Text to image论文精读PDF-GAN:文本生成图像新度量指标SSD Semantic Similarity Distance
SSD,全称为Semantic Similarity Distance,是一种基于CLIP的新度量方式,是西交利物浦大学学者提出的一种新的文本生成图像度量指标,受益于所提出的度量,作者进一步设计了并行深度融合生成对抗网络(PDF-GAN),它可以融合不同粒度的语义信息并捕获准确的语义。文章22年10月在arcxiv发表。
论文地址:https://arxiv.org/abs/2210.15235
本篇文章是阅读这篇论文的精读笔记
一、原文摘要
从给定文本中生成一致且高质量的图像对于视觉语言理解至关重要。尽管在生成高质量图像方面取得了令人印象深刻的结果,但文本图像一致性仍然是现有基于GAN的方法中的一个主要问题。特别地,最流行的度量R精度可能不能准确地反映文本图像的一致性,这常常导致生成的图像中的语义非常误导。尽管其意义重大,但如何设计出一个更好的文本图像一致性度量,在社区中仍处于探索之中,这一点令人惊讶。
在本文中,我们进一步开发了一种新的基于CLIP的度量,称为语义相似度距离(SSD),该度量既从分布角度理论上建立,又在基准数据集上进行了实证验证。受益于所提出的度量,我们进一步设计了并行深度融合生成对抗网络(PDF-GAN),它可以融合不同粒度的语义信息并捕获准确的语义。配备了两个新颖的即插即用组件:硬否定句构造器和语义投影,所提出的PDF-GAN可以缓解不一致的语义并弥合文本-图像语义差距。一系列实验表明,与当前最先进的方法相比,我们的PDF-GAN可以显著提高文本图像的一致性,同时在CUB和COCO数据集上保持良好的图像质量。
二、为什么提出SSD?
根据文本描述生成图像,通常称为文本到图像生成(T2I),是一项具有挑战性的任务,需要生成高质量的图像并保持文本图像的一致性。
尽管RiFeGAN、SegAttnGAN、DF-GAN取得了高质量的分数,在从文本描述生成高质量图像方面取得了令人印象深刻的成果,但他们仍然难以在复杂的语义中保持文本图像的一致性。一旦文本描述变得更加复杂,生成的图像的语义可能会与文本不匹配。
基于此作者提出了一种新的基于CLIP的文本图像一致性度量,称为语义相似度距离(SSD)。
三、介绍与创新点
对于T2I合成任务,CLIP提供了一个联合语言视觉嵌入空间,可以直接测量图像和文本的语义分布之间的相似性。我们的SSD是通过结合两个阶级矩项设计的:
- 一阶矩项直接测量文本图像的语义相似性,反映生成的图像和文本之间的语义偏差;
- 二阶矩项评估了以文本为条件的合成图像和真实图像之间语义变化的差异,表明生成的图像中的语义多样性也应该与真实图像中的一致。二阶矩项可以为精确的语义带来更多的可信度,在总体一致性和详细一致性之间平衡评估。
在理论方面,作者表明SSD的基本原理植根于使用修正的Wasserstein距离来测量两个分布的散度。还表明,它可以与最近的两个指标密切相关,即CLIPScore(CS)(Hessel等人2021)和Conditional Frechet Inception Distance(CFID)(Soloveitchik等人2021),且在测量语义一致性方面表现出更理想的特性。
通过实验,作者发现:
- 不同层次的语义信息可以显著帮助文本图像的一致性。然而,语义差距将导致对抗性损失和语义感知损失之间的优化冲突,因此,随意地添加语义感知损失会削弱语义监督,导致文本图像一致性的不良表现。
- 用于鉴别的不匹配样本通常利用成批样本或来自其他类别的随机样本,这可能导致文本图像一致性的下降。
根据上述发现,我们提出了一种新的一阶段T2I生成框架,命名为PDF-GAN。
文章创新点如下:
- 引入了一种新的度量——语义相似度距离(Semantic Similarity Distance),它可以评估文本图像的相似度以及生成图像与受文本约束的真实图像之间的语义变化差异。SSD理论上是有根据的,可以在不同的数据集上进行交叉比较。
- 提出了一个新的框架——并行深度融合生成对抗网络(PDF-GAN),具有语义感知损失和PFM,以融合不同层次的语义信息。
