CTR预估 论文精读(十二)--Deep Session Interest Network(DSIN)
We observe that user behaviors are highly homogeneous in each session, and heterogeneous cross sessions. Based on this observation, we propose a novel CTR model named Deep Session Interest Network (DSIN) that leverages users’ multiple historical sessions in their behavior sequences. We first use self-attention mechanism with bias encoding to extract users’ interests in each session. Then we apply Bi-LSTM to model how users’ interests evolve and interact among sessions. Finally, we employ the local activation unit to adaptively learn the influences of various session interests on the target item.
1. 创新点
- 提出 session 概念,将用户点击 sequence 按照时间间隔分割成一段段 session,认为同一段 session 中的用户行为 item 高度相似(论文中取行为 item 点击时间间隔超过30分钟作为划分 session 的判定)——对应 Session Division Layer;
- 使用 Transformer 中的 multi-head self-attention 模块,结合了 bias encoding 抽取 session 内部的行为之间关系,来进一步提取 session interest;——对应Session Interest Extractor Layer;
- 使用 Bi-LSTM 捕获不同 session 之间的序列关系(interaction and evolution of users’ varying historical session interests);——对应 Session Interest Interacting Layer;
- 使用 Target Attention (对应 Local Activation Unit )分别从 Session Interest Extractor Layer 和 Session Interest Interacting Layer 中取出与当前候选推荐(论文中使用 target item + user profile + item profile 做为 Target,不同于以往只使用 target item 或者 target item + context feature)相关的兴趣特征;
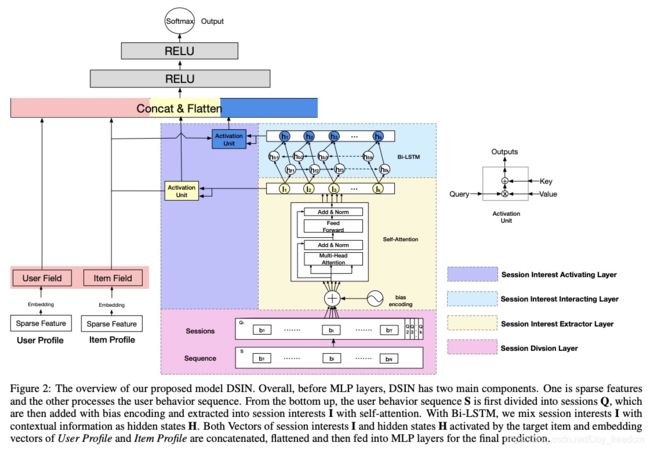
阿里目前的主流序列模型中:self-attention + target attention 已经是标配;
Session: A session is a list of interactions (user behaviors) that occur within a given time frame.
Self-attention: Self-attention can capture the inner interaction/correlation of session behaviors and then extract users’ interests of each session.
2. 理论细节
2.1 Session Division Layer
2.1.1session 划分原因:
从sequence的角度我们虽然能看到 interest 的变化过程,但是却忽视了这样两个事实:
-
同一个 session 内的用户行为高度同构
-
不同 sessions 间的 用户行为异构

用户行为中,相同 session 内 item 高度相似,不同 session 间 item 多种多样。基于此,将用户 sequence 划分为不同的 session 段;
2.1.2 session的划分规则
根据用户的点击时间:前一个 session 最后一个 behavior 到后一个 session 第一个 behavior 的时间差大于等于30min。
将用户 Sequence 划分为 Sessions,其中其 k 个 session 如下:
Q k = [ b 1 ; … ; b i ; … ; b T ] ∈ R T × d ~ model \mathbf{Q}_{k}=\left[\mathbf{b}_{1} ; \ldots ; \mathbf{b}_{i} ; \ldots ; \mathbf{b}_{T}\right] \in \mathbb{R}^{T \times \tilde{d}_{\text {model}}} Qk=[b1;…;bi;…;bT]∈RT×d~model
T 是每个 session 中 behaviors 数目; d ~ model \tilde{d}_{\text {model}} d~model 是 embedding 后每个 behavior 的 size; b i b_i bi 是 session 中第 i i i 个behavior.
