Pytorch个人学习笔记
Pytorch 个人学习笔记
Pytorch官方文档
Pytorch中文官方文档
参考哔哩哔哩的up主:我是土堆,视频链接
代码均来自:我是土堆,视频链接
文章目录
- Pytorch 个人学习笔记
- 1. Pytorch 环境配置
-
- 1.1 安装 anaconda
-
- 1.1.1 管理conda
- 1.1.2 管理环境
- 1.2 配置显卡
- 1.3 安装 pytorch
-
- 1.3.1 准备工作
- 1.3.2 安装pytorch
- 1.3.3 检验gpu是否可用
- 1.3.4 解决安装时下载慢的问题:
- 1.3.5 python学习中的两大法宝函数
- 1.3.6 安装 jupyter
- 2. Pytorch入门实战
-
- 2.1 Pytorch加载数据初识
-
- 2.1.1 Dataset
- 2.1.2 Dataloader
- 2.2 Tensorboard 的使用
- 2.3 Transformers 的使用
-
- 2.3.1 Transforms 简介
- 2.3.2 Transforms 运行机制
- 2.3.3 土堆 Transforms 的例子
- 2.3.4 常见的Transformers
- 2.3.5 使用Transformers需要注意的点
- 2.4 torchvision中的数据集使用
- 2.5 神经网络基础
-
- 2.5.1 神经网络的基本骨架——nn.Module 的使用
- 2.5.2 神经网络——卷积层
- 2.5.3 神经网络——最大池化的使用
- 2.5.4 神经网络——非线性激活
- 2.5.5 神经网络——线性层
- 2.5.6 神经网络——torch.nn.Sequential
- 2.5.7 神经网络——搭建小实战
- 2.5.8 损失函数与反向传播
- 2.5.9 优化器
- 2.5.10 现有网络模型的使用及修改
- 2.5.11 网络模型的保存与读取
- 2.6 完整的模型训练套路
- 2.7 GPU训练
-
- 2.7.1 GPU训练方式1:
- 2.7.2 GPU训练方式2:
- 2.7.3 GPU训练note:
- 2.8 完整的模型验证套路
1. Pytorch 环境配置
1.1 安装 anaconda
anaconda installer 网站
安装anaconda可参考该文章
Anaconda是一个包含180+的工具包及其依赖项的发行版本,其包含的工具包包括:conda, numpy, scipy, ipython notebook等。也就是说安装了anaconda 就安装了许多 package,包括 python之类的。
1.从官网下载 anaconda3
①. 我本机的 windows系统的 python 版本是:python 3.8.10,因此我下载的anaconda 是:Anaconda3-2021.05-Windows-x86_64.exe 。
②. 远程服务器是linux系统,我下载的是:Anaconda3-2021.05-Linux-x86_64.sh
2.安装anaconda:
a. windows下安装
windows下安装anaconda时需要注意:(1)记住安装路径 (2)跳过Visual Stutio Code,剩下的选项默认即可。
b. linux下安装anaconda
①下载安装包
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
② 需要首先赋权再执行安装程序,依次输入下面两条命令:
chmod +x Anaconda3-2021.05-Linux-x86_64.sh
./Anaconda3-2021.05-Linux-x86_64.sh
③ 设置环境变量:
export PATH="/disk/wangzy/anaconda3/bin:$PATH"
export PATH="$PATH: /disk/wangzy//anaconda/bin"
3. 检验是否安装成功
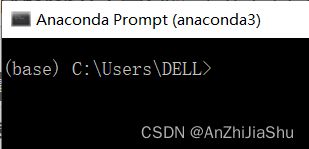
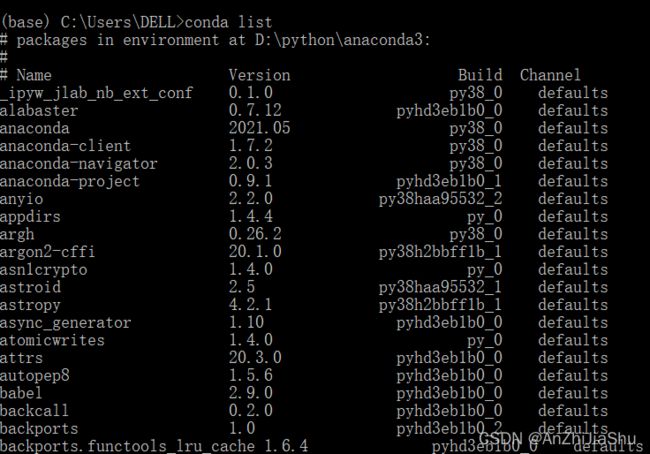
点击 Anaconda Prompt,有"(base)"则表明安装成功。
或者在终端中输入命令 conda list ,如果Anaconda被成功安装,则会显示已经安装的包名和版本号。
1.1.1 管理conda
Windows打开“Anaconda Prompt”;macOS和Linux用户打开“Terminal”(“终端”)进行操作。
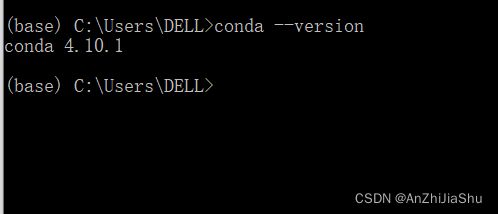
1.验证conda已被安装
在终端输入如下指令:
conda --version
终端上将会以 conda 版本号 的形式显示当前安装conda的版本号。
2. 更新conda至最新版本
conda update conda
- 执行命令后,conda将会对版本进行比较并列出可以升级的版本。同时,也会告知用户其他相关包也会升级到相应版本。
- 当较新的版本可以用于升级时,终端会显示 Proceed ([y]/n)? ,此时输入 y 即可进行升级。
3.查看conda帮助信息
conda --help
或
conda -h
4.卸载conda
① Linux 或 macOS
rm -rf ~/anaconda3
即删除Anaconda的安装目录。
② Windows
控制面板 → 添加或删除程序 → 选择“Python X.X (Anaconda)” → 点击“删除程序”
注意:
① Python X.X:即Python的版本,如:Python 3.8。
② Windows 10的删除有所不同。
1.1.2 管理环境
1.创建新环境
conda create --name <env_name> <package_names>
▫
▫
① 如果要安装指定的版本号,则只需要在包名后面以 = 版本号的形式执行。如: conda create --name/n pytorch python=3.8 ,即创建一个名为“pytorch”的环境,环境中安装版本为3.8的python。
② 如果要在新创建的环境中创建多个包,则直接在 conda create -n pytorch python=3.5 numpy pandas ,即创建一个名为 "pytorch” 的环境,环境中安装版本为3.5的python,同时也安装了numpy和pandas。
▫ --name 同样可以替换为 --n 。
note: 默认情况下,新创建的环境将会被保存在 /Users/
2.激活环境
conda activate <env_name>
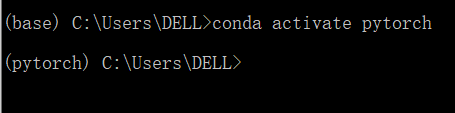
3.退出环境至root
conda deactivate

4.显示已创建环境
conda info --envs
或
conda info -e
或
conda env list
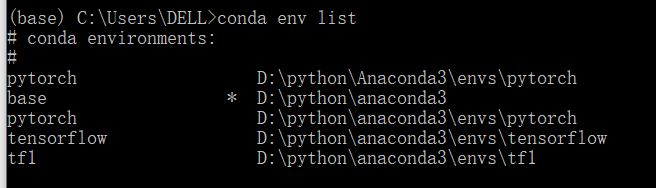
结果中星号“*”所在行即为当前所在环境。
5.复制环境
conda create --name <new_env_name> --clone <copied_env_name>
注意:
①
②
③ conda create --name py2 --clone python2 ,即为克隆名为“python2”的环境,克隆后的新环境名为“py2”。此时,环境中将同时存在“python2”和“py2”环境,且两个环境的配置相同。
6.删除环境
conda remove --name <env_name> --all
注意:
1.2 配置显卡
gpu适合于张量计算,能加速深度学习模型的训练过程,配置显卡主要是:
显卡驱动+CUDA Tookit,CUDA Tookit 能够根据 pytorch 一键安装,所以这里我们主要检查 显卡的驱动是否正确安装。
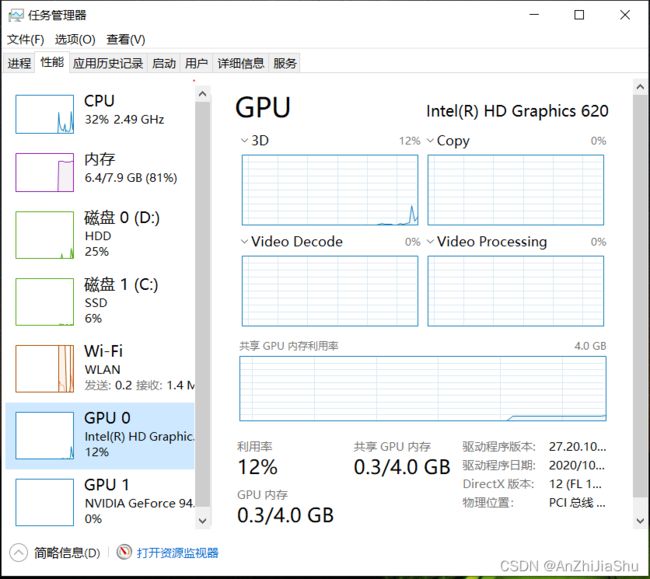
1.检查显卡驱动是否正确安装
打开任务管理器,在性能选项卡中查看,如果GPU正常运转则表明显卡驱动安装成功。
1.3 安装 pytorch
1.3.1 准备工作
1.创建一个名为pytorch(也可以叫别的名字)的虚拟环境
conda create --n pytorch python=3.8
2.激活pytorch环境
conda activate pytorch
3.查看该环境中所装的包
pip list
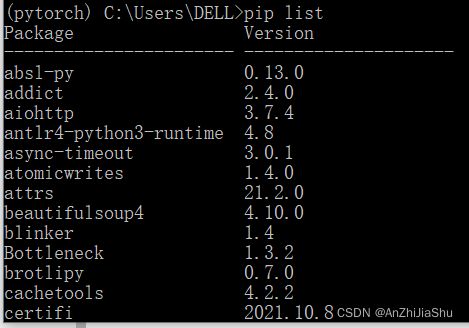
最开始没安装pytorch的时候,会发现没有名字为 ”torch“ 的包,所以接下来要安装pytorch
1.3.2 安装pytorch
pytorch官网进行安装
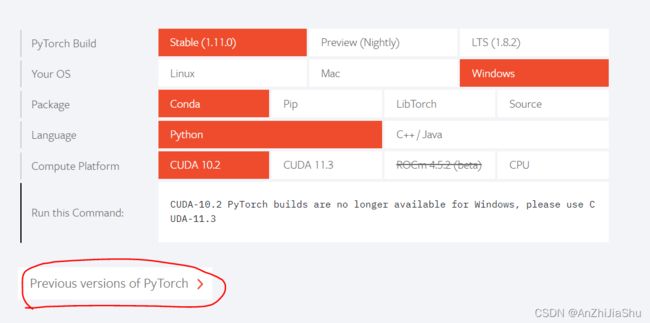
note: cuda
首先需要了解我们的GPU的型号,以及是否支持cuda
①. 点击任务管理器查看自己GPU的型号(NVIDA是独立显卡):
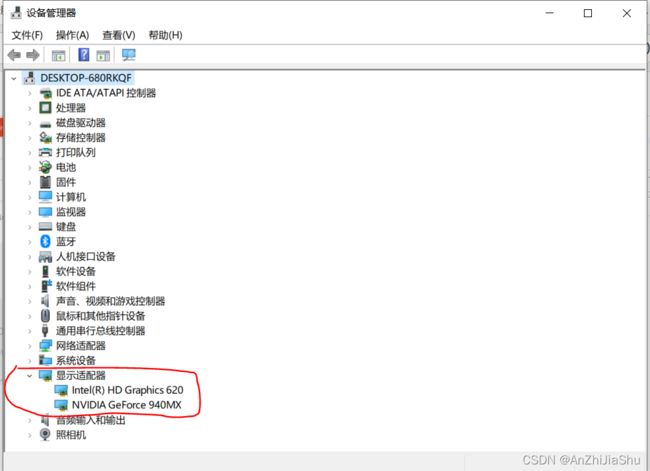
②. 点击官网 看自己的GPU是否支持CUDA
③. 重要!!!! 看自己的驱动版本
在命令行敲 nvidia-smi,查看驱动版本Driver Version,cuda 9.2以上只支持 驱动版本大于392.26,否则需要升级驱动。升级驱动可以在英伟达的官网下载驱动进行下载安装。
下图是我本机的驱动版本
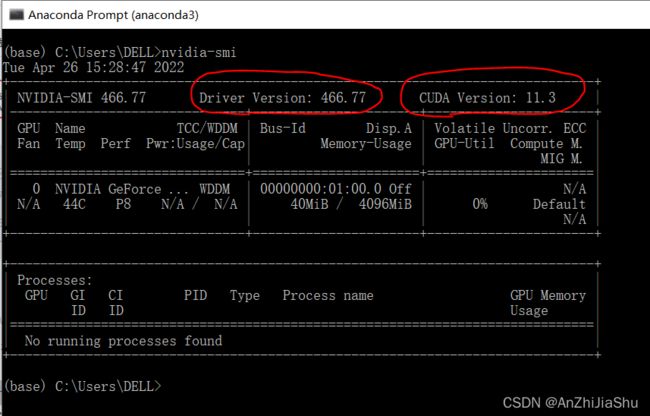
下图是实验室服务器的驱动版本:
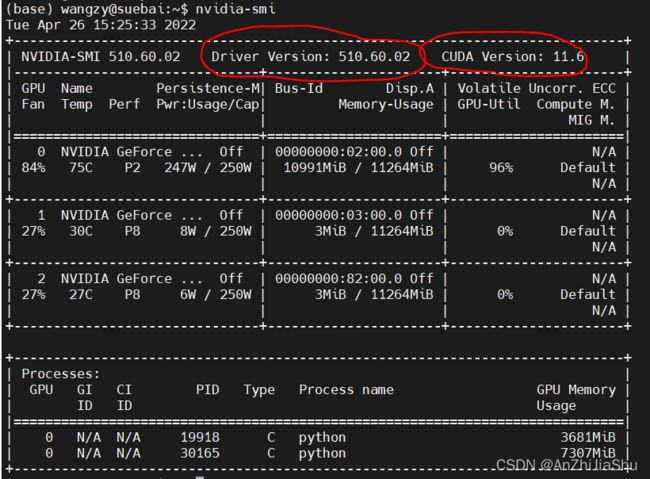
在windows上安装pytorch,本机我安装的pytorch版本是1.8.0,cudatookit是10.2
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
安装完成后,输入pip list,查看是否安装成功
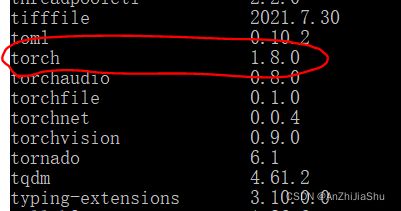
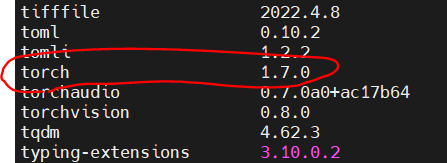
在服务器上我安装的是:
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.1 -c pytorch
1.3.3 检验gpu是否可用
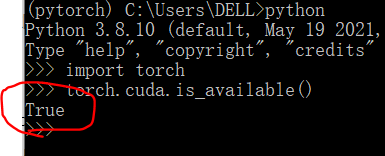
敲如下命令:
python
import torch
torch.cuda.is_available()
输出为 true 则可用
1.3.4 解决安装时下载慢的问题:
方法① 加载清华源:在 base环境中输入如下命令
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
安装pytorch时,官网命令:
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
若用清华源下载的话把 -c pytorch 去掉
方法② 自己将安装包下载后放到anaconda 的 pkgs目录
1.3.5 python学习中的两大法宝函数
- dir() 函数,能让我们知道 工具箱以及工具箱中的分隔区有什么东西。
- help()函数,能让我们知道每个工具箱是如何使用的,工具的使用方法。
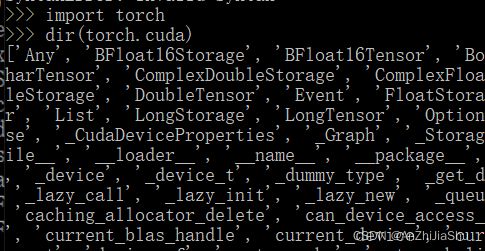
实例:dir(torch),能够看到里面有很多工具箱,其中有一个cuda

我们还想知道’cuda’ 里面有什么,继续使用
import torch
dir(torch.cuda)
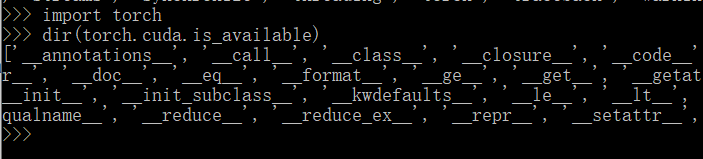
可以看到里面有’is_available‘,继续查看
import torch
dir(torch.cuda.is_available)
可以看到里面有很多前后双下划线,是一种规范,表示不能修改。
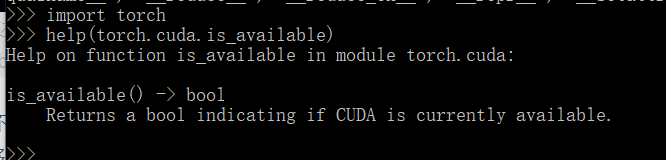
这说明 is_available 不再是一个分隔区,而是一个确确实实的函数,函数是一个道具,我们就能够用help()查看他的使用方法。
1.3.6 安装 jupyter
1.anaconda下自带jupyter,但是仍需要在pytorch环境中安装一下。
激活pytorch环境之后,输入如下指令:
conda install nb_conda
2.启动jupyter notebook
jupyter notebook
3.启动jupyter notebook后核选择pytorch
2. Pytorch入门实战
ctrl+p 能知道方法需要哪些参数
2.1 Pytorch加载数据初识
下图来自:https://blog.csdn.net/weixin_43135178/article/details/115230710
