酒店推荐系统(基于文本描述)
基于酒店文本描述来推荐相似酒店
针对新用户可以通过该用户搜索酒店的关键词进行推荐
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
from sklearn.metrics.pairwise import linear_kernel
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import re
import random
import cufflinks
from plotly.offline import iplot
cufflinks.go_offline()
查看酒店的详细数据
名字,位置,详细介绍等
df = pd.read_csv('Seattle_Hotels.csv', encoding="latin-1")
df.head()
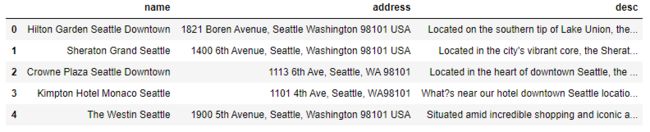
查看数据集中酒店的文本描述信息
vec = CountVectorizer().fit(df['desc'])
bag_of_words = vec.transform(df['desc'])

通过计词器查看文本大小(一共152句话,3200个词)
因为数据集中共152条
bag_of_words.shape
![]()
查看词出现的个数
sum_words = bag_of_words.sum(axis=0)
sum_words
查看词出现次数
从第一个词开始进行遍历
words_freq = [(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]
words_freq

把词出现的次数进行排序(从大到小)
words_freq = sorted(words_freq,key=lambda x:x[1],reverse=True)
words_freq

集中处理,合并为一个函数
def get_top_n_words(corpus,n=None):
vec = CountVectorizer().fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]
words_freq = sorted(words_freq,key=lambda x:x[1],reverse=True)
return words_freq[:n]
common_words=get_top_n_words(df['desc'],20)
common_words

转化一下格式
df1 = pd.DataFrame(common_words,columns=['desc','count'])
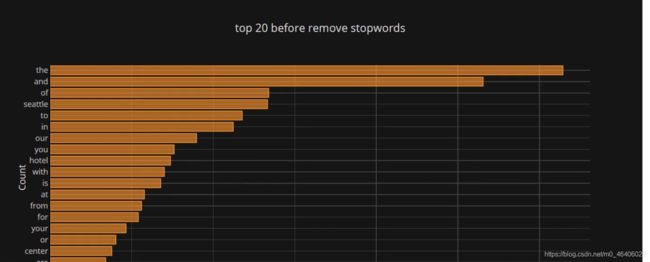
画图展示,利用词和词频
df1.groupby('desc').sum()['count'].sort_values().iplot(kind='barh',yTitle='Count',linecolor='black',title='top 20 before remove stopwords')
def get_top_n_words(corpus,n=None):
vec = CountVectorizer(stop_words='english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]
words_freq = sorted(words_freq,key=lambda x:x[1],reverse=True)
return words_freq[:n]
找出key_words
common_words=get_top_n_words(df['desc'],20)
df2 = pd.DataFrame(common_words,columns=['desc','count'])
df2.groupby('desc').sum()['count'].sort_values().iplot(kind='barh',yTitle='Count',linecolor='black',title='top 20 after remove stopwords')
可以看出处理之后和处理之前的区别(过滤掉一些无用词)
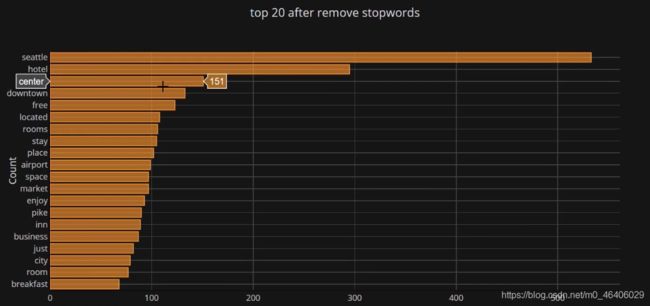
把词进行匹配,上述统计过程中词均是单个的没法完成推荐,要匹配到一起才有意义,以为搜索时也不可能利用一个词来搜索比如要把停车和场要匹配
def get_top_n_words(corpus,n=None):
vec = CountVectorizer(stop_words='english',ngram_range=(1,3)).fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word,sum_words[0,idx]) for word,idx in vec.vocabulary_.items()]
words_freq = sorted(words_freq,key=lambda x:x[1],reverse=True)
return words_freq[:n]
common_words=get_top_n_words(df['desc'],20)
df3 = pd.DataFrame(common_words,columns=['desc','count'])
df3.groupby('desc').sum()['count'].sort_values().iplot(kind='barh',yTitle='Count',linecolor='black',title='top 20 before remove stopwords-ngram_range=(2,2)')
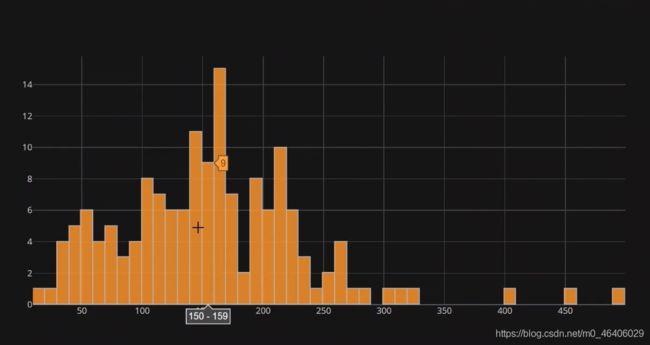
描述的一些统计信息
df['word_count']=df['desc'].apply(lambda x:len(str(x).split()))
df.head()

查看酒店描述时每句话出现词的个数的分布
df['word_count'].iplot(kind='hist',bins=50)
文本处理
利用正则。来保留自己需要的数据,过滤不需要的数据
转化大小写和替换,利用工具包
替换时如果不在提供此词表中就拿过来,并进行拼接
sub_replace = re.compile('[^0-9a-z #+_]')
stopwords = set(stopwords.words('english'))
def clean_txt(text):
text.lower()
text = sub_replace.sub('',text)
' '.join(word for word in text.split() if word not in stopwords)
return text
df['desc_clean'] = df['desc'].apply(clean_txt)
查看结果
df.head()

查看对比,人工加入提供词表越多效果越好
df['desc'][0]
df['desc_clean'][0]

计算相似度(余弦相似度)
df.set_index('name',inplace = True)
tf=TfidfVectorizer(analyzer='word',ngram_range=(1,3),stop_words='english')
转化
tfidf_matrix=tf.fit_transform(df['desc_clean'])
计算余弦相似度,把文本转化成数值方便计算相似度
cosine_similarity =linear_kernel(tfidf_matrix,tfidf_matrix)
查看第一个数据的相似度
cosine_similarity[0]
自己与自己相似度为1

构造一个索引
indices = pd.Series(df.index)
indices[:5]
定义一个函数,做相似度推荐
def recommendations(name,cosine_similarity):
recommended_hotels = []
idx = indices[indices == name].index[0]
score_series = pd.Series(cosine_similarity[idx]).sort_values(ascending=False)
top_10_indexes = list(score_series[1:11].index)
for i in top_10_indexes:
recommended_hotels.append(list(df.index)[i])
return recommended_hotels
得出推荐结果
recommendations('Hilton Garden Seattle Downtown',cosine_similarity)
