数据结构 | 顺序表SeqList【增、删、查、改~】
不止增、删、查、改四件套哦~
- 概念及结构
-
- 前言
- 分类
-
- 静态顺序表
- 动态顺序表
- 接口实现
-
- 初始化【Init】
- 销毁【Destroy】
- 尾插【PushBack】
-
- 本地扩容和异地扩容【生活小案例1:酒店开房】
- 尾删【PopBack】
- 打印输出【Print】
- 阶段测试1
- 头插【PushFront】
- 头删【PopFront】
-
- 有关越界访问的拓展【生活小案例2:交警查酒驾】
- ⭐指定位置插入【万能插入复用】
- 阶段测试2
- ⭐指定位置删除【万能删除复用】
- 阶段测试3
- 寻找指定元素的位置【Find】
-
- 查出位置删除指定的数
- 不断查询位置删除所有指定的数
- 二分查找的思维❓【生活小案例3:用跑车拉水泥】
- 阶段测试4
- 建立菜单测试
- OJ题目实训
-
- 【LeetCode】26 - 删除有序数组中的重复项
- 【LeetCode】27 - 移除元素
- 【LeetCode】88 - 合并两个有序数组
- 总结与提炼
概念及结构
前言
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改
- 对于顺序表,是一个统称,其实简单来说,就是我们在C语言中学习过的数组。对于顺序表呢,你要记住一点的是内容是需要连续存储的,那这点是不是和数组的特性很类型的
- But顺序表和数组还是有一些区别的,我们先来看一下顺序表可以分为哪两大类
分类
首先对于顺序表,是可以分为静态顺序表和动态顺序表两类,我们一般会选择使用动态顺序表
静态顺序表
- 静态顺序表:使用定长数组存储元素
#define MAX 10000 //小了不够用,大了浪费
typedef int SLDataType;
typedef struct SeqList {
SLDataType data[MAX]; //存放顺序表中的元素
int length; //记录存储了多少个有效数据
}SL;
- 可以看到,以上结构体的定义,就是属于静态顺序表的,分为数据域和数据长度,可以看到,其数据域和我们的数组就是一个道理,数组大小是使用宏定义的MAX值,若是数组大小不够了,随时可以更改,变得大一些
- 但是这样不停地去修改数组大小的值真的好吗,当然是不好的,若是你将这个值改小了就不够用了,改大了呢又会浪费空间。这就是我们为什么不去选择静态顺序表的原因
动态顺序表
- 动态顺序表:使用动态开辟的数组存储
typedef int SLDataType;
typedef struct SeqList {
SLDataType* a; //存放顺序表中的元素
int size; //记录存储了多少个有效数据
int capacity; //容量空间大小
}SL;
- 以上就是动态顺序表所定义出的结构体,可以看到,数据域我使用的是一个指针,其中还有size用于记录存储了多少个有效数据,以及capacity表示容量空间大小,是为了判断放入顺序表中的数据是否超出了
- 然后对于这个【typedef int SLDataType】,这个的话是定义一个整体的类型,若是你只将这个数据的类型定义成为int,那么你在下面的函数接口中用到插入删除这个数据时,现在虽然是int整型,但是后面如果有需求改成了字符型或是浮点型,就需要全部进行一个修改,就会变得很麻烦,所以定义这样一个数据类型,是为了后面方便修改,之后我们学习的其他数据结构也会使用到这样的形式。对于数据结构来说因为要实现的接口很多,所以需要提供一些方便修改的东西去减轻开发的负担
- 为了更形象地理解这个结构体封装的变量,我们通过一张图来看看
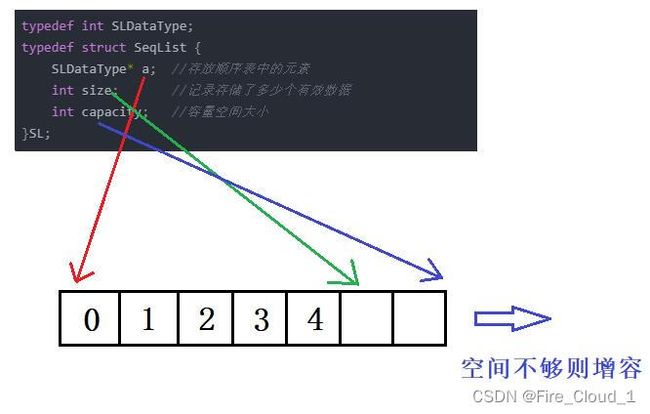
- 可以看到,对于数组名,指向的就是首元素地址,size就是只现在放入顺序表中的元素有多少个,capacity就是这个顺序表总共可以存放多少内容
接口实现
看完了一些基本概念和结构的定义,接下去让我们去看一下顺序表接口的实现
- 那有同学问了,什么是顺序表的接口呢?所谓接口,指的就是函数接口,也就是对顺序表进行增、删、查、改等一系列操作所需要的函数
- 所谓的数据结构,就是需要有一个结构体,去帮我们管理这些数据,然后还需要的是一些函数接口,使我们可以通过调用函数进行增删查改
初始化【Init】
void SLtInit(SL* ps)
{
assert(ps);
ps->a = NULL;
ps->size = 0;
ps->capacity = 0;
}
- 可以看到,如果要对一个顺序表进行初始化,就要通过指针接收其地址,这里的assert就是为了检查外部时候传入了 一个空指针,因为我们不可以对空指针进行一个操作
- 然后就是对应的初始化了,将a也就是存放数组元素的指针置为空,size和capacity置为0
- 有看了学校教材的同学一定疑惑在顺序表初始的时候为什么不为这个数组开辟一块空间,其实这步操作我是做了的,不过不是在这里,而是在下面插入元素的地方。但是你想要再这里直接为数组malloc空间也是可以的,属于比较常规的做法
SL s1;
SLtInit(&s1);
销毁【Destroy】
- 然后是销毁顺序表的实现,对于任何的数据结构,只要你将其初始化了,那内存中就为其开辟了一块地址,当你使用完这块内存地址的时候,就要将其销毁,释放其所在的内存地址
- 当然首先要断言判断这个传进来的顺序表是否为空,若为空则不能释放。在释放时还有判断这个数组是否为空,内部尤其要注意的一点是这个free(),挺多程序的报错都会报在free这里,但是很多小伙伴就不知道为什么,把Destory()去掉之后又没问题了。其实free()这里报错多半是因为你的数组越界了,还有可能是你释放的位置不对,malloc出来的空间但是并没有free()这块空间
- 我们后面在进行Pop删除数据的时候就有可能造成这个数组越界,具体的我们再看下去
void SLDestroy(SL* ps)
{
assert(ps);
if (ps->a)
{
free(ps->a);
ps->capacity = ps->size = 0;
}
}
尾插【PushBack】
void SLPushBack(SL* ps, SLDataType x)
{
ps->a[ps->size] = x;
ps->size++;
}
- 可以看到,因为当前的size是指向末尾元素的下一个位置,因为下标是从0开始的,但是数字的个数是下标+1,所以在上述的尾插中,只需要在s->size处插入待插元素x即可,然后size++,供下一次的插入
- 但仅仅是这样的无限插入就可以了吗,我们知道,数组的容纳量是有限的,所以我们才会选择去使用动态顺序表,去动态开辟一块内存地址,若是出现了我们上面这样数据放不下的情况,就可以进行扩容,显得更加弹性一点
- 那应该在什么时候进行一个扩容呢?是的,也就是当这个size == capacity的时候
if (ps->size == ps->capacity)
- 那么应该怎么扩?扩多少呢?这又是我们需要思考的另一个问题
- 这个地方应该分为两种情况去考虑,若一开始size 和 capacity均为0时,也就是还没有放入数据的时候,此时我们应该为其分配一个4B的空间,此处就是我上面所要说的在数组初始化的时候为其开辟空间,此处当这个容量为0的时候就是数组刚刚初始化的时候,然后再配合下面的realloc就可以实现替代malloc的操作;接着就是其他情况,直接为其扩容原来容量的两倍即可
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
- 此处我使用的是一个三目运算符,看起来会简洁许多
- 想好了要括多少,接下去我们要知道的就是怎么去进行一个扩容,因为这里进行的是一个扩容操作,因此我们尽量是使用realloc合适一些,因为realloc是在已有容量的基础上去做一个更改的,而malloc则是当存储区中的初始值不确定来进行使用的,一般是放在初始化的地方使用
realloc(ps->a, newCapacity * sizeof(SLDataType*));
- 可能有同学对realloc如何使用不太了解,我们打开Cplusplus看一下

