多智能体深度强化学习综述与批判——Matthew E. Taylor
这篇综述是华盛顿大学的Matthew E. Taylor总结的,“A Survey and Critique of Multiagent Deep Reinforcement Learning”。下载链接:http://arxiv.org/abs/1810.05587v3。
0. 摘要
深度强化学习(Deep Reinforcement Learning, DRL)近年来取得了突破性的成果,出现了大量与之相关的算法和应用。最近的很多研究已经不仅仅局限于单智能体强化学习,进而开始研究多智能体学习场景下的深度强化学习。这篇综述的首要目的是对目前的多智能体深度强化学习(Multiagent Deep Reinforcement Learning, MDRL)相关文献力求做一个清晰的概述。主要包含以下内容:
(i)回顾多智能体学习(Multiagent Learning, MAL)和强化学习的基本要素,突出它们是如何发展到多MDRL场景的。
(ii)对这个领域新的研究者一些基本的指导,即介绍MDRL工作中的经验和教训,给出最近的基准,勾勒出待研究的问题。
(iii)从批判的角度指出MDRL现实中面临的挑战,如实现和计算方面的需求、可复现性等。希望能够有助于将来在大量的MAL和RL文献中用统一的范式通过共同努力来推动多智能体研究取得更多成果。
1. 引言
大概20年前,Stone和Veloso的重要综述奠定了多智能体系统的基石,并且定义了人工智能语境下多智能体系统的待解决的问题。大概10年前,Shoham, Powers,和Grenager看到大量的MAL领域的研究文章后指出MAL领域正在飞速发展。在那之后,MAL领域发表的研究结果继续稳定上升。那时候出现了很多不同的关于MAL的综述,有些分析MAL的基础和挑战,有些强调特定的领域如博弈论和MAL,还有合作场景,以及MAL的动态进化等。在过去几年里,总共有三篇与MAL相关的综述发表:learning in non-stationary environments , agents modeling agents, and transfer learning in multiagent RL。
伴随着人工智能的成功,研究者对MAL的研究兴趣也大大增加。一开始是单智能体玩电玩,然后是两个玩家的游戏如围棋和扑克等,接下来是两只相互竞争的队伍如Dota2和StartCraft II,这些工作都给大家留下了深刻的印象。
尽管上述不同场景使用了不同的技术和算法,但是大多来自RL和DL两个领域的组合。
RL是机器学习的一个子领域,主要研究智能体如何与动态环境交互进行学习。强化学习面临的一个重要挑战,也是创传统的机器学习面临的,就是需要人为的设计高质量的特征用于学习。而DL是一种高效的表示学习,可以自动发现原始数据中的有用特征。近年来DL成功应用在计算机视觉和自然语言处理等领域,而关键的原因就是神经网络(NN)可以从高维的原始数据中提取出有用的表达。
在DRL中,训练好的深度神经网络用来近似最优策略函数或者值函数。DNN作为近似器,大大提高了RL算法的泛化能力。DRL主要的优势就是能够将RL扩展到高维的状态和动作空间中去。不过目前应用较为成功的领域主要还是视觉领域,如玩Atari游戏。面对更加复杂且动态变化的现实应用,DRL还有很多工作要做。
DRL被认为是构建通用人工智能的重要技术,并且成功地与规划以及多智能体系统结合,出现了MDRL。
多智能体场景下的学习问题相较于单智能体,困难显著增大。非平稳、维度灾难、多智能体贡献分配、全局探索以及过于简化等问题。问题虽多,但AI的一些顶会如AAAI、ICML、ICLR、IJCAI、NeurIPS以及多智能体专门会议AAMAS都发表了许多MDRL的研究工作。基于这些最新的研究,首先做出概述,然后理顺与已有文献的关联。
首先回顾RL里面的关键算法如Q-Learning和REINFORCE,然后回顾DRL,最后介绍MAL和MDRL。
MDRL可以分为四类:
- Analysis of emergent behaviors:主要将单智能体DRL的算法应用到MAL场景,观察是否会出现新>- 的行为(比如学会了合作、竞争或者产生了语言)。
- Learning communication:智能体通过学习通信协议来解决合作任务。
- Learning cooperation:智能体在不完全观测条件下学习如何合作。这里特指无通信下的合作场景。
- Agents modeling agents:对其他智能体进行建模推断来完成任务。
图1 多智能体强化学习分类。

