2022年你应该知道的5个高级SQL概念
2022年你应该知道的5个高级SQL概念 今天就掌握这些节省时间的高级SQL查询方法吧
成为SQL的专家!
SQL或结构化查询语言是任何从事数据工作的人必须拥有的工具。
随着数据量的增加,对熟练的数据专业人员的需求也在增加。仅有高级SQL概念的知识是不够的,你应该能够在你的工作中有效地实施它们,这也是数据科学职位的面试中所需要的!
因此,我在这里列出了5个高级SQL概念,并附有解释和查询实例,你应该在2022年知道这些概念。
我把这篇文章写得很短,这样你就可以迅速完成它,并掌握这些必须知道的、赢得面试的SQL技巧。
你可以使用这个索引快速导航到你最喜欢的部分。
- 常见的表表达式(CTE)
- ROW_NUMBER() vs RANK() vs DENSE_RANK()
- CASE WHEN语句
- 从日期-时间列提取数据
- SELF JOIN :我正在使用SQLite DB浏览器和一个用Faker创建的Dummy_Sales_Data,你可以在我的Github repo上免费获得这个数据。
好了,我们开始吧...
常用表表达式(CTEs) 在处理现实世界的数据时,有时你需要查询另一个查询的结果。实现这一目的的一个简单方法是使用子查询。
然而,随着复杂性的增加,计算的子查询变得难以阅读和调试。
这时,CTEs就会出现,使你的生活更容易。CTEs使编写和维护复杂的查询变得容易。✅
例如,考虑使用子查询进行以下数据提取
SELECT Sales_Manager, Product_Category, UnitPrice
FROM Dummy_Sales_Data_v1
WHERE Sales_Manager IN (SELECT DISTINCT Sales_Manager
FROM Dummy_Sales_Data_v1
WHERE Shipping_Address = 'Germany'
AND UnitPrice > 150)
AND Product_Category IN (SELECT DISTINCT Product_Category
FROM Dummy_Sales_Data_v1
WHERE Product_Category = 'Healthcare'
AND UnitPrice > 150)
ORDER BY UnitPrice DESC
这里我只用了两个子查询,代码很容易理解。
这仍然很难理解,如果你在子查询中添加更多的计算,甚至添加更多的子查询--复杂性增加,使得代码不容易读懂,难以维护。
现在,让我们看看上述带CTE的子查询的简化版本,如下所示。
WITH SM AS
(
SELECT DISTINCT Sales_Manager
FROM Dummy_Sales_Data_v1
WHERE Shipping_Address = 'Germany'
AND UnitPrice > 150
),
PC AS
(
SELECT DISTINCT Product_Category
FROM Dummy_Sales_Data_v1
WHERE Product_Category = 'Healthcare'
AND UnitPrice > 150
)
SELECT Sales_Manager, Product_Category, UnitPrice
FROM Dummy_Sales_Data_v1
WHERE Product_Category IN (SELECT Product_Category FROM PC)
AND Sales_Manager IN (SELECT Sales_Manager FROM SM)
ORDER BY UnitPrice DESC
复杂的子查询被分解成更简单的代码块来使用。
通过这种方式,复杂的子查询被重新写成两个CTE SM和PC,更容易理解和修改。
上述两个查询,用同样的时间执行,结果是同样的输出,如下所示。
CTE与子查询|
CTE本质上允许你从查询的结果中创建一个临时表。这可以提高代码的可读性和维护性。✅
现实世界中的数据集可能有几百万或几十亿行,占据1000多GB的存储空间。使用这些表的数据进行计算,特别是将它们与其他表直接连接,将是相当昂贵的。
这种任务的最终解决方案是使用CTEs。
接下来,让我们看看如何使用窗口函数为数据集中的每一行分配一个整数 "等级"。
2
ROW_NUMBER() vs RANK()vs DENSE_RANK()
在处理真实数据集时,另一个常用的概念是记录的排名。公司在不同的情况下使用它,例如
按销售数量对最畅销的品牌进行排名
按订单数量或产生的收入对顶级产品的垂直市场进行排名
获得各类型电影中观看次数最多的电影名称
ROW_NUMBER、RANK()和DENSE_RANK()基本上是用来给结果集中提到的分区的每条记录分配连续的整数。
当你在某些记录上有并列关系时,它们之间的差异是可见的。
当结果表中存在重复的记录时,为每条记录分配整数的行为和方式会发生变化。✅
让我们来看看虚拟销售数据集的一个简单例子,按照运费的降序列出所有的产品类别和送货地址。
SELECT Product_Category,
Shipping_Address,
Shipping_Cost,
ROW_NUMBER() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RowNumber,
RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RankValues,
DENSE_RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as DenseRankValues
FROM Dummy_Sales_Data_v1
WHERE Product_Category IS NOT NULL
AND Shipping_Address IN ('Germany','India')
AND Status IN ('Delivered')

