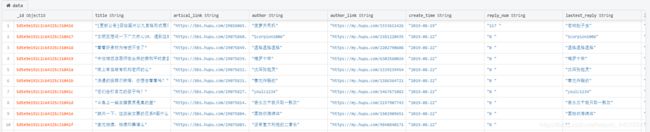
python数据保存到mongodb
本文主要介绍MongoDB和python的连接,将python爬取的数据保存到MongoDB中。
以虎扑网为例,爬取网站的文章标题,连接,作者等信息,并保存到MongoDB中。
虎扑步行街:https://bbs.hupu.com/bxj
所有我们需要的数据都包含在这个 ‘ul’,class_="for-list"里

现在开始爬取并保存数据:
导入相关python库
import requests
from bs4 import BeautifulSoup
import time
import random
from pymongo import MongoClient
定义方法来获取当前网页的所有文章信息
def get_information(page=0):
url = 'https://bbs.hupu.com/bxj-postdate-' + str(page+1)
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Referer": "https://bbs.hupu.com/bxj"
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.content.decode("utf-8"),"html.parser")
out = soup.find("ul",attrs={"class":"for-list"})
datas = out.find_all('li')
datas_list = []
try:
for data in datas:
title = data.find('a', attrs={"class":"truetit"}).text.split()[0]
artical_link = "https://bbs.hupu.com" + data.find('a', attrs={"class": "truetit"}).attrs['href']
author = data.find('a', class_="aulink").text
author_link = data.find('a', class_="aulink").attrs['href']
create_time = data.find('a', style="color:#808080;cursor: initial; ").text
reply_num = data.find('span', class_='ansour box').text.split("/")[0]
lastest_reply = data.find('span', class_='endauthor').text
lastest_reply_time = data.find('div', class_='endreply box').a.text
datas_list.append({"title":title,"artical_link":artical_link,"author":author,"author_link":author_link,"create_time":create_time,"reply_num":reply_num,"lastest_reply":lastest_reply,"lastest_reply_time":lastest_reply_time})
except:
None
return datas_list
定义类来保存数据到MongoDB中:
class MongoAPI():
def __init__(self,db_ip,db_port,db_name,table_name):
self.db_ip = db_ip
self.db_port = db_port
self.db_name = db_name
self.table_name = table_name
self.conn = MongoClient(host=self.db_ip, port=self.db_port)
self.db = self.conn[self.db_name] # 连接数据库
self.table = self.db[self.table_name] # 连接集合
def get_one(self,query): # 获取一条数据
return self.table.find_one(query, projection={"_id":False})
def get_all(self,query): # 获取满足条件所有数据
return self.table.find(query)
def add(self,kv_dict): # 新增数据
return self.table.insert(kv_dict)
def delete(self, query): # 删除数据
return self.table.delete_many(query)
def check_exist(self,query): # 查看数据是否已经存在
ret = self.table.find_one(query)
return ret != None
def update(self,query,kv_dict): # 更新数据(新增)
self.table.update_one(query,{'$set': kv_dict}, upsert=True)
运行程序(这里只爬取前10页数据):
if __name__ == "__main__":
hupu_data = MongoAPI('localhost', 27017, 'hupu', 'data')
for page in range(10):
datas = get_information(page)
for data in datas:
hupu_data.add(data)
print("正在爬取第%s页"%(page+1))
time.sleep(1+random.random()*2)
进入MongoDB查看数据:
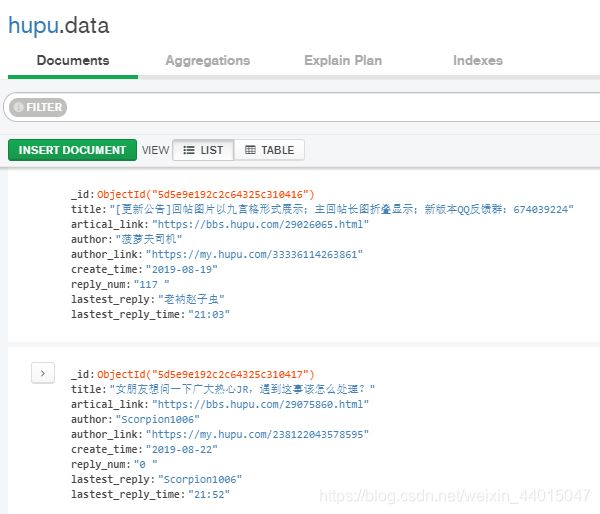
也可以使用表格的方式查看: