神经网络-激活函数
上一篇讲了一下多层前馈神经网络的结构,这一篇我们来具体讲一讲里面的激活函数。
对于一个神经元,先计算输入向量和权重向量的内积,加上偏置项,再送入一个函数进行变化。这个函数就是激活函数。在神经网络的结构里,除了输入层的神经元不需要激活函数,后面的若干层隐藏层和输出层的神经元都需要激活函数。
为什么需要激活函数
因为如果不使用激活函数函数,整个神经网络其实还是一个线性模型,并不能解决非线性问题。假如,现在有一个四层的神经网络,第一层为输入向量x,第一层至第二层的权重向量为 ,偏置项为
,偏置项为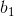 ;第二层至第三层的权重向量为
;第二层至第三层的权重向量为 ,偏置项为
,偏置项为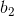 ; 第三层至第四层的的权重向量分别为
; 第三层至第四层的的权重向量分别为![]() ,偏置项为
,偏置项为![]() 。
。
第二层输出结果 :![]()
第三层输出结果:![]()
第四层输出结果:![]()
我们可以看到最后的结果还是一个线性函数:
![]()
给每一个神经元加上一个非线性的激活函数以后,结果就会变为非线性 。
作为激活函数需要哪些条件:
- 非线性,因为这样才能是网络变为非线性;
- 几乎处处可导,因为在反向传播的过程中需要求导;
- 单调
- 连续
接着我们来看一下由激活函数导致的一个问题,梯度消失。神经网络其实很早就已经出现了,但是在一段时间后就没落了。主要就是因为梯度消失,会影响模型的训练。
梯度消失
在之前我们说过在训练神经网络的时候会用到反向传播算法结合梯度下降来更新神经网络每一层的参数。每一层的梯度计算公式为:
![]()
我们可以看到每次都要计算激活函数的导数,如果激活函数的导数是一个小于1的数,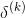 的值在反向传播的过程中就会越变越小,这样就会导致在反向传播的过程中梯度消失,影响神经网络的训练。
的值在反向传播的过程中就会越变越小,这样就会导致在反向传播的过程中梯度消失,影响神经网络的训练。
饱和性
激活函数的饱和性会对梯度消失产生影响。饱和性又分为硬饱和,软饱和。
软饱和可以定义为:
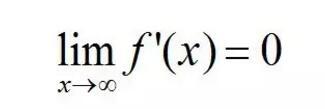
与极限的定义类似,饱和也分为左饱和和有饱和。
软饱和左饱和:
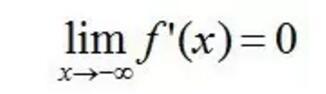
软饱和右饱和:
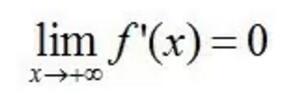
硬饱和可以定义为:
f'(x)=0,当 |x| > c,其中 c 为常数
同理,硬饱和也可以分为左饱和和又饱和。
常用的激活函数
1、sigmoid函数:
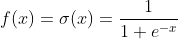
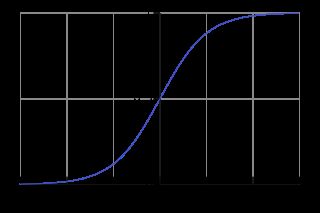
sigmoid函数导数:
![]()
sigmoid函数适合需要0~1的场合,比如概率,适合作为输出层。因为它的值域在0到1之间。sigmoid函数在特征相差比较复复杂或是相差不是特别大时,需要更细微的分类判断的时候,效果会好一些。因为sigmoid函数具有软饱和性,它的导数的最大值为0.25,所以在神经网络的层数很深的情况下,就容易参数梯度消失。
2、tanh函数
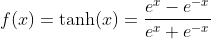

![]() , tanh函数和sigmoid函数之间的关系
, tanh函数和sigmoid函数之间的关系
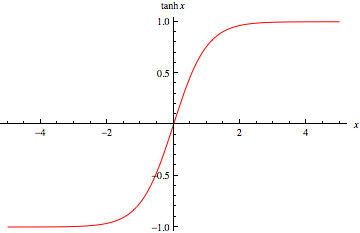
tanh函数导数
![]()
tanh函数适合需要-1~1的场合,因为它的值域在-1到1之间。tanh函数也具有软饱和性,它导数的最大值为1,相比于sigmoid函数能够缓解一点梯度消失。因为 tanh 的输出均值比 sigmoid 更接近 0,SGD会更接近 natural gradient(一种二次优化技术),从而降低所需的迭代次数。tanh函数在特征相差明显时的效果会很好。需要注意的是,使用sigmoid和tanh作为激活函数的话,一定要注意对输入层进行归一化,否则激活后的值都会进入平坦区,使隐含层的输出全部趋同。但是下面的ReLU并不需要输入归一化来防止它们达到饱和。
3、ReLU函数
ReLU函数导数
ReLU函数为左侧硬饱和激活函数。但是,相比于之前两个函数,能够更好的缓解梯度消失问题。但是会产生一个ReLU坏死的情况。
4、Leaky ReLU
, 参数并不固定为0.01
Leaky ReLU导数
Leaky ReLU在ReLU的基础之上做了一个小小的改动,当x<0时,f(x)的值不为0,而是一个小于1的系数乘以x。这样可以防止dead神经元。
除了通过改变激活函数来缓解梯度消失,也有其他缓解梯度消失的方法。例如:DBN中的分层预训练,Batch Normalization的逐层归一化,Xavier和MSRA权重初始化等代表性技术。
参考链接:https://docs.deepin.io/?p=753
https://zhuanlan.zhihu.com/p/22142013
Amari, S.-I., Natural gradient works efficiently in learning. Neural computation, 1998. 10(2): p. 251-276.