深入理解mybatis
参考《深入浅出Mybatis技术原理与实战》
目录
- 一、Mybatis简介
-
- 1.1 JDBC的弊端
- 1.2 ORM模型
- 1.3 Mybatis
- 二、Mybatis基本组成
- 三、配置与映射器
- 四、Mybatis的运行原理
-
- 4.1 读取配置文件
- 4.2 SqlSession运行流程
- 五、执行器
-
- 5.1 SimpleExecutor
- 5.2 ReuseExecutor
- 5.3 BatchExecutor
- 5.4 基础执行器
- 5.5 CachingExecutor
- 5.6 总结
- 六、一级缓存
一、Mybatis简介
1.1 JDBC的弊端
在深入理解Mybatis之前,先回顾JDBC的操作步骤,Java程序要操作数据库都是使用JDBC,使用步骤如下:
- 加载数据库驱动,class.forname
- 建立数据库连接,获取Connection 对象
- 创建数据库操作对象Statement
- 定义操作的SQL语句
- 执行数据库操作
- 获取并操作结果集ResultSet
- 关闭对象,回收数据库资源
具体代码如下:
public class JDBCTest {
/**
* 使用JDBC连接并操作mysql数据库
*/
public static void main(String[] args) {
// 数据库驱动类名的字符串
String driver = "com.mysql.jdbc.Driver";
// 数据库连接串
String url = "jdbc:mysql://127.0.0.1:3306/jdbctest";
// 用户名
String username = "root";
// 密码
String password = "mysqladmin";
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 1、加载数据库驱动( 成功加载后,会将Driver类的实例注册到DriverManager类中)
Class.forName(driver );
// 2、获取数据库连接
conn = DriverManager.getConnection(url, username, password);
// 3、获取数据库操作对象
stmt = conn.createStatement();
// 4、定义操作的SQL语句
String sql = "select * from user where id = 100";
// 5、执行数据库操作
rs = stmt.executeQuery(sql);
// 6、获取并操作结果集
while (rs.next()) {
System.out.println(rs.getInt("id"));
System.out.println(rs.getString("name"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 7、关闭对象,回收数据库资源
if (rs != null) { //关闭结果集对象
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (stmt != null) { // 关闭数据库操作对象
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) { // 关闭数据库连接对象
try {
if (!conn.isClosed()) {
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
通过上面的代码可以得出使用传统的JDBC代码的弊端:
-
数据库连接,使用时就创建,不使用就释放,对数据库进行频繁连接开关和关闭,造成数据库资源浪费,影响数据库的性能
解决:使用数据库连接池管理数据库的连接 -
sql语句使用硬编码在java程序中,修改sql语句,就需要重新编译java代码,不利于系统维护
-
PreparedStatement对象设置参数时使用序号进行占位,不利于系统维护
-
遍历结果集时,存在硬编码,不灵活
1.2 ORM模型
使用JDBC进行代码编写由于存在缺陷,后面提出了ORM模型:数据库表和简单的Java对象的映射关系模型,也就是说将数据库中的一张表映射为Java对象中的一个实体类

目前使用广泛的ORM模型的框架有,Hibernate和Mybatis,有了ORM模型,开发者只需要了解Java应用而无需对数据库的相关知识深入理解,ORM提供的规则使得数据库的数据通过配置可以轻易的映射到Java实体类上。
1.3 Mybatis
Hibernate提供了全表映射的模型,使用Hibernate不需要编写sql语句,只需要提供hbm.xml文件提供映射配置规则即可,Hibernate大大的简化了开发,提高了编程的简易性和可读性,但是这种好处也同时带来了巨大的缺点:
- 无法根据条件组合不同的SQL
- 对多表管理和复杂sql,需要自己编写SQL,也需要自己组装POJO
- 不能进行sql性能优化
而Mybatis一个半自动映射型的框架诞生了,Hibernate是全自动因为只需要提供POJO和映射关系即可,而Mybatis需要提供POJO、映射关系和SQL语句

