第九周周报
学习目标:
ViTGAN代码
吴恩达深度学习
学习内容:
GAN
DCGAN
ViTGAN
NLP
学习时间:
10.31-11.4
学习产出:
一、GAN
了解了GAN的网络结构并编写代码
'''
数据准备
'''
transform = transforms.Compose([
transforms.ToTensor(), # 0-1归一化,channel,high,weight的设置然后转化为Tensor
transforms.Normalize(0.5, 0.5) # 均值和方差是0.5,是数据处于(-1,1)
])
train_ds = torchvision.datasets.MNIST('data', train=True, transform=transform, download=True) # 使用上面的transform来转换数据
dataloader = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
'''
定义生成器
'''
# 输入长度为100的噪声(生态分布随机数)
# 输出为(28,28,1)的图片
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28 * 28),
nn.Tanh()
)
print('gen-init')
def forward(self, x): # x表示长度为100的noise输入
img = self.main(x)
img = img.view(-1, 28, 28, 1) # 28*28的图片
print('gen-forward')
return img
# 输入为(28,28,1)的图片,输出为二分类的概率值,输出使用sigmoid激活
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.LeakyReLU(),
nn.Linear(512, 256),
nn.LeakyReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
print('dis-init')
def forward(self, x):
x = x.view(-1, 28 * 28) # 将图片展平
x = self.main(x)
print('dis-forward')
return x
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)
# 优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=0.0001)
g_optim = torch.optim.Adam(gen.parameters(), lr=0.0001)
# 损失函数
loss_fn = torch.nn.BCELoss()
def gen_img_plot(model, test_input):
# np.squeeze:从数组的形状中删除单维度条目,即把shape中为1的维度去掉,在这里是去掉通道数
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
# print('prediction:', prediction)
fig = plt.figure(figsize=(4, 4))
for i in range(16): # 绘制16张子图
plt.subplot(4, 4, i + 1) # 4行4列,i+1是图的位置
plt.imshow((prediction[i] + 1) / 2) # tanh输出的值为(-1,1),将tanh设置为(0,1)
plt.axis('off') # 关闭坐标轴
plt.show()
test_input = torch.randn(16, 100, device=device) # 返回一个符合均值为0,方差为1的正态分布(标准正态分布)中填充随机数的张量(16行,100列)
D_loss = []
G_loss = []
for epoch in range(20):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader) # 返回批次数,值938
print('count:', count)
for step, (img, _) in enumerate(dataloader): # img和_可以理解为x和y
img = img.to(device)
size = img.size(0) # 返回图片的维度(一个batch有64张图片),值64
print('size:',size)
random_noise = torch.randn(size, 100, device=device) # 创建张量,作为generator的输入
# 判别器
# 真实图像
d_optim.zero_grad() # 将鉴别器梯度归零
real_output = dis(img) # 判别器输入真实图片,real_output是对真实图片的预测结果(希望是1,即为真)
# print('real_output:', real_output)
# 使用loss_fn计算real_output的损失,将real_output与torch.ones_like(real_output)这个全为1的矩阵进行比较计算损失
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # 判别器在真实图像上的损失
print('d_real_loss', d_real_loss.item())
d_real_loss.backward() # 计算梯度
# 生成图像
gen_img = gen(random_noise) # 生成图片
fake_output = dis(gen_img.detach()) # 判别器输入生成图片,fake_output是对生成图片的预测结果(希望全为0,即为假),detach():截断梯度,即不让生成器的梯度更新
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # 判别器在生成图像上的损失
print('d_fake_loss:', d_fake_loss.item())
d_fake_loss.backward() # 计算梯度
d_loss = d_real_loss + d_fake_loss
print('d_loss:', d_loss)
d_optim.step() # 根据梯度和学习率进行更新
# 生成器
g_optim.zero_grad()
fake_output = dis(gen_img) # 得到对生成图像的输出
g_loss = loss_fn(fake_output, torch.ones_like(fake_output)) # 生成器的损失;对生成器来说,希望生成的图像被判定为1
print('g_loss', g_loss.item())
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad():
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch)
gen_img_plot(gen, test_input)

二、DCGAN
了解了DCGAN最主要的转置卷积并编写了DCGAN的代码
1、处理噪声MappingNetwork
manualSeed = 999 # 随机数种子
random.seed(manualSeed) # 生成随机数
torch.manual_seed(manualSeed) # 设置CPU生成随机数的种子,方便下次复现实验结果。
dataroot = './data/anime'
workers = 2 # 数据加载器加载数据的线程数
batch_size = 128
image_size = 64 # 输入图片尺寸
nc = 3 # 输入图片的通道数
nz = 100 # 潜在空间的长度
ngf = 64 # 与通过生成器进程的特征映射深度有关
ndf = 64 # 设置通过鉴别器传播的特征映射的深度
num_epochs = 100 # 训练轮数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器参数beta1
ngpu = 1 # gpu数量
dataset = dataset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# 加载数据
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,shuffle=True, num_workers=workers)
# 设置gpu训练
device = torch.device('cuda:0' if (torch.cuda.is_available() and ngpu > 0) else 'cpu')
# 权重初始化
def weights_init(m):
classname = m.__class__.__name__ # 首先用self.__class__将实例变量指向类,然后再去调用__name__类属性
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02) # 初始化权重为正态分布
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0) # 初始化偏差
# 生成器
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 转置卷积,输入通道数为100的噪声,输出64 * 8的张量,卷积核4x4,stride=1,padding=0
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
# Batch归一化处理
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64,即输出通道为3,尺寸为64*64的图