在3.2小节将对以上各个类型的MDRL进行具体描述并总结最新的研究。4.1小节介绍RL和MAL相关的算法一开始是如何形成MDRL的。4.2小节对这个领域新的研究者一些基本的指导,即介绍MDRL工作中的经验和教训。4.3小节给出最近的研究的基准。4.4小节从批判的角度介绍MDRL的挑战,如可复现性、超参数调整和计算能力需求能。4.5小节列出一些开放研究的问题。最后在第5节进行总结。
2. 单智能体学习
这一节在介绍DRL之前先给出RL的形式化描述及其要素、挑战、最新的算法。
2.1. 强化学习
这部分参考Sutton的书看看,很多人也总结了,这里就不写了。
2.2. 深度强化学习
这部分参考这个专栏吧,介绍很细致且提供详细注释的代码::
{}
《深度强化学习极简入门》{}
3. 多智能体深度强化学习
在介绍不同类型的MDRL之前,先建立基本的描述框架。
3.1 MAL
直接从MDP进行扩展,即 ( S , N , A , T , R \mathcal{S,N,A,T,R} S,N,A,T,R) ,与单智能体情况下的MDP不同的是,这里的转移函数 T \mathcal{T} T 和奖励函数 R \mathcal{R} R 都是基于联合动作空间 A = A 1 × ⋯ × A N \mathcal{A=}A_1\times\cdots\times A_\mathcal{N} A=A1×⋯×AN ,即 T = S 1 × A 1 ⋯ × A N \mathcal{T}=S_1\times A_1\cdots\times A_\mathcal{N} T=S1×A1⋯×AN 、 R = R 1 ⋯ × R N \mathcal{R}=R_1\cdots\times R_\mathcal{N} R=R1⋯×RN 。对于智能体 i i i,将除它以外的所有智能体记为 − i = N ∖ { i } -i=\mathcal{N}\setminus\left\{i\right\} −i=N∖{i} ,此时的值函数依赖联合动作 a = ( a i , a − i ) \boldsymbol{a}=(a_i,\boldsymbol{a}_{-i}) a=(ai,a−i) 和联合策略 π ( s , a ) = ∏ j π ( s , a j ) \pi(s,\boldsymbol{a})=\prod_j\pi(s,a_j) π(s,a)=∏jπ(s,aj):
V i π ( s ) = ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S T ( s , a i , a − i , s ′ ) [ R i ( s , a i , a − i ) + γ V i ( s ′ ) ] (4) V_{i}^{\pi}(s)=\sum_{\boldsymbol{a}\in\mathcal{A}}\pi(s,\boldsymbol{a})\sum_{s'\in\mathcal{S}}\mathcal{T}(s,a_i,\boldsymbol{a}_{-i},s')[R_i(s,a_i,\boldsymbol{a}_{-i})+\gamma V_i(s')]\tag{4} Viπ(s)=a∈A∑π(s,a)s′∈S∑T(s,ai,a−i,s′)[Ri(s,ai,a−i)+γVi(s′)](4)
同样,智能体 i i i的最优策略也依赖其他智能体的策略
π i ∗ ( s , a i , π − i ) = argmax π i V i ( π , π − i ) ( s ) = argmax π i ∑ a ∈ A π i ( s , a i ) π − i ( s , a − i ) ∑ s ′ ∈ S T ( s , a i , a − i , s ′ ) [ R i ( s , a i , a − i ) + γ V i ( π , π − i ) ( s ′ ) ] (5) \pi_i^*(s,a_i,\boldsymbol{\pi}_{-i})=\text{argmax}_{\pi_i}V_i^{(\pi,\boldsymbol{\pi}_{-i})}(s)=\\\text{argmax}_{\pi_i}\sum_{\boldsymbol{a}\in\mathcal{A}}\pi_i(s,a_i)\boldsymbol{\pi}_{-i}(s,\boldsymbol{a}_{-i})\sum_{s'\in\mathcal{S}}\mathcal{T}(s,a_i,\boldsymbol{a}_{-i},s')[R_i(s,a_i,\boldsymbol{a}_{-i})+\gamma V_i^{(\pi,\boldsymbol{\pi}_{-i})}(s')]\tag{5} πi∗(s,ai,π−i)=argmaxπiVi(π,π−i)(s)=argmaxπia∈A∑πi(s,ai)π−i(s,a−i)s′∈S∑T(s,ai,a−i,s′)[Ri(s,ai,a−i)+γVi(π,π−i)(s′)](5)
