CVPR2021|| Coordinate Attention注意力机制
Paper:https://arxiv.org/pdf/2103.02907.pdf
GitHub:https://github.com/Andrew-Qibin/CoordAttention
轻量,优秀,好用!
小知识
我从论文中提取的只言片语。。。
标准卷积本身很难对信道关系建模。
显式地构建通道间的依赖关系可以增加模型对信息通道的敏感性,这些信息通道对最终分类决策的贡献更大。
使用全局平均池还可以帮助模型捕获卷积所缺少的全局信息。
讲之前我们先回顾一下以前的SE与CBAM
SE
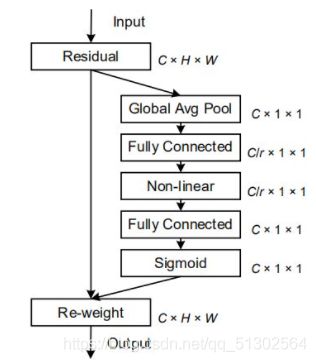
SE比较简单,看一下结构图差不多就能理解了,如果有些实现不太懂的,可以借鉴一下CBAM的。
但SE只考虑内部通道信息而忽略了位置信息的重要性,而视觉中目标的空间结构是很重要的。
CBAM
稍微介绍一下CBAM,如图b所示,CBAM包含空间注意力和通道注意力两部分。
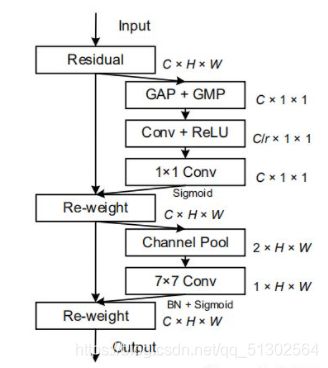
通道注意力:对input feature maps每个feature map做全局平均池化和全局最大池化,得到两个1d向量,再经过conv,ReLU,1x1conv,sigmoid进行归一化后对input feature maps加权。
空间注意力:对feature map的每个位置的所有通道上做最大池化和平均池化,得到两个feature map,再对这两个feature map进行7x7 Conv,再使BN和sigmoid归一化。
通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)

BAM和CBAM尝试去通过在通道上进行全局池化来引入位置信息,但这种方式只能捕获局部的信息,而无法获取长范围依赖的信息。(经过几层的卷积后feature maps的每个位置都包含了原图像一个局部区域的信息,CBAM是通过对每个位置的多个通道取最大值和平均值来作为加权系数,因此这种加权只考虑了局部范围的信息。)
Coordinate Attention
现在我们进入正题:
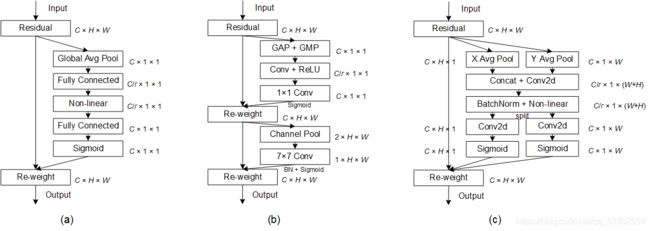
本文提出的协调注意块©与经典SE通道注意块(a)和CBAM注意块(b)的示意图(下图)比较。这里的“GAP”和“GMP”分别指全局平均池和全局最大池。“X平均池”和“Y平均池”分别指一维水平全局池和一维垂直全局池。
注意力机制用于移动网络(模型比较小)会明显落后于大网络。主要是因为大多数注意力机制带来的计算开销对于移动网络而言是无法承受的,例如self-attention。
因此,在移动网络上主要使用Squeeze-and-Excitation (SE),BAM和CBAM。
- 但SE只考虑内部通道信息而忽略了位置信息的重要性,而视觉中目标的空间结构是很重要的。
- BAM和CBAM尝试去通过在通道上进行全局池化来引入位置信息,但这种方式只能捕获局部的信息,而无法获取长范围依赖的信息(过几层的卷积后feature maps的每个位置都包含了原图像一个局部区域的信息,CBAM是通过对每个位置的多个通道取最大值和平均值来作为加权系数,因此这种加权只考虑了局部范围的信息)。
总的来说:
在本文中提出了一种新颖且高效的注意力机制,通过把位置信息嵌入到通道注意力,从而使移动网络获取更大区域的信息而避免引入大的开销。
为了避免2D全局池化引入导致位置信息损失,本文提出分解通道注意为两个并行的1D特征编码,来高效地整合空间坐标信息。
具体而言:
利用两个1D全局池化操作将沿垂直和水平方向的input features分别聚合为两个单独的direction-aware feature maps(位置感知)。
然后将具有嵌入的特定方向信息的这两个特征图分别编码为两个attention map,每个attention map都沿一个空间方向捕获输入特征图的远距离依存关系。
位置信息因此可以被保存在所生成的attention map中。 然后通过乘法将两个attention map都应用于input feature maps,以强调注意区域的表示。
考虑到其操作可以区分空间方向(即坐标)并生成coordinate-aware attention maps,因此论文将提出的注意力方法称为“coordinate attention”。
优点
我们先来讲Coordinate Attention的优点:
考虑到其操作可以区分空间方向(即坐标)并生成coordinate-aware attention maps,因此论文将提出的注意力方法称为“coordinate attention”。
我们先来讲Coordinate Attention的优点:
-
同时考虑了通道间关系和位置信息。它不仅捕获了跨通道的信息,还包含了direction-aware和position-sensitive(方向与位置敏感)的信息,这使得模型更准确地定位到并识别目标区域。
-
这种方法灵活且轻量,很容易插入到现有的经典移动网络中,例如MobileNet_v2中的倒残差块和MobileNeXt中的沙漏块中去提升特征表示性能。
-
对一个预训练的模型来说,这种coordinate attention可以给使用移动网络处理的down-stream任务带来明显性能提升,尤其是那些密集预测的任务,例如语义分割。
如下图中的C(coordinate attention)所示,分别对水平方向和垂直方向进行平均池化得到两个1D向量,在空间维度上Concat和1x1Conv来压缩通道,再是通过BN和Non-linear来编码垂直方向和水平方向的空间信息,接下来split,再各自通过1x1得到input feature maps一样的通道数,再归一化加权。
简单说来,Coordinate Attention是通过在水平方向和垂直方向上进行平均池化,再进行transform对空间信息编码,最后把空间信息通过在通道上加权的方式融合。

