Pytorch学习:图像分类入门!使用CIFAR-10数据集,完整地创建深度神经网络进行训练、测试并保存和读取
前言
本模型最终能得到约 83% 的分类测试精度,占用约1.7g显存大小。
使用的是经典CIFAR-10数据集,里面包含了10个种类的图片:

1. 导入Pytorch以及相关包
本文使用pytorch=1.5.1+cuda10.1
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import time,os
torch.nn和torch.nn.functional中包含了很多高度集成的函数。
torchvision中提供了主流的公开数据集,如MNIST、CIFAR-10、CIFAR-100等。MNIST(手写黑白图像数据集)比较小并且简单,并不能很好地体现现在模型的性能。使用CIFAR-10包含了共十类彩色图像数据集),可以较好地测试模型的能力。CIFAR-100更加困难一些。
torchvision.transforms可以对图像进行数据增强,并使用transforms.ToTensr()将数据转换成训练所需要的tensor。
torch.optim中包含了pytorch中可使用的各种optimizer,如Adam、SGD等等。
2. 下载、加载数据集并进行增强
transform = transforms.Compose([
transforms.transforms.RandomRotation(0.5),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = torchvision.datasets.CIFAR10(root='./datasets', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=50,
shuffle=True, num_workers=0)
test_dataset = torchvision.datasets.CIFAR10(root='./datasets', train=False,
download=False, transform=transform_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=25,
shuffle=False, num_workers=0)
使用Compose()整合地对数据进行增强/预处理。其中:
RandomRotation(0.5)(),对图像进行角度旋转,0.5代表在(-0.5, +0.5)范围内进行旋转,可以自行设置RandomGrayscale(),随机对图像转换成灰度图,默认为50%ToTensor(),将图像从numpy的array转化为pytorch训练需要的tensorNormalize(),将tensor集合转换成指定的mean和std,这里都取0.5。其实,0.5是常用标准,要想提升模型能力,对于不同的数据集,应该使用不同具体的的mean和std,具体如何计算不同数据集的mean和std,可能以后会写。
一般,loader函数中的num_wokers设置成2,具体作用可以自行搜索,这里设置成0是因为我的电脑GPU在多线程载入数据时会出现某些错误,当程序报错的时候会无法杀死旧的进程,设置成0就没事了。
数据增强/预处理,能够通过改变数据集的多样性,提升模型的鲁棒性和精度,几乎所有的训练都要对数据进行增强,是模型训练中必不可少的一部分。关于更多预处理的简单介绍请看。
使用torchvision.datasets.CIFAR10()下载数据集,需要设置download=True,root=为下载位置,下载成功后只要不改变下载位置不会反复下载,所以建议都下载在统一文件夹中,便于管理并节省空间;在训练集中,需要设置train=True,表示对训练集进行训练,测试集则不需要;transform代表使用之前定义好的transform方法。
可以通过以下代码对数据集某个数据进行可视化:
import matplotlib.pyplot as plt
fig = plt.figure()
plt.imshow(train_dataset.data[0]) # 第一个数据
plt.show()
整个训练集为5W个32*32*3的彩色图,其中一个示例:

3. 模型设计
深度学习网络框架由AlexNet建立,包含了卷积层、激活函数、池化层和全连接层;之后的VGG通过将7*7卷积替换成两个3*3卷积,减少了参数,并且由于可以额外增加一个激活函数,增加了模型的非线性程度,性能得到较大提升;而ResNet通过residual block结构,将深度一词发挥的非常彻底,也极大地提升了模型的性能。
本文基于VGG设计网络结构,由于苦逼1050GPU只有2G大,所以为了提高性能,只能通过增加多个1x1卷积减少模型参数:
class Model(nn.Module):
def __init__(self,num_classes=10): #
super(Model,self).__init__()
layers = [] # 将层数添加到此列表中
in_dim = 3 # 输入3通道的彩色图片
out_dim = 64
for i in range(1, 6): # 共5个block;
layers += [nn.Conv2d(in_dim, out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim), nn.ReLU(inplace=True),
# 使用1x1卷积减少模型参数
nn.Conv2d(out_dim, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim), nn.ReLU(inplace=True),
nn.Conv2d(out_dim, out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),nn.ReLU(inplace=True),
]
# 使用步长为2的卷积代替maxpooling
if i==2 or i==3 or i==4:
layers += [nn.Conv2d(out_dim, out_dim,
kernel_size=3, stride=2, padding=1)]
# 也可以使用maxpooling
# layers+= [nn.Maxpool2d(2,2,padding=1)]
in_dim = out_dim # 交换
if i != 4: # 通道翻倍
out_dim *= 2
self.features = nn.Sequential(*layers)
# 布置全连接层进行分类
self.classifier = nn.Sequential(nn.Linear(8192, 1024),nn.Dropout2d(),
nn.Linear(1024,1024),nn.Dropout2d(),
nn.Linear(1024,num_classes))
