Pytorch分布式训练/多卡训练(一) —— Data Parallel并行(DP)
数据并行是指,多张 GPUs 使用相同的模型副本,但采用同一batch中的不同数据进行训练.
模型并行是指,多张 GPUs 使用同一 batch 的数据,分别训练模型的不同部分.
DP
数据并行在pytorch中就是DP,就是nn.DataParallel
DP就是很容易,只要一句就可以搞定
model = nn.DataParallel(model) 实际上应该是 model = nn.DataParallel(model,device_ids=[0,1,2]) 默认device_ids是全部可见GPU其他内部的操作都由nn.DataParallel来帮你做
事实上DataParallel也是一个Pytorch的nn.Module
# 注: 多卡训练时,默认将 model 和 data 先保存到 id:0 的卡上(这里是第1块卡) # 然后 model 的参数再复制共享到其他卡上; # data 也会平分为 subbatch 到其他卡上. # 故:一般第一张卡显存占用多点. device = torch.device("cuda:0") #或者device = torch.device("cuda") # 1.将模型放到 GPU 上 model = nn.DataParallel(model, device_ids=[0,1])#必须从零开始(这里0表示第1块卡,1表示第2块卡.) model.to(device) # 2.将id:0 卡数据平分到其他卡. data.to(device) #data虽然没有data=nn.DataParallel(data),但是在后面output = model(data)的时候,model的DataParallel会自动将data分发到不同卡上的注意device = torch.device("cuda:0")这里必须是0, 如果指定cuda:1等的话,会报错
DP原理
DP的操作原理是将一个batchsize的输入数据均分到多个GPU上分别计算(此处注意,batchsize要大于GPU个数才能划分)
在DP模式中,总共只有一个进程(受到GIL很强限制)。master节点相当于参数服务器,其会向其他卡广播其参数;在梯度反向传播后,各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。这种参数更新方式,会导致master节点的计算任务、通讯量很重,从而导致网络阻塞,降低训练速度。
假设读入一个 batch 的数据,其大小为 [30, 5, 2],假设采用三张 GPUs,其运行过程大致为:
- 将模型放到主 GPU 上,一般为
cuda:0;- 把模型同步到 3 张 GPUs 上;
- 将总输入 batch 的数据平分为 3 份,这里每一份大小为 [10, 5, 2];
- 依次分别作为每个副本模型的输入;
- 每个副本模型分别独立进行前向计算,假设为 [4, 5, 2];
- 从 3 个 GPUs 中收集分别计算后的结果,并按照次序拼接,即 [12, 5, 2],计算 loss;
- 更新梯度,后向计算.
模型同步 - 数据分发 - 分别前向计算 - loss 计算 - 梯度反传.
也就是当你调用nn.DataParallel的时候,只是在你的input数据是并行的,但是你的output loss却不是这样的,每次都会在第一块GPU相加计算,这就造成了第一块GPU的负载远远大于剩余其他的显卡。
主卡显存占用比其他卡会多很多
官方示例
.to(device)就是把数据从内存放到GPU显存
import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader class RandomDataset(Dataset): def __init__(self, size, length): self.len = length self.data = torch.randn(length, size) def __getitem__(self, index): return self.data[index] def __len__(self): return self.len class Model(nn.Module): # Our model def __init__(self, input_size, output_size): super(Model, self).__init__() self.fc = nn.Linear(input_size, output_size) def forward(self, input): output = self.fc(input) print("\tIn Model: input size", input.size(), "output size", output.size()) return output # Parameters and DataLoaders input_size = 5 output_size = 2 batch_size = 30 data_size = 100 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #这里没用到分布式 rand_loader = DataLoader( dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True ) #模型定义时没有用到分布式 model = Model(input_size, output_size) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") # dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs model = nn.DataParallel(model) model.to(device) for data in rand_loader: input = data.to(device) output = model(input) print("Outside: input size", input.size(), "output_size", output.size())单卡
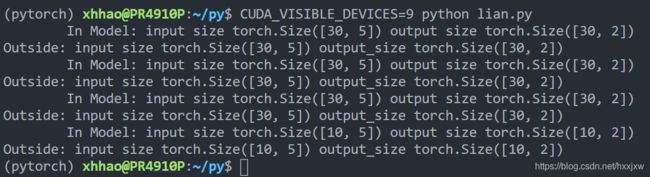
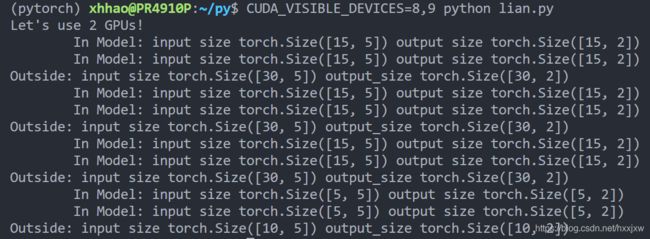
2卡
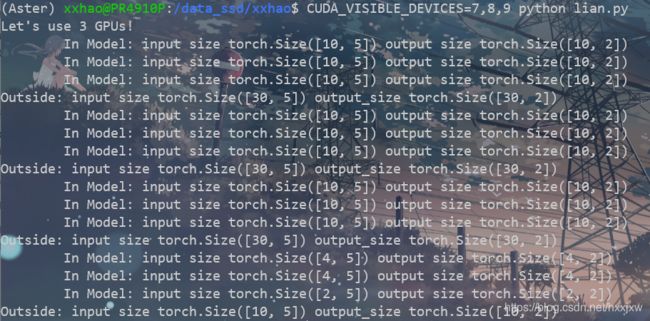
3卡
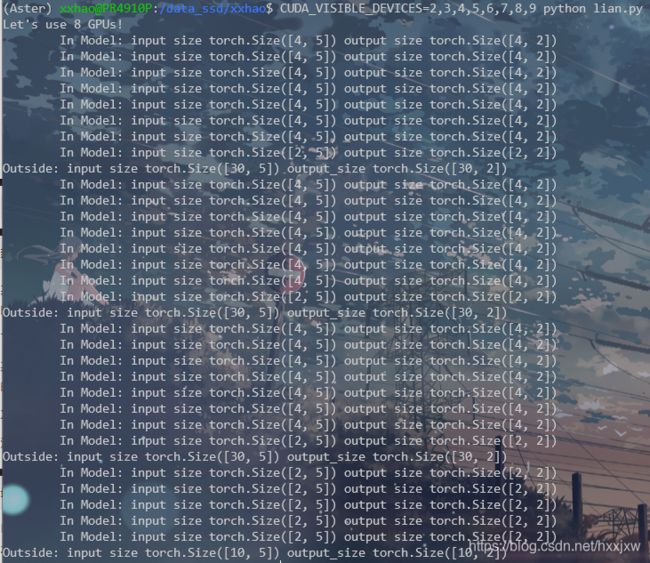
8卡
如果直接 python lian.py, 会直接用到10卡,默认会使用全部avaliable的GPU
If you have no GPU or one GPU, when we batch 30 inputs and 30 outputs, the model gets 30 and outputs 30 as expected. But if you have multiple GPUs, then the result will be different.
DataParallel splits your data automatically and sends job orders to multiple models on several GPUs. After each model finishes their job, DataParallel collects and merges the results before returning it to you.
如果你没有 GPU 或只有一个 GPU,当我们批处理 30 个input和 30 个output时,模型得到 30 个输入并且输出 30 个。 但是如果你有多个 GPU,那么结果就会不同。
DataParallel 会自动拆分输入数据并将其发送到多个 GPU 上的多个模型(这样每个GPU上的模型接收到的输入是多少个就不确定了)。每个模型完成其工作后,DataParallel 会收集并合并结果,然后再将结果返回。