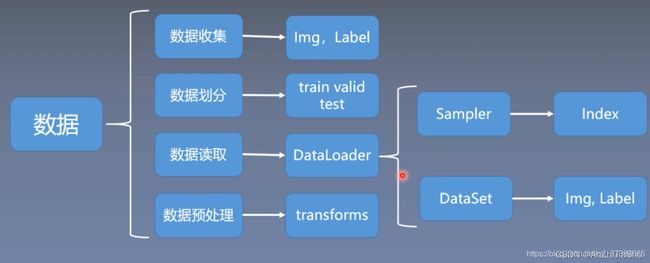
Dataset 与 Dataloader:
- Dataset:提供一种方式去获取数据及其 label。 需要实现以下两个方法:
①:如何获取每一个数据及其label
②:告诉我们总共有多少数据。(这样在神经网络训练时才知道如何去迭代)
Dataset的一个示例:有图片有label
- Dataloader:为后面的网络提供不同的数据形式。
PyTorch为我们提供的两个Dataset和DataLoader类分别负责可被Pytorhc使用的数据集的创建以及向训练传递数据的任务。如果想个性化自己的数据集或者数据传递方式,也可以自己重写子类。
2.1.1 Dataset
1.Pytorch内置数据集
如CIFAR10在PyTorch中CIFAR10是一个写好的Dataset,在使用时只需以下代码:
data = torchvision.datasets.CIFAR10("./data/", transform=transform, train=True, download=True)
torchvision.datasets.CIFAR10就是一个Datasets子类,data是这个类的一个实例。
我们有的时候需要用自己在一个文件夹中的数据作为数据集,这个时候,我们可以使用ImageFolder这个方便的API。
FaceDataset = torchvision.datasets.ImageFolder('./data', transform=img_transform)
如何自定义一个数据集
torch.utils.data.dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。
数据集其实就是一个负责处理索引(index)到样本(sample)映射的一个类(class)。
Pytorch提供两种数据集:
- Map式数据集
一个Map式的数据集必须要重写__getitem__(self, index),len(self)两个内建方法,用来表示从索引到样本的映射(Map)。举个例子,dataset[idx]表示从硬盘中读取数据集中第 idx 张图片及其标签;len(dataset)会返回这个数据集的容量。 - Iterable式数据集
一个Iterable(迭代)式数据集是抽象类data.IterableDataset的子类,并且覆写了__iter__方法成为一个迭代器。这种数据集主要用于数据大小未知,或者以流的形式的输入,本地文件不固定的情况,需要以迭代的方式来获取样本索引。
自定义数据集示例,新建一个read_data.py文件,运行以下代码,运行结果是数据集的长度。
from torch.utils.data import Dataset #这个包是必须的
from PIL import Image
import os #python中的一个系统库,用于获取地址
class MyData(Dataset): #集成Dataset类
def __init__(self, root_dir, label_dir): #初始化函数,当创建类时,必运行的函数,为整个class提供一个全局变量
self.root_dir=root_dir #初始化root_dir
self.label_dir=label_dir #初始化label_dir
self.path=os.path.join(self.root_dir,self.label_dir) #初始化图片地址
self.img_path=os.listdir(self.path) # 返回一个包含文件夹中所有文件名的一个list
#__getitem__:supporting fetching a data sample for a given key.
def __getitem__(self, idx): #第二个参数默认是item,将其改为idx,表示索引
img_name=self.img_path[idx] #通过索引获取图片名称(img_path是一个list)
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) #获取一个具体样本的路径
img=Image.open(img_item_path) #打开图片,#打开图片,Image.open打开的img是PIL数据类型
label=self.label_dir #获取图片的标签
return img,label #返回图片与标签,img是tensor数据类型
#返回列表list的长度,即获取数据集长度
def __len__(self):
return len(self.img_path)
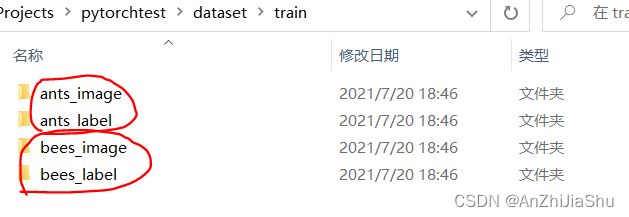
root_dir = '../dataset/train'
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir) #实例化一个蚂蚁数据集,传入root_dir与label_dir
bees_dataset = MyData(root_dir,bees_label_dir) #实例化一个蜜蜂数据集,传入root_dir与label_dir
train_dataset = ants_dataset+bees_dataset #将两个数据集合并为一个训练集
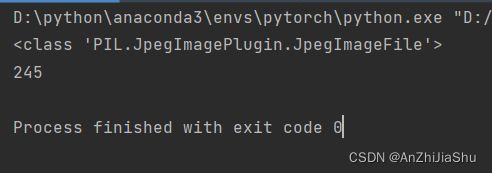
img,label=train_dataset[0]
print(type(img)) #运行结果:
2.1.2 Dataloader
1.torch.utils.data.DataLoade功能: Combines a dataset and a sampler, and provides an iterable over the given dataset。构建可迭代的数据装载器。
dataset只是告诉程序data的位置。可以想象成我们在打扑克牌,那么dataset就是这一幅扑克牌。dataloader是一个loader,把数据加载到神经网络中,比如将手看作神经网络,那么dataloader做的事就是没错从dataset中取数据,那么每次取多少,如何取数据这个过程是由dataloader中的参数设置的。
一般来说PyTorch中深度学习训练的流程是这样的:
- 创建Dateset Dataset
- 传递给DataLoader
- DataLoader迭代产生训练数据提供给模型
对应的一般都会有这三部分代码
# 创建Dateset(可以自定义)
dataset = MyData #2.1.1节定义的
#Dataset传递给DataLoader
dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=False,num_workers=0)
# DataLoader迭代产生训练数据提供给模型
for i in range(epoch):
for index,(img,label) in enumerate(dataloader):
pass ##DataLoader迭代产生训练数据提供给模型
Dataset负责建立索引到样本的映射,DataLoader负责以特定的方式从数据集中迭代的产生 一个个batch的样本集合。在enumerate过程中实际上是dataloader按照其参数sampler规定的策略调用了其dataset的getitem方法。
2. 参数介绍
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
参数介绍:
dataset (Dataset)– 定义好的Map式或者Iterable式数据集。batch_size (python:int, optional)– 一个batch含有多少样本(每次打牌取几张) (default: 1)。shuffle (bool, optional)– 每一个epoch的batch样本是相同还是随机 (洗牌)(default: False)。sampler (Sampler, optional)– 决定数据集中采样的方法. 如果有,则shuffle参数必须为False。batch_sampler (Sampler,optional)– 和 sampler 类似,但是一次返回的是一个batch内所有样本的index。和 shuffle, sampler, and drop_last 三个参数互斥。num_workers (python:int, optional)– 多少个子程序同时工作来获取数据,多线程。 (default: 0)collate_fn (callable, optional)– 合并样本列表以形成小批量。pin_memory (bool, optional)–如果为True,数据加载器在返回前将张量复制到CUDA固定内存中。drop_last (bool, optional)–如果数据集大小不能被batch_size整除,设置为True可删除最后一个不完整的批处理。如果设为False并且数据集的大小不能被batch_size整除,则最后一个batch将更小。(default: False)timeout (numeric, optional)–如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。(default: 0)worker_init_fn (callable, optional)– 每个worker初始化函数(default: None)
其中,采样器 sampler 是重点参数,它是一个迭代器。PyTorch提供了多种采样器,用户也可以自定义采样器。所有sampler都是继承 torch.utils.data.sampler.Sampler这个抽象类。
参考:https://www.cnblogs.com/yanghh/p/14074744.html
DataLoader 本质上就是一个 iterable(内部定义了 __iter__ 方法),__iter__ 被定义成生成器,使用 yield 来返回数据,并利用多进程来加速 batch data 的处理,DataLoader 组装好数据后返回的是 Tensor 类型的数据。
note:DataLoader 是间接通过 Dataset 来获得数据的,然后进行组装成一个 batch 返回,因为采用了生成器,所以每次只会组装一个 batch 返回,不会一次性组装好全部的 batch,所以 DataLoader 节省的是 batch 的内存,并不是指数据集的内存,数据集可以一开始就全部加载到内存里,也可以分批加载,这取决于 Dataset 中 __init__ 函数的实现。
示例代码1:来自:https://www.cnblogs.com/yanghh/p/14074744.html
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
# 因为数据集比较小,所以全部加载到内存里了
data = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = data.shape[0]
self.x_data = torch.from_numpy(data[:,:-1])
self.y_data = torch.from_numpy(data[:,[-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, # 传递数据集
batch_size=32, # 小批量的数据大小,每次加载一batch数据
shuffle=True, # 打乱数据之间的顺序
num_workers=2) # 使用多少个子进程来加载数据,默认为0, 代表使用主线程加载batch数据
for epoch in range(100): # 训练 100 轮
for i, data in enumerate(train_loader, 0): # 每次惰性返回一个 batch 数据
iuputs, label = data
示例代码2:来自土堆
新建一个test_dataloader.py文件
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试数据集,并且通过torchvision.transforms.ToTensor()将数据集转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#每批64张图片,drop_last=False代表如果最后一批不满64张也列出来,shuffle代表洗牌
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片及label
img,label=test_data[0]
print(img.shape) #torch.Size([3, 32, 32]) RGB图像,3通道,大小为52×52