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self,ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 卷积,输出通道数为3,输出通道数为64,卷积核4x4,stride=2,padding=1,input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
# negative_slope-控制负斜率的角度。默认值:1e-2,当inplace = True 时,nn.ReLU会修改输入对象的值作为输出,而不是创建一个新的对象。
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
generator = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
generator = nn.DataParallel(generator, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
generator.apply(weights_init)
# Print the model
print(generator)
discriminator = Discriminator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
discriminator = nn.DataParallel(discriminator, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
discriminator.apply(weights_init)
# Print the model
print(discriminator)
# 定义损失函数
criterion = nn.BCELoss()
real_label = 1
fake_label = 0
d_optim = optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999))
g_optim = optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999))
# 噪声
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
img_list = []
D_loss = []
G_loss = []
iters = 0
if __name__ == '__main__':
real_batch = next(iter(dataloader))
# 64张图
plt.figure(figsize=(8, 8))
plt.axis('off')
plt.title('Training Images')
# np.transpose:将数据格式由(channels,imagesize,imagesize)转化为(imagesize,imagesize,channels),make_grid(real_batch[0].to(device)[:64]:将64张图组成网格
plt.imshow(
np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(), (1, 2, 0)))
for epoch in range(num_epochs):
for i, img in enumerate(dataloader, 0):
# 鉴别器
# 真实图像
d_optim.zero_grad()
img = img[0].to(device)
size = img.size(0) # 返回batch中图片的数量
# 给定fill_value和size,创建一个矩阵元素全为fill_value的大小为size的tensor。b_size:指定输出tensor的形状,real_label:将tensor填充为1
label = torch.full((size,), real_label, dtype=torch.float, device=device) # 类似torch.ones_like(real_output)
real_output = discriminator(img).view(-1)
d_real_loss = criterion(real_output, label)
d_real_loss.backward()
D_x = real_output.mean().item() # 真实图像中鉴别器图像判断的平均概率
# 生成图像
noise = torch.randn(size, nz, 1, 1, device=device)
gen_img = generator(noise)
label.fill_(fake_label) # 全0矩阵
d_fake_output = discriminator(gen_img.detach()).view(-1)
d_fake_loss = criterion(d_fake_output, label)
d_fake_loss.backward()
D_G_z1 = d_fake_output.mean().item() # 生成图像中鉴别器图像判断的平均概率
d_loss = d_real_loss + d_fake_loss
d_optim.step()
# 生成器
g_optim.zero_grad()
label.fill_(real_label)
g_fake_output = discriminator(gen_img).view(-1)
g_loss = criterion(g_fake_output, label)
g_loss.backward()
D_G_z2 = g_fake_output.mean().item() # 生成器图像概率
g_optim.step()
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
d_loss.item(), g_loss.item(), D_x, D_G_z1, D_G_z2))
G_loss.append(g_loss.item())
D_loss.append(d_loss.item())
if (iters % 500 == 0) or ((epoch == num_epochs - 1) and (i == len(dataloader) - 1)):
with torch.no_grad():
gen_img = generator(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(gen_img, padding=2, normalize=True))
iters += 1
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_loss, label="G")
plt.plot(D_loss, label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# %%capture
fig = plt.figure(figsize=(8, 8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())
# Grab a batch of real images from the dataloader
# Plot the real images
plt.figure(figsize=(15, 15))
plt.subplot(1, 2, 1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(
np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(), (1, 2, 0)))
# Plot the fake images from the last epoch
plt.subplot(1, 2, 2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1], (1, 2, 0)))
plt.show()
ViTGAN
了解了ViTGAN的生成器和鉴别器内容,知道了各个函数及类的作用
Generator
1、MappingNetwork
# 噪声处理的MappingNetwork
class MappingNetwork(nn.Module):
def __init__(self,
z_dim, # Input latent (Z) dimensionality, 0 = no latent.
c_dim, # Conditioning label (C) dimensionality, 0 = no label.
w_dim, # Intermediate latent (W) dimensionality.
num_ws=None, # Number of intermediate latents to output, None = do not broadcast.
num_layers=8, # Number of mapping layers.
embed_features=None, # Label embedding dimensionality, None = same as w_dim.
layer_features=None, # Number of intermediate features in the mapping layers, None = same as w_dim.
activation='lrelu', # Activation function: 'relu', 'lrelu', etc.
lr_multiplier=0.01, # Learning rate multiplier for the mapping layers.
w_avg_beta=0.995, # Decay for tracking the moving average of W during training, None = do not track.
