一文深入理解 Java 虚拟机

类文件结构
class类文件的结构
任何一个Class文件都对应着唯一的一个类或接口的定义信息[插图],但是反过来说,类或接口并不一定都得定义在文件里(譬如类或接口也可以动态生成,直接送入类加载器中)。
《Java虚拟机规范》
根据《Java虚拟机规范》的规定,Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:“无符号数”和“表”。
无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,为了便于区分,所有表的命名都习惯性地以“_info”结尾。
字节码由10部分组成,依次是魔数、版本号、常量池、访问权限、类索引、父类索引、接口索引、字段表索引、方法、Attribute。
魔数 每个Class文件的头4个字节被称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件
1个十六进制数对应 4 位 二进制数,那么CAFEBABE 一共 8 个十六进制数,一共需要 32 位二进制数,对应就是 4 个字节
版本号 由minor_version(次版本号)major_version(主版本号) 组成各占两个字节
常量池 Class文件结构中与其他项目关联最多的数据,通常也是占用Class文件空间最大的数据项目之一,另外,它还是在Class文件中第一个出现的表类型数据项目。
常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。字面量比较接近于Java语言层面的常量概念,如文本字符串、被声明为final的常量值等。而符号引用则属于编译原理方面的概念,主要包括下面几类常量:
·被模块导出或者开放的包(Package)
类和接口的全限定名(Fully Qualified Name)
·字段的名称和描述符(Descriptor)
·方法的名称和描述符·方法句柄和方法类型(Method Handle、Method Type、Invoke Dynamic)
·动态调用点和动态常量(Dynamically-Computed Call Site、Dynamically-ComputedConstant)
访问标识 紧接着的2个字节代表访问标志(access_flags),这个标志用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final;等等
类索引(this_class)和父类索引(super_class)都是一个u2类型的数据,而接口索引集合(interfaces)是一组u2类型的数据的集合,Class文件中由这三项数据来确定该类型的继承关系。
字段表(field_info)用于描述接口或者类中声明的变量。Java语言中的“字段”(Field)包括类级变量以及实例级变量,但不包括在方法内部声明的局部变量。段可以包括的修饰符有字段的作用域(public、private、protected修饰符)、是实例变量还是类变量(static修饰符)、可变性(final)、并发可见性(volatile修饰符,是否强制从主内存读写)、可否被序列化(transient修饰符)、字段数据类型(基本类型、对象、数组)、字段名称。
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示
对于数组类型,每一维度将使用一个前置的“[”字符来描述,如一个定义为“java.lang.String[][]”类型的二维数组将被记录成“[[Ljava/lang/String;”,一个整型数组“int[]”将被记录成“[I”。
用描述符来描述方法时,按照先参数列表、后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法void inc()的描述符为“()V”,方法java.lang.StringtoString()的描述符为“()Ljava/lang/String;”,方法int indexOf(char[]source,intsourceOffset,int sourceCount,char[]target,int targetOffset,int targetCount,intfromIndex)的描述符为“([CII[CIII)I”。
7.方法表集合 方法里的Java代码,经过Javac编译器编译成字节码指令之后,存放在方法属性表集合中一个名为“Code”的属性里面,属性表作为Class文件格式中最具扩展性的一种数据项目。
有可能会出现由编译器自动添加的方法,最常见的便是类构造器“
8.属性表(attribute_info)在前面的讲解之中已经出现过数次,Class文件、字段表、方法表都可以携带自己的属性表集合,以描述某些场景专有的信息。《Java虚拟机规范》允许只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,Java虚拟机运行时会忽略掉它不认识的属性。
字节码指令
Java字节码指令就是Java虚拟机能够听得懂、可执行的指令,可以说是Jvm层面的汇编语言,或者说是Java代码的最小执行单元。
javac命令会将Java源文件编译成字节码文件,即.class文件,其中就包含了大量的字节码指令。
Java虚拟机采用面向操作数栈而不是面向寄存器的架构(这两种架构的执行过程、区别和影响将在第8章中探讨),所以大多数指令都不包含操作数,只有一个操作码,指令参数都存放在操作数栈中。
字节码指令分类:
存储和加载类指令:主要包括load系列指令、store系列指令和ldc、push系列指令,主要用于在局部变量表、操作数栈和常量池三者之间进行数据调度;(关于常量池前面没有特别讲解,这个也很简单,顾名思义,就是这个池子里放着各种常量,好比片场的道具库)
对象操作指令(创建与读写访问):比如我们刚刚的putfield和getfield就属于读写访问的指令,此外还有putstatic/getstatic,还有new系列指令,以及instanceof等指令。
操作数栈管理指令:如pop和dup,他们只对操作数栈进行操作。
类型转换指令和运算指令:如add/div/l2i等系列指令,实际上这类指令一般也只对操作数栈进行操作。
控制跳转指令:这类里包含常用的if系列指令以及goto类指令。
方法调用和返回指令:主要包括invoke系列指令和return系列指令。这类指令也意味这一个方法空间的开辟和结束,即invoke会唤醒一个新的java方法小宇宙(新的栈和局部变量表),而return则意味着这个宇宙的结束回收。
公有设计,私有实现
虚拟机实现的方式主要有以下两种:
·将输入的Java虚拟机代码在加载时或执行时翻译成另一种虚拟机的指令集;
·将输入的Java虚拟机代码在加载时或执行时翻译成宿主机处理程序的本地指令集(即即时编译器代码生成技术)。
精确定义的虚拟机行为和目标文件格式,不应当对虚拟机实现者的创造性产生太多的限制,Java虚拟机是被设计成可以允许有众多不同的实现,并且各种实现可以在保持兼容性的同时提供不同的新的、有趣的解决方案。
class文件的变化
Class文件格式所具备的平台中立(不依赖于特定硬件及操作系统)、紧凑、稳定和可扩展的特点,是Java技术体系实现平台无关、语言无关两项特性的重要支柱。
Class文件是Java虚拟机执行引擎的数据入口,也是Java技术体系的基础支柱之一。
虚拟机类加载机制
Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被称作虚拟机的类加载机制。

类的生命周期
java编译时不像其他语言需要连接,类型的加载、连接和初始化过程都是在程序运行期间完成的。编写一个面向接口的应用程序,可以等到运行时再指定其实际的实现类,用户可以通过Java预置的或自定义类加载器,让某个本地的应用程序在运行时从网络或其他地方上加载一个二进制流作为其程序代码的一部分。运行时加载广泛应用于Java程序之中。

