李宏毅学习笔记4.分类Classification: Probabilistic Generative Model
文章目录
- 分类的概念与应用
- 教学案例
-
- 问题描述
-
- 宝可梦的数字化
- 问题的重要性
- 如何解决这个问题?
-
- 插曲:能否使用回归的问题来解决分类问题?
-
- 二分类的讨论
- 多分类的情况
- 问题的新描述
- Probabilistic Generative Model
-
- 概率与分类的关系
- 第一步
- 第二步
-
- 补充知识:高斯分布
- 从79个样本推算出他们的高斯分布
-
- 推算新样本点来自高斯分布的概率
- 如何找到均值和协方差矩阵(最大似然 maximum likelihood)
- 最大似然的数学表示及解法
- 第二步的计算结果
- 开始分类
- 分类结果
- Probabilistic Generative Model的改进
-
- 模型改进
- 改进结果
- Probabilistic Generative Model的回顾
-
- 为什么选高斯分布
- Posterior Probalility(后验概率)
-
- z的推导
- 坑
课程标题:Classification: Probabilistic Generative Model
主要内容是分类,概率生成模型,下一课还有逻辑回归分类模型
分类的概念与应用

注意这里的类别可以为n种,老师先给出一些分类问题在实际生活中的应用:

信用贷款判定:找一个function,它的input是某一个人的收入,存款,工作(是否公务员),年纪,过去有没有欠债等等。output就是要不要贷款给他。这是个binary classification的问题。

医疗诊断: input是症状,年龄,性别,过去就医历史等。output是他生的哪种病。这是一个多分类问题。

手写输入识别:输入和输出见图例,老师特别提到中文识别比英文识别要复杂。
教学案例
再次祭出杀手锏:宝可梦

宝可梦的属性包括:水、火、电、草、毒等等18种属性(没玩过宝可梦,可以参照上面的英文)。
问题描述

现在要做一个分类的问题。这个分类的问题就是要找一个function,
input就是某一只宝可梦,
output就是告诉你这只宝可梦是属于哪一种type的。
比如,input一只皮卡丘,他的output就是雷。input一只杰尼龟,output就是水。input一个妙蛙草,他的output就是草。所以是一个classification的问题。
宝可梦的数字化
现在第一个问题就是怎么把一个宝可梦当做一个function的input。要当做input得数值化。要用数字来表示一个宝可梦,才能把它放到一个function里面。那怎么把一只宝可梦用数字来表示呢?一只宝可梦其实有很多的特性。这些特性是可以数字化的,比如他整体的强度。

当然还有很多其他特性:

例如:一只皮卡丘,他的总体强度是320,HP为35,攻击力为55,防御力为40,特殊攻击力为50,特殊防御力为50,速度为90。也就是一只皮卡丘可以用一个7维的向量来表示。

问题的重要性

以上是18×18的属性相克表(因为宝可梦有18种属性),竖下来右边红色表示攻击方,横着上方蓝色代表防御方,例如:左边第二行格斗系对上第一列一般系,会有2X倍的攻击加成。
本问题的重要性在于,当游戏过程中对方给出图鉴中没有见过的宝可梦,此时我们可以用本function预测对方宝可梦的属性,并派出相克属性的宝可梦迎战!!!
如何解决这个问题?
1、收集数据(宝可梦的属性)

数据就是带标记的数据对,输入皮卡丘,输出就是电。。。
2、![]()
插曲:能否使用回归的问题来解决分类问题?
二分类的讨论

在train的过程中,target就是 y ^ \hat y y^
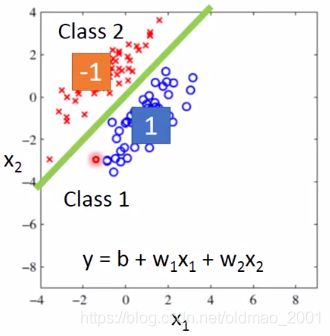
绿色的线就是 b + w 1 x 1 + w 2 x 2 = 0 b+w_1x_1+w_2x_2=0 b+w1x1+w2x2=0,以上是理想状态的分布,此时回归方法可以很好的解决分类问题,但是如果class 1的分布如下图所示:

以绿色线为界,左上角的值是小于0,右下的值是大于0,而且离得越远值越大,在regression算法中,会倾向于使得class1的输出值越接近1越好,因此,用regression算法来对上图进行train的话,得到结果会不会是绿色,而是紫色线,因为对于紫色线而言,右下角的样本输出值没有这么大。

因此结论是:regression会惩罚那些太正确的值,反而得到结论不是很好。
多分类的情况
做法:

这样定义的时候默认class 1与class 2有某种关系(数字1和2,差为1),class 2与class 3有某种关系(数字2和3,差为1),如果他们之间不存在这些关系,那么在train的时候就会出问题。
问题的新描述

损失函数是输出和标记(label)不同的次数之和,这个函数是无法微分的。学过的梯度下降无法解决这个问题,解决方案有:感知机、支持向量机,但今天会用概率的方式解决这个问题。
Probabilistic Generative Model
概率与分类的关系
老师用盒子中抽球的例子与分类问题进行类比
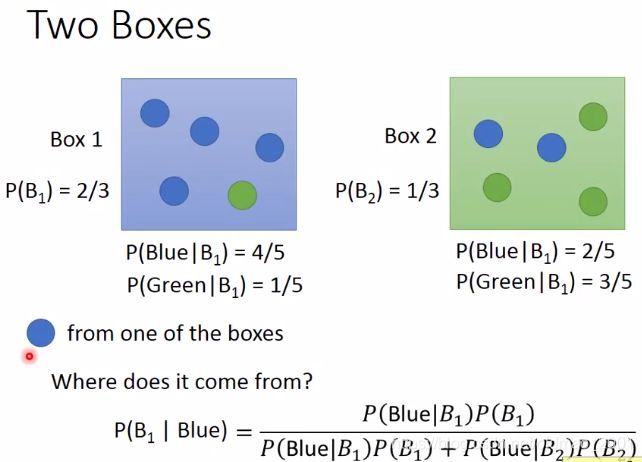
从box1抽球的几率是2/3,从box2抽球的几率是1/3.每个盒子里面蓝色和绿色球抽取的概念如↑图所示。则抽取蓝色球,该蓝色球是从box1抽取的概率是多少?
把盒子换成分类问题:
图中x可以看成某个宝可梦,最后的 P ( C 1 ∣ x ) P(C_1|x) P(C1∣x)表示这只宝可梦属于Class1类别的几率。
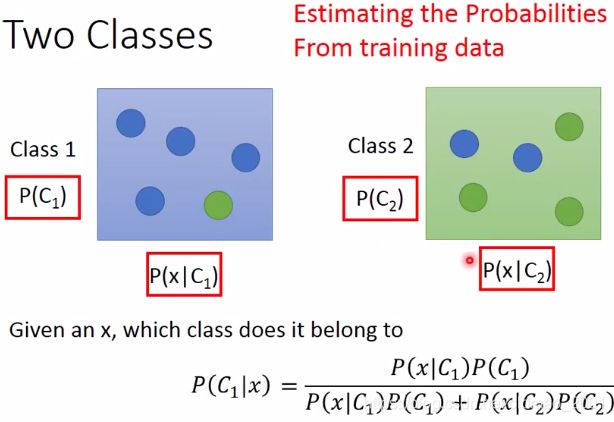
要计算 P ( C 1 ∣ x ) P(C_1|x) P(C1∣x),则需要从训练数据集总找到上图中红色框中的四个东西。这套思路称为:Generative Model(有关生成模型概念看这里,当然还有判别模型)
![]()
也就是最终得到x的分布。
第一步
先算 P ( C 1 ) P(C_1) P(C1)(这里是指水系宝可梦)和 P ( C 2 ) P(C_2) P(C2)(这里是指一般系的宝可梦)
PS:老师解释水系和一般系的宝可梦数量较多,所以选这两种进行分类

训练集数据取前400只宝可梦,在训练集中,水系和一般系宝可梦数量如上图, P ( C 1 ) P(C_1) P(C1)和 P ( C 2 ) P(C_2) P(C2)就可以算出来了
第二步
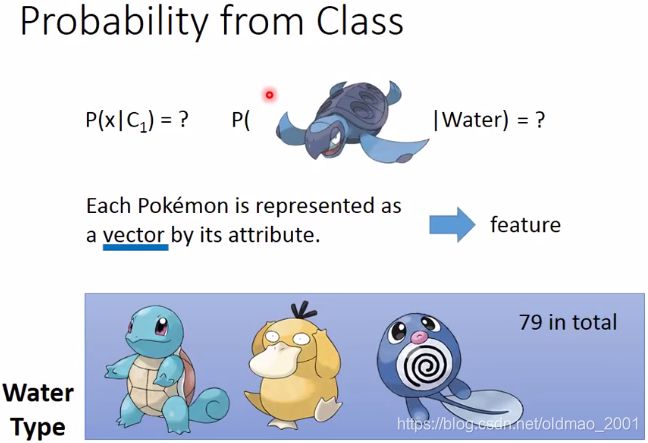
如何知道一个宝可梦(例如一只海龟)属于水系的概率是多少?实际上是要根据这个宝可梦的数据(向量也就是它的特征)来判断。
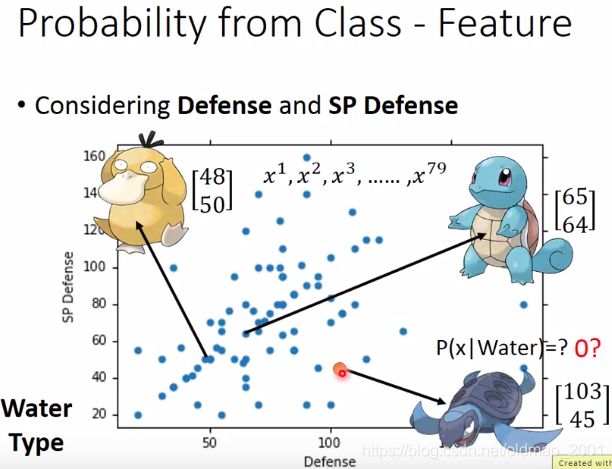
这里只列出两个特征(特殊防御和防御值),需要预测的是橙色点,即海龟来自水系宝贝的概率是多少。
**错误思想:**由于海龟从未在水系宝可梦数据集中出现,所以海龟来自水系宝贝的概率为0!
正确思想:所有水系宝贝的特殊防御和防御值都来自一个高斯分布(Gaussian distribution),上面那些蓝色的点只不过是从这个高斯分布中取样(sample)出来的,取样了79个点之后,变成下面这个样子

则从高斯分布中取样到橙色点的概率不会是0~!
补充知识:高斯分布
整个高斯分布可以想象成一个函数
输入x是某一个宝可梦的特征,输出是从分布中sample到这个宝可梦的几率(准确的说法应该是概率密度probability density)
高斯分布由均值 μ \mu μ和协方差矩阵 Σ \Sigma Σ决定


以上是相同的方差,不同的均值,以及相同均值,不同的方差高斯分布的不同形态。
从79个样本推算出他们的高斯分布
就是用79个样本计算均值和协方差矩阵

计算出的结果可以得到一个高斯分布的方程:

推算新样本点来自高斯分布的概率
定性来看,新样本点距离高斯分布中心越远,概率越小,反之概率越大
如何找到均值和协方差矩阵(最大似然 maximum likelihood)
79个样本可以从不同均值和协方差矩阵的高斯分布(任意)中sample出来,例如:

但是从不同高斯分布sample出这些点的似然性不一样,上图中明显从圆形高斯分布sample出79个样本的likelihood要比右上角的椭圆高斯分布大!
思想:因此我们可以计算不同高斯分布对79个样本的likelihood,然后取最大值,就找到了最大似然高斯分布。
说明:下式中的L表示的是likelihood,不是损失函数的那个Loss。

某高斯分布sample出第一个点的几率 * sample出第二个点的几率。。。。*sample出第79个点的几率
最后找到的最大似然高斯分布,我们把它的两个参数记为![]()
最大似然的数学表示及解法
数学表示如下:
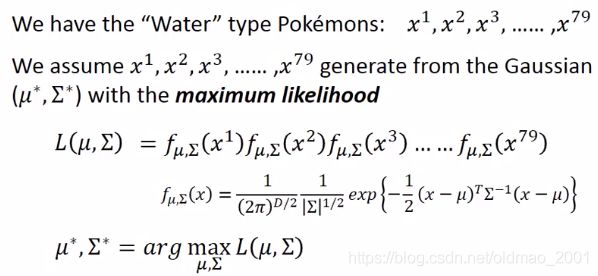
求最小值就是求导后取0值处就是极值的位置,推导过程可以参考别的资料,例如李航的《统计学习方法》
下面直接给结果:
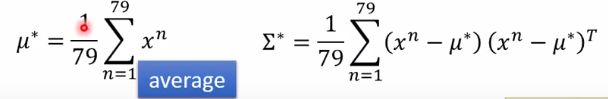
第二步的计算结果

开始分类
至此,四个红色框的参数已算出来,带入公式即可得到分类结果
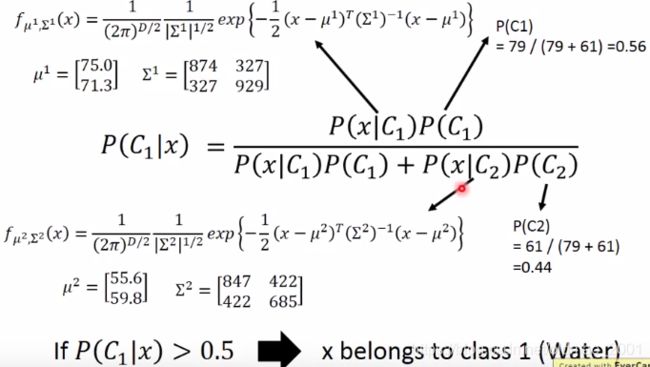
分类结果

图中坐标轴分别是防御力和特殊防御力,每一个点都代表x属于 C 1 C_1 C1的几率,红色属于一般系的概率大,蓝色属于水系的概率大

上图是training set的结果,把该结果应用到testing set上

准确率为47%,当然这里只考虑了2个特征
如果考虑7个特征:

准确率提高到54%。。。然后老师开始挖坑,说下次改进
Probabilistic Generative Model的改进

思想:不同的分类使用相同的协方差矩阵,这样可以使得模型参数减少,防止过拟合。(参数越多,模型越复杂,越容易过拟合)
模型改进
根据上面的改进思想重新设置下面的参数:
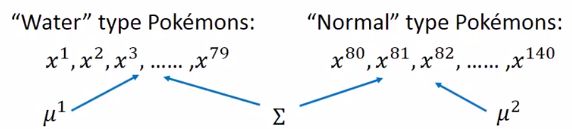
如何计算上图中的三个参数的最大似然呢?

