初见深度学习,基于cuDNN和TensorFlow2.9
目录
-
-
- 起因
- 环境准备
- 数据预处理
-
- 模块导入
- 加载数据
- 大小检查以及重塑
- 分割数据集
- 取出标签值范围
- 类别化Y
- 模型构建与训练
-
- 构建模型
- 编译与训练模型
- 训练模型
- 绘制损失量和准确率曲线
- 导出模型图
- 结语
-
起因
在昨天一天在NVIDIA DLI系列课程:深度学习新手入门系列课程学习了一天。
了解了深度神经网络(Deep Neural Network),卷积神经网络(Convolution Neural Networl)和循环神经网络(Recyclabel Neural Netowork)等与网络架构的知识。
也学习了什么是神经元(Neruons),什么是网络密度(Network Density)。
觉得自己似乎,好像,em…之后,我准备自己动手,脱离NVIDIA GPU Cloud环境,在自己本地开始训练一个属于自己的深度神经网络的Helloworld程序。
环境准备
本次实验,我选择使用基于WSL2内核的Ubuntu20.04子系统
(base) root@ElinsLaptop:~/dlTest# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.4 LTS
Release: 20.04
Codename: focal
(base) root@ElinsLaptop:~/dlTest#
CUDA方面与主机保持一致,使用11.7,cuDNN版本为8.4.1.50
(base) root@ElinsLaptop:~/cudnnInstall# nvidia-smi
Sun Jul 10 18:25:29 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.57 Driver Version: 516.59 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 On | N/A |
| N/A 50C P8 9W / N/A | 988MiB / 6144MiB | 6% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
(base) root@ElinsLaptop:~/cudnnInstall# ll
total 830792
drwxr-xr-x 3 root root 4096 Jul 10 17:16 ./
drwx------ 21 root root 4096 Jul 10 18:07 ../
drwxr-xr-x 4 25503 tape 4096 May 20 15:55 cudnn-linux-x86_64-8.4.1.50_cuda11.6-archive/
-rw-r--r-- 1 root root 850711772 Jul 10 16:54 cudnn-linux-x86_64-8.4.1.50_cuda11.6-archive.tar.xz
-rw-r--r-- 1 root root 0 Jul 10 17:16 importLib.sh
(base) root@ElinsLaptop:~/cudnnInstall#
Python方面,使用基于Python3.9的Anaconda.20225月月度更新版本,具体Conda版本号为:4.13.0
TensorFlow则采用最新版本:2.9.1-gpu
(base) root@ElinsLaptop:~/cudnnInstall# conda -V
conda 4.13.0
(base) root@ElinsLaptop:~/cudnnInstall# conda list | grep tensorflow
tensorflow-estimator 2.9.0 pypi_0 pypi
tensorflow-gpu 2.9.1 pypi_0 pypi
tensorflow-io-gcs-filesystem 0.26.0 pypi_0 pypi
(base) root@ElinsLaptop:~/cudnnInstall#
数据预处理
模块导入
# Import the dependencies
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout
from tensorflow.compat.v1.keras.layers import CuDNNLSTM
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import os
import tensorflow as tf
加载数据
我这里使用了来自sklearn.dataset下的鸢尾花(Iris)数据集,使用load_iris()函数来加载神剧
# Load the data
iris = load_iris()
该数据包含两组已标记的numpy.ndarray类型数据,分别为data和target,因此我们需要将其分别存储为X和y。
# Load the features and labels
X = iris.data
y = iris.target
大小检查以及重塑
因为原始是矩阵,因此我们可以直接调用.shape属性来查看它的大小,该属性的返回值为一个Python 元祖(Tuple)类型数据,包含X维度的长度与Y维度的长度
# Check and Reshape
X.shape,y.shape
((150, 4), (150,))
可以看到:X和y的X维度长度都是150,X的y维度是4,而y的y维度是1(因为是label).
那么我可以直接调用reshape()函数直接将其重塑为:(-1,2,2,)的长度,这也以为着X中每个元素的维度将从(4,1)转换为(2,2,),至于这里为什么最后一个逗号后面不是1,以及这里为什么要把(4,1)转变为`(2,2,)``,我们后文自会解释。
分割数据集
我们使用sklearn.modelelection.train_test_split()来对数据进行分割。
# Split the data into train and test
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
取出标签值范围
# Extract the label range
np.min(y),np.max(y)
(0, 2)
这里我们可以看到,标签值的最小值为:0,最大值为:2,那么也就是标签的分类长度是3.