# 前向传播
def forward(self,x):
x = self.features(x)
# 将BxCxWxH的数据类型=>Bx(C*W*H)后进入全连接层
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
继承nn.Module类后开始初始化__init__(),并前向传播forward()
- 初始化:使用
self.features和self.classifier保存网络结构,其中self.features保存在layers中,包含了网络中的卷积层、池化层、BN层、激活层等等 - 前向传播:输入x传进网络中,然后通过展平,将
self.features的输出通道与self.classifier的输入通道保持一致,计算并得到输出。现在还没进行反向传播
这里全连接层的参数8192是如何来的呢?在工程上一般不需要直接设定好,直接搭建好模型,跑一遍。会报出BUG,BUG会显示无法进行矩阵相乘。这时只需要将报出的数据填入就好,具体我就不展示了,大家可以自己试一下。
通过:
model = Model()
model
打印出所构建的五层(除去全连接层)网络结构:
Model(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(13): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(16): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(17): ReLU(inplace=True)
(18): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(19): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(21): ReLU(inplace=True)
(22): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(23): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(24): ReLU(inplace=True)
(25): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(27): ReLU(inplace=True)
(28): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(29): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(30): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(33): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(34): ReLU(inplace=True)
(35): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(36): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(37): ReLU(inplace=True)
(38): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(39): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(40): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(41): ReLU(inplace=True)
(42): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(43): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(44): ReLU(inplace=True)
(45): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(46): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
(47): ReLU(inplace=True)
)
(classifier): Sequential(
(0): Linear(in_features=8192, out_features=1024, bias=True)
(1): Dropout2d(p=0.5, inplace=False)
(2): Linear(in_features=1024, out_features=1024, bias=True)
(3): Dropout2d(p=0.5, inplace=False)
(4): Linear(in_features=1024, out_features=10, bias=True)
)
)
4. Loss和优化器选择
loss和优化器的选择非常多,选择经典的nn.CrossEntropyLoss();优化器没有选择SGD,而是optim.Adam(),Adam在绝大多数任务中都能取得非常不错的效果。
loss = nn.CrossEntropyLoss()
# 若选择lr=0.001,精度会改变,关于超参数好坏可以自行实验确定
optimizer = optim.Adam(self.parameters(), lr=0.0001)
5. 训练与测试
首先确定训练分为多少epoches,epoch为完整地将所有训练数据走一遍,同是还存在这样一个公式:1 epoch = batch_size * batch_idx(iteration),其中batch_size在现在一般为mini-batch,可以自行设定。通常,batch_size提高也能搞提高模型的精度,但是也增加模型单次训练时的体积。
关于epoch、batch_size和batch_idx(iteration)不理解的可以看我之前的文章。
训练:
def train(self,device):
lr = 0.0001 # 从0.001→0.0001明显acc上升
initepoch = 0
epoches = 10
# 对模型参数optimize
optimizer = optim.Adam(self.parameters(),lr=lr)
loss = nn.CrossEntropyLoss()
for epoch in range(initepoch, epoches): # (0,10) 共10个epoch
timestart = time.time()
running_loss = 0.0
correct = 0
total = 0