print(type(img)) #tensor数据类型,在终端打开tensorboard
tensorboard --logdir="test1\dataloader" --port=6008

点击链接,在tensorboard中进行查看
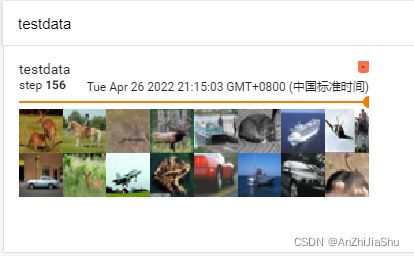
1.testdata:因为drop_last=False,所以最后一个step不满64张。
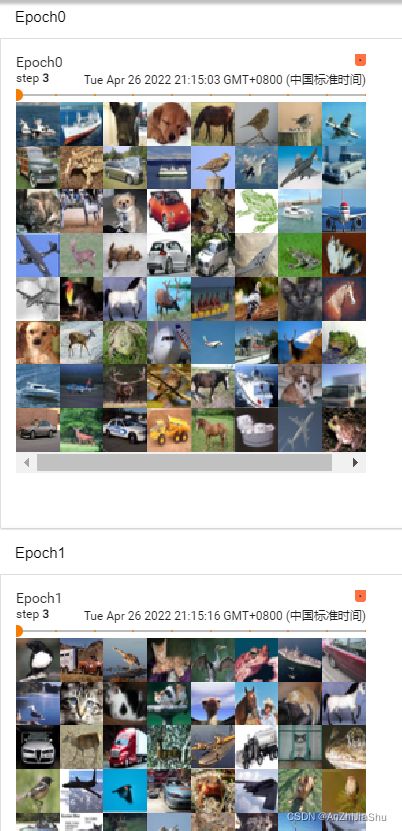
2.Epoch0,Epoch1:因为shuffle=True,所以每个Epoch相同 step 的图片也不一样。
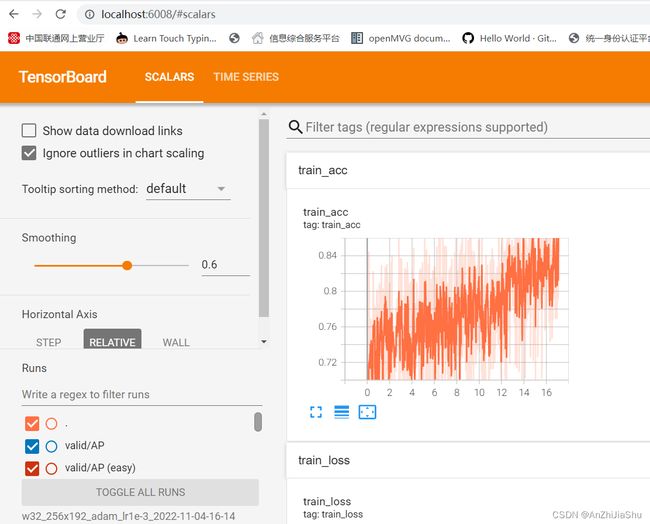
2.2 Tensorboard 的使用
tensorBoard 作为一款与Tensorflow配套的可视化工具,其目的是方便用户理解、调试与优化深度神经网络,其记录了训练过程的相关信息,并将其可视化表现。利用它,我们可以直观地感受网络参数的变化与分布,Loss值的下降,训练集与验证集Accuracy在模型更新过程中的变化。
TensorBoard 是 TensorFlow 中强大的可视化工具,支持标量、文本、图像、音频、视频和 Embedding 等多种数据可视化。
在 PyTorch 中也可以使用 TensorBoard,具体是使用 TensorboardX 来调用 TensorBoard。除了安装 TensorboardX,还要安装 TensorFlow 和 TensorBoard,其中 TensorFlow 和 TensorBoard 需要一致。
TensorBoardX 可视化的流程需要首先编写 Python 代码把需要可视化的数据保存到 event file 文件中,然后再使用 TensorBoardX 读取 event file 展示到网页中。
安装tensorboard:
pip install tensorboard
测试tensorbaord,创建一个test_tensorboard.py文件,输入以下代码
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
'''
SummaryWriter 将entries直接写入日志目录中的事件文件,以供TensorBoard使用。
“SummaryWriter”类提供了一个高级API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。
该类异步更新文件内容。这允许训练程序调用方法,直接从训练循环向文件添加数据,而不会减慢训练速度。
'''
writer=SummaryWriter("logs") #将事件写入logs文件夹中
'''在tensorbaord中写入一个scalar标量'''
#scalar_value对应y轴,global_step对应x轴,绘制y=2x
for i in range(100):
writer.add_scalar(tag="y=2x" ,scalar_value=2*i, global_step=i)
'''在tensorbaord中写入一个图片'''
image_path ="../dataset/train/ants_image/5650366_e22b7e1065.jpg"
image_PIL=Image.open(image_path) #打开图片,在这里,image_PIL是一个PIL数据类型,不满足add_image的数据类型要求
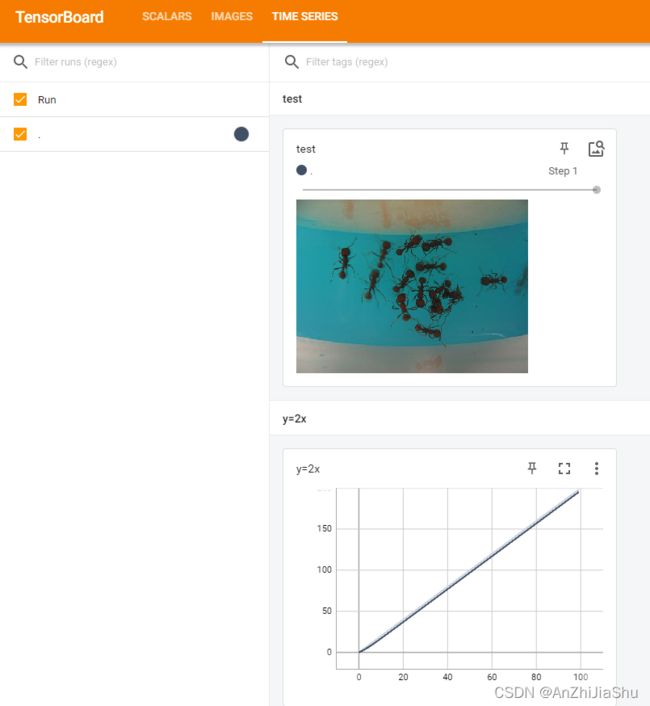
print(type(image_PIL))#在终端敲tensorboard --logdir="test1\logs" --port=6008

点击链接,查看tensorboard内容
若在服务器上运行的 tensorboard,需要在本地查看时,需要在本地连接服务器,打开cmd,敲如下命令:
ssh -L 16007:127.0.0.1:6006 -p server_port username@server_ip
16007是服务器上运行的tensorboard的端口号,6007是映射到本地的端口号,例如,我敲的是:
ssh -L 6008:127.0.0.1:6008 -p 23765 [email protected]
然后在本地的浏览器输入:http://localhost:6008
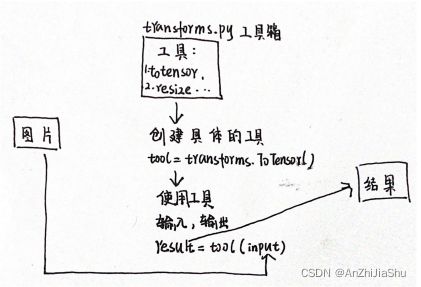
2.3 Transformers 的使用
torchvision中的transforms主要是对图片进行一些变换
· 图片——>transform工具包处理——>结果
2.3.1 Transforms 简介
transforms在计算机视觉工具包torchvision下:
torchvision.transforms: 常用的图像预处理方法torchvision.datasets: 常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等torchvision.model: 常用的模型预训练,AlexNet,VGG, ResNet,GoogLeNet等
torchvision.transforms : 常用的图像预处理方法,提高泛化能力:• 数据中心化 • 数据标准化 • 缩放 • 裁剪 • 旋转 • 翻转 • 填充 • 噪声添加 • 灰度变换 • 线性变换 • 仿射变换 • 亮度、饱和度及对比度变换
相当于真正高考前做的三年高考五年模拟,五年高考是原始数据,三年模拟是在原题基础上改的模拟题。
2.3.2 Transforms 运行机制
采用transforms.Compose(),将一系列的transforms有序组合,实现时按照这些方法依次对图像操作。
train_transform = transforms.Compose([
transforms.Resize((32, 32)), # 缩放
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.ToTensor(), # 图片转张量,同时归一化0-255 ---》 0-1
transforms.Normalize(norm_mean, norm_std), # 标准化均值为0标准差为1
])
2.3.3 土堆 Transforms 的例子
在这里通过transfrom.totensor去回答两个问题:
- tranasforms如何使用
- 为何需要tensor数据类型
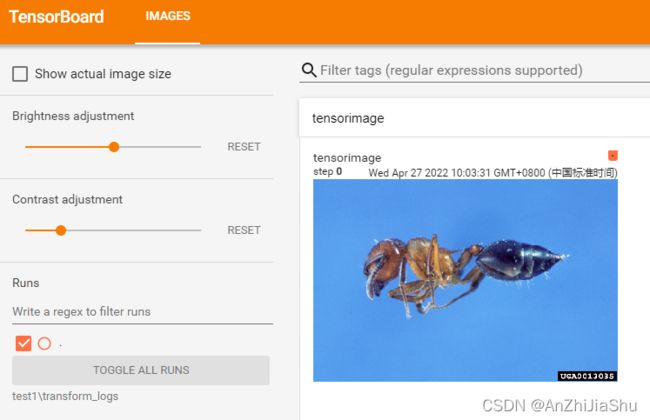
① 问题1:transform如何使用。新建一个test_transform.py文件,输入以下代码:
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
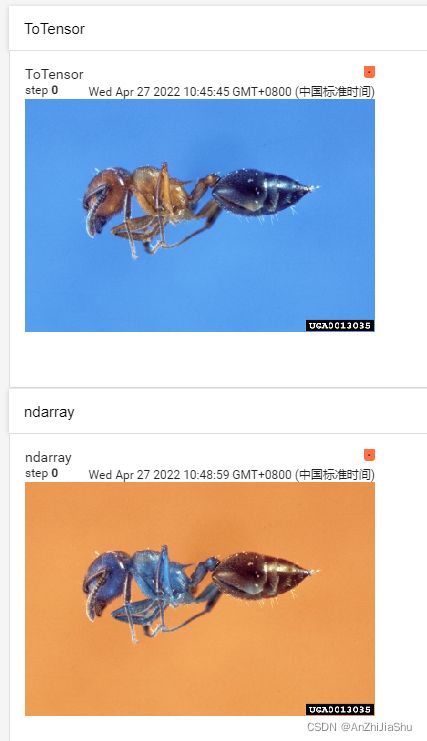
img_path="../dataset/train/ants_image/0013035.jpg"
img=Image.open(img_path) #Image是python内置的,open根据路径打开图片
print(type(img)) #因为image是from PIL import Image,所以img是个PIL类型,不满足SummaryWriter.add_image中的参数“img_tensor”所要求的类型,所以需要转换
writer=SummaryWriter("transform_logs") #将日志文件记录在 transform_logs文件夹下
'''class ToTensor: Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.'''
to_tensor=transforms.ToTensor()#ToTensor必须声明,否则会报错。利用transforms.ToTensor()将 img转换为tensor数据类型
tensor_image=to_tensor(img)#利用transforms.ToTensor()将 img转换为tensor数据类型
print(type(tensor_image))#输出tensor数据类型
writer.add_image(tag="tensorimage",img_tensor=tensor_image)
writer.close()
tensorboard打开日志文件查看:
tensorboard --logdir="test1\transform_logs"
上述transforms的用法可以用下图进行描述:
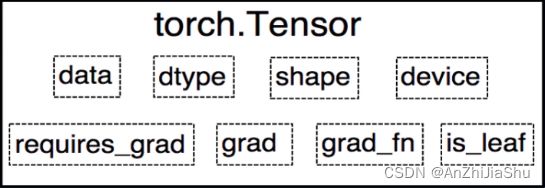
② 问题2:为何需要tensor数据类型。
tensor数据类型包装了神经网络所需要的一系列参数。 ,所以在神经网络中必定会用到 tensor 数据类型。
图源:https://pytorch.zhangxiann.com/1-ji-ben-gai-nian/1.2-tensor-zhang-liang-jie-shao
新建一个test_totensor.py文件,输入下列代码
import cv2
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_pth="../dataset/train/ants_image/0013035.jpg" #图片路径
img=Image.open(img_pth)
print(type(img)) #tensorboard打开日志文件查看:
tensorboard --logdir="test1\tensor_logs"
2.3.4 常见的Transformers
使用transformers时需要关注输入输出的类型。
Image.open()——> 返回 PIL数据类型transformers.ToTensor()——>返回tensor数据类型cv.imread()——>返回numpy.narrys数据类型
—————————————————插入土堆小课堂————————————————
Python 中的 __call__ 的用法: __call__() 的功能类似于在类中 重载 () 运算符(也就是说 对象名() = 对象名.__call__()),使得类实例对象可以像调用普通函数那样,以 “对象名()” 的形式使用。也就是说,利用内置call,可以不用 点 的调用,直接对象+()。对于可调用对象,实际上“名称()”可以理解为是“名称.__call__()”的简写。
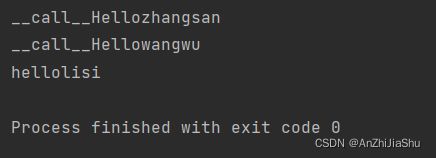
例子,新建一个testCall.py文件,输入下列代码:
class Person:
def __call__(self, name):
print("__call__"+"Hello"+name)
def hello(self,name):
print("hello"+name)
person=Person()
#利用内置call,可以不用 点 的调用,直接对象+()
person("zhangsan") #__call__Hellozhangsan
person.__call__("wangwu") #__call__Hellowangwu
person.hello("lisi") # hellolisi
运行结果:
—————————————————土堆小课堂 end———————————————
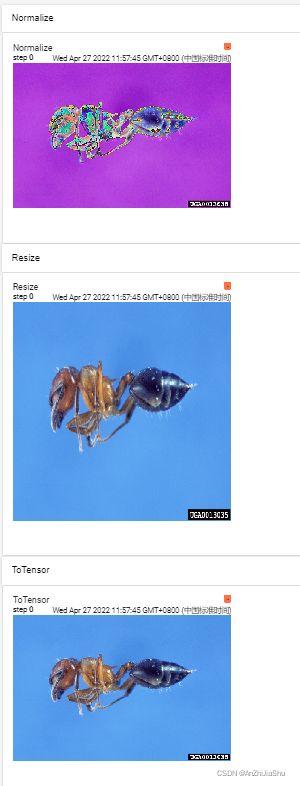
① 测试normalize和resize,新建一个test_transforms_usual.py文件,输入以下代码:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_pth="../dataset/train/ants_image/0013035.jpg" #图片路径
img=Image.open(img_pth)
writer=SummaryWriter("transformsusual_logs")#记录日志文件
#ToTensor:Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. This transform does not support torchscript.
trans_totensor=transforms.ToTensor() #Totensor必须声明否则会报错
img_tensor=trans_totensor(img)
writer.add_image(tag="ToTensor",img_tensor=img_tensor)
#Normalize正则化
'''Normalize a tensor image with mean平均值 and standard deviation标准差.