- 设计了一个HNSC,用于挖掘hard negative文本样本,并设计了SProj,用于缓解语义差距,增强文本图像一致性。
四、文本生成图像专用域定量指标
4.1、R-precision(R分数)
目前文本生成图像专用域合成度量有R-precision(R分数),其通过评估生成的图像是否比其他99个随机采样的文本更符合给定文本来判断文本图像的一致性。这种度量可能不能准确反映文本和图像之间的直接一致性。
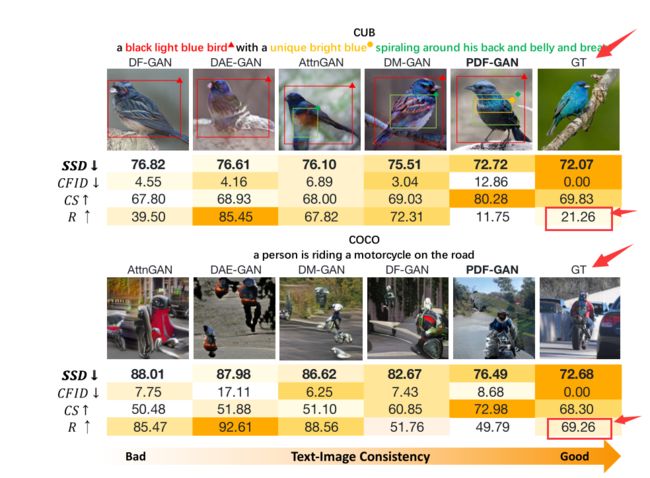
如上图所示,GT表示真实图像,可以看到,在有些情况下,真实图像反而得不到很好的R分数,这会在生成的图像中产生非常误导的语义。
4.2、SOA(语义对象准确度)
另外一种专用评估指标:语义对象准确度(SOA)(Hinz、Heinrich和Wermter 2020)是最近提出的一种专门用于评估多对象文本图像一致性的度量标准,在不评估对象属性和关系的情况下,仍然无法测量整个语义一致性。更严重的是,SOA不能应用于通常只有一个对象出现在生成的图像中的数据集,如CUB。为了缓解这些问题,研究人员必须依靠人类评估。然而,该过程通常成本高昂,并且其设置在不同的方法中差异很大,这使得它更难在实际场景中应用。
4.3、其他
CS(Hessel等人2021)设计用于图像字幕,但剪辑嵌入的余弦相似性可能不会明确将属性绑定到对象,并忽略语义变化(Ramesh等人2022)。
通过条件分布,CFID(Soloveitchik等人2021)评估了文本条件下的假图像和真实图像分布之间的距离。然而,直接对齐假分布和真实分布可能会使真实图像中的冗余部分不匹配,即文本未指定的内容。这严重影响了CFID在测量文本图像一致性方面的效果。
五、SSD(语义相似距离)
SSD不仅评估直接的文本图像语义相似性,还评估基于文本的合成图像和真实图像之间的语义变化差异。
从分布的角度来看,我们假设在联合语言视觉嵌入空间中生成的图像ef、真实图像er和文本es分布都是类高斯分布Φ: Q f = Φ ( m f , C f f ) , Q r = Φ ( m r , C r r ) , Q s = Φ ( m s , C s s ) \mathbb{Q}_{f}=\Phi\left(m_{f}, \mathbb{C}_{f f}\right), \mathbb{Q}_{r}=\Phi\left(m_{r}, \mathbb{C}_{r r}\right), \mathbb{Q}_{s}=\Phi\left(m_{s}, \mathbb{C}_{s s}\right) Qf=Φ(mf,Cff),Qr=Φ(mr,Crr),Qs=Φ(ms,Css)。其中m和C表示均值和协方差;f、 r和s分别表示生成的图像、真实图像和文本。
基于相同文本s,生成的图像分布和真实的图像分布分别为: Q f ∣ s = Φ ( m f ∣ s , C f f ∣ s ) , Q r ∣ s = Φ ( m r ∣ s , C r r ∣ s ) \mathbb{Q}_{f \mid s}=\Phi\left(m_{f \mid s}, \mathbb{C}_{f f \mid s}\right), \mathbb{Q}_{r \mid s}=\Phi\left(m_{r \mid s}, \mathbb{C}_{r r \mid s}\right) Qf∣s=Φ(mf∣s,Cff∣s),Qr∣s=Φ(mr∣s,Crr∣s),其中 C f f ∣ s \mathbb{C}_{f f \mid s} Cff∣s和 C r r ∣ s \mathbb{C}_{r r \mid s} Crr∣s表示ef和er的条件协方差,它们是常数并且独立于条件es。
5.1、定义
由于最终目标是测量ef和es之间的语义距离,我们考虑Qf和Qs之间的距离,以及 Q f f ∣ s \mathbb{Q}_{f f \mid s} Qff∣s和 Q r r ∣ s \mathbb{Q}_{r r \mid s} Qrr∣s之间的距离。SSD定义如下:
SSD ( Q f , Q s , Q f ∣ s , Q r ∣ s ) = [ 1 − cos ( m f , m s ) ] + ∥ d ( C f f ∣ s ) − d ( C r r ∣ s ) ∥ 2 \begin{array}{c} \operatorname{SSD}\left(\mathbb{Q}_{f}, \mathbb{Q}_{s}, \mathbb{Q}_{f \mid s}, \mathbb{Q}_{r \mid s}\right)= {\left[1-\cos \left(m_{f}, m_{s}\right)\right]+\left\|d\left(\mathbb{C}_{f f \mid s}\right)-d\left(\mathbb{C}_{r r \mid s}\right)\right\|^{2}} \end{array} SSD(Qf,Qs,Qf∣s,Qr∣s)=[1−cos(mf,ms)]+∥ ∥d(Cff∣s)−d(Crr∣s)∥ ∥2
后面做的就是需要计算解这两部分的式子。
由于预训练的CLIP模型用于将图像和文本映射到联合语言视觉嵌入空间,因此很直观地测量其嵌入的余弦距离,如等式的第一矩项中所做的那样。由于Qf和Qs之间的语义差距,仅测量余弦距离不能完全反映分布差异。
然后,我们使用Qf|s和Qr|s以弥合语义鸿沟。如果模型能够完全捕捉语义,其生成的图像应该与真实图像共享相同的语义变化。语义变化还可以帮助绑定对象和属性,从而实现更精确的语义对齐。请注意,我们不直接对齐Qf|s和Qr|s,因为它过度关注文本中未描述的冗余。
因此,我们在等式中设计了一个二阶矩项,通过计算假图像分布和真实图像分布的文本条件协方差之间的对角差来评估语义变化。
5.2、引理
如果C是非负对角矩阵,则二阶矩项可以改写为:
∥ d ( C f f ∣ s ) − d ( C r r ∣ s ) ∥ 2 ∝ Tr [ ( C f f ∣ s 1 2 − C f f ∣ s 1 2 ) 2 ] = Tr [ C f f ∣ s + C r r ∣ s − 2 ( C f f ∣ s 1 2 C r r ∣ s C f f ∣ s 1 2 ) 1 2 ] \begin{aligned} &\left\|d\left(\mathbb{C}_{f f \mid s}\right)-d\left(\mathbb{C}_{r r \mid s}\right)\right\|^{2} \propto \operatorname{Tr}\left[\left(\mathbb{C}_{f f \mid s}^{\frac{1}{2}}-\mathbb{C}_{f f \mid s}^{\frac{1}{2}}\right)^{2}\right] = \operatorname{Tr}\left[\mathbb{C}_{f f \mid s}+\mathbb{C}_{r r \mid s}-2\left(\mathbb{C}_{f f \mid s}^{\frac{1}{2}} \mathbb{C}_{r r \mid s} \mathbb{C}_{f f \mid s}^{\frac{1}{2}}\right)^{\frac{1}{2}}\right] \end{aligned} ∥ ∥d(Cff∣s)−d(Crr∣s)∥ ∥2∝Tr[(Cff∣s21−Cff∣s21)2]=Tr[Cff∣s+Crr∣s−2(Cff∣s21Crr∣sCff∣s21)21]
条件协方差可以等价地写为:
C f f ∣ s = C f f − C f s C s s − 1 C s f , C r r ∣ s = C r r − C r s C s s − 1 C s r \mathbb{C}_{f f \mid s}=\mathbb{C}_{f f}-\mathbb{C}_{f s} \mathbb{C}_{s s}^{-1} \mathbb{C}_{s f}, \mathbb{C}_{r r \mid s}=\mathbb{C}_{r r}-\mathbb{C}_{r s} \mathbb{C}_{s s}^{-1} \mathbb{C}_{s r} Cff∣s=Cff−CfsCss−1Csf,Crr∣s=Crr−CrsCss−1Csr