类别化Y
我们是用keras.utils.to_categoryical()函数来对y_train和y_test进行类别化处理,该处理法是一种基于独热编码(One Hot Encoding)编码器,对于我们的深度神经网络而言,处理逻辑化的数据(即0或1)比其他类型数据更为得心应手,因此我们这里对y_train和y_test进行编码
# Categorize the labels
import tensorflow.keras as keras
y_train = keras.utils.to_categorical(y_train,3)
y_test = keras.utils.to_categorical(y_test,3)
模型构建与训练
构建模型
这里我们使用keras.model.Sequential()函数来初始化我们的模型,当然我们并不能直接去调用模型,因为它是一个网络,因此我们需要为其添加层。
首先我们添加一个Dense来创建我们的输入层,分配512个神经元,激活函数为relu,你不必了解relu激活函数的工作原理(至少NVIDIA是这么教我的),输入大小分配为:(2,2,)
还记得我们之前的reshpe()操作吗?没错,这里正是因为rshape了,所以我们的输入大小是2x2。
之后我们创建一个CuDNNLSTM()层,并分配100个神经单元。
那么何为LSTM呢?LSTM是一个种名为:长短时记忆(Long Shor Term Moemory)的模型。
与普通的深度神经网络不同,LSTM是一种RNN(循环神经网络),用于存储迭代过程中模型所学到的知识。
还记得的我们之前reshape过得数据吗,LSTM是一种三维数据计算网络,如果我们将数据以原始大小(4,1)传入,那么LSTM模型则会报错,告诉你dim(Dimension)不等于3,因此无法开始训练。

需要注意,在本案例中一定要是用CuDNNLSTM()来创建RNN层,否则会cuDNN会提示输入逻辑模式不正确。
# Create Model
model = Sequential()
model.add(Dense(512,activation='relu',input_shape=(2,2,)))
model.add(CuDNNLSTM(100))
model.add(Dense(3,activation='softmax'))
2022-07-10 18:08:21.261334: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:961] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2022-07-10 18:08:21.261372: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 3920 MB memory: -> device: 0, name: NVIDIA GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5
可以看到,因为我的CPU是笔记本的酷睿i7-9750H处理器,拥有6核心。12线程,而且使用的Windows和Ubuntu版为家庭版进和WSL2,因此不支持工作站级别的NUMA CPU节点调度策略,所以TensorFlow很主动的为我们使用CUDA GPU来初始化模型了,可以通过Log看到,我的RTX 2060已经被初始化,VRAM分配了4GB,至于为什么不是完整的6GB,是因为TensorFlow的内存调度机制,无论是CPU,GPU还是TPU,都是属于按需分配,如果我们将内存选项设置为:auto_growth,那么TensorFlow将视数据的大小,维度以及模型的复杂程度动态分配显存。
编译与训练模型
调用Sequential.compile()来编译我们的模型,编译参数loss损失函数我们使用categorical_crossentropy(二元交叉熵),因为我们之前对y_train,y_test使用了.to_categorical()函数来进行编码,因此这里二元交叉熵来作为损失函数编译模型,另外度量参数metrics是一个可接受多方法的参数,因此metrics的参数类型需要传入一个Python 列表(List)。
# Compile the model
model.compile(loss='categorical_crossentropy', metrics=['accuracy'])
使用Sequential,summary()查看模型总结
# Checkout model summary
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 2, 512) 1536
cu_dnnlstm (CuDNNLSTM) (None, 100) 245600
dense_1 (Dense) (None, 3) 303
=================================================================
Total params: 247,439
Trainable params: 247,439
Non-trainable params: 0
_________________________________________________________________
可以看到我们为网络添加的三个层都被识别出来了,另外总共247,439个连接的利用率为100%。
训练模型
我们使用model.fit()来训练模型,参数如下:
- X_train:训练集X
- y_train:训练集y
- epochs:模型迭代次数
- batch_size:簇大小,即一组数据中有多少个样本
- validation_data:需要将验证集X,y使用元祖打包传入
# Train the model
history = model.fit(X_train, y_train, epochs=20,batch_size=48,validation_data=(X_test,y_test))
Epoch 1/20
3/3 [==============================] - 0s 41ms/step - loss: 0.1954 - accuracy: 0.9833 - val_loss: 0.1687 - val_accuracy: 0.9667
Epoch 2/20
3/3 [==============================] - 0s 36ms/step - loss: 0.1882 - accuracy: 0.9833 - val_loss: 0.2252 - val_accuracy: 0.8667
Epoch 3/20
3/3 [==============================] - 0s 25ms/step - loss: 0.3117 - accuracy: 0.8417 - val_loss: 0.1562 - val_accuracy: 0.9667
Epoch 4/20
3/3 [==============================] - 0s 26ms/step - loss: 0.1743 - accuracy: 0.9750 - val_loss: 0.1380 - val_accuracy: 1.0000
Epoch 5/20
3/3 [==============================] - 0s 24ms/step - loss: 0.1703 - accuracy: 0.9500 - val_loss: 0.1337 - val_accuracy: 1.0000
Epoch 6/20
3/3 [==============================] - 0s 25ms/step - loss: 0.1685 - accuracy: 0.9583 - val_loss: 0.2021 - val_accuracy: 0.9333
Epoch 7/20
3/3 [==============================] - 0s 26ms/step - loss: 0.2108 - accuracy: 0.9083 - val_loss: 0.1243 - val_accuracy: 1.0000
Epoch 8/20
3/3 [==============================] - 0s 22ms/step - loss: 0.1689 - accuracy: 0.9583 - val_loss: 0.1299 - val_accuracy: 0.9667
Epoch 9/20
3/3 [==============================] - 0s 24ms/step - loss: 0.1522 - accuracy: 0.9500 - val_loss: 0.1944 - val_accuracy: 0.8667
Epoch 10/20
3/3 [==============================] - 0s 25ms/step - loss: 0.1607 - accuracy: 0.9667 - val_loss: 0.1151 - val_accuracy: 0.9667
Epoch 11/20
3/3 [==============================] - 0s 24ms/step - loss: 0.1527 - accuracy: 0.9583 - val_loss: 0.1125 - val_accuracy: 1.0000
Epoch 12/20
3/3 [==============================] - 0s 21ms/step - loss: 0.1953 - accuracy: 0.9083 - val_loss: 0.2181 - val_accuracy: 0.9000
Epoch 13/20
3/3 [==============================] - 0s 22ms/step - loss: 0.2385 - accuracy: 0.8917 - val_loss: 0.1262 - val_accuracy: 0.9667
Epoch 14/20
3/3 [==============================] - 0s 25ms/step - loss: 0.1403 - accuracy: 0.9917 - val_loss: 0.1436 - val_accuracy: 0.9333
Epoch 15/20
3/3 [==============================] - 0s 23ms/step - loss: 0.1945 - accuracy: 0.9333 - val_loss: 0.1004 - val_accuracy: 1.0000
Epoch 16/20
3/3 [==============================] - 0s 20ms/step - loss: 0.1326 - accuracy: 0.9750 - val_loss: 0.0972 - val_accuracy: 1.0000
Epoch 17/20
3/3 [==============================] - 0s 20ms/step - loss: 0.1725 - accuracy: 0.9333 - val_loss: 0.2306 - val_accuracy: 0.8667
Epoch 18/20
3/3 [==============================] - 0s 21ms/step - loss: 0.1745 - accuracy: 0.9417 - val_loss: 0.0985 - val_accuracy: 1.0000
Epoch 19/20
3/3 [==============================] - 0s 20ms/step - loss: 0.1476 - accuracy: 0.9583 - val_loss: 0.1381 - val_accuracy: 0.9667
Epoch 20/20
3/3 [==============================] - 0s 22ms/step - loss: 0.1577 - accuracy: 0.9583 - val_loss: 0.1085 - val_accuracy: 0.9667
绘制损失量和准确率曲线
x = len(history.history['loss'])
y1 = history.history['loss']
y2 = history.history['val_loss']
y3 = history.history['accuracy']
y4 = history.history['val_accuracy']
plt.figure(figsize=(10,8))
plt.title('Loss and Accuracy')
plt.plot(range(x),y1,label='Loss')
plt.plot(range(x),y2,label='Validation Loss')
plt.plot(range(x),y3,label='Accuracy')
plt.plot(range(x),y4,label='Validation Accuracy')
plt.legend()
plt.show()
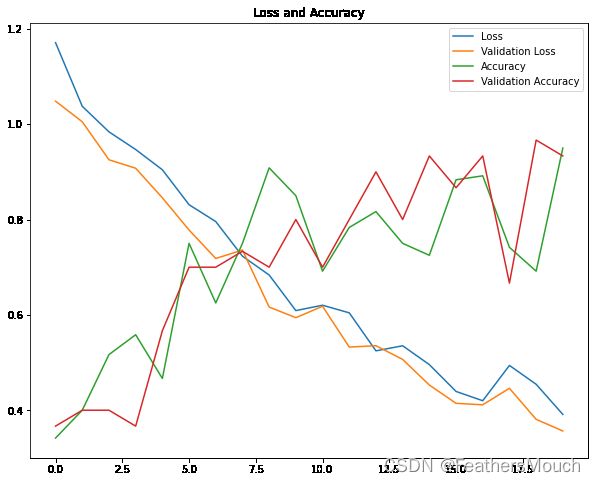
可以看到,训练集和验证集的走势几乎完全重合,这也说明我们的模型训练的非常成功。
导出模型图
# Visualize Model
from keras.utils.vis_utils import plot_model
plot_model(model,to_file='model_vis.png',show_shapes=True,show_dtype=True,show_layer_activations=True,show_layer_names=True)

结语
在NVIDIA DLI的学习经历是很轻松愉快多的,也让我这么一个菜鸡学得到了使用的深度学习知识。