**kwargs
):
super().__init__()
self.z_dim = z_dim # 噪声维度,z_dim=latent_dim
self.c_dim = c_dim # 条件标签的维度,c_dim=0
self.w_dim = w_dim # 中间层的维度,w_dim=hidden_size,hidden_size=hidden_features, default=384,
self.num_ws = num_ws # num_ws=None,不广播
self.num_layers = num_layers # num_layers=style_mlp_layers,default=8,
self.w_avg_beta = w_avg_beta # 训练期间跟踪W的移动平均值的衰减,w_avg_beta=None
if embed_features is None:
embed_features = w_dim
if c_dim == 0:
embed_features = 0
if layer_features is None:
layer_features = w_dim
features_list = [z_dim + embed_features] + [layer_features] * (num_layers - 1) + [w_dim]
if c_dim > 0:
self.embed = FullyConnectedLayer(c_dim, embed_features)
for idx in range(num_layers):
in_features = features_list[idx]
out_features = features_list[idx + 1]
layer = FullyConnectedLayer(in_features, out_features, activation=activation, lr_multiplier=lr_multiplier)
setattr(self, f'fc{idx}', layer)
if num_ws is not None and w_avg_beta is not None:
self.register_buffer('w_avg', torch.zeros([w_dim]))
def forward(self, z, c=None, truncation_psi=1, truncation_cutoff=None, skip_w_avg_update=False):
# Embed, normalize, and concat inputs.
x = None
with torch.autograd.profiler.record_function('input'):
if self.z_dim > 0:
assert z.shape[1] == self.z_dim
x = normalize_2nd_moment(z.to(torch.float32))
if self.c_dim > 0:
assert c.shape[1] == self.c_dim
y = normalize_2nd_moment(self.embed(c.to(torch.float32)))
x = torch.cat([x, y], dim=1) if x is not None else y
# Main layers.
for idx in range(self.num_layers):
layer = getattr(self, f'fc{idx}')
x = layer(x)
# Update moving average of W.更新训练期间跟踪W的移动平均值
if self.w_avg_beta is not None and self.training and not skip_w_avg_update:
with torch.autograd.profiler.record_function('update_w_avg'):
self.w_avg.copy_(x.detach().mean(dim=0).lerp(self.w_avg, self.w_avg_beta))
# Broadcast.
if self.num_ws is not None:
# record_function:用户自定义“范围”,用with把一段代码包起来统计
with torch.autograd.profiler.record_function('broadcast'):
# repeat:
x = x.unsqueeze(1).repeat([1, self.num_ws, 1])
# Apply truncation.
if truncation_psi != 1:
with torch.autograd.profiler.record_function('truncate'):
assert self.w_avg_beta is not None
if self.num_ws is None or truncation_cutoff is None:
x = self.w_avg.lerp(x, truncation_psi)
else:
x[:, :truncation_cutoff] = self.w_avg.lerp(x[:, :truncation_cutoff], truncation_psi)
# print('MappingNetwork__x:', x)
# print('MappingNetwork__x:', x.shape)
return x
2、Encoder
(1)GeneratorTransformerEncoderBlock
class GeneratorTransformerEncoderBlock(nn.Module):
def __init__(self,
hidden_size=384,
sln_paremeter_size=384,
drop_p=0.,
forward_expansion=4,
forward_drop_p=0.,
**kwargs):
super().__init__()
self.sln = SLN(hidden_size, parameter_size=sln_paremeter_size)
self.msa = MultiHeadAttention(hidden_size, **kwargs)
self.dropout = nn.Dropout(drop_p)
self.feed_forward = FeedForwardBlock(hidden_size, expansion=forward_expansion, drop_p=forward_drop_p)
def forward(self, hidden, w):
res = hidden
hidden = self.sln(hidden, w)
hidden = self.msa(hidden)
hidden = self.dropout(hidden)
hidden += res
res = hidden
hidden = self.sln(hidden, w)
self.feed_forward(hidden)
hidden = self.dropout(hidden)
hidden += res
return hidden
(2)SLN:自调制层归一化
# Self-Modulated LayerNorm:自调制层归一化
class SLN(nn.Module):
def __init__(self, input_size, parameter_size=None, **kwargs):
super().__init__()
if parameter_size == None:
parameter_size = input_size
assert (input_size == parameter_size or parameter_size == 1)
self.input_size = input_size
self.parameter_size = parameter_size
self.ln = nn.LayerNorm(input_size)
self.gamma = FullyConnectedLayer(input_size, parameter_size, bias=False)
self.beta = FullyConnectedLayer(input_size, parameter_size, bias=False)
# self.gamma = nn.Linear(input_size, parameter_size, bias=False)
# self.beta = nn.Linear(input_size, parameter_size, bias=False)
def forward(self, hidden, w):