C∗∗定义为协方差矩阵,它是正半定矩阵。同时,在CLIP空间中,我们只关注C的对角部分,因为CLIP试图通过训练最大化嵌入之间的余弦相似性。因此,C可以简化为非负对角矩阵。
当mf,ms归一化时,第一矩项可以改写为:
1 − cos ( m f , m s ) ≜ ∥ m f − m s ∥ 2 1-\cos \left(m_{f}, m_{s}\right) \triangleq\left\|m_{f}-m_{s}\right\|^{2} 1−cos(mf,ms)≜∥mf−ms∥2
余弦距离相当于归一化向量的欧几里得距离。在CLIP空间中,mf、ms是生成的图像ef和文本es的归一化嵌入。
在后续中,作者还证明了SSD和CS、CFID之间的比较和联系。
5.3、总结
我们提出的新的SSD可以理解为将文本和图像之间的直接一致性作为第一时刻偏差项来评估,将假图像和受文本约束的真实图像之间的语义变化差异作为第二时刻变化项来评估。相比之下,CS省略了二阶矩变化项,从而导致语义变化估计的不足。
六、Parallel Deep Fusion GAN(PDF-GAN)
通过配备硬否定句构造器(HNSC)和语义投影(SProj)构造:并行深度融合生成对抗网络(PDF-GAN)
PDF-GAN通过使用并行融合模块(PFM)融合不同层次的语义信息。对于语义监督,采用了全局和局部鉴别器、语义感知损失和对比损失。为了更准确和稳健地捕获文本中的语义信息,HNSC创建了稳定和可控的硬否定样本,SProj可以通过约束语义优化方向来克服语义差距。
6.1、PDF-GAN框架结构
模型结构如下图所示:

可以看到,大致框架也可以分为三大部分:
- 使用了HNSC、CLIP的文本编码器部分(橙色框标记出)
- 使用了PFM,深度融合句子嵌入、方面嵌入指导图像生成的生成器部分(红色框标记出)
- 鉴别器部分(绿色框标记出)

6.2、文本编码器部分
SSD说明:在不同级别使用文本数据可以提高文本图像的一致性。
CLIP被用作编码器,将图像和文本映射到联合语义空间中。
 全局级特征 { e g } 1 \left\{e_{g}\right\}^{1} {eg}1是文本描述嵌入;局部级特征 { e l } n \left\{e_{l}\right\}^{n} {el}n是文本方面嵌入; { e m i s } 1 \left\{e_{mis}\right\}^{1} {emis}1是否定句嵌入。
全局级特征 { e g } 1 \left\{e_{g}\right\}^{1} {eg}1是文本描述嵌入;局部级特征 { e l } n \left\{e_{l}\right\}^{n} {el}n是文本方面嵌入; { e m i s } 1 \left\{e_{mis}\right\}^{1} {emis}1是否定句嵌入。
HNSC:
硬否定句构造器HNSC通过根据词性(POS)随机替换给定描述中的标记来构造硬否定句样本。名词、动词和形容词被其他名词、动词或形容词取代。例如,对于文本“这只鸟尾巴上是蓝色的,有一个长长的尖嘴”,HNSC将随机地用POS替换一定百分比的单词(将“蓝色”改为“红色”,将“尾巴”改为”头部”等)。从数据集中收集替换候选。HNSC产生稳定和可控的硬否定文本样本,迫使鉴别器学习精确的语义。
6.3、生成器
在生成器G中,作者提出了PFM,用于全局和局部特征之间的有效融合。
PFM:Parallel Fusion Module

PFM将先前步骤的输出作为输入,将 { e g } 1 \left\{e_{g}\right\}^{1} {eg}1和 { e l } n \left\{e_{l}\right\}^{n} {el}n作为条件,输入 h t − 1 h_{t−1} ht−1首先上采样到 h t − 1 ′ h_{t−1}' ht−1′,然后在两组条件下进行深度融合(DF),深度融合之后,来自两个分支的融合特征通过信道连接,然后经过卷积层并输出为 h t h_t ht。