Given mean均值: ``(M1,...,Mn)`` and std标准差: ``(S1,..,Sn)`` for ``n``个 channels, this transform
will normalize each channel of the input ``torch.*Tensor`` i.e.
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
'''
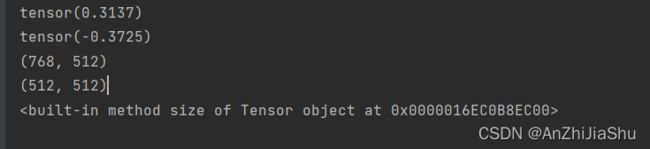
print(img_tensor[0][0][0]) #tensor(0.3137)
tensor_norm=transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5]) #均值,标准差(RGB三通道)
img_norm=tensor_norm(img_tensor)
print(img_norm[0][0][0]) #tensor(-0.3725)=(0.3137-0.5)*2
writer.add_image(tag="Normalize",img_tensor=img_norm)
#resize
print(img.size) #(768, 512)
trans_resize=transforms.Resize((512,512))
img_resize1=trans_resize(img)#img PIL->resize->img_resize PIL类型
print(img_resize1.size) #(512, 512)
img_resize=trans_totensor(img_resize1)#img_resize PIL->img_resize->totensor tensor类型
print(img_resize.size) #运行结果:-0.3725=(0.3137-0.5)*2
tensorboard打开日志文件查看:
tensorboard --logdir="test1\transformsusual_logs"
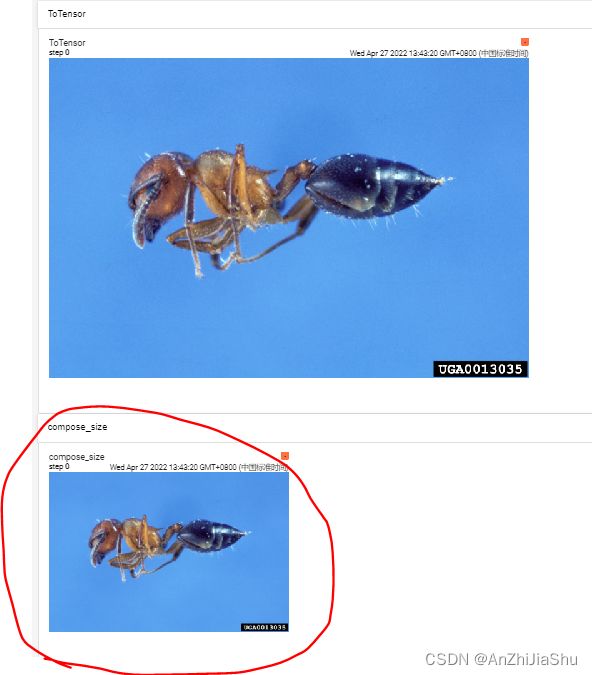
② 测试compose,compose用法:
 在test_transforms_usual.py文件,输入以下代码:
在test_transforms_usual.py文件,输入以下代码:
#compose
trans_resize2 = transforms.Resize(256) #声明
trans_compose =transforms.Compose([trans_resize2,trans_totensor])
img_resize2= trans_compose(img) #输入的必须是PIL image
writer.add_image(tag="compose_size",img_tensor=img_resize2)
tensorboard打开日志文件查看:
tensorboard --logdir="test1\transformsusual_logs"
2.3.5 使用Transformers需要注意的点
- 关注输入输出的数据类型;
- 多看官方文档;
- 关注方法需要什么参数;
- 不知道返回值时,可以:
print、print(type())、debug
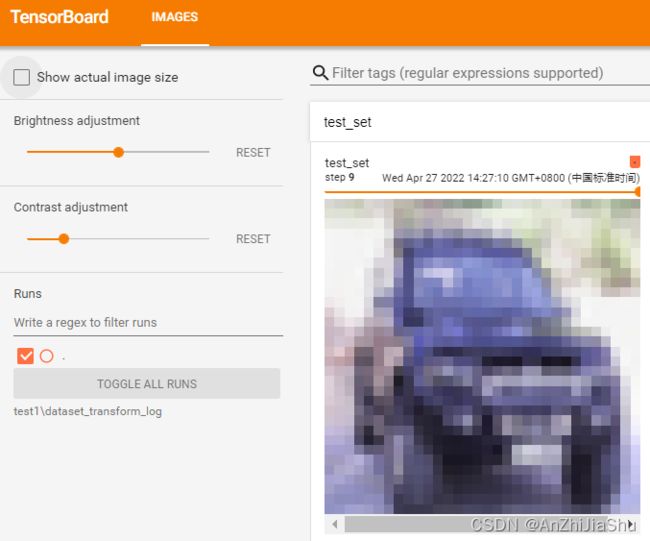
2.4 torchvision中的数据集使用
torchvision中内置了一些数据集,如CIFAR10、MNIST等,下面介绍torchvision数据集与transforms的联合使用。新建一个dataset_transforms.py文件,输入以下代码:
import torchvision
from torch.utils.tensorboard import SummaryWriter
#compose
dataset_transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
print(type(dataset_transform)) #tensorboard打开日志文件查看:
tensorboard --logdir="test1\dataset_transform_log"
2.5 神经网络基础
2.5.1 神经网络的基本骨架——nn.Module 的使用
神经网络的一些工具主要在 torch.nn 里面,nn来自于神经网络的英文 neural network。本节主要学习 nn里面的Containers,containers翻译为容器,但是可以将其理解为是一个骨架。有了骨架就需要往里面填充一些东西,比如卷积层、池化层、非线性激活层等等。如下图所示,Containers主要有6个模块:
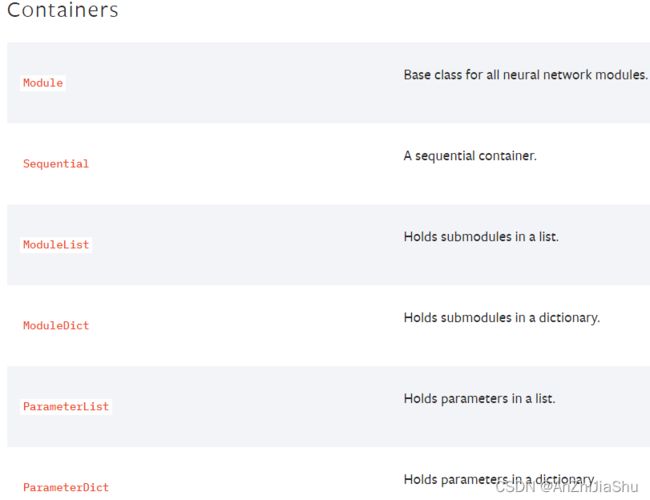
其中,Moudle是一个基本的类,主要为神经网络提供一个基本的骨架。模型必须继承这个类。pytorch里面一切自定义操作基本上都是继承nn.Module类来实现的。我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__构造函数和 forward() 方法。但有一些注意技巧:
- 一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数
__init__()中,当然我也可以吧不具有参数的层也放在里面; - 一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数
__init__里面,则在forward方法里面可以使用nn.functional来代替。 forward()方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。- 所有放在构造函数__init__里面的层的都是这个模型的“固有属性”。
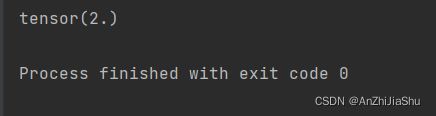
示例代码,新建一个nn_moudle.py文件,写下列代码:
import torch
from torch import nn
class Tudui(nn.Module):#定义一个名为Tudui的神经网络模板
def __init__(self):
super().__init__() ##必要的,调用父类的初始化函数
def forward(self,input): #前向传播函数
output=input+1
return output
tutui=Tudui() #实例化一个神经网络
x=torch.tensor(1.0)
output=tutui(x) #把x输入到神经网络中,会自动执行forward
print(output)
输出如下图所示:
2.5.2 神经网络——卷积层
① torch.nn.functional 中的 Convolution functions

卷积有一维卷积、二维卷积、三维卷积。conv1d代表1维卷积,conv2d代表2维卷积,一般情况下,卷积核在几个维度上滑动,就是几维卷积。比如在图片上的卷积就是二维卷积。所以主要是conv2d,因为主要针对图像,图像是一个二维的矩阵。
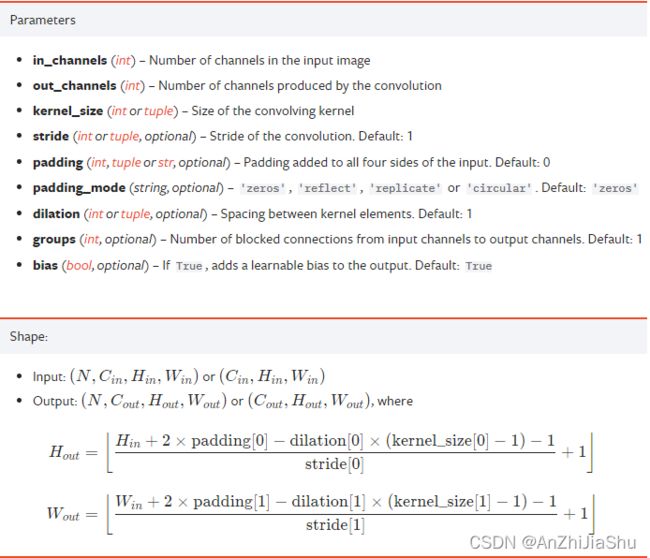
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor

示例代码,新建一个nn_conv.py文件
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]) #输入shape为:5*5 (1个([])里面5个[] 每个[]里面5个,
print("input.shape:",input.shape) #torch.Size([5, 5])
kernel=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]]) #卷积核shape为:3*3
print("kernel.shape:",kernel.shape)#torch.Size([5, 5])
#因为conv2d的input tensor 的shape是(minibatch,in_channels,iH,iW),所以需要reshape
input=torch.reshape(input,(1,1,5,5)) #将input(5*5) reshape 为(1*1*5*5)
print("reshape_input.shape:",input.shape)#torch.Size([1, 1, 5, 5])
#因为weight – filters of shape (out_channels,in_channels/groups,kH,kW)(groups默认=1)
kernel=torch.reshape(kernel,(1,1,3,3)) # 将kernel(3*3) reshape为(1*1*3*3)
print("reshape_kernel.shape:",kernel.shape)#torch.Size([1, 1, 3, 3])
output=F.conv2d(input=input,weight=kernel,stride=1) #conv2d2维卷积
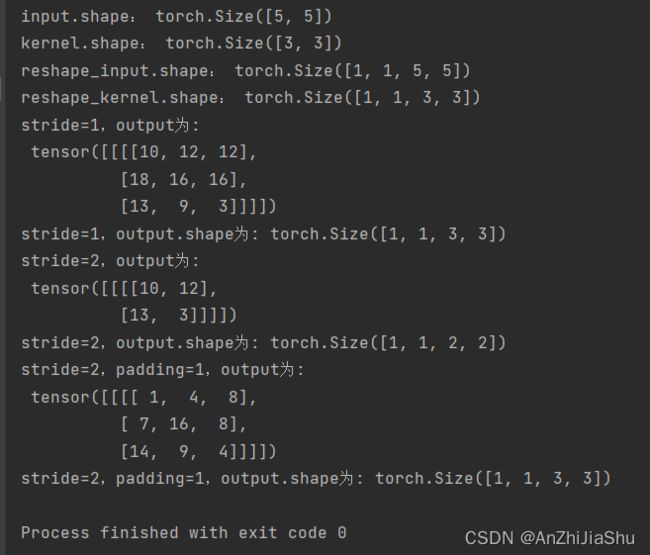
print("stride=1,output为:\n",output)
'''
stride=1,output为:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
'''
print("stride=1,output.shape为:",output.shape) #torch.Size([1, 1, 3, 3]),([])里面有一个[[[]]],[[[]]]里面有一个[[]],[[]]里面有3个[],每个[]里面3个,
output2=F.conv2d(input=input,weight=kernel,stride=2)
print("stride=2,output为:\n",output2)
'''
stride=2,output为:
tensor([[[[10, 12],
[13, 3]]]])
