图像识别:基于ResNet网络的cifar-10数据集图像识别分析与参数对比
1 图像识别的背景
作为人工智能与计算机视觉的重要组成部分,图像识别技术是目标检测、图像语义分割等技术的基础,因此,图像识别的准确率往往决定了很多其他计算机视觉技术的效果。一般来说,图像识别任务主要包括对于图像的分类;但是准确的来说,计算机本身不具有理解图像的能力,图像识别就是为了让计算机有和人类一样对图像理解的能力,包括图像表示的内容,图像中物体之间的关系等要素。
图像识别是一项比较传统的技术,从一开始的模板匹配法、霍夫变换(Hough Transform),到发展了一定时期后产生的基于贝叶斯模型和马尔科夫随机场等图像统计模型的方法,再到了目前应用最为广泛的各种深度学习方法。随着各类卷积神经网络的逐渐应用,图像识别任务的效果也逐渐获得了大幅度的提升。
在我看来,使用神经网络进行图像识别任务的关键在于图像特征的充分提取。在传统的图像处理手段中,往往会对彩色图像进行二值化,这样其实就丢失了很多图像的相关信息,导致特征提取不完全;而通过3D卷积核的卷积运算,却可以做到对于RGB彩色特征的充分利用。通过调研论文以及查阅相关资料,总结目前主流的一些卷积神经网络的模型如表所示。
| 改进方面 | 主要模型 |
|---|---|
| 卷积核的空间特征提取能力 | LeNet、AlexNet、ZefNet、VGG-16、GoogleNet |
| 提升网络深度 | ResNet、Inception-V3/V4 |
| 多路径网络 | DenseNet、ResNet |
| 横向多连接 | WideResNet、Xception、PyramidalNet |
| 卷积运算与feature map | Gabor CNN、Squeeze and Excitation |
| 注意力机制 | Residual Attention NN、Convolutional Block Attention |
一直以来对于残差块这一结构十分感兴趣,因此以ResNet为研究对象,并通过cifar-10数据集对其进行训练、测试和分析。
2 所用ResNet的模型结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并加入了残差单元。相比于一些增加网络层数和进行模型组合的方法,ResNet可以说是对于网络结构一种极大的创新,它通过增加残差连接这一结构,解决了深层网络随着网络层数加深,网络会出现由于梯度弥散和梯度爆炸而导致深层次网络模型的效果反而变差。神经网络的每一层分别对应于提取不同层次的特征信息,有低层,中层和高层,而网络越深的时候,提取到的不同层次的信息会越多,而不同层次间的层次信息的组合也会越多。ResNet中主要采用残差块来实现残差网络的残差连接,如图1所示为ResNet所采用的主要的两种残差结构。
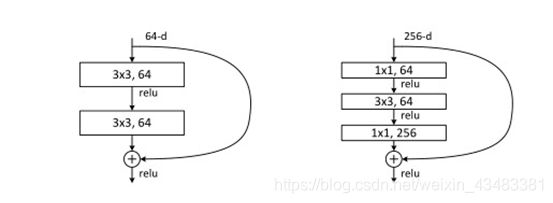
ResNet中的残差块主要有两种结构,分别是basicblock与bottleblock,两者最大的区别就在于basicblock采用了跨越了两层结构而bottleblock跨越了三层,并且bottleblock利用了尺寸1*1的卷积核进行简化计算以及改变输出的维度。通过这两种残差连接手段,使得上一层网络的张量计算值可以直接“跳传”到下下层网络中去,而不必非要通过中间网络层让张量发生改变。在我个人理解下,通过这种方式,ResNet模型通过训练最差可以至少保证深层次网络具有和浅层次网络一样的效果,并且其提供了一种低层特征直接与高层特征链接的渠道,增加了网络的可拟合的范围。
为了更好地实际体验ResNet对于深层次网络的改进效果,使用了不同层数的ResNet网络对cifar-10数据集进行了训练和测试。
| 模型结构 | 网络层数 | 参数总数量 |
|---|---|---|
| ResNet20 | 20 | 0.27M |
| ResNet32 | 32 | 0.46M |
| ResNet44 | 44 | 0.66M |
| ResNet56 | 56 | 0.85M |
| ResNet110 | 110 | 1.7M |
| ResNet1202 | 1202 | 19.4M |
3 实验设置与结果
由于cifar10数据集不是很大,并且数据集中每张图片的尺寸都是32*32的小尺寸,因此训练对于硬件的要求不高。但是由于ResNet110、ResNet1202模型层数过多,笔记本无法支持对其充分的训练,因此自己训练了剩下的四种ResNet模型。由于计算资源有限(Epoch均取得50),每个模型可能训练的不是特别充分,训练时的超参数设置如表所示。
| 超参数 | 值 |
|---|---|
| epoch | 50 |
| batch-size | 128 |
| 学习率(α) | 从0.1开始衰减 |
| 优化算法 | SGD |
| weight-decay | 0.0001 |
| Momentum(β) | 0.95 |