- 可以看到,第一个参数需要传入的是一个void的指针类型,也就是原本需要扩容的数组,后面则是你要为其扩容的大小,这个时候看我上面这段代码应该有所理解了,但是千万不要忘了乘【sizeof(SLDataType)】,看到类型是size_t,无符号整型unsigned int的缩写,说明我们要传入的是一个字节数,但是newCapacity只是我们为其分配的数据个数罢了,还要乘上每一个数据个数所占有的空间大小,才算是为这个数组真正地分配出来一块足够可用的空间
- 然后这个时候看到最后一句话,因为realloc返回的类型是一个void*空指针类型,所以我们需要对其返回的值进行一个判断,若是不为空,才去为数组更新为这块新的内存空间大小,若是为空的话,则需要提示扩容失败,然后程序异常退出
- 所以我们拿一些SLDataType*的指针去接收一下这个新扩容出来的数组大小
SLDataType* tmp = (SLDataType*)realloc(ps->a, newCapacity * sizeof(SLDataType*));
- 然后对这个tmp去进行一个空指针异常的判断
//判断是否开辟空间成功【失败会返回空指针null pointer】
if (tmp == NULL)
{
perror("realloc fail\n");
exit(-1); //结束掉程序【程序异常结束】
}
若是以上的操作均没问题,则表示可以进行一个扩容,更新一下数组a以及capacity容量的大小即可
//扩容成功
ps->a = tmp;
ps->capacity = newCapacity;
这些操作就是放在这段代码之上的,这样就显得整个尾插的逻辑非常严谨,不会出现一些Bug
ps->a[ps->size] = x;
ps->size++;
还是给出整体代码看看
void SLPushBack(SL* ps, SLDataType x)
{
if (ps->size == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SLDataType* tmp = (SLDataType*)realloc(ps->a, newCapacity * sizeof(SLDataType*));
//判断是否开辟空间成功【失败会返回空指针null pointer】
if (tmp == NULL)
{
perror("realloc fail\n");
exit(-1); //结束掉程序【程序异常结束】
}
//扩容成功
ps->a = tmp;
ps->capacity = newCapacity;
}
ps->a[ps->size] = x;
ps->size++;
}
本地扩容和异地扩容【生活小案例1:酒店开房】
然后对于扩容这一块呢,既然讲到了,就顺便说说本地扩容和异地扩容这个知识
- 首先我们通过一个生活中的小案例来让大家了解一下这两个扩容机制。平常我们外出旅游的时候由于比较遥远,无法一天之内回来,就会选择一些酒店或者旅馆暂住一宿,那假设这个时候有一个旅行团要去住酒店,因为这家酒店只有单人间,可是呢他们有四个人,因为感情好,想住在一起,所以就让酒店前台开了一些连着的四个房间,互相之间串门方便一些,对于给出的这四个房间其实就是一开始为数组malloc空间,比较小一些
- 然而这个时候呢,他们四个人又分别叫了自己的伙伴来,想要一些进行下一天的结伴旅行,想要和他们住在一起,于是问酒店前台小赵可以不可以在已经为他们开的四个房间的后面再连续地开四个房间,这样他们8个人就可以住在一块了,虽然这很过分,但是刚好真的有连续的房间空出来,所以就又为他们开了四间房,这个时候新开的四间房就叫做本地扩容,就是在与上一次开辟空间后临接着开辟的
- 这个时候这个前台小萌新就不知道怎么办了,于是去隔壁找了一个经验丰富的管理人员老王,老王这个时候想,既然他们是朋友,那就找一个一排空房间给到他们好了,原来的四间房还可以空出来。就在酒店的另一个大区域为他们开了八间房,然后让服务员把原来的四个人叫出来,然后把他们安置到新的四间房内,然后他们住过的房间就可以重新空出来为其他房客用了,然后呢又把新来的四个人安排在他们的后面的接连房间内,于是他们8个人就并排地住在了一起,过上了幸福美满的生活。。。。哦,不对,应该是度过了一个美好的晚上
- 这里说的为他们8个人重新找一块区域安置就叫做异地扩容,也就是将原本开辟的空间中所存放的内容拷贝过来,然后放到新的空间中,接着把需要新放入的内容接着旧的内容之后
通过这么一个案例你应该对本地扩容和异地扩容有所了解了
尾删【PopBack】
- 接下去我们讲讲尾删,也就是从尾部删除顺序表中的数据,那么从尾部删除数据就是将这个size–,但是对比尾插,尾删就这么一句代码可以了吗,嗯。。实现是可以实现,但是呢,会出问题
void SLPopBack(SL* ps)
{
ps->size--;
}
我们可以先用着试试,之后如果出现问了再修改
打印输出【Print】
- 先来讲讲打印输出,这一块不难,就是一个遍历即可
void SLPrint(SL* ps)
{
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}
阶段测试1
有了以上这些功能,我们就可以先来测试一下
- 可以看到,我在初始化这个顺序表后在其后面插入了9个元素,我们来看看是否会出问题
void SeqListTest1()
{
SL s1;
SLtInit(&s1);
SLPushBack(&s1, 1);
SLPushBack(&s1, 2);
SLPushBack(&s1, 3);
SLPushBack(&s1, 4);
SLPushBack(&s1, 5);
SLPushBack(&s1, 5);
SLPushBack(&s1, 5);
SLPushBack(&s1, 5);
SLPushBack(&s1, 5);
SLPrint(&s1);
SLDestroy(&s1);
}