二、Mybatis基本组成
Mybatis的使用应该不成问题,按照官方文档使用即可,在本章的末尾也会给出一个使用的实例,下面介绍Mybatis的基本构成(核心组件)
- SqlSessionFactoryBuilder(构造器):会根据配置信息或者代码(这种方式实不推荐的)来生成SqlSessionFactory(工厂接口)
- SqlSessionFactory:依靠工厂来生成SqlSession(会话)
- SqlSession:是一个即可以发送SQL去执行并返回结果的组件,也可以获取Mapper的接口
- SQL Mapper:它是由一个java接口和XML文件(或注解)构成的,需要给出对应的SQL和映射规则。它负责发送SQL去执行,并返回结果。
SqlSessionFactoryBuilder
SqlSessionFactoryBuilder是利用XML获得资源来构建SqlSessionFactory,一但构建好了SqlSessionFactory,SqlSessionFactoryBuilder就失去了价值,所以SqlSessionFactoryBuilder的生命周期只存在于方法的局部,就是构建SqlSessionFactory对象
SqlSessionFactory
SqlSessionFactory的实例可以通过SqlSessionFactoryBuilder获得。但是需要注意SqlSessionFactory是一个工厂接口而不是实现类,它的任务是创建SqlSession。在创建SqlSessionFactory后,XML配置文件中的信息将会保存在Configuration类对象中,所以SqlSessionFactory应该存在Mybatis的一阵个应用的生命周期中,那么很显然,需要使用单例模式
SqlSessionFactory在Mybatis中具有两个实现类:
- DefaultSqlSessionFactory
- SqlSessionManager
SqlSession
SqlSession是一次会话,相当于JDBC的一个Connection对象。SqlSession是一个接口类,可以看看SqlSession的一些方法,都是一些增删改查,事务,创建连接、关闭链接的方法。SqlSession提供了一个门面,而真正干活的是Executor。
Mapper
Mapper是一个接口,用于发送SQL,这点用过mybatis应该知道,定义sql语句有两种方式使用注解或者使用配置文件的方式,但是都要创建一个dao
上面是简单的介绍一下Mybatis的重要部件,先在大脑里有一个宏观的概念,后面深入理解Mybatis的时候能有更深的理解,下面给出一个使用Mybatis的实例
项目结构:
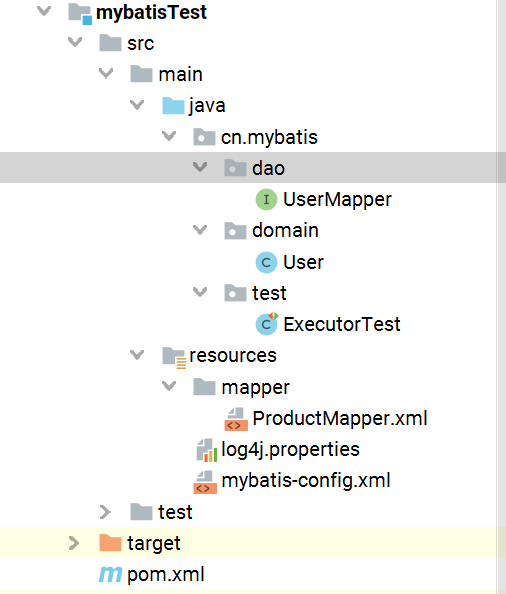
log4j.properties:
log4j.rootLogger=DEBUG,Console
#DEBUG:级别 Console:输出到控制台
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
mybatis-config.xml
<configuration>
<settings>
<setting name="logImpl" value="LOG4J"/>
settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql:///techer"/>
<property name="username" value="root"/>
<property name="password" value="213213"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="mapper/ProductMapper.xml"/>
mappers>
configuration>
UserMapper:
public interface UserMapper {
User findAll();
User findById(Integer id);
}
User:
//get和set方法省略
public class User {
private Integer id;
private String userName;
private String passWord;
}
mapper/ProductMapper.xml
<mapper namespace="cn.mybatis.dao.UserMapper">
<select id="findAll" resultType="cn.mybatis.domain.User" >
select * from tb_user
select>
<select id="findById" resultType="cn.mybatis.domain.User" parameterType="int">
select * from tb_user where id = #{id}
select>
mapper>
ExecutorTest:测试类,main方法
public class ExecutorTest {
@Test
public void testMybatis() throws IOException {
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.findById(1);
System.out.println(user);
}
}
三、配置与映射器
下面来看看Mybatis的配置文件mybatis-config.xml,mybatis-config.xml是具有层次结构的,不能随意颠倒顺序,这块知识只是简单的说明一下,因为是mybatis的使用,百度即可
<configuration>
<porperties/>
<settings/>
<typeAliases/>
<TypeHandlers/>
<objectFactory/>
<plugins/>
<environments>
<environment>
<transactionManager/>
<datasource>
environment>
environments>
<databaseIdProcider>
<mappers/>
configuration>
查看官方文档即可
映射器相关的使用也直接可以参考官方文档。
四、Mybatis的运行原理
在理解Mybatis的运行原理之前,需要有两块的前置知识:反射和动态代理。Mybatis的运行原理总体上分为两部分:
- 读取配置文件到Configuration对象中,这是一个全局的配置文件
- SqlSession的执行过程
4.1 读取配置文件
先思考一个问题:在mybatis的使用中有两个配置文件:mybatis-config.xml和mapper映射文件,那么是不是对应着这两个配置文件中的内容会被解析到两个对象中呢?
下面来读一读Mybatis的源码,首先入口在自己写的代码中:
//创建字节流
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.findById(1);
System.out.println(user);
首先是读取mybatis-config.xml文件这是java基础的代码,前面也简单的说过SqlSessionFactoryBuilder是利用XML获得资源来构建SqlSessionFactory。
读取配置文件获取Configuration对象过程比较清晰但是代码比较复杂,因为通过看配置文件也可以知道,可以配置的标签有很多,这里只是贴出主线代码:
- 加载mybatis-config.xml配置文件
- 加载mapper映射文件
点开builder方法
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
//build(Configuration config)
