极市平台sdk封装简易教程
文章目录
-
极市平台算法开发简易教程 -
- 一、导出onnx模型
-
- 1.1 启动模型开发实例,在线编码,选择 vscode 编辑器。
- 1.2 修改 yolo.py 文件, 注释
- 1.3 创建 export_onnx.sh 文件
- 1.4 模拟测试 export_onnx.sh
- 1.5 生成的 onnx 模型可视化
- 1.6 发起训练,然后生成onnx模型。
- 二、创建实例
- 三、在线编码
-
- 3.1 点击启动,然后在线编辑。
- 3. 2 上传模板代码
- 3.3 使用`vscode` 编辑器
-
- 3.3.1 复制上传的代码地址
- 3.3.2 复制代码文件到 ev_sdk 文件夹路径下
- 3.3.3 修改配置文件 `config/algo_config.json`
- 3.3.4 修改 `src/Configuration.hpp` 文件
- 3.3.5 src/configuration.hpp 后添加定义报警类型 alarmType
- 3.3.6 修改 `src/SampleAlgorithm.cpp` 模型 onnx 路径
- 3.3.7 修改 `src/SampleDetector.cpp` 模型推理。
- 四、发起调试。
-
- 4.1 配置数据,选择对应的文件
- 4.2 创建 debug_gpu.sh 文件, 内容如下。
- 五、小结
极市平台算法开发简易教程
9月份我在极市平台参加视觉AI工程项目实训周,完成了两个项目开发,其中有个项目已完成封装部署,并且一次验收通过。
本文主要讲解极市平台算法封装开发步骤(默认模型开发已训练得出分数),也默认使用 yolov5 版本训练出来的模型。
一、导出onnx模型
导出onnx 模型,这得在模型开发,实例导出生成 onnx 结构。
1.1 启动模型开发实例,在线编码,选择 vscode 编辑器。
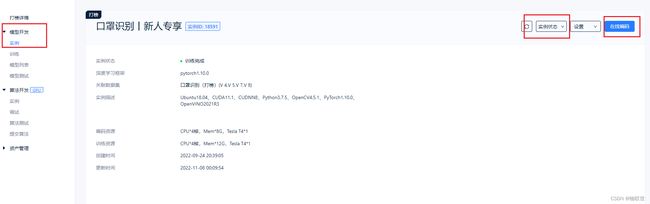
1.2 修改 yolo.py 文件, 注释
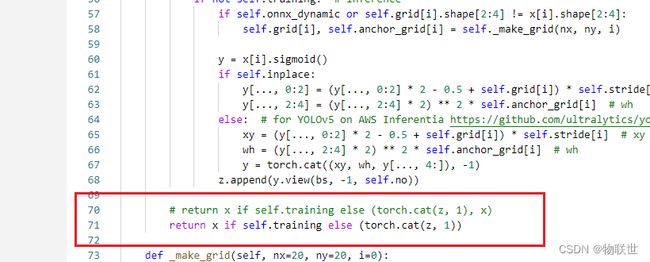
1.3 创建 export_onnx.sh 文件
pip install onnx==1.9.0
pip install onnx-simplifier==0.4.1
# 切换到导出目录下
cd /project/train/src_repo/v5/export
# 运行导出onnx 命令。
python export.py --data data/data.yaml --weights /project/train/models/exp/weights/best.pt --simplify --include onnx
1.4 模拟测试 export_onnx.sh
- 在/project/train/models 路径下创建文件夹 exp / weights
- 复制yolov5s.pt 文件, /project/train/models/exp/weights/ 路径下,重命名 best.pt
- 运行 bash export_onnx.sh
1.5 生成的 onnx 模型可视化
可视化软件 https://netron.app 。也可下载 https://github.com/lutzroeder/netron/releases
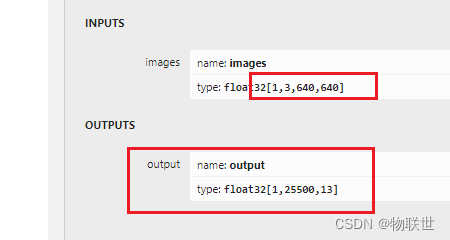
想验证是否对,可在本地电脑验证,生成的onnx,是否只有一个输入,一个输出
1.6 发起训练,然后生成onnx模型。
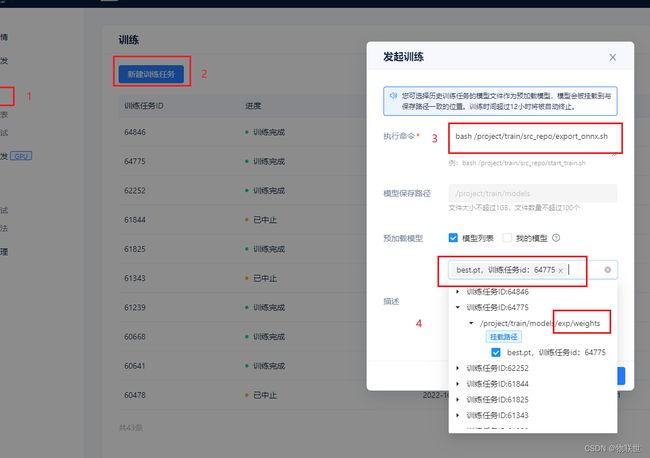
二、创建实例
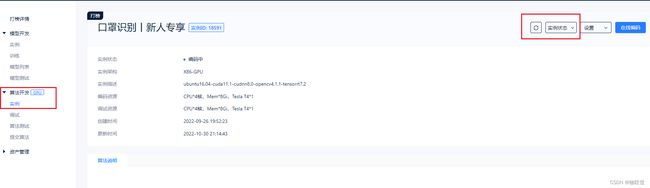
选择tensorRT c++ 推理实例
三、在线编码
3.1 点击启动,然后在线编辑。
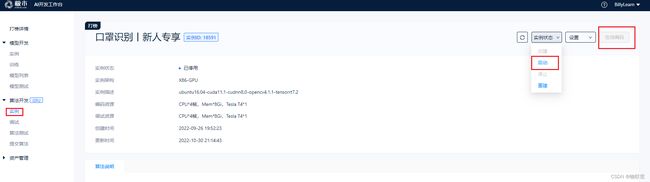
3. 2 上传模板代码
先下载模板代码路径: https://gitee.com/cvmart/ev_sdk_demo4.0_pedestrian_intrusion_yolov5.git
然后上传到平台
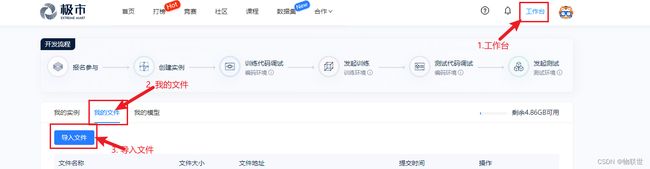
3.3 使用vscode 编辑器
快捷键 (ctrl + ` ) 打开命令 cmd 端口
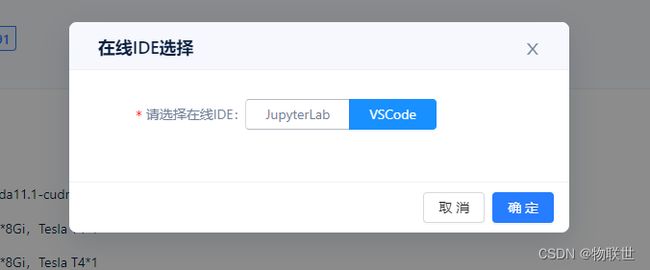
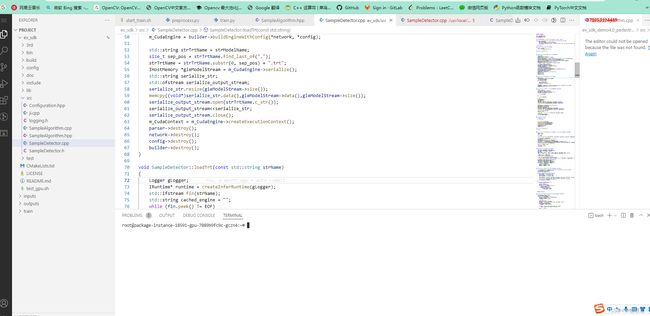
3.3.1 复制上传的代码地址
在 vscode 命令行端口,执行命令
wget -c https://extremevision-js-userfile.oss-cn-hangzhou.aliyuncs.com/user-29090-files/0ba628c3-9051-4659-95fd-e5fce36399c3/ev_sdk_demo4.0.zip
3.3.2 复制代码文件到 ev_sdk 文件夹路径下
cp -r ev_sdk_demo4.0/* ./ev_sdk/
3.3.3 修改配置文件 config/algo_config.json
注意这里的顺序,要跟模型训练pt的类别顺序,要一致。

3.3.4 修改 src/Configuration.hpp 文件
修改容器 targetRectTextMap 修改为所参加比赛的类别。

3.3.5 src/configuration.hpp 后添加定义报警类型 alarmType

3.3.6 修改 src/SampleAlgorithm.cpp 模型 onnx 路径
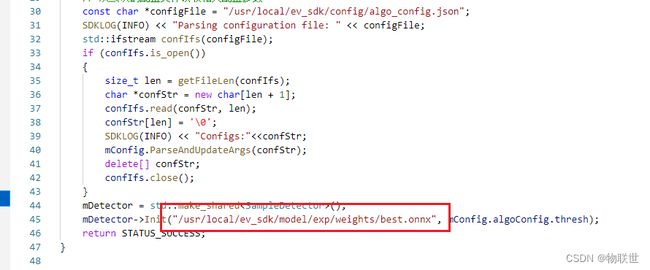
3.3.7 修改 src/SampleDetector.cpp 模型推理。
这里我没用官方的,采用了修改过后的TensorRT 推理代码,比官方快,精度高。
源代码CPP 具体实现。
#include 至此,已修改好推理代码。
四、发起调试。
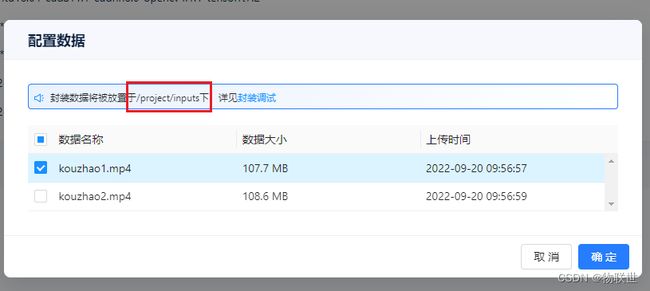
4.1 配置数据,选择对应的文件
4.2 创建 debug_gpu.sh 文件, 内容如下。
#编译SDK库
mkdir -p /usr/local/ev_sdk/build
cd /usr/local/ev_sdk/build
cmake ..
make install
#编译测试工具
mkdir -p /usr/local/ev_sdk/test/build
cd /usr/local/ev_sdk/test/build
cmake ..
make install
# 调试
cd /usr/local/ev_sdk/bin/
# 这里路径,对应修改为上面的数据名称。
./test-ji-api -f 1 -i /project/inputs/kouzhao1.mp4 -o result.mp4
然后发起调试,执行命令 bash xxx/debug_gpu.sh
五、小结
能学到算法,部署模型等系列流程的真实项目,群里又有大佬教导,又不用花钱。而且完成上分要求,还有奖金拿,这极市,爱了爱了。
在算法开发部署模型时,一定要仔细看官方文档,demo源代码教程(有些坑已经描述了),最好先从官方提供的源代码例子开始,熟悉整个训练算法,部署模型流程。熟悉之后,可以按照自己的想法进行修改。