assert (hidden.size(-1) == self.parameter_size and w.size(-1) == self.parameter_size)
gamma = self.gamma(w).unsqueeze(1)
beta = self.beta(w).unsqueeze(1)
ln = self.ln(hidden)
return gamma * ln + beta
(3)MultiHeadAttention:自注意力计算,如果是鉴别器那么使用L2距离,生成器正常计算
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size=384, num_heads=4, dropout=0, discriminator=False, **kwargs):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.discriminator = discriminator
# fuse the queries, keys and values in one matrix
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
if self.discriminator:
self.qkv = spectral_norm(self.qkv)
self.projection = spectral_norm(self.projection)
def forward(self, x, mask=None):
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# 如果是鉴别器那么计算L2距离
if self.discriminator:
# calculate L2-distances
energy = torch.cdist(queries.contiguous(), keys.contiguous(), p=2)
else:
# sum up over the last axis
# 'bhqd, bhkd -> bhqk'语义解释如下:输入a_tensor: 4维数组,下标为bhqd,输入b_tensor: 4维数组,下标为bhkd,输出output:4维数组,下标为bhqk。
# 隐含语义:输入a,b下标中相同的bh,是求和的下标,对应上面的例子2的公式
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
(4)siren网络,用作Generator输出后对patch的处理
# SIREN
# Code for SIREN is taken from https://colab.research.google.com/github/vsitzmann/siren/blob/master/explore_siren.ipynb
'''
ModulatedLinear调制模块 是用于将二维位置信息映射到模型特征中,增加模型细节,就是里面的傅里叶编码(Fourier Embedding)
Fourier特征网络告诉我们,若是把坐标(x,y)变换到频域,将频域坐标输入网络中,则网络的表征能力变强了
如果不经过傅里叶变换,那么得到的图像和形状等非常模糊,而进行傅里叶变换之后,可以重建清晰的图像。
Fourier域上的特征确实比空域特征更能表征高频细节
'''
class ModulatedLinear(nn.Module):
def __init__(self, in_channels, out_channels, style_size, bias=False, demodulation=True, **kwargs):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.style_size = style_size
self.scale = 1 / np.sqrt(in_channels)
self.weight = nn.Parameter(
torch.randn(1, out_channels, in_channels, 1)
)
self.modulation = None
if self.style_size != self.in_channels:
self.modulation = FullyConnectedLayer(style_size, in_channels, bias=False)
self.demodulation = demodulation
def forward(self, input, style):
batch_size = input.shape[0]
if self.style_size != self.in_channels:
style = self.modulation(style) # 调制
style = style.view(batch_size, 1, self.in_channels, 1)
weight = self.scale * self.weight * style
if self.demodulation:
demod = torch.rsqrt(weight.pow(2).sum([2]) + 1e-8)
weight = weight * demod.view(batch_size, self.out_channels, 1, 1)
weight = weight.view(
batch_size * self.out_channels, self.in_channels, 1
)
img_size = input.size(1)
input = input.reshape(1, batch_size * self.in_channels, img_size)
out = F.conv1d(input, weight, groups=batch_size)
out = out.view(batch_size, img_size, self.out_channels)
return out
# 使用Siren网络用作隐层神经表示
class SineLayer(nn.Module):
def __init__(self, in_features, out_features, style_size, bias=False,
is_first=False, omega_0=30, weight_modulation=True, **kwargs):
super().__init__()
self.omega_0 = omega_0
self.is_first = is_first
self.in_features = in_features
self.weight_modulation = weight_modulation
# 用于对encoder的输出图像进行处理
if weight_modulation:
self.linear = ModulatedLinear(in_features, out_features, style_size=style_size, bias=bias, **kwargs)
else:
self.linear = ResLinear(in_features, out_features, style_size=style_size, bias=bias, **kwargs)
self.init_weights()
def init_weights(self):
with torch.no_grad():
if self.is_first:
if self.weight_modulation:
self.linear.weight.uniform_(-1 / self.in_features,
1 / self.in_features)
else:
self.linear.linear.weight.uniform_(-1 / self.in_features,
1 / self.in_features)
else:
if self.weight_modulation:
self.linear.weight.uniform_(-np.sqrt(6 / self.in_features) / self.omega_0,
np.sqrt(6 / self.in_features) / self.omega_0)
else:
self.linear.linear.weight.uniform_(-np.sqrt(6 / self.in_features) / self.omega_0,
np.sqrt(6 / self.in_features) / self.omega_0)
def forward(self, input, style):