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
上面代码调用XMLConfigBuilder的parse方法将配置文件解析成Configuration,因为解析配置文件的任务过于复杂,所以将这个任务交给了XMLConfigBuilder,使用了构建者模式,将一个复杂对象的构建与其表示进行分离
接着进入parse方法
//XMLConfigBuilder中的方法
public Configuration parse() {
//避免多次解析
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
可以看到上面代码将要解析配置文件中的configuration节点,那么进入parseConfiguration方法
//XMLConfigBuilder中的方法
private void parseConfiguration(XNode root) {
try {
// issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
parseConfiguration方法中进行了一系列节点的解析,重点是看看mapperElement方法,因为这里解析的是mappers节点,也就是配置mapper映射器的路径的地方
mapper标签可以通过三种方式进行配置:
<mappers>
<mapper resource="mapper/DemoMapper.xml" >mapper>
<mapper class="com.mybatistest.TestMapper"/>
<mapper url=""/>
<package name="com.mybatistest"/>
mappers>
那么解析也会对应着三种方式:
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
因为使用的是resource方式配置的,所以XMLMapperBuilder就成为了解析mapper映射器的构建者类。阅读这块的源码和解析mybatis-config.xml类似,只需要抓住主线代码即可,下面通过一个流程图来总结上面的过程:
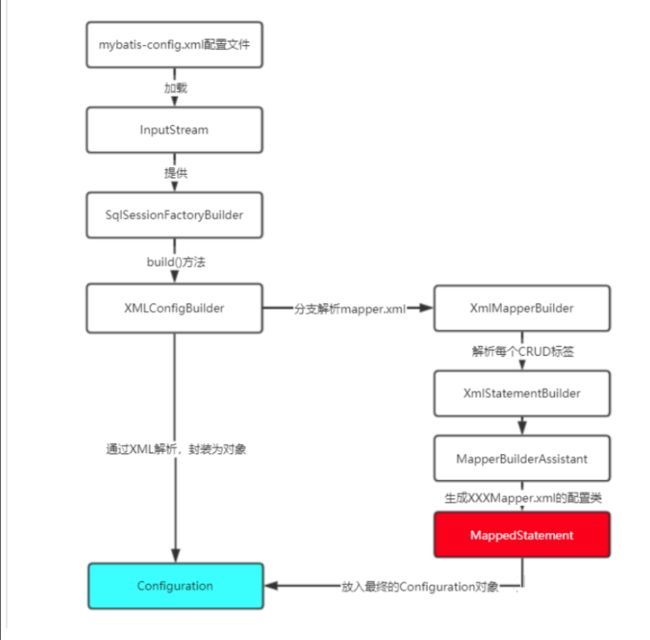
4.2 SqlSession运行流程
前面说的是mybatis读取配置文件的流程,读取配置文件封装成Configuration对象的目的是为了后续执行SQL时能够使用上,Configuration是SqlSessionFactory的一个属性
根据入口代码,现在应该是获取SqlSession:
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
这段源码没有特别之处,主要是对SqlSession进行加工封装、增加了事务,执行器等等,重点是阅读下面的getmapper方法,可想而知我们写的UserMapper是一个接口,但是接口是不能实例化的,所以这段mybatis使用到了动态代理和反射
@SuppressWarnings("unchecked")
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
//MapperProxyFactory 在解析的时候会生成一个map map中会有我们的DemoMapper的Class,所以这里直接get就行
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
knownMappers其实就是一个hashmap,这个map映射了类与MapperProxyFactory的关系,而knownMappers的put阶段在解析配置文件的时候完成的,在XMLMapperBuilder类中的bindMapperForNamespace中完成的
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
接着看newInstance方法,就是JDK的动态代理了,那么invoke方法在第三个参数上,也就是MapperProxy类,所以重点介绍这个类
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
MapperProxy类
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
//具体实例为PlainMethodInvoker
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
上面一堆判断是判断该方法是否为Object自带方法或者是接口中的默认方法,这些都不是我们需要的,继续追踪源码,发现最后执行sql的逻辑是MapperMethod的execute方法
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
//判断是否有返回值
//无放回值
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
//多个返回值
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
//返回map
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
//返回Cursor
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
那么进入executeForMany方法
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {
List<E> result;
Object param = method.convertArgsToSqlCommandParam(args);
//判断分页
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.selectList(command.getName(), param, rowBounds);
} else {
//真正执行sql的方法
result = sqlSession.selectList(command.getName(), param);
}
// issue #510 Collections & arrays support
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
if (method.getReturnType().isArray()) {
return convertToArray(result);
} else {
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
}
return result;
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//MappedStatement:解析XML时生成的对象, 解析某一个SQL 会封装成MappedStatement,里面存放了我们所有执行SQL所需要的信息
MappedStatement ms = configuration.getMappedStatement(statement);
//交给手下执行器去真正执行sql
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
那么接下来的逻辑就是判断是否有缓存,我们知道二级缓存的作用域比一级缓存大,所以会先查询二级缓存然后查询一级缓存最后使用底层的jdbc进行数据库查询,前面也提过SqlSession只是提供了一个门面,而真正执行的是Executor,所以后面章节会单独介绍Executor与缓存相关以及后续的结果集处理