《Java虚拟机规范》则是严格规定了有且只有六种情况必须立即对类进行“初始化”(而加载、验证、准备自然需要在此之前开始):
1)遇到new、getstatic、putstatic或invokestatic这四条字节码指令时,如果类型没有进行过初始化,则需要先触发其初始化阶段。能够生成这四条指令的典型Java代码场景有:·使用new关键字实例化对象的时候。·读取或设置一个类型的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候。·调用一个类型的静态方法的时候。
2)使用java.lang.reflect包的方法对类型进行反射调用的时候,如果类型没有进行过初始化,则需要先触发其初始化。
3)当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
4)当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
5)当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。
6)当一个接口中定义了JDK 8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
接口与类真正有所区别的是前面讲述的六种“有且仅有”需要触发初始化场景中的第三种:当一个类在初始化时,要求其父类全部都已经初始化过了,但是一个接口在初始化时,并不要求其父接口全部都完成了初始化,只有在真正使用到父接口的时候(如引用接口中定义的常量)才会初始化。
类加载过程
加载
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
获取类的二进制字节流的形式
·从ZIP压缩包中读取,这很常见,最终成为日后JAR、EAR、WAR格式的基础。
·从网络中获取,这种场景最典型的应用就是Web Applet。·运行时计算生成,这种场景使用得最多的就是动态代理技术,在java.lang.reflect.Proxy中,就是用了ProxyGenerator.generateProxyClass()来为特定接口生成形式为“*$Proxy”的代理类的二进制字节流。
·由其他文件生成,典型场景是JSP应用,由JSP文件生成对应的Class文件。·从数据库中读取,这种场景相对少见些,例如有些中间件服务器(如SAP Netweaver)可以选择把程序安装到数据库中来完成程序代码在集群间的分发。
·可以从加密文件中获取,这是典型的防Class文件被反编译的保护措施,通过加载时解密Class文件来保障程序运行逻辑不被窥探。
验证
验证阶段大致上会完成下面四个阶段的检验动作:文件格式验证、元数据验证、字节码验证和符号引用验证。
“停机问题”(Halting Problem)[插图],即不能通过程序准确地检查出程序是否能在有限的时间之内结束运行。
准备
正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
首先是这时候进行内存分配的仅包括类变量,而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中。其次是这里所说的初始值“通常情况”下是数据类型的零值,假设一个类变量的定义为:
public static int value=123;那变量value在准备阶段过后的初始值为0而不是123,因为这时尚未开始执行任何Java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器

解析
Java虚拟机将常量池内的符号引用替换为直接引用的过程。
符号引用与虚拟机实现的内存布局无关,引用的目标并不一定是已经加载到虚拟机内存当中的内容。直接引用是可以直接指向目标的指针、相对偏移量或者是一个能间接定位到目标的句柄。直接引用是和虚拟机实现的内存布局直接相关
1.类或接口的解析
需要判断该类是否是数组类型
如果我们说一个D拥有C的访问权限,那就意味着以下3条规则中至少有其中一条成立:
·被访问类C是public的,并且与访问类D处于同一个模块。
·被访问类C是public的,不与访问类D处于同一个模块,但是被访问类C的模块允许被访问类D的模块进行访问。
·被访问类C不是public的,但是它与访问类D处于同一个包中。
2.字段解析
首先将会对字段表内class_index[插图]项中索引的CONSTANT_Class_info符号引用进行解析,也就是字段所属的类或接口的符号引用;
3.方法解析
先解析出方法表的class_index[插图]项中索引的方法所属的类或接口的符号引用,如果解析成功,那么我们依然用C表示这个类。
1)由于Class文件格式中类的方法和接口的方法符号引用的常量类型定义是分开的,如果在类的方法表中发现class_index中索引的C是个接口的话,那就直接抛出java.lang.IncompatibleClassChangeError异常。
2)如果通过了第一步,在类C中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。
3)否则,在类C的父类中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。
4)否则,在类C实现的接口列表及它们的父接口之中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果存在匹配的方法,说明类C是一个抽象类,这时候查找结束,抛出java.lang.AbstractMethodError异常。
5)否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError。最后,如果查找过程成功返回了直接引用,将会对这个方法进行权限验证,如果发现不具备对此方法的访问权限,将抛出java.lang.IllegalAccessError异常。
4.接口方法解析
方法解析类似
JDK 9中增加了接口的静态私有方法,也有了模块化的访问约束,所以从JDK 9起,接口方法的访问也完全有可能因访问权限控制而出现java.lang.IllegalAccessError异常。
初始化
初始化阶段就是执行类构造器
·
类加载器
对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。
比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
这里所指的“相等”,包括代表类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法的返回结果,也包括了使用instanceof关键字做对象所属关系判定等各种情况。
从java虚拟机角度看有俩种不同的类加载器:
一:启动类加载器(Bootstrap ClassLoader) C++实现
二:所有其他的类加载器(全部都继承自抽象类java.lang.ClassLoader) java实现
从开发人员角度看:
启动类加载器Bootstrap ClassLoader
作用:负责将存放在
扩展类加载器Extension ClassLoader
这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载
应用程序加载器Application ClassLoader
这个类加载器是由sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器。如果应用程序中没有自定义自己的类加载器,一般情况下这个就是程序中默认的类加载器。
双亲委派模型
双亲委派模型的工作流程:
当类加载器接收到类加载的请求时,它不会自己去尝试加载这个类,而是把这个请求委派给父加载器去完成,每一个层次的类加载器都是如此,因此所有的请求最终都应该传送到启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围内没有找到所需的类)时,子加载器才会尝试自己去加载。
优点:java类随着它的类加载器一起具备了一种带有优先级的层次关系。
举例:比如我们要加载java.lang.Object,它存放在rt.jar中,无论哪个类加载器要加载换个类,都会委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类(上面提到了如何比较俩个类是否'相等')。相反,如果没有双亲委派模型,那么各个类加载器都去自行加载的话,那么在程序中就会出现多个Object类,导致应用程序一片混乱。
双亲委派模型的实现
protected synchronized Class loadClass(String name, Boolean resolve) throws ClassNotFoundException{
//首先检查请求的类是否已经被加载过
Class c = findLoadedClass(name);
if(c == null){
try{
if(parent != null){
//委派父类加载器加载
c = parent.loadClass(name, false);
}
else{
//委派启动类加载器加载
c = findBootstrapClassOrNull(name);
}
}catch(ClassNotFoundException e){
//父类加载器无法完成类加载请求
}
if(c == null){
//本身类加载器进行类加载
c = findClass(name);
}
}
if(resolve){
resolveClass(c);
}
return c;
}
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。不过这里类加载器之间的父子关系一般不是以继承(Inheritance)的关系来实现的,而是通常使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的破坏
JDK12才有双亲委派模型,面对已经存在的用户自定义类加载器的代码,为了兼容这些已有代码,无法再以技术手段避免loadClass()被子类覆盖的可能性,只能在JDK 1.2之后的java.lang.ClassLoader中添加一个新的protected方法findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。
由这个模型自身的缺陷导致的,如果有基础类型又要调用回用户的代码。
由于用户对程序动态性的追求而导致的,这里所说的“动态性”指的是一些非常“热”门的名词:代码热替换(Hot Swap)、模块热部署(HotDeployment)等
OSGi实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结构
Java模块化系统
在JDK 9中引入的Java模块化系统(Java Platform Module System,JPMS)是对Java技术的一次重要升级,为了能够实现模块化的关键目标——可配置的封装隔离机制,Java虚拟机对类加载架构也做出了相应的变动调整,才使模块化系统得以顺利地运作。
·JAR文件在类路径的访问规则:所有类路径下的JAR文件及其他资源文件,都被视为自动打包在一个匿名模块(Unnamed Module)里,这个匿名模块几乎是没有任何隔离的,它可以看到和使用类路径上所有的包、JDK系统模块中所有的导出包,以及模块路径上所有模块中导出的包。
·模块在模块路径的访问规则:模块路径下的具名模块(Named Module)只能访问到它依赖定义中列明依赖的模块和包,匿名模块里所有的内容对具名模块来说都是不可见的,即具名模块看不见传统JAR包的内容。
·JAR文件在模块路径的访问规则:如果把一个传统的、不包含模块定义的JAR文件放置到模块路径中,它就会变成一个自动模块(Automatic Module)。尽管不包含module-info.class,但自动模块将默认依赖于整个模块路径中的所有模块,因此可以访问到所有模块导出的包,自动模块也默认导出自己所有的包。
JDK9以后,扩展类加载器(Extension Class Loader)被平台类加载器(Platform ClassLoader)取代。
当平台及应用程序类加载器收到类加载请求,在委派给父加载器加载前,要先判断该类是否能够归属到某一个系统模块中,如果可以找到这样的归属关系,就要优先委派给负责那个模块的加载器完成加载,也许这可以算是对双亲委派的第四次破坏。
虚拟机执行引擎
Java虚拟机以方法作为最基本的执行单元,“栈帧”(Stack Frame)则是用于支持虚拟机进行方法调用和方法执行背后的数据结构,它也是虚拟机运行时数据区中的虚拟机栈(VirtualMachine Stack)[插图]的栈元素。
栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。
每一个方法从调用开始至执行结束的过程,都对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。
局部变量表
局部变量表(Local Variables Table)是一组变量值的存储空间,用于存放方法参数和方法内部定义的局部变量。在Java程序被编译为Class文件时,就在方法的Code属性的max_locals数据项中确定了该方法所需分配的局部变量表的最大容量。
一个变量槽可以存放一个32位以内的数据类型,Java中占用不超过32位存储空间的数据类型有boolean、byte、char、short、int、float、reference[插图]和returnAddress这8种类型。
第7种reference类型表示对一个对象实例的引用,虚拟机实现至少都应当能通过这个引用做到两件事情,一是从根据引用直接或间接地查找到对象在Java堆中的数据存放的起始地址或索引,二是根据引用直接或间接地查找到对象所属数据类型在方法区中的存储的类型信息,否则将无法实现《Java语言规范》中定义的语法约定。
当一个方法被调用时,Java虚拟机会使用局部变量表来完成参数值到参数变量列表的传递过程,即实参到形参的传递。如果执行的是实例方法(没有被static修饰的方法),那局部变量表中第0位索引的变量槽默认是用于传递方法所属对象实例的引用,在方法中可以通过关键字“this”来访问到这个隐含的参数。
操作数栈
操作数栈(Operand Stack)也常被称为操作栈,它是一个后入先出(Last In First Out,LIFO)栈。同局部变量表一样,操作数栈的最大深度也在编译的时候被写入到Code属性的max_stacks数据项之中。
Java虚拟机的解释执行引擎被称为“基于栈的执行引擎”,里面的“栈”就是操作数栈。