'''
print("stride=2,output.shape为:",output2.shape)#torch.Size([1, 1, 2, 2]),
output3=F.conv2d(input=input,weight=kernel,stride=2,padding=1)
print("stride=2,padding=1,output为:\n",output3)
'''
stride=2,padding=1,output为:
tensor([[[[ 1, 4, 8],
[ 7, 16, 8],
[14, 9, 4]]]])
'''
print("stride=2,padding=1,output.shape为:",output3.shape)# torch.Size([1, 1, 3, 3])
运行结果:
② torch.nn 中的 Convolution Layers
主要也是 nn.Conv2d,点击 nn.Conv2d 进行查看。


示例代码,新建一个 nn_conv2.py文件,写入下列代码:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset=dataset,batch_size=64) #载入数据
class Tudui(nn.Module): #实现自己的一个网络模型,必须重载nn.Module
def __init__(self):
super(Tudui,self).__init__() ##必要的,调用父类的初始化函数
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x): #前向传播
x=self.conv1(x)
return x
tudui=Tudui() ##实例化一个模型
writer=SummaryWriter("nnlogs") #记录到日志中
#这里进行1个epoch,batch_size=64,也就是是个batch 64张图片,所以N=64
step=0
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
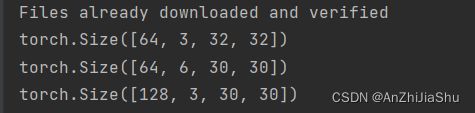
print(imgs.shape)#torch.Size([64, 3, 32, 32]) N=batch_size=64,in_channel=3,w=32,h=32
# (inputsize-kernelsize+2padding)/stride+1=(32-3+0)/1+1=30
print(output.shape)#torch.Size([64, 6, 30, 30]) N=batch_size=64,out_channel=6,w=30,h=30
writer.add_images(tag="input",img_tensor=imgs,global_step=step)
'''writer.add_images(tag="output", img_tensor=output, global_step=step)
这样会报错,因为output_channel=6,图像是3个channel,所以tensorboard不知道如何显示,所以需要将其reshape为3个channel
'''
# reshape,-1代表会根据后面的值自动计算
output=torch.reshape(output,(-1,3,30,30))#torch.size([64, 6, 30, 30])->([128,3,30,30)(-1代表会自动计算)
print(output.shape) #torch.size([128, 6, 30, 30])
writer.add_images(tag="output",img_tensor=output,global_step=step)
step+=1
writer.close()
运行结果:
tensorboard打开日志文件查看:
tensorboard --logdir="test1\nnlogs"
2.5.3 神经网络——最大池化的使用
torch.nn 的 Pooling layers,最大池化就是为了下采样,减少数据量,加速训练。
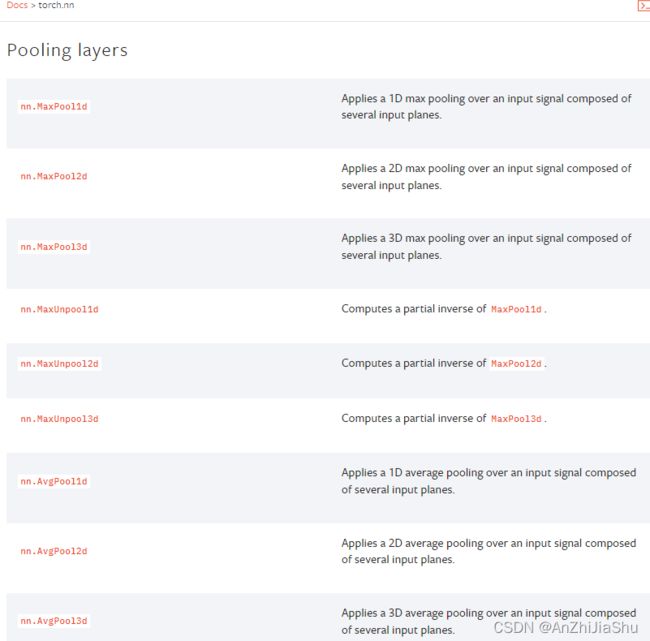
maxpooling也称作下采样,最常用的是 MaxPool2d,点进去之后可看到:

主要是一个kernel_size
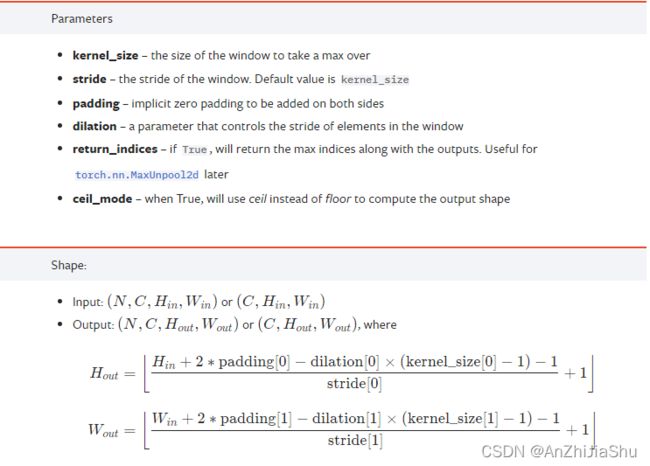
ceil_mode 如果为True,将使用ceil (天花板模式) 而不是floor (地板模式) 来计算输出形状,默认为False,也就是说若走到末尾不满足池化核大小则抛弃。
示例代码,新建一个nn_maxpooling.py文件,写入如下代码测试一个给定的tensor的maxpool结果,以及CIFAR10数据集的maxpool结果
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module): #定义自己的模型,必须继承nn.Module
def __init__(self):
super(Tudui,self).__init__() ##必要的,调用父类的初始化函数
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True) #天花板模式,不抛弃不满足kernel_size的块
def forward(self,input):
output=self.maxpool1(input)
return output
tudui=Tudui() #实例化神经网络
#------------------用给定的tensor测试 maxpool-------------------#
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) #不加dtype会报错
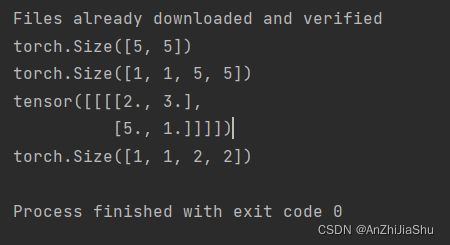
print(input.shape)#torch.Size([5, 5]),一个([])里面5个[],每个[]里面5个,
input=torch.reshape(input,(-1,1,5,5))# 将input reshape为 torch.Size([1, 1, 5, 5]),-1代表会根据后面的值自动计算
print(input.shape) #torch.Size([1, 1, 5, 5])
output1=tudui(input)
print(output1)
'''
tensor([[[[2., 3.],
[5., 1.]]]])
'''
print(output1.shape) #torch.Size([1, 1, 2, 2]),([])里面 1 个[[[]]],每个[[[]]]里面 1 个[[]],每个 [[]]里面 2 个[],每个[]里面 2 个,
#------------------用给定的数据集测试 maxpool-------------------#
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
writer=SummaryWriter("logs_maxpool") ##用summary记录日志
#测试一个epoch
step=0
for data in dataloader:
imgs,target=data
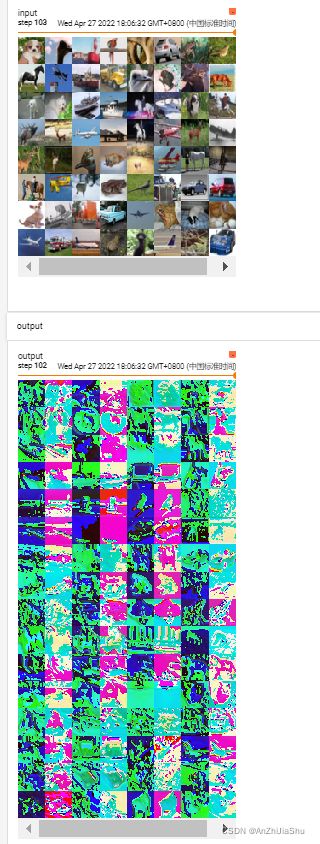
writer.add_images(tag="input",img_tensor=imgs,global_step=step)
output=tudui(imgs)
writer.add_images(tag="output", img_tensor=output, global_step=step)
step+=1
writer.close()
运行结果如下图所示
tensorboard打开日志文件查看:
tensorboard --logdir="test1\logs_maxpool"
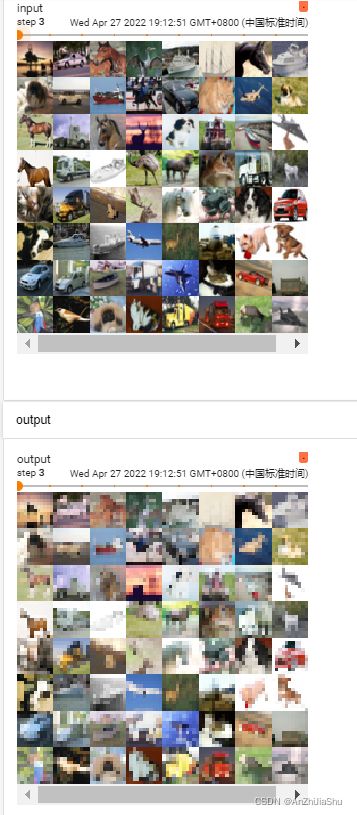
2.5.4 神经网络——非线性激活
torch.nn 的 Non-linear Activations (weighted sum, nonlinearity),非线性变换主要是为网络引入非线性特征,非线性越多才能训练出符合各种特征的模型。

以ReLU激活函数为例,点进去可看到
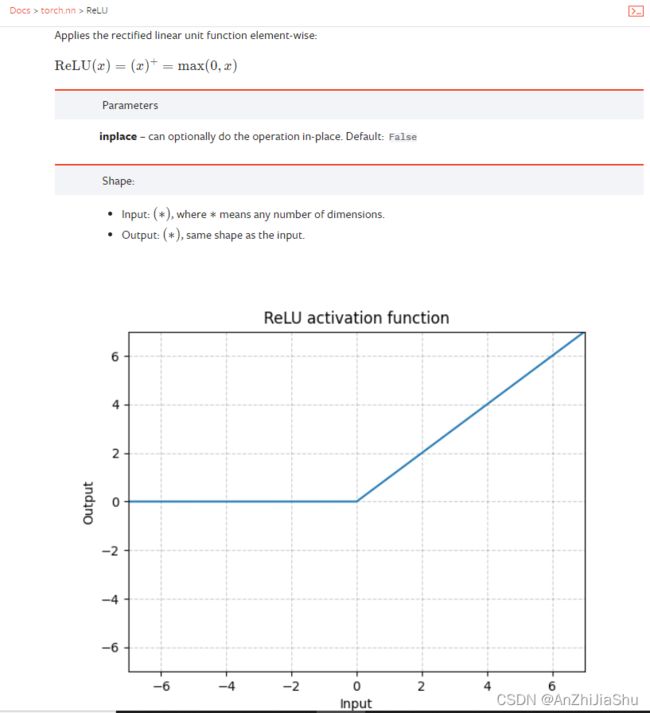
示例代码,新建一个nn_relu.py文件,输入以下代码,测试一个给定的tensor以及数据集CIFAR10
import torch
from torch import nn
import torchvision
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module): #定义自己的模型,必须继承nn.Module
def __init__(self):
super(Tudui,self).__init__() ##必要的,调用父类的初始化函数
self.relu=ReLU() #Relu激活函数,参数inplace默认为False,也就是说不改变输入
def forward(self,input): #前向传播进行计算
output=self.relu(input)
return output
tudui=Tudui() #实例化一个模型
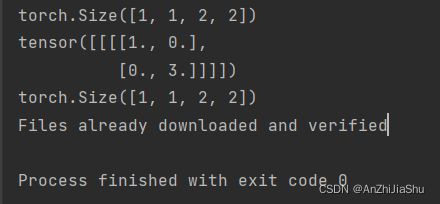
#----------以给定的一个tensor为例---------------
input = torch.tensor([[1,-0.5],
[-1,3]]) #torch.Size([2,2])
input_reshape=torch.reshape(input,(-1,1,2,2))
print(input_reshape.shape) #torch.Size([1,1,2,2])
output=tudui(input_reshape)
print(output)
'''
tensor([[[[1., 0.],
[0., 3.]]]])