2.2 Session Interest Extractor Layer
就像之前提到的那样,即使同个 session 中的行为是高度同构的,但是还是会有一些随意的一些行为会使得 session 的兴趣表示变得不准确:比如我想买衣服,看着看着衣服,但不小心误触到其他推送内容,但那和我的真实想去点击的东西无关。
所以为了对同一 session 中多个行为的关系进行建模和减轻那些不相关行为的影响。 DSIN 对每个 session 都使用 Transformer 中的 multi-head self-attention 模块来抽取用户session的兴趣特征。
Bias Encoding:
将 session 依据时间排序,得到 session 之间的序列关系,使用 bias encoding
利用 self-attention 建模同一 session 内的 item 相关关系,利用 Bi-LSTM 建模 session 之间的序列关系;
使用 self-attention 需要进行位置编码(positional encoding),同时,进一步扩展到session 之间的序列关系,作者提出 bias encoding 来整合 session 内 item 位置编码和 session 间位置编码;
提出 Bias Encoding:
B E ( k , t , c ) = w k K + w t T + w c C \mathbf{B E}_{(k, t, c)}=\mathbf{w}_{k}^{K}+\mathbf{w}_{t}^{T}+\mathbf{w}_{c}^{C} BE(k,t,c)=wkK+wtT+wcC
其中 w k K ∈ R K \mathbf{w}^{K}_{k} \in \mathbb{R}^{K} wkK∈RK 为 session 的 bias vector,第二项 w t T ∈ R T \mathbf{w}^{T}_{t} \in \mathbb{R}^{T} wtT∈RT 为 behavior 的 bias vector,第三项 w c C ∈ R d m o d e l \mathbf{w}^{C}_{c} \in \mathbb{R}^{d_{model}} wcC∈Rdmodel 为用户行为 embedding 中 unit 的 bias vector;
加上用户 bias encoding 之后,用户的行为 session Q 更新如下:
Q = Q + B E Q = Q + BE Q=Q+BE
然后我们将经过 Bias Encoding 处理的输入传入 Multi-head Self Attention 结构里来提取 session 内部 interest;
Multi-head Self Attention:
这里面 Multi-head Self Attention 其实就是多个 self-attention 结构的结合,每个 head 学习到在不同表示空间中的特征,如下图所示,两个 head 学习到的 Attention 侧重点可能略有不同,这样给了模型更大的容量。
因为用户的点击行为会受各种因素影响,比如颜色、款式和价格,那么这些因素就是作为所谓的 head。所以第一步就是将 session Q 根据 H 个 head 划分为 H 份。
即: Q k = [ Q k 1 ; … ; Q k h ; … ; Q k H ] \mathbf{Q}_{k}=\left[\mathbf{Q}_{k 1} ; \ldots ; \mathbf{Q}_{k h} ; \ldots ; \mathbf{Q}_{k H}\right] Qk=[Qk1;…;Qkh;…;QkH]
其中 Q k h ∈ R T × d h \mathbf{Q}_{k h} \in \mathbb{R}^{T \times d_{h}} Qkh∈RT×dh 为 Q k Q_k Qk 的第 h h h 个头, H H H 是头的数量, d h = 1 h d m o d e l d_h = \frac{1}{h}d_{model} dh=h1dmodel;
在对 Q Q Q 划分完后就要对每个 head 去计算,计算如下:
head h = Attention ( Q k h W Q , Q k h W K , Q k h W V ) = softmax ( Q k h W Q W K T Q k h T d model ) Q k h W V \begin{aligned} \text { head }_{h} &=\text { Attention }\left(\mathbf{Q}_{k h} \mathbf{W}^{Q}, \mathbf{Q}_{k h} \mathbf{W}^{K}, \mathbf{Q}_{k h} \mathbf{W}^{V}\right) \\ &=\operatorname{softmax}\left(\frac{\mathbf{Q}_{k h} \mathbf{W}^{Q} \mathbf{W}^{K^{T}} \mathbf{Q}_{k h}^{T}}{\sqrt{d_{\text {model}}}}\right) \mathbf{Q}_{k h} \mathbf{W}^{V} \end{aligned} head h= Attention (QkhWQ,QkhWK,QkhWV)=softmax(dmodelQkhWQWKTQkhT)QkhWV
其中 W Q , W K , W V W^{Q}, W^{K}, W^{V} WQ,WK,WV 进行矩阵线性变换;
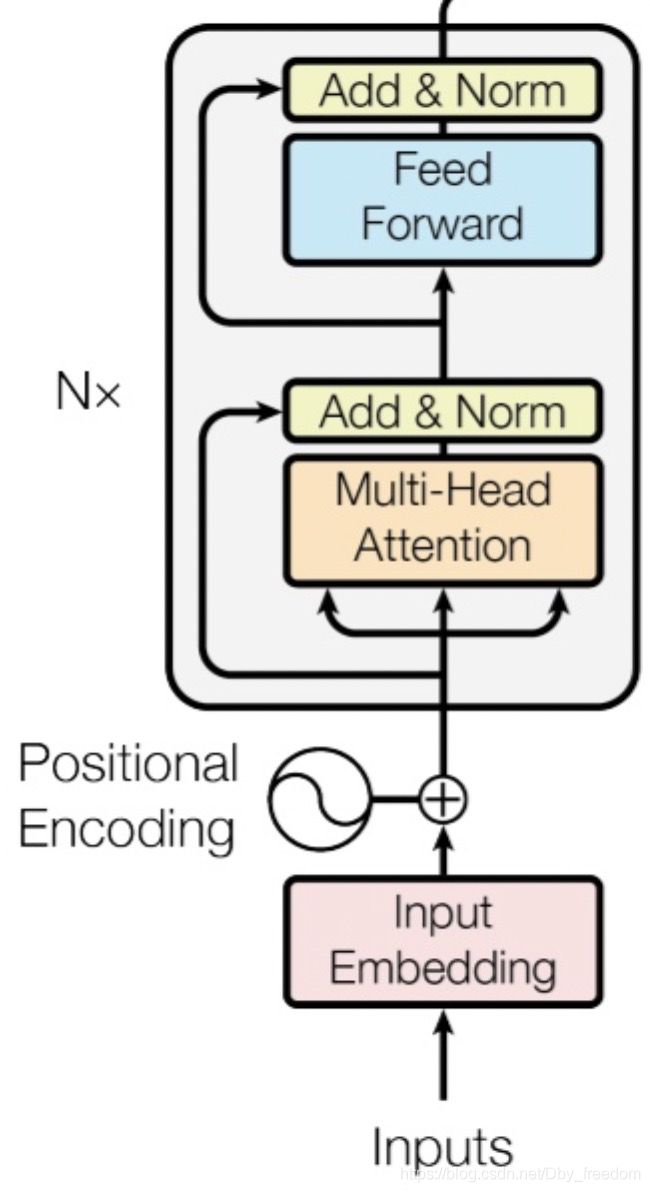
上图为原始 self-attention 编码器结构,其中,在 multi-head 下面有三个箭头其实是比较细节的, 因为对于 self-attention 来讲, 这三个输入量分别为: Q ( Q u e r y ) , K ( K e y ) , V ( V a l u e ) Q(Query), K(Key), V(Value) Q(Query),K(Key),V(Value) 三个矩阵。
他们均来自同一输入,首先我们要计算 Q 与 K 之间的点乘, 然后为了防止其结果过大, 会除以一个尺度标度 d k , \sqrt{d_{k}}, dk, 其中 d k d_{k} dk 为一个 query 和 key 向量的维度。
再利用Softmax操 作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表 示。该操作可以表示为 Attention ( Q , K , V ) = softmax ( Q K T d k ) V (Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V (Q,K,V)=softmax(dkQKT)V
现在再看DSIN的公式是不是会简单些? 稍有不同的是加入了 W Q , W K , W V W^{Q}, W^{K}, W^{V} WQ,WK,WV 进行矩阵线性变换;
将各个 head 结果进行 concat,同之前的输入一起放入 add&norm 后放入 FFN,然后再做 add&norm, 最后得到 session 内部各个 item 对应 interest embedding。
这里的 add&norm 作用应该也和前一个一样, W o W^{o} Wo 同样是线性变换矩阵;
I k Q = FFN ( Concat ( head 1 , … , head H ) W O ) \mathbf{I}_{k}^{Q}=\text { FFN }\left(\text { Concat }\left(\text { head }_{1}, \ldots, \text { head }_{H}\right) \mathbf{W}^{O}\right) IkQ= FFN ( Concat ( head 1,…, head H)WO)
将 session 中各 item embedding 进行 average pooling,得到 session 对应的 embedding 表征,如下;
I k = Avg ( I k Q ) \mathbf{I}_{k}=\operatorname{Avg}\left(\mathbf{I}_{k}^{Q}\right) Ik=Avg(IkQ)
得到用户第 k 个 session 的 embedding 表征;
注:Note that weights are shared in the self-attention mechanism of different sessions.