动态连接
每个栈帧都包含一个指向运行时常量池[插图]中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。
Class文件的常量池中存有大量的符号引用,字节码中的方法调用指令就以常量池里指向方法的符号引用作为参数。这些符号引用一部分会在类加载阶段或者第一次使用的时候就被转化为直接引用,这种转化被称为静态解析。另外一部分将在每一次运行期间都转化为直接引用,这部分就称为动态连接。
方法返回地址
当一个方法开始执行后,只有两种方式退出这个方法。
第一种方式是执行引擎遇到任意一个方法返回的字节码指令,这时候可能会有返回值传递给上层的方法调用者(调用当前方法的方法称为调用者或者主调方法),方法是否有返回值以及返回值的类型将根据遇到何种方法返回指令来决定,这种退出方法的方式称为“正常调用完成”(Normal Method InvocationCompletion)。
另外一种退出方式是在方法执行的过程中遇到了异常,并且这个异常没有在方法体内得到妥善处理。这种退出方法的方式称为“异常调用完成(Abrupt Method Invocation Completion)”。一个方法使用异常完成出口的方式退出,是不会给它的上层调用者提供任何返回值的。
无论采用何种退出方式,在方法退出之后,都必须返回到最初方法被调用时的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层主调方法的执行状态。
方法正常退出时,主调方法的PC计数器的值就可以作为返回地址,栈帧中很可能会保存这个计数器值。而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中就一般不会保存这部分信息。
一般会把动态连接、方法返回地址与其他附加信息全部归为一类,称为栈帧信息。
方法调用
方法调用并不等同于方法中的代码被执行,方法调用阶段唯一的任务就是确定被调用方法的版本(即调用哪一个方法),暂时还未涉及方法内部的具体运行过程。
解析
所有方法调用的目标方法在Class文件里面都是一个常量池中的符号引用,在类加载的解析阶段,会将符合“编译期可知,运行期不可变”的方法符号引用转化为直接引用。换句话说,调用目标在程序代码写好、编译器进行编译那一刻就已经确定下来。这类方法的调用被称为解析(Resolution)。
静态方法、私有方法、实例构造器、父类方法4种,再加上被final修饰的方法(尽管它使用invokevirtual指令调用),这5种方法调用会在类加载的时候就可以把符号引用解析为该方法的直接引用。这些方法统称为“非虚方法”(Non-VirtualMethod),与之相反,其他方法就被称为“虚方法”(Virtual Method)。
分派Dispatch
1.静态分派
英文一般是“Method Overload Resolution”,所以其实是个动态概念
public class StaticDispatch {
static abstract class Human{
}
static class Man extends Human{
}
static class Woman extends Human{
}
public void sayHello(Human guy){
System.out.println("Hello guy");
}
public void sayHello(Man guy){
System.out.println("Hello gentleman");
}
public void sayHello(Woman guy){
System.out.println("Hello lady");
}
public static void main(String[] args){
Human man = new Man();
Human woman = new Woman();
StaticDispatch staticDispatch = new StaticDispatch();
staticDispatch.sayHello(man);
staticDispatch.sayHello(woman);
}
}
运行结果
Hello guy
Hello guy
Human hu = new Man():
面代码中的“Human”称为变量的静态类型(Static Type)或者外观类型(Apparent Type),后面的“Man”则称为变量的实际类型(Actual Type),静态类型和实际类型在程序中都可以发生一些变化,区别是静态类型的变化仅仅在使用时发生,变量本身的静态类型不会被改变,并且最终的静态类型是编译期可知的;而实际类型变化的结果在运行期才可确定,编译期在编译程序的时候并不知道一个对象的实际类型是什么?如下面的代码:
//实际类型变化
Human man = new Man();
man = new Woman();
//静态类型变化
sd.sayHello((Man)man);
sd.sayHello((Woman)man);
所有依赖静态类型来决定方法执行版本的分派动作,都称为静态分派。静态分派的最典型应用表现就是方法重载。静态分派发生在编译阶段,因此确定静态分派的动作实际上不是由虚拟机来执行的,这点也是为何一些资料选择把它归入“解析”而不是“分派”的原因。
public class StaticPaiDemo {
public static void sayHello(int i){
System.out.println("int 类型");
}
public static void sayHello(Object obj){
System.out.println("obj 类型");
}
public static void sayHello(long i){
System.out.println("long 类型");
}
public static void sayHello(char i){
System.out.println("char 类型");
}
public static void main(String[] args) {
sayHello(1);
sayHello(1L);
sayHello('a');
}
}
笔者讲述的解析与分派这两者之间的关系并不是二选一的排他关系,它们是不同层次上去筛选、确定目标方法的过程。例如,前面说过,静态方法会在类加载期就进行解析,而静态方法显然也是可以拥有重载版本的,选择重载版本的过程也是通过静态分派完成的。
自动转型还能继续发生多次,按照char>int>long>float>double的顺序转型进行匹配,但不会匹配到byte和short类型的重载,因为char到byte或short的转型是不安全的。
自动装箱
装箱后转型为父类了,如果有多个父类,那将在继承关系中从下往上开始搜索,越接上层的优先级越低。
可见变长参数的重载优先级是最低的,这时候字符'a'被当作了一个char[]数组的元素。
有一些在单个参数中能成立的自动转型,如char转型为int,在变长参数中是不成立的
动态分派
Java语言多态性的另外一个重要体现——重写(Override)。
public class DynamicDispatch {
static abstract class Human{
protected abstract void sayHello();
}
static class Man extends Human{
@Override
protected void sayHello() {
System.out.println("man say hello!");
}
}
static class Woman extends Human{
@Override
protected void sayHello() {
System.out.println("woman say hello!");
}
}
public static void main(String[] args) {
Human man=new Man();
Human woman=new Woman();
man.sayHello();
woman.sayHello();
man=new Woman();
man.sayHello();
}
}
输出结果:
man say hello!
woman say hello!
woman say hello!
根据《Java虚拟机规范》,invokevirtual指令的运行时解析过程[插图]大致分为以下几步:
1)找到操作数栈顶的第一个元素所指向的对象的实际类型,记作C。
2)如果在类型C中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则返回这个方法的直接引用,查找过程结束;不通过则返回java.lang.IllegalAccessError异常。
3)否则,按照继承关系从下往上依次对C的各个父类进行第二步的搜索和验证过程。
4)如果始终没有找到合适的方法,则抛出java.lang.AbstractMethodError异常。
正是因为invokevirtual指令执行的第一步就是在运行期确定接收者的实际类型,所以两次调用中的invokevirtual指令并不是把常量池中方法的符号引用解析到直接引用上就结束了,还会根据方法接收者的实际类型来选择方法版本,这个过程就是Java语言中方法重写的本质。我们把这种在运行期根据实际类型确定方法执行版本的分派过程称为动态分派。
既然这种多态性的根源在于虚方法调用指令invokevirtual的执行逻辑,那自然我们得出的结论就只会对方法有效,对字段是无效的,因为字段不使用这条指令。事实上,在Java里面只有虚方法存在,字段永远不可能是虚的,换句话说,字段永远不参与多态,哪个类的方法访问某个名字的字段时,该名字指的就是这个类能看到的那个字段。当子类声明了与父类同名的字段时,虽然在子类的内存中两个字段都会存在,但是子类的字段会遮蔽父类的同名字段。


