机器学习流程
机器学习流程(spark 和 sklearn)
- 概述
- 机器学习流程
- 一 获取数据(pandas)
-
- CSV
- HDF5(二进制)
- JSON
- 获取数据(spark)
-
- 数据集分类
- 将本地数据导入spark
-
- 连接 pyspark
- 创建 RDD 或 DataFrom
- 二 数据的基本处理
-
- 数据去重
- 缺失值处理
- 异常值处理
- 数据集分割
- 数据抽样
- 三 特征工程
-
- 特征提取
-
- 数据离散化 和 one-hot编码
- 文本特征提取 和 jieba分词
- Tfidf
- 特征预处理
-
- 归一化 和 标准化
- 特征衍生
- 特征降维
-
- 特征选择(Filter)
-
- 低方差特征过滤
- 相关系数
-
- 皮尔逊相关系数
- 斯皮尔曼相关系数(Rank IC)
- 嵌入式(Embedded)
-
- 基于L1的特征选择
- 基于lightgbm/XGBoost 的特征选择
- 主成分分析(PCA)
- 四 模型训练(算法)
-
- 算法分类(根据数据集种类)
- 区别
- 五 模型评估
-
- 拟合和欠拟合(评估结果效果)
-
- 欠拟合
- 过拟合
- 分类模型评估
-
- 准确率
- 精确率、召回率、F1-score
- AUC指标(ROC线下面积)
- 回归模型评估
-
- 均方误差(Mean Squared Error)
- 决定系数(Coefficient of Determination)
- 六 模型的保存和加载
概述
人工智能发展必备三要素:数据、算法、计算力
人工智能和机器学习,深度学习的关系:
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
机器学习概述:从数据中自动分析获取模型,并利用模型对未知数据进行预测
需要安装:scikit-learn
scikit-learn 官方文档
机器学习流程
机器学习工作流程总结:
- 获取数据
- 数据基本处理
- 特征工程
- 模型训练 (算法阶段)
- 模型评估
评估结果达到要求,上线服务
没有达到要求,重复2-5步
数据处理和特征工程决定了机器学习的上限,而模型训练和优质算法只是为了逼近这个上限
一 获取数据(pandas)
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,例如CSV,SQL,XLS,JSON,HDF5。
注:最常用的HDF5和CSV文件

CSV
读取CSV数据
pandas.read_csv(filepath_or_buffer,sep =',',usecols=[])
filepath_or_buffer:文件路径(相对路径和绝对路径均可使用)sep:分隔符,默认用,usecols=[]:指定读取的列名,列表形式chunksize:分批加载,每次加载的多少条数据iterator:读取的数据 呈 可迭代类型 输出(可遍历)
保存数据为 CSV 文件
DataFrame对象名.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None)
path_or_buf:文件路径sep:分隔符,默认用,columns:选择需要写入文件的列索引名header:是否写入列索引,布尔值或字符串列表,默认为True,index:是否写入 行索引,False为不写入行索引;读取时会将其当做一列数据而非列索引mode:写入方式 。w:删除原文件数据写入,a追加写入
HDF5(二进制)
需要安装安装tables模块,否则不能读取HDF5文件
pip install tables
HDF5文件可以保存多张表,因此读取和存储需要指定一个key来 标识 DataFrom
读取格式:pandas.read_hdf(path_or_buf,key =None,** kwargs)
保存格式:pandas.to_hdf(path_or_buf,key =None,** kwargs)
path_or_buffer:文件路径key:保存和读取时 用来标识DataFrom的键return:Theselected object
注意:优先选择使用HDF5文件存储
HDF5在存储的时候支持压缩,使用的方式是blosc- 速度最快,也是
pandas默认支持的 - 使用压缩可以提磁盘利用率,节省空间
HDF5还是跨平台的,可以轻松迁移到hadoop上面
JSON
pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False)
-
将
JSON格式准换成默认的Pandas DataFrame格式 -
orient:string,Indication of expected JSON string format-
split:dict like {index -> [index], columns -> [columns], data -> [values]}
split 将索引总结到索引,列名到列名,数据到数据。将三部分都分开了s='{"index":["stu1", "stu2", "stu3"],'\ '"columns":["name","age"],'\ '"data":[["xiaomaimiao", 20],["xxt", 18],["xmm", 1]]'\ '}' print(pd.read_json(s,orient='split')) 执行结果: age name stu1 20 xiaomaimiao stu2 18 xxt stu3 1 xmm -
records:list like [{column:value}, ... , {column:value}]最常规s='[{"name":"xiaomaimiao","age":20},'\ '{"name":"xxt","age":18},'\ '{"name":"xmm","age":1}]' print(pd.read_json(s,orient='records')) 执行结果: age name 0 20 xiaomaimiao 1 18 xxt 2 1 xmm -
index:index: {columns:values, ...}...s='{"stu1":{"name": "xiaomaimiao", "age":20},'\ '"stu2":{"name": "xxt", "age": 18},'\ '"stu3":{"name": "xmm", "age": 1},}' print(pd.read_json(s,orient='index')) 执行结果: age name stu1 20 xiaomaimiao stu2 18 xxt stu3 1 xmm -
columns:columns: {index:values,...}s='{"name":{"stu1": "xiaomaimiao", "stu2": "xxt", "stu3": "xmm"},'\ '"age":{"stu1": 20, "stu2": 18 "stu3": 1}}' print(pd.read_json(s,orient='columns')) 执行结果: name age stu1 xiaomaimiao 20 stu2 xxt 18 stu3 xmm 1 -
values:just the values array
values直接输出值s='[["a",1],["b",2]]' print(pd.read_json(s,orient='values')) 执行结果: 0 1 0 a 1 1 b 2
-
-
lines:boolean, 默认False按照每行读取json对象,json与DataFrom行行对应 -
typ:默认 ‘frame’, 指定转换成的对象类型series或者dataframe
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- 将
Pandas对象存储为json格式 path_or_buf=None:文件地址orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}lines:一个对象存储为一行
获取数据(spark)
算法中的数据一般以 数据集的形式存在:
- 数据集类似于二维表格
- 一行数据 称为 一个样本
- 一列数据 成为 一个特征
数据集分类
根据数据集中是否包含目标值和目标值类型分为:
- 连续型目标值
特征值+目标值(目标值是连续)
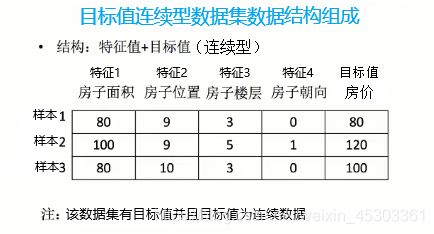
- 离散型目标值
特征值+目标值(目标值是离散的)

- 没有目标值
只有特征值,没有目标值
将本地数据导入spark
连接 pyspark
RDD的程序入口
1. 导入pyspark库中的SparkContext类
from pyspark import SparkContext
2. 创建SparkContext实例,并设置Spark应用的基本信息
sc = sparkContext('local','test')
源码:pyspark.SparkContext(master = None,appName = None,sparkHome = None,pyFiles = None,environment = None,batchSize = 0,
serializer = PickleSerializer(),conf = None,gateway = None,jsc = None,
profiler_cls = )