# 从第一个数据开始训练
for batch_idx, (inputs, labels) in enumerate(train_loader,0):
# 将输入和标签送入GPU
inputs, labels = inputs.to(device), labels.to(device)
# 每epoch开始前都要进行梯度清零
optimizer.zero_grad()
# 输入送入模型并得到输出
outputs = self(inputs)
# 计算loss
l = loss(outputs, labels)
# 反向传播并优化
l.backward() # 竟然忘记反向传播和优化,怪不得这么低的acc
optimizer.step()
running_loss += l.item()
# 每1000次打印一下(1 epoch)
if batch_idx == 999:
print('[%d, %d] loss: %.4f' %(epoch+1, epoches,
running_loss / 500))
running_loss = 0
_, predicted = torch.max(outputs.data, 1) # 标签预测
total += labels.size(0)
correct += (predicted==labels).sum().item() # 计算精度
print('Train accuracy is : %.3f %%'(100.0 * correct / total))
total = 0
correct = 0
print('epoch %d costs %4f sec' %(epoch,time.time()-timestart))
print("#####Finished Training!!!#####")
测试:
def test(self,device):
correct = 0
total = 0
# 测试不需要计算梯度
with torch.no_grad():
for batch_idx, (inputs, labels) in enumerate(test_loader, 0):
inputs, labels = inputs.to(device), labels.to(device)
outputs = self(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted==labels).sum().item()
print('Test accuracy is : %.3f %%'(100.0 * correct / total))
训练把数据一个个batch载入然后进行前向传播、计算梯度、反向传播并优化;而测试只需要进行前向传播,不需要计算梯度和反向传播。
6. 使用GPU
深度学习可以将模型装载在GPU上进行训练,会比CPU快太多,所以基本上现在所有的训练都是在GPU上面的。那如何使用GPU呢
首先先确定自己的电脑是否能够使用GPU:
torch.cuda.is_availabel()
如果正确装好cuda并且可以GPU型号支持的话,这里会显示True。
一般的,像我用自己的电脑,并没有进行多卡训练,不需要选择torch中的DataParallel功能,即多卡同时训练。
所以直接设置:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Model().to(device)
device会选择,如果有GPU且环境正确则使用GPU,没有则使用CPU。下一句是将模型载入GPU。
7. 保存模型与载入已有模型
训练过程中,常常遇到训练时间过长、停电或者其他不想见到的情况,这些情况都会导致训练的暂停,并且我们应当主动保存优秀的模型。
通过:
...
path = "checkpoint.tar" # 存放的模型名字和路径(此时表示当前文件夹)
...
torch.save({'epoch':epoch, 'model_state_dict':model.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),'loss':loss}, path)
通过torch.save函数,保存模型的参数。pytorch的好处就是函数简单易懂明了,model.state_dict()和optimizer.state_dict()分别保存了模型和优化器的参数在字典中,大家可以自己打出来看看。
再通过torch.load()函数进行载入:
checkpoint = torch.load(path)
self.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
8. 完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import time,os
transform = transforms.Compose([
transforms.transforms.RandomRotation(0.5),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = torchvision.datasets.CIFAR10(root='./dataset', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=50,
shuffle=True, num_workers=0)
test_dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False,
download=False, transform=transform_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=25,
shuffle=False, num_workers=0)
class Model(nn.Module):
def __init__(self,num_classes=10): #
super(Model,self).__init__()
layers = [] # 将层数添加到此列表中
in_dim = 3 # 输入3通道的彩色图片
out_dim = 64
for i in range(1, 6): # 共5个block;
layers += [nn.Conv2d(in_dim, out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim), nn.ReLU(inplace=True),
# 使用1x1卷积减少模型参数
nn.Conv2d(out_dim, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim), nn.ReLU(inplace=True),
nn.Conv2d(out_dim, out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),nn.ReLU(inplace=True),