输出两句都是“I am Son”,这是因为Son类在创建的时候,首先隐式调用了Father的构造函数,而Father构造函数中对showMeTheMoney()的调用是一次虚方法调用,实际执行的版本是Son::showMeTheMoney()方法,所以输出的是“I am Son”,这点经过前面的分析相信读者是没有疑问的了。而这时候虽然父类的money字段已经被初始化成2了,但Son::showMeTheMoney()方法中访问的却是子类的money字段,这时候结果自然还是0,因为它要到子类的构造函数执行时才会被初始化。main()的最后一句通过静态类型访问到了父类中的money,输出了2。
方法的多分派和单分派
方法的接收者与方法的参数统称为方法的宗量,这个定义最早应该来源于著名的《Java与模式》一书。根据分派基于多少种宗量,可以将分派划分为单分派和多分派两种。单分派是根据一个宗量对目标方法进行选择,多分派则是根据多于一个宗量对目标方法进行选择。
根据上述论证的结果,我们可以总结一句:如今(直至本书编写的Java 12和预览版的Java 13)的Java语言是一门静态多分派、动态单分派的语言。
动态语言支持
JDK 7的发布的字节码首位新成员——invokedynamic指令。
动态类型语言的关键特征是它的类型检查的主体过程是在运行期而不是编译期进行的,满足这个特征的语言有很多,常用的包括:APL、Clojure、Erlang、Groovy、JavaScript、Lisp、Lua、PHP、Prolog、Python、Ruby、Smalltalk、Tcl,等等。那相对地,在编译期就进行类型检查过程的语言,譬如C++和Java等就是最常用的静态类型语言。
Java虚拟机层面对动态类型语言的支持一直都还有所欠缺,主要表现在方法调用方面:JDK 7以前的字节码指令集中,4条方法调用指令(invokevirtual、invokespecial、invokestatic、invokeinterface)的第一个参数都是被调用的方法的符号引用(CONSTANT_Methodref_info或者CONSTANT_InterfaceMethodref_info常量),前面已经提到过,方法的符号引用在编译时产生,而动态类型语言只有在运行期才能确定方法的接收者。
java.lang.invoke包[插图]是JSR 292的一个重要组成部分,这个包的主要目的是在之前单纯依靠符号引用来确定调用的目标方法这条路之外,提供一种新的动态确定目标方法的机制,称为“方法句柄”(Method Handle)。
invokedynamic指令与MethodHandle机制的作用是一样的,都是为了解决原有4条“invoke*”指令方法分派规则完全固化在虚拟机之中的问题,把如何查找目标方法的决定权从虚拟机转嫁到具体用户代码之中,让用户(广义的用户,包含其他程序语言的设计者)有更高的自由度。
基于栈的字节码解释执行引擎
读、理解,然后获得执行能力。大部分的程序代码转换成物理机的目标代码或虚拟机能执行的指令集之前,都需要下图的步骤:

基于栈的指令集与基于寄存器的指令集这两者之间有什么不同呢?举个最简单的例子,分别使用这两种指令集去计算“1+1”的结果,基于栈的指令集会是这样子的: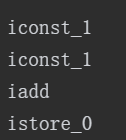
两条iconst_1指令连续把两个常量1压入栈后,iadd指令把栈顶的两个值出栈、相加,然后把结果放回栈顶,最后istore_0把栈顶的值放到局部变量表的第0个变量槽中。这种指令流中的指令通常都是不带参数的,使用操作数栈中的数据作为指令的运算输入,指令的运算结果也存储在操作数栈之中。
而如果用基于寄存器的指令集,那程序可能会是这个样子: mov指令把EAX寄存器的值设为1,然后add指令再把这个值加1,结果就保存在EAX寄存器里面。这种二地址指令是x86指令集中的主流,每个指令都包含两个单独的输入参数,依赖于寄存。
mov指令把EAX寄存器的值设为1,然后add指令再把这个值加1,结果就保存在EAX寄存器里面。这种二地址指令是x86指令集中的主流,每个指令都包含两个单独的输入参数,依赖于寄存。
基于栈的指令集主要优点是可移植,因为寄存器由硬件直接提供[插图],程序直接依赖这些硬件寄存器则不可避免地要受到硬件的约束。
栈架构指令集的主要缺点是理论上执行速度相对来说会稍慢一些,所有主流物理机的指令集都是寄存器架构。
例如:
a=100;
b=200;
c=300;
return (a+b)*c
javap提示这段代码需要深度为2的操作数栈和4个变量槽的局部变量空间

代码编译和优化
Tomcat的类加载

OSGi(Open Service Gateway Initiative)是OSGi联盟(OSGi Alliance)制订的一个基于Java语言的动态模块化规范(在JDK 9引入的JPMS是静态的模块系统)
字节码生成技术与动态代理的实现
字节码生成技术应用于:javac,Web服务器中的JSP编译器,编译时织入的AOP框架,还有很常用的动态代理技术,甚至在使用反射的时候虚拟机都有可能会在运行时生成字节码来提高执行速度。
动态代理中所说的“动态”,是针对使用Java代码实际编写了代理类的“静态”代理而言的,它的优势不在于省去了编写代理类那一点编码工作量,而是实现了可以在原始类和接口还未知的时候,就确定代理类的代理行为,当代理类与原始类脱离直接联系后,就可以很灵活地重用于不同的应用场景之中。
跨越JDK版本之间的沟壑,把高版本JDK中编写的代码放到低版本JDK环境中去部署使用。为了解决这个问题,一种名为“Java逆向移植”的工具(Java Backporting Tools)应运而生,Retrotranslator[插图]和Retrolambda是这类工具中的杰出代表。
JDK的每次升级新增的功能大致可以分为以下五类:
1)对Java类库API的代码增强。譬如JDK 1.2时代引入的java.util.Collections等一系列集合类,在JDK 5时代引入的java.util.concurrent并发包、在JDK 7时引入的java.lang.invoke包,等等。
2)在前端编译器层面做的改进。这种改进被称作语法糖,如自动装箱拆箱,实际上就是Javac编译器在程序中使用到包装对象的地方自动插入了很多Integer.valueOf()、Float.valueOf()之类的代码;变长参数在编译之后就被自动转化成了一个数组来完成参数传递;泛型的信息则在编译阶段就已经被擦除掉了(但是在元数据中还保留着),相应的地方被编译器自动插入了类型转换代码[插图]。
3)需要在字节码中进行支持的改动。如JDK 7里面新加入的语法特性——动态语言支持,就需要在虚拟机中新增一条invokedynamic字节码指令来实现相关的调用功能。不过字节码指令集一直处于相对稳定的状态,这种要在字节码层面直接进行的改动是比较少见的。
4)需要在JDK整体结构层面进行支持的改进,典型的如JDK 9时引入的Java模块化系统,它就涉及了JDK结构、Java语法、类加载和连接过程、Java虚拟机等多个层面。
5)集中在虚拟机内部的改进。如JDK 5中实现的JSR-133[插图]规范重新定义的Java内存模型(Java Memory Model,JMM),以及在JDK 7、JDK 11、JDK 12中新增的G1、ZGC和Shenandoah收集器之类的改动,这种改动对于程序员编写代码基本是透明的,只会在程序运行时产生影响。
编译的概念
前端编译器(叫“编译器的前端”更准确一些)把*.java文件转变成*.class文件的过程;
Java虚拟机的即时编译器(常称JIT编译器,Just In Time Compiler)运行期把字节码转变成本地机器码的过程;
指使用静态的提前编译器(常称AOT编译器,Ahead Of Time Compiler)。
Java中即时编译器在运行期的优化过程,支撑了程序执行效率的不断提升;而前端编译器在编译期的优化过程,则是支撑着程序员的编码效率和语言使用者的幸福感的提高。
编译——1个准备3个处理过程
1)准备过程:初始化插入式注解处理器。
2)解析与填充符号表过程,包括:·词法、语法分析。将源代码的字符流转变为标记集合,构造出抽象语法树。·填充符号表。产生符号地址和符号信息。
3)插入式注解处理器的注解处理过程:插入式注解处理器的执行阶段,本章的实战部分会设计一个插入式注解处理器来影响Javac的编译行为。
4)分析与字节码生成过程,包括:·标注检查。对语法的静态信息进行检查。·数据流及控制流分析。对程序动态运行过程进行检查。·解语法糖。将简化代码编写的语法糖还原为原有的形式。·字节码生成。将前面各个步骤所生成的信息转化成字节码。
执行插入式注解时又可能会产生新的符号,如果有新的符号产生,就必须转回到之前的解析、填充符号表的过程中重新处理这些新符号
插入式注解处理器看作是一组编译器的插件,当这些插件工作时,允许读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行过修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环过程称为一个轮次(Round)。
语义分析与字节码生成
1.标注检查
标注检查步骤要检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配。
常量折叠(Constant Folding)的代码优化:在代码里面定义“a=1+2”比起直接定义“a=3”来,并不会增加程序运行期哪怕仅仅一个处理器时钟周期的处理工作量。
2.数据及控制流分析
数据流分析和控制流分析是对程序上下文逻辑更进一步的验证,它可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。
语法糖
泛型
泛型的本质是参数化类型(Parameterized Type)或者参数化多态(ParametricPolymorphism)的应用,即可以将操作的数据类型指定为方法签名中的一种特殊参数,这种参数类型能够用在类、接口和方法的创建中,分别构成泛型类、泛型接口和泛型方法。
Java选择的泛型实现方式叫作“类型擦除式泛型”(Type Erasure Generics),而C#选择的泛型实现方式是“具现化式泛型”(Reified Generics)。
Java语言中的泛型则不同,它只在程序源码中存在,在编译后的字节码文件中,全部泛型都被替换为原来的裸类型(Raw Type,稍后我们会讲解裸类型具体是什么)了,并且在相应的地方插入了强制转型代码,因此对于运行期的Java语言来说,ArrayList
在没有泛型的时代,由于Java中的数组是支持协变(Covariant)的,引入泛型后可以选择:
1)需要泛型化的类型(主要是容器类型),以前有的就保持不变,然后平行地加一套泛型化版本的新类型。
2)直接把已有的类型泛型化,即让所有需要泛型化的已有类型都原地泛型化,不添加任何平行于已有类型的泛型版。
我们继续以ArrayList为例来介绍Java泛型的类型擦除具体是如何实现的。由于Java选择了第二条路,直接把已有的类型泛型化。要让所有需要泛型化的已有类型,譬如ArrayList,原地泛型化后变成了ArrayList
如何实现裸类型。这里又有了两种选择:一种是在运行期由Java虚拟机来自动地、真实地构造出ArrayList这样的类型,并且自动实现从ArrayList派生自ArrayList的继承关系来满足裸类型的定义;另外一种是索性简单粗暴地直接在编译时把ArrayList还原回ArrayList,只在元素访问、修改时自动插入一些强制类型转换和检查指令。
基于这种方法实现的泛型称为伪泛型。
public static void main(String[] args){
Map map=new HashMap();
map.put("hello","nihao");
map.put("how are you","chifan");
System.out.println(map.get("hello"));
System.out.println(map.get("how are you"));
}
这段代码编译成Class文件,然后用字节码反编译工具进行反编译后,泛型类型都变回了原生类型
public static void main(String[] args){
Map map=new HashMap();
map.put("hello","nihao");
map.put("how are you","chifan");
System.out.println((String)map.get("hello"));
System.out.println((String)map.get("how are you"));
}
java泛型擦除式实现的缺陷:
1.对原始类型(Primitive Types)数据的支持又成了新的麻烦,既然没法转换那就索性别支持原生类型的泛型了吧,你们都用ArrayList
2.运行期无法取到泛型类型信息。

由于List

另外,从Signature属性的出现我们还可以得出结论,擦除法所谓的擦除,仅仅是对方法的Code属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是我们在编码时能通过反射手段取得参数化类型的根本依据。
条件编译
定义一个 final 的变量,然后在 if 语句用中它隔开代码。
public class Hello {
public static void main(String[] args) {
final boolean DEBUG = true;
if (DEBUG) {
System.out.println("Hello, world!");
} else {
// some code
}
}
}
因为编译器会对代码进行优化,对于条件永远为 false 的语句,Java 编译器将不会对其生成字节码。
应用场景:实现一个区分DEBUG和RELEASE模式的程序。
协变与逆变
逆变与协变用来描述类型转换(type transformation)后的继承关系,其定义:如果A、B表示类型,f(⋅)表示类型转换,≤表示继承关系(比如,A≤B表示A是由B派生出来的子类);
f(⋅)是逆变(contravariant)的,当A≤B时有f(B)≤f(A)成立;
f(⋅)是协变(covariant)的,当A≤B时有f(A)≤f(B)成立;
f(⋅)是不变(invariant)的,当A≤B时上述两个式子均不成立,即f(A)与f(B)相互之间没有继承关系。
数组是协变的
Food food = new Fruit();
// or
food = new Meat(); // 即 把子类赋值给父类引用
Fruit [] arrFruit = new Fruit[3];
Food [] arrFood = arrFruit; // 数组协变的
泛型是不变的
List beefList = new ArrayList<>();
List foodList = beefList; //错误:不可协变
beefList = foodList; // 错误 :不可逆变
eat(beefList);// 错误::不可协变
public void addFood(List list){
list.add(new Apple());
}
泛型使用通配符实现协变与逆变。 PECS: producer-extends, consumer-super.
实现了泛型的协变,比如:
List list = new ArrayList
实现了泛型的逆变,比如:
List list = new ArrayList
List foodList = new ArrayList<>();
List appleList = new ArrayList<>();
foodList = appleList; // ok 协变
foodList.add(new Beef()); // 错误 不能执行添加null 以外的操作
foodList.add(new Food());// 错误,同上,
foodlist.add(new Apple()); // 错误,同上
Food food = foodList.get(index); //ok, 把子类引用赋值给父类显然是可以的
可以把 appleList 赋值给 foodList,但是不能对foodList 添加除null 以外的任何对象。
方法的形参是协变的、返回值是逆变的:
通过与网友iamzhoug37的讨论,更新如下。
调用方法result = method(n);根据Liskov替换原则,传入形参n的类型应为method形参的子类型,即typeof(n)≤typeof(method's parameter);result应为method返回值的基类型,即typeof(methods's return)≤typeof(result)
后端编译
字节码看作是程序语言的一种中间表示形式(Intermediate Representation,IR)的话,那编译器无论在何时、在何种状态下把Class文件转换成与本地基础设施(硬件指令集、操作系统)相关的二进制机器码,它都可以视为整个编译过程的后端。
高效并发
当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍,
CPU长期都是以指数型快速提高,但是近年来,CPU主频始终保持在4G赫兹左右,无法再进一步提升。摩尔定律逐渐失效。

处理器数量 并行比例
计算机的运算速度与它的存储和通信子系统的速度差距太大,大量的时间都花费在磁盘I/O、网络通信或者数据库访问上。
衡量一个服务性能的高低好坏,每秒事务处理数(Transactions PerSecond,TPS)是重要的指标之一,它代表着一秒内服务端平均能响应的请求总数,而TPS值与程序的并发能力又有非常密切的关系
java内存模型
主内存和工作内存
Java内存模型的主要目的是定义程序中各种变量的访问规则,即关注在虚拟机中把变量值存储到内存和从内存中取出变量值这样的底层细节。此处的变量(Variables)与Java编程中所说的变量有所区别,它包括了实例字段、静态字段和构成数组对象的元素,但是不包括局部变量与方法参数,因为后者是线程私有的[插图],不会被共享,自然就不会存在竞争问题。为了获得更好的执行效能,Java内存模型并没有限制执行引擎使用
处理器的特定寄存器或缓存来和主内存进行交互,也没有限制即时编译器是否要进行调整代码执行顺序这类优化措施。
Java内存模型规定了所有的变量都存储在主内存(Main Memory)中(此处的主内存与介绍物理硬件时提到的主内存名字一样,两者也可以类比,但物理上它仅是虚拟机内存的一部分)。每条线程还有自己的工作内存(Working Memory,可与前面讲的处理器高速缓存类比),线程的工作内存中保存了被该线程使用的变量的主内存副本[插图],线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的数据[插图]。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存这一类的实现细节。
·lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
·unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
·read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
·load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。·use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
·assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
·store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
·write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
如果要把一个变量从主内存拷贝到工作内存,那就要按顺序执行read和load操作,如果要把变量从工作内存同步回主内存,就要按顺序执行store和write操作。注意,Java内存模型只要求上述两个操作必须按顺序执行,但不要求是连续执行。也就是说read与load之间、store与write之间是可插入其他指令的,如对主内存中的变量a、b进行访问时,一种可能出现的顺序是reada、read b、load b、load a。除此之外,Java内存模型还规定了在执行上述8种基本操作时必须满足如下规则:·不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者工作内存发起回写了但主内存不接受的情况出现。·不允许一个线程丢弃它最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。·不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
volatile 将具备两项特性:第一项是保证此变量对所有线程的可见性,这里的“可见性”是指当一条线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的。而普通变量并不能做到这一点,普通变量的值在线程间传递时均需要通过主内存来完成。比如,线程A修改一个普通变量的值,然后向主内存进行回写,另外一条线程B在线程A回写完成了之后再对主内存进行读取操作,新变量值才会对线程B可见。
第二个语义是禁止指令重排序优化,普通的变量仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致。
Java内存模型中对volatile变量定义的特殊规则的定义。假定T表示一个线程,V和W分别表示两个volatile型变量,那么在进行read、load、use、assign、store和write操作时需要满足如下规则:·只有当线程T对变量V执行的前一个动作是load的时候,线程T才能对变量V执行use动作;并且,只有当线程T对变量V执行的后一个动作是use的时候,线程T才能对变量V执行load动作。线程T对变量V的use动作可以认为是和线程T对变量V的load、read动作相关联的,必须连续且一起出现。
原子性(Atomicity)
基本数据类型的访问、读写都是具备原子性的(例外就是long和double的非原子性协定
可见性(Visibility)
普通变量与volatile变量的区别是,volatile的特殊规则保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新
Java还有两个关键字能实现可见性,它们是synchronized和final。同步块的可见性是由“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)”这条规则获得的。而final关键字的可见性是指:被final修饰的字段在构造器中一旦被初始化完成,并且构造器没有把“this”的引用传递出去(this引用逃逸是一件很危险的事情,其他线程有可能通过这个引用访问到“初始化了一半”的对象),那么在其他线程中就能看见final字段的值。
有序性(Ordering)
Java程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有的操作都是有序的;如果在一个线程中观察另一个线程,所有的操作都是无序的。前半句是指“线程内似表现为串行的语义”(Within-ThreadAs-If-Serial Semantics),后半句是指“指令重排序”现象和“工作内存与主内存同步延迟”现象。
先行发生原则
Java内存模型下一些“天然的”先行发生关系,这些先行发生关系无须任何同步器协助就已经存在,可以在编码中直接使用。如果两个操作之间的关系不在此列,并且无法从下列规则推导出来,则它们就没有顺序性保障,虚拟机可以对它们随意地进行重排序。
·管程锁定规则(Monitor Lock Rule):在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。注意,这里说的是控制流顺序而不是程序代码顺序,因为要考虑分支、循环等结构。
·管程锁定规则(Monitor Lock Rule):一个unlock操作先行发生于后面对同一个锁的lock操作。这里必须强调的是“同一个锁”,而“后面”是指时间上的先后。
·volatile变量规则(Volatile Variable Rule):对一个volatile变量的写操作先行发生于后面对这个变量的读操作,这里的“后面”同样是指时间上的先后。
·线程启动规则(Thread Start Rule):Thread对象的start()方法先行发生于此线程的每一个动作。
·线程终止规则(Thread Termination Rule):线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过Thread::join()方法是否结束、Thread::isAlive()的返回值等手段检测线程是否已经终止执行。
·线程中断规则(Thread Interruption Rule):对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread::interrupted()方法检测到是否有中断发生。
·对象终结规则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始。
·传递性(Transitivity):如果操作A先行发生于操作B,操作B先行发生于操作C,那就可以得出操作A先行发生于操作C的结论。
时间先后顺序与先行发生原则之间基本没有因果关系,所以我们衡量并发安全问题的时候不要受时间顺序的干扰,一切必须以先行发生原则为准。
线程
线程的三种实现
使用内核线程实现(1:1实现)——内核线程(Kernel-Level Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,内核线程的一种高级接口——轻量级进程(LightWeight Process,LWP),轻量级进程就是我们通常意义上所讲的线程。
系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。其次,每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。