参数:master:要连接的群集URL (例如:mesos:// host:port,spark:// host:port,local [4])
appName:您的工作的名称,将显示在群集Web UI上。
sparkHome:在群集节点上安装Spark的位置。
pyFiles:.zip或.py文件的集合,以发送到集群并添加到PYTHONPATH
这些可以是本地文件系统或HDFS,HTTP,HTTPS或FTP URL上的路径。
environment:在工作节点上设置的环境变量字典
batchSize:表示为单个的Python对象的数量Java对象。
设置1禁用批处理,
设置0以根据对象大小自动选择批处理大小
设置-1以使用无限的 批处理大小
serializer :RDD的序列化器。
conf:AL {SparkConf}对象设置Spark属性。
gateway:使用现有的网关和JVM,否则将实例化新的JVM
jsc:JavaSparkContext实例(可选)。
profiler_cls:一类用于进行概要分析的自定义Profiler
(默认为pyspark.profiler.BasicProfiler)。
DataForm的程序入口
4. 导入pyspark库中的SparkSession类
from pyspark.sql import SparkSession
5. 创建sparkSession实例,并设置Spark应用的基本信息
sparkSession实例名 = SparkSession.builder.appName("xxx").getOrCreate()
类方法:
.appName:工作名称,将显示在群集 Spark Web UI上( host:4040 )
.getOrCreate():获取一个现有的SparkSession,如果不存在,则根据此构建器中设置的选项创建一个新的。
.config(key = None,value = None,conf = None ):设置配置选项
使用此方法设置的选项会自动传播到SparkConf和SparkSession自己的配置中。
.enableHiveSupport():启用Hive支持,包括与持久性Hive Metastore的连接,对Hive Serdes的支持以及Hive用户定义的功能。
.master:要连接的群集URL (例如,mesos:// host:port,spark:// host:port,local [4])
传入local代表本地模式, local[4]代表本地模式4内核运行 , 或者spark://master:7077 提交到 standalone集群模式运行
创建 RDD 或 DataFrom
-
创建成
RDD-
由本地或
HDFS文件创建# 读取本地文件 sparkContext实例名.textFile("file:///xxx/xxx.txt") # sc为创建的sparkcontext对象 # 读取本地压缩包 sparkContext实例名.textFile("file:///xxx/xxx.gz") # 读取hdfs的上的文件 sparkContext实例名.textFile("hdfs://node-teach:8020/xxx/xxx.log")支持整个目录、多文件、通配符
-
集合并行化:把
非RDD数据转换为RDD- 调用
SparkContext的parallelize方法 将 现有的可迭代对象或者集合 转化# 定义一个列表,并将列表序列化为 RDD data=[1,2,3,4,5] rdd1 = sparkContext实例名.parallelize(data, 指定分区数量)- 分区数量 需要根据
CPU核数指定(每个CPU核有2-4个分区) - 若不指定分区数量,则
Spark会自动设置分区(CPU核数*2)
- 分区数量 需要根据
- 调用
-
-
创建
DataFrom-
基于本地
RDD、csv、json、parquet、orc、jdbc文件,通过sparkSession.read.数据源格式.local(数据源文件名)生成# 基于 Java文件 生成 (两种方法,两种书写方法) 方法一:反射自动推测,适合静态数据 jsonDF = sparkSession实例名.read.json("xxx.json") jsonDF = sparkSession实例名.read.format('json').load('xxx.json') 方法二:程序指定,适合程序运行中动态生成的数据 from pyspark.sql.types import StructType, StructField # 根据json的具体数据类型指定DataFrom的Schema(两种写法) jsonSchema = StructType() \ # StructType表示的是一个对象,在json中的体现为 大括号 {} .add("id", StringType(),True) \ # (json中的键,该键对应值的数据类型,是否为空) .add("city", StringType()) \ .add("pop" , LongType()) \ .add("state",StringType()) jsonSchema = StructType([ StructField("id", StringType(), True), StructField("city", StringType(), True), StructField("loc" , ArrayType(DoubleType())), # 表示 键loc值的数据类型为数组,并且数组中的元素为 Double类型(双精度小数) StructField("pop", LongType(), True), StructField("state", StringType(), True) ]) jsonSchema = StructType() \ # 有嵌套类型的json .add("dc_id", StringType()) \ .add("source", MapType(StringType(), # 表示 键source值中嵌套了几个并列的json,其中嵌套json的键数据类型为StringType,值为StructType(......) StructType() \ .add("description", StringType()) \ .add("ip", StringType()) \ .add("id", LongType()) \ .add("geo", StructType() \ # 表示 键geo值中嵌套了一个json .add("lat", DoubleType()) \ .add("long", DoubleType()) ) ) ) jsonDF = sparkSession实例名.read.schema(jsonSchema).format('json').load('xxx.json') # json字符串的解析 explodedDF = jsonDF.select("dc_id",explode("source")) # explode("source") 表示 获取 source嵌套json内部的 key 和 value notifydevicesDS = explodedDF.select( "dc_id", "key", explodedDF.value.getItem("id") ,explodedDF.value['temp'].alias('为列起别名') ) # 通过value.getItem(键名)或 value[键名] 进一步取指定值 # 基于csv文件 创建 CSVdf = sparkSession实例名.read.csv("hdfs://IP:9000/csv文件名.csv", header=True, schema=schema) # 读取CSV文件中保存的json CSVdf = sparkSession实例名.read.format("csv"). option("header", "true") .load("csv文件名.csv") 方法: .format(数据源格式):指定输入数据源格式 .load(path = 指定文件路径列表,format = None,schema = None,** options ):从数据源加载数据,并将其作为:class`DataFrame`返回 .option(key,value):为基础数据源添加输出选项 # 基于mysql数据库 jdbcDF = sparkSession实例名.read.format("jdbc") .option("url","jdbc:mysql://localhost:3306/数据库名") # 数据库的主句IP,端口 和数据库名 .option("dbtable","表名") # 连接的表名 .option("user","用户名") # 用户名 .option("password","密码") # 密码 .load() 注意:若是将DataFrom保存成相应的数据类型 仅需将 read 改成 save -
基于已有的
pandas dataframe、list、RDD,通过sparkSession.createDataFrame生成# 基于RDD创建 sc = sparkContext('local','test') l = [('Ankit',25),('Jalfaizy',22),('saurabh',20),('Bala',26)] rdd = sc.parallelize(l) 方法1 # 为数据添加列名 people = rdd.map(lambda x: Row(name=x[0], age=int(x[1]))) # 创建DataFrame schemaPeople = sparkSession实例名.createDataFrame(people) 方法2 # 定义Schema from pyspark.sql.types import StructType ,structField schema = StructType (structField ("字段名", 数据类型, 能否为空),structField ("name", stringType (), True),structField("age", LongType (), True) # 创建DataFrom swimmers = sparkSession实例名.createDataRrame (stringCSVRDD, schema)
-
二 数据的基本处理
作用:对数据中的缺失值、异常值 和 重复值 进行 补全、替换 或 删除 等处理
数据去重
pandas
dataframe.duplicated() # 判断该数据记录是否重复(返回 True 和 False)
dataframe.drop_duplicates([指定列的列表]) # 删除数据记录中指定列列值都相同的记录
spark
格式:datafrom.dropDuplicates(字段列表) 表示删除字段列表中的值完全一致的重复行
1. 删除完全一样的记录
df1 = df.dropDuplicates()
2. 删除关键字段值完全一致的记录(例:删除 除id 外 其余值一致的数据)
df2 = df1.dropDuplicates(subset = [c for c in df2.columns if c!='id'])
3. 查看某一列是否有重复值
import pyspark.sql.functions as fn
df2.agg(fn.count('id').alias('id_count'),fn.countDistinct('id').alias('distinct_id_count')).collect()
对于id这种无意义的列重复,添加另外一列自增id
df2.withColumn('new_id',fn.monotonically_increasing_id()).show()
缺失值处理
缺失值处理方式
- 直接删除带有缺失值的行记录(整行删除)或者列字段(整列删除),删除意味着会消减数据特征,不适合直接删除缺失值的情况:
- 数据记录不完整情况且比例较大(如超过10%),删除会损失过多有用信息。
- 带有缺失值的数据记录大量存在着明显的数据分布规律或特征
- 带有缺失值的数据记录的目标标签(即分类中的Label变量)主要集中于某一类或几类,如果删除这些数据记录将使对应分类的数据样本丢失大量特征信息,导致模型过拟合或分类不准确。
- 填充缺失值 相对直接删除而言,用适当方式填充缺失值,形成完整的数据记录是更加常用的缺失值处理方式。常用的填充方法如下:
- 统计法
- 对于数值型的数据,使用均值、加权均值、中位数等方填充
- 对于分类型数据,使用类别众数最多的值填充。
- 模型法:更多时候我们会基于已有的其他字段,将缺失字段作为目标变量进行预测,从而得到最为可能的补全值。如果带有缺失值的列是数值变量,采用回归模型补全;如果是分类变量,则采用分类模型补全。
- 专家补全:对于少量且具有重要意义的数据记录,专家补足也是非常重要的一种途径。
- 其他方法:例如随机法、特殊值法、多重填补等。
- 统计法
- 真值转换法 承认缺失值的存在,并且把数据缺失也作为数据分布规律的一部分,将变量的实际值和缺失值都作为输入维度参与后续数据处理和模型计算中。但是变量的实际值可以作为变量值参与模型计算,而缺失值通常无法参与运算,因此需要对缺失值进行真值转换。
- 以用户性别字段为例,男 女 未知
- 不处理 数据分析和建模应用中很多模型对于缺失值有容忍度或灵活的处理方法,因此在预处理阶段可以不做处理。常见的能够自动处理缺失值的模型包括:KNN、决策树和随机森林、神经网络和朴素贝叶斯
pandas
1. 获取缺失值的标记方式( NaN 或 其他标记方式)
将其他标记的缺失值替换成 NaN : .replace(to_replace='?', value=np.nan)
2. 判断是否含有缺失值数据
1. pd.isnull(DataFrame对象名) 配合 np.any()使用( pd.isnull().any())
配合`sun()`直接获取字段空值个数`pd.isnull().sum()`
2. pd.notnull(DataFrame对象名) 配合 np.all()使用
3. pd[(DataFrame对象名)=="其他标记符号"] 配合 np.any()使用
4. 1 - (DataFrame对象名.count()/DataFrame对象名.shape[0]) 查看列缺失比例
5. 绘制行缺失比例个数条形图
h_nan = 1 - (DataFrame对象名.count(1)/DataFrame对象名.shape[1])
h_nan.groupby(h_nan.values).count().plot.bar()
3. 处理缺失值
1. 删除缺失值少于指定非缺失值个数的行和列:dropna(axis ='rows', thresh=非缺失值个数) axis =1 表示删除列,默认为删除行
注:不会修改原数据,需要接受返回值
2. 替换缺失值:fillna(value,inplace = True, method='backfill')
value: 替换成的值
inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
method:表示填充方式
backfill:用后面的值替换缺失值
bfill, limit=1: 用后面的值替代缺失值,限制每列只能替代一个缺失值,当连续出现NAN时,填充后仍会包含NAN
pad:用前面的值替换缺失值
{'col2': 1.1, 'col4': 1.2}: 用不同值替换不同列的缺失值
.fillna(df.mean()['col2':'col4']) :选择各自列的均值替换缺失值
使用sklearn填充缺失值
from sklearn.impute import SimpleImputer # 导入sklearn中SimpleImputer库
nan_model = SimpleImputer(missing_values=np.nan, strategy='mean') # 建立替换规则:将值为NaN的缺失值以均值做替换
nan_result = nan_model.fit_transform(df) # 应用模型规则
spark
df_miss = spark.createDataFrame([
(1, 143.5, 5.6, 28,'M', 100000),
(2, 167.2, 5.4, 45,'M', None),
(3, None , 5.2, None, None, None),
(4, 144.5, 5.9, 33, 'M', None),
(5, 133.2, 5.7, 54, 'F', None),
(6, 124.1, 5.2, None, 'F', None),
(7, 129.2, 5.3, 42, 'M', 76000),],
['id', 'weight', 'height', 'age', 'gender', 'income'])
1. 计算各列的缺失情况百分比
df_miss.agg(*[(1 - (fn.count(c) / fn.count('*'))).alias(c + '_missing') for c in df_miss.columns]).show()
2. 删除缺失值过于严重的列
df_miss_no_income = df_miss.drop('列1')
3. 计算每行记录的缺失值情况
df_miss.rdd.map(lambda row:(row['id'],sum([c==None for c in row]))).collect()
[(1, 0), (2, 1), (3, 4), (4, 1), (5, 1), (6, 2), (7, 0)]
4. 按照 非缺失值个数 删除行
df_miss_no_income.dropna(thresh=3).show()
5. 填充缺失值,可以用fillna来填充缺失值,
# 对于数值类型,可以用均值或者中位数等填充
# 先计算均值,并组织成一个字典
means = df_miss_no_income.agg( *[fn.mean(c).alias(c) for c in df_miss_no_income.columns if c != 'gender']).toPandas().to_dict('records')[0]
# 对于bool类型、或者分类类型,可以为缺失值单独设置一个类型,missing
means['gender'] = 'missing'
# 根据字典修改缺失值
df_miss_no_income.fillna(means).show()
异常值处理
异常值:不属于正常的值
包含:超过正常范围内的较大值或较小值
方法:分位数去极值、中位数绝对偏差去极值、正态分布去极值
核心思想:通过原始数据设定一个正常的范围,超过此范围的就是一个异常值
异常值(极值)处理:
- 对异常数据进行处理前,需要先辨别出到底哪些是真正的数据异常。从数据异常的状态看分为两种:
- 由于业务特定运营动作产生的,正常反映业务状态,而不是数据本身的异常规律。
- 不是由于特定的业务动作引起的,而是客观地反映了数据本身分布异常