注意公式中的 Σ Σ Σ没有下标。 μ 1 μ^1 μ1和 μ 2 μ^2 μ2的计算公式还是和前面一样,求各自类别的样本的均值。

改进结果
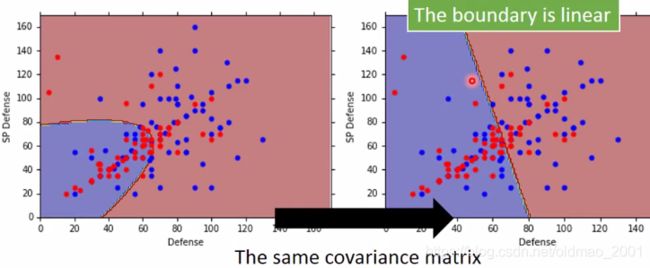
可以看到边界变成线性的了,考虑7个特征后准确率也提高了
![]()
Probabilistic Generative Model的回顾
老师在概述的时候就提到过,ML其实就是三个步骤,现在就把这个model对应到这三个步骤中去:

为什么选高斯分布
可以根据喜好来选几率模型,当然几率模型简单,参数比较少,偏差bias大,方差variance就小,复杂的模型反之。
如果特征向量中每一个特征都是独立的话:则每个特征都对应的1维高斯分布,这样训练出来的结果很差

因此:考虑特征之间的相互关系是很有必要的


Posterior Probalility(后验概率)

分子分母同除以分子

然后假设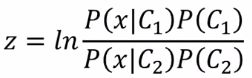
上面的式子就变成:
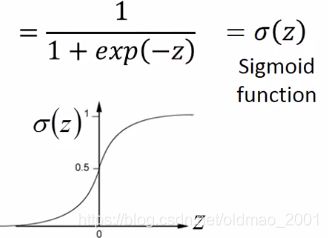
z的推导
Warning of Math

其中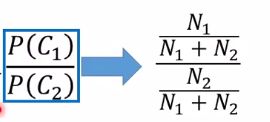
N 1 N_1 N1代表class1在train set中出现的次数; N 2 N_2 N2代表class2在train set中出现的次数。所以上面等于:
N 1 / N 2 N_1/N_2 N1/N2
下面两项是两个高斯分布:

 可以变成
可以变成

红色部分和分布无关可以消掉,绿色框里面东西提出来,后面exp相除变成相减,且ln和exp可以消掉。

分别取对数后变成下面

展开其中一部分如下:

蓝色部分合并,另外一部分也展开
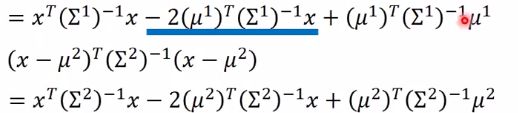
整理后:
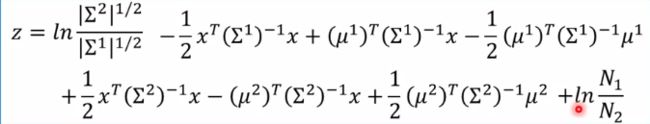
在前面的模型改进部分有说过两个类都是共用一个 Σ Σ Σ,即:
Σ 1 = Σ 2 = Σ Σ^1=Σ^2=Σ Σ1=Σ2=Σ
利用这个条件简化上面的公式:

把里面两项有x的弄到一起,与x无关的放到一起:
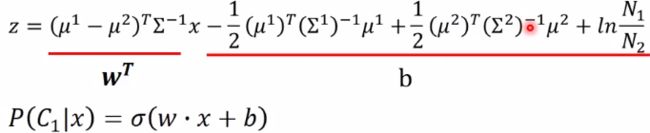
注意:x前面的是矩阵,后面b的是向量
这里讲了为什么讲这小节由于设置了 Σ 1 = Σ 2 = Σ Σ^1=Σ^2=Σ Σ1=Σ2=Σ这个条件,所以z是线性方程,所以分界线是直线。
坑
最后老师给出一个坑

既然搞来搞去,最后变成了线性方程形式,为什么不能直接找线性方程的两个参数 w , b w,b w,b?这个时候如果直接计算w和b会怎么样?
下节课填这个坑:Logistic Regression