- 很明显,从运行结果看来,并没有出什么大问题,原本是插入4个元素后就不可插入了,会数据溢出,但是呢我实现了一个扩容机制,所以是不会出问题的
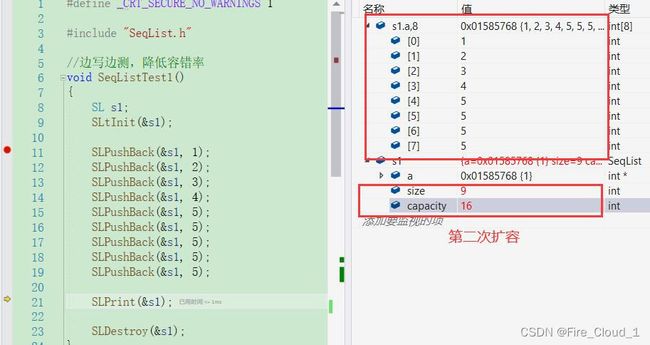
- 带大家DeBug来看一下
- 可以看到,当运行到插入第4个元素时,还没有任何问题
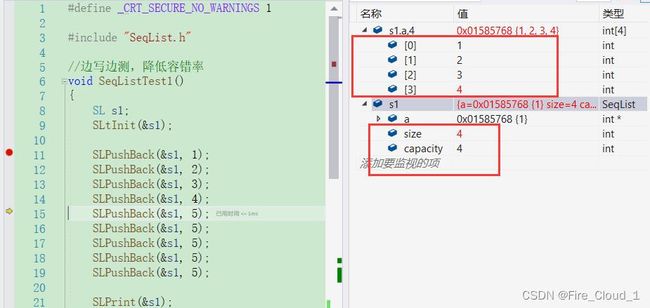
- 然后从这个扩容机制来看,size变成了5,然后capacity增加了它的两倍,来供后面的元素插入
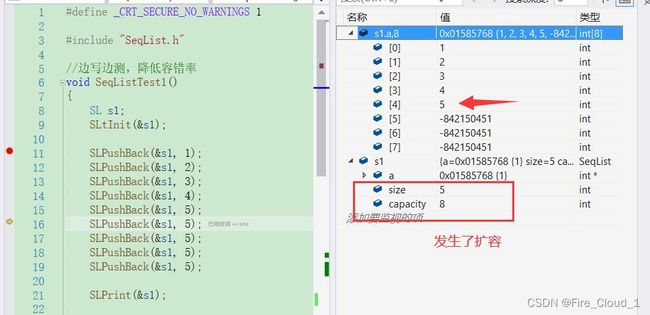
- 然后便可以看到,当插入完最后一个5的时候,又进行了一次扩容,将这个capacity的大小扩充为原来的2倍
- 看完了插入,没有问题,接下来我们看看删除
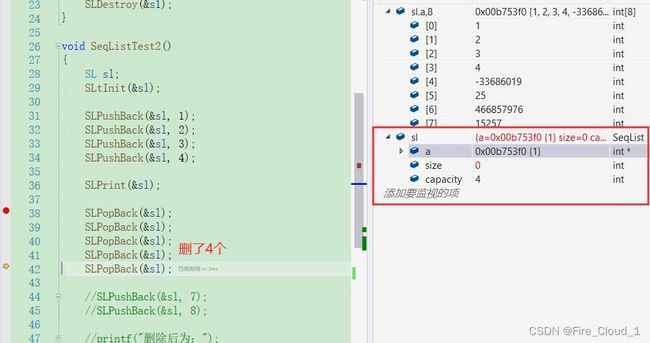
- 首先看到,线性插入了4个元素,然后我们要使用PopBack进行一个尾删