'''
print(output.shape) #torch.Size([1, 1, 2, 2])
#-----------------------以给定的数据集为例-----------------------------------
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64) #dataloader加载数据集,batch_size=64
writer=SummaryWriter("logsrelu")
#-----测试一个epoch-----------
step=0
for data in dataloader:
imgs,target=data
writer.add_images("input",imgs,step)
output=tudui(imgs)
writer.add_images("output",output,step)
step+=1
writer.close()
运行结果如下所示:
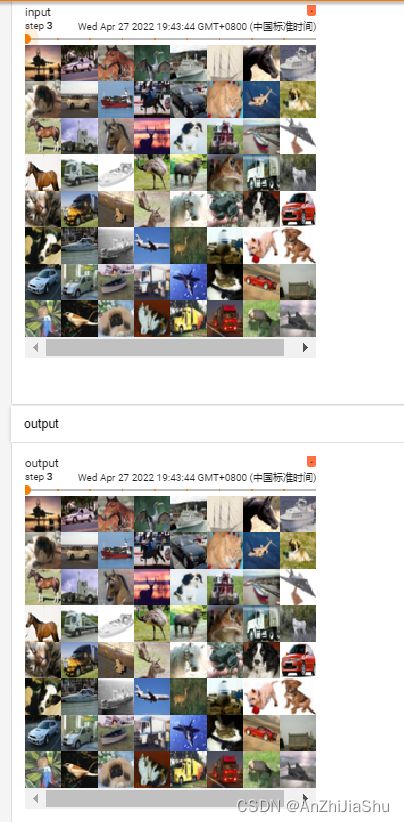
tensorboard打开日志文件查看:(relu测试数据集的结果不明显,可换成sigmoid)
tensorboard --logdir="test1\logsrelu"
2.5.5 神经网络——线性层
torch.nn 的 Linear Layers。线性链接层就是全连接层。

点进去 Linear 进行查看。线性链接层就是全连接层。

示例代码,新建一个nn_linear.py文件,写下如下代码:
import torch
from torch import nn
import torchvision
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64,drop_last=True) #抛弃最后不满足64的
class Tudui(nn.Module): #构建自己的一个模型用于测试linear层,必须继承nn.Module
def __init__(self):
super(Tudui,self).__init__() #必要的,调用父类的初始化方法
self.linear=Linear(in_features=196608,out_features=10)#infeature,outfeature,分成10类
def forward(self,input): #前向传播
output=self.linear(input)
return output
tudui=Tudui() #实例化一个模型
#---------------------测试一个epoch--------------------------
step=0
for data in dataloader:
imgs,target=data
print(imgs.shape) #torch.Size([64, 3, 32, 32]),我们想将其变为(1,1,1,*)
output1=torch.reshape(imgs,(1,1,1,-1)) # -1代表根据后面的值自动计算
print(output1.shape) #torch.Size([1, 1, 1, 196608])
output2=torch.flatten(imgs) #也可以用flatten处理,input是个tensor数据类型
print(output2.shape) #torch.Size([196608])
output3 = tudui(output1)
print(output3.shape) # torch.Size([1, 1, 1, 10])
output4=tudui(output2)
print(output4.shape) #torch.Size([10])
step+=1
运行结果如下所示:
2.5.6 神经网络——torch.nn.Sequential
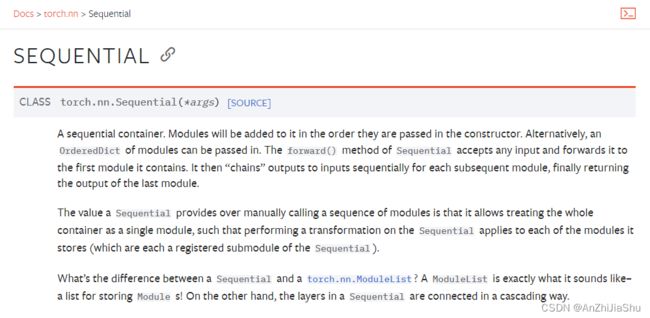
Sequential是一个顺序容器。模块将按照在构造函数中传递的顺序添加到它。或者,可以传入一系列模块。Sequential的forward()方法接受任何输入,并将其转发到它包含的第一个模块。然后,它将输出按顺序“链接”到每个后续模块的输入,最后返回最后一个模块的输出。
官方示例
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
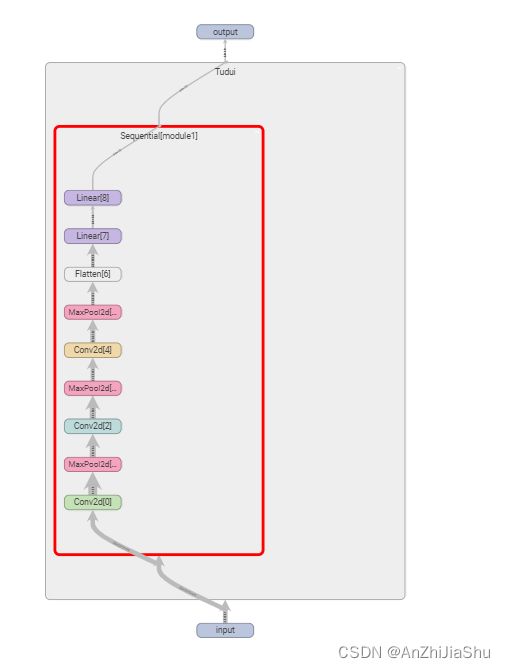
2.5.7 神经网络——搭建小实战
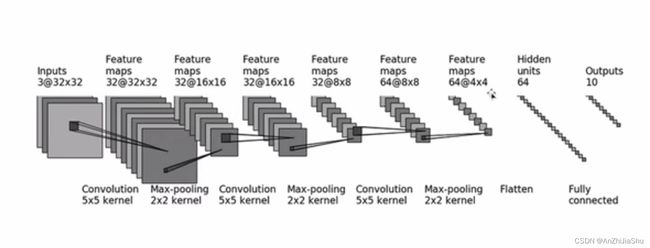
搭建一个如下图所示的小型网络
新建一个nn_seq.py文件,并写下如下代码,从代码可以看出,使用Sequential时定义的网络模型更简介
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules import Flatten
from torch.utils.tensorboard import SummaryWriter
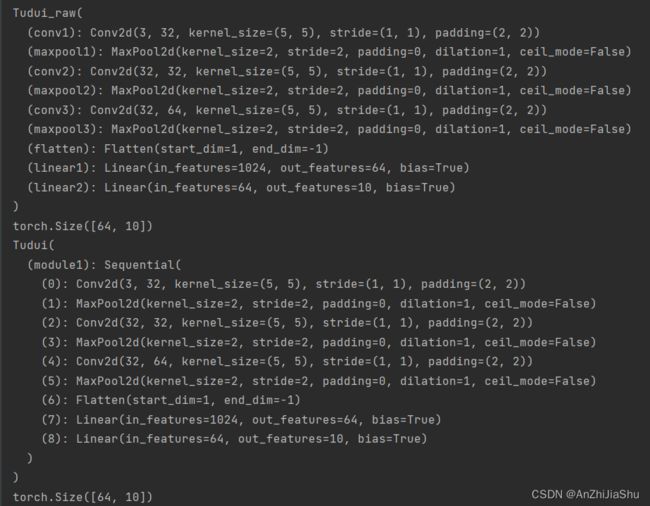
class Tudui_raw(nn.Module): #不使用Sequential进行搭建
def __init__(self):
super(Tudui_raw,self).__init__()
self.conv1=Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2)
self.maxpool1=MaxPool2d(kernel_size=2)
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
self.maxpool2 = MaxPool2d(kernel_size=2)
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
self.maxpool3 = MaxPool2d(kernel_size=2)
self.flatten=Flatten()
self.linear1=Linear(in_features=1024,out_features=64)
self.linear2=Linear(in_features=64,out_features=10)
def forward(self,x):
x=self.conv1(x)
x=self.maxpool1(x)
x=self.conv2(x)
x=self.maxpool2(x)
x=self.conv3(x)
x=self.maxpool3(x)
x=self.flatten(x)
x=self.linear1(x)
x=self.linear2(x)
return x
#使用Sequential进行搭建
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.module1 = Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024,out_features=64),
Linear(in_features=64,out_features=10)
)
def forward(self,x):
x=self.module1(x)
return x
input=torch.ones((64,3,32,32))
#----------------测试不使用Sequential进行搭建的模型-------------------
tuduiraw=Tudui_raw()
print(tuduiraw)
output1=tuduiraw(input)
print(output1.shape) #torch.Size([64, 10])
#----------------测试使用Sequential进行搭建的模型,并写入tensorboard-------------------
tudui=Tudui()
print(tudui)
output=tudui(input)
print(output.shape) #torch.Size([64, 10])
writer=SummaryWriter("logs_seq")
writer.add_graph(tudui,input)
writer.close()
输出结果:
tensorboard打开日志文件查看:
tensorboard --logdir="testCIFAR10\logs_seq"
2.5.8 损失函数与反向传播
loss function的作用:
- 用于衡量预测与真实之间的误差,loss越小越好。
- 通过loss来提高预测,为更新输出提供一定的依据(反向传播)。
loss function在torch.nn里面:
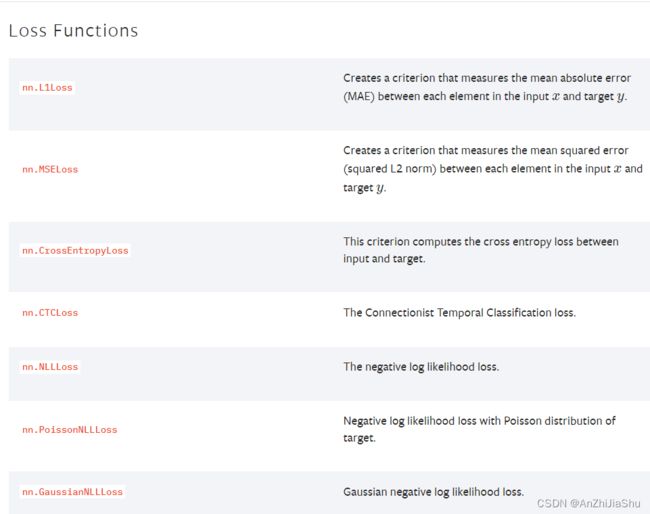
①:示例代码1:一些loss的示例,新建一个nn_loss.py文件,并写下如下代码:
import torch
from torch import nn
from torch.nn import L1Loss
input=torch.tensor([1,2,3],dtype=torch.float32)
target=torch.tensor([1,2,5],dtype=torch.float32) #GT
print(input.shape)#torch.Size([3])
print(target.shape)#torch.Size([3])
input=torch.reshape(input,(1,1,1,3))
target=torch.reshape(target,(1,1,1,3))
#-------------------L1Loss--------------------
loss=L1Loss(reduction="sum")
result=loss(input,target)
print(result) #tensor(2.)
#--------------------MSELoss----------------------
loss_mse=nn.MSELoss()
result_mse=loss_mse(input,target)
print(result_mse) #tensor(1.3333)
#--------------------CrossEntropyLoss----------------------
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))
print(x) #tensor([[0.1000, 0.2000, 0.3000]])
loss_cross=nn.CrossEntropyLoss()
result_cross=loss_cross(x,y)
print(result_cross) #tensor(1.1019)
运行结果如下所示:

②示例代码2: 在具体模型训练中使用loss,新建一个nn_loss_network.py文件,并写下如下代码:
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules import Flatten
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
daraloader=DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.module1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.module1(x)
return x
#-----------定义一个交叉熵损失函数-------------------
loss=nn.CrossEntropyLoss()
tudui=Tudui()
#-------------测试一个epoch-------------------
for data in daraloader:
imgs,target=data #target就是标签
output=tudui(imgs)
#----------计算模型输出output与真实target之间的loss--------------
result_loss=loss(output,target)
print(result_loss)
#------------反向传播-----------------
result_loss.backward()#反向传播计算梯度grad
运行结果如下所示:
2.5.9 优化器
torch.optim。torch.optim是一个实现了各种优化算法的库。
使用optimizer
使用torch.optim,需要构建一个optimizer对象。该对象能够保持当前参数状态并基于“计算得到的梯度”进行参数更新。
构建
构建一个Optimizer,需要给它一个包含了需要优化的参数(必须都是Variable对象)的iterable。然后,可以设置optimizer的参数选项,比如学习率,权重衰减,等等。
例子:
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001)
为每个参数单独设置选项
Optimizer也支持为每个参数单独设置选项。若想这么做,不要直接传入Variable 的 iterable,而是传入 dict 的 iterable,每一个 dict 都分别定义了一组参数,并且包含一个 param键,这个键对应参数的列表。
注意:你仍然能够传递选项作为关键字参数。在未重写这些选项的组中,它们会被用作默认值。当你只想改动一个参数组的选项,但其他参数组的选项不变时,这是 非常有用的。
例如,当我们想指定每一层的学习率时,这是非常有用的:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
这意味着 model.base 的参数将会使用 1e-2 的学习率,model.classifier 的参数将会使用 1e-3 的学习率,并且 0.9 的 momentum 将会被用于所 有的参数。
进行单次优化
所有的 optimizer 都实现了 step() 方法,这个方法会更新所有的参数。它能按两种方式来使用:
optimizer.step():是大多数optimizer所支持的简化版本。一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数。
例子
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.step(closure):一些优化算法例如 Conjugate Gradient 和 LBFGS 需要重复多次计算函数,因此你需要传入一个闭包去允许它们重新计算你的模型。这个闭包应当清空梯度, 计算损失,然后返回。
例子:
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)
土堆的示例代码,新建一个nn_optim.py文件,写下如下代码:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules import Flatten
from torch.utils.data import DataLoader
#把数据集转化为tensor
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
daraloader=DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.module1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.module1(x)
return x
loss=nn.CrossEntropyLoss() #定义一个交叉熵Loss
tudui=Tudui() #实例化模型
'''定义一个SGD优化器,需要给它一个包含了需要优化的参数(必须都是`Variable`对象)的`iterable,在这里就是模型的参数:tudui.parameters()'''
optim=torch.optim.SGD(tudui.parameters(),lr=0.01)#优化器,lr是学习率,学习速率一开始比较大,后面比较小
#----------训练----------------------
for epoch in range(20):
running_loss=0.0 #计算每一个 epoch的 loss的和
for data in daraloader: #依次从dataloader中取数据
imgs, target = data
output = tudui(imgs) #将图片数据送入模型进行训练
result_loss = loss(output, target) #计算输出与目标之间的损失
#-----------------优化器--------------------------------
'''优化是每一步先清0,再反向传播'''
optim.zero_grad() #必须先把网络中可以调节的参数对应的梯度调为0
'''设置为0之后,需要优化器对每一个参数进行优化,优化器需要每一个参数的梯度,所以需要计算梯度'''
result_loss.backward() #反向传播计算每一个参数的梯度
optim.step() #调用step对每个参数进行调优