| 网络结构 | ResNet20、ResNet32、ResNet44、ResNet56 |
将cifar数据集按照5:1的比例进行训练集和测试集的划分,同时从网上找到了ResNet相关的已经训练好的模型作为对比,并且也与论文中的结果进行了对比,测试集上的结果如表所示。
| 模型结构 | 自己训练的 | 网上的 | 论文中的 |
|---|---|---|---|
| ResNet20 | 91.05% | 91.73% | 91.25% |
| ResNet32 | 92.49% | 92.63% | 92.49% |
| ResNet44 | 92.57% | 93.10% | 92.83% |
| ResNet56 | 92.76% | 93.39% | 93.03% |
| ResNet110 | - | 93.68% | 93.57% |
| ResNet1202 | - | 93.82% | 92.07% |
部分测试集图像展示,使用这个测试不同参数的网络,结果如下表:

| 预测结果 | |
|---|---|
| 真实值 | Cat ship ship plane frog frog fish frog |
| ResNet20 | Cat ship car plane frog frog fish bird |
| ResNet32 | Cat ship ship plane frog dog fish frog |
| ResNet44 | Cat ship ship plane frog frog fish frog |
| ResNet56 | Cat ship ship plane frog frog fish bird |
| ResNet110 | Cat ship ship plane frog frog fish frog |
| ResNet1202 | Cat ship ship ship frog frog fish frog |
4 结果分析与深入讨论
首先,在训练过程中发现,ResNet网络出乎意料的收敛性好,不管是随机正态分布初始化还是使用finetuning方法,训练过程模型都具有很好的收敛性。本次实验限于计算资源没有对于原始ResNet网络添加过多tricks进行对比,只是相比于原始模型增加了学习率衰减,以提升模型前期的训练速度。在尝试使用Adam作为优化器时,遇到了训练速度大幅减慢的问题,因此没有采用。在后续,感觉还可以从批归一化的角度对模型进行进一步的改进,并且可以考虑将训练数据进行增强来提升训练效果。
其次,在表4中可以发现,随着模型深度的增加,模型的准确率逐步提高,这也体现了残差网络的深度优势。无论是自己训练的模型,还是网络上和论文里的模型,模型效果都是随着网络层次的加深而提高的。因此,使用残差块的模型在层次深度上和模型效果是正相关的,这一点与之前介绍的残差原理也一致。
最后,通过图2和表5的结果可以发现,浅层网络更容易出现误判的问题,而深层网络则较少。同时,从实际图像中可以发现,深层次的ResNet对于测试图像错误的判断风格也和浅层的有区别。作为最深层次的网络,ResNet1202还是出现了错误,并且其出错的图片在其他模型中都预测正确了。从这可以看出,一方面是由于cifar数据集图像太小了,不能充分体现深层网络的特征提取优势;另一方面也体现出了深层次ResNet提取的特征更加复杂,与浅层次ResNet是不同的。
5 代码(参考的github)
模型结构:
'''
Properly implemented ResNet-s for CIFAR10 as described in paper [1].
The implementation and structure of this file is hugely influenced by [2]
which is implemented for ImageNet and doesn't have option A for identity.
Moreover, most of the implementations on the web is copy-paste from
torchvision's resnet and has wrong number of params.
Proper ResNet-s for CIFAR10 (for fair comparision and etc.) has following
number of layers and parameters:
name | layers | params
ResNet20 | 20 | 0.27M
ResNet32 | 32 | 0.46M
ResNet44 | 44 | 0.66M
ResNet56 | 56 | 0.85M
ResNet110 | 110 | 1.7M
ResNet1202| 1202 | 19.4m
which this implementation indeed has.
