论文之生成对抗U-Net
[1] Chen X , Li Y , Yao L , et al. Generative Adversarial U-Net for Domain-free Medical Image Augmentation[J]. arXiv:2101.04793v1, 2021.
用于自由域医学图像增强的生成对抗U-Net
摘要:
医学图像标注的不足是医学图像计算领域面临的最大挑战之一。如果没有足够的训练样本,基于深度学习的模型很可能会出现过度拟合问题。常见的解决方案是图像预处理,如图像旋转、裁剪或调整大小。随着更多训练样本的引入,这些方法有助于缓解过度拟合问题。然而,它们并没有真正引入包含额外信息的新图像,并且可能会导致数据泄漏,因为测试集可能包含训练集中出现的类似样本。为了应对这一挑战,我们提出使用生成性对抗网络生成不同的图像。在本文中,我们开发了一种新的生成方法,名为生成对抗U-Net,它利用了生成对抗网络和U-Net。与现有的方法不同,我们新设计的模型是无域限制的,可以推广到各种医学图像。在八个不同的数据集上进行了大量实验,包括计算机断层扫描(CT)、病理学、X射线等。可视化和定量结果证明了所提出的方法在生成大量高质量医学图像方面的有效性和良好的泛化性。
关键词:生成对抗网络、U-Net、数据增强、医学图像分析
1. 引言
近十年来,深度学习在医学影像计算及其应用的研究中吸引了越来越多的研究兴趣。将深度学习应用于医学成像领域的最大挑战之一是从小型数据集或有限数量的注释样本中学习可概括的特征模式。基于深度学习的方法需要大量带注释的训练样本来支持推断,这在医学影像分析中很难实现[1-3]。在医学成像任务中,注释由具有数据和相关任务专家知识的放射科医生进行。得益于日益开放的医学数据集和巨大的挑战,数据集的短缺在一定程度上得到了缓解。然而,这些数据集的大小仍然有限,因为它们不可避免地需要放射科医生进行艰苦的工作[4]。
为了克服这个问题,数据扩充已经被广泛使用。最常用的数据扩充策略是数据处理,包括对数据的各种简单修改,如平移、旋转、翻转、裁剪和缩放[5,6]。这些数据增强方法已被广泛应用于丰富训练集,从而提高各种计算机视觉任务中的模型性能[7,8]。图像修改可以引入一些像素级的边信息来提高性能。然而,像素级修改不能引入新图像,而只能引入原始图像的变体,因此仍然可能存在过度拟合问题。合成数据增强方法被认为是更合理的替代方法,因为它可以基于原始图像生成复杂类型的数据。生成对抗网络(GAN)是合成数据增强方法[9]的代表,能够提供更多的可变性来丰富数据集。
受博弈论的启发,GAN的目标是在模型中实现纳什均衡[9]。GAN由两个主要网络组成,它们在对抗环境下联合训练,其中一个网络根据输入生成假图像,另一个网络将生成的图像与真实图像区分开来。GANs已越来越多地应用于图像合成[9,10],如去噪[11]、图像翻译[12]等。此外,还提出了多种GANs变体,以生成高质量的真实自然图像[13]、情节可视化[14],并基于低分辨率图像合成高分辨率图像[15]。
最近,一些医学影像学研究采用了GANs及其变体作为主要框架[4,16,17]。大多数研究都使用GAN技术生成图像或医学跨模态翻译。Zhang等人[16]应用GAN来减少多源数据集中的固有噪声,因为不同的设备会产生不同类型的噪声,这样的站点效应会显著影响数据分布。Zhang等人[18]提出了SkrGAN方法,通过整合全局上下文信息,即精细的前景结构来提高图像质量。Xue等人[19]使用两个GANs来了解大脑MRI图像和脑肿瘤分割图之间的关系。Fird等人[4]利用GAN生成肝脏病变图像,以提高CNN分类性能。此外,GANs还成功地应用于分割。Dong等人[20]采用GAN进行神经结构搜索,以找到对胸部器官进行分割的最佳方法。Khosravan等人[21]在GAN中引入了投影模块,以提高肺分割的性能。
然而,现有的大多数研究都集中在一个特定的任务或领域,没有一种健壮的方法可以推广到各个领域。在本研究中,我们的目标是设计一种适用于任何畴而非特定畴的无畴GAN结构。具体来说,所提出的方法可以应用于任何领域,如X射线、CT扫描、病理学等。此外,vanilla GANs存在训练不稳定性问题,难以使模型收敛[22]。我们在模型中采用了Wasserstein-GAN作为主要框架,因为它显示了更高的训练稳定性。U-Net是医学成像分析中的一种著名结构,尤其是在分割[5,23]中。图像分割的目的是发现像素级的异常,这需要很强的特征提取能力。GANs中的发电机需要类似的能力。因此,我们在研究中使用U-Net作为生成器。U-Net类似于自动编码器,它可以学习潜在的表示,并以与输入相同的大小重建输出。为了满足生成要求,我们将一个高斯变量连接到潜在表示中,以确保它不会每次生成相同的图像。我们研究的主要贡献可以总结如下:本文的贡献可以总结如下:
- 我们提出了一种新的GAN变体,名为生成对抗U-Net,用于无域医学图像增强。该方法生成的图像质量优于vanilla GANs及其著名的变异条件variant conditional GANs
-
为了利用优越的特征提取能力,我们首先将U-Net分解为编码器和生成器。然后,我们将生成器组装到GAN结构中以生成图像。
-
在不同领域的八个不同数据集上进行了广泛的实验,包括CT扫描、病理学、胸部X射线、皮肤镜、超声波和光学相干断层扫描。实验结果表明,在不同的数据域中具有很高的通用性和鲁棒性。
2. 方法
在本节中,将简要介绍提出的生成对抗U-Net。我们将首先描述所开发的深度学习模型的总体结构,然后解释包括残差U-Net网络生成器、鉴别器和训练策略。我们开发的方法的整体流程图如图1所示。
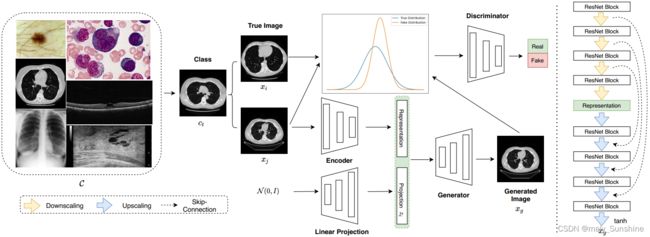
图1 提出模型结构图 给定任意类别的![]() ,我们的模型可以基于采样图像xj生成相应的图像。每次将从给定的ct类中抽取两个不同的样本,以支持鉴别器。xj将被编码成一个潜在的表示形式,并与高斯变量连接,作为用于生成的最终表示形式。生成的图像xg将与真实数据xi,xj一起被馈送到鉴别器中;鉴别器用于区分两种分布,即真实分布{xi;xj}和假分布{xi;xg}。生成器旨在使这两种分布尽可能相似。
,我们的模型可以基于采样图像xj生成相应的图像。每次将从给定的ct类中抽取两个不同的样本,以支持鉴别器。xj将被编码成一个潜在的表示形式,并与高斯变量连接,作为用于生成的最终表示形式。生成的图像xg将与真实数据xi,xj一起被馈送到鉴别器中;鉴别器用于区分两种分布,即真实分布{xi;xj}和假分布{xi;xg}。生成器旨在使这两种分布尽可能相似。
A. 概述
U-Net最早于[24]提出,并已广泛应用于医学图像分割[5]。它是一种人工神经网络,采用带跳跃连接的自动编码器结构。编码器用于从给定图像中提取特征,解码器用于利用提取的空间特征构建分割图。编码器遵循类似于具有堆叠卷积层的完全卷积网络(FCN)[25]的结构。具体来说,编码器由一系列用于下采样操作的块组成,每个块包括几个卷积层,然后是最大池层。在每次下采样操作后,卷积层中的滤波器数量将增加一倍。最后,编码器输出输入图像的学习特征映射。
不同的是,解码器设计用于上采样和构造图像分割。解码器首先利用反卷积层对编码器生成的特征映射进行上采样。反卷积层包含转置卷积运算,将使输出中的滤波器数量减半。然后是由两个卷积层和一个反卷积层组成的一系列上采样块。然后,使用另一个卷积层作为最终层来生成分割结果。最后一层使用Sigmoid函数作为激活函数,而所有其他层使用ReLU函数。
此外,U-Net将部分编码器功能与解码器连接起来,这在ResNet中被称为skipconnection[26]。对于编码器中的每个块,最大池之前的卷积结果对称地传输到解码器。在解码器中,每个块接收从编码器学习的特征表示,并将其与反褶积层的输出连接起来。然后将连接的结果向前传播到连续块。这种级联操作有助于解码器捕获maxpooling可能丢失的特征[23]。
B. 基于U-Net的生成模型
如前所述,U-Net在医学图像分割任务上展示了最先进的性能,显示了其在医学图像特征提取方面的优势。因此,我们利用U-Net作为所提出的生成模型的主要结构。GANs G(z)是生成模型,旨在学习从随机噪声向量z到输出图像的映射xg,G : z→xg[9].
z N(0, I) (1)
N(0, I) (1)
然而,由GANs生成的图像是随机的,这很难定义标签。因此,我们改用条件GANs[13]。条件GANS学习从随机噪声向量z和观察到的图像ct类的xi到输出图像xg。生成器G经过训练,以生成无法通过对抗性训练鉴别器D与“真实”图像区分的图像。鉴别器D被训练用来检测生成器产生的假图。或者,GANs设计用于在生成的数据和实际数据之间进行分布差异测量。条件GANs的目标函数可以表示为:
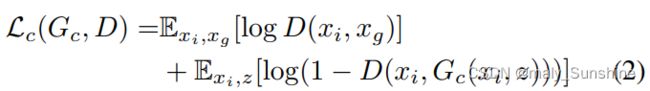
其中Gc试图最小化目标函数,而D试图使其最大化。从数学上讲,它的公式如下:

式中,G是等式(3)达到纳什均衡时的结果生成器。
然而,条件GANs与传统GANs有相似的局限性,存在训练不稳定性和模型崩溃问题。因此,我们使用Wasserstein GAN[22]作为生成模型的主要结构。具体而言,正常GAN使JS发散最小化,如等式(2)所示,而Wasserstein GAN的目标函数为:

此外,引入了梯度惩罚[10],以对Wasserstein GAN实施Lipschitz约束,即
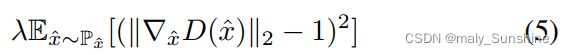
其中Px沿着从数据分布和生成器分布中采样的点对之间的直线均匀采样。x^是原始图像和从均匀分布u(0,1)中采样的生成图像的组合,控制因子为sigma。
生成对抗网络可用于进行数据扩充。给定特定类别的Ct和相应的数据点x,我们能够通过编码器学习输入图像rx的表示,使得rx=g(x),其中g(·)表示编码器网络。此外,将潜在的高斯变量zi引入学习的表示中,以提供以下形式的变化:

其中,gl是将高斯噪声投影为向量形式的线性投影,以便将其与学习的表示连接起来。一旦学习了表示,它将被输入生成器以生成图像。在该方法中,U-Net被分解为编码器和生成器。U形网的结构如图1右侧所示。ResNet块用作基本单元,定义为:
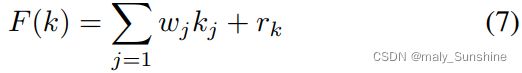
kj是k层输入,wj是相应的训练权重,rk为残差输入。此外,与传统的U-Net不同,我们使用leaky ReLU f(x)作为激活函数。

值得注意的是,生成的图像xg和原始图像xj都被提供给鉴别器。我们希望确保生成器能够生成与原始图像xj相关但不同的图像。也就是说,生成的图像xg应该来自与xj相同的类,而不仅仅是xj的复制或简单修改。通过提供当前图像xj,我们可以防止生成器对其进行简单编码。此外,还提供了类信息,生成器可以更好地了解所有类的通用模式。
C. 模型架构
生成器包含八个模块,其中每个模块块有4个3×3卷积层+BN[27],然后是降尺度或升尺度层。降尺度层是步幅2的卷积,然后是LEAKY ReLU、BN和dropout。上采样层是以1/2的步长进行反卷积,然后是leaky ReLU、BN和dropout。如上所述,我们还在生成器内部属于skip连接。我们使用与ResNet类似的策略,我们使用1×1卷积层在块之间传递特征。采用DenseNet[28]作为鉴别器。由于我们发现层标准化比批量标准化有更好的性能,因此采用了层标准化来代替批量标准化。鉴别器包含四个密集块和四个过渡层,其中每个密集块包含4个卷积层,并以一个dropput层结束。我们之所以在最后一层应用dropout层,是因为它可以避免过度拟合。
D. 优化
为了优化我们的网络,我们遵循[9]中介绍的标准方法:交替更新D上的一个梯度下降步骤,然后更新G上的一个步骤。正如原始WGAN论文中所建议的,我们根据算法1训练模型。