- 大多数情况下,异常值都会在数据的预处理过程中被认为是噪音而剔除,以避免其对总体数据评估和分析挖掘的影响。但在以下几种情况下,我们无须对异常值做抛弃处理。
- 异常值由运营活动导致,正常反映了业务运营结果
- 公司的A商品正常情况下日销量为1000台左右。由于昨日举行优惠促销活动导致总销量达到10000台,由于后端库存备货不足导致今日销量又下降到100台。在这种情况下,10000台和100台都正确地反映了业务运营的结果,而非数据异常案例。
- 异常检测模型
- 围绕异常值展开的分析工作,如异常客户(羊毛党)识别,作弊流量检测,信用卡诈骗识别等
- 对异常值不敏感的数据模型
- 如决策树
- 异常值由运营活动导致,正常反映了业务运营结果
pandas 的 Z-Score 去极值
计算公式 Z = X-μ/σ 其中μ为总体平均值,X-μ为离均差,σ表示标准差。z的绝对值表示在标准差范围内的原始分数与总体均值之间的距离。当原始分数低于平均值时,z为负,以上为正

df = pd.DataFrame({'col1': [1, 120, 3, 5, 2, 12, 13],
'col2': [12, 17, 31, 53, 22, 32, 43]})
# 通过Z-Score方法判断异常值
z_score = (df - df.mean()) / df.std() # 计算每列的Z-score得分
df_zscore = z_score.abs() < 2.2 # 判断Z-score得分是否大于2.2,如果是则是True,否则为False
# 删除异常值所在的行
df_drop_outlier = df[df_zscore].dropna() # 取出df_zscore中为True的数据,为False的数据变成 NaN;之后删除含NAN的行
# 一行代码表示
df_drop_outlier = df[((df - df.mean())/df.std()).abs()<2.2].dropna()
pandas分位数去极值
# 构建数据
df_outliers = pd.DataFrame([
(1, 143.5, 5.3, 28),
(2, 154.2, 5.5, 45),
(3, 342.3, 5.1, 99),
(4, 144.5, 5.5, 33),
(5, 133.2, 5.4, 54),
(6, 124.1, 5.1, 21),
(7, 129.2, 5.3, 42),
], columns=['id', 'weight', 'height', 'age'])
# 设置行索引
df = df_outliers.set_index("id")
# 根据四分位数计算出内距
df_ = df.describe().loc[["25%", "75%"],:].T
df_["min"] = df_["25%"] - 1.5 * (df_["75%"] - df_["25%"])
df_["max"] = df_["75%"] + 1.5 * (df_["75%"] - df_["25%"])
# 删除不在内距中的异常值
df[(df >= df_["min"]) & (df <= df_["max"])].dropna()
spark 分位数去极值
df_outliers = spark.createDataFrame([
(1, 143.5, 5.3, 28),
(2, 154.2, 5.5, 45),
(3, 342.3, 5.1, 99),
(4, 144.5, 5.5, 33),
(5, 133.2, 5.4, 54),
(6, 124.1, 5.1, 21),
(7, 129.2, 5.3, 42),
], ['id', 'weight', 'height', 'age'])
# 设定范围 超出这个范围的 用边界值替换
# approxQuantile方法计算分位数,接收三个参数:参数1,列名;参数2:想要计算的分位点,可以是一个点,也可以是一个列表(0和1之间的小数),
第三个参数是能容忍的误差,如果是0,代表百分百精确计算。
cols = ["weight","height","age"]
# bounds,用来存储后面生成的各个字段值的边界
bounds = {}
for col in cols:
# 涉及统计中的4分位。计算Q1和Q3
quantiles = df_outliers.approxQuantile(col, [0.25,0.75], 0.05)
# 计算4分位距
IQR = quantiles[1] - quantiles[0]
# 计算内限
bounds[col] = [quantiles[0] - 1.5*IQR, quantiles[1] + 1.5*IQR]
print("bounds: ",bounds)
# 判断是否为异常值,在内限之外的值为异常值
outliers = df_outliers.select(*['id'] + \
[((df_outliers[c] < bounds[c][0]) | (df_outliers[c] > bounds[c][1]) )\
.alias(c +"_o") for c in cols])
outliers.show()
+---+--------+--------+-----+
| id|weight_o|height_o|age_o|
+---+--------+--------+-----+
| 1| false| false|false|
| 2| false| false|false|
| 3| true| false| true|
| 4| false| false|false|
| 5| false| false|false|
| 6| false| false|false|
| 7| false| false|false|
+---+--------+--------+-----+
# 再回头看看这些异常值的值,重新和原始数据关联
df_outliers = df_outliers.join(outliers, on='id')
df_outliers.filter('weight_o').select('id', 'weight').show()
+---+------+
| id|weight|
+---+------+
| 3| 342.3|
+---+------+
df_outliers.filter('age_o').select('id', 'age').show()
+---+---+
| id|age|
+---+---+
| 3| 99|
+---+---+
数据集分割
机器学习一般会将数据集划分为两个部分:
- 训练数据:用于训练模型
- 测试数据:用于评估模型
常见划分比例:
| 训练集 | 70% | 80% | 75% |
|---|---|---|---|
| 测试集 | 30% | 20% | 25% |
sklearn
方法1:x_train, x_test, y_train, y_test = sklearn.model_selection.train_test_split(arrays, *options)
x: 数据集的特征值y: 数据集的标签值test_size: 测试集的大小,在 [0, 1]之间,确定训练集和测试集比例random_state: 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
方法2:df1,df2 = DataFlame.randomSplit([df1占比例, df2占比例],随机数种子)
例如 :trainDF, testDF = df.randomSplit([0.7, 0.3],100)
- 占比和不唯一则会按比例进行归一化(
[2, 3] ==> [0.4, 0.6]) - 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
spark
- 拆分数据即集:
randomSplit拆成两部分
格式 :df1,df2 = DataFlame.randomSplit([df1占比例, df2占比例])trainDF, testDF = df.randomSplit([0.6, 0.4]) - 采样数据:
sample
格式:DataFlame.sample(抽样是否放回,采样比例,随机种子100)sdf = df.sample(False,0.2,100)
数据抽样
抽样:从整体样本中通过一定的方法选择一部分样本
-
为什么要抽样
- 数据量太大,全量计算对硬件要求太高
- 数据采集限制。很多时候抽样从数据采集端便已经开始,例如做社会调查
- 时效性要求。抽样带来的是以局部反映全局的思路,如果方法正确,可以以极小的数据计算量来实现对整体数据的统计分析,在时效性上会大大增强。
-
数据抽样的现实意义
- 通过抽样来实现快速的概念验证
- 通过抽样可以解决样本不均衡问题(欠抽样、过抽样以及组合/集成的方法)
- 通过抽样可以解决无法实现对全部样本覆盖的数据分析场景(市场研究、客户线下调研、产品品质检验)
-
如何进行抽样
-
抽样方法从整体上分为非概率抽样和概率抽样两种
-
非概率抽样:不是按照等概率的原则进行抽样,而是根据人类的主观经验和状态进行判断
可以解决样本不均衡(不同类别的样本量差异非常大)问题
样本分布不均衡将导致样本量少的分类所包含的特征过少,建立的模型容易过拟合。
如果不同分类间的样本量差异超过10倍就需要引起警觉,超过20倍就一定要想法解决了。- 样本分布不均衡易出现场景
- 异常检测:大多数企业中的异常个案都是少量的,比如恶意刷单、黄牛订单、信用卡欺诈、电力窃电、设备故障等。这些数据样本所占的比例通常是整体样本中很少的一部分。以信用卡欺诈为例,刷实体信用卡欺诈的比例一般在0.1%以内
- 客户流失:大型企业的流失客户相对于整体客户通常是少量的,尤其对于具有垄断地位的行业巨擘,例如电信、石油、网络运营商等更是如此
- 偶发事件:罕见事件与异常检测类似,都属于发生个案较少的情况;但不同点在于异常检测通常都有是预先定义好的规则和逻辑,并且大多数异常事件都对会企业运营造成负面影响,因此针对异常事件的检测和预防非常重要;但罕见事件则无法预判,并且也没有明显的积极和消极影响倾向。例如,由于某网络大V无意中转发了企业的一条趣味广告,导致用户流量明显提升便属于此类。
- 低频事件:这种事件是预期或计划性事件,但是发生频率非常低。例如,每年一次的“双11”购物节一般都会产生较高的销售额,但放到全年来看,这一天的销售额占比很可能只有不到1%,尤其对于很少参与活动的公司而言,这种情况更加明显。这种就属于典型的低频率事件。
- 如何处理样本分布不均衡问题
-
抽样:抽样是解决样本分布不均衡相对简单且常用的方法,包括过抽样和欠抽样两种。
- 过抽样:又称上采样,通过 增加分类中少数类样本的数量来实现样本均衡
- 最直接的方法:复制少数类样本以形成多条记录
- 缺点:如果样本特征少则可能导致过拟合。经过改进的过抽样方法会在少数类中加入随机噪声、干扰数据,或通过一定规则产生新的合成样本,例如
SMOTE算法。
- 欠抽样:又称下采样,其通过减少分类中多数类样本的数量来实现样本均衡
- 最直接的方法:随机去掉一些多数类样本来减小多数类的规模
- 缺点:会丢失多数类样本中的一些重要信息。
- 过抽样:又称上采样,通过 增加分类中少数类样本的数量来实现样本均衡
-
正负样本的惩罚权重:在算法实现过程中,对于分类中不同样本数量的类别分别赋予不同的权重(一般思路分类中的小样本量类别权重高,大样本量类别权重低),然后进行计算和建模。
- 很多模型和算法中都有基于类别参数的调整设置,以
scikit-learn中的SVM为例,通过在class_weight:{dict,'balanced'}中针对不同类别来手动指定权重,如果使用其默认的方法balanced,那么SVM会将权重设置为与不同类别样本数量呈反比的权重来进行自动均衡处理,计算公式如下:n_samples/(n_classes*np.bincount(y))
- 很多模型和算法中都有基于类别参数的调整设置,以
-
组合/集成:每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生分类预测结果。
- 数据集中的正、负例的样本分别为
100条和10000条,比例为1:100。此时可以将负例样本(类别中的大量样本集)随机分为100份(当然也可以分更多),每份100条数据;然后每次形成训练集时使用所有的正样本(100条)和随机抽取的负样本(100条)形成新的数据集。如此反复可以得到100个训练集和对应的训练模型。
这种解决问题的思路类似于随机森林。在随机森林中,虽然每个小决策树的分类能力很弱,但是通过大量的“小树”组合形成的“森林”具有良好的模型预测能力。
- 数据集中的正、负例的样本分别为
-
import pandas as pd from imblearn.over_sampling import SMOTE # 过抽样处理库SMOTE from imblearn.under_sampling import RandomUnderSampler # 欠抽样处理库RandomUnderSampler # 使用SMOTE方法进行过采样处理 model_smote = SMOTE() # 建立SMOTE模型对象 x_smote_resampled, y_smote_resampled = model_smote.fit_sample(x, y) # 输入数据并作过采样处理 x_smote_resampled = pd.DataFrame(x_smote_resampled, columns=['col1', 'col2', 'col3', 'col4', 'col5']) # 将特征数据转换为 DataFrame 并命名列名 y_smote_resampled = pd.DataFrame(y_smote_resampled, columns=['label']) # 将目标数据转换为 DataFrame 并命名列名 smote_resampled = pd.concat([x_smote_resampled, y_smote_resampled], axis=1) # 按列合并DataFrame # 使用RandomUnderSampler方法进行欠采样处理 model_RandomUnderSampler = RandomUnderSampler() # 建立RandomUnderSampler模型对象 x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled = model_RandomUnderSampler.fit_sample(x, y) # 输入数据并作欠采样处理 x_RandomUnderSampler_resampled = pd.DataFrame(x_RandomUnderSampler_resampled, columns=['col1', 'col2', 'col3', 'col4', 'col5']) # 将数据转换为数据框并命名列名 y_RandomUnderSampler_resampled = pd.DataFrame(y_RandomUnderSampler_resampled, columns=['label']) # 将数据转换为数据框并命名列名 RandomUnderSampler_resampled = pd.concat([x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled], axis=1) # 按列合并数据框 # 查看采样后的数据分布 groupby_data_RandomUnderSampler = RandomUnderSampler_resampled.groupby('label').count() # 对label做分类汇总 - 样本分布不均衡易出现场景
-
概率抽样:以数学概率论为基础,按照随机的原则进行抽样。
- 简单随机抽样
- 按等概率原则直接从总样本中抽取n个样本
- 简单、易于操作,但是它并不能保证样本能完美代表总体
- 基本前提是所有样本个体都是等概率分布的,但真实情况却是多数样本都不是或无法判断是否是等概率分布的
- 在简单随机抽样中,得到的结果是不重复的样本集,还可以使用有放回的简单随机抽样,这样得到的样本集中会存在重复数据。该方法适用于个体分布均匀的场景
使用 Numpy 进行随机采样 shuffle_index = np.random.choice(np.arange(data.shape[0]),2000,True) # 随机生成2000个行号 data_sample = data[shuffle_index] # 从原始数据中取出2000个行号对应的数据 使用 Pandas 进行随机采样 DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None) 参数:n :随机抽取的样本数(不能与frac一起使用) frac:随机抽取的比例(不能与n一起使用) replace:是否直接替换原DataFrom数据 weights:str或ndarray,可选 “None”:等概率加权 Series:将与索引上的目标对象对齐。在采样对象中找不到的权重索引值将被忽略,而在采样对象中没有权重的索引值将被分配为零。如果在DataFrame上调用,则在axis = 0时将接受列的名称。除非权重为Series,否则权重的长度必须与要采样的轴的长度相同。如果权重不等于1,则将它们归一化为总和1。权重列中的缺失值将被视为零。不允许使用无限值 random_state:随机种子 使用 Sklearn 采样数据 rdd1.sample(抽样是否放回,采样比例,随机种子)- 等距抽样
- 等距抽样是先将所有样本按顺序编号,然后按照固定抽样间隔抽取个体
- 该方法适用于个体分布均匀或呈现明显的均匀分布规律,无明显趋势或周期性规律的数据
- 当总体样本的分布呈现明显的分布规律时容易产生偏差,例如增减趋势、周期性规律等。
# 等距抽样 data = np.loadtxt('data3.txt') # 导入普通数据文件 sample_count = 2000 # 指定抽样数量 record_count = data.shape[0] # 获取最大样本量 width = record_count / sample_count # 计算抽样间距 data_sample = [] # 初始化空白列表,用来存放抽样结果数据 i = 0 # 自增计数以得到对应索引值 while len(data_sample) <= sample_count and i * width <= record_count - 1: # 当样本量小于等于指定抽样数量并且矩阵索引在有效范围内时 data_sample.append(data[int(i * width)]) # 新增样本 i += 1 # 自增长 print(data_sample[:2]) # 打印输出前2条数据 print(len(data_sample)) # 打印输出样本数量 - 简单随机抽样
-
-
-
抽样需要注意的几个问题
- 数据抽样要能反映运营背景
- 数据时效性问题:使用过时的数据(例如1年前的数据)来分析现在的运营状态。