h t h_t ht再经过两组MLP分别学习由局部语义调节的尺度和偏差(类似DF-GAN),变为 h t + 1 ′ h_{t+1}' ht+1′(论文图中错误标注成了t-1)首先扩展到正确的形状,然后缩放并偏置。条件特征被平均并传递给后续处理器。
6.4、鉴别器

为了捕获全局和局部级别的语义信息,鉴别器使用了双线鉴别,一线用的是图像特征(Image feature)+文本方面嵌入(Aspect embeddings),另外一线用的是图像特征(Image feature)+文本句子嵌入(Sentence embeddings),然后将其最后卷积、联结进行判别。
SProj:SProj用于缓解语义差距,通过约束语义优化方向来克服语义差距,从而增强文本图像一致性,SProj受GEM持续学习的启发将最小化La和Ls视为两项任务,不交替训练两项任务,而是同时优化它们。在每个步骤中,在我们计算了La和Ls的梯度δa和δs之后,在我们处理两个任务的反向传播之前,我们对δs进行PROJECT。如果存在方向冲突,语义优化方向δs将被重新投影到一个新的方向δs,在该方向δs中,它可以在不放大La的情况下优化Ls伪代码如下:

6.5、损失函数

可以看到损失由四大部分组成:分别为 L c \mathcal{L}_{c} Lc、 L g \mathcal{L}_{g} Lg、 L a \mathcal{L}_{a} La、 L l \mathcal{L}_{l} Ll
- L c \mathcal{L}_{c} Lc是语义投影后的对比性损失;
- L g \mathcal{L}_{g} Lg是全局语义感知损失;
- L a \mathcal{L}_{a} La是鉴别器对抗损失;
- L l \mathcal{L}_{l} Ll是局部语义感知损失。
L c \mathcal{L}_{c} Lc对比性损失: L c = f C ( G ( z ~ ) ) T ⋅ e ~ m g f C ( G ( z ~ ) ) T ⋅ e ~ m g + f C ( G ( z ~ ) ) T ⋅ e ~ g \mathcal{L}_{c}=\frac{f_{C}(G(\tilde{z}))^{T} \cdot \tilde{e}_{m g}}{f_{C}(G(\tilde{z}))^{T} \cdot \tilde{e}_{m g}+f_{C}(G(\tilde{z}))^{T} \cdot \tilde{e}_{g}} Lc=fC(G(z~))T⋅e~mg+fC(G(z~))T⋅e~gfC(G(z~))T⋅e~mg,主要用于以进一步排斥失配样本
L g \mathcal{L}_{g} Lg全局语义感知损失: L g = f C ( G ( z ~ ) ) T ⋅ e ~ g \mathcal{L}_{g}=f_{C}(G(\tilde{z}))^{T} \cdot \tilde{e}_{g} Lg=fC(G(z~))T⋅e~g 主要用于增强G中全局层次的语义信息
L l \mathcal{L}_{l} Ll局部语义感知损失: L l = 1 n ∑ i = 1 n f C ( G ( z ~ ) ) T ⋅ e ~ l i \mathcal{L}_{l}=\frac{1}{n} \sum_{i=1}^{n} f_{C}(G(\tilde{z}))^{T} \cdot \tilde{e}_{l}^{i} Ll=n1∑i=1nfC(G(z~))T⋅e~li主要用于增强G中局部层次的语义信息
L a \mathcal{L}_{a} La鉴别器对抗损失,鉴别器的损失函数使用了铰链损失+改进的匹配感知梯度惩罚,计算公式为:
L D = E x r ∼ P r , e ∈ { e } k [ 1 − D g ( x , e ) ] + 1 2 [ E x r ∼ P r , e m ∈ { e m } k [ 1 + D g ( x , e m ) ] + E G ( z ) ∼ P g , e ∈ { e } k [ 1 + D g ( G ( z ) , e ) ] ] + q E x ∼ P r [ ( ∥ ∇ x D g ( x , e ˉ ) ∥ + ∥ ∇ e D ( x , e ˉ ) ∥ ) p ] \begin{aligned} \mathcal{L}_{D} &=\mathbb{E}_{x_{r} \sim \mathbb{P}_{r}, e \in\{e\}^{k}}\left[1-D_{g}(x, e)\right] \\ &+\frac{1}{2}\left[\mathbb{E}_{x_{r} \sim \mathbb{P}_{r}, e_{m} \in\left\{e_{m}\right\}^{k}}\left[1+D_{g}\left(x, e_{m}\right)\right]\right.\\ &\left.+\mathbb{E}_{G(z) \sim \mathbb{P}_{g}, e \in\{e\}^{k}}\left[1+D_{g}(G(z), e)\right]\right] \\ &+q \mathbb{E}_{x \sim \mathbb{P}_{r}}\left[\left(\left\|\nabla_{x} D_{g}(x, \bar{e})\right\|+\left\|\nabla_{e} D(x, \bar{e})\right\|\right)^{p}\right] \end{aligned} LD=Exr∼Pr,e∈{e}k[1−Dg(x,e)]+21[Exr∼Pr,em∈{em}k[1+Dg(x,em)]+EG(z)∼Pg,e∈{e}k[1+Dg(G(z),e)]]+qEx∼Pr[(∥∇xDg(x,eˉ)∥+∥∇eD(x,eˉ)∥)p]
最终损失为: L G = λ ( L g + L l + L c ) ⏟ Semantic loss L s + L a ⏟ Adversarial loss \mathcal{L}_{G}=\underbrace{\lambda\left(\mathcal{L}_{g}+\mathcal{L}_{l}+\mathcal{L}_{c}\right)}_{\text {Semantic loss } \mathcal{L}_{s}}+\underbrace{\mathcal{L}_{a}}_{\text {Adversarial loss }} LG=Semantic loss Ls λ(Lg+Ll+Lc)+Adversarial loss La
七、实验
7.1、实验设置
数据集:CUB、COCO
定量评估:专用评估指标有SSD(本文提出),R分数、CS,和CFID。标准评估指标(公认性更强)有Inception Score(IS)和 Fréchet Inception Distance(FID) ,IS未用于评估COCO,因为它对COCO的效果不好。所有度量都是在30K个生成的图像上计算的。
7.2、实验结果
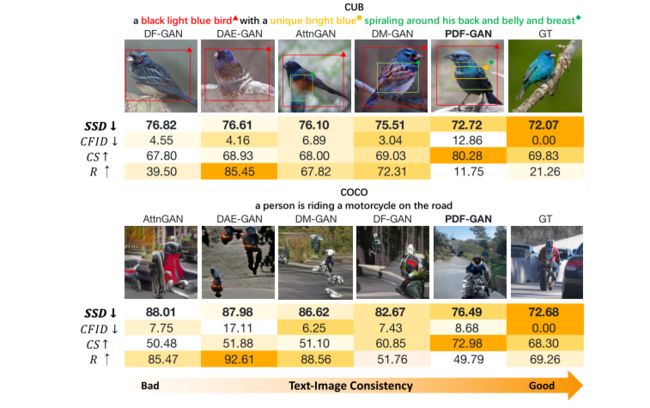
在CUB上通过AttnGAN、DM-GAN、DAE-GAN、DF-GAN和PDF-GAN的合成实例:
在COCO上通过AttnGAN、DMGAN、DF-GAN和PDF-GAN合成T2I的实例:

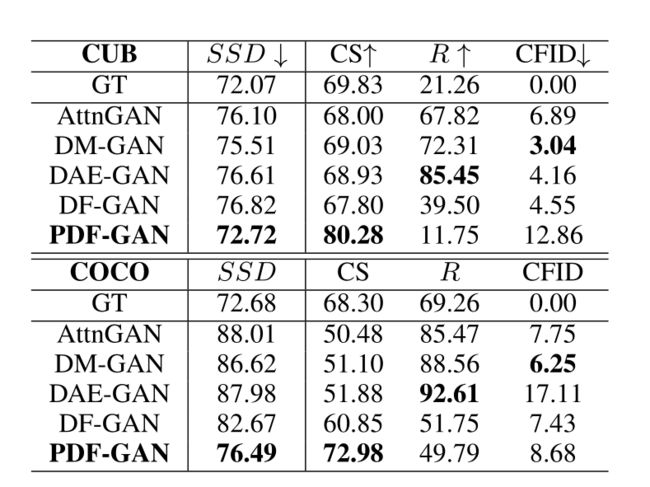
CUB和COCO上SSD、CS、R和CF ID的文本图像一致性结果:
CUB和COCO上FID和IS的得分结果:

消融研究:


八、总结
本文提出了一种新的度量SSD以更好地评估文本图像的一致性,理论分析和实证研究都表明,SSD确实能够反映文本到图像生成中的语义一致性。
另外,本文还设计了一个名为PDF-GAN的新框架,以及两个即插即用模块,可以进一步增强文本图像的一致性,在基准数据集上的实验定性和定量地证实了SSD的有效性以及PDF-GAN的优势。
最后
我们已经建立了T2I研学团队,如果你对本文还有其他疑问或者对文本生成图像方向很感兴趣,可以点击下方链接或者私信我加入社群。
加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
☕️ 社区免费送马克杯:亚马逊云共学拿奖励
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言