目标检测Neck总结
特征金字塔
特征金字塔是目前用于目标检测、语义分割、行为识别等方面比较重要的一个部分,对于提高模型性能具有非常好的表现,因为视觉任务中存在不同尺寸的物体,而cnn特征提取层级化结构的特点,因此需要在不同level层检测不同尺寸大小的物体。特征金字塔具有在不同尺度下有不同分辨率的特点,不同大小的目标都可以在相应的尺度下拥有合适的特征表示,通过融合多尺度信息,在不同尺度下对不同大小的目标进行预测,从而很好地提升了模型的性能。
两种构建特征金字塔的方式:
- 通过多次降采样生成不同分辨率的层构成,这种方式应用比较广,比较常见的应用有SSD, FPN, YOLO_v3, …此外还有很多。
- 通过多条具有不同空洞率的空洞卷积的支路来构建。目前这方面的应用有ASPP, RFP等。
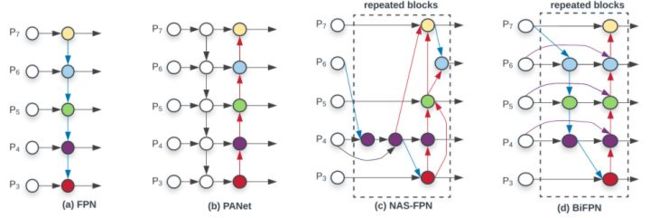
构建金字塔只是个基础操作,对于构建后的处理才是重点,目前有多种多样的方法去处理,这方面的改进主要有ASFF, PANet, FPT, YOLOF, BiFPN, STDN等。
ASPP
ASPP是通过并联不同空洞率 3 * 3的卷积核组成的,通过多支路后进行concate,再进行1x1卷积(降维)。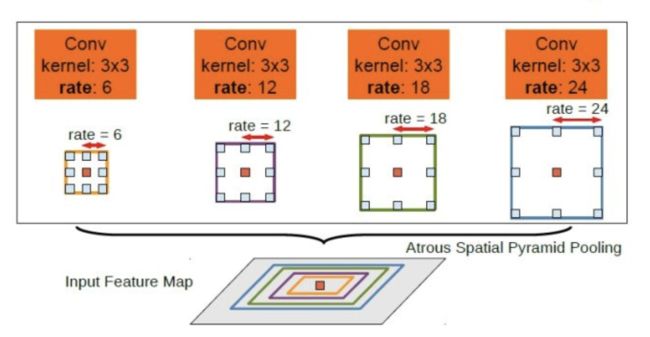
FPN
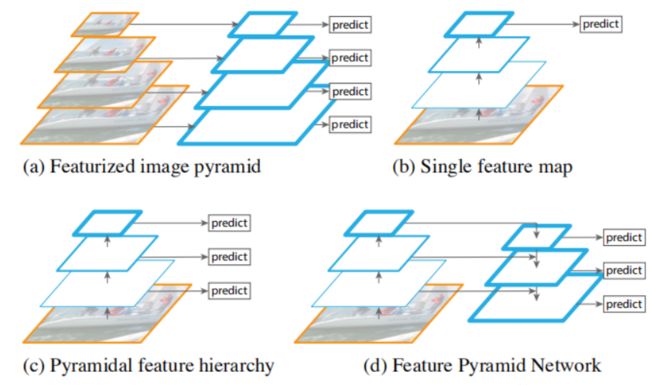
对于一般的神经网络都是采用图b所示的方式来预测,通过对图像多次降采样,在最后一层进行预测,这种方式的缺点是对小目标的检测效果不好。在SSD中采用了图c的方式,利用前几层的信息进行多尺度预测,这种方式的缺点是低层的语义信息不够,而且SSD为了避免重复使用前面已经卷积过的feature map,而从靠后的层(eg: conv4_3 of VGG nets )才开始构建金字塔,这样做的缺点就是金字塔的低层的分辨率也不够,丢失了前面层高分辨率的信息,而那些才是对识别小目标起重要作用的信息。
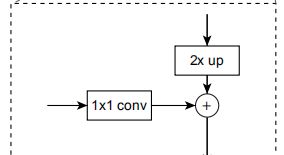
而FPN是目前应用比较广的一种方式,在图C的基础上增加了一条自上而下的路径,主要目的就是解决前面三种方式存在的问题。通过自上而下的路径,使得低层的feature map具有较好的语义信息。
这条路径的实现方式如下图所示:
PANet