2.3 Session Interest Interacting Layer
建模用户的 session 动态变化可以丰富 session 的表征,利用 Bi-LSTM 提取 session 间的序列关系;
Bi-LSTM 计算公式如下:
i t = σ ( W x i I t + W h i h t − 1 + W c i c t − 1 + b i ) f t = σ ( W x f I t + W h f h t − 1 + W c f c t − 1 + b f ) c t = f t c t − 1 + i t tanh ( W x c I t + W h c h t − 1 + b c ) o t = σ ( W x o I t + W h o h t − 1 + W c o c t + b o ) h t = o t tanh ( c t ) \begin{aligned} \mathbf{i}_{t} &=\sigma\left(\mathbf{W}_{x i} \mathbf{I}_{t}+\mathbf{W}_{h i} \mathbf{h}_{t-1}+\mathbf{W}_{c i} \mathbf{c}_{t-1}+\mathbf{b}_{i}\right) \\ \mathbf{f}_{t} &=\sigma\left(\mathbf{W}_{x f} \mathbf{I}_{t}+\mathbf{W}_{h f} \mathbf{h}_{t-1}+\mathbf{W}_{c f} \mathbf{c}_{t-1}+\mathbf{b}_{f}\right) \\ \mathbf{c}_{t} &=\mathbf{f}_{t} \mathbf{c}_{t-1}+\mathbf{i}_{t} \tanh \left(\mathbf{W}_{x c} \mathbf{I}_{t}+\mathbf{W}_{h c} \mathbf{h}_{t-1}+\mathbf{b}_{c}\right) \\ \mathbf{o}_{t} &=\sigma\left(\mathbf{W}_{x o} \mathbf{I}_{t}+\mathbf{W}_{h o} \mathbf{h}_{t-1}+\mathbf{W}_{c o} \mathbf{c}_{t}+\mathbf{b}_{o}\right) \\ \mathbf{h}_{t} &=\mathbf{o}_{t} \tanh \left(\mathbf{c}_{t}\right) \end{aligned} itftctotht=σ(WxiIt+Whiht−1+Wcict−1+bi)=σ(WxfIt+Whfht−1+Wcfct−1+bf)=ftct−1+ittanh(WxcIt+Whcht−1+bc)=σ(WxoIt+Whoht−1+Wcoct+bo)=ottanh(ct)
其中 i t , f t , o t i_t, f_t, o_t it,ft,ot 分别表示更新门、遗忘门、输出门;其中 cell vectors 具有与 i t i_t it 相同的 size;
因为是 Bi-LSTM,所以存在前向、后向 RNN 结构,下式两项 h f t → , h b t ← \overrightarrow{\mathbf{h}_{f t}}, \overleftarrow{\mathbf{h}_{b t}} hft,hbt分别是前向传播和反向传播对应的 t t t 时刻的hidden state, 一共有 k k k 个 H t H_t Ht,分别代表了前后memory的某个 session 的 interest 序列特征。
H t = h f t → ⊕ h b t ← \mathbf{H}_{t}=\overrightarrow{\mathbf{h}_{f t}} \oplus \overleftarrow{\mathbf{h}_{b t}} Ht=hft⊕hbt
式中 ⊕ \oplus ⊕ 表示 concatenation;
那么,到这为止,模型已经同时捕获到了session 内部和 session 之间的顺序关系。
2.4 Local Activation Unit
采用了 DIN 的 Target Attention 思路,很主流的一种做法,结合序列特征,与 DIEN(AIGRU) 的差别主要是多了 sequence 中 session 的划分;
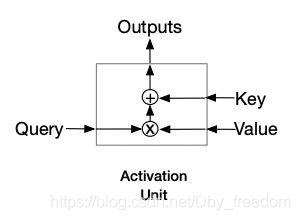