return torch.sin(self.omega_0 * self.linear(input, style)) # 用Sin函数作为激活函数的全连接网络
class Siren(nn.Module):
def __init__(self, in_features, hidden_size, hidden_layers, out_features, style_size, outermost_linear=False,
first_omega_0=30, hidden_omega_0=30., weight_modulation=True, bias=False, **kwargs):
super().__init__()
self.net = []
self.net.append(SineLayer(in_features, hidden_size, style_size,
is_first=True, omega_0=first_omega_0,
weight_modulation=weight_modulation, **kwargs))
for i in range(hidden_layers):
self.net.append(SineLayer(hidden_size, hidden_size, style_size,
is_first=False, omega_0=hidden_omega_0,
weight_modulation=weight_modulation, **kwargs))
if outermost_linear:
if weight_modulation:
final_linear = ModulatedLinear(hidden_size, out_features,
style_size=style_size, bias=bias, **kwargs)
else:
final_linear = ResLinear(hidden_size, out_features, style_size=style_size, bias=bias, **kwargs)
with torch.no_grad():
if weight_modulation:
final_linear.weight.uniform_(-np.sqrt(6 / hidden_size) / hidden_omega_0,
np.sqrt(6 / hidden_size) / hidden_omega_0)
else:
final_linear.linear.weight.uniform_(-np.sqrt(6 / hidden_size) / hidden_omega_0,
np.sqrt(6 / hidden_size) / hidden_omega_0)
self.net.append(final_linear)
else:
self.net.append(SineLayer(hidden_size, out_features,
is_first=False, omega_0=hidden_omega_0,
weight_modulation=weight_modulation, **kwargs))
self.net = nn.Sequential(*self.net)
def forward(self, coords, style):
coords = coords.clone().detach().requires_grad_(True) # allows to take derivative w.r.t. input
# output = self.net(coords, style)
output = coords
for layer in self.net:
output = layer(output, style)
return output
(5)GeneratorViT
class GeneratorViT(nn.Module):
def __init__(self,
style_mlp_layers=8,
patch_size=4,
latent_dim=32,
hidden_size=384,
sln_paremeter_size=1,
image_size=32,
depth=4,
combine_patch_embeddings=False,
combined_embedding_size=1024,
forward_drop_p=0.,
bias=False,
out_features=3,
out_patch_size=4,
weight_modulation=True,
siren_hidden_layers=1,
**kwargs):
super().__init__()
self.hidden_size = hidden_size
self.mlp = MappingNetwork(z_dim=latent_dim, c_dim=0, w_dim=hidden_size, num_layers=style_mlp_layers,
w_avg_beta=None) # 输出一个16x384的tensor
num_patches = int(image_size // patch_size) ** 2 # 64
self.patch_size = patch_size # 4
self.num_patches = num_patches
self.image_size = image_size # 32
self.combine_patch_embeddings = combine_patch_embeddings # 将encode输出后分散的patch组合在一起,default=False
self.combined_embedding_size = combined_embedding_size # default=384
self.out_patch_size = out_patch_size # 3
self.out_features = out_features # 4
# 输入的位置编码
self.pos_emb = nn.Parameter(torch.randn(num_patches, hidden_size))
self.transformer_encoder = GeneratorTransformerEncoder(depth,
hidden_size=hidden_size,
sln_paremeter_size=sln_paremeter_size,
drop_p=forward_drop_p,
forward_drop_p=forward_drop_p,
**kwargs)
self.sln = SLN(hidden_size, parameter_size=sln_paremeter_size)
if combine_patch_embeddings: # False
# print('combine_patch_embeddings is true')
self.to_single_emb = nn.Sequential(
FullyConnectedLayer(num_patches * hidden_size, combined_embedding_size, bias=bias, activation='gelu'),
nn.Dropout(forward_drop_p),
)
self.lff = LFF(self.hidden_size)
self.siren_in_features = combined_embedding_size if combine_patch_embeddings else self.hidden_size
self.siren = Siren(in_features=self.siren_in_features, out_features=out_features,
style_size=self.siren_in_features, hidden_size=self.hidden_size, bias=bias,
hidden_layers=siren_hidden_layers, outermost_linear=True,
weight_modulation=weight_modulation, **kwargs)
self.num_patches_x = int(image_size // self.out_patch_size)
def fourier_input_mapping(self, x):
return self.lff(x)
# 傅里叶位置编码
def fourier_pos_embedding(self, device):
# Create input pixel coordinates in the unit square
coords = np.linspace(-1, 1, self.out_patch_size, endpoint=True)