其他智能体的联合策略 π − i ( s , a − i ) \boldsymbol{\pi}_{-i}(s,\boldsymbol{a}_{-i}) π−i(s,a−i)可以是非平稳的,一些具有学习能力的对手的策略会随着时间发生改变。
Littman研究了马尔可夫博弈中强化学习算法学习联合动作时的收敛性,得出的结论是:在对抗环境下(零和博弈),针对任意对手都可以得到一个最优玩法,比如Minimax Q-learning。在合作条件下(在一些需要合作的游戏中,所有智能体共享相同的奖励函数),需要做出很强的假设才能收敛到最优行为,比如Nash Q-learning以及Friend-or-Foe Q-learning。其他类型的环境下,暂未调研到有value-based RL算法能保证收敛性。
最近的MDRL研究更强调规模而不是那么强调收敛性了。2018年Srinivasan发表文章指出了AC算法与遗憾最小算法之间的联系,进而不完全信息零和博弈条件下独立RL算法的收敛性有了保证。这一结果导出了另外一个叫做Exploitability Descent的算法。
对多智能体收敛性感兴趣的可以看这些文章*****。关于action shadowing, curse of dimensionality, and multiagent credit assignment就不在这篇综述的讨论范围之内了。现在给出MAL一些特定领域的综述:博弈论与多智能体强化学习看这些xx,合作场景看这些xx ,多智能体动态进化学习看这些xx,非平稳环境下的的看这个x,agents modeling agents看这些xx,MARL中的迁移学习看这些xx。
3.2 MDRL的几个类型
根据以前的这些综述 ,总结出四种类型的工作:
- Analysis of emergent behaviors:主要将单智能体DRL的算法应用到MAL场景,观察是否会出现新的行为(比如学会了合作、竞争或者产生了语言)。
- Learning communication:智能体通过学习通信协议来解决合作任务。
- Learning cooperation:智能体在不完全观测条件下学习如何合作。这里特指无通信下的合作场景。
- Agents modeling agents:对其他智能体进行建模推断来完成任务。
3.3 Emergent behaviors
在MAL场景下使用DRL看会出现什么新的行为,比如是否会产生合作或者竞争。Tampuu用两个独立的DQN agent玩Pong这个游戏 。Lerer 和Peysakhovich用DRL扩展TFT策略,理论和实验表明这样可以保持合作。Self-play这个概念有点意思,因为这类博弈问题往往都可以收敛,现在已经称为RL和MAL的一个标准技巧。self-play有点不稳定定,智能体忘记以前的知识,Leibo提出了Malthusian强化学习将self-play扩展为population dynamics。这种可以看做社区协同进化的方法,结果表明这种方法可以相比于拥有内动力的独立智能体,可以更好的避免陷入局部最优。这种方法的局限性在于没有与state-of-the -art的进化或者基因算法做对比。这篇文章使用进化策略解决强化学习问题。进化策略也被用于求解近似纳什均衡。
Bansal在MuJoCo物理仿真环境中探索会有什么新的合作或者竞争行为产生。他们使用PPO训练独立的智能体并且做了两个新的工作来处理MAL相关的问题。第一,使用密集奖励叫做exploration reward让agents学会基本的(非竞争)的行为,这种奖励会随着时间逐渐消失取而代之的是逐渐增大的环境奖励(竞争性)权重。Exploration Reward早先的一些机器人和单智能体研究中提出的,用来给出密集的奖励从而提高样本效率。在所智能体场景下,密集奖励可以在训练的初始阶段增加随机动作产生正奖励的概率。第二,对手采样,维持了一个对吼版本池用来采样对手,而不是使用最新的版本。
Raghu研究了DRL(DQN,A2C,PPO)在一些列两个玩家零和且难度可调的游戏(Erdos-Selfridge-Spencer)中的表现。在不同难度算法表现出了广泛的适应能力。
Lazaridou提出了基于多智能体通信的语言学习模型。里面的智能体都用前馈神经网络表示,需要使用“新的语言”来解决相应的任务。任务被形式化建模为一个“信号模型”,里面包含两个agents,一个sender,一个receiver,获得一些图片。sender被告知图片里面有一张是target image,sender从图片里面选一张发给receiver。只有当receiver识别出target image后,sender和receiver同时获得奖励。结果表明基于智能体在视觉领域可以合作。为了分析这里面的语言属性(…回头看看这篇文章,居然说可以产生新的语言,而且人类还能看得懂?)
