深度学习基础学习-1x1卷积核的作用(CNN中)
前言
这里就不赘述卷积神经网络相关内容了,直接通过博主看的一些资料,自己进行了一些整合,大佬绕道。
对于1x1卷积核的作用主要可以归纳为以下几点
- 增加网络深度(增加非线性映射次数)
- 升维/降维
- 跨通道的信息交互
- 减少卷积核参数(简化模型)
1、普通卷积
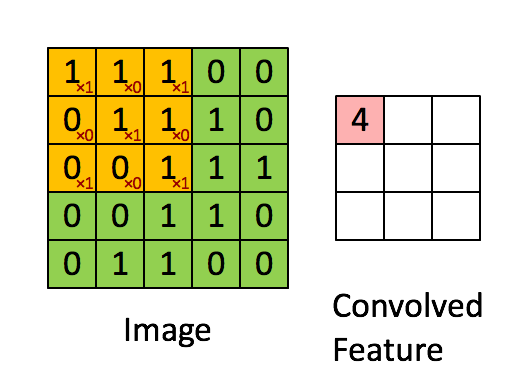
这里首先展示了一个我们最常见的卷积方式(通道数为1),一个5x5的图怕,通过一个3x3的卷积核提取特征得到一个3x3的结果。如果这里的卷积核是1x1的,那么效果如下
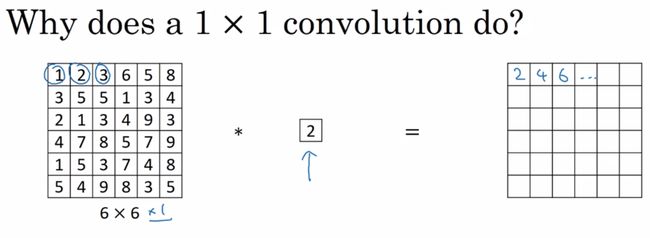
2、1x1卷积核作用
2.1 增加网络深度(增加非线性映射次数)
首先直接从网络深度来理解,1x1 的卷积核虽小,但也是卷积核,加 1 层卷积,网络深度自然会增加。
1x1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很深。并且1x1卷积核的卷积过程相当于全连接的计算过程,通过加入非线性激活函数,可以增加网络的非线性,使得网络可以表达更复杂的特征。
具体来说,引用一下「frank909」博客的内容:
其实问题往下挖掘,应该是增加网络深度有什么好处?为什么非要用 1x1 来增加深度呢?其它的不可以吗?
其实,这涉及到感受野的问题,我们知道卷积核越大,它生成的 featuremap 上单个节点的感受野就越大,随着网络深度的增加,越靠后的 featuremap 上的节点感受野也越大。因此特征也越来越抽象。
但有的时候,我们想在不增加感受野的情况下,让网络加深,为的就是引入更多的非线性。
而 1x1 卷积核,恰巧可以办到。
我们知道,卷积后生成图片的尺寸受卷积核的大小和跨度影响,但如果卷积核是 1x1 ,跨度也是 1,那么生成后的图像大小就并没有变化。
但通常一个卷积过程包括一个激活函数,比如 Sigmoid 和 Relu。
所以,在输入不发生尺寸的变化下,却引入了更多的非线性,这将增强神经网络的表达能力
2.2、升维/降维
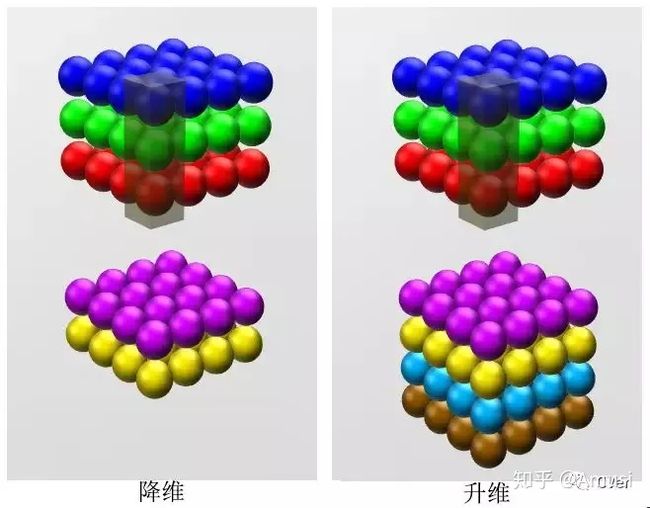
其实这里的升维、降维具体指的是通道数的变化,当我们确定了卷积核尺寸后,我们的height、width都不变,那么这里的维度具体指的就是channels。我们通过改变卷积核的数量来改变卷积后特征图的通道channels来实现升维、降维的效果。这样可以将原本的数据量进行增加或者减少
下面分别举两个例子就能明显看到效果
2.2.1 升维
2.2.2 降维
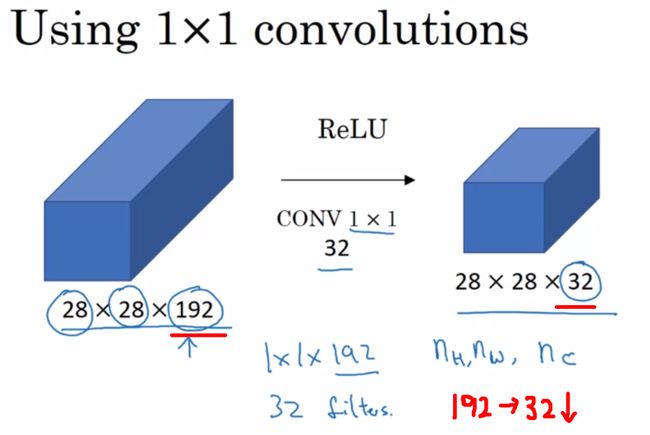
其实很明显的能看出来,无论是升维还是降维,我们都是通过改变卷积核的数量实现的,卷积后的特征图的通道数channels同卷积核的数量保持一致,这里其实不仅仅是1x1卷积核能实现这个功能,其他尺寸的卷积核也可以,那么我们为什么要选用1x1卷积核呢
2.2.3 使用1x1卷积核升维/降维的原因
当我们仅仅只是想要改变通道数的情况下,1x1卷积核是最小的选择,因为大于1x1的卷积核无疑会增加计算的参数量,内存也会随之增大,所以只想单纯的去提升或者降低特征图的通道,选用1x1卷积核最为合适, 1x1卷积核会使用更少的权重参数数量。
2.3 跨通道的信息交互
1x1卷积核只有一个参数,当它作用在多通道的feature map上时,相当于不同通道上的一个线性组合,实际上就是加起来再乘以一个系数,但是这样输出的feature map就是多个通道的整合信息了,能够使网络提取的特征更加丰富。
使用1x1卷积核,实现降维和升维的操作其实就是 channel 间信息的线性组合变化。
比如:在尺寸 3x3,64通道个数的卷积核后面添加一个尺寸1x1,28通道个数的卷积核,就变成了尺寸3x3,28尺寸的卷积核。 原来的64个通道就可以理解为跨通道线性组合变成了28通道,这就是通道间的信息交互。
注意:只是在通道维度上做线性组合,W和H上是共享权值的滑动窗口。
2.4 减少卷积核参数(简化模型)
下面仅以计算权重数为例子进行计算(不添加bias)
2.4.1 一层卷积添加1x1卷积核,分别计算权重数
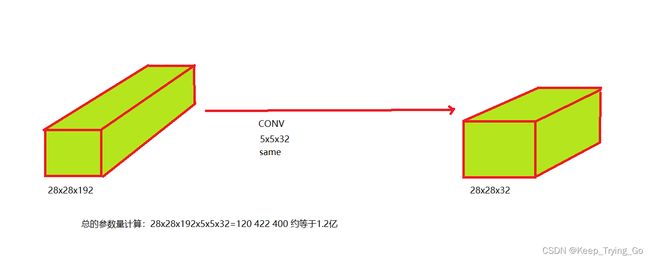
(1)不使用1x1卷积核
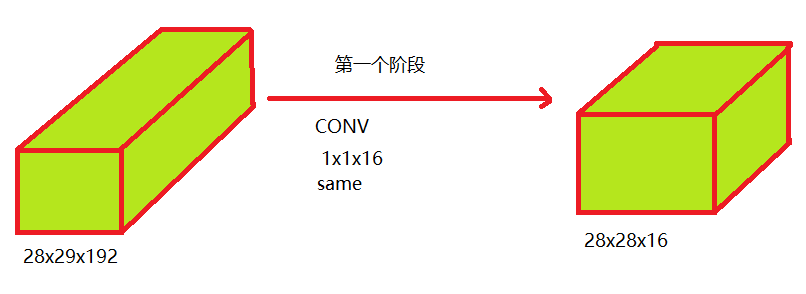
(2)使用1x1卷积核
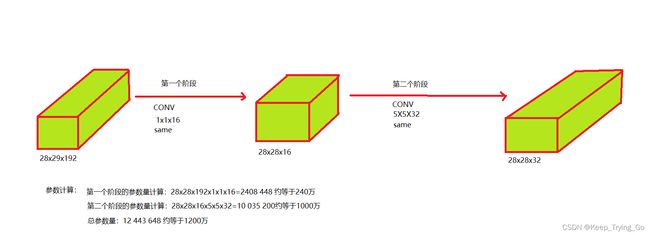
可以看到不使用1x1的卷积核是使用卷积核的10倍左右
2.4.2 GoogLeNet的3a模块
(1)不使用1x1卷积核
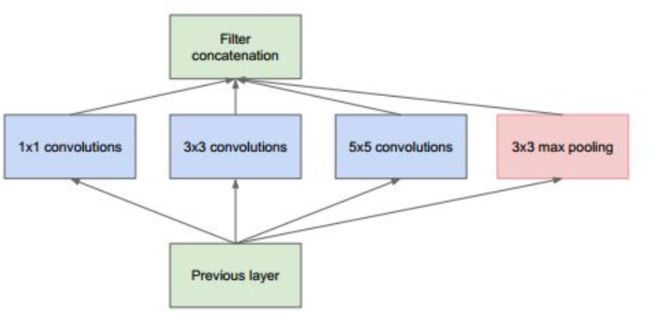
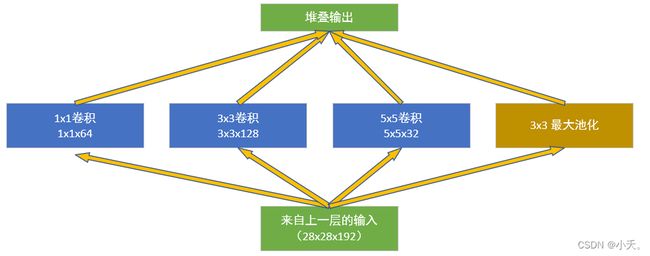
权重数:192 × (1×1×64) +192 × (3×3×128) + 192 × (5×5×32) = 387072
这个网络的说明如下
(1)采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