pos = np.stack(np.meshgrid(coords, coords), -1)
pos = torch.tensor(pos, dtype=torch.float, device=device)
result = self.fourier_input_mapping(pos).reshape([self.out_patch_size ** 2, self.hidden_size])
return result.to(device)
def repeat_pos(self, hidden):
pos = self.fourier_pos_embedding(hidden.device)
result = repeat(pos, 'p h -> n p h', n=hidden.shape[0]) # 将pos扩充维度
return result
# encoder输出后的特征图经过SLN后在经过一个LFF处理后进行傅里叶编码处理然后输入siren模型中进行操作使encoder输出的特征图更加平滑,即论文中使用的隐层神经表示
def forward(self, z):
w = self.mlp(z) # 1、MLP
pos = repeat(torch.sin(self.pos_emb), 'n e -> b n e', b=z.shape[0]) # 扩充维度
hidden = self.transformer_encoder(pos, w) # 2、GeneratorTransformerEncoderBlock,特征图输出
if self.combine_patch_embeddings:
# Output [batch_size, combined_embedding_size]
hidden = self.sln(hidden, w).view((z.shape[0], -1))
hidden = self.to_single_emb(hidden)
else:
# Output [batch_size*num_patches, hidden_size]
hidden = self.sln(hidden, w).view((-1, self.hidden_size)) # 3、SLN
pos = self.repeat_pos(hidden) # 3、siren网络的输入(LFF)
result = self.siren(pos, hidden) # 4、隐层神经处理
model_output_1 = result.view(
[-1, self.num_patches_x, self.num_patches_x, self.out_patch_size, self.out_patch_size, self.out_features])
model_output_2 = model_output_1.permute([0, 1, 3, 2, 4, 5])
model_output = model_output_2.reshape([-1, self.image_size ** 2, self.out_features])
# print(model_output)
print(model_output.shape)
return model_output
3、训练
代码中参数等不重要的部分去掉了
if __name__ == '__main__':
# 单独从siren网络生成图片而不经过patch
if combine_patch_embeddings:
#print(1111)
out_patch_size = image_size
combined_embedding_size = combine_patch_embeddings_size
else:
#print(2222)
out_patch_size = patch_size # 4
combined_embedding_size = hidden_size # 384
siren_in_features = combined_embedding_size # siren输入的特征图
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0., 0., 0.), (1., 1., 1.))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=False, num_workers=2
# Experiments
if generator_type == "vitgan":
# print(111)
# Create the Generator
Generator = GeneratorViT(patch_size=patch_size,
image_size=image_size,
style_mlp_layers=style_mlp_layers,
latent_dim=latent_dim,
hidden_size=hidden_size,
combine_patch_embeddings=combine_patch_embeddings,
combined_embedding_size=combined_embedding_size,
sln_paremeter_size=sln_paremeter_size,
num_heads=num_heads,
depth=depth,
forward_drop_p=dropout_p,
bias=bias,
weight_modulation=weight_modulation,
siren_hidden_layers=siren_hidden_layers,
demodulation=demodulation,
out_patch_size=out_patch_size,
).to(device)
print(Generator)
# use the modules apply function to recursively apply the initialization
# 应用权重
Generator.apply(init_normal)
num_patches_x = int(image_size // out_patch_size)
# 加载训练好的参数
if os.path.exists(f'{experiment_folder_name}/weights/Generator.pth'):
Generator = torch.load(f'{experiment_folder_name}/weights/Generator.pth')
wandb.watch(Generator)
elif generator_type == "cnn":
cnn_generator = CNNGenerator(hidden_size=hidden_size, latent_dim=latent_dim).to(device)
print(cnn_generator)
cnn_generator.apply(init_normal)
if os.path.exists(f'{experiment_folder_name}/weights/cnn_generator.pth'):
cnn_generator = torch.load(f'{experiment_folder_name}/weights/cnn_generator.pth')
wandb.watch(cnn_generator)
# Create the three types of discriminators
if discriminator_type == "vitgan":
Discriminator = ViT(discriminator=True,
patch_size=patch_size * 2,
stride_size=patch_size,
n_classes=1,
num_heads=num_heads,
depth=depth,
forward_drop_p=dropout_p,
).to(device)
print(Discriminator)
Discriminator.apply(init_normal)
if os.path.exists(f'{experiment_folder_name}/weights/discriminator.pth'):
Discriminator = torch.load(f'{experiment_folder_name}/weights/discriminator.pth')
wandb.watch(Discriminator)
elif discriminator_type == "cnn":
cnn_discriminator = CNN().to(device)