Reference:
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Deep Residual Learning for Image Recognition. arXiv:1512.03385
[2] https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
If you use this implementation in you work, please don't forget to mention the
author, Yerlan Idelbayev.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as init
from torch.autograd import Variable
__all__ = ['ResNet', 'resnet20', 'resnet32', 'resnet44', 'resnet56', 'resnet110', 'resnet1202']
def _weights_init(m):
classname = m.__class__.__name__
#print(classname)
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight)
class LambdaLayer(nn.Module):
def __init__(self, lambd):
super(LambdaLayer, self).__init__()
self.lambd = lambd
def forward(self, x):
return self.lambd(x)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1, option='A'):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
if option == 'A':
"""
For CIFAR10 ResNet paper uses option A.
"""
self.shortcut = LambdaLayer(lambda x:
F.pad(x[:, :, ::2, ::2], (0, 0, 0, 0, planes//4, planes//4), "constant", 0))
elif option == 'B':
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2)
self.linear = nn.Linear(64, num_classes)
self.apply(_weights_init)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, out.size()[3])
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def resnet20():
return ResNet(BasicBlock, [3, 3, 3])
def resnet32():
return ResNet(BasicBlock, [5, 5, 5])
def resnet44():
return ResNet(BasicBlock, [7, 7, 7])
def resnet56():
return ResNet(BasicBlock, [9, 9, 9])
def resnet110():
return ResNet(BasicBlock, [18, 18, 18])
def resnet1202():
return ResNet(BasicBlock, [200, 200, 200])
def test(net):
import numpy as np
total_params = 0
for x in filter(lambda p: p.requires_grad, net.parameters()):
total_params += np.prod(x.data.numpy().shape)
print("Total number of params", total_params)
print("Total layers", len(list(filter(lambda p: p.requires_grad and len(p.data.size())>1, net.parameters()))))
if __name__ == "__main__":
for net_name in __all__:
if net_name.startswith('resnet'):
print(net_name)
test(globals()[net_name]())
print()
数据训练:
import argparse
import os
import shutil
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision
import resnet
model_names = sorted(name for name in resnet.__dict__
if name.islower() and not name.startswith("__")
and name.startswith("resnet")
and callable(resnet.__dict__[name]))
# print(model_names)
parser = argparse.ArgumentParser(description='Propert ResNets for CIFAR10 in pytorch')
parser.add_argument('--arch', '-a', metavar='ARCH', default='resnet32',
choices=model_names,
help='model architecture: ' + ' | '.join(model_names) +
' (default: resnet32)')
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('--epochs', default=200, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=128, type=int,
metavar='N', help='mini-batch size (default: 128)')
parser.add_argument('--lr', '--learning-rate', default=0.1, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--momentum', default=0.95, type=float, metavar='M',
help='momentum')
parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float,
metavar='W', help='weight decay (default: 5e-4)')
parser.add_argument('--print-freq', '-p', default=40, type=int,
metavar='N', help='print frequency (default: 20)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--pretrained', dest='pretrained', action='store_true',
help='use pre-trained model')
parser.add_argument('--lookit', dest='lookit', action='store_true',
help='look the performance of model in images, need resume first')
parser.add_argument('--half', dest='half', action='store_true',
help='use half-precision(16-bit) ')
parser.add_argument('--save-dir', dest='save_dir',
help='The directory used to save the trained models',
default='save_temp', type=str)
parser.add_argument('--save-every', dest='save_every',
help='Saves checkpoints at every specified number of epochs',
type=int, default=10)
best_prec1 = 0
def main():
global args, best_prec1
args = parser.parse_args()
# Check the save_dir exists or not
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
if args.pretrained:
print("使用finetuning模型")
model = torch.nn.DataParallel(resnet.__dict__[args.arch]())
model.load_state_dict(torch.load("finetuning/resnet32_finetuning.th")['state_dict'])
else:
model = torch.nn.DataParallel(resnet.__dict__[args.arch]())
model.cuda()
# optionally resume from a checkpoint
if args.resume:
print("检查点路径:", args.resume)
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
# args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
# print("=> loaded checkpoint '{}' (epoch {})"
# .format(args.evaluate, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10(root='./data', train=True, transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, 4),
transforms.ToTensor(),
normalize,
]), download=True),
batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
datasets.CIFAR10(root='./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
normalize,
])),
batch_size=128, shuffle=False,
num_workers=args.workers, pin_memory=True)
# define loss function (criterion) and pptimizer
criterion = nn.CrossEntropyLoss().cuda()
if args.half:
model.half()
criterion.half()
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[100, 150], last_epoch=args.start_epoch - 1)
if args.arch in ['resnet1202', 'resnet110']:
# for resnet1202 original paper uses lr=0.01 for first 400 minibatches for warm-up
# then switch back. In this setup it will correspond for first epoch.
for param_group in optimizer.param_groups:
param_group['lr'] = args.lr*0.1
# 观测已训练好模型的表现,从单张图片可视化角度
if args.lookit:
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10(root='./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
normalize,
])),
batch_size=8, shuffle=False,
num_workers=args.workers, pin_memory=True)
dataiter = iter(test_loader)
images, labels = dataiter.next()
images = images.cuda()
outputs = model(images).cpu()
print("out:",outputs)
_, predicted = torch.max(outputs, 1)
print("predicted:", predicted)
print("labels", labels)
# print images
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
images = images.cpu()
imshow(torchvision.utils.make_grid(images), "true")
print('GroundTruth: ', ' '.join('%5s' % predicted[labels[j]] for j in range(8)))
return
# 观测已训练好模型的表现,从测试集准确率角度
if args.evaluate:
# 传入三个参数, 验证集合、模型以及损失函数
validate(val_loader, model, criterion)
return
# print("程序运行还行:")
# return
# 下面是是开始训练过程
for epoch in range(args.start_epoch, args.epochs):
# train for one epoch
print('current lr {:.5e}'.format(optimizer.param_groups[0]['lr']))
train(train_loader, model, criterion, optimizer, epoch)
lr_scheduler.step()
# evaluate on validation set
prec1 = validate(val_loader, model, criterion)
# remember best prec@1 and save checkpoint
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
if epoch > 0 and epoch % args.save_every == 0:
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
}, is_best, filename=os.path.join(args.save_dir, 'checkpoint.th'))
save_checkpoint({
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
}, is_best, filename=os.path.join(args.save_dir, 'model.th'))
def train(train_loader, model, criterion, optimizer, epoch):
"""
Run one train epoch
"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
target = target.cuda()
input_var = input.cuda()
target_var = target
if args.half:
input_var = input_var.half()
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
output = output.float()
loss = loss.float()
# measure accuracy and record loss
prec1 = accuracy(output.data, target)[0]
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1))
def validate(val_loader, model, criterion):
"""
Run evaluation
"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
with torch.no_grad():
# 这里i枚举的范围是0-79
for i, (input, target) in enumerate(val_loader):
target = target.cuda()
input_var = input.cuda()
target_var = target.cuda()
if args.half:
input_var = input_var.half()
# compute output
output = model(input_var)
loss = criterion(output, target_var)
output = output.float()
loss = loss.float()
# measure accuracy and record loss
prec1 = accuracy(output.data, target)[0]
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'损失函数Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'部分测试集准确率: {top1.val:.3f} ({top1.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1))
print('全体测试集准确率:{top1.avg:.3f}'
.format(top1=top1))
return top1.avg
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
"""
Save the training model
"""
torch.save(state, filename)
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def imshow(img, name):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.savefig(".\\plotfigure\\" + str(name) + ".png", dpi=300)
if __name__ == '__main__':
main()
测试集运行脚本:
import os
# 用于直接遍历文件夹并返回文件夹的文件相对路径列表,类似于os.walk
def DFS_file_search(dict_name):
# list.pop() list.append()这两个方法就可以实现栈维护功能
stack = []
result_txt = []
stack.append(dict_name)
while len(stack) != 0: # 栈空代表所有目录均已完成访问
temp_name = stack.pop()
try:
temp_name2 = os.listdir(temp_name) # list ["","",...]
for eve in temp_name2:
stack.append(temp_name + "\\" + eve) # 维持绝对路径的表达
except NotADirectoryError:
result_txt.append(temp_name)
return result_txt
paths = DFS_file_search("pretrained_models")
for path in paths:
model_selected = path.split("\\")[-1].split(".")[0]
os.system('python trainer.py --resume={} -e --evaluate --arch={}'.format(path, model_selected))