无tensorflow,在pytorch下使用tensorboard可视化工具报错:Could not load dynamic library ‘cudart64_110.dll‘; dlerror
文章目录
- 报错信息:
- 真实原因
- 解决方案
- tensorboard完整demo代码:
在pycharm终端下输入命令
(如果是在cmd中输入命令的话,记得一定要把cmd中的目录切换成本项目的路径,博客最后面有介绍):
tensorboard --logdir logs --host 0.0.0.0
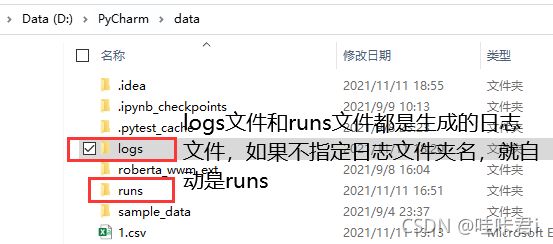
命令中的 logs 是运行完tensorboard的demo脚本后自动会生成的日志文件夹,logs是指定的日志文件夹名称,我最开始没有指定日志文件夹名,自动生成的是runs文件夹(在博客后面会有截图看得到)
直接看:
报错信息:
W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.

个人碎碎念:
找了一下午的原因,因为很久之前就把 tensorflow 和 pytorch 都装了,运行tensorboard的demo脚本后,报错,发现是两个框架冲突,因此卸载tensorflow, 准备在 pytorch 下使用 tensorboard 可视化工具。( 之后可能就只用pytorch了,弃用tf )
没想到打开了网址 http://localhost:6006/ 后,显示:
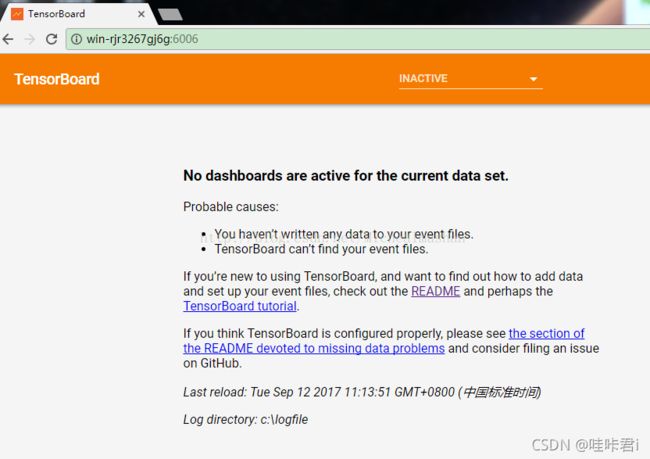
然后我就一直在找 No dashboards are for the current data set. 的原因,网上的很多博主的方法都解决不了我这个。
真实原因
。。。。
发现最终原因是:
cudart64_110.dll not found (没有找到cudart64_110.dll)
。。。。
解决方案
进入官网:dll下载官网
根据报错提示,我缺的是 110 版本的dll ,因此直接搜 110,或者 搜 cudart64_110.dll,按照自己缺损的dll文件版本来下载即可
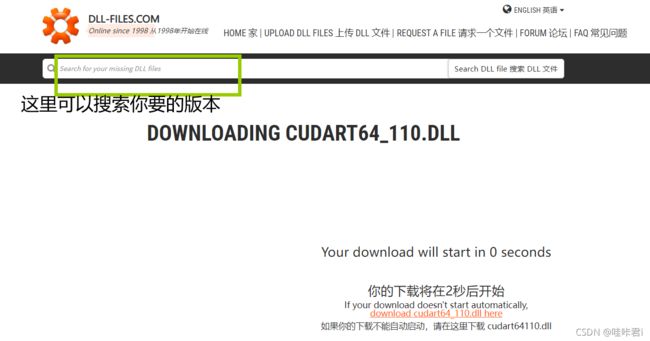
然后把下载下来的zip压缩包中的 cudart64_110.dll 文件复制到相应的路径中:
C:\Windows\System32
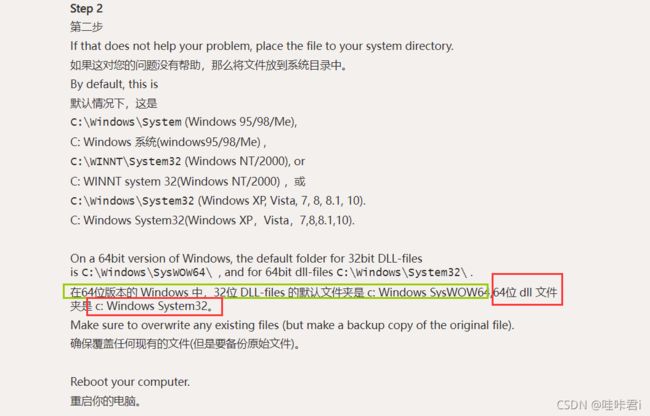
根据官网提示,
64位版本的windows中,
32位的 dll 文件放在 C:\Windows\SysWOW64\ 目录下;
64位的 dll 文件放在 C:\Windows\System32\ 目录下;