print(cnn_discriminator)
cnn_discriminator.apply(init_normal)
if os.path.exists(f'{experiment_folder_name}/weights/discriminator.pth'):
cnn_discriminator = torch.load(f'{experiment_folder_name}/weights/discriminator.pth')
wandb.watch(cnn_discriminator)
elif discriminator_type == "stylegan2":
stylegan2_discriminator = StyleGanDiscriminator(image_size=32).to(device)
print(stylegan2_discriminator)
# stylegan2_discriminator.apply(init_normal)
if os.path.exists(f'{experiment_folder_name}/weights/discriminator.pth'):
stylegan2_discriminator = torch.load(f'{experiment_folder_name}/weights/discriminator.pth')
wandb.watch(stylegan2_discriminator)
# Training
os.makedirs(f"{experiment_folder_name}/weights", exist_ok=True)
os.makedirs(f"{experiment_folder_name}/samples", exist_ok=True)
# Loss function
criterion = nn.BCEWithLogitsLoss()
if discriminator_type == "cnn":
discriminator = cnn_discriminator
elif discriminator_type == "stylegan2":
discriminator = stylegan2_discriminator
elif discriminator_type == "vitgan":
discriminator = Discriminator
if generator_type == "cnn":
params = cnn_generator.parameters()
else:
params = Generator.parameters()
# 优化器
optim_g = torch.optim.Adam(lr=lr, params=params, betas=beta)
optim_d = torch.optim.Adam(lr=lr_dis, params=discriminator.parameters(), betas=beta)
ema = ExponentialMovingAverage(params, decay=0.995) # 滑动平均
fixed_noise = torch.FloatTensor(np.random.normal(0, 1, (16, latent_dim))).to(device)
# 鉴别器判断生成器生成图像时,损失函数进行计算时使用的全0矩阵
discriminator_f_img = torch.zeros([batch_size, 3, image_size, image_size]).to(device)
trainset_len = len(trainloader.dataset) # 50000
# print('trainset_len:',trainset_len)
step = 0
for epoch in range(epochs):
for batch_id, batch in enumerate(trainloader):
step += 1
# Train discriminator
# 鉴别器,真实图像
# Forward + Backward with real images
r_img = batch[0].to(device) # torch.Size([16, 3, 32, 32])
# print('r_img:',r_img.shape)
r_logit = discriminator(r_img).flatten()
r_label = torch.ones(r_logit.shape[0]).to(device)
# 鉴别器损失
lossD_real = criterion(r_logit, r_label)
# 鉴别器bCR损失
lossD_bCR_real = F.mse_loss(r_logit, discriminator(r_img, do_augment=False))
# Forward + Backward with fake images
# 噪声
latent_vector = torch.FloatTensor(np.random.normal(0, 1, (batch_size, latent_dim))).to(device) # torch.Size([16, 32])
# print('latent_vector',latent_vector.shape)
if generator_type == "vitgan":
f_img = Generator(latent_vector) # 生成器的生成图像,torch.Size([16, 1024, 3])
# print('f_img1:',f_img.shape)
f_img = f_img.reshape([-1, image_size, image_size, out_features]) # torch.Size([16, 32, 32, 3])
# print('f_img2:',f_img.shape)
f_img = f_img.permute(0, 3, 1, 2) # torch.Size([16, 3, 32, 32])
# print('f_img3:',f_img.shape)
else:
model_output = cnn_generator(latent_vector)
f_img = model_output
# assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
assert f_img.size(0) == batch_size, f_img.shape
assert f_img.size(1) == out_features, f_img.shape
assert f_img.size(2) == image_size, f_img.shape
assert f_img.size(3) == image_size, f_img.shape
f_label = torch.zeros(batch_size).to(device)
# Save the a single generated image to the discriminator training data
# batch_size_history_discriminator:True,查看lossD_fake_history使用
if batch_size_history_discriminator:
discriminator_f_img[step % batch_size] = f_img[0].detach()
f_logit_history = discriminator(discriminator_f_img).flatten()
lossD_fake_history = criterion(f_logit_history, f_label)
else:
lossD_fake_history = 0
# Train the discriminator on the images, generated only from this batch
# 生成器生成图像
f_logit = discriminator(f_img.detach()).flatten()
# 鉴别器在生成图像上的损失
lossD_fake = criterion(f_logit, f_label)
lossD_bCR_fake = F.mse_loss(f_logit, discriminator(f_img, do_augment=False))
# print('lossD_bCR_fake:',lossD_bCR_fake)
# 噪声
f_noise_input = torch.FloatTensor(np.random.rand(*f_img.shape) * 2 - 1).to(device)