- 可以看到,此处已经删除了4个元素,size == 0,即将删除第5个元素
- 然后可以看到,此处size的值变成了-1
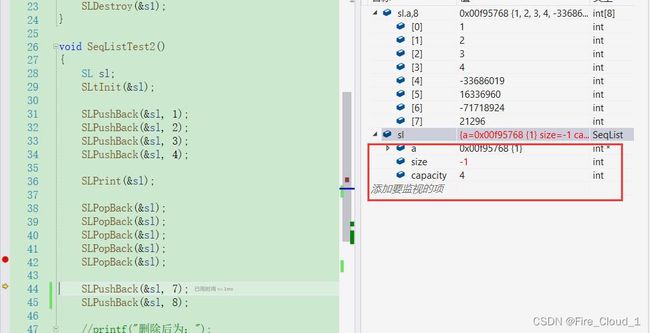
- 然后我们执行两个插入操作
SLPushBack(&sl, 7);
SLPushBack(&sl, 8);
- 可以看到,此时在执行插入操作的时候,就在a[-1]的位置去做了一个插入,那这个时候其实就出现问题了,因为数组上溢出造成的访问越界
- 这个时候的问题就出现了,对应我们上面说的free()时数组越界的情况,编译器在其他地方检查不出来,但是在free()这个地方一定能检查出来,因为你要将申请的这块空间还回去了,那别人肯定要看看你借去的东西有没有问题。所以当编译器一运行到Destory中的free()时,就会报出错误
- 所以大家写代码的时候要谨慎一些,不要出现数组越界的错误,在Java中可能有【ArrayIndexOutOfBoundsException】这种数组下标越界异常检测,但是在C/C++中可就要我们自己去调试查找了,到时候调Bug调到奔溃可是你自己落下的根源
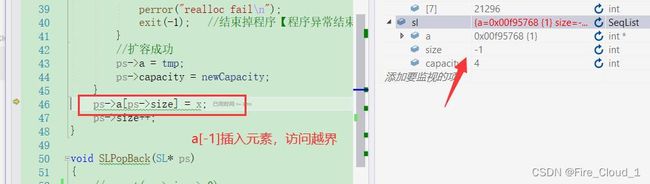
- 那有同学问,这该怎么办呢,系统完全检查不出错误来呀!这个时候其实就要用到我们的assert断言了,在Pop尾删的的函数中加上这个,去检查这个size是否被减得小于0了
assert(ps->size > 0);
- 可以看到,此时编译器报了一个警告,然后还明确地指出了什么地方有问题,那有同学说,这个断言也太屌了,有了这个断言完全就是犹如神助呀,断言确实是我们在写程序时很重要的一个东西,可以帮助我们快速定位何处出现了问题
- 但是要注意的是,断言是要包含头文件的
#include 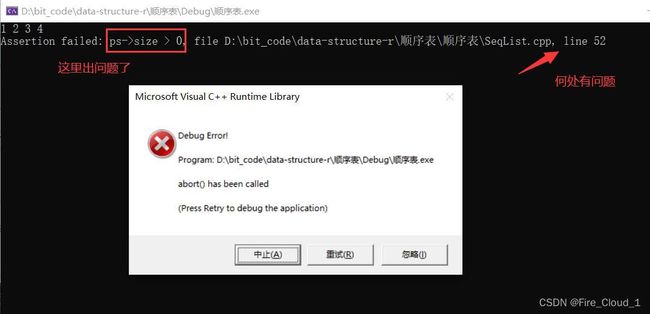
- 所以我们的尾删应该这么写才是准确的
void SLPopBack(SL* ps)
{
assert(ps->size > 0);
ps->size--;
}
看完尾插和尾删,接下去我们来看看头插和头删
头插【PushFront】
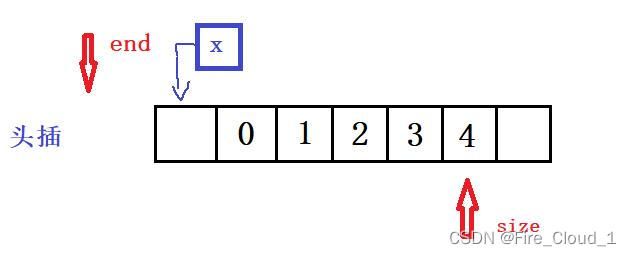
- 首先就是头插,对于头插我们需要一个end指针指向最后一个元素,因为是要在头部插入,所以要先将原有的数据从后往前以后移动,这里要注意,不可以从前往后挪动,举个例子,先将0移动到1的位置,那下一次要去移动1的时候这个1就不存在了

- 所以正确的移动方法应该现将最后一个位置进行一个挪动,那这时候又同学说,要是4后面没有空间了怎么办呢?这是个很好的问题,因为我们上面在实施尾插的时候也有考虑到若是顺序表空间不够了怎么办,这个时候就需要进行扩容,但如果再在此处写一个扩容的功能就会显得代码很冗余,因此我们将这个检查是否需要扩容的机制单独封装成一个函数,那这就成了一个独立的功能
- 接下来让我们来看看代码
void SLCheckCapacity(SL* ps)
{
//扩容
/* 酒店的案例
* 原地扩容:发现与上一次开辟空间旁有足够的位置
* 异地扩容:没有足够的位置,重新找一块地方,将原来开辟空间中的内容自动拷贝过来放在新空间中
* 然后释放原来的空间
*/
if (ps->size == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SLDataType* tmp = (SLDataType*)realloc(ps->a, newCapacity * sizeof(SLDataType*));
//判断是否开辟空间成功【失败会返回空指针null pointer】
if (tmp == NULL)
{
perror("realloc fail\n");
exit(-1); //结束掉程序【程序异常结束】
}
//扩容成功
ps->a = tmp;
ps->capacity = newCapacity;
}
}
- 可以看到,我将这个扩容机制单独封装成为一个模块,这样下面需要的函数均可以进行一个调用
void SLPushFront(SL* ps, SLDataType x)
{
assert(ps);
SLCheckCapacity(ps);
int end = ps->size - 1;
while (end >= 0)
{
ps->a[end + 1] = ps->a[end];
end--;
}
ps->a[0] = x;
ps->size++;
}
- 代码逻辑的话就是先让这个end首先指向size的前一个位置,然后通过【ps->a[end + 1] = ps->a[end];】进行一个移位操作,这里的循环边界值大家要注意,当end = 0的时候就是在移动第一个数据了,是满足条件的。然后让这个end<0时,便跳出了循环,此时下标为0的位置便空了出来,将这个需要头插的元素放入这个位置即可,当然插入了元素size就要++,表示数据个数+1
- 看完了头插,对比尾插你觉得那一个方法的效率更高呢,很明显是尾插,对于尾插,它的时间复杂度是O(1),而对于头插呢,其时间复杂度为O(N),因为当你需要插入一个数据时其余数据就需要挪动N - 1次,这也是会消耗时间的
头删【PopFront】
- 讲完头插,那对应的肯定有头删,对于头删,它刚好和头插相反,需要从前往后删,假设说你要删除的是下标为1的这个位置上的数,那就需要将2先移动到1的位置,然后将3再移动到2的位置,最后将4移动到3的位置。若是这个时候你从后往前去挪动,也会造成覆盖的情况
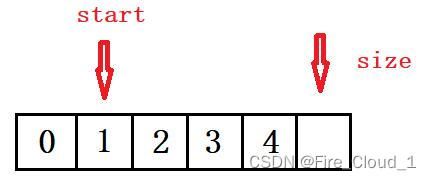
- 在这里我们需要定义一个start开始指针指向顺序表的开头位置,但是这里有两种初始的放置方法:第一个是将start置于0的位置,然后执行a[start + 1] = a[start]的操作,这个时候start停止的位置需要是在【size - 2】的位置,此时a[start + 1]才算是有效的,若是停在【size - 1】的位置,拿去访问a[start + 1]就是一个空的位置,会造成访问越界的问题
- 然后对于另一种方法就是让start从下标为1的位置开始,然后执行a[start - 1] = a[start],因为最大访问的是a[start]所以到这个【size - 1】的位置即可
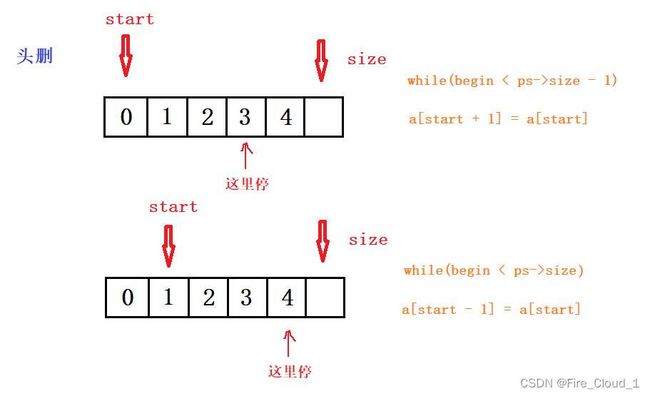
- 我们来看一下具体代码,我是用的是下面这种
//头删【从前往后挪】
void SLPopFront(SL* ps)
{
int start = 1;
while (start < ps->size)
{
ps->a[start - 1] = ps->a[start];
++start;
}
ps->size--;
}
- 看了这个代码后大家觉得这个代码严谨吗?可以运行吗?我们一起来运行看看