# -----------------优化器--------------------------------
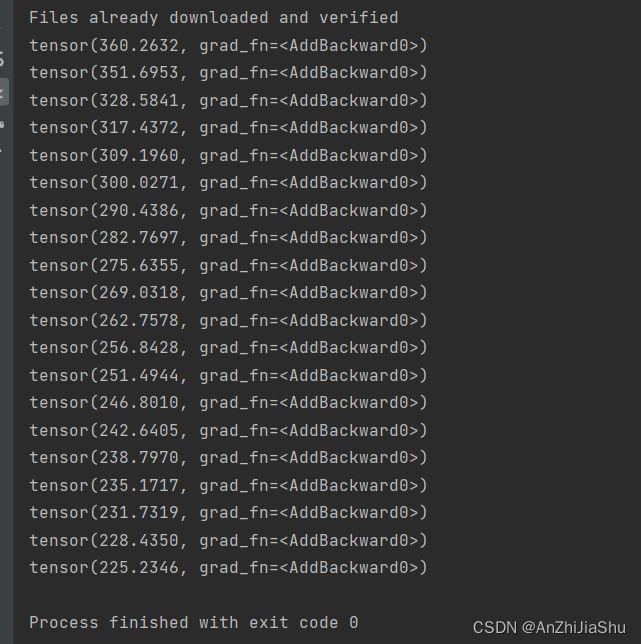
running_loss=running_loss+result_loss
print(running_loss)
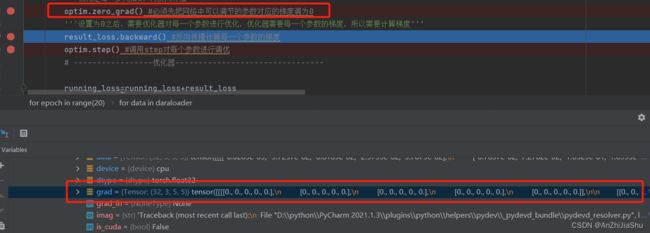
Debug查看优化器是如何进行的:
debug查看参数:
tudui->Protected Attributes->modules->‘module1’->Protected Attributes->module->‘0’->weight
① 执行完optim.zero_grad()后,梯度被清0
②:执行result_loss.backward()反向传播计算梯度
③调用step对每个参数进行调优
程序运行结果:
2.5.10 现有网络模型的使用及修改
torchvision.models模块的子模块中主要包含关于图像的网络模型,例如VGG、AlexNet、ResNet等。可以使用随机初始化的权重来创建这些模型。
例如:
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
squeezenet = models.squeezenet1_0()
densenet = models.densenet_161()
torchvision也提供了预训练(pre-trained)的模型。pretrained=True就可以使用预训练的模型
import torchvision.models as models
#pretrained=True就可以使用预训练的模型
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
本节主要以VGG16为例:(progress设置为true会显示下载进度条)
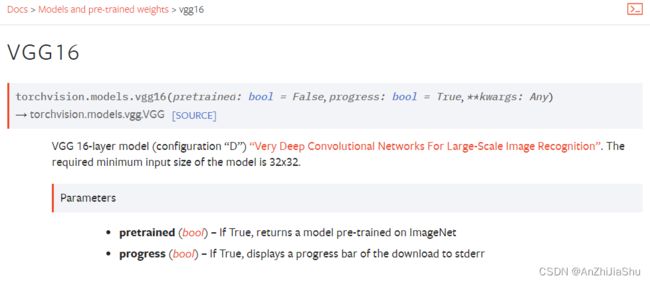
数据集选择CIFAR10,该数据集有10个类别,但是VGG16最后会将数据集分为1000类,所以需要对模型进行修改,新建一个nn_vgg16_module.py文件,写下如下代码:
import torchvision
from torch import nn
#----------------------实例化VGG16网络模型
vgg16_false = torchvision.models.vgg16(pretrained=False) #如果pretrained为False,不需要下载预训练的模型
#vgg16_true=torchvision.models.vgg16(pretrained=True) #如果pretrained为True,则返回在ImageNet上预先训练的模型,需要下载预训练的模型
print("vgg16_false:\n",vgg16_false)
#print("vgg16_true:\n",vgg16_true)
#-------------下载数据集,并用torchvision.transforms.ToTensor()将数据类型转换为tensor--------------------------
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
'''因为CIFAR10数据集是10类,但是VGG16模型分成了1000个类,所以需要对模型进行修改'''
vgg16_false.classifier.add_module('add_linear',nn.Linear(1000,10)) ##加一个线性层名为“add_linear”,将最后一层分类层输出修改为10
print("增加线性层的vgg16_flase:\n",vgg16_false)
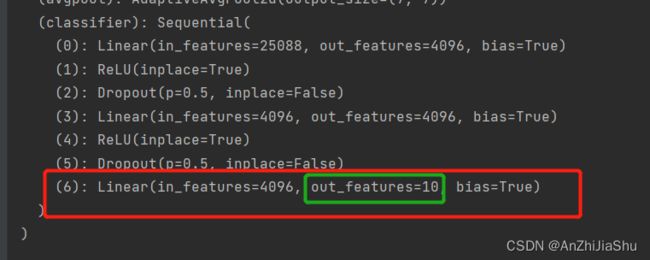
'''对模型进行修改方法2'''
vgg16_false2 = torchvision.models.vgg16(pretrained=False) #如果pretrained为False,不需要下载预训练的模型
vgg16_false2.classifier[6]=nn.Linear(4096,10) #也可以直接对最后一个分类层进行修改,使其输出为10
print("修改最后一层的vgg16_false:\n",vgg16_false2)
运行结果:
①添加add_linear的模型:
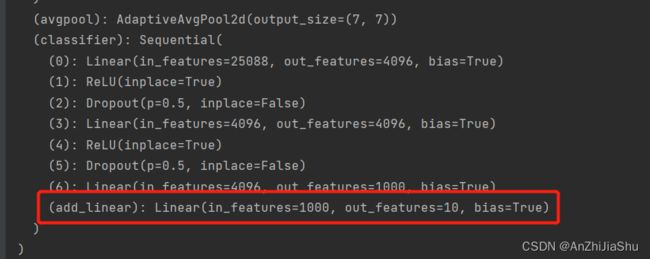
②直接对模型最后一层分类层进行修改:
2.5.11 网络模型的保存与读取
模型的保存和加载各有两种方法:
①:模型保存方法1 :模型结构+模型参数 (不推荐,有陷阱)
vgg16=torchvision.models.vgg16(pretrained=False)
#保存方式1,保存模型结构+模型参数
torch.save(vgg16,"vgg16_method1.pth") #第一个参数是网络模型,第二个参数是保存的路径
方法①对应的加载模型的方式:
model=torch.load("vgg16_method1.pth")
②:模型保存方式2:模型参数(官方推荐) ,因为这个方式,储存量小
state_dic()相当于把模型的状态保存成一种字典格式,也就是将网络模型的参数保存成字典格式,不保存网络结构。
vgg16=torchvision.models.vgg16(pretrained=False)
#保存方式2,保存模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
方法②对应的模型加载方式:1. 新实例化一个网络结构,2. 然后再进行加载恢复,直接恢复的话加载出来的是字典形式的:
'''新建一个网络结构,然后再进行加载恢复,直接恢复的话加载出来的是字典形式的'''
vgg16 = torchvision.models.vgg16(pretrained=False) #实例化一个网络结构
model2 = vgg16.load_state_dict(torch.load("vgg16_method2.pth")) #加载模型
2.6 完整的模型训练套路
以CIFAR10数据集为例,完成对他的分类(10分类问题)。
步骤① 准备数据集: 新建一个nn_dataset.py文件,并写下如下代码利用dataset和dataloader加载数据集:
import torchvision
from torch.utils.tensorboard import SummaryWriter
from test_network.nn_network import *
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
#加载训练集与测试集,并将数据格式转化为tensor数据类型,target_transform=None 指不对 target 做修改
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),target_transform=None, download=True)
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),target_transform=None,download=True)
#查看数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度为:{}".format(train_data_size)) #50000
print("测试数据集长度为:{}".format(test_data_size)) #10000
#利用dataloader 加载数据,batchsize=64
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
步骤② 建立一个网络模型: 搭建一个如下图所示的网络模型:
新建一个nn_network.py文件,写下如下代码利用 nn.Sequential 建立一个与网络模型:
#神经网络
import torch
from torch import nn
#搭建一个网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), #卷积层
nn.MaxPool2d(kernel_size=2), #池化层
nn.Conv2d(in_channels=32,out_channels=32, kernel_size=5, stride=1, padding=2), #卷积层
nn.MaxPool2d(kernel_size=2), #池化层
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), #卷积层
nn.MaxPool2d(kernel_size=2), #池化层
nn.Flatten(), #展平64*4*4=1024(2^10)
nn.Linear(in_features=1024, out_features=64),#线性层
nn.Linear(in_features=64, out_features=10) #线性层
)
def forward(self, x): #前向传播
x = self.model(x)
return x
'''
测试神经网络是否正确
'''
if __name__=='__main__':
tudui=Tudui()
input=torch.ones((64,3,32,32))#torch.Size([64, 3, 32, 32]),用于模拟每个batch的数据集,N=batchsize=64,channel=3,size=32*32
print(input.shape) # torch.Size([64, 3, 32, 32])
output=tudui(input)
print(output.shape) #torch.Size([64, 10])
#----------下面这样写是不对的,因为torch.tensor([64,3,32,32])就是一个数据为[64,3,32,32]的tensor,其torch.size=([4])-----------------------
# input=torch.tensor([64,3,32,32])#torch.Size([4])
# input=torch.reshape(input,(-1,3,32,32))
# print(input.shape)
测试网络模型是否正确的输出结果:
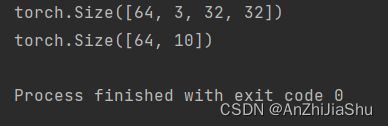
步骤③ 实例化一个网络模型: 在nn_dataset.py文件中补充如下代码来实例化一个网络模型:
'''----------搭建神经网络,实例化网络模型----------'''
tudui=Tudui()
步骤④ 定义损失函数与优化器:** 在nn_dataset.py文件中补充如下代码来定义一个交叉熵损失函数与SGD优化器:
'''---------定义一个交叉熵损失函数--------'''
loss_fn=nn.CrossEntropyLoss()
'''---------定义一个SGD优化器------------'''
learning_rate=1e-2 #学习率 1*10^(-2)
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
步骤⑤ 设置训练的一些参数:** 在nn_dataset.py文件中补充如下代码来设置训练的轮数epoch,总的训练次数与总的测试次数。
'''-------设置训练的一些参数-------'''
total_train_step=0 #记录训练的次数
total_test_step=0 #记录测试的次数
epoch=10 #记录训练的轮数
步骤⑥ 开始训练: 每次训练时需要计算loss,然后进行反向传播计算梯度,并利用优化器更新参数,同时,模型训练时如何知道模型是否训练好,因此每次训练完一轮(1个epoch) 都需要进行一次测试,以测试数据集上的损失进行评估。在测试过程中,利用现有的模型进行测试,无梯度,无调优。在nn_dataset.py文件中补充如下代码来进行训练:
1. 代码1: 无tensorboard和准确率:
for i in range(epoch):
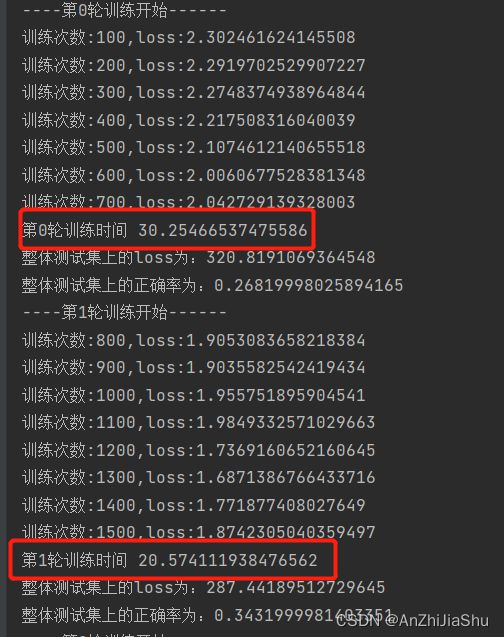
print("----第{}轮训练开始------".format(i))
#--------------start 不添加tensorboard----------------------------
#训练步骤开始
for data in train_dataloader: #从train_dataloader中获取 data
imgs,targets=data #从data中获取图片及标签
output=tudui(imgs) #将图片送入模型
loss=loss_fn(output,targets) #计算预测与目标之间的loss
#优化器处理模型,分3步,清零,反向传播,递进
optimizer.zero_grad() #调用优化器将梯度清零
loss.backward() #反向传播
optimizer.step() #优化器更新参数
total_train_step+=1 #总训练次数+1
if total_train_step%100==0: #每100次输出一个loss
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
#测试,模型训练时如何知道模型是否训练好,因此每次训练完一轮都需要进行一次测试,以测试数据集上的损失进行评估
#测试步骤开始
total_test_loss=0
with torch.no_grad(): #利用现有的模型进行测试,torch.no_grad()保证无梯度,无调优
for data in test_dataloader: #从测试集中获得数据
imgs,targets=data
output=tudui(imgs) #将图片用训练的模型进行测试
loss=loss_fn(output,targets) #计算测试的loss
total_test_loss+=loss.item() #因为loss是tensor数据类型,而total_test_loss是普通的数字,所以需要loss.item()
print("整体测试集上的loss为:{}".format(total_test_loss))
2. 代码2: 加上 tensorboard 对训练及测试的 loss 进行可视化:
#添加tensorboard
writer=SummaryWriter("mynetworklogs")
for i in range(epoch):
print("----第{}轮训练开始------".format(i))
#------------start 添加tensorboard---------------------------------------------
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
output=tudui(imgs)
loss=loss_fn(output,targets)
#优化器处理模型,分3步,清零,反向传播,递进
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar(tag="train_loss",scalar_value=loss.item(),global_step=total_train_step) #画train_loss图,每逢100画一次
#测试,模型训练时如何知道模型是否训练好,因此每次训练完一轮都需要进行一次测试,以测试数据集上的损失进行评估
#测试步骤开始
total_test_loss=0
with torch.no_grad(): #利用现有的模型进行测试,无梯度,无调优
for data in test_dataloader:
imgs,targets=data
output=tudui(imgs)
loss=loss_fn(output,targets)
total_test_loss+=loss.item()
print("整体测试集上的loss为:{}".format(total_test_loss))
writer.add_scalar(tag="test_loss",scalar_value=total_test_loss,total_test_step) #每一个epoch画一次loss
total_test_step+=1
torch.save(tudui,"tuidui_{}.pth".format(i)) #每训练一个epoch,保存一次模型
print("模型已保存")
#-------------end 添加tensorboard-------------------------
writer.close()
3. 代码3: 加上 tensorboard 对训练及测试的 loss 进行可视化以及加上正确率查看分类效果:
——————————————start 土堆小课堂分类问题的正确率————————————————
AP = TP/(TP+FP) = TP/ALL,pytorch中引入argmax来查看tensor每个维度的最大值的位置进而计算TP。
output=torch.tensor([[0.1,0.2],
[0.3,0.4]])