]
# 使用步长为2的卷积代替maxpooling
if i==2 or i==3 or i==4:
layers += [nn.Conv2d(out_dim, out_dim,kernel_size=3, stride=2, padding=1)]
# 也可以使用maxpooling
# layers+= [nn.Maxpool2d(2,2,padding=1)]
in_dim = out_dim # 交换
if i != 4: # 通道翻倍
out_dim *= 2
self.features = nn.Sequential(*layers)
# 布置全连接层进行分类
self.classifier = nn.Sequential(nn.Linear(8192, 1024),nn.Dropout2d(),
nn.Linear(1024,1024),nn.Dropout2d(),
nn.Linear(1024,num_classes))
# 前向传播
def forward(self,x):
x = self.features(x)
# 将BxCxWxH的数据类型=>Bx(C*W*H)后进入全连接层
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 训练
def train(self,device):
path = "checkpoint.tar" # 存放的模型名字和路径(此时表示当前文件夹)
lr = 0.0001 # 从0.001→0.0001明显acc上升
initepoch = 0
epoches = 15
# 选择optimizer和loss
optimizer = optim.Adam(self.parameters(),lr=lr)
# loss = nn.CrossEntropyLoss()
# 模型载入
if os.path.exists(path):
checkpoint = torch.load(path)
self.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
else:
loss = nn.CrossEntropyLoss()
for epoch in range(initepoch, epoches): # (0,10) 共10个epoch
timestart = time.time()
running_loss = 0.0
correct = 0
total = 0
print("Now epoch is %s"%(epoch+1)) # 如果直接有checkpoint,会到最后一个epoch
# 从第一个数据开始训练
for batch_idx, (inputs, labels) in enumerate(train_loader,0):
# 将输入和标签送入GPU
inputs, labels = inputs.to(device), labels.to(device)
# 每epoch开始前都要进行梯度清零
optimizer.zero_grad()
# 输入送入模型并得到输出
outputs = self(inputs)
# 计算loss
l = loss(outputs, labels)
# 反向传播并优化
l.backward()
optimizer.step()
running_loss += l.item()
# 每1000次打印一下(1 epoch)
if batch_idx == 999:
print('[%d, %d] loss: %.4f' %(epoch+1, epoches,
running_loss / 500))
running_loss = 0
_, predicted = torch.max(outputs.data, 1) # 标签预测
total += labels.size(0)
correct += (predicted==labels).sum().item() # 计算精度
print('Train accuracy is : %.3f %%'%(100.0 * correct / total))
total = 0
correct = 0
torch.save({'epoch':epoch,
'model_state_dict':model.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'loss':loss}, path)
print('epoch %d costs %4f sec' %(epoch,time.time()-timestart))
print("#####Finished Training!!!#####")
# 测试
def test(self,device):
correct = 0
total = 0
# 测试不需要计算梯度
with torch.no_grad():
for batch_idx, (inputs, labels) in enumerate(test_loader, 0):
inputs, labels = inputs.to(device), labels.to(device)
outputs = self(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted==labels).sum().item()
print('Test accuracy is : %.3f %%'%(100.0 * correct / total))
# 模型装入GPU开始训练并且测试
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Model().to(device)
model.train(device)
model.test(device)
后记
网络结构和超参数几乎没用太多的优化,都是已有网络结构的简单叠加,唯二和传统VGG不同或者教学中不常用的是结构上使用了步长为2的卷积代替了maxpooling,以及使用了多个1x1卷积(具体作用可以自己搜一下,也许我也会整一篇文章)。在超参数上几乎保持了默认值。
另外,我是在windows环境下运行的,使用notebook新建的terminal,输入nvidia-smi.exe可以获取GPU状态,可以查看GPU显存占用情况。linux环境下直接nvidia-smi即可。
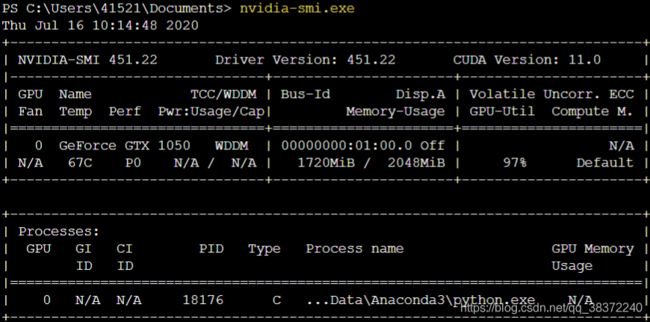
代码运行出bug之后,重新运行,出现显存超出的情况,实际上可能是旧的进程仍在占用,使用kill 18176杀死进程,具体数字每次训练不同,再重新进行训练即可。
如果自己的GPU是很好的,修改batch_size到100或者200都可以的,然后batch_idx也通过上面的等式进行修改即可,否则print不出来。
另外,未来还会整理一些inception和resnet的基础入门pytorch文章。