- 看到这段代码,我在插入完5个数据实行了删除数据,而且一删就删了6个,此时程序并没有出问题,但是我们通过DeBug看看
- 可以看到,此时当删除了6个元素的时候,数组个数size已经变成了-1,但是下面我即将执行一个PushBack的操作,也就是在-1这个位置插入元素

- 然后程序走到这里也没有出现问题,而且继续执行的话也是不会报出错误,很明显编译器是检查不出来这种越界访问呢的情况的,那这个时候要怎么办呢?

- 没错,就是assert断言,我们需要在头删的部分加一个assert的断言判断,当这个size = 0是就不可以继续删除元素了,因为当size = 0时,此时顺序表中已经是没有元素了,所以不可以继续执行删除操作
//头删【从前往后挪】
void SLPopFront(SL* ps)
{
//size减到0就不能删除了
assert(ps->size > 0); //检查都要放前面
int start = 1;
while (start < ps->size)
{
ps->a[start - 1] = ps->a[start];
++start;
}
ps->size--;
}
- 代码的逻辑我已经分析过了,你可以对照着我的分析理一遍代码
有关越界访问的拓展【生活小案例2:交警查酒驾】
- 有同学看了上面的头删部分,觉得为什么会错在越界访问这么一说,然后编译器又查找不出来,我们通过一个数组访问的案例来看看
int a[10] = { 0 };
//越界读,一般不会被检查出来
printf("%d\n", a[10]);
printf("%d\n", a[11]);

- 可以看到,此处只是访问大了一个很大的随机负数值,但是并没有进行一个报错,所以可以看到若是越界了,编译器也不一定能查找出来,我们再来看一个,对这个越界的位置进行一个值的修改

- 很明显,当进行这个越界修改时,就引发了异常的错误,但是你再看下面这个,但我对下标为11的位置进行一个值的修改时,又不会报错了

- 下标为12的位置也是一样不会出问题

- 但是可以看到,当去访问这个下标为13的位置并且进行一个读写的时候,又报出了错误,那可以看出,编译器对于【越界读取】是不太可能查出来,但是对于【越界读写】却有可能会查出这个错误,那编译器就是这样,琢磨不透,你有什么办法呢?

- 接下来给大家讲一个有关酒驾的生活小案例,你就明白编译器是怎么想的了

- 其实编译器查错就和交警查酒驾是一个道理,比如说交警大队看今天三环的车很多,然后又是元宵佳节,于是在所里吃了即可汤圆后立马出动开始查酒驾,那他们肯定是在某一个路口安排一两名交警,然后让车主停下来一一吹气,但是这一两个人的力量是单薄的,也不可以会出动一大批的交警去查酒驾,于是呢就会有一些漏网之鱼逃过了交警的查询,心想【非常地开心】,然后家里开始联系亲朋好友准备吃席了☎️
- 所以说呢,这个编译器差错也是和交警查就要一个道理,不可能所有的错误都被它找到然后排查出来,最多也就是十个里面找打4 5个这样,但是为什么编译器的查错是随机的呢?
- 这又可以联系交警查酒驾了,来查酒驾的路上他们发现了一条羊肠小道,而且道上有很多车轮印,这个时候大队长就想很有可能这群酒驾的人会从此经过,于是便在此处安置了3名交警。果然,在两小时后的查询过程中,其他地方很少查出来酒驾的人,但是在那条羊肠小道上却检测出了6 7个酒驾的人,编译的思维可能也是这样的,有时候觉得这个地方可能有错误,就去排查一下,可能刚好被它接连地找到了一堆错误,很明显这是随机的
最后要说的就是道路【代码】千万条,行车【暴力】第一条;行车【暴力】不规范,亲人【编译】两行泪
⭐指定位置插入【万能插入复用】
- 好,中间搞了一个小插曲,主要是考虑读者的思维疲劳,开心一刻
- 接下去我们继续来讲这个顺序表的接口实现,接下去要讲的这两个非常重要,若是学会了这两个,那上面的【头插、头删、尾插、尾删】都可以不用了,那有同学说,那我还学他干嘛!!!锻炼一下思维吗,是吧
- 首先来看一下函数的定义,此时不仅是除了要传入需要插的数据,而且还需要具体的位置,这里的位置我是从下标开始的,同学们学校里的教材可能是从1开始的也就是逻辑位置,这个影响不大,开头减个1就行
void SLInsert(SL* ps, int pos, SLDataType x)
- 那具体的思路应该怎么去实现呢,我们通过图示先来看一下

- 其实这个插入和头插法是类似的,因为要在pos的位置插入这个数据,但是呢需要先把这个位置给腾出来,所以就需要执行从后往前移动的这个逻辑,对于一些边界条件的处理也是和头插法一样,就不作过多的细讲
int end = ps->size - 1;
while (end >= pos)
{
ps->a[end + 1] = ps->a[end];
end--;
}
ps->a[pos] = x;
ps->size++;
主要的还是将一些头部的预测检测部分,首先需要思考到的一点是最后一个元素的后面没有位置给其移动放置了怎么办,这个时候就又需要去执行扩容的逻辑了,此时我们只需要调用一下上面封装好的判断是否需要扩容的逻辑
但是这样真的ok了吗?当然不是对这个插入的位置也是需要判断的,上面我有说到,学会了这个接口你就不需要去实现头插和尾插了,那就表示这个接口就可以实现头插和尾插,对于头插的话就是 = 0的情况,对于尾插的话其实就是 = size 这个位置的情况,但是超出了这两个位置就不了
这里我们直接用粗暴一些的方式,也就是利用assert去进行一个断言操作
assert(ps);
assert(pos >= 0);
assert(pos <= ps->size);
- 那对于头插和尾插其实你只需要实现一个复用就可以了,在它们的函数内部传入具体的参数就行,其他的一概不需要写了
void SLPushFront(SL* ps, SLDataType x)
{
//使用Insert复用
SLInsert(ps, 0, x);
}
void SLPushBack(SL* ps, SLDataType x)
{
//使用Insert复用
SLInsert(ps, ps->size, x);
}
阶段测试2
通过上面的讲解,我们通过具体的测试案例来看看功能是否可以真正地实现
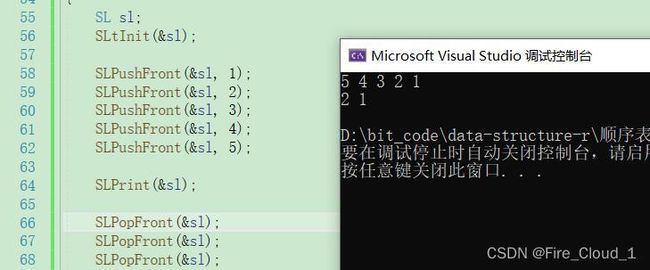
- 以上是头插和尾删的运行结果,可以看到,对于头插,是呈现一个逆序的结果,最先插入的是在最后面,然后对于头删的话也是最先删除最前面的内容,这里我是删了三个
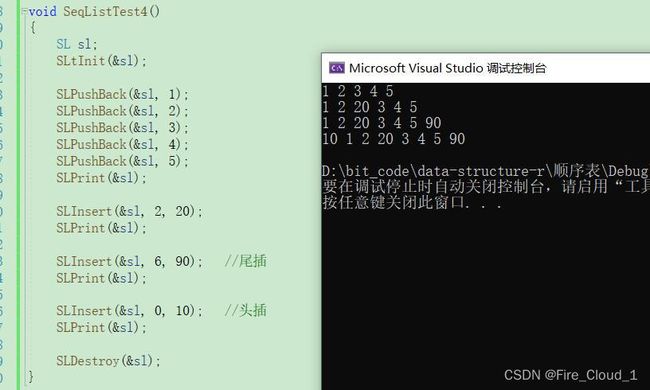
- 上面这一段呢是对于【Insert定位插入的测试】,可以看到,我们使用尾插法首先插入了5个数字【这里的尾插法已经复用了Insert的逻辑】
- 然后使用Insert在“下标为2”的位置插入一个数20,这是对于中间位置的插入
- 接着在此时数据大小位置也就是尾部又插入了一个数据,实现了尾插
- 最后在0的位置插入了数据,实现了头插
给出代码,供大家测试用
void SeqListTest4()
{
SL sl;
SLtInit(&sl);
SLPushBack(&sl, 1);
SLPushBack(&sl, 2);
SLPushBack(&sl, 3);
SLPushBack(&sl, 4);
SLPushBack(&sl, 5);
SLPrint(&sl);
SLInsert(&sl, 2, 20);
SLPrint(&sl);
SLInsert(&sl, 6, 90); //尾插
SLPrint(&sl);
SLInsert(&sl, 0, 10); //头插
SLPrint(&sl);
SLDestroy(&sl);
}
⭐指定位置删除【万能删除复用】
- 好,说完了指定位置插入,接下去我们来说说指定位置删除,这段逻辑其实和头删法的逻辑差不多,我们先来看一下图解
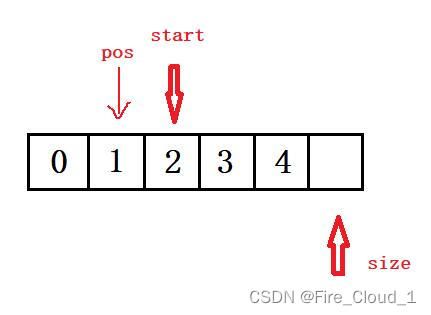
- 也是一样,若是要删除下标为1这个位置上的数,就需要将234都往前挪动一个位置,就是需要【从前往后】移动,首先让这个start指向pos的下一个位置,然后让2移到1的位置,再让3移到2的位置,依次类推,就可以实现一个删除的逻辑
- 对于删除其实也是一样,你需要去判断这个pos的位置是否合法,也就是极端的两个位置是都可以删除,首先是0这个位置,这其实就相等于头删法;然后就是末尾的这个位置,对于size这个位置和插入不一样,对于尾插的话是可以插入在最后一个位置的,但是对于尾删的话是需要有一个具体的值,否则的话也算是访问越界了
- 给出具体的代码给你看看
//指定位置删除
void SLErase(SL* ps, int pos)
{
assert(ps);
assert(pos >= 0);
assert(pos < ps->size);
//assert(ps->size > 0); 走不到这里
int start = pos + 1;
while (start < ps->size)
{
ps->a[start - 1] = ps->a[start];
start++;
}
ps->size--;
}
- 然后对于尾删和头删的话,改成这样就好了,一个是传入【pos = 0】,另一个是传入【pos = ps->size - 1】
void SLPopFront(SL* ps)
{
SLErase(ps, 0);
}
void SLPopBack(SL* ps)
{
SLErase(ps, ps->size - 1);
}
阶段测试3
看完了指定位置删除,我们再来进行一个测试。这里有一点给大家讲一下,对于写代码的话,不要写一大堆放到最后去测,一定要写一部分测一部分,不然到了最后一运行一堆错误,然后改Bug改了半个小时,终于改得只剩最后一个了,结果改完最后一个又报出了其他的错误,这其实就是一个很大的问题了
- 好,小插曲,我们来进行一个测试
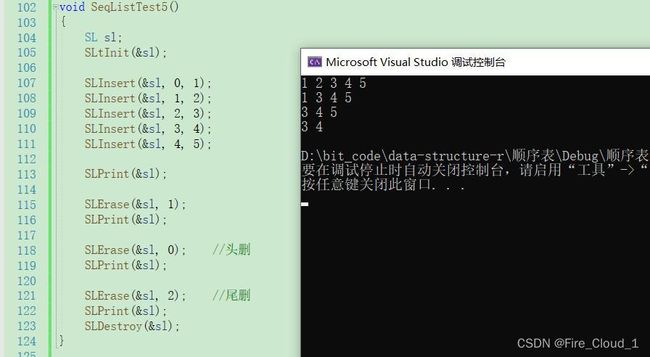
- 从上述代码可以看到,首先是使用Insert进行了一个插入,然后呢又Erase了下标为1这个位置上的数据,接下去两步就是进行的一个头删和尾删,不做多讲
- 给出代码,供大家测试用
void SeqListTest5()
{
SL sl;
SLtInit(&sl);
SLInsert(&sl, 0, 1);
SLInsert(&sl, 1, 2);
SLInsert(&sl, 2, 3);
SLInsert(&sl, 3, 4);
SLInsert(&sl, 4, 5);
SLPrint(&sl);
SLErase(&sl, 1);
SLPrint(&sl);
SLErase(&sl, 0); //头删
SLPrint(&sl);
SLErase(&sl, 2); //尾删
SLPrint(&sl);
SLDestroy(&sl);
}
寻找指定元素的位置【Find】
好,终于到了最后一个接口,也就是寻找这个指定元素的位置
- 这段逻辑其实是挺好实现的,就是去遍历一下这个顺序表,然后根据对应位置上去做一个判断,若是相等的话直接返回这个位置的下标即可,若是没找到的话返回-1
int SLFind(SL* ps, SLDataType x)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
if (ps->a[i] == x)
{
return i;
}
}
return -1;
}
那有同学问了,找出来这个位置有什么用呢,这你就不懂了吧,这可以是一个位置,你能联想到什么呢?没错,就是我们上面说到过的指定位置删除,这时候使用Find找出来的一个位置就可以用在此处,我们一起来看看
查出位置删除指定的数
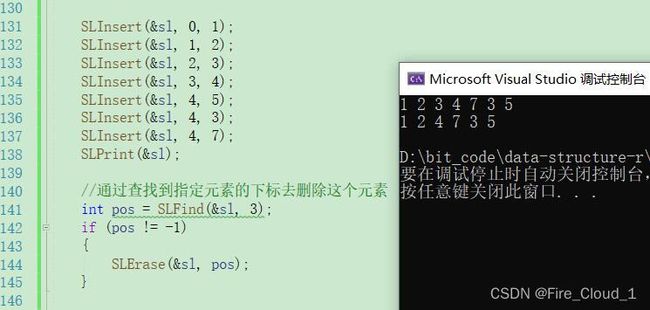
- 可以看到,我通过这个Find找到了元素3所在的位置,然后就可以使用Erase进行一个删除。可以看到,顺序表中的数字3就被删除了
- 这个时候就又有同学问了,万一这个顺序表中有不止一个3呢,那删的是那个,那这里我告诉你,默认是删除第一个的。但是又有同学抬杠,说【我就要删除全部的3】,这个时候该怎么办呢?其实也是有办法的,我们一起来看看
不断查询位置删除所有指定的数
- 对于上面的这种说法,其实就要使用到C++库中的一个叫做缺省参数的东西,怎么说呢,和函数重载差不多吧,就是给到一个begin起始位置,但你删除了第一个3之后,就可以更新这个起始位置,然后继续寻找还有没有3,知道把这个顺序表遍历完为止
- 下面这段代码逻辑整体还是一样的,多了一个起始的begin值以及修改了这个循环的起始条件
int SLFind(SL* ps, SLDataType x, int begin)
{
assert(ps);
for (int i = begin; i < ps->size; ++i)
{
if (ps->a[i] == x)
{
return i;
}
}
return -1;
}
二分查找的思维❓【生活小案例3:用跑车拉水泥】
对于我们上面所说查找一个数字所在的对应下标,那有同学说为什么不使用二分查找呢,这不是来得更加高效一些吗?我们来分析一下
- 其实对于二分查找,并不是完全高效的,它是要建立在数组元素有序的情况下才能成立的,而对于原本就乱序的数组,就需要进行一个排序,但是对于排序来说,存在一定的不确定性,若是你这个数据接近有序,当然排起来不复杂,但若是你原本的这个数组就是整体降序,但是需要排成升序,这就需要耗费不少的时间复杂度
- 所以我们直接通过遍历每一个下标然后一一比较,其实来的更加简洁有效一些
- 这个的话其实又可以联系生活实际,二分查找其实就是一辆跑车,在一些竞技的场合可以起到很关键的作用,但是你将一辆跑车开到工地上去拉水泥,这其实就有点大材小用了,因为这并不是合适。拉水泥应该用专门的水泥车去拉才是更加好的