RANK() 是根据ORDER BY子句的条件来检索排名的行。正如你所看到的,前两行之间有一个平局,即前两行的Shipping_Cost列有相同的值(这在ORDER BY子句中提到)。
RANK为这两行分配了相同的整数。然而,它将重复的行数加入到重复的等级中,以得到下一行的等级。这就是为什么第三行(红色标记),RANK分配的等级是3(2个重复行+1个重复等级)。
DENSE_RANK与RANK类似,但它不会跳过任何数字,即使行与行之间存在平局。这一点你可以在上图的蓝色框中看到。
与以上两种不同,ROW_NUMBER只是为分区中的每条记录分配连续的数字,从1开始。如果它在同一分区中检测到两个相同的值,它会为两者分配不同的等级数字。
对于产品类别-送货地址→娱乐-印度的下一个分区,所有三个函数的等级都从1开始,如下所示。

CASE WHEN 语句 CASE语句将允许你在SQL中实现if-else,所以你可以用它来有条件地运行查询。
CASE语句主要是测试WHEN子句中提到的条件,并返回THEN子句中提到的值。当没有满足条件时,它将返回ELSE子句中提到的值。✅
在实际的数据项目中,CASE语句经常被用来根据其他列的值来对数据进行分类。它也可以和聚合函数一起使用。
例如,让我们再次使用虚拟销售数据,根据数量将销售订单分为高、中、低三个等级。
SELECT OrderID,
OrderDate,
Sales_Manager,
Quantity,
CASE WHEN Quantity > 51 THEN 'High'
WHEN Quantity < 51 THEN 'Low'
ELSE 'Medium'
END AS OrderVolume
FROM Dummy_Sales_Data_v1

简单地说,它创建了一个新的列OrderVolume,并根据列Quantity的值添加了 "高"、"低"、"中 "的值。
你可以包括多个WHEN...THEN子句,跳过ELSE子句,因为它是可选的。
如果你没有提到ELSE子句,并且没有满足任何条件,查询将返回该特定记录的NULL。
CASE语句的另一个经常使用但鲜为人知的使用情况是--数据透视。
数据透视是一个重新排列结果集中的列和行的过程,这样你就可以从不同的角度查看数据。
有时你处理的数据是长格式的(行数>列数),而你需要以宽格式(列数>行数)获取它。
在这种情况下,CASE语句就很方便。
例如,让我们找出每个销售经理为新加坡、英国、肯尼亚和印度处理了多少订单。
SELECT Sales_Manager,
COUNT(CASE WHEN Shipping_Address = 'Singapore' THEN OrderID
END) AS Singapore_Orders,
COUNT(CASE WHEN Shipping_Address = 'UK' THEN OrderID
END) AS UK_Orders。
COUNT(CASE WHEN Shipping_Address = 'Kenya' THEN OrderID
END) AS Kenya_Orders。
COUNT(CASE WHEN Shipping_Address = 'India' THEN OrderID
END) AS India_Orders
FROM Dummy_Sales_Data_v1
GROUP BY Sales_Manager
使用CASE...WHEN...THEN,我们为每个发货地址创建了单独的列,以获得预期的输出,如下所示。
SELECT Product_Category,
Shipping_Address,
Shipping_Cost,
ROW_NUMBER() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RowNumber,
RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RankValues,

根据你的使用情况,你也可以使用不同的聚合,如SUM, AVG, MAX, MIN与CASE语句。
接下来,当涉及到处理现实世界的数据时,它往往包含日期时间值。因此,了解如何提取日期-时间值的不同部分是很重要的,如月、周、年。
从日期-时间列中提取数据 在大多数的面试中,你会被要求按月汇总数据或计算特定月份的某些指标。
当数据集中没有单独的月份列时,你需要从数据中的日期-时间变量中提取所需的日期部分。
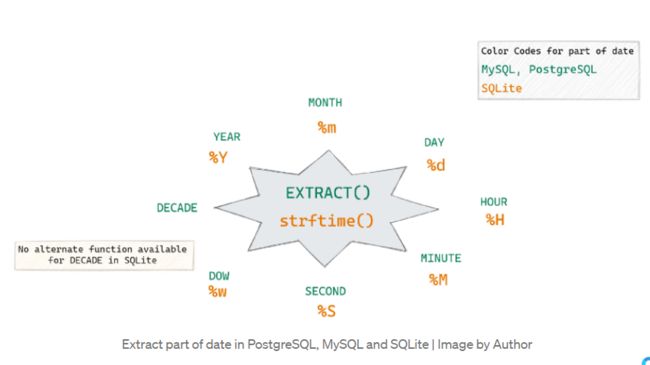
不同的SQL环境有不同的函数来提取日期的一部分。
EXTRACT(part_of_date FROM date_time_column_name)
YEAR(date_time_column_name)
MONTH(date_time_column_name)
MONTHNAME(date_time_column_name)
DATE_FORMAT(date_time_column_name)
例如,让我们从虚拟销售数据集中找出每个月的总订单量。
SELECT strftime('%m', OrderDate) as Month,
SUM(Quantity) as Total_Quantity
from Dummy_Sales_Data_v1
GROUP BY strftime('%m', OrderDate)
如果你也像我一样使用SQLite DB浏览器,你必须使用函数strftime()来提取日期部分,如下所示。你需要在strftime()中使用'%m'来提取月份。

下面是一张图片,显示了大部分常用的日期提取部分,以及你应该在EXTRACT函数中使用的关键字。
在PostgreSQL、MySQL和SQLite中提取日期的一部分 | 图片由作者提供 我在这个快速阅读中解释了几乎所有类型的日期部分提取。请看一下它,以获得一个完整的概念。
5个必须知道的数据分析的SQL函数 关于SQL函数的最全面的指南,以便从数据中获得最大的收益! python.plainenglish.io
最后但也是最重要的。
你会经常看到在现实世界中,数据被存储在一个大表中,而不是多个小表。这时,SELF JOIN就会出现,以解决在这些数据集上工作时的一些有趣的问题。
SELF JOIN 这些与SQL中的其他JOIN完全相同,唯一的区别是--在SELF JOIN中,你将一个表与它自己连接起来。
请记住,没有SELF JOIN关键字,所以你只需使用JOIN,其中参与连接的两个表是同一个表。由于两个表的名称相同,所以在SELF JOIN中必须使用表的别名。✅
写一个SQL查询,找出收入超过经理的员工
- 关于SELF JOIN最常被问到的面试问题之一
让我们以这个为例,创建一个Dummy_Employees数据集,如下所示。

虚拟雇员数据集 |
并尝试用这个查询来找出哪些员工比他们的经理处理更多的订单。
SELECT t1.EmployeeName, t1.TotalOrders
FROM Dummy_Employees AS t1
JOIN Dummy_Employees AS t2
ON t1.ManagerID = t2.EmployeeID
WHERE t1.TotalOrders > t2.TotalOrders

结果集|图片由作者提供 正如预期的那样,它返回了员工--Abdul和Maria--他们处理的订单比他们的经理--Pablo多。
在我面对的几乎80%的面试中,我都会遇到这个问题。所以,这就是SELF JOIN的典型用例。
这就是全部了!
我希望你能尽快读完这篇文章,并发现它对掌握SQL很有帮助。
我从过去3年开始使用SQL,我发现这些概念经常作为数据分析师、数据科学家职位的面试问题。这些概念在实际项目工作中非常有用。
有兴趣在Medium上阅读无限的故事吗?
考虑成为Medium会员,以获得Medium上的无限故事和每日有趣的Medium摘要。我将从你的费用中得到一小部分,而你没有任何额外费用。
请务必注册到我的电子邮件列表中,以免错过关于数据科学指南、技巧和提示、SQL和Python的另一篇文章。
本文由 mdnice 多平台发布