自然语言处理
文章目录
- 一、基本方法
-
- TF-IDF
- 二、Textcnn:
- 三、FastText:
- 三、Word2vec
-
- skipgram
- cbow
- Word2vec的负采样:
- 四、循环神经网络
-
- 1、RNN的梯度爆炸
- 2.LSTM通过门机制来解决梯度爆炸问题
- 3.常见使用方法:
- 4.双向 RNN
- 5.多层 RNN
- 6.Simple-RNN
- 四.LSTM
-
- 五、命名实体识别
- 六、注意力机制:
- 七、自注意力机制:
- 八、Transformer
- 九、BERT
一、基本方法
TF-IDF
- 原理
TF指的是某一个给定的词语在该文件中出现的次数,IDF是一个词语普遍重要性的度量。 - Idf 的为什么要算log
首先idf是一个单调增的变量取对数不会对他有影响,同时他的值通常过大,为了缩小数据的绝对值方便计算(某些公式取对数可以将惩罚计算简化为加法计算)
二、Textcnn:
第一层为输入层。输入层是一个n*k的矩阵,其中n为一个句子中的单词数, k 是每个词对应的词向量的维度。这里为了使向量长度一致对原句子进行了padding操作。
词向量可以是预先在其他语料库中训练好的,也可以作为未知的参数由网络训练得到
预先训练的词嵌入可以利用其他语料库得到更多的先验知识,
当前网络训练的词向量能够更好地抓住与当前任务相关联的特征。
第二层为卷积层。
输入层的"image"是一个由词向量拼成的词矩阵,且卷积核的宽和该词矩阵的宽相同,该宽度即为词向量大小,且卷积核只会在高度方向移动。因此,每次卷积核滑动过的位置都是完整的单词,不会将几个单词的一部分"vector"进行卷积。
卷积核和word embedding的宽度一致,一个卷积核对于一个sentence,卷积后得到的结果是一个vector,shape=(sentence_len - filter_window_size + 1, 1),在经过max-pooling操作后得到的就是一个Scalar。使用多个filter_window_size(不同的kernel可以获取不同范围内词的关系(纵向的差异信息))每个filter_window_size又有num_filters(2)个卷积核(每个filter都有自己的关注点,这样多个卷积核就能学习到多个不同的信息(从同一个窗口学习相互之间互补的特征))。
第三层为池化层
Max池化,即为从每个滑动窗口产生的特征向量中筛选出一个最大的特征,然后将这些特征拼接起来构成向量表示。将不同长度的句子通过池化得到一个定长的向量表示。
Mlp:
使用多层感知机输出分类结果进行二分类或多分类

三、FastText:
功能:训练词向量+文本分类 不适合中文
结构:用文本分类训练模型:类似cbow。文章/句子的embedding用词的求和均值表示。 输出加softmax作为文章的label (cbow为中心词的概率)

输入词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。

输入 词/trigram的初始向量
隐藏 对所有的输入向量进行加和求平均
输出 分层级的softmax
特点:Hierarchical Softmax + N-gram
ngram:由于fasttext隐层是通过简单的求和取平均得到的丢失了词顺序的信息。增加了N-gram的特征。通过把N-gram当成一个词,也用embedding向量来表示,在计算隐层时,把N-gram的embedding向量也加进去求和取平均。
增加了子词特性。通过把每个word,拆成若干个char-level的ngram表示丰富了词表示的层次,学习到当两个词有相同的词缀时语义的相似性。但对于中文来说,这种方法可能会有些问题。如“原来”和”原则”,虽有相同前缀,但意义相差甚远。
Hierarchical Softmax :在类别很多时标准的softmax非常耗时,提出了分层softmax。将时间复杂度从N降到logN 。通过Huffman编码,构造了一颗庞大的Huffman树,给非叶子结点赋予向量。计算目标词w的概率,含义:指从root结点开始随机走,走到目标词w的概率。
在使用负采样的skipgram基础上将每个中心词看作字词的集合,用子词向量表示这个词
可以区分字词和整词 (where 中的 her 和 her)
叠加词向量 用词袋模型 得到文档向量
用文档向量 进行softmax
三、Word2vec
得到节点的embedding 计算 embedding之间的余弦相似度 得到topn 进行推荐。
可分为CBOW 和Skip-gram两大类型

skipgram
- 输入层:中心单词的onehot.1*v (节点数=v)
- 中心单词的onehot乘以中心词向量矩阵Wv*n.
- 所得的向量作为隐层向量1*n
- 乘以上下文词向量矩阵W’n*v
- 得到输出向量1*v激活函数处理得到概率分布
- 设计损失函数(根据与窗口中上下文词的误差更新两个权重矩阵)

cbow
- 输入层:上下文单词的onehot.1*v (节点数=v)
- 所有onehot分别乘以共享的输入权重矩阵Wv*n.
- 所得的向量相加求平均作为隐层向量1*n
- 乘以输出权重矩阵W’n*v
- 得到输出向量1*v激活函数处理得到概率分布
- 设计损失函数(根据与中心词的误差更新两个权重矩阵)
Word2vec的负采样:
- 作用
不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一部分的权重,这样就降低梯度下降过程中的计算量。加速了模型计算保证了模型训练的效果,(其一模型每次只需要更新采样的词的权重,不用更新所有的权重。其二中心词其实只跟它周围的词有关系,位置离着很远的词没有关系,也没必要同时训练更新。) - 操作
随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。同时对我们的positive word进行权重更新。
四、循环神经网络
RNN 可以将任意长度的序列编码为固定尺寸的向量,同时可以捕获序列中的结构特性。
假设我们的时间序列只有三段, 神经元没有激活函数,则RNN最简单的前向传播过程如下:


网络训练的任务就是设定 R 和 O 使得状态能表达我们关注的任务中的有用信息。
1、RNN的梯度爆炸
使用随机梯度下降法训练RNN其实就是对 W、b 求偏导,并不断调整它们以使Loss尽可能达到最小的过程。
如:对t3时刻的参数求偏导

对Wx求偏导的公式![]()
加上激活函数![]()
然而大部分情况下tanh的导数是小于1的,因为很少情况下会出现,![]()
如果 Ws 也是一个大于0小于1的值,则当t很大时![]()
就会趋近于0。同理当Ws很大时![]()
就会趋近于无穷,
RNN产生梯度消失与梯度爆炸的原因就在于![]()
。
2.LSTM通过门机制来解决梯度爆炸问题


 使函数值基本上不是0就是1。
使函数值基本上不是0就是1。
3.常见使用方法:
Acceptor直接基于输出向量 y_n 进行预测,RNN 被当成一个 acceptor 进行训练。
Encoder也是基于输出向量 y_n 进行预测,但预测模块不仅利用 y_n 还利用其它特征。RNN 主要用处就是作为可训练的灵活的特征提取器使用,可以替换部分更传统的特征提取器。
Transducer 对每个输入产生一个输出,从而为每个输出产生一个局部损失,最后结合所有局部损失构成展开序列的损失,
4.双向 RNN
允许关注任意远的过去序列和未来序列,从而放宽了固定尺寸窗口的假设。在每个序列位置 i 设定两个不同的状态 s_if 和s_ib 来实现上述想法。前向状态 s_if 基于 x_{1:i},后向状态s_ib 基于 x_{n:i},这两个状态分别由不同的 RNN 产生。输出 y_i 即两个输出 y_if = O(s_if )和 y_ib=O(s_ib) 的 串联。即biRNN 对第 i 个词的编码实际是两个 RNN 结果的串联,一个从序列的开头读,一个从序列的末尾读。
双向RNN非常适用于标注任务

5.多层 RNN
RNN 可以按层堆叠形成一个网,这种堆叠结构通常称为 deep RNN

6.Simple-RNN
当R 为加和函数,O 为恒等映射时,RNN == CBOW,丧失了顺序信息。

最简单的对顺序信息敏感的 RNN 结构为 Simple-RNN

S-RNN比 CBOW 复杂了点,主要区别在于非线性激活函数 g,使得网络能捕获顺序信息。
由于梯度消失问题,S-RNN 很难高效训练。在反向传播过程中,前面环节的误差信号/梯度小时的很快,无法到达更前面的输入信号,使得 S-RNN 难以捕获广范围的依赖。LSTM 和 GRU 加入了门限结构就是来解决这个缺陷。
四.LSTM
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。
门是一种让信息选择式通过的方法。包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。LSTM拥有三个门,来保护和控制细胞状态。