Mordatch and Abbeel也研究了出现语言的问题。
3.4 Learning communication
通信是多智能体交互过程中出现的重要特征,特别是智能体之间需要合作,而每个智能体又只能获得部分观测,此时环境中agents需要通过交流来更好的达成一个共同目标。
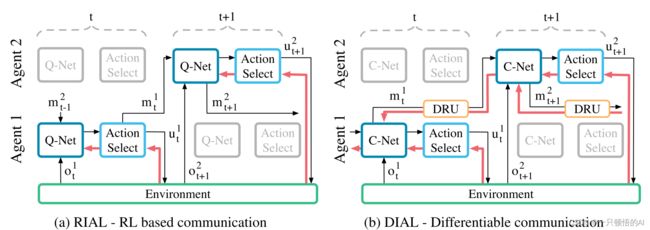
Foerster等人2016年在NIPS上提出Reinforced Inter-Agent Learning(RIAL)和Differentiable Inter-Agent Learning 是两种使用深度网络学习通信的算法(PS:Foerster写了很多DRML的文章,被很多其他重要文献引用)。都使用神经网络来输出智能体的Q值以及需要传给其他智能体的消息。RIAL是基于深度循环Q网络(DRQN )并且使用参数共享的概念,比如使用一个网络,这个网络的参数与所有智能体进行共享。DIAL则在学习阶段通过通信信道(下图中的DRU)传递梯度,并且在执行过程中消息被离散化然后映射到通信动作集合。(这里面有一个概念,叫做centralised learning and decentralised excution。RIAL在excution阶段每个智能体使用copy of the learned netwiork)。
图2 CommNet。RIAL(a)里面,Q网络的输出值输入到动作选择器中,选择器选择应对环境的动作以及给其他智能体的消息。红色箭头标出的梯度使用DQN进行计算,并且只流过单个智能体。DIAL(b)消息m^a_t通过动作选择器旁边的DRU输入到另一个智能体的C-network,因此梯度可以在不同智能体之间进行传递。
内存驱动(Memory Driven, MD)通信是在Multi-Agent Deep Deterministic Policy Gradient(MADDPG )的基础上提出的。在MD-MADDPG 中,智能体使用共享内存作为通信信道:在采取动作之前,智能体首先读取内存,然后写入反应。这种情况下,智能体的策略和它的观测以及对内存集合的解释有关。实验使用了两个智能体进行合作完成任务,发现在相对简单的任务里面智能体会在任务快要结束的时候显著的降低内存的活动,因为环境变化较小;而在复杂环境下,内存的使用快速变化,因为此时会出现许多子任务。
Dropout 是一种神经网络用于防止过拟合的技术(在监督学习中,过拟合指的是算法只在特定数据集上有很好的性能而没有泛化能力),它在训练的时候随机取消一部分神经元的活性。Kim等人在多智能体环境下提出了一个相似的方法,即智能体可以直接使用消息进行通信,在训练阶段其他智能体的消息会随机丢失,作者吧这种方法叫做Message-Dropout MADDPG算法 。这种方法可以在完全或者部分观测的条件下使用。实验结果表明,合理选择信息丢失率,所提出的方法可以显著的提高训练速度以及所学习到的策略的鲁棒性(通过引入通信错误率)。这种能力在MDRL中十分重要,因为这样的智能体值仿真或者受控的环境中训练好之后,在迁移到更加实际的环境中不会那么脆弱。
与RIAL和DIAL使用离散通信信道不同的是,CommNet 使用的是连续的矢量信道。智能体通过这样的信道接收所有其他智能体传输的信号的和。作者设定了一个完全合作的场景,并且训练一个网络用于所有的智能体。相比于之前的研究,CommNet有两个突出的特点:一是在每个时间步允许多个通信环,二是允许智能体动态变化,比如智能体加入和退出环境。(CommNet,Facebook AI Research 提出的,后面很多论文都拿它对比)BiCNet(Multiagent Bidirectionally Coordinated Network) 方法中的通信发生在隐藏空间(如隐藏层)。它也使用参数共享,但使用双向循环神经网络 来建模动actor和critic网络(RL中AC是很重要的一类算法,不了解的可回到本文第二节了解一下)。需要指出的是,BiCNet中的智能体不会显式的共享信息,因此可以认为它是一个学习如何合作的方法。
学习如何通信是MDRL领域的一个活跃的研究方向,这里面还有很多问题没有解决,感兴趣的读者可以读一读Lowe等人最近的研究,里面会讨论一些常见的坑(同时也会教你如何避免踩雷)同时也会对多智能体的通信进行一些度量。