使用用户线程实现(1:N实现)——一个线程只要不是内核线程,都可以认为是用户线程(User Thread,UT)的一种

使用用户线程加轻量级进程混合实现(N:M实现)。
用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并且可以支持大规模的用户线程并发。而操作系统支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级进程来完成,这大大降低了整个进程被完全阻塞的风险。
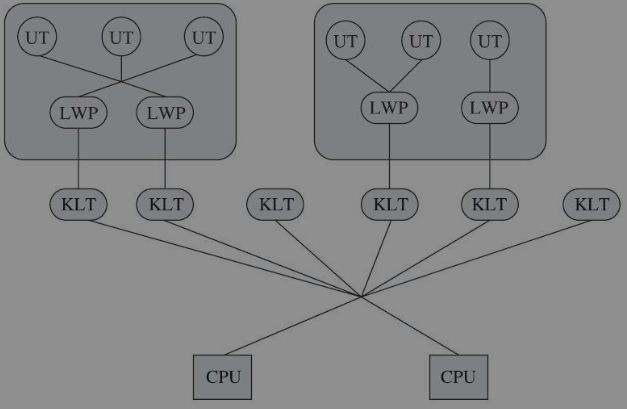
主流java虚拟机是内核线程实现
线程调度是指系统为线程分配处理器使用权的过程,调度主要方式有两种,分别是协同式(Cooperative Threads-Scheduling)线程调度和抢占式(Preemptive Threads-Scheduling)线程调度。
协同式调度——如果使用协同式调度的多线程系统,线程的执行时间由线程本身来控制,线程把自己的工作执行完了之后,要主动通知系统切换到另外一个线程上去。
Java语言一共设置了10个级别的线程优先级(Thread.MIN_PRIORITY至Thread.MAX_PRIORITY)。Windows系统线程优先级有7个
java定义的线程状态:
6种状态分别是:
·新建(New):创建后尚未启动的线程处于这种状态。
·运行(Runnable):包括操作系统线程状态中的Running和Ready,也就是处于此状态的线程有可能正在执行,也有可能正在等待着操作系统为它分配执行时间。
·无限期等待(Waiting):处于这种状态的线程不会被分配处理器执行时间,它们要等待被其他线程显式唤醒。以下方法会让线程陷入无限期的等待状态:■没有设置Timeout参数的Object::wait()方法;■没有设置Timeout参数的Thread::join()方法;■LockSupport::park()方法。
·限期等待(Timed Waiting):处于这种状态的线程也不会被分配处理器执行时间,不过无须等待被其他线程显式唤醒,在一定时间之后它们会由系统自动唤醒。以下方法会让线程进入限期等待状态:■Thread::sleep()方法;■设置了Timeout参数的Object::wait()方法;■设置了Timeout参数的Thread::join()方法;■LockSupport::parkNanos()方法;■LockSupport::parkUntil()方法。
·阻塞(Blocked):线程被阻塞了,“阻塞状态”与“等待状态”的区别是“阻塞状态”在等待着获取到一个排它锁,这个事件将在另外一个线程放弃这个锁的时候发生;而“等待状态”则是在等待一段时间,或者唤醒动作的发生。在程序等待进入同步区域的时候,线程将进入这种状态。
·结束(Terminated):已终止线程的线程状态,线程已经结束执行。
协程
Java目前的并发编程机制就与上述架构趋势产生了一些矛盾,1:1的内核线程模型是如今Java虚拟机线程实现的主流选择,但是这种映射到操作系统上的线程天然的缺陷是切换、调度成本高昂,系统能容纳的线程数量也很有限。
内核线程的调度成本主要来自于用户态与核心态之间的状态转换,而这两种状态转换的开销主要来自于响应中断、保护和恢复执行现场的成本。
协程是怎么来处理的呢,就是对于一个阻塞的业务操作,我们不是用线程来处理,而是用用协程,这样当出现IO阻塞的时候,并且你还没运行完时间片,你不会让CPU跑掉,而是调起你的另一个协程任务,让他继续进行计算。而通常我们知道,代码纯计算执行是非常快的,5ms可能跑了N个方法了,因此这样充分的利用时间片,并且减少CPU切换的时间。
线程安全
当多个线程同时访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那就称这个对象是线程安全的。
按照线程安全的“安全程度”由强至弱来排序,可以将Java语言中各种操作共享的数据分为以下五类:
不可变
String之外,常用的还有枚举类型及java.lang.Number的部分子类,如Long和Double等数值包装类型、BigInteger和BigDecimal等大数据类型。但同为Number子类型的原子类AtomicInteger和AtomicLong则是可变的
绝对线程安全
相对线程安全
相对线程安全就是我们通常意义上所讲的线程安全,它需要保证对这个对象单次的操作是线程安全的,我们在调用的时候不需要进行额外的保障措施,但是对于一些特定顺序的连续调用,就可能需要在调用端使用额外的同步手段来保证调用的正确性。
线程兼容
线程对立
一个线程对立的例子是Thread类的suspend()和resume()方法。如果有两个线程同时持有一个线程对象,一个尝试去中断线程,一个尝试去恢复线程,在并发进行的情况下,无论调用时是否进行了同步,目标线程都存在死锁风险——假如suspend()中断的线程就是即将要执行resume()的那个线程,那就肯定要产生死锁了。也正是这个原因,suspend()和resume()方法都已经被声明废弃了。
线程安全的实现
1、互斥同步(Mutual Exclusion & Synchronization)是一种最常见也是最主要的并发正确性保障手段。也被称为阻塞同步(Blocking Synchronization)。
同步是指在多个线程并发访问共享数据时,保证共享数据在同一个时刻只被一条(或者是一些,当使用信号量的时候)线程使用。而互斥是实现同步的一种手段,临界区(CriticalSection)、互斥量(Mutex)和信号量(Semaphore)都是常见的互斥实现方式。因此在“互斥同步”这四个字里面,互斥是因,同步是果;互斥是方法,同步是目的。
在Java里面,最基本的互斥同步手段就是synchronized关键字,这是一种块结构(BlockStructured)的同步语法。synchronized关键字经过Javac编译之后,会在同步块的前后分别形成monitorenter和monitorexit这两个字节码指令。这两个字节码指令都需要一个reference类型的参数来指明要锁定和解锁的对象。
·被synchronized修饰的同步块对同一条线程来说是可重入的。这意味着同一线程反复进入同步块也不会出现自己把自己锁死的情况。
·被synchronized修饰的同步块在持有锁的线程执行完毕并释放锁之前,会无条件地阻塞后面其他线程的进入。这意味着无法像处理某些数据库中的锁那样,强制已获取锁的线程释放锁;也无法强制正在等待锁的线程中断等待或超时退出。
ReentrantLock一样是可重入的,在功能上是synchronized的超集:等待可中断、可实现公平锁及锁可以绑定多个条件。
jdk6以后两者性能差不多,synchronized可自动释放锁,lock需要在finally中手动释放。
2、非阻塞同步