- 不能缺少关键因素数据:没有将运营分析涉及的主要因素所产生的数据放到抽样数据中,导致无法根据主要因素产生有效结论,模型效果差,例如抽样中没有覆盖大型促销活动带来的销售增长。
- 必须具备业务随机性:有意/无意多抽取或覆盖特定数据场景,使得数据明显趋向于特定分布规律,例如在做社会调查时不能使用北京市的抽样数据来代表全国。
- 业务增长性:在成长型公司中,公司的发展不都是呈现线性趋势的,很多时候会呈现指数趋势。这时需要根据这种趋势来使业务满足不同增长阶段的分析需求,而不只是集中于增长爆发区间。
- 数据来源的多样性:只选择某一来源的数据做抽样,使得数据的分布受限于数据源。例如在做各分公司的销售分析时,仅将北方大区的数据纳入其中做抽样,而忽视了其他大区的数据,其结果必然有所偏颇。
- 业务数据可行性问题:很多时候,由于受到经费、权限、职责等方面的限制,在数据抽样方面无法按照数据工作要求来执行,此时要根据运营实际情况调整。这点往往被很多数据工作者忽视。
- 数据抽样要能满足数据分析和建模需求
- 抽样样本量的问题(数据量与模型效果关系)
- 以时间为维度分布的,至少包含一个能满足预测的完整业务周期
- 做预测(包含分类和回归)分析建模的,需要考虑特征数量和特征值域(非数值型)的分布,通常数据记录数要同时是特征数量和特征值域的100倍以上。例如数据集有5个特征,假如每个特征有2个值域,那么数据记录数需要至少在1000(100×5×2)条以上。
- 做关联规则分析建模的,根据关联前后项的数量(每个前项或后项可包含多个要关联的主体,例如品牌+商品+价格关联),每个主体需要至少1000条数据。例如只做单品销售关联,那么单品的销售记录需要在1000条以上;如果要同时做单品+品牌的关联,那么需要至少2000条数据。
- 对于异常检测类分析建模的,无论是监督式还是非监督式建模,由于异常数据本来就是小概率分布的,因此异常数据记录一般越多越好。
- 抽样样本在不同类别中的分布问题
- 做分类分析建模问题时,不同类别下的数据样本需要均衡分布
- 抽样样本能准确代表全部整体特征:
- 非数值型的特征值域(例如各值频数相对比例、值域范围等)分布需要与总体一致。
- 数值型特征的数据分布区间和各个统计量(如均值、方差、偏度等)需要与整体数据分布区间一致。
- 缺失值、异常值、重复值等特殊数据的分布要与整体数据分布一致。
- 做分类分析建模问题时,不同类别下的数据样本需要均衡分布
- 抽样样本量的问题(数据量与模型效果关系)
- 异常检测类数据的处理:
- 对于异常检测类的应用要包含全部异常样本。对于异常检测类的分析建模,本来异常数据就非常稀少,因此抽样时要优先将异常数据包含进去。
- 对于需要去除非业务因素的数据异常,如果有类别特征需要与类别特征分布一致;如果没有类别特征,属于非监督式的学习,则需要与整体分布一致。
- 数据抽样要能反映运营背景
三 特征工程
作用:使用专业背景知识和技巧处理数据,使机器学习在关键的特征上学习并且简化计算量(其结果直接影响测试结果)
特征提取
作用:将任意数据(如文本或图像)转换为可用于机器学习的数字特征

数据离散化 和 one-hot编码

数据离散化:在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值 代表落在每个子区间中的 属性值
- 简化数据结构,减少给定连续属性值的个数
- 算法需要(血糖含量分类:低血糖,正常,高血糖)将回归问题转化为分类问题
- 注意离散化之后避免出现 数据样本不均衡现象
one-hot编码:把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1其。又被称为热编码
- 将非数值型数据 转化成 布尔型数据,便于矩阵运算
- 将 离散特征值 扩展到 欧式空间,离散特征的某个取值 就 对应欧式空间的某个点,根据欧式空间距离计算相似度
分类特征转换为数值型索引:对于一些分类比较多的特征并且值为字符串型数据,可以将特征分类转化成数值型索引
from sklearn.preprocessing import OrdinalEncoder
# 拆分数值特征和字符串特征
str_or_num = (df.dtypes=='object') # 返回值: 列名1 True/False 列名2 True/False ......
str_cols = str_or_num[str_or_num == True].index # 获取字符串特征列名
string_data = df[str_cols]
num_data = df[[i for i in str_or_num.index if i not in str_cols]]
# 分类特征转换为数值型索引
model_oe = OrdinalEncoder()
string_data_con = model_oe.fit_transform(string_data)
string_data_pd = pd.DataFrame(string_data_con,columns=string_data.columns)
# 合并原数值型特征和onehotencode后的特征
feature_merge = pd.concat((num_data,string_data_pd),axis=1)
代码实现
-
pandas 实现数据离散化 data必须是一维数组 series 1. 等频离散化:离散结果series = pd.qcut(data, q) 每个区间样本数一致 2. 自定义区间离散:离散结果series = pd.cut(data, bins=自定义区间列表) 3. 使用聚类算法离散 统计每组的个数:离散结果series.value_counts():统计分组次数 one-hot 编码 主要在分类算法的数据处理 上应用 pandas.get_dummies(data, prefix=分组名字),只会对非数值类型的数据做转换 data 参数:可包含多列 可用数据类型 array-like、Series、DataFrame
-
sklearn实现-
连续数值的 二极化
from sklearn import preprocessing # 此处是根据该列的平均数作为阈值,小于为0;大于为1 binarizer_scaler = preprocessing.Binarizer(threshold=df['income'].mean()) # 建立Binarizer模型对象 income_tmp = binarizer_scaler.fit_transform(df[['income']]) # Binarizer标准化转换 income_tmp.resize(df['income'].shape) # 转换数据形状 df['income'] = income_tmp # Binarizer标准化转换 -
将
list;np.array;pd.Series一维数据进行one-hot 编码from sklearn.preprocessing import LabelBinarizer # 导包 # 列表数据(list;np.array;pd.Series)不能是二维数组 data = ['动作片', '喜剧片', '爱情片', '科幻片'] data = np.array(data) data = pd.Series(data) transfer = LabelBinarizer() data = transfer.fit_transform(data) data = pd.DataFrame(data,columns=transfer.classes_) print(data) 动作片 喜剧片 爱情片 科幻片 0 0 0 1 0 1 0 0 0 1 2 1 0 0 0 3 0 1 0 0 -
将字典数据进行
one-hot 编码(可以将pd.DataFrom.to_dict转化成字典)from sklearn.feature_extraction import DictVectorizer # 导包 # 字典数据 data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}] data = DataFrom 数组名.to_dict(orient="records")) # orient 表示转化成字典的样式 # 1、实例化一个转换器类 若 sparse=True 则表示生成稀疏矩阵, 对象.toarray() 将sparse矩阵转换为正常矩阵 transfer = DictVectorizer(sparse=False) # 2、调用fit_transform data = transfer.fit_transform(data) # 打印转化后的 one-hot 编码矩阵 print("返回的结果:\n", data) # 打印特征名字 print("特征名字:\n", transfer.get_feature_names()) 返回的结果: [[ 0. 1. 0. 100.] [ 1. 0. 0. 60.] [ 0. 0. 1. 30.]] 特征名字: ['city=上海', 'city=北京', 'city=深圳', 'temperature'] -
将 数组数据
