添加行
t = pd.DataFrame(columns=["姓名","平均分"])
t = t.append({"姓名":"小红","平均分":M1},ignore_index=True)
t = t.append({"姓名":"张明","平均分":M2},ignore_index=True)
t = t.append({"姓名":"小江","平均分":M3},ignore_index=True)
t = t.append({"姓名":"小李","平均分":M4},ignore_index=True)
print(t)使用append的时候发出警告如下:
FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.于是我就按它提示的来。
concat是将两个DataFrame拼接起来
td = pd.DataFrame([
{"姓名":"小红","平均分":"%.2f"%M1},
{"姓名":"张明","平均分":"%.2f"%M2},
{"姓名":"小江","平均分":"%.2f"%M3},
{"姓名":"小李","平均分":"%.2f"%M4}],
index=["M1","M2","M3","M4"],)
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)
这样子写的话,都不用设置表头了
你也可以这样写:
# 写法2
td1 = pd.DataFrame({"姓名":"小红","平均分":"%.2f"%M1},index=["M1"])
td2 = pd.DataFrame({"姓名":"张明","平均分":"%.2f"%M2},index=["M2"])
td3 = pd.DataFrame({"姓名":"小江","平均分":"%.2f"%M3},index=["M3"])
td4 = pd.DataFrame({"姓名":"小李","平均分":"%.2f"%M4},index=["M4"])
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td1,td2,td3,td4],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)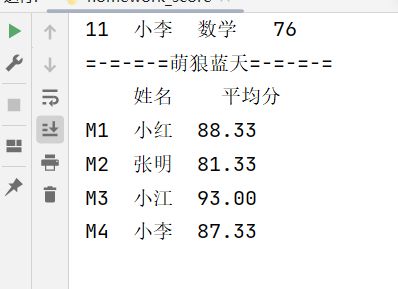
如果你也要测试的话
1.将下面内容保存在名为homework1.txt
姓名,科目,成绩
小红,语文,100
小红,英语,90
小红,数学,75
张明,语文,80
张明,英语,76
张明,数学,88
小江,语文,79
小江,数学,120
小江,英语,80
小李,英语,87
小李,语文,99
小李,数学,762.Python源码
import pandas as pd
data = pd.read_table("homework1.txt",sep=",")
print(data)
pd1= data.loc[data["姓名"]=="小红",:]
M1=pd1["成绩"].mean()
pd2= data.loc[data["姓名"]=="张明",:]
M2=pd2["成绩"].mean()
pd3= data.loc[data["姓名"]=="小江",:]
M3=pd3["成绩"].mean()
pd4= data.loc[data["姓名"]=="小李",:]
M4=pd4["成绩"].mean()
# 旧版本操作
# t = pd.DataFrame(columns=["姓名","平均分"])
# t = t.append({"姓名":"小红","平均分":M1},ignore_index=True)
# t = t.append({"姓名":"张明","平均分":M2},ignore_index=True)
# t = t.append({"姓名":"小江","平均分":M3},ignore_index=True)
# t = t.append({"姓名":"小李","平均分":M4},ignore_index=True)
# print(t)
# 新版本操作
# tt = pd.DataFrame(columns=["姓名","平均分"])
# # "%.2f"% 保留小数点后两位
# td = pd.DataFrame([
# {"姓名":"小红","平均分":"%.2f"%M1},
# {"姓名":"张明","平均分":"%.2f"%M2},
# {"姓名":"小江","平均分":"%.2f"%M3},
# {"姓名":"小李","平均分":"%.2f"%M4}],
# index=["M1","M2","M3","M4"],)
# # 如果不设置index,下面的ignore_index设置为True
# result = pd.concat([td],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
# print("=-=-=-=萌狼蓝天=-=-=-=")
# print(result)
# 写法2
td1 = pd.DataFrame({"姓名":"小红","平均分":"%.2f"%M1},index=["M1"])
td2 = pd.DataFrame({"姓名":"张明","平均分":"%.2f"%M2},index=["M2"])
td3 = pd.DataFrame({"姓名":"小江","平均分":"%.2f"%M3},index=["M3"])
td4 = pd.DataFrame({"姓名":"小李","平均分":"%.2f"%M4},index=["M4"])
# 如果不设置index,下面的ignore_index设置为True
result = pd.concat([td1,td2,td3,td4],ignore_index=False) # 若axis=0 则是跨行合并(垂直合并);若axis=1,则是跨列合并(水平合并)
print("=-=-=-=萌狼蓝天=-=-=-=")
print(result)