3.5 Learning cooperation
尽管研究多智能体中显式通信问题最近比较热,但是依然有很多合作场景下的研究并不涉及通信 ,下面做这方面的介绍。
Foester等人研究 了独立的使用Q-learning进行学习的智能体简单场景下的合作问题 ,这一研究中使用了标准的DQN结构和经验重放(ER)缓存。但是使用ER要求数据满足一定的假设条件,而这些条件在多智能体世界中往往时候满足不了的。多智能体环境的动态特性使得产生的数据放到ERbuffer中之后,不在能够反映出当前的规律,从而变成了过时的经验 。他们给出的解决方法是给经验对加入信息来帮助确定从经验池中所采样数据的“年龄”。与之相关的有两种方法,Multiagent Importance Sampling 和Multiagent Fingerprints 。
Gupta等人研究了部分观测且无通信条件下的多智能体合作问题 。核心思想是学习一个全局共享的网络在执行的时候可以有不同的表现(Foerster也提出过类似的概念)。Lenient-DQN (LDQN) 在对经验池进行采样的时候,使用leniency condition来决定是否使用这一样本。
Decentralized-Hysteretic Deep Recurrent Q-Networks (DEC-HDRQNs) 是一种用来促进独立(无通信)智能体之前合作的方法。作者使用了一种叫做策略蒸馏的方法来提高模型泛化能力。DEC-HDRQN在学习和执行的时候都是完全decentralized。
Lowe等人指出 ,在多智能体环境下使用标准的策略梯度方法会产生比较高的方差且表现很差。原因在于智能体的奖励依赖于其他的智能体,方差会随着智能体数量呈指数增加。为此,作者提出了Multi-Agent Deep Deterministic Policy Gradient (MADDPG),这是一种基于DDPG的算法,在训练的时候会针对每个之智能体训练一个centralized critic且使用所有智能体的策略作为输入。这样一来,去掉了多智能体同时学习造成的非平稳性,进而降低了方差。
Counterfactual Multi-Agent Policy Gradients (COMA) 是另一个基于策略梯度的方法,其研究的基本设定是完全中心化(fully centralized)和做智能体贡献分配(multiagent assignment credit) 。多智能体合作场景下如果偶有智能体共享一个全局奖励,此时该如何计算每个智能体的贡献?作者给出的解决办法是计算一个反推基线(counterfactual baseline),即将每个智能体边缘化(marginalized)并保持其他智能体动作不变。这样就可以计算一个优势函数来比较当前的Q值和反推出来的基线。一方面,fully centralized approaches do not suffer from non-stationarity but have constrained scalability。另一方面,independent learning agents are better suited to scale but suffer from non-stationarity issues。因此有人使用混合的方法,学习一个centralized同时考虑Q值的值函数。值分解网络(Value Decomposition Networks)将团队的值函数分解为各自值函数相加 。QMIX 是一种基于因式分解的方法,不过它使用的是一个叫做mixing network来非线性地组合局部值。分解的方法虽然在实验中都取得了较好的结果,但是仍然是一个研究中的问题,还有很多问题没解决,比如如何学习分解因子等。
3.6 Agents modeling agents
通过建模来推断其他智能体的行为是智能体的一个重要能力。Deep Reinforcement Opponent Network(DRON) 是较早的使用深度学习进行智能体建模的研究。基本的想法是使用两个网络,一个估计Q值,另一个学习对手的策略的表征。此外,作者使用了几个专家网络一起来预测Q值,实际的考虑是专家网络可以捕捉对手的策略 。
4. 从RL, MAL到MDRL
4.1. MDRL的几个例子
