阿旭机器学习实战【5】KNN算法实战练习2:利用KNN模型进行手写体数字识别
关于KNN算法详细介绍可以参考我之前的博文《阿旭机器学习实战【1】K-近邻算法(KNN)模型应用实例,以及图像表征方式》,在这里就不做详细介绍了。
目录
- 1. 数据集说明
- 2. 读取数据并查看数据信息
- 3. 加载所有图片数据并进行处理
- 4. 构建模型并进行预测
- 5. 用图像来展示预测的数字和其预测情况
- 6. 将算法保存到本地
案例及数据集获取方式见文末。 需要的小伙伴可自行获取学习,欢迎大家一起共同学习交流。
1. 数据集说明
手写体数字识别数据集共有5000个样本图片。包含0-9这10个数字类别,每个数字为一个文件夹,每个文件夹下存放500张该数字的图片。
图片信息:
图片大小:像素为28 * 28
图片类型:二维灰度图片,每个数字的数值范围为0-255

2. 读取数据并查看数据信息
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
%matplotlib inline
# 读取一个图片数据,并查看形状
z = plt.imread("./data/0/0_1.bmp")
z.shape
(28, 28)
plt.figure(figsize=(1,1))
plt.imshow(z,cmap="gray")

3. 加载所有图片数据并进行处理
# 读取所有的图片,并且给这些图片加上标签
data = [] # 用于存放图片的数据
target = [] # 用于存放图片对应的标签
for i in range(10):
for j in range(1,501):
im = plt.imread("./data/%d/%d_%d.bmp"%(i,i,j))
# 把读取到的图片的数据存放
data.append(im)
# 把图片对应的标签存储
target.append(i)
# 由于sklearn不接受列表数据,我们需要把data和target转化成数组
data = np.array(data)
target = np.array(target)
# 查看数据形状
data.shape
(5000, 28, 28)
# 将二维图片数据点展开成一维数据,28 * 28 = 784
data_res = data.reshape(5000,-1)
data_res.shape
(5000, 784)
4. 构建模型并进行预测
# 切分数据
x_train,x_test,y_train,y_test = train_test_split(data_res,target,test_size=0.02)
# 构建模型
knn = KNeighborsClassifier()
# 对模型进行训练
knn.fit(x_train,y_train)
# 查看模型的准确度
knn.score(x_test,y_test)
0.92
模型预测准确率为92%
5. 用图像来展示预测的数字和其预测情况
# 利用模型对测试数据进行预测
y_ = knn.predict(x_test)
plt.figure(figsize=(10*2,10*1))
# 打印出预测错误的数据进行查看
error_num = 0
for i in range(100):
axes = plt.subplot(2,10,error_num+1)
if y_[i] != y_test[i]:
axes.imshow(x_test[i].reshape(28,28),cmap="gray")
axes.axis("off")
axes.set_title("True:%d\nPredict:%d"%(y_test[i],y_[i]))
error_num += 1
if error_num == 20:
break
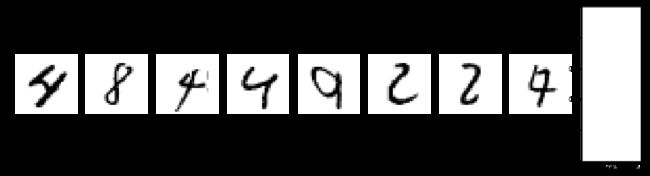
6. 将算法保存到本地
# joblib这个模块可以将训练成熟的算法保存到本地,下次再用的时候,不需要再次训练
from sklearn.externals import joblib
# 将上面的knn这个模型保存到本地,会在本地生成一个模型文件
joblib.dump(knn,"./digist_reco.m") # 将knn模型打包成一个本地的静态文件
['./digist_reco.m']
# 加载本地算法
d = joblib.load("./digist_reco.m")
# 进行预测
d.predict(x_test[:10])
array([1, 6, 5, 1, 9, 8, 0, 8, 9, 3])
# 同样我们也可以将数组打包到本地,生成.npy文件,加载就用np.load('文件路径')
np.save("./11",data_res)
如果内容对你有帮助,感谢记得点赞+关注哦!
关注我的公众号:
阿旭算法与机器学习,发送:KNN实战2,即可获取本文pdf及实战案例所使用的数据集。
更多干货内容持续更新中…