附上代码实现:
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
# 如果下面这个原论文代码用不了的话,可以换成另一个试试
out = identity * a_w * a_h
# out = a_h.expand_as(x) * a_w.expand_as(x) * identity
return out
Conclusion
这种方式与SE,CBAM相比有明显提升。


注意力机制要加在哪里嘞?
如果对于本文提到的Coordinate Attention注意力机制,Paper Owner 是这样回答我的。
我写了一些注意力放置位置的个人理解,请移步这里。
希望各位大佬能发表自己的看法
如果要加载别人的网络模型
因为不能改变已有的网络结构,所以注意力不能加在block里面,因为加进去网络结构发生了变化,所以不能用预训练参数。加在最后一层卷积和第一层卷积不改变网络,可以用预训练参数。(我对这段话有些小疑惑,下面是博主给我的回答)
两种初始化添加注意力后的网络的方法
# 自己重写的网络
net = resnet50()
# 需要加载的预训练参数
resnet = models.resnet50(pretrained=True)
# 在重写的网络中加载预训练网络
new_state_dict = resnet.state_dict()
dd = net.state_dict()
for k in new_state_dict.keys():
print(k)
if k in dd.keys() and not k.startswith('fc'): # 不加载全连接层
print('yes')
dd[k] = new_state_dict[k]
net.load_state_dict(dd)
ps
冻结完之后建议再打印一下没有被冻结层的关键字,防止冻结错误,炼了半天白炼了
来自Mr DaYang(CSDN):
pretrained_dict = torch.load(model_path)['state_dict'] # torch.load得到是字典,我们需要的是state_dict下的参数
pretrained_dict = {k.replace('module.', ''): v for k, v in
pretrained_dict.items()} # 因为pretrained_dict得到module.conv1.weight,但是自己建的model无module,只是conv1.weight,所以改写下
# 删除pretrained_dict.items()中model所没有的东西
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} # 只保留预训练模型中,自己建的model有的参数
model_dict.update(pretrained_dict) # 将预训练的值,更新到自己模型的dict中
model.load_state_dict(model_dict) # model加载dict中的数据,更新网络的初始值
如果打算从头炼
emmm 求路过大佬指教/doge
部分来自:
cv技术总结(知乎):https://zhuanlan.zhihu.com/p/363327384
CSDN:https://blog.csdn.net/qq_38410428/article/details/103694759