts":{
"build":"webpack"
}3 webpack 配置文件
webpack配置文件
在通常情况下,webpack需要打包的项目是非常复杂的,并且我们需要一系列的配置来满足要求,默认配置必然是不可以的
我们在根目录下创建一个webpack.config.js文件,作为webpack配置文件
const path = require('path')
// 导出配置信息
module.exports = {
entry:"./src/main.js",
output:{
filename:"bundle.js",
path:path.resolve(__dirname,"./dist")
}
}指定配置文件
如果我们的配置文件不是webpack.config.js的名字 而是其他的?
如 我们将webpack.config.js修改成xiong.config.js
这时 我们通过 --config来指定对应的配置文件
webpack --config xiong.config.js但是每次执行命令来对源码进行编译 会很繁琐,所以我们可以在packa.json中增加一个脚本
{
Debug
"scripts":{
"build":"webpack --config xiong.config.js"
},
"devDependencies":{
"webpack":"^5.14.0",
"webpack-cli":"^4.3.1"
}
}Webpack的依赖图
webpack到底是如何对我们的项目进行打包的?
事实上 webpack在处理应用程序时 会根据命令或者配置文件找到入口文件
从入口开始 生成一个依赖关系图 这个依赖关系图 会包含应用程序中所需的所有模块(如 js css 等)
然后遍历图结构,打包成一个个模块(根据文件的不同使用不同的loader来解析)

4 编写和打包CSS文件
css-loader的使用
Loader 可以用于对 模块的源代码 进行转换
我们可以将css文件也看成一个模块,我们通过import来加载这个模块
在加载这个模块时 webpack其实并不知道如何对其进行加载,必须要指定对应的loader来完成这个功能
我们需要一个什么样的loader?
对于加载css文件来说 我们需要一个可以读取css文件的loader
这个loader最常用的是css-loader
CSS-loader的安装
npm install css-loader -DCSS -loader 的使用方案
如何使用loader来加载css文件呢? 有三种方式:
1 内联方式:
在引入的样式前加上使用的loader,并使用!分割
import "css-loader!../css/style.css"2 CLI方式(webpack5中不再使用)
已淘汰..
3 配置方式
loader配置方式
我们的webpack.config.js文件中写明配置信息:
module.rules中允许我们配置多个loader(因为我们也会继续使用其他的loader,来完成其他文件的加载)
这种方式可以更好的表示loader的配置 也方便后期的维护 同时也让你对各个loader有一个全局的概览
module.rules的配置如下:
rules属性对应的值是一个数组[Rule]
数组中存放的是一个个Rule,Rule是一个对象,对象中可以设置多个属性
test属性:用于对resource(资源)进行匹配,通常会设置正则表达式
use属性:对应的值是一个数组:[UseEntry]
UseEntry是一个对象 可以通过对象的属性来设置一些其他的属性
loader:必须有一个loader属性,对应的值是一个字符串
options:可选属性 值是一个字符串或对象,值会被传入loader中
query:目前已经使用options来替代;
传递字符串(如:use:['style-loader'])是loader属性的简写方式:(如:use[{loader:'style-loader'}])
loader属性:Rule.use:[{loader}]的简写
认识style-loader
可以通过css-loader来加载css文件了
但是发现 这个css在我们的代码中没有生效(页面没效果)
为什么呢?
因为css-loader只负责将.css文件进行解析,并不会将解析之后的css插入到页面中
如果我们希望再完成 插入 style的操作,我们还需要另外一个loader 就是 style-loader
安装 style-loader
npm install style-loader -D配置style=loader
在配置文件中 添加 style-loader
注:因为loader的执行顺序是从右向左(或者说 从下到上,从后到前)所以我们需要将style-loader写到css-loader的前面
use:[
// 注 style-loader写到css-loader的前面
{loader:"style-loader"}
{loader:"css-loader"}
]5 编写和打包LESS文件
如何处理less文件?
在开发中 可能会使用less sass styus的预处理器 来编写css样式 效率更高
那么 如何让我们的环境支持这些预处理器?
首先我们需要确定less sass 等编写的css需要通过工具转换成普通css
如 下面编写的less样式:
@fontSize: 50px;
@fontColor:blue;
.title {
font-size: @fontSize;
color: @fontColor;
}可以使用less-loader来处理
先使用less工具转换到css 再用style
npm install less-loader -D
{
test:/\.less$/,
use:["style-loader","css-loader","less-loader"]
}6 postcss工具处理CSS
认识PostCSS工具
什么是PostCSS呢?
他是一个通过Js来转换样式的工具
可以帮助我们进行一些CSS的转换和适配 如 自动添加浏览器前缀,css样式的重置
实现这些功能 需要借助于PostCSS对应的插件
如何使用PostCSS呢? 分为两步:
一:查找PostCSS在构建工具中的拓展,如webpack和postcss-loader;
二:选择可以添加你需要的PostCSS相关的插件
Postcss-loader
可以借助于构建工具:
在webpack中使用postcss就是使用postcss-loader来处理
我们来安装postcss-loader:
npm install postcss-loader -D我们修改加载css的loader:(配置文件过多,给出一部分了)
注:因为postcss需要有对应的插件才会起效果.所以我们需要配置它的plugin
{
loader:"postcss-loader",
options:{
postcssOptions:{
plugins:[
require('abtoprefixer')
]
}
}
}单独的postcss配置文件
因为我们需要添加前缀,所以要安装autoprefixer;
我们可以将这些配置信息放到一个单独的文件中进行管理
在根目录下创建postcss.config.js
module.exports = {
plugins:[
// require("autoprefixer")
"autoprefixer"
],
}postcss-preset-env
preset => 预设
事实上,在配置postcss-loader时 我们配置插件并不需要使用autpprefixer
我们可以使用另外一个插件:postcss-preset-env
postcss-preset-env也是一个postcss的插件
它可以帮助我们将一些现代的CSS特性,转成大多数浏览器认识的CSS 且会根据目标浏览器或者运行时环境添加所需的polyfill
也包括会自动帮助我们添加autoprefixer(相当于已经内置了autoprefixer)
首先 我们需要安装它
npm install postcss-preset-env -D之后 我们直接修改之前的autoorefixer即可:
plugins:[
"postcss-preset-env"
],