极智AI | 讲解 TensoRT Activation 算子
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文讲解一下 TensorRT Activation 算子。
激活函数在神经网络中具有增加非线性、数据归一化 或 调整数据分布的作用。在分类、目标检测任务中都会有所涉及,如 relu、sigmoid、relu 等。这里讲解 TensorRT 中的 Activation 算子实现。
文章目录
-
- 1 TensorRT Activation 算子介绍
- 2 TensorRT Activate 算子实现
1 TensorRT Activation 算子介绍
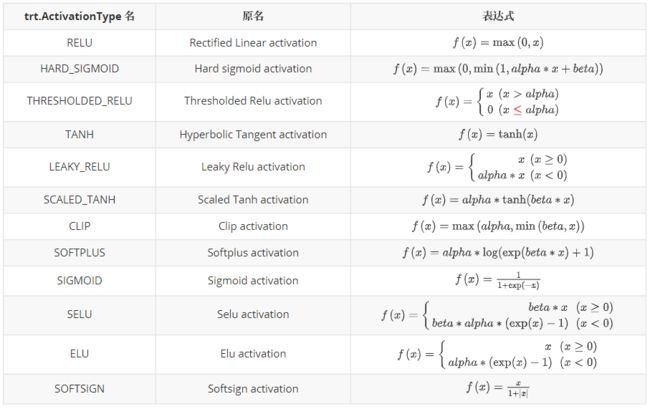
TensorRT Activation 有丰富的内置的激活函数可直接调用,可以通过 trt.ActivationType 进行查看支持的激活函数,如下:
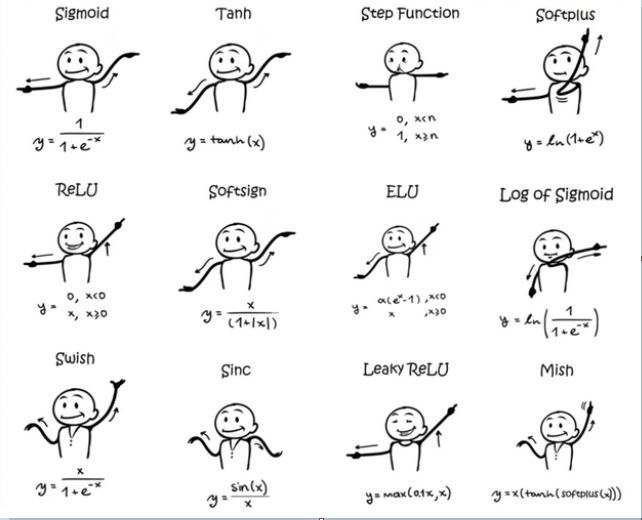
讲激活函数一定要附上这张图 (不是说 TensorRT 都支持,只是因为 生动、形象):
2 TensorRT Activate 算子实现
在 TensorRT 中如何构建一个 Activate 算子呢,来看:
# 通过 add_activation 添加 activate 算子
activationLayer = network.add_activation(inputT0, trt.ActivationType.RELU)
# 重设激活函数类型
activationLayer.type = trt.ActivationType.CLIP
# 部分激活函数需要 1 到 2 个参数,.aplha 和 .beta 默认值均为 0
activationLayer.alpha = -2
activationLayer.beta = 2
来看一个实际的例子:
import numpy as np
from cuda import cudart
import tensorrt as trt
# 输入张量 NCHW
nIn, cIn, hIn, wIn = 1, 1, 3, 3
# 输入数据
data = np.arange(-4, 5, dtype=np.float32).reshape(nIn, cIn, hIn, wIn)
np.set_printoptions(precision=8, linewidth=200, suppress=True)
cudart.cudaDeviceSynchronize()
logger = trt.Logger(trt.Logger.ERROR)
builder = trt.Builder(logger)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
config = builder.create_builder_config()
inputT0 = network.add_input('inputT0', trt.DataType.FLOAT, (nIn, cIn, hIn, wIn))
#-------------------------------------------------------------------------------# 替换部分
# 这里演示使用 ReLU 激活函数
# 也可以替换成你想用的激活函数
activationLayer = network.add_activation(inputT0, trt.ActivationType.RELU)
#-------------------------------------------------------------------------------# 替换部分
network.mark_output(activationLayer.get_output(0))
engineString = builder.build_serialized_network(network, config)
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString)
context = engine.create_execution_context()
_, stream = cudart.cudaStreamCreate()
inputH0 = np.ascontiguousarray(data.reshape(-1))
outputH0 = np.empty(context.get_binding_shape(1), dtype=trt.nptype(engine.get_binding_dtype(1)))
_, inputD0 = cudart.cudaMallocAsync(inputH0.nbytes, stream)
_, outputD0 = cudart.cudaMallocAsync(outputH0.nbytes, stream)
cudart.cudaMemcpyAsync(inputD0, inputH0.ctypes.data, inputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice, stream)
context.execute_async_v2([int(inputD0), int(outputD0)], stream)
cudart.cudaMemcpyAsync(outputH0.ctypes.data, outputD0, outputH0.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost, stream)
cudart.cudaStreamSynchronize(stream)
print("inputH0 :", data.shape)
print(data)
print("outputH0:", outputH0.shape)
print(outputH0)
cudart.cudaStreamDestroy(stream)
cudart.cudaFree(inputD0)
cudart.cudaFree(outputD0)
-
输入张量形状 (1, 1, 3, 3)
[ [ [ − 4. − 3. − 2. − 1. 0. 1. 2. 3. 4. ] ] ] \left[\begin{matrix} \left[\begin{matrix} \left[\begin{matrix} -4. & -3. & -2. \\ -1. & 0. & 1. \\ 2. & 3. & 4. \end{matrix}\right] \end{matrix}\right] \end{matrix}\right] ⎣⎡⎣⎡⎣⎡−4.−1.2.−3.0.3.−2.1.4.⎦⎤⎦⎤⎦⎤ -
输出张量形状 (1, 1, 3, 3)
[ [ [ 0. 0. 0. 0. 0. 1. 2. 3. 4. ] ] ] \left[\begin{matrix} \left[\begin{matrix} \left[\begin{matrix} 0. & 0. & 0. \\ 0. & 0. & 1. \\ 2. & 3. & 4. \end{matrix}\right] \end{matrix}\right] \end{matrix}\right] ⎣⎡⎣⎡⎣⎡0.0.2.0.0.3.0.1.4.⎦⎤⎦⎤⎦⎤
好了,以上分享了 讲解 TensorRT Activation 算子,希望我的分享能对你的学习有一点帮助。
【公众号传送】
《极智AI | 讲解 TensorRT Activation 算子》

扫描下方二维码即可关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