-
忘记门:决定我们要从细胞状态中丢弃什么信息。靠sigmoid函数决定根据输入和上一时刻的输出来决定当前细胞状态是否有需要被遗忘的内容。(如果之前细胞状态中有主语,而输入中又有了主语,那么原来存在的主语就应该被遗忘)
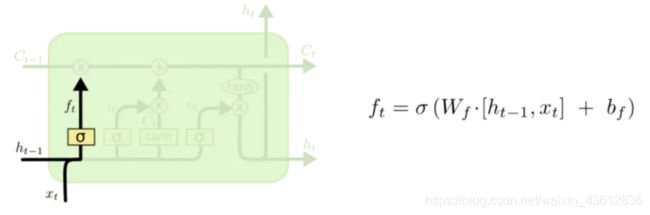
-
输入门:决定我们要更新什么值(哪些值要被加入)
**靠sigmoid函数决定将新进来的主语中 的哪些内容记住哪些内容加入到细胞状态。**但需要被记住的内容并不是直接加入。concatenate的输入和上一时刻的输出,还要经过tanh(和RNN保持一致)。


- 输出门:根据当前的状态和现在的输入,输出应该是什么。通过sigmoid函数做门,对细胞状态状态做tanh后的结果 过滤,得到最终的预测结果输出。

五、命名实体识别
一个数据集,其中有两个实体类型,Person和Organization。此时有5个实体标签:B-Person;I- Person;B-Organization;I-Organization;O
x是一个包含5个单词的句子,w0,w1,w2,w3,w4。[w0,w1]是一个Person实体,[w3]是一个Organization实体,其他都是O
将句子中的每个单词表示为一个向量,其中包括单词的嵌入和字符的嵌入。字符嵌入是随机初始化的。词嵌入从一个预先训练的词嵌入文件导入(w2v)的。所有的嵌入将在训练过程中进行微调。
-
BiLSTM+CRF
BiLSTM-CRF模型的输入是这些嵌入,输出是句子中的单词的预测标签

-
CRF
作用:从训练数据中学到约束
原理: BiLSTM输出是每个标签的分数。如,对于w0, BiLSTM节点的输出为1.5 (B-Person)、0.9 (I-Person)、0.1 (B-Organization)、0.08 (I-Organization)和0.05 (O),这些分数将作为CRF层的输入.
BiLSTM层预测的所有分数输入CRF层。在CRF层中,选择预测得分最高的标签序列
约束条件:
句子中第一个单词的标签应该以“B-”或“O”开头,而不是“I-”
“B-label1 I-label2 I-label3 I-…”,在这个模式中,label1、label2、label3…应该是相同的命名实体标签。例如,“B-Person I-Person”是有效的,但是“B-Person I-Organization”是无效的。
“O I-label”无效。一个命名实体的第一个标签应该以“B-”而不是“I-”开头,换句话说,有效的模式应该是“O B-label”
关键概念:
Emission得分:BiLSTM输出的word对应不同lable的得分
Transition得分(得分矩阵可随机初始化,在训练过程中学习):

损失函数:损失函数由真实路径得分和所有可能路径的总得分组成


-
HMM
解决的问题:
1)基于序列的,比如时间序列,或者状态序列。
2)问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列



-
BiLSTM
前向的LSTM与后向的LSTM结合成BiLSTM ,最后将前向和后向的隐向量进行拼接得到{[hl0, hr2], [hl1, hr1], [hl2,hr0 ]},即{h0,h1,h2 }。