有时候很多想法很早就被提出了,但是后来的研究者往往不会再去审视这些研究,就算后来用了相近的思路,可能存在不引用相关旧文献的情况。因此有必要罗列一些阶段性的比较突出的研究成果。
Dealing with non-stationarity in independent learners.通常认为从相互独立的智能视角来看,环境是非平稳的。Hyper-Q 将其他智能体的策略和信息放到状态的表示中,有效的将问题变为平稳问题。
Multiagent credit assignment.在合作场景下,需要给每个智能体分配局部或者全局的奖励。然而局部奖励常常难以获取,因此往往使用全局奖励。这就引入了贡献分配的问题:一个智能体的某个动作对于整个系统的贡献怎么去衡量?Agogino等人 考虑了如何评估以下两个方面的问题:1)奖励如何在不同状态下促进智能体合作?2)单个智能体学习最大化奖励的过程是否足够简单?
Multitask learning.多任务学习要求智能体能在多个相关的任务中执行。蒸馏(distillation),可以简单理解为将大型模型的知识迁移到小模型上,这一概念是从监督学习和模型压缩中引入的 。受该概念启发,有学者将policy distillation 扩展到DRL领域。Policy distillation就是训练一个较小的网络来融合多个特定问题的策略而形成一个整体策略。Auxiliary tasks.考虑到环境中包含各种各样的训练信息(如像素的变化等),Jaderberg等 提出了auxiliary这一术语。
Experience replay.
Double estimators.
4.2. 一些经验(Lessons learned)
Experience replay buffer in MDRL
Centralized learning and decentralized excution
Parameter sharing
Recurrent networks
Overfitting in MAL
4.3. MDRL研究的基线(Benchmarks for MDRL)
主要是一些实验环境:
Fully Cooperative Multiagent Object Transporation Problems (CMOTPs)
The Apprentice Firemen Game
Pommerman
Starcraft Multiagent Challenge
The Multi-Agent Reinforcement Learning in Malmo (MARLO)
Hanabi is a cooperative multiplayer card game (two to ve players)
Arena
MuJoCo Multiagent Soccer
Neural MMO
4.4. MDRL的挑战(challenges in MDRL)
主要是吐槽了一下:
实现起来困难(复现起来难度大)、超参数难调
太吃计算资源(联想到最近华为怼DeepMind,说DeepMind发表的Nature论文在现有计算条件下无法实现。。。)
貌似和DL被吐槽的地方差不多。。。
4.5. 待解决的问题(Open questions)
基本上都是一些比较粗略的问题:
On the challenge of sparse and delayed rewards.
On the role of self-play
On the challenge of the combinatorial nature of MDRL
5. 总结
原文的总结就不翻译了,说说自己的读后感。看完觉得这篇文列出了386篇文献,最新的参考文献为2019年发表,应该是综述里面比较新的了。文章从RL和MAL两个领域进行了梳理,RL->DRL->MDRL。对DRL的概括为四个主要的类型,虽然是粗略的分类,但是还是有助于理解目前很多文章的侧重点。可能包含的内容有点多,对有些文章的概述我个人不太能看明白,需要读原文,这些就没有翻译。不过,写这样一篇综述的工作量应该很大,上一个版本叫做“Is multiagent deep reinforcement learning the answer or the question? A brief survey”,感谢作者!