preds=output.argmax(1) #参数1是指横着看,0指竖着看,0.3和0.4最大,得([1,1])
targets=torch.tensor([0,1]) #设置标签是(0, 1)
print((preds==targets).sum())#tensor(1) #当预测=GT时为TP
—————————————end 土堆小课堂分类问题的正确率———————————————————
加tensorboard 和 准确率的代码为:
#-----------------------开始训练---------------------------------
#添加tensorboard
writer=SummaryWriter("mynetworklogs")
for i in range(epoch):
print("----第{}轮训练开始------".format(i))
#----------------start 添加tensorboard 以及正确率---------------------------
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
output=tudui(imgs)
loss=loss_fn(output,targets)
#优化器处理模型,分3步,清零,反向传播,递进
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar(tag="train_loss",scalar_value=loss.item(),global_step=total_train_step) #每逢100画一次
#测试,模型训练时如何知道模型是否训练好,因此每次训练完一轮都需要进行一次测试,以测试数据集上的损失进行评估
#测试步骤开始
total_test_loss=0
total_accuracy=0
with torch.no_grad(): #利用现有的模型进行测试,无梯度,无调优
for data in test_dataloader:
imgs,targets=data
output=tudui(imgs)
loss=loss_fn(output,targets)
total_test_loss+=loss.item()
accuracy=(output.argmax(1)==targets).sum() #当预测=目标时计算TP
total_accuracy+=accuracy
print("整体测试集上的loss为:{}".format(total_test_loss))
ap=torch.true_divide(total_accuracy, test_data_size) #AP=TP/ALL
print("整体测试集上的正确率为:{}".format(ap))
writer.add_scalar(tag="test_loss",scalar_value=total_test_loss,global_step=total_test_step)
writer.add_scalar(tag="test_accuracuy",scalar_value=ap, global_step=total_test_step)
total_test_step+=1
#torch.save(tudui,"tuidui_{}.pth".format(i))
torch.save(tudui.state_dict(),"tudui_{}.pth".format(i)) #每一个epoch保存一次模型
print("模型已保存")
#-------------------end 添加tensorboard 以及正确率------------------------------------------
writer.close()
nn_dataset.py代码运行结果:
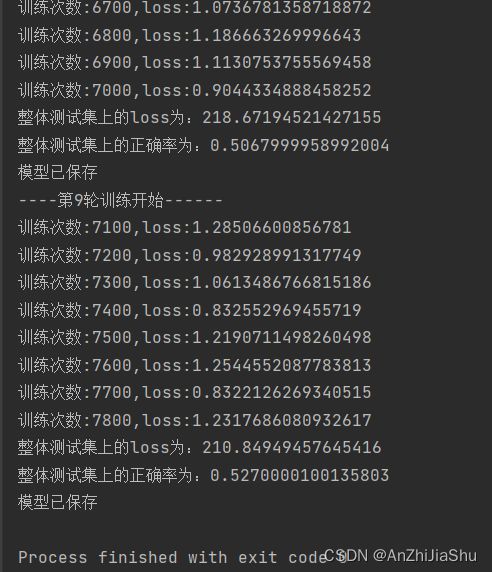
tensorboard打开日志文件查看:
tensorboard --logdir="test_network\mynetworklogs"
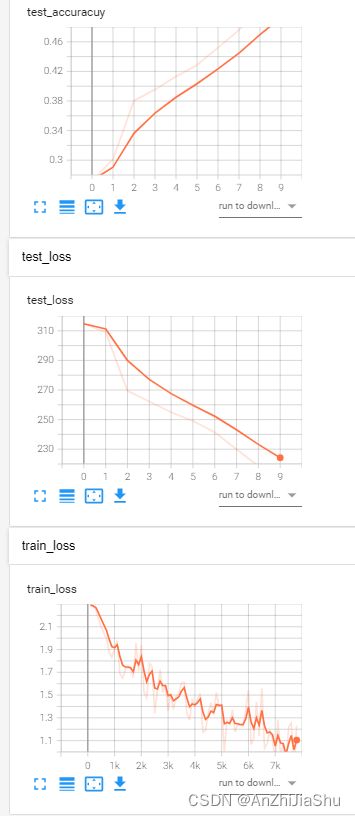
———————————————start 土堆小课堂 model.eval() 和 model.trian()作用————————————————
有时候会在训练之前加上 model.train() ,在测试之前加上 model.eval()
train(mode=True),将module设置为training mode。仅仅当模型中有Dropout和BatchNorm是才会有影响。eval():将模型设置成evaluation模式,仅仅当模型中有Dropout和BatchNorm是才会有影响。
model.eval() 和 model.trian()
有些网络层在训练状态和测试状态是不一样的,如 dropout 层,在训练时 dropout 层是有效的,但是数据尺度会缩放,为了保持数据尺度不变,所有的权重需要除以 1-p。而在测试时 dropout 层是关闭的。因此在测试时需要先调用model.eval()设置各个网络层的的training属性为 False,在训练时需要先调用model.train()设置各个网络层的的training属性为 True。
—————————————————end 土堆小课堂model.eval() 和 model.trian()作用———————————————————
2.7 GPU训练
使用GPU训练有两种方式:

2.7.1 GPU训练方式1:
找出 网络模型、数据(输入,标注)、损失函数这几个变量,直接调用他们的 .cuda(),例如 loss.cuda(),输入图片和标签都要调用,且必须是:img = img.cuda()。
示例代码:利用gup训练方式1进行训练,并计算每个epoch的训练时间,新建一个gpu_time1.py文件,写下如下代码:
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度为:{}".format(train_data_size))
print("测试数据集长度为:{}".format(test_data_size))
#加载数据
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
tudui=Tudui()
tudui=tudui.cuda()
#损失函数,交叉熵
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()
#优化器
learning_rate=1e-2 #学习率 1*10^(-2)
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#设置训练的一些参数
total_train_step=0 #记录训练的次数
total_test_step=0 #记录测试的次数
epoch=10 #记录训练的轮数
#添加tensorboard
writer=SummaryWriter("gpu_time1_logs")
for i in range(epoch):
print("----第{}轮训练开始------".format(i))
start_time = time.time() # 记录训练开始时间
#添加tensorboard 以及正确率
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()
output=tudui(imgs)
loss=loss_fn(output,targets)
#优化器处理模型,分3步,清零,反向传播,递进
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
end_time = time.time()
print("第{}轮训练时间".format(i), end_time - start_time) # 输出每个epoch的训练时间
#测试,模型训练时如何知道模型是否训练好,因此每次训练完一轮都需要进行一次测试,以测试数据集上的损失进行评估
#测试步骤开始
total_test_loss=0
total_accuracy=0
with torch.no_grad(): #利用现有的模型进行测试,无梯度,无调优
for data in test_dataloader:
imgs,targets=data
imgs = imgs.cuda()
targets = targets.cuda()
output=tudui(imgs)
loss=loss_fn(output,targets)
total_test_loss+=loss.item()
accuracy=(output.argmax(1)==targets).sum()
total_accuracy+=accuracy
print("整体测试集上的loss为:{}".format(total_test_loss))
ap=torch.true_divide(total_accuracy, test_data_size)
print("整体测试集上的正确率为:{}".format(ap))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracu",ap, total_test_step)
total_test_step+=1
torch.save(tudui.state_dict(),"tudui_gpu1.pth")
print("模型已保存")
writer.close()
代码运行结果,gpu第一次启动的时候比较慢:
2.7.2 GPU训练方式2:
找出 网络模型、数据(输入,标注)、损失函数这几个变量,调用它们的.to(device) 方法,例如 loss.to(device),图片和标签都要调用。
tensor 和module的 to()方法的区别是:tensor.to()执行的不是 inplace 操作,因此需要赋值;module.to()执行的是 inplace 操作。
其中:
device=torch.device("cpu") '''CPU训练'''
device=torch.device("cuda") '''GPU训练'''
device=torch.device("cuda:0") '''指定一个显卡'''
device=torch.device("cuda:1") '''若电脑上多张显卡,想指定第二张显卡'''
示例代码:利用gup训练方式 2 进行训练,并计算每个epoch的训练时间,新建一个gpu_time2.py文件,写下如下代码:
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
device=torch.device("cuda") #控制在GPU上进行训练
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度为:{}".format(train_data_size))
print("测试数据集长度为:{}".format(test_data_size))
#加载数据
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
tudui=Tudui()
tudui=tudui.to(device)
#损失函数,交叉熵
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.to(device)
#优化器
learning_rate=1e-2 #学习率 1*10^(-2)
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#设置训练的一些参数
total_train_step=0 #记录训练的次数
total_test_step=0 #记录测试的次数
epoch=10 #记录训练的轮数
#添加tensorboard
writer=SummaryWriter("gpu_time2_logs")
start_time=time.time() #训练开始时间
for i in range(epoch):
print("----第{}轮训练开始------".format(i))
#添加tensorboard 以及正确率
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
imgs=imgs.to(device) #将图片放在gpu上
targets=targets.to(device) #将标签放在gpu上
output=tudui(imgs)
loss=loss_fn(output,targets)
#优化器处理模型,分3步,清零,反向传播,递进
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step+=1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
end_time = time.time()
print("第{}轮训练时间".format(i), end_time - start_time) # 输出每个epoch的训练时间
#测试,模型训练时如何知道模型是否训练好,因此每次训练完一轮都需要进行一次测试,以测试数据集上的损失进行评估
#测试步骤开始
total_test_loss=0
total_accuracy=0
with torch.no_grad(): #利用现有的模型进行测试,无梯度,无调优
for data in test_dataloader:
imgs,targets=data
imgs = imgs.to(device)
targets = targets.to(device)
output=tudui(imgs)
loss=loss_fn(output,targets)
total_test_loss+=loss.item()
accuracy=(output.argmax(1)==targets).sum()
total_accuracy+=accuracy
print("整体测试集上的loss为:{}".format(total_test_loss))
print("整体测试集上的正确率为:{}".format(torch.true_divide(total_accuracy, test_data_size)))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracu",torch.true_divide(total_accuracy, test_data_size), total_test_step)
total_test_step+=1
torch.save(tudui.state_dict(),"tudui_gpu2.pth")
print("模型已保存")
writer.close()
2.7.3 GPU训练note:
在用gpu训练时 模型和loss可以直接model.cuda()或model.to(device) 不必要 model=model.to(device),但是数据必须重新赋值:img=img.to(device) target=target.to(device)
2.8 完整的模型验证套路
完整的模型验证套路-利用已经训练好的模型,然后给它提供输入。
-
准备一张测试的图片“cat.png”,将其放在images文件夹下:

-
新建一个train_model_test.py文件,并输入以下代码:
import torch
import torchvision
from PIL import Image
from test_network.nn_network import *
img_path="../images/cat.png"
image=Image.open(img_path) #Image.open是PIL数据类型的
image=image.convert('RGB')#png图像有四个通道
#利用torchvision.transforms.Compose集合图片的转换
# 先通过Resize将图片转换为32乘32大小的tensor数据类型
#再通过ToTensor将图片转换为Tentor数据类型
transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image=transform(image) #转换图片
image=image.cuda() #将数据放在cuda上
#用方式2保存的模型,因此用方式2加载网络模型,先实例化一个模型,再进行加载
model=Tudui().cuda()
#在gpu上训练的模型需要加,map_location=torch.device("cpu")
model.load_state_dict(torch.load("tudui_end.pth"))
print(model)
image=torch.reshape(image,(1,3,32,32)) #将图片reshape,相当于batchsize=1
#------------进行验证------------------
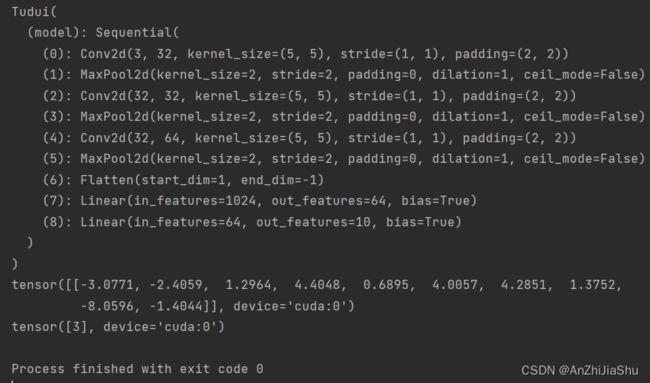
model.eval()
with torch.no_grad():
output=model(image)
print(output)
print(output.argmax(1))#tensor([3], device='cuda:0') tensor[3]对应的是cat
运行结果: