在了解string之前,我们需要了解模板等等的一些铺垫知识,让我们开始吧!
一、泛型编程
泛型编程是什么意思呢?我们通过下面的例子来具体了解:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
int main()
{
int a = 1, b = 2;
Swap(a, b);
double c=1.33,d=2.33;
Swap(a,b)
}
就拿交换函数来说,当我们交换不同类型的变量的值,那就需要不停的写交换函数的重载,这样代码复用率就较低,那我们能不能创造一个模板呢??
一个Swap的模板,但是我可以用不同的类型去实现这个模板,继而试用它。
如果在 C++ 中,也能够存在这样一个 模具 ,通过给这个模具中 填充不同材料 ( 类型 ) ,来 获得不同材料的铸件 ( 即生成具体类型的代码)。 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
二、模板(初阶)
模板分为:函数模板和类模板
1.函数模板
1.单参数类型
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定 类型版本。 就拿Swap来说: typename 是 用来定义模板参数 关键字,T是类型(也可以用class,(class T))
templatevoid Swap(T& left, T& right) { T temp = left; left = right; right = temp; } int main() { int a = 1, b = 2; Swap(a, b); int x = 1, y = 2; Swap(x, y); double m = 1.1, n = 2.2; Swap(m, n); char p = 'a', q = 'b'; Swap(p, q); Swap(m,a);//不同类型 }
那么,具体是怎样实现的呢?
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模 板就是将本来应该我们做的重复的事情交给了编译器。
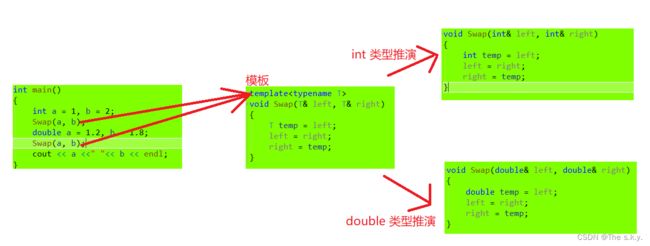
编译器通过类型推演,将函数模板进行实例化,对应的T就会替换成具体的类型,模板实例化是用几个实例化几个,不是所有不同类型都提前模板实例化。
1.当变量类型相同,但是变量不同,调用Swap();模板实例化只会实例化一个,因为虽然变量不同,但类型相同,模板实例化就是将T换成具体的类型。
2.当Swap(m,a),变量是不同类型时,会发生什么??
因为在推演void Swap(T& left, T& right);时,T的类型不明确,就会发生错误(推演报错),直接报错
但如果不用模板,我们自己这样:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
int main()
{
int a=2;
double b=2.22;
Swap(a,b);
}
可能有人就会想:在Swap(a,b)中,会不会a和b发生饮食类型转化呢?较小的类型转化成较大的类型。
当然不会:隐式类型转化只有在 赋值:b=3;(产生临时变量);函数传参的时候(产生临时变量),才会发生隐式类型转化。
函数形参是引用,当类型是引用时,我们就要小心:是否会发生权限放大?当b传值时,中间的临时变量具有常性(只读),而形参是可读可写,权限就会放大,也是不可以通过的,除非加了const,但是加了const就无法交换了,所以这样还是行不通的!
自动推演实例化和显式实例化:
templateT Add(const T& left, const T& right) { return left + right; } int main() { int a1 = 10, a2 = 20; double d1 = 10.1, d2 = 20.2; // 自动推演实例化 cout << Add(a1, a2) << endl; cout << Add(d1, d2) << endl; cout << Add((double)a1, d2) << endl; //强制类型转化也是产生临时变量,不是改变a1 cout << Add(a1, (int)d2) << endl; // 显示实例化 cout << Add (a1, d2) << endl;//隐式类型转化 cout << Add (a1, d2) << endl; return 0; }
在自动推演实例化中,必须强转,不然还是和之前问题一样,该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 double类型而报错。 (推演报错)
不强转情况:显示实例化,:在函数名后的<>中指定模板参数的实际类型(我让你怎么来你就怎么来!)
在函数名后加入了指定模板参数后,就会在实例化时,T直接是指定的类型,这样就会发生隐式类型转换。
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅 Add(a1, d1); 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
2.多参数类型
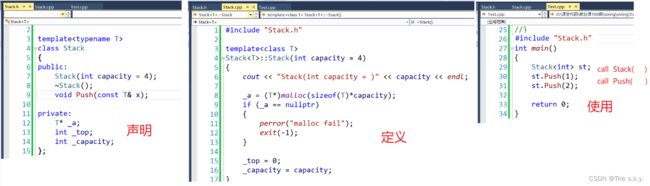
template 此时,当Add(不同类型时),就不会发生推演错误,你是什么类型就会推演成什么模板函数。 当模板函数和自己实现的函数是否可以同时存在时? 当自己写的函数和模板函数同时存在时,二者不会冲突,在之前我们讲过他们的函数名修饰规则是不同的。 同时存在,且调用时,首先会调用自己写的函数。因为模板函数相当于一个半成品,他需要推演实例化才会生成具体的函数,所以当然先使用自己实现的。 如果一定要使用模板函数的话,就需要显示实例化:Add 这就叫泛型编程,与具体的类型无关! 类模板与函数模板不同的是:类模板统一显式实例化,不需要推演,或者说没有推演的时机,而函数模板实参传递形参时,就会发生推演实例化。 格式: 可能有人会问:s1=s2; 会不会发生隐式类型转换呢?当然不会,隐式类型转换只有在类型相近才会发生。 接下来创建一个数组类模板: 我们可以发现,类对象居然也可以使用数组那一套了??当然是取决于运算符重载。 他与普通数组最大的区别是: 1. 普通数组对于数组越界的这种情况,只能随机的抽查!而我们自己实现的类模板可以严格的控制越界访问这种情况!别说越界修改,越界访问都不行! 2.效率上因为[]是运算符重载,使用就会调用函数开辟栈帧,但是若定义到类中,并且加inline,就对于效率来说,那真是完美! 我们在实现数据结构的时候,是不是会经常去分几个文件去实现不同模块的功能? (个人习惯).h文件中,我们写声明;.cpp文件中,我们写定义;test.cpp中,我们测试使用 但今天学习的模板就不能这么做了!!具体不能怎么做,我们上代码: 如果这样写的话,他就会报链接错误(就是在使用时找不到定义) 我们知道,在预处理阶段,就会将.h头文件展开,test.cpp中只有声明,在调用函数时,就会去找他的地址(call stack()),那么在编译的时候,编译器允许只有声明没有函数,相当于你可以先给他一个承诺,兑不兑现后面再说。 但在链接的时候,test.cpp中,却不能找到它的地址,这是为什么??这就是模板和其他的区别! 链接错误原因: .cpp中的定义,不是实例化模板,他只是一个模板,没有任何实例化成任何类型。所以你在使用类模板的时候,压根就找不到它的定义,当然也找不到地址了,这不就链接错误了吗? 看上图:stack 用的地方在实例化,但是有声明,没有定义; 定义的地方没有实例化。 解决方法: 那转来转去就是一个问题:stack.cpp中定义没有实例化!! 办法一: 你没有实例化,我给你补上:在定义后面加一个实例化 但是就会有另一个问题,我如果使用的时候,创建不同类型,那模板实例化就要有不同类型,那就要一直补实例化,总不肯用一个补一个吧。 方法二: 那就是模板的编译不分离:(不要将定义和声明一个到.cpp,一个到.h) 当放在一个文件中时,在编译时,.h 文件展开后,定义和声明都在test.cpp中,那直接就会完成模板实例化,就有了函数地址,不需要再去链接了。 链接:只有声明没有定义才会到处去找定义。 那有人就会问,加inline可以吗? inline当然不可以,加了inline后,直接不产生符号表,还存在什么地址吗? 直接放类中也不行,当数据量大的时候,都挤到一推,代码阅读性很差,会傻傻搞不清! 到此这篇关于C++印刷模板使用方法详解的文章就介绍到这了,更多相关C++印刷模板内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!template

3.模板函数和自定义函数
//专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template
2.类模板
template
namespace mj
{
template
3.模板不支持分离编译
template