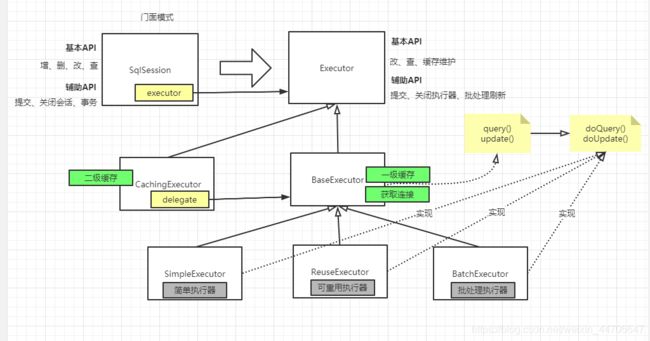
五、执行器
SqlSession提供了一个接口,设置了增删改查、事务相关的方法,但是只是提供了一个接口,提供了一个门面,真正执行的是Executor,ExecutorType下定义了3个执行器:
SIMPLE在每次执行完成后都会关闭statement对象;REUSE会在本地维护一个容器,当前statement创建完成后放入容器中,当下次执行相同的sql时会复用statement对象,执行完毕后也不会关闭;BATCH会将修改操作记录在本地,等待程序触发或有下一次查询时才批量执行修改操作
前面章节介绍过Mybatis的执行分为两步:
- 解析配置文件到Configuration
- 执行sql
而执行器便是执行sql这边的核心组件,下面是Executor的子类图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ve6ONb0J-1614134645336)(http://cdn.noteblogs.cn/image-20210222154044366.png#pic_center)]
在执行sql这个过程中,下面四个组件是必须的:
- **执行器:**Executor, 处理流程的头部,主要负责缓存、事务、批处理。一个执行可用于执行多条SQL。它和SQL处理器是1对N的关系。
- **Sql处理器:**StatementHandler 用于和JDBC打道,比如基于SQL声明Statement、设置参数、然后就是调用Statement来执行。它只能用于一次SQL的执行
- **参数处理器:**ParameterHandler,用于解析SQL参数,并基于参数映射,填充至PrepareStatement。同样它只能用于一次SQL的执行
- **结果集处理器:**ResultSetHandler,用于读取ResultSet 结果集,并基于结果集映射,封装成JAVA对象。他也只用用于一次SQL的执行。
5.1 SimpleExecutor
SimpleExecutor是默认的简单执行器,使用看下面代码
private Configuration configuration;
private Connection connection;
private JdbcTransaction jdbcTransaction;
@Before
public void init() throws Exception {
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("mybatis-config.xml"));
configuration = sessionFactory.getConfiguration();
connection = DriverManager.getConnection(JDBC.URL, JDBC.USERNAME, JDBC.PASSWORD);
jdbcTransaction = new JdbcTransaction(connection);
}
@Test
public void simpleTest() throws SQLException {
SimpleExecutor simpleExecutor = new SimpleExecutor(configuration, jdbcTransaction);
MappedStatement ms = configuration.getMappedStatement("cn.mybatis.dao.UserMapper.findById");
List<Object> list = simpleExecutor.doQuery(ms, 3, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(3));
simpleExecutor.doQuery(ms, 3, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(3));
System.out.println(list.get(0));
}
还记得MappedStatement对象吗?在处理mapper映射器的时候mybatis会将sql的所有信息保存在MappedStatement对象中,所以执行sql是必不可少的,doQuery的参数声明:
- MappedStatement对象保存sql的所有信息
- 参数
- 分页,可以使用RowBounds的默认
- 默认结果处理集
- BoundSql生成sql

可以看到无论sql是否一样,每次都会进行预编译
5.2 ReuseExecutor
ReuseExecutor使用代码和上面一样,ReuseExecutor可重复执行器的特点是,可重复使用JDBC中的Statement,能减少预编译的次数,该执行器会把Statement缓存起来,下次遇到相同的sql,就直接取出来使用,减少预编译的次数
@Test
public void reuseTest() throws SQLException {
ReuseExecutor reuseExecutor = new ReuseExecutor(configuration, jdbcTransaction);
MappedStatement ms = configuration.getMappedStatement("cn.mybatis.dao.UserMapper.findById");
List<Object> list = reuseExecutor.doQuery(ms, 3, RowBounds.DEFAULT, ReuseExecutor.NO_RESULT_HANDLER, ms.getBoundSql(3));
reuseExecutor.doQuery(ms, 3, RowBounds.DEFAULT, ReuseExecutor.NO_RESULT_HANDLER, ms.getBoundSql(3));
System.out.println(list.get(0));
}

可以看到执行两次相同的sql,只使用了一次预编译
5.3 BatchExecutor
BatchExecutor 是批处理执行器,每次的执行操作不会立即进行,而是把对应的Statement填充好参数之后存储起来,当调用flushStatements 的时候会一次性提交到数据库,它可以用于批处理插入的场景,效果相当于SQL的拼装,需要注意的是,JDBC的批处理并不适用于查询语句,例如:
@Test
public void batchTest() throws SQLException{
BatchExecutor batchExecutor = new BatchExecutor(configuration, jdbcTransaction);
MappedStatement ms = configuration.getMappedStatement("cn.mybatis.dao.UserMapper.findById");
List<Object> list = batchExecutor.doQuery(ms, 3, RowBounds.DEFAULT, BatchExecutor.NO_RESULT_HANDLER, ms.getBoundSql(3));
batchExecutor.doQuery(ms, 3, RowBounds.DEFAULT, BatchExecutor.NO_RESULT_HANDLER, ms.getBoundSql(3));
System.out.println(list.get(0));
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OkbImKSh-1614134076750)(http://cdn.noteblogs.cn/image-20210222193345295.png)]可以看到还是预编译了两次,BatchExecutor执行update
5.4 基础执行器
Mybatis是具有一级缓存和二级缓存的,可以发现如果使用上面的方法执行sql,是没有走到缓存相关的逻辑的,而缓存相关的逻辑是在BaseExecutor中实现的,具体结构可见下图

当我们执行query,其实是执行了BaseExecutor中的query方法,里面定义了缓存相关的逻辑
@Test
public void testBase() throws SQLException {
SimpleExecutor simpleExecutor = new SimpleExecutor(configuration, jdbcTransaction);
MappedStatement ms = configuration.getMappedStatement("cn.mybatis.dao.UserMapper.findById");
List<Object> list = simpleExecutor.query(ms, 3, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
simpleExecutor.query(ms, 3, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
System.out.println(list.get(0));
}
将会先去查询一级缓存,如果一级缓存中有那么直接返回结果,如果没有则调用子类执行器SimpleExecutor、ReuseExecutor、BatchExecutor中的query方法,所以上述代码的执行值进行了一次编译sql

下图是BaseExecutor中的query方法

5.5 CachingExecutor
上面提到一级缓存相关的执行逻辑,也就是调用BaseExecutor的query方法,如果一级缓存没有命中则直接调用子类的doQuery方法进行数据库的查询,那么二级缓存呢? CachingExecutor就是二级缓存执行的具体逻辑类
通过前面说SqlSession的运行流程就知道,正常来说实现进行二级缓存的查询,然后进行一级缓存,那么mybatis使用了装饰者模式,在CachingExecutor中有一个delegate指向一级缓存器BaseExecutor
装饰者模式:在不改变原有类的结构和继承的情况下,通过包装原对象区扩展一个新功能
下面来测试一下二级缓存,注意在此之前要开启二级缓存
public void testCache() throws SQLException{
Executor simpleExecutor = new SimpleExecutor(configuration, jdbcTransaction);
MappedStatement ms = configuration.getMappedStatement("cn.mybatis.dao.UserMapper.findById");
CachingExecutor cachingExecutor = new CachingExecutor(simpleExecutor);
List<Object> list = cachingExecutor.query(ms, 3, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
//需要手动提交,这个是必须的
cachingExecutor.commit(true);
cachingExecutor.query(ms, 3, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
cachingExecutor.query(ms, 3, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
cachingExecutor.query(ms, 3, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
System.out.println(list.get(0));
}

可以看到已经执行了二级缓存相关的逻辑,并且命中率也在上升,从代码中也可以看到在new CachingExecutor对象中传入了一个SimpleExecutor作为delegate,进行装饰,那么上述代码的流程为:
CachingExecutor的二级缓存query方法 —> BaseExecutor的query方法 —> SimpleExecutord的doQuery方法
5.6 总结
上面的代码都是直接使用Executor,下面我们通过最基本的方法来回顾上述mybatis的执行器的执行流程
@Test
public void testSqlSession() throws Exception {
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("mybatis-config.xml"));
SqlSession sqlSession = sessionFactory.openSession(true);
List<Object> list = sqlSession.selectList("cn.mybatis.dao.UserMapper.findById", 3);
sqlSession.commit();
sqlSession.selectList("cn.mybatis.dao.UserMapper.findById", 3);
sqlSession.selectList("cn.mybatis.dao.UserMapper.findById", 3);
sqlSession.selectList("cn.mybatis.dao.UserMapper.findById", 3);
System.out.println(list.get(0));
}
SqlSession是一个门面,比如说通过服务员点餐和直接通过大厨点餐是一样的,只不过服务员提供了一个门面,通过debug查看SqlSession的属性

上述代码的执行流程为:
CachingExecutor的query方法(二级缓存) --> BaseExecutor的query(一级缓存) --> SimpleExecutor的doQuery方法(数据库查询)
通过一个图来总结:

六、一级缓存
mybatis是默认开启一级缓存的,一级缓存的作用域是一个会话级别的,但是要想命中一级缓存需要下面几个条件:
- SQL传入参数一致
- 同一个会话(SqlSession对象,一级缓存属于会话级缓存)
- 方法名和类名必须一样(Statement ID必须一样如:com.xxx.XXXMapper.findById())
- 行范围一样 rowbound
- 不手动清空缓存 (-cleanCache -commit rollback)
- 没有Update操作
- 缓存作用域不能是STATEMENT
- 未配置flushCash为false