f_noise_logit = discriminator(f_noise_input).flatten()
lossD_noise = criterion(f_noise_logit, f_label)
# 鉴别器损失计算
lossD = lossD_real * 0.5 + \
lossD_fake * 0.5 + \
lossD_fake_history * lambda_lossD_history + \
lossD_noise * lambda_lossD_noise + \
lossD_bCR_real * lambda_bCR_real + \
lossD_bCR_fake * lambda_bCR_fake
optim_d.zero_grad()
lossD.backward()
optim_d.step()
# Train Generator
# 生成器
if generator_type == "vitgan":
f_img = Generator(latent_vector)
f_img = f_img.reshape([-1, image_size, image_size, out_features])
f_img = f_img.permute(0, 3, 1, 2)
else:
model_output = cnn_generator(latent_vector)
f_img = model_output
assert f_img.size(0) == batch_size
assert f_img.size(1) == out_features
assert f_img.size(2) == image_size
assert f_img.size(3) == image_size
f_logit = discriminator(f_img).flatten()
r_label = torch.ones(batch_size).to(device)
lossG_main = criterion(f_logit, r_label)
lossG_diversity = diversity_loss(f_img) * lambda_diversity_penalty # lambda_diversity_penalty=0,带惩罚的梯度计算
lossG = lossG_main + lossG_diversity # 生成器损失
optim_g.zero_grad()
lossG.backward()
optim_g.step()
ema.update()
if batch_id % 20 == 0:
print(f'epoch {epoch}/{epochs}; batch {batch_id}/{int(trainset_len / batch_size)}')
print(f'Generator: {"{:.3f}".format(float(lossG_main))}, ' + \
f'Gen(diversity): {"{:.3f}".format(float(lossG_diversity))}, ' + \
f'Dis(real): {"{:.3f}".format(float(lossD_real))}, ' + \
f'Dis(fake): {"{:.3f}".format(float(lossD_fake))}, ' + \
f'Dis(fake_history): {"{:.3f}".format(float(lossD_fake_history))}, ' + \
f'Dis(noise) {"{:.3f}".format(float(lossD_noise))}, ' + \
f'Dis(bCR_fake): {"{:.3f}".format(float(lossD_bCR_fake * lambda_bCR_fake))}, ' + \
f'Dis(bCR_real): {"{:.3f}".format(float(lossD_bCR_real * lambda_bCR_real))}')
# Plot 8 randomly selected samples
# if step % sample_interval == 0:
if generator_type == "vitgan":
Generator.eval()
# img_siren.eval()
vis = Generator(fixed_noise)
vis = vis.reshape([-1, image_size, image_size, out_features])
vis = vis.permute(0, 3, 1, 2)
else:
model_output = cnn_generator(fixed_noise)
vis = model_output
assert vis.shape[0] == fixed_noise.shape[
0], f'vis.shape[0] is {vis.shape[0]}, but should be {fixed_noise.shape[0]}'
assert vis.shape[1] == out_features, f'vis.shape[1] is {vis.shape[1]}, but should be {out_features}'
assert vis.shape[2] == image_size, f'vis.shape[2] is {vis.shape[2]}, but should be {image_size}'
assert vis.shape[3] == image_size, f'vis.shape[3] is {vis.shape[3]}, but should be {image_size}'
vis.detach().cpu()
vis = make_grid(vis, nrow=4, padding=5, normalize=True)
writer.add_image(f'Generated/epoch_{epoch}', vis)
wandb.log({'examples': wandb.Image(vis)})
vis = T.ToPILImage()(vis)
vis.save(f'{experiment_folder_name}/samples/vis{epoch}.jpg')
if generator_type == "vitgan":
Generator.train()
# img_siren.train()
else:
cnn_generator.train()
print(f"Save sample to {experiment_folder_name}/samples/vis{epoch}.jpg")
# Save the checkpoints.
if generator_type == "vitgan":
torch.save(Generator, f'{experiment_folder_name}/weights/Generator.pth')
# torch.save(img_siren, f'{experiment_folder_name}/weights/img_siren.pth')
elif generator_type == "cnn":
torch.save(cnn_generator, f'{experiment_folder_name}/weights/cnn_generator.pth')
torch.save(discriminator, f'{experiment_folder_name}/weights/discriminator.pth')
print("Save model state.")
writer.close()


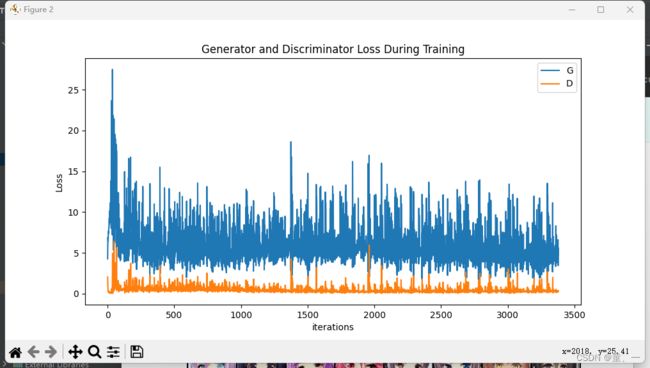
由于没有经验,第一次训练时loss一直不变因此将学习率调小十倍变成了0.0001,因此生成图片的效果与论文不一致,且loss没有收敛。
三、深度学习
学习了吴恩达深度学习的最后一门课序列模型,了解了RNN、NLP、Word Embedding、序列模型和注意力机制。
1、RNN

判断一句话中的单词是否是人名:
在零时刻构造一个激活值0,通常是零向量,然后将单词的独热向量编码输入第一个神经网络,计算a1
![]()
然后计算y1
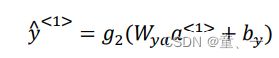
将激活值一直往下传完成前向传播得到结果。
2、Word Embedding
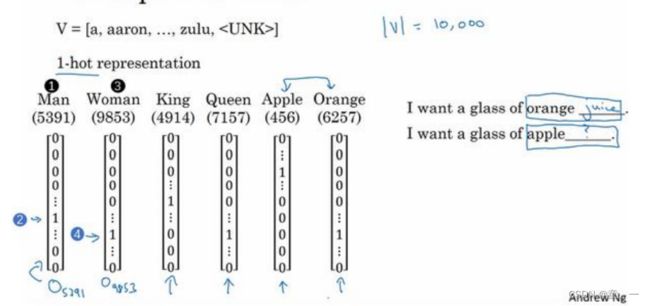
使用一定数量的单词构成词汇表,然后将词汇表中的单词使用one-hot编码表示

使用一定数量的特征词(如300个),通过对词汇表中单词进行判断得到每个单词与特征词的相关性从而得到嵌入矩阵E。