- 左边是带推荐的 item embedding,右边是输入的是被 embedding 的商品信息,右边两个都是用户的 interest 信息,然后给出一个输出。
- 它的作用类似一个开关,控制了这类特征是否放入特征向量以及放入时权重的大小。
- 那这个开关由谁控制呢?它是由被预测 item 跟 session interest 的关系决定的。也就是说,在预测用户 u u u 是否喜欢商品 i i i 这件事上,我们只把跟商品 i i i 有关的特征考虑进来,其他特征会完全不考虑或者权重很小。
- 这是比较好理解的,用户的 session interest 与 target item 关系越密切,对用户会去点击 target item 的影响越大,因此这样的 session interest 应该赋予更大的权重。
对 Session Interest 内部特征依据 Target item 做相关性提取;
比较好理解的,用户的 session interest 与 target item 关系越密切,对用户会去点击 target item 的影响越大,因此这样的 session interest 应该赋予更大的权重。
a k I = exp ( I k W I X I ) ) ∑ k K exp ( I k W I X I ) U I = ∑ k a k I I k \begin{aligned} a_{k}^{I} &=\frac{\left.\exp \left(\mathbf{I}_{k} \mathbf{W}^{I} \mathbf{X}^{I}\right)\right)}{\sum_{k}^{K} \exp \left(\mathbf{I}_{k} \mathbf{W}^{I} \mathbf{X}^{I}\right)} \\ \mathbf{U}^{I} &=\sum_{k} a_{k}^{I} \mathbf{I}_{k} \end{aligned} akIUI=∑kKexp(IkWIXI)exp(IkWIXI))=k∑akIIk
对 Session Interest 序列特征依据 Target item 做相关性提取;
a k H = exp ( H k W H X I ) ) ∑ k K exp ( H k W H X I ) U H = ∑ k a k H H k \begin{aligned} a_{k}^{H} &=\frac{\left.\exp \left(\mathbf{H}_{k} \mathbf{W}^{H} \mathbf{X}^{I}\right)\right)}{\sum_{k}^{K} \exp \left(\mathbf{H}_{k} \mathbf{W}^{H} \mathbf{X}^{I}\right)} \\ \mathbf{U}^{H} &=\sum_{k} a_{k}^{H} \mathbf{H}_{k} \end{aligned} akHUH=∑kKexp(HkWHXI)exp(HkWHXI))=k∑akHHk
最后,把用户特征向量、待推荐物品向量、会话兴趣加权向量 U I U^I UI、带上下文信息的会话兴趣加权向量 U H U^H UH 进行横向拼接,输入到全连接层中,得到输出;
3. 总结
总体来讲,DSIN 在 DIEN 和 DIN 的基础上,将序列特征进一步做了细化处理,将 sequence 切割成 session 段,一种很好的业务同理论相结合的技巧。
使用 self-attention 提取 session 特征,使用 Bi-LSTM 提取 session 之间的序列特征,使用 Target Attention 分别从 session 特征和 session 序列特征中提取与候选 item 相关的有用信息;同时,在提取 session 特征过程中用到的 BE(Bias Encoding) 也是一种很实用的技巧。
综合来看,个人感觉本文相较于 DIN 略工于技,相较于 DIEN 更偏业务考量,是一篇非常不错的CTR精排论文!
值得注意的是,Self Attention + Target Attention 目前已经是处理序列特征的标配,其效果在阿里得到广泛验证;
参考文献
[1] Deep Session Interest Network(DSIN)
[2] Deep Session Interest Network(DSIN) 源码
[3] DSIN(Deep Session Interest Network )分享