再回到pycharm终端中,输入命令
tensorboard --logdir logs --host 0.0.0.0
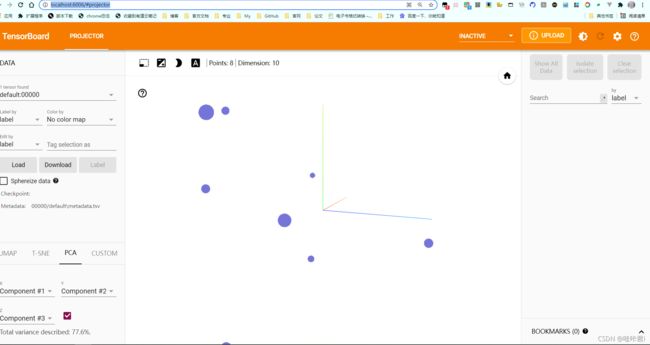
启动tensorboard成功。
对了,再提一嘴,在cmd中也可以输入启动命令,但是:
cmd中的目录一定要进入到生成的logs日志的上一级那一级,然后再输入命令,
而且 –logdir 后面可以不需要 = 等于号,
直接敲命令:
tensorboard -logdir 日志文件名 --host 0.0.0.0
或
tensorboard -logdir 日志文件名
也能成功启动tensorboard


tensorboard完整demo代码:
# 导入torch和tensorboard的摘要写入方法
import torch
import fileinput
from torch.utils.tensorboard import SummaryWriter
# 实例化一个摘要对象,并指定了“logs”日志文件夹路径,还可以写成“logs/a”等
writer = SummaryWriter("logs")
# 代表8个词汇,每个词汇被表示成10维的向量,这里的8个词汇必须和下面输入的vocab.csv中的词汇个数相等
embedded = torch.randn(8, 10)
meta = list(map(lambda x: x.strip(), fileinput.FileInput("vocab.csv", openhook=fileinput.hook_encoded('utf-8', ''))))
writer.add_embedding(embedded, metadata=meta)
writer.close()
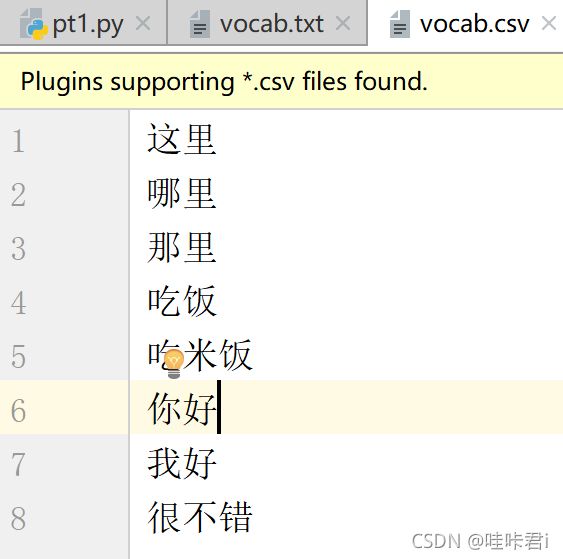
我的vocab文件是这样做的,首先建一个vocab.txt文本,在里面随便输入多少个词语,每个词语占一行,我就输入了8个词,点击保存关闭后,直接修改 vocab.txt 文件的后缀为 vocab.csv
本此的成功解决方案来源于这两篇博客,感大佬们的积极创作:
https://www.pianshen.com/article/31911647685/
https://blog.csdn.net/qq_47233366/article/details/115710212
以上。