对于情感分类任务来说,我们采用的句子的表示往往是[hL2,hR2 ]。因为其包含了前向与后向的所有信息,

六、注意力机制:
Attention用于seq2seq模型的优化。
- 目标:从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略不重要的信息。
- 原理:
通过计算query与每一组key的相似性,得到每个key的权重系数,再通过对value加权求和,得到最终attention数值。
通过计算代表了信息的重要性的权重,并通过Normalization进行归一化 对值进行加权平均 计算output。1根据Query和Key计算权重系数,2根据权重系数对Value进行加权求和。
七、自注意力机制:
用注意力机制捕捉数据上下文相关性,不需要循环神经网络,解决循环神经网络下一步的计算依赖上一步的状态,前后计算有相互依赖关系 无法并行,不方便优化的问题。
- 原理
计算涉及序列中某一个输入相对于其他所有输入之间的联系。
自问自答:Query Key Value
Q K : 根据Q获取K的分数 作为 V 的权重得到输出结果
使用multihead-attentioon 捕获多种序列之间的关联 (单个attention只能捕获一种序列之间的关联,multihead捕获不同距离单词之间的关系)类似多个卷积核 - 优点
1.参数少:相比于 CNN、RNN ,其复杂度更小,参数也更少。
2.速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。
3.涉及矩阵乘法更简单更方便优化
4.效果好
八、Transformer
-
seq2seq的发展过程
1、将self-attention用于seq2seq问题的解决 输入输出均为sequence 之前会使最开始用RNN来解决这个问题,存在无法并行化的问题
2、提出用CNN解决并行化的问题,每个CNN只考虑一定范围内的内容 只有叠加很多层才能进行考虑整个句子的信息
3、提出使用self-attention解决这个问题,能够同时考虑整个范围的内容并实现并行化【attention is all you need】 -
构成
1)Transformer由self-Attenion和前馈神经网络组成。基于Encoder-Decoder的结构,encoder的输出会作为decoder的输入,
2)Encoder的每一层有两个操作,分别是Self-Attention和Feed Forward;
3)Decoder的每一层有三个操作,分别是Self-Attention、Encoder-Decoder Attention以及Feed Forward操作。

-
Encoder
1、输入
Embedding+位置编码
2、Self-attention:
1)将输入单词x1转化成嵌入向量a1
2)将每一个嵌入向量*wq *wk *wv 得到 q,k,v 三个向量
3)为每个向量计算一个score,每个q1对每一个ki做attention score11 = q1k1 score12 = q1k2 score13 = q1k3 …
4)为了梯度的稳定,在softmax前还需要进行一次scale(向量的点积结果会很大,会将softmax的导数限制到很小的区域,导致几乎全部的概率分布都分配给了最大值对应的标签,导致梯度消失为0,造成参数更新困难,scaled会缓解这种现象)即除以key向量维度的开平方sqrt(dk)=8 (设向量 q和k的各个分量是互相独立的随机变量,均值是0,方差是1,那么点积q.k的均值是0,方差是 dk,通过除以key向量维度的开平方sqrt(dk)将方差控制为1,也就有效地控制了前面提到的梯度消失的问题);
5)对α1i施以softmax激活函数,使得最后α1i和为1;
6)softmax点乘Value值 v ,得到加权的当前输入向量的评分 b1;
7)相加之后得到当前词的最终的输出结果:self-attention层的输出

转换成矩阵形式:
3、Multi-head
进行多次矩阵运算并将最后的结果拼起来乘上一个权重矩阵
4、Add & Norm
Add:缓解梯度消失现象 Norm:归一化
5、Feed Forward
两层全连接
6、位置编码
 其中,PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;dmodel表示词向量的维度;i表示词向量的位置。
其中,PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;dmodel表示词向量的维度;i表示词向量的位置。
通过在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此来填满整个PE矩阵,然后加到input embedding中去
7、Padding
为了保证原始数据的输入长度固定,设定一个统一长度N(文章中句子的最大长度)。在较短的序列后面填充0到长度为N。对于补零的数据来说,我们的attention机制不应该把注意力放在这些位置上,所以我们需要把这些位置的值加上一个非常大的负数(负无穷),这样经过softmax后,这些位置的权重就会接近0 -
Decoder
1、输入:为encoder的输出 + i-1位置decoder的输出输出:对应i位置的输出词的概率分布。
2、Self-attention 和 Encoder-Decoder Attention 其实都是Multi-Head Attention,取名不同是因为self-attention 的 key,values,query是相同的向量经过线性变换得到的,Encoder-Decoder Attention 的key,value来自Encoder,query(训练集正确结果的输入)来自Decoder。
3、加入了Encoder-Decoder Attention在encoder-decoder attention中, Q 来自于解码器的上一个输出,K 和 V 则来自于与编码器的输出
九、BERT
-
损失函数
分别使用负对数似然函数的方法计算单词级别的损失函数和句子级别的损失函数
Mask-LM: 的单词级别分类任务,随机遮盖或替换一句话里任意的字,让模型通过上下文预测被遮盖或被替换的部分。
所用的损失函数叫做负对数似然函数(且是最小化,等价于最大化对数似然函数)
Next-Sentence-Prediction句子级别的分类任务:通过在两个句子中加一些特殊的token,开始cls 中间和末尾sep
所用的损失函数为一个分类问题的损失函数 -
优点
通过这两个任务的联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句子级别的语义信息。