(2)之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
(3)文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
(4)网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
(2)使用1x1卷积核
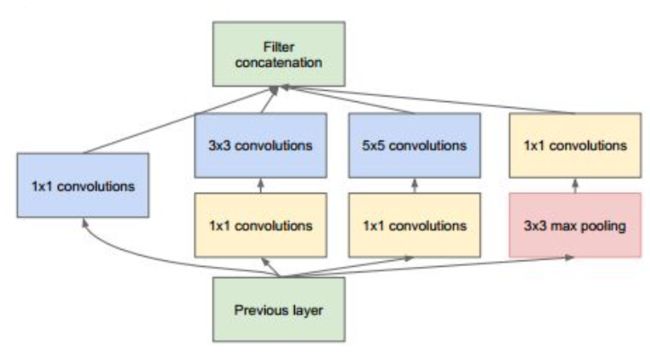
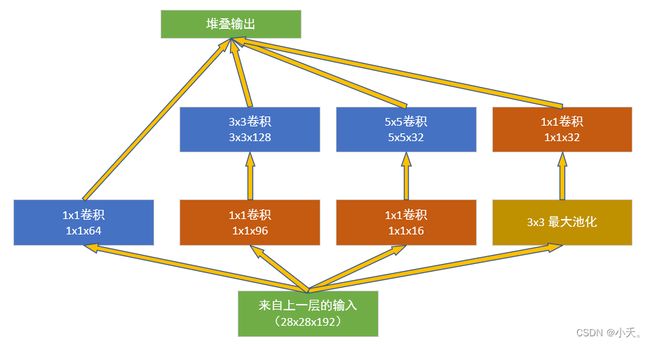
权重数:192 × (1×1×64) +(192×1×1×96+ 96 × 3×3×128)+(192×1×1×16+16×5×5×32)= 157184
不使用1x1的卷积核是使用1x1卷积核的权重数2倍
2.4.3 ResNet
ResNet同样也利用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,参数数量进一步减少
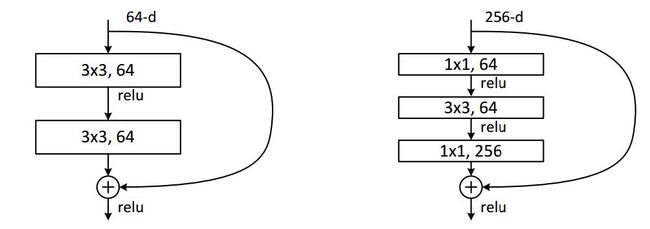
其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,
当我们的特征图通道数为256时,变得很大,出现的问题是计算复杂度会很高,这里做法是通过1×1卷积投影映射回64维,再做一个3×3通道数不变的卷积,然后再通过1×1卷积投影回去256维,因为输入是256维,输出要匹配上,这样设计之后复杂度就跟左图差不多了。
左图参数量:64 x ( 3 x 3 x 64)+64 x ( 3 x 3 x 64 ) = 73728
当通道数增加到 256时:256 x ( 3 x 3 x 256 ) + 256 x ( 3 x 3 x 256 ) = 1179648
右图参数量:256 x ( 1 x 1 x 64) + 64 x ( 3 x 3 x 64 ) + 256 x ( 1 x 1 x 64) = 69632
当通道数增加为256时,可以发现添加两层1x1的卷积的参数量和64为原有残差块参数量差不多。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的网络中,目的是减少计算和参数量(实用目的)
参考资料
一文读懂卷积神经网络中的1x1卷积核
1x1卷积核的作用
【深度学习】CNN 中 1x1 卷积核的作用
深度学习 1x1卷积核的作用
1x1卷积的作用