3. 实验
A. 实验建立
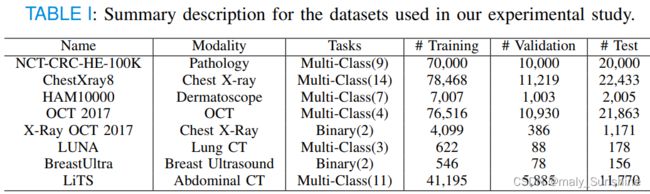
实验在多个公共可用数据集上进行,这些数据集包括:
NCT-CRC-HE-100K [29]:一个数据集包含10万个来自苏木精和伊红染色组织学图像的非重叠图像块。涉及九种不同类型的组织。
ChestXray8 [30]:一个数据集包含112120张30张正面X射线图像;805名患者,有14个疾病图像标签。
HAM10000 [31]:一个数据集包含10015张常见色素性皮肤病变的多源皮肤镜图像,这些图像属于七个不同类别.
Optical Coherence Tomography 2017 (OCT2017) [32]:一个数据集包含四种不同类型视网膜疾病的109309张光学相干断层扫描图像。
X-Ray OCT 2017 [32]:从2017年10月开始扩展的数据集包含5856张肺炎和正常患者的胸部CT图像。
LUNA [33]: 肺结节分析是一个开放的数据集,包括888次CT扫描,分为三类:非结节、结节<3mm和结节≥ 3毫米。
BreastUltra [34]:一个数据集包含780张乳腺超声图像,分为三类:正常、良性和恶性。
LiTS [35]:包含3D计算机断层扫描(CT)的肝脏肿瘤分割基准数据集。我们使用[36]中类似的方法将其转换为具有轴向视图的二维图像。
OpenCV2用于将所有医学图像调整为256×256×3。我们使用7:1:2的比例将数据集分为训练集、验证集和患者层面的测试集。所有这些数据集的信息汇总在表一中。
实验在一台有八个GPU的机器上进行,其中包括六个NVIDIA TITAN X Pascal GPU和两个NVIDIA TITAN RTX。该模型在Tensorflow中实现。
生成图像的质量评估是一个具有挑战性的问题[37]。传统的指标,如每像素均方误差,很难反映性能。因此,我们使用Frechet初始距离(FID)[38]来测量生成的分布和实际分布之间的距离。FID较低表示生成的图像质量较高。此外,我们还使用每像素精度(PA)来测量生成图像的可分辨性[12]、[37]、[39]。为了证明所提出方法的优越性,我们选择以下基线来比较质量。
Vanilla GAN[9]:GAN的原始版本。追:(34条消息) Generative Adversarial Nets(译)_小时候贼聪明-CSDN博客
条件GaN[13]:考虑标签信息的条件GAN。
值得一提的是,U-Net是一种自动编码器,但自动编码器不能用作基线。自动编码器被广泛用于重建任务,而不是增强任务,它不适用于本手稿。对于分类,我们使用以下几种不同的指标:
准确度,衡量整个数据集中正确分类样本的百分比;
精确度,测量所有预测阳性样本中真阳性(TP)的百分比;
召回率,用于测量TPs在所有阳性样本中的百分比;
AUC, 测量FPs和TPs之间关系的曲线下面积(AUC)。
选择以下基线作为分类器:ResNet-18、ResNet-50、DenseNet-161和支持向量机(SVM)。
B. 超参数设定
在这一部分中,我们简要介绍了实验中使用的参数设置。梯度惩罚系数λ为10。对于Adma优化器[40],我们设置α=0.0001;β1 = 0; β2 = 0.9. 密集区块的增长率k=64,训练次数为5000。使用Adma optimizer(α=0.001)对分类器进行5000个epoche的训练;β1 = 0.9; β2 =0.99
C. 结果
我们首先比较了GAN、cGAN和我们的方法的图像生成性能。表2中总结的结果表明,与GAN和条件GAN相比,我们的方法在这两个指标上都取得了最好的结果。

为了更好地分析生成的图像,我们提供了这些生成图像的可视化。我们使用三种不同的数据集:Luna、ChestXray8和BreatUltra作为演示数据集。可视化效果如图2所示。很明显,我们的模型生成的图像更接近地面真相。

图2:在三个不同区域生成的图像:肺部CT、胸部X射线和超声波。从左到右分别是:原始图像、我们的方法、GAN生成的图像和条件GAN生成的图像。显然,我们的方法生成的图像与原始图像更为相似.
我们还提供了表III中所有八个数据集的分类结果,其中有四个不同的分类器。我们发现,所有分类器的性能在增强后都显著提高。
4. 结论
由于缺乏带注释的医学图像,基于图像的医学研究面临着重大挑战,例如快速诊断、疾病预测等。数据扩充是缓解这一问题的常用方法。本文提出了一种新的医学图像增强方法——生成对抗U-Net网络。它可以用来生成多模态数据,以缓解医学成像研究中普遍面临的数据短缺问题。具体而言,我们调整生成性对抗网络的结构,以适应U型网络。我们在八个数据集上进行了广泛的实验,这些数据集具有不同的模式,从二元分类到多类分类。我们的实验结果表明,在所有这些数据集上,与最先进的方法相比,该方法具有更高的性能。在未来,我们计划将我们的工作扩展到更具挑战性的少数镜头学习场景或半监督学习场景[41,42],其中只有少数样本,甚至没有特定类别的样本可用。我们计划研究迁移学习,以帮助丰富当前模型,增强处理全新课堂中看不见样本的能力。