机器学习第四章之逻辑回归模型
逻辑回归模型
-
- 4.1 逻辑回归模型算法原理
-
- 4.1.1 逻辑回归模型的数学原理(了解)
- 4.1.2 逻辑回归模型的代码实现(重要)
- 4.1.3 逻辑回归模型的深入理解
- 4.2 案例实战 - 股票客户流失预警模型
-
- 4.2.1 案例背景
- 4.2.2 数据读取与变量划分
- 4.2.3 模型搭建与使用
- 4.3 模型评估方法 - ROC曲线与KS曲线
-
- 4.3.1 分类模型的评估方法 - ROC曲线
- 4.3.2 案例实战 - 评估股票客户流失预警模型
- 4.3.3 KS曲线与KS值
- 4.4课程相关资源
这一章主要讲解机器学习中非常经典的逻辑回归模型,包括逻辑回归的算法原理,编程实现等。同时将介绍一个逻辑回归的经典案例:股票客户流失预警模型来巩固所学知识点,最后我们将讲解机器学习中对于分类模型常见的模型评估方法。
点击下载。
4.1 逻辑回归模型算法原理
在上一章我们学习了线性回归模型,线性回归模型是一个回归模型,回归模型是用来进行对连续变量进行预测,如预测收入范围、客户价值等。而逻辑回归模型虽然名字中有回归两字,其本质却是分类模型。分类模型与回归模型的区别在于其预测的变量不是连续的,而是离散的一些类别,以最常见的二分类模型为例,分类模型可以预测一个人是否会违约、客户是否会流失、肿瘤是属于良性肿瘤还是恶性肿瘤等。逻辑回归模型就是一个非常常用的分类模型。
4.1.1 逻辑回归模型的数学原理(了解)
那么既然逻辑回归模型是分类模型,为什么其名字里还含有回归两字呢?这是因为其算法原理中同样涉及了之前线性回归模型中学习到的线性回归方程:
y = k0 + k1*x1 + k2*x2 + k3*x3……
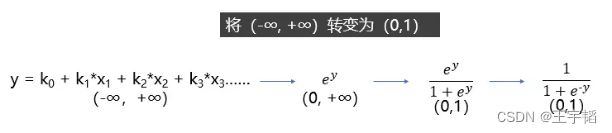
上面这个方程是预测连续变量的,其取值范围属为负无穷到正无穷,而逻辑回归模型是用来预测类别的,比如它预测某物品是属于A类还是B类,它本质预测的是属于A类或者B类的概率,而概率的取值范围是0-1,因此我们不能直接用线性回归方程来预测概率,那么如何把一个取值范围是(-∞, +∞)的回归方程变为取值范围是(0,1)的内容呢?
这就需要到用到下图所示的Sigmoid函数,该函数可以将取值为(-∞, +∞)的数转换到(0,1)之间,例如倘若y=3,那个通过Sigmoid函数转换后,f(y)就变成了1/(1+e^-3)=0.95了,这就可以作为一个概率值使用了。
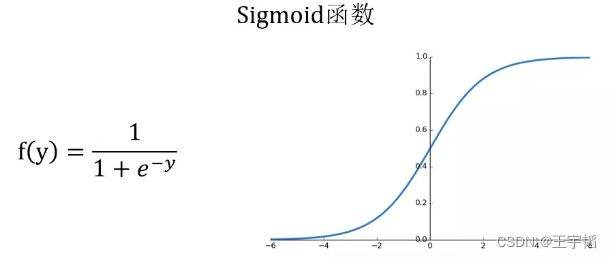
感兴趣的读者可以通过如下代码绘制Sigmoid函数:
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-6, 6) # 通过linspace()函数生成-6到6的等差数列,默认50个数
y = 1.0 / (1.0 + np.exp(-x)) # Sigmoid函数计算公式,exp()函数表示指数函数
plt.plot(x,y)
plt.show()
如果对Sigmoid函数还是感到有点困惑,则可以参考下图的一个推导过程,其中y就是之前提到的线性回归方程,其范围是(-∞, +∞),那么指数函数![]() 的范围便是(0, +∞),再做一次变换,
的范围便是(0, +∞),再做一次变换,![]() 的范围就变成(0, 1)了,然后分子分母同除以
的范围就变成(0, 1)了,然后分子分母同除以![]() 就获得了我们上面提到的Sigmoid函数了。
就获得了我们上面提到的Sigmoid函数了。
总结来说,逻辑回归模型本质就是将线性回归模型通过Sigmoid()函数进行了一个非线性转换得到一个介于0到1之间的概率值,对于二分类问题(分类0和1)而言,其预测分类为1(或者说二分类中数值较大的分类)的概率如下图所示:
![]()
因为概率和为1,则分类为0(或说二分类中数值较小的那个分类)的概率为1-P。
**逻辑回归模型的本质就是预测属于各个分类的概率,有了概率之后,就可以进行分类了。**对于二分类问题来说,比如在预测客户是否会违约的违约预测模型中,如果预测违约的概率P为70%,不违约的概率为30%,违约概率大于不违约概率,那么就可以认为该客户会违约。对于多分类问题来说,逻辑回归模型会预测属于各个分类的概率(各个概率之和为1),然后根据哪个概率最大,判定属于哪个分类。
了解了逻辑回归模型的基本原理后,在实际模型搭建中,就是要找到合适的系数ki和截距项k0使得预测的概率较为准确,在数学中是使用极大似然估计法来确定合适的系数ki和截距项k0,从而得到相应的概率,在Python中则有相应的库将数学方法已经整合好了,我们通过调用相应的模块就能建立逻辑回归模型,从而预测概率进而进行分类,下面我们通过一个简单的案例来通过Python快速搭建逻辑回归模型加深大家对逻辑回归模型的理解。
4.1.2 逻辑回归模型的代码实现(重要)
这里通过一个简单的Python案例来说明逻辑回归中算法原理,数据如下,其中特征变量X中有两个特征变量X1和X2,Y是目标变量,Y的取值为0或1,代表两个不同的分类。以客户违约预测模型为例,大家可以把特征变量X1当作收入,X2当作历史违约次数,目标变量Y当作是否违约,其中0表示不违约,1表示违约。
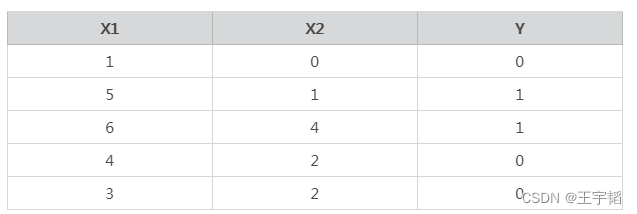
构造数据代码如下:
X = [[1, 0], [5, 1], [6, 4], [4, 2], [3, 2]]
y = [0, 1, 1, 0, 0]
将已有的数据使用逻辑回归模型进行拟合:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, y)
第一行代码从Scikit-Learn库中引入逻辑回归模型:LogisticRegression。
第二行代码将逻辑回归模型赋值给model变量,这里没有设置参数,也即使用默认参数。
第三行代码则是通过fit()函数来进行模型的训练。
训练完模型之后,我们就可以用模型的predict()函数来进行预测分类了,代码如下:
model.predict([[2, 2]]) # 通过predict()函数进行预测
预测结果如下:
[0]
有的读者可能会奇怪为什么上面predict()函数中要写两组中括号,为什么不可以直接写成model.predict([2, 2])呢?这是因为predict()函数默认接受一个多维数据,这个概念在同时预测多个数据时候大家就能更加明白了,同时预测多个数据的代码如下:
model.predict([[1, 0], [5, 1], [6, 4], [4, 2], [3, 2]])
因为这里演示的多个数据和X是一样的,所以也可以直接写成model.predict(X),通过print()函数将其打印输出,结果如下:
[0 1 1 0 0]
可以看到其预测准确度为100%。
这里多提一句,有时使用默认参数运行时,程序运行后会出现下图所示的FutureWarning警告,这个不用在意,它只是在告诉你以后模型的官方默认参数会有所调整而已,并不是报错。
![]()
通常我们会忽视这个警告信息,如果不想看到这个警告信息,可以在代码的最上面加上如下代码忽略警告信息:
import warnings
warnings.filterwarnings('ignore')
4.1.3 逻辑回归模型的深入理解
逻辑回归模型的本质其实是预测概率,而不是直接预测是属于0或1具体的类别,那么通过如下代码就可以获取概率值:
y_pred_proba = model.predict_proba(X)
可以直接将y_pred_proba打印出来,它是一个numpy格式的二维数组,也可以根据2.2.1节数组构造DataFrame的知识点,通过引入pandas库将其通过DataFrame的形式打印出来:
import pandas as pd
a = pd.DataFrame(y_pred_proba, columns=['分类为0的概率', '分类为1的概率'])
将其打印,结果如下,左列是分类为0的概率,右列是分类为1的概率(这里为了数据美观仅保留2位小数)。可以看到其中1、4、5行预测分类为0的概率大于预测为分类1的概率,因此它们被预测为0;第2和3行预测分类为1的概率大于分类为0的概率,所以它们将被预测为分类1,这个也的确和实际相符。

在本案例中,因为每个数据是有两个特征变量,所以逻辑回归计算概率原理的本质就是下图所示的计算公式,注意在二分类模型(0和1两个分类)中,下面这个概率P值默认预测分类为1的概率。

机器学习模型所需要确定就是其中的截距项k0和系数k1和k2,使得预测的概率尽可能准确,通过如下代码便可以获取机器计算出来的截距项k0和系数k1和k2,其中model为之前训练的模型名称,通过coef_属性可以获得特征变量前的系数ki,intercept_属性可以获得截距项k0。
print(model.coef_) # 系数k1与k2
print(model.intercept_) # 截距项k0
结果如下,这里为了数据美观仅保留2位小数。
[[1.01 0.02]] # 系数k1与k2
[-4.60] # 截距项k0
有的读者可能会有疑惑,逻辑回归模型不是会预测每个分类的概率,为什么这里只有一组系数和截距的数据呢?这是因为在二分类模型(0和1两个分类)中,上面的系数和截距默认只展示预测分类为1(或者说数值较大的那个分类)的系数和截距。
获取了系数和截距项后,我们就知道预测为分类为1的概率公式如下所示:
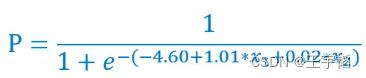
我们以第一个样本数据[1, 0]为例来演示如何获取它分类为1的概率,其两个特征X1和X2分别为1和0,代入如下图所示概率公式,得到预测分类为1的概率为0.40,这个和之前通过model.predict_proba(X)获得的预测概率是一致的。
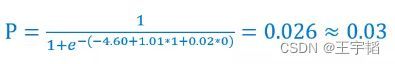
如果想批量查看预测概率,可以通过如下代码进行批量运算,其中np.exp()用来进行指数运算(即e^x),np.dot()用来做数据点乘,即将系数和特征值一一相乘,model.coef_.T中的.T则是将数据进行转置,这个是为了点乘做准备,了解即可。
import numpy as np
for i in range(5): # 这里共有5条数据,所以循环5次
print(1 / (1 + np.exp(-(np.dot(X[i], model.coef_.T) + model.intercept_))))
获取结果如下所示,这个就是预测Y=1的概率。
[0.40123133]
[0.62062798]
[0.61176316]
[0.53758191]
[0.47596374]
对比使用模型自带的predict_proba()函数所得到的分类为1的概率,结果与之一致。这证实了逻辑回归模型的本质即是通过预测概率,从而进行分类。
补充知识点:多分类问题
逻辑回归模型除了可以处理二分类问题外,还可以处理多分类问题,演示代码如下:
# 构造数据,此时y有多个分类
X = [[1, 0], [5, 1], [6, 4], [4, 2], [3, 2]]
y = [-1, 0, 1, 1, 1] # 这里有三个分类-1、0、1
# 模型训练
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, y)
模型训练完成后,我们同样可以利用predict()函数来进行分类预测,代码如下:
print(model.predict([[0, 0]]))
将结果打印如下所示:
[-1]
同样我们可以用predict_proba()函数获取各个分类的概率,代码如下:
y_pred_proba = model.predict_proba([[0, 0]])
此时获取的就是三个分类的概率,将其打印,如下所示:

可以看到预测分类为-1的概率最大,因此数据[0, 0]被预测为分类-1。
这里重点提一下多分类问题中的系数coef_属性和截距intercept_属性,它获取的内容和之前演示的二分类问题略有不同,代码如下:
print(model.coef_) # 系数k1与k2
print(model.intercept_) # 截距项k0
获取结果如下:
[[-0.47930478 -0.47425749] # 分类为-1的系数k1和k2
[ 0.18376302 -0.72762991] # 分类为0的系数k1和k2
[-0.19922975 0.96006181]] # 分类为1的系数k1和k2
[ 0.28698363 -0.42723909 -0.21693287] # 分别对应三种分类的截距
这时可以看到,这里获取的就是各个分类的系数和截距了,而不是像二分类(0和1)问题中只获取预测分类为1的系数和截距了。
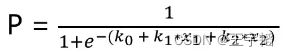


4.2 案例实战 - 股票客户流失预警模型
客户流失预警模型用来预测客户是否会流失,在金融、电信、娱乐游戏等行业都有广泛的应用,这一节以金融行业的股票客户流失预警模型为例来讲解逻辑回归模型在商业实战中的应用。
4.2.1 案例背景
在进行每一笔股票交易的时候,交易者(股民)都是要付给开户所在的证券公司一些手续费的,虽然单笔交易的手续费并不高,然而股票市场每日都有巨额的成交量,使得每一笔交易的手续费汇总起来的数目相当可观,而这一部分收入对于一些证券公司来说很重要,甚至可以占到所有营业收入50%以上,因此证券公司对于客户(也即交易者)的忠诚度和活跃度是很看重的。
如果一个客户不再通过该证券公司交易,也即该客户流失了,那么对于证券公司来说便损失了一个收入来源,因此证券公司会搭建一套客户流失预警模型来预测交易者是否会流失,从而对于流失概率较大的客户进行相应的挽回措施,因为通常情况下,获得新客户的成本比保留现有客户的成本要高的多。
4.2.2 数据读取与变量划分
这里首先通过pandas库来读取数据,并将变量划分为特征变量和目标变量。
1.读取数据
这里通过如下代码读取数据,其中df.head()用来展示前5行数据。
import pandas as pd
df = pd.read_excel('股票客户流失.xlsx')
df.head()
运行结果如下表所示,其中共有7000组左右的历史数据,约2000组为流失客户,约5000组为未流失客户。账户资金就是客户通过证券公司用来炒股的金额,交易佣金也即手续费,券商即证券公司,因为Python数学建模中无法识别文本内容,所以“是否流失”栏中的内容已经进行了数值处理:0表示未流失,1表示流失(我们将在11.1小节讲解如何进行文本内容数据预处理)。
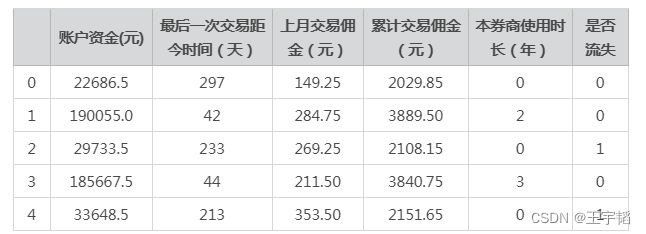
我们将把是否流失这一项作为目标变量,剩下的字段作为特征变量,通过一个股票交易者的的一些基本情况和交易记录来判断他是否会流失,或者说流失的概率。这里为了方便演示,只选取了5个特征变量,在商业实战中,用到的特征变量则多的多。
2.划分特征变量和目标变量
通过如下代码将特征变量和目标变量单独提取出来,代码如下:
X = df.drop(columns='是否流失')
y = df['是否流失']
这里通过drop()函数删除“是否流失”这一列,将剩下的数据作为特征变量赋值给变量X。然后通过DataFrame提取列的方式提取“是否流失”这一列作为目标变量,并赋值给变量y。
4.2.3 模型搭建与使用
读取完数据并划分好变量后就可以进行模型的搭建和使用了。
1.划分训练集和测试集
和之前线性回归模型稍微不同的是,在本章及之后的章节中,在进行模型搭建和使用前都会将数据分成训练集数据(简称训练集)和测试集数据(简称测试集)。顾名思义,训练集是用来训练数据从而搭建模型的,而测试集就是拿来检验训练后搭建的模型的效果。划分训练集和测试集的目的一是为了对模型进行评估,二是可以通过测试集对模型进行调优。
通过如下代码可以将数据分为训练集和测试集:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
第一行代码便是从Scikit-Learn库中引入train_test_split()函数。
第二行代码通过train_test_split()函数进行训练集合测试集的划分,其中X_train,y_train为训练集的特征变量和目标变量数据,X_test,y_test则为测试集中的特征变量和目标变量数据。其中train_test_split()函数的X和y便是之前的特征变量和目标变量;test_size则是测试集数据所占的比例,这里选择的是20%,也即0.2。
test_size补充知识点:
通常我们会根据样本量的大小来划分训练集和测试集,当样本量大的时候,可以划分多一点的比例的数据给训练集,比如有10万组数据的时候,我们可以设定9:1的比例来划分训练集和测试集。这里有7000多个数据,并不算多,所以按8:2的比例来划分训练集和测试集。
数据的划分是随机的,我们可以通过print(X_train)这样的代码将划分后的训练集和测试集数据打印出来看下(如果是在第一章讲的Jupyter Notebook中运行,那么在代码框中直接输入X_trian即可查看相关数据),此时的训练集和测试集数据如下图所示:
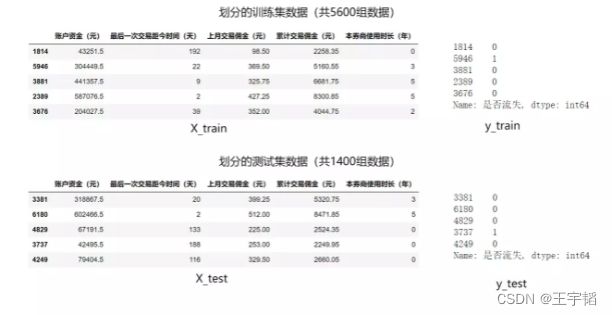
因为每次运行程序时,train_test_split()函数都是随机划分数据的,如果想每次划分数据产生的内容都是一致的,可以设置random_state参数,代码如下:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
其中random_state的数字1没有特殊含义,可以换成别的数字,它只是相当于一个种子参数,使得这样每次划分数据的时候,内容都是一致的。
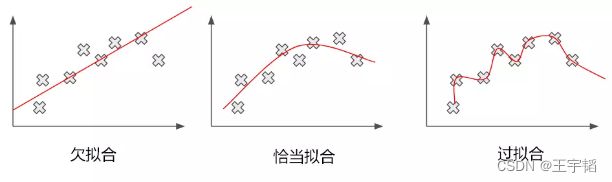
补充知识点:过拟合与欠拟合
这里再补充讲解下引入测试数据集的一个原因:用来查看模拟是否出现过拟合现象。
如下图所示,所谓过度拟合(简称过拟合),是指模型在训练样本中拟合程度过高,虽然它很好地贴合了训练集数据,但是却丧失了泛化能力,模型不具有推广性(即如果换了训练集以外的数据就达不到较好的预测效果),导致在测试数据集中表现不佳,例如每次模考都做同一份卷子,训练的时候得分很高,但是期末考试换了套卷子就得分很低。此外与过拟合相对的则是欠拟合,欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
2.模型搭建
模型搭建的过程相对比较容易,通过如下代码即可搭建逻辑回归模型。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
第一行代码从Scikit-Learn库中引入逻辑回归模型:LogisticRegression。
第二行代码将逻辑回归模型赋值给model变量,这里没有设置参数,也即使用默认参数。
第三行代码则是通过fit()函数来进行模型的训练,其中传入的参数就是上一步骤获得的训练集数据X_train, y_train。
至此,一个逻辑回归模型其实便已经搭建完成了,模型搭建完成后就可以利用模型来进行预测了,此时之前划分的测试集就可以发挥作用了,我们可以利用测试集来进行预测并评估模型的预测效果。
3.模型使用1 - 预测数据结果
搭建模型的目的便是希望利用它来预测数据,这里把测试集中的数据导入到模型中来进行预测,代码如下,其中model就是上面搭建的逻辑回归模型。
y_pred = model.predict(X_test)
通过打印y_pred[0:100]来查看预测的前100项数据,如下图所示,0和1为预测的结果,0为预测不会流失,1为预测会流失。

利用2.1.1节pandas库创建DataFrame相关知识点,将预测的y_pred和测试集实际的y_test汇总到一起,其中y_pred是一个numpy.ndarray一维数组结构,y_test为Series一维序列结构,所以这里都用list()函数将其转换为列表,代码如下:
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
可以通过a.head()查看表格前5行,此时生成的对比表格如下所示:
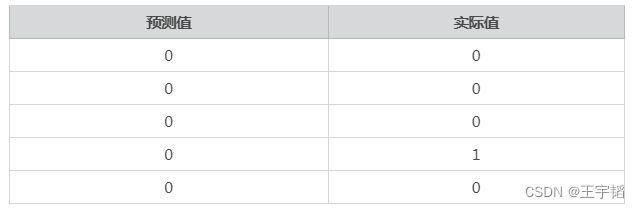
可以看到此时前五项的预测准确度为80%,如果想看所有测试集数据的预测准确度,可以使用如下代码:
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
其中第一行引入可以计算准确度的accuracy_score()函数,然后第二行将预测值y_pred和实际值y_test传入accuracy_score()函数的括号中,便可以计算预测的准确度,将score打印输出,发现score的值为0.7977,也即预测准确度为79.77%,说明在近1400个测试数据中,共有约1117个数据预测正确,283个数据预测错误。
此外,除了通过accuracy_score函数外,我们还可以通过模型自带的score函数来获取准确度评分,代码如下:
model.score(X_test, y_test)
将其打印,结果同样为0.7977。
4.模型使用2 - 预测概率
我们之前讲过,逻辑回归模型的本质其实是预测概率,而不是直接预测是属于0或1具体的类别,那么通过如下代码就可以获取概率值:
y_pred_proba = model.predict_proba(X_test)
通过y_pred_proba[0:5]将概率的前五项打印出来是个多维数组,数组左列是不流失(分类为0)概率,右侧是流失(分类为1)概率。或者通过如下代码进行更加美观的整理:
a = pd.DataFrame(y_pred_proba, columns=['不流失概率', '流失概率'])
通过打印a.head()查看前5行,结果如下:
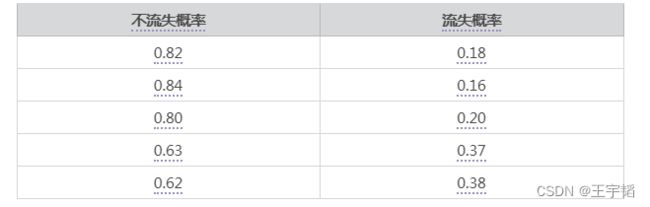
可以看到前五组数据的不流失概率(分类为0)都大于50%,都大于流失(分类为1)的概率,因此这五组数据都会判定为不流失。
如果只查看流失的概率(分类为1的概率),可采用如下代码,中括号[:,1]中第一个元素“:”表示二维数组所有行,第二个元素“1”表示二维数组第二列(也即分类为1,表示流失概率的那列),如果把“1”换成“0”,则表示数组第一列(Python中序号从0开始):
y_pred_proba[:,1]
5.查看逻辑回归系数
在4.1.1小节我们讲过逻辑回归模型本质就是将线性回归模型通过Sigmoid()函数进行了一个非线性转换,这里共有5个特征变量,所以其预测y=1的概率P如下所示:
![]()
通过以下代码可以查看上面公式中的系数和截距项,其中model为之前训练的模型名称,coef_属性可以获得变量前的系数ki,intercept_属性可以获得截距项k0。
print(model.coef_) # 系数ki
print(model.intercept_) # 截距项k0
获取结果如下所示,其中e-05表示10^-5,其余依次类推,这里为数据美观,仅保留2位小数。可以看到这里的系数ki共有5个,也即对应5个特征变量前的系数。
[[ 2.42e-05 8.17e-03 1.04e-02 -2.53e-03 -1.10e-04]]
[-1.43e-06]
在4.2.3节我们查看了测试集数据,其中第一条测试集数据如下:
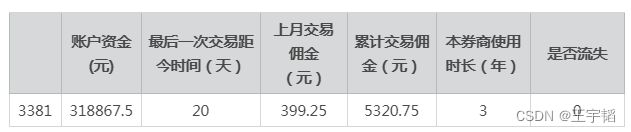
我们可以将5列特征变量数据代入公式,计算得其预测为y=1的概率为0.18,也即预测其流失的概率为0.18,该概率小于0.5,所以可以判断该客户不会流失,预测正确。
如果想批量查看测试集数据的预测概率,可以通过4.1.3节相关代码进行批量运算,其中np.exp()用来进行指数运算(即e^x),np.dot()用来做数据点乘,即将系数和特征值一一相乘,iloc[i]用来选取DataFrame的行数据,可以参考2.2.3节相关知识点。
import numpy as np
for i in range(5): # 这里演示前5条测试集数据的预测流失的概率
print(1 / (1 + np.exp(-(np.dot(X_test.iloc[i], model.coef_.T) + model.intercept_))))
获取结果如下所示,这个就是预测y=1的概率,也即预测流失的概率,可以看到和之前通过model.predict_proba(X_test)获取的结果是一致的。
[0.17958509]
[0.15970387]
[0.20180658]
[0.37010808]
[0.38363389]
这里将上面的代码进行简单的汇总,如下所示:
# 1.读取数据
import pandas as pd
df = pd.read_excel('股票客户流失.xlsx')
# 2.划分特征变量和目标变量
X = df.drop(columns='是否流失')
y = df['是否流失']
# 3.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 4.模型搭建
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# 5.模型使用1 - 预测数据结果
y_pred = model.predict(X_test)
print(y_pred[0:100]) # 打印预测内容的前100个看看
# 查看全部的预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)
# 6.模型使用2 - 预测概率
y_pred_proba = model.predict_proba(X_test)
print(y_pred_proba[0:5])
4.3 模型评估方法 - ROC曲线与KS曲线
模型搭建完成后,我们还需要对模型的优劣进行评估,对于二分类模型来说,主流的评估方法有ROC曲线和KS曲线两种方法,这里我们先主要讲解ROC曲线的基本原理,并用ROC曲线来评估上一小节搭建的股票客户流失预警模型。
4.3.1 分类模型的评估方法 - ROC曲线
我们之前已经获得了模型的准确度为79.77%,但是这个准确度并不可靠,因为如果预测所有人都不会流失,那么由于7000组数据里实际便有5000组未流失数据,如果这样预测的话,也能达到5000/7000约71%的准确度,显然这个较高的准确度是没有意义的,因为它一个可能流失的人都没有预测出来。在商业实战中,我们更关心下面两个指标:

其中TP、FP、TN、FN的含义如下表所示,这个表也叫作混淆矩阵。
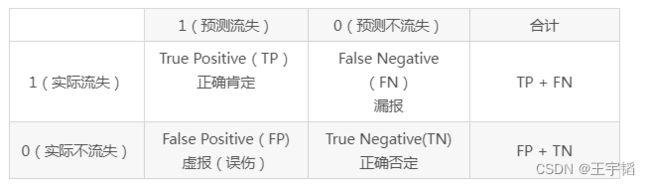
以上面提到的例子为例,7000客户中有2000个流失,5000个不流失客户,假设模型预测所有客户都不会流失,如下表所示,那么模型的假警报率(FPR)为0,即没有误伤一个未流失客户,但是此时模型的命中率(TPR)也为0,即没有揪出一个流失客户。
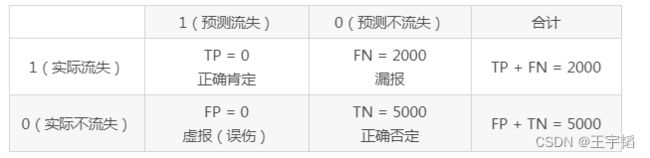
总结来说,命中率计算的便是在所有实际流失的人中,预测为流失的比例,也称真正率或召回率;而假警报率则是计算在所有实际没有流失的人当中,预测为流失的比例,也称假正率。为加深大家的理解,笔者绘制了如下的图片方便大家记忆:

一个优秀的客户流失预警模型,我们希望命中率(TPR)尽可能的高,即能尽量地揪出潜在流失客户,同时也希望假警报率(FPR)能尽可能的低,即不要把未流失客户误判断为流失客户。(不要误伤好人,也不要放过坏人)
然而这两者往往成正相关性,因为一旦调高阈值,比如认为流失的概率率超过90%的才认定为流失,那么会导致假警报率很低,但是命中率也很低;而降低阈值,比如认为流失的概率超过10%就认定为流失,那么命中率就会很高,但是假警报率也会很高。因此为了衡量一个模型的优劣,数据科学家根据不同阈值下的命中率和假警报率绘制了ROC曲线图,如下图所示。
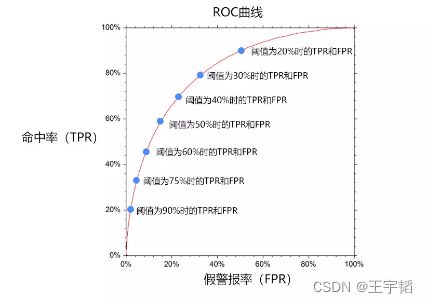
ROC曲线的横坐标为假警报率(FPR),其纵坐标为命中率(TPR),在某一个阈值条件下,我们希望命中率能尽可能的高,而假警报率尽可能的低。
举例来说,某一检测样本总量为100,其中流失客户为20人,未流失客户为80人,当阈值为20%的时候,即流失概率超过20%的时候即认为客户会流失时,模型A和模型B预测出来的流失客户都是15人。
如果模型A预测流失的15人中有10人的确流失,有5人属于误判,那么命中率达10/20=50%,此时假警报率为5/80=6.25%;
如果模型B预测流失的15人中只有5人的确流失,有10人属于误判,那么其命中率为5/20=25%,假警报率为10/80=12.5%。
此时模型A的命中率是模型B的2倍,假警报率是模型B的一半,因此我们认为模型A是一个较优的模型。总的来说,对于不同模型,我们希望在相同的阈值条件下命中率越高,假警报率越低。
如果把假警报率理解为代价的话,那么命中率就是收益,所以也可以说在相同阈值的情况下,我们希望假警报率(代价)尽量小的情况下,命中率(收益)尽量的高,该思想反映在图形上就是这个曲线尽可能的陡峭,曲线越靠近左上角说明在同样的阈值条件下,命中率越高,假警报率越小,模型越完善。换一个角度来理解,一个完美的模型是在不同的阈值下,假警报率(FPR)都接近于0,而命中率(TPR)接近于1,该特征反映在图形上,就是曲线非常接近(0,1)这个点,也即曲线非常陡峭。
补充知识点:混淆矩阵的Python代码实现
这里简单提一下如何通过Python查看混淆矩阵,代码如下:
from sklearn.metrics import confusion_matrix
m = confusion_matrix(y_test, y_pred) # 传入预测值和真实值
将m打印,获得结果如下,它是一个2行2列的二维数组。
[[968 93]
[192 156]]
其中第一行为实际分类为0的数量,第二行为实际分类为1的数量;第一列为预测分类为0的数量,第二列为预测分类为1的数量。我们用如下代码给表格添加行列索引:
a = pd.DataFrame(m, index=['0(实际不流失)', '1(实际流失)'], columns=['0(预测不流失)', '1(预测流失)'])
将a打印,获取结果如下表所示,需要注意一下的是,通过Python获得的行列顺序和4.3.1节开头讲解原理时使用的表格结构略有不同,这里是先展示的分类为0的情况,而讲解原理时使用的表格是先展示的分类为1的情况。

可以看到实际流失的348人中(192+156)中有156人被准确预测,因此命中率(TPR)为45%,实际未流失的1061人中有93人被误判为流失,因此假警报率(FPR)为8.7%,此外注意这里的TPR和FPR都是基于50%阈值情况下的。
我们还可以通过如下代码打印查看命中率情况,而无需手动计算:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred)) p# 传入预测值和真实值
获得结果如下图所示,其中recall对应的就是之前所说的命中率,也称之为召回率,可以看到对于分类为1的命中率为0.45,和我们之前手动计算的一样。

这边也简单提一下其他获得的内容:下方的accuracy表示的是整体的准确度,这里显示的结果为0.8,和4.2.3节中获得的0.7977是一致的。support则表示样本数量,其中1061表示实际分类0的样本数,348为实际分类为1的样本数,1409则表示测试集全部样本数。此外,这里还有两个之前没提到过的性能度量指标,其中一个是precision(精准率),另外一个为f1-score,两者的计算公式及含义如下所示,这两个指标相对于命中率(TPR)和假警报率(FPR)的重要性要低很多,所以简单了解即可。

4.3.2 案例实战 - 评估股票客户流失预警模型
上面我们讲解了ROC曲线的原理,这一小节我们便通过之前搭建的股票客户流失预警模型作为案例来讲解下如何在实战中应用ROC曲线。
上一节提到过,在商业实战中,我们希望在相同阈值的情况下,假警报率尽量小,命中率尽可能的高,该思想反映在图形上,就是曲线非常接近(0,1)这个点,也即曲线非常陡峭。
曲线的描述相对还是比较抽象,在数值比较上我们可以使用AUC值来衡量模型的好坏,AUC值(Area Under Curve)指在ROC曲线下面的面积,该面积的取值范围通常为0.5到1,0.5表示随机判断,1则代表完美的模型(其实实际中也不是特别高,就好,可能这个模型有点问题)。在商业实战中,因为存在很多扰动因子,AUC值能达到0.75以上就已经可以接受了,如果能达到0.85以上,则为非常不错的模型了。
在Python实现上,通过如下代码就可以求出在不同阈值下的命中率(TPR)以及假警报率(FPR)的值,从而可以绘制ROC曲线。
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test, y_pred_proba[:,1])
其中第一行代码引入roc_curve()函数。第二行代码传入测试集目标变量y_test的值,及4.2.3节讲过的预测的流失概率y_pred_proba[:,1],然后通过roc_curve()函数计算出不同阈值下的命中率和假警报率,并将三者赋值给变量fpr(假警报率)、tpr(命中率)、thres(阈值),此时获得fpr、tpr、thres为三个一维数组。注意roc_curve()函数返回的是一个含有3个元素的元组,其中默认第一个元素为假警报率、第二个元素为命中率,第三个元素为阈值,所以在第二行代码中写变量顺序的时候要按fpr、tpr、thres的顺序来写。
通过如下代码可以将三者合并成一个二维数据表,代码如下:
a = pd.DataFrame() # 创建一个空DataFrame
a['阈值'] = list(thres)
a['假警报率'] = list(fpr)
a['命中率'] = list(tpr)
通过打印a.head()和a.tail()便可以查看在不同阈值下的假警报率和命中率,如下表所示:

可以看到随着阈值降低,命中率在上升、假警报率也在上升。
该表格中还有几个注意的点:
1.第一行的阈值表示只有当一个客户被预测流失的概率>=193%,才判定其会流失,但因为概率不会超过100%,所以此时不会有人被判定为流失,即所有人都不会被预测为流失,那么命中率和假警报率都为0,所以第一行的阈值其实没有什么意义,那为什么还要设置它呢,这个是roc_curve函数的默认设置,下面是它的官方介绍:

其中文含义是第一个阈值没有含义,其往往设置为最大的阈值(本案例中为0.9303)+1,保证没有任何记录被选中,了解即可。至于阈值是如何产生的,可以参考本节的补充知识点。
2.第二行表示只有当一个客户预测为流失的概率>=93.03%,才判定其会流失,这个条件还是比较苛刻,此时被预测为流失的人还是很少,命中率TPR为0.0028,也即“预测为流失且实际流失的人/实际流失的人”这一比率为0.0028,假设此时共有5000组实际流失的客户,那么在该阈值条件下,实际流失的客户中会有5000*0.0028=14人被准确判断为会流失,这个也是命中率一词的由来。此时假警报率FPR为0,也即“预测为流失但实际未流失的人/实际未流失的人”这一比率为0,即实际未流失的人中不会有人被误判为流失。之后的内容含义可以仿照第二行内容的含义解释以此类推。
已知了不同阈值下的假警报率和命中率,可通过2.3.1小节Matplotlib库相关知识点绘制ROC曲线,代码如下:
import matplotlib.pyplot as plt
plt.plot(fpr, tpr) # 通过plot()函数绘制折线图
plt.title('ROC') # 添加标题
plt.xlabel('FPR') # 添加X轴标签
plt.ylabel('TPR') # 添加Y轴标签
plt.show()
绘制的ROC曲线如下图所示:
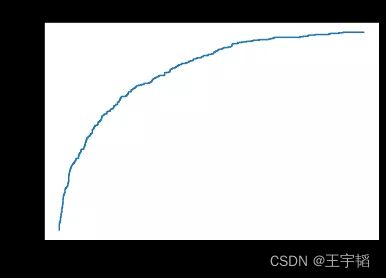
而通过如下代码则可以快速求出模型的AUC值:
from sklearn.metrics import roc_auc_score
score = roc_auc_score(y_test, y_pred_proba[:,1])
其中第一行代码引入roc_auc_score()函数。第二行代码传入测试集目标变量y_test的值,以及预测的流失概率。将获得AUC值打印出来为:0.81,可以说预测效果还是不错的。
补充知识点:对阈值取值的理解
我们上面已经知道假警报率和命中率是根据阈值计算而来的,那么阈值是如何取值的呢?例如下表中第二个阈值为什么取值为0.930369,这个数字有什么特殊的含义嘛?

这些阈值并不是无缘无故来的,在测试样本中,对预测为分类为1的概率进行排序,通过2.2.3节sort_values函数相关知识点,并设置ascending参数为False使得倒序排列,代码如下:
a = pd.DataFrame(y_pred_proba, columns=['分类为0的概率', '分类为1的概率'])
a = a.sort_values('分类为1概率', ascending=False)
通过a.head(15)可以查看前15行的数据,如下表所示(有些不重要的数据用……代替了):
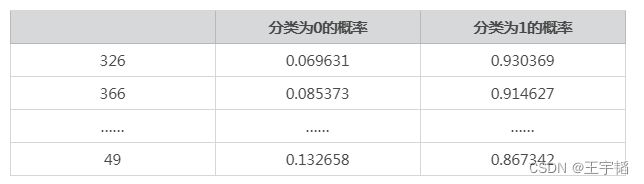
其中第一列为测试集样本的序号,后两列为其分类为0和分类为1的概率,可以看到序号326的样本其分类为1的概率最高,为0.930369,这个也就是之前提到的阈值(也是除1.9303外实际中最大的阈值)。有了这个数值后,便是以此为阈值,对所有样本进行分类,分类为1的概率小于该阈值的都被分为分类0,大于等于该阈值的都被分为分类1,因为只有序号326满足分类为1的概率大于等于该阈值,因此此时只有1个样本会被分类为1(事实上序号326样本也的确为分类1),其余样本都分类为0,在4.3.1节的补充知识点中我们知道一共有348个实际分类为1的样本,所以此时命中率(TPR)为1/348=0.002874,与通过程序获得结果是一致的。
再举个例子,序号49的样本其分类为1的概率为0.867342,从之前的表格发现其是除1.9303外第二大的阈值,然后序号49排在第12位,因此大于等于该概率的共有12个样本,因此这12个样本会被分类为分类1(这12个样本实际也为分类1),其余样本则被分类为分类0,此时的命中率(TPR)为12/348=0.034483,也与通过程序获得结果是一致的。
至此,我们可以得出结论,这些阈值都是各个样本分类为1的概率(其实并没有全部都取,例如序号366分类为1的概率就没有被拿来当作阈值)。
4.3.3 KS曲线与KS值
这里再补充一个分类模型的常用评估方法:KS曲线与KS值。对于二分类模型,业内经常使用ROC曲线和KS曲线来衡量预测的效果。这里我们先讲解KS曲线和KS值的基本原理,并用KS曲线和KS值来评估之前搭建的股票客户流失预警模型。
1.二分类模型的另一种评估方法 - KS曲线与KS值
KS曲线和ROC曲线的本质其实是相同的,同样关注命中率(TPR)和假警报率(FPR),希望命中率(TPR)尽可能的高,即能尽可能地揪出潜在流失客户,同时也希望假警报率(FPR)能尽可能的低,即不要把未流失客户误判断为流失客户。
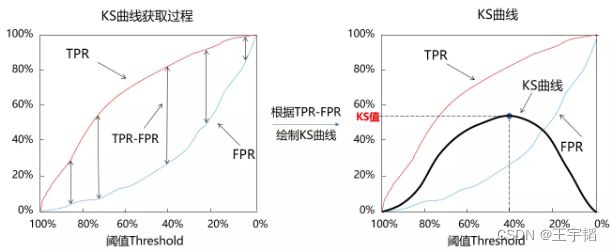
区别于ROC曲线将假警报率(FPR)作为横轴,命中率(TPR)作为纵轴,KS曲线的横坐标为阈值,其纵坐标为命中率(TPR)与假警报率(FPR)之差,如下图所示:

初学者看KS曲线往往会有些费劲,为方便读者理解,笔者绘制了如下KS曲线获取过程图和KS曲线图:这里首先将阈值从大到小进行排序,计算不同阈值下的TPR和FPR,并以阈值为横坐标,分别以TPR和FPR的值为纵坐标画出两条曲线,如下图左边所示,注意这里为了图片美观,阈值是从大到小排序的(因为当阈值为100%时对应的TPR和FPR都是0,当阈值为0%时,对应的TPR和FPR都是100%)。然后我们根据TPR-FPR的差值绘制下图右边的KS曲线。
和ROC曲线一样,除了可视化的图像外,我们还需要一个可以量化的指标来衡量模型预测效果,与ROC曲线对应的是AUC值,而与KS曲线相对应的就是KS值。KS值的定义如下所示:
![]()
图片: https://uploader.shimo.im/f/bL5LVA3iWmIrUuOZ.png!thumbnail?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2NjAyMTEyOTIsImZpbGVHVUlEIjoiaFJLa1Z5aDlYcUdYNmQ5eCIsImlhdCI6MTY2MDIxMDk5MiwiaXNzIjoidXBsb2FkZXJfYWNjZXNzX3Jlc291cmNlIiwidXNlcklkIjoyNzQzNDczMH0.WfwISY1AI4JPo8JhNVvmuJ1ArULOXxgSHGvLsBLynZo
这个值就是KS曲线的峰值,具体来说,每一个阈值都对应一个(TPR-FPR),那么一定存在一个阈值,使得在该阈值条件下,(TPR-FPR)的值最大,那么此时的(TPR-FPR)的值便称为KS值。例如上图中当阈值等于40%时,命中率(TPR)为80%,假警报率(FPR)为25%,所以(TPR-FPR)为55%,该值是所有不同阈值条件下(TPR-FPR)中最大的,因此此时这个模型的KS值就是55%。
通俗的来说,就是该模型在阈值为40%的时候,它能尽可能地识别坏人,并尽可能的不误伤好人,此时命中率(TPR)减去假警报率(FPR)的差值为55%,即为该模型的KS值。
通常来说,我们希望模型有较大的KS值,较大的KS值说明模型有较强的区分能力,其处在不同范围的模型的含义如下所示:
KS值小于0.2,一般认为模型区分能力较弱。
KS值在[0.2,0.3]区间内,模型具有一定区分能力。
KS值在[0.3,0.5]区间内,模型具有较强的区分能力。
但KS值也不是越大越好,如果KS值大于0.75,往往表示模型有异常。其实在真正的生产实际中,KS值处于[0.2,0.3]区间类,就已经挺不错了。
2.案例实战 - 评估股票客户流失预警模型
上面我们讲解了KS曲线与KS值的原理,这里便通过之前搭建的股票客户流失预警模型作为案例来讲解下如何在实战中应用KS曲线与KS值。
在Python实现上,与ROC曲线的绘制相同,仍然通过如下代码求出在不同阈值下的假警报率(FPR)以及命中率(TPR)的值,从这里我们也可以看出KS曲线和ROC曲线其实是同根同源的。
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test, y_pred_proba[:,1])
我们通过和绘制ROC曲线一样的代码整理此时的阈值、命中率、假警报率,代码如下:
a = pd.DataFrame() # 创建一个空DataFrame
a['阈值'] = list(thres)
a['假警报率'] = list(fpr)
a['命中率'] = list(tpr)
此时获取表格如下表所示:
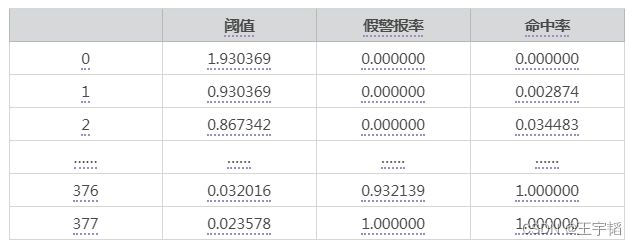
已知了不同阈值下的假警报率和命中率,可通过2.3.1小节Matplotlib库相关知识点绘制KS曲线,代码如下:
plt.plot(thres[1:], tpr[1:])
plt.plot(thres[1:], fpr[1:])
plt.plot(thres[1:], tpr[1:] - fpr[1:])
plt.xlabel('threshold')
plt.legend(['tpr', 'fpr', 'tpr-fpr'])
plt.gca().invert_xaxis()
plt.show()
第1行代码,第2行代码和第3行代码分别以阈值为x轴,以命中率,假报警率及两者之差绘制曲线,因为表格第一行中的第一个阈值大于1,无意义,在绘图过程中会导致图像不美观,所以通过切片的方式将第一行的信息剔除,其中thres[1:]、tpr[1:]、f
pr[1:]都表示相关内容从第二个元素到最后的信息;
第4行代码给x轴加上threshold的标签;
第5行代码给图片加上图例;
第6行代码反转X轴,即把阈值从大到小排序再绘制KS曲线,这个之前讲解原理的时候也提到过,为了图像美观,KS曲线中的横轴为从大到小排序的阈值。具体来说,这里通过gca()函数(gca代表get current axes)获取坐标轴信息,然后通过invert_xaxis()函数反转X轴。
绘制的KS曲线如下图所示:

通过如下代码则可以快速求出KS值:
max(tpr - fpr)
将该KS值打印出来为:0.4744,KS值在[0.3,0.5]区间内,因此模型具有较强的区分能力。
补充知识点:KS值对应的阈值
有的读者可能还想知道此时该KS值对应的阈值是多少,这里补充讲解下如何获取KS值对应的阈值,我们利用2.2.3小节pandas表格运算的相关知识点算出每一个阈值对应的(TPR-FPR),代码如下:
a['TPR-FPR'] = a['命中率'] - a['假警报率']
a.head()
通过a.head()查看此时表格前5行,如下表所示:
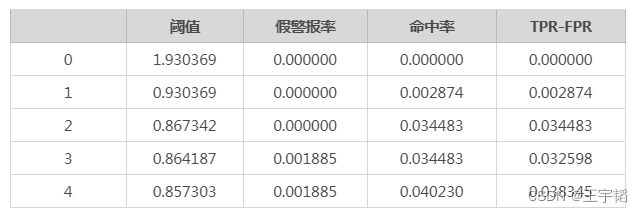
有了这么一张表格后,通过如下代码便可以同样获取KS值了:
max(a['TPR-FPR'])
获取结果如下所示,和之前通过max(tpr - fpr)获取的结果是一致的。
0.474466
通过2.2.3小节pandas库按照特定条件筛选表格相关知识点,我们可以通过如下代码获取该KS值对应的阈值信息,代码如下:
a[a['TPR-FPR'] == max(a['TPR-FPR'])]
获取信息如下所示:

那么此时我们便知道该KS值对应的阈值为0.27769了。
自此逻辑回归模型的基础知识我们就讲解完毕了,其实除了进行模型评估外,通过测试集我们还能进行模型调优,最常用的就是利用测试集进行参数调优,关于参数调优的内容我们在下一章节决策树模型中进行讲解。
总的来说,逻辑回归模型是一个非常重要的机器学习模型,在商业实战中有着广泛的应用场景,如银行信贷场景中的信用评分卡模型运用的就是逻辑回归模型,如果想从事银行行业中的大数据风控,那么就一定得好好掌握逻辑回归模型,此外在第十一章我们还会讨论数据分箱以及如何通过WOE值和IV值进行特征筛选,这个在实际的银行信贷大数据风控中也常和逻辑回归模型一起使用,感兴趣的读者可以进行参考。
多分类下的ROC曲线和AUC:
多分类下的ROC曲线和AUC
点击下载。

4.4课程相关资源
点击获取。