阶段测试4
- 然后我们来测试一下上面这段逻辑
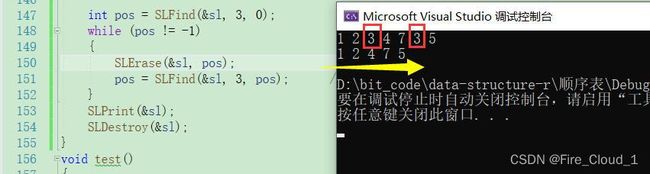
- 可以看到,顺序表中所有元素3都被删除了,我们来理一遍这个逻辑,当Find去顺序表中查找这个元素3然后返回第一次找到的对应下标时,便进入循环,这里要注意,我是用的是while循环,而不是if判断,原因就是这个寻找待删元素是一个不断寻找的过程
- 首先删除了第一个3之后又去继续寻找下一个3,但是很重要的一点就是需要更新这个begin也就是开始查找的位置,那当你删除掉第一个有效元素后,你的起始位置是不是就是这个呢,所以在删除完第一个元素之后需要去更新一个下一次遍历的起始位置,否则的话你又从最前面开始遍历,徒增遍历的次数
也是提供这个测试的代码给大家
void SeqListTest6()
{
SL sl;
SLtInit(&sl);
SLInsert(&sl, 0, 1);
SLInsert(&sl, 1, 2);
SLInsert(&sl, 2, 3);
SLInsert(&sl, 3, 4);
SLInsert(&sl, 4, 5);
SLInsert(&sl, 4, 3);
SLInsert(&sl, 4, 7);
SLPrint(&sl);
//通过查找到指定元素的下标去删除这个元素
//int pos = SLFind(&sl, 3);
//if (pos != -1)
//{
// SLErase(&sl, pos);
//}
int pos = SLFind(&sl, 3, 0);
while (pos != -1)
{
SLErase(&sl, pos);
pos = SLFind(&sl, 3, pos); //更新下一个位置
}
SLPrint(&sl);
SLDestroy(&sl);
}
建立菜单测试
声明并实现完了所有的函数接口,接下去我们将这些接口做成一个菜单
- 很简单,做一个menu菜单,然后通过通过你键盘上输入的选择实行我们上面相对应的操作即可。
void menu()
{
printf("******************************\n");
printf("1.头插 2.头删\n");
printf("3.尾插 4.尾删\n");
printf("5.打印 -1.退出\n");
printf("******************************\n");
}
int main(void)
{
int option = 0;
int val = 0;
SL sl;
SLtInit(&sl);
do {
menu();
printf("请输入你的选择:>");
scanf("%d", &option);
switch (option)
{
case 1:
printf("请输入你要插入的数据:>");
scanf("%d", &val);
while (val != -1)
{
SLPushFront(&sl, val);
scanf("%d", &val);
}
break;
case 2:
SLPopFront(&sl);
break;
case 3:
printf("请输入你要插入的数据:>");
scanf("%d", &val);
while (val != -1)
{
SLPushBack(&sl, val);
scanf("%d", &val);
}
break;
case 4:
SLPopBack(&sl);
break;
case 5:
SLPrint(&sl);
break;
default:
printf("输入错误,请重新输入\n");
break;
}
} while (option != -1);
SLDestroy(&sl);
return 0;
}
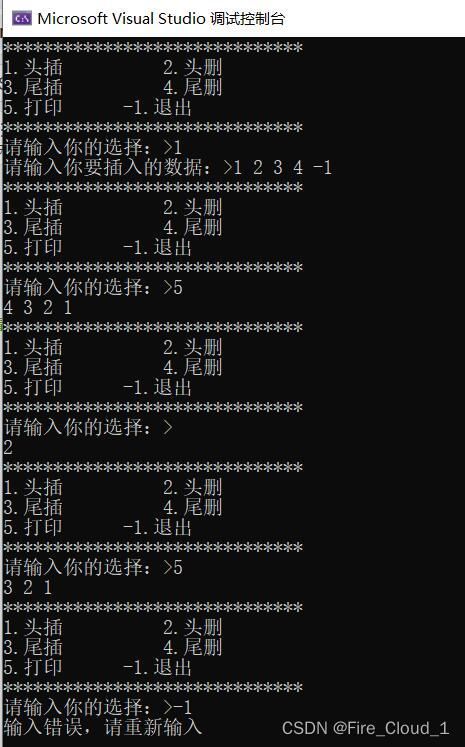
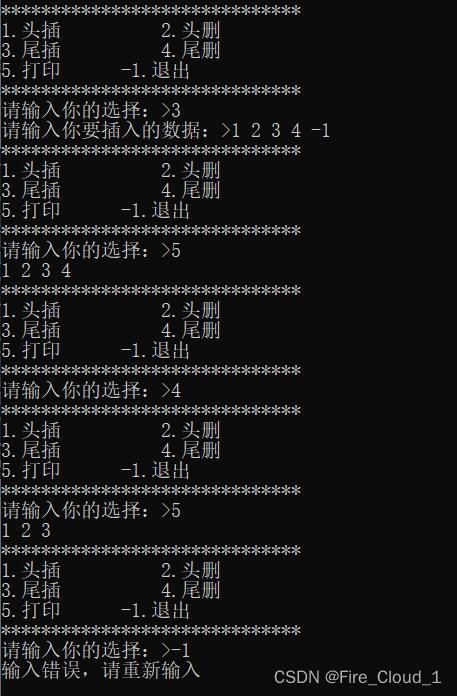
- 通过运行结果来看一下
OJ题目实训
以下三题请通过我另一个专栏【LeetCode算法题解】观看
【LeetCode】26 - 删除有序数组中的重复项
链接
【LeetCode】27 - 移除元素
链接
【LeetCode】88 - 合并两个有序数组
链接
总结与提炼
- 在本文中,我们通过学习顺序表的增、删、查、改以及其他相关操作,对这个和数组的结构极为类似的数据结构——顺序表有了一个基本的认识和了解
- 这是我们接触到的第一种数据结构,也是在数据结构中最简单,最好理解的一种,在后续我们还会学习链表、栈、队列、树、图这些基本的数据结构,关注我一波,带你深入浅出学会【数据结构】
以上就是本文所要描述的所有内容,感谢您对本文的观看,如有疑问请于评论区留言或者私信我都可以