基于冲突检测的乐观并发策略,通俗地说就是不管风险,先进行操作,如果没有其他线程争用共享数据,那操作就直接成功了;如果共享的数据的确被争用,产生了冲突,那再进行其他的补偿措施,最常用的补偿措施是不断地重试,直到出现没有竞争的共享数据为止。这种乐观并发策略的实现不再需要把线程阻塞挂起,因此这种同步操作被称为非阻塞同步(Non-Blocking Synchronization),使用这种措施的代码也常被称为无锁(Lock-Free)编程。
·比较并交换(Compare-and-Swap,下文称CAS)
如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然为A值,那就能说明它的值没有被其他线程改变过了吗?这是不能的,因为如果在这段期间它的值曾经被改成B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过。这个漏洞称为CAS操作的“ABA问题”。
解决方案是使用版本号
3、无同步方案
同步只是保障存在共享数据争用时正确性的手段,如果能让一个方法本来就不涉及共享数据,那它自然就不需要任何同步措施去保证其正确性
可重入代码(Reentrant Code):这种代码又称纯代码(Pure Code),是指可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误,也不会对结果有所影响。
线程本地存储(Thread Local Storage)
java.lang.ThreadLocal类来实现线程本地存储的功能。每一个线程的Thread对象中都有一个ThreadLocalMap对象,这个对象存储了一组以ThreadLocal.threadLocalHashCode为键,以本地线程变量为值的K-V值对,ThreadLocal对象就是当前线程的ThreadLocalMap的访问入口,每一个ThreadLocal对象都包含了一个独一无二的threadLocalHashCode值,使用这个值就可以在线程K-V值对中找回对应的本地线程变量。
锁优化
锁自旋
如果物理机器有一个以上的处理器或者处理器核心,能让两个或以上的线程同时并行执行,我们就可以让后面请求锁的那个线程“稍等一会”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只须让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。
间必须有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程。
JDK6引入自适应的自旋。自适应意味着自旋的时间不再是固定的了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而允许自旋等待持续相对更长的时间,比如持续100次忙循环。另一方面,如果对于某个锁,自旋很少成功获得过锁,那在以后要获取这个锁时将有可能直接省略掉自旋过程,以避免浪费处理器资源。
锁消除
锁消除是指虚拟机即时编译器在运行时,对一些代码要求同步,但是对被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持,如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当作栈上数据对待,认为它们是线程私有的,同步加锁自然就无须再进行。
锁粗化
如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作是出现在循环体之中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部。
轻量级锁
“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的,因此传统的锁机制就被称为“重量级”锁。
HotSpot虚拟机的对象头(Object Header)

代码进入同步块前,若同步对象标志位为01,没有被锁定->则在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的MarkWord的拷贝。
虚拟机将使用CAS操作尝试把对象的Mark Word更新为指向Lock Record的指针。如果这个更新动作成功了,即代表该线程拥有了这个对象的锁,并且对象Mark Word的锁标志位(Mark Word的最后两个比特)将转变为“00”,表示此对象处于轻量级锁定状态。如果这个更新操作失败了,那就意味着至少存在一条线程与当前线程竞争获取该对象的锁。
虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是,说明当前线程已经拥有了这个对象的锁,那直接进入同步块继续执行就可以了,否则就说明这个锁对象已经被其他线程抢占了。如果出现两条以上的线程争用同一个锁的情况,那轻量级锁就不再有效,必须要膨胀为重量级锁,锁标志的状态值变为“10”,此时Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也必须进入阻塞状态。
解锁过程也同样是通过CAS操作来进行的,如果对象的Mark Word仍然指向线程的锁记录,那就用CAS操作把对象当前的Mark Word和线程中复制的Displaced Mark Word替换回来。假如能够成功替换,那整个同步过程就顺利完成了;如果替换失败,则说明有其他线程尝试过获取该锁,就要在释放锁的同时,唤醒被挂起的线程。
偏向锁
如果说轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连CAS操作都不去做了。
这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。
假设当前虚拟机启用了偏向锁(启用参数-XX:+UseBiased Locking,这是自JDK 6起HotSpot虚拟机的默认值),那么当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设置为“01”、把偏向模式设置为“1”,表示进入偏向模式。同时使用CAS操作把获取到这个锁的线程的ID记录在对象的Mark Word之中。如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新操作等)。

当一个对象已经计算过一致性哈希码后,它就再也无法进入偏向锁状态了;而当一个对象当前正处于偏向锁状态,又收到需要计算其一致性哈希码请求[插图]时,它的偏向状态会被立即撤销,并且锁会膨胀为重量级锁。在重量级锁的实现中,对象头指向了重量级锁的位置,代表重量级锁的ObjectMonitor类里有字段可以记录非加锁状态(标志位为“01”)下的Mark Word,其中自然可以存储原来的哈希码。
启用参数-XX:+UseBiased Locking,这是自JDK 6起HotSpot虚拟机的默认值
参数-XX:-UseBiasedLocking来禁止偏向锁优化
source: https://www.yuque.com/molizhuzhu/thrgrk/mp67gn
![]()
喜欢,在看