缩短信息流动路径和增加不同分支来增加信息流动路径的思想会产生比较强的性能,总结起来就是“split-transform-merge”和“feature reuse”,这也是这几年神经网络的主要改进思想,几乎可以说所有的改进方案都是基于这两种思想。在PANet同样基于这一点,提出了在FPN中自上而下的路径的基础上增加了一条自下而上的路径,具体如下图所示。
- PANet论文提出当目标大小相差超过10个像素的时候,就有可能被分到不同的level上检测,而事实上这两个目标可能差不多,因此这种方式并不是最优方案。
- PANet论文的第二点贡献是提出自适应特征池化( Adaptive Feature Pooling),主要思想是将所有level中产生的候选框中的信息,都用来参与预测。而不是大的目标在higher level检测,小的目标在lower level检测,具体做法如下图所示,使用ROIAlign将金字塔reshape到相同的大小,使用共享的一个全连接层对这四个level分别计算,再通过逐像素求和或取max的方式融合四个level到一个feature map。

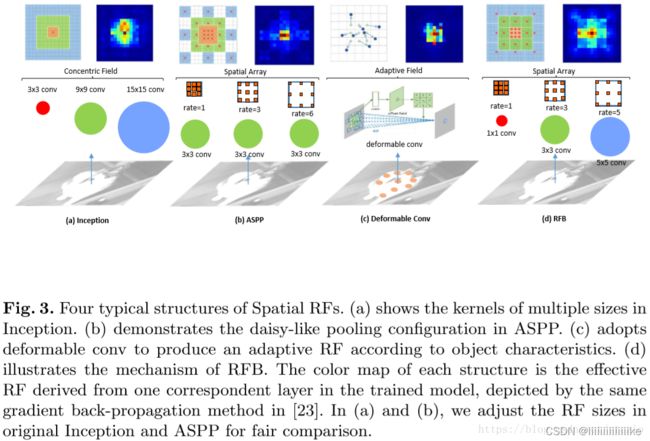
RFB
RFB论文认为ASPP使用不同空洞率的空洞卷积所组成的多分支结构效果很好,但由于在使用之前,使用的是同尺寸的卷积核,导致每条分支产生的分辨率仍然是相同的,只是感受野不同而已。这样的方式与雏菊型卷积核相比,产生的特征并不是那么明显。
因此,RFB论文提出了Receptive Field Block,主要做法就是在进行空洞卷积前加一层不同大小的卷积层,分别是1x1, 3x3, 5x5这样每条支路产生的分辨率不同。

这种方式的效果与其他方式的对比:
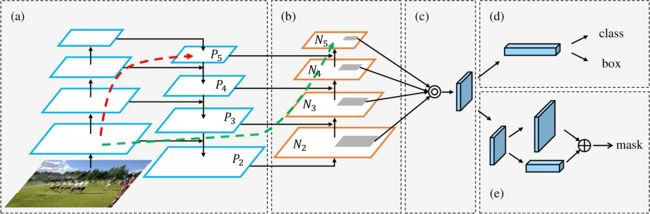
ASFF
 在FPN中这种分而治之除了在PANet中提到的一个问题是,当一个大的目标在higher level上检测时,小的目标在higher level是被当作了background。同理,大目标在lower level中被当成了background,实际上在这些地方是存在目标的,只是不在这一层检测而已,因此这样会存在较大的问题,基于这个问题,ASFF提出了adaptively spatial feature fusion (ASFF)。主要思想是将每层的信息都相互融合起来。
具体操作是先对每一层进行1x1降维,对于第一和二,第二和第三层这种分辨率比为1:2的,通过3x3,步长为2的卷积降采样,对于第一和第三层这种分辨率比为1:4的,先对进行max-pooling,再通过3x3,步长为2的卷积降采样。然后通过系数加权融合。

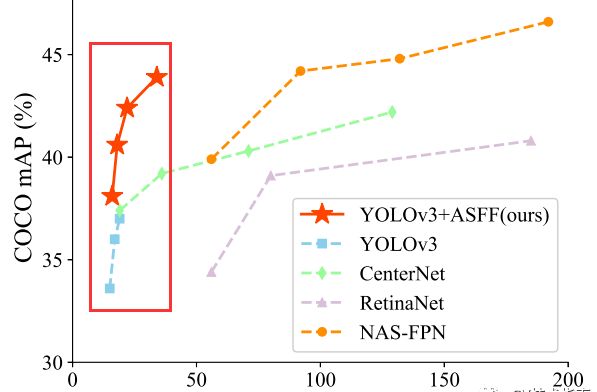
该方法用于YOLO_v3,提高了大概5-10的mAP。
FPT
这篇论文的主要观点是认为背景中其它物品的存在也会辅助识别某一个类别,例如电脑只会在电脑桌上,而不是大街上或水里,背景中的鼠标,键盘也会辅助区分电视机与电脑显示器。因此需要融合金字塔其它level的信息,这虽然出发点与ASFF不同,但实际改进的思路都是一样的,都是让每一层都融合其它层的语义信息。
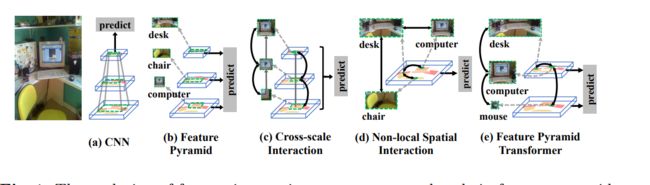
主要思想:利用Non Local Block的操作,以一层为query,其它每层为key,value,计算相似性,得出加权系数,对该层进行加权,每一层都进行这样的操作。
YOLOF
YOLOF通过实验得出结论在特征金字塔的C5层已经有足够的语义信息,融合其它层信息并不会带来很大的精度提升,也就1的mAp,而使用分而治之的思想极为有效,可以提升大概12的mAP。因此YOLOF提出只需要使用C5层信息,并仍然基于分而治之的思想。但由于使用max-iou的匹配方式,只在C5层预测会出现对大小不同的目标生成的positive anchor数量不平衡的问题;分而治之存在计算量大,需要的内存大,推理速度慢的问题。
基于这两个问题,YOLOF提出Dialted encoder和Uniform Matching来实现在单层上进行预测,而这种预测可以做到仍然是基于分而治之的思想。
- Dialted encoder:主要操作是串联四个不同空洞率的3x3空洞卷积,注意与ASPP,RFB不同的是,这里是串联,ASPP和RFB是多支路并联。
- Uniform Matching:使用最近邻方式来匹配,替代了Max-IOU。具体方式是选择GT boxes最近的K个boxes,这样的方式不管GT boxes大小可以匹配相同数量的Boxes。
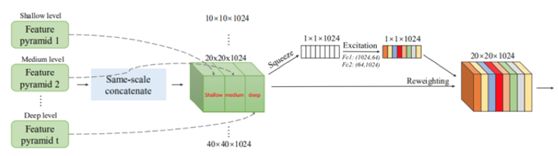
M2Det中SFAM
BiFPN
来源于论文《EffificientDet: Scalable and Effificient Object Detection》