pd.DataFrame进行one-hot 编码from sklearn.preprocessing import OneHotEncoder # 导包 # 构造数据 data = [['有房',40,50000], ['无房',22,13000], ['有房',30,30000]] data = pd.DataFrame(data,columns=['house','age','income']) # 进行one-hot编码 enc = OneHotEncoder() tempdata = enc.fit_transform(data).toarray() # 获取特征名字 columns1 = enc.get_feature_names(['house','age','income']) # 将 one-hot 矩阵 转换成 DataFrom tempdata = pd.DataFrame(tempdata,columns=list(columns1))
-
-
spark实现(三步才能实现)StringIndexer:对指定字符串列数据进行特征处理(将其转化成:1、2、3、4 … )OneHotEncoder:对特征列数据进行热编码(常需结合StringIndexer使用)Pipeline:让数据按顺序依次处理,将前一次的处理结果作为下一次的输入
from pyspark.ml.feature import OneHotEncoder StringIndexer
from pyspark.ml import Pipeline
# StringIndexer对指定字符串列进行特征处理
stringindexer = StringIndexer(inputCol='pid', outputCol='pid_feature')
# 对处理出来的特征处理列进行,one-hot 编码
encoder = OneHotEncoder(dropLast=False, inputCol='pid_feature', outputCol='pid_value')
# 创建管道并设定处理顺序,上一个处理的结果作为下一个的处理的输入
pipeline = Pipeline(stages=[stringindexer, encoder])
# 利用管道训练数据集
pipeline_model = pipeline.fit(raw_sample_df)
new_df = pipeline_model.transform(raw_sample_df)
new_df.show() # 处理完的数据集会新增 pid_feature 和 pid_value 两列,其中pid_value为稀疏矩阵,可用 .toArray() 转化为正常矩阵显示
文本特征提取 和 jieba分词
sklearn
import jieba # 导入 jieba 分词
import collections # 词频统计库
string_data = "我爱北京,北京"
seg_list_exact = jieba.cut(string_data, cut_all=False) # jieba.cut() 将中文进行精确模式分词
# Counter({'我': 1, '爱': 1, '北京': 2, ',': 1})
word_counts = collections.Counter(seg_list_exact ) # 对分词做词频统计
# [('北京', 2), ('我', 1), ('爱', 1), (',', 1)]
word_counts_top5 = word_counts.most_common(5) # 获取前10个频率最高的词
# 可以获取分词 词性
import jieba.posseg as pseg
words = pseg.cut(string_data) # 分词,返回值为慈和词性,不会对词进行统计
words_pd = pd.DataFrame(words, columns=['词', '词性']) # 创建结果数据框
# 词性分类汇总-两列分类
words_gb = words_pd.groupby(['词性', '词'])['词'].count()
# 词性 词
# ns 北京 2
# r 我 1
# v 爱 1
# x , 1
# 选择特定类型词语做展示
words_pd_index = words_pd['词性'].isin(['ns', 'eng'])
# 关键字提取
import jieba.analyse # 导入关键字提取库
tags_pairs = jieba.analyse.extract_tags(string_data, topK=5, withWeight=True, allowPOS=['ns', 'n', 'vn', 'v', 'nr'], withFlag=True) # 提取关键字标签
tags_list = [(i[0].word, i[0].flag, i[1]) for i in tags_pairs] #
tags_pd = pd.DataFrame(tags_list, columns=['word', 'flag', 'weight']) # 创建数据框
# word flag weight
# 0 北京 ns 4.667402
# 文本提取API:
sklearn.feature_extraction.text.CountVectorizer(stop_words=['停用词列表'])
训练数据:CountVectorizer.fit_transform(X) # 参数X:文本或者包含文本字符串的可迭代对象
返回值:返回 one-hot 的 sparse矩阵
注意没有sparse参数
对象.toarray() 将sparse矩阵转换为正常矩阵
[1, 0, 0]
[0, 1, 0]
[0, 0, 2]
属性:CountVectorizer.get_feature_names() :单词列表
['我', '爱', '北京']
Tfidf
主要思想:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
公式: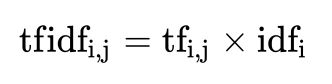
tf词频:某一个给定的词语在该文件中出现的频率idf逆向文档频率:一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
sklearn
sklearn.feature_extraction.text.TfidfVectorizer()
# 1、实例化转换器类
transfer = TfidfVectorizer(stop_words=['停用词(不用于统计的无意义的词)'])
# 2、调用fit_transform
data = transfer.fit_transform(text_list) # 若text_list中包含 中文,则需要使用jieba.cut()进行分词
print("文本特征抽取的结果:\n", data.toarray()) # 默认输出 one-hot 的系数矩阵
print("返回特征名字:\n", transfer.get_feature_names())
特征预处理
作用:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
意义:将特征值无量纲化,即将所有的特征值映射到同一范围(一般为0-1之间)内,使不同规格的数据转换到同一规格。避免因 特征的 单位、大小 或 方差 相差几个数量级,从而 影响或支配学习结果,使得算法无法学习到其它的特征
归一化 和 标准化
归一化作用:通过对原始数据进行变换把数据映射到(默认为[0,1])之间,将不同特征数据无量纲化,使不同规格的数据转换到同一规格
公式:作用于每一列

max为一列的最大值min为一列的最小值mx和mi分别为指定区间的上限和下限,默认:mx为1,mi为0

sklearn代码实现:
- 实例化API:
对象名 = sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
feature_range表示将数据处理到的指定区间,默认(0,1) - 归一化数据集:
对象名.fit_transform(X)
参数X:需要归一化的数据集(numpy array格式数据)data['milage','Liters','Consumtime']
返回值:转换后的形状相同的array数据集
归一化的缺陷:因为最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景
归一化进阶版:标准化
规避掉了异常值的影响,适合现代嘈杂大数据场景
注意:标准化是一种中心化方法,会改变原有数据的分布结构,不适合对稀疏数据做处理

mean为平均值,σ为标准差
sklearn代码实现:
- 实例化API:
对象名 = sklearn.preprocessing.StandardScaler () - 标准化数据集:
对象名.fit_transform(X)
参数X:需要归一化的数据集(numpy array格式数据)data['milage','Liters','Consumtime']
返回值:转换后的形状相同的array数据集
数据标准化后存在的方法:
对象名.mean_:获取每一列特征的平均值
对象名.var_:获取每一列特征的方差
spark代码实现:
- 实例化API:
对象名 = pyspark.ml.feature.StandardScaler()
参数:withMean = False:withStd = True:inputCol = None:outputCol = None:
特征衍生
- 数值型特征
- 统计个数:
pd.DataFrame(df.groupby('uid').apply(lambda df:len(df[i])).reset_index()) - 统计大于0的个数:
pd.DataFrame(df.groupby('uid').apply(lambda df:np.where(df[i]>0,1,0).sum()).reset_index()) - 统计累计和:
pd.DataFrame(df.groupby('uid').apply(lambda df:np.nansum(df[i])).reset_index()) - 统计均值:
nanmean;统计最大值:nanmax;最小值:nanmin;统计方差:nanvar;统计极差:nanmax-nanmin
- 统计个数:
- 文本型特征(一般是统计个数处理)
- 时间型特征(统计多长时间内某事件的次数)
特征降维
原因:在训练模型时,是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
作用:在不损失或少量损失信息实现 特征个数(维度)减少的过程
指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程

特征选择(Filter)
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联- 方差选择法:低方差特征过滤
- 相关系数
Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
低方差特征过滤
删除 低方差 的一些特征
特征方差小:某个特征大多样本的值比较相近
特征方差大:某个特征很多样本的值都有差别
sklearn实现:
-
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
初始化VarianceThreshold,指定阀值方差 -
Variance.fit_transform(X)调用fit_transform
参数X:数据集(numpy array格式)[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。threshold默认值为0,即删除所有样本中具有相同值的特征。
相关系数
皮尔逊相关系数
反映变量之间相关关系密切程度的统计指标

相关系数的值介于 –1 与 +1 之间,其性质如下:
- 当
r>0时,表示两变量正相关,r<0时,两变量为负相关 - 当
|r|=1时,表示两变量为完全相关 - 当
r=0时,表示两变量间无相关关系 - 当
0<|r|<1时,表示两变量存在一定程度的相关。
且|r|越接近1,两变量间线性关系越密切
一般可按三级划分:
|r|<0.4为低度相关0.4≤|r|<0.7为显著性相关0.7≤|r|<1为高度线性相关
Pandas API:
df.corr() # 获取各个特征之间的相关系数
# 获取最相关的特征排序
df.corr([['目标值']].sort_values('目标值',ascending=False)
scipy API:
from scipy.stats import pearsonr
pearsonr(x, y)
参数:
x : (N,) 第一特征列数据
y : (N,) 第二特征类数据
返回值: (两个特征之间的皮尔逊相关系数,p-value)
斯皮尔曼相关系数(Rank IC)
反映变量之间相关关系密切程度的统计指标
斯皮尔曼相关系数表明 X (自变量) 和 Y (因变量)的相关方向
如果当X增加时, Y 趋向于增加, 斯皮尔曼相关系数则为正
与之前的皮尔逊相关系数大小性质一样,取值 [-1, 1]之间
斯皮尔曼相关系数比皮尔逊相关系数应用更加广泛
scipy API:
from scipy.stats import spearmanr
x1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9] # 第一特征列数据
x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5] # 第二特征列数据
spearmanr(x1, x2)
结果
SpearmanrResult(correlation=0.9999999999999999, pvalue=6.646897422032013e-64)
嵌入式(Embedded)
根据逻辑回归或XGBoost获取的特征权重,获取最重要的几个特征
基于L1的特征选择
通过L1正则项,将不重要的特征权重置于0,可以通过 feature_selection.SelectFromModel来选择权重不为0的特征
- 分类:
svm.LinearSVC()from sklearn.feature_selection import SelectFromModel from sklearn.svm import LinearSVC lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X,y) model = SelectFromModel(lsvc, prefit=True) X_embed = model.transform(X) X_embed.shape - 回归:
linear_model.Lasso()linear_model.LogisticRegression()
基于lightgbm/XGBoost 的特征选择
lightgbm和XGBoost一样,都是 Boosting集成思想 + 二阶泰勒展开 + 决策树模型 +正则项
import lightgbm as lgb
def lgb_test(train_x,train_y,test_x,test_y):
clf =lgb.LGBMClassifier(boosting_type = 'gbdt',
objective = 'binary',
metric = 'auc',
learning_rate = 0.1,
n_estimators = 24,
max_depth = 5,
num_leaves = 20,
max_bin = 45,
min_data_in_leaf = 6,
bagging_fraction = 0.6,
bagging_freq = 0,
feature_fraction = 0.8,
)
clf.fit(train_x,train_y,eval_set = [(train_x,train_y),(test_x,test_y)],eval_metric = 'auc')
return clf,clf.best_score_['valid_1']['auc'],
lgb_model , lgb_auc = lgb_test(train_x,train_y,test_x,test_y)
feature_importance = pd.DataFrame({'name':lgb_model.booster_.feature_name(),
'importance':lgb_model.feature_importances_})
.sort_values(by=['importance'],ascending=False)
import xgboost as xgb
xgb_model = xgb.XGBClassifier().fit(X,y)
feature_importances = xgb_model.feature_importances_
indices = np.argsort(feature_importances)[::-1]
for index in indices:
print("特征 %s 重要度为 %f" %(feature_names[index], feature_importances[index]))
主成分分析(PCA)
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
sklearn API:
sklearn.decomposition.PCA(n_components=None) # 将数据分解为较低维数空间
参数:
n_components:
小数:表示保留百分之多少的信息
整数:减少到多少特征
PCA.fit_transform(X)
参数:
X:整个特征数据,numpy array格式的数据 [n_samples,n_features]
返回值:转换后指定维度的array
四 模型训练(算法)
- 实例化算法API
estimator = 算法API函数 - 执行训练
estimator.fit(训练集的特征值, 测试集的特征值)
早停参数:,early_stopping_rounds=10, eval_metric="auc", eval_set=[(X_val, y_val) - 预测结果
estimator.predict(测试数据的特征值)预测结果
算法分类(根据数据集种类)
经典算法 及 其API(另一篇博客)
-
监督学习
输入数据是由输入特征值和目标值所组成,其有分为回归于分类两种-
回归(目标值为连续型,函数的输出可以是一个连续的值)
线性回归(岭回归):根据自变量(特征)和因变量(目标值)之间的关系 进行建模- 应用场景
- 预测目标值(预测销量,价格)
- 分析特征的重要性(判断哪个渠道更有效,更值得投入和各渠道投入比例)
- 注意事项:
- 自变量和因变量之间必须有相关性
- 自变量之间不能存在共线性
- 必须处理空值,需要标准化
- 应用场景
-
分类(目标值为离散型,或是输出是有限个离散值)
通过对已知类别训练集的计算和分析,从中发现类别规则并预测新数据的类别- 常用的分类算法:
- KNN:几乎不用
- 朴素贝叶斯: 仅用于文本分类
- 逻辑回归 :用于二分类(会不会逾期、点击、流失),具有不错的解释性(可知预测结果的概率信息)
- 决策树/随机森林:可获取 明确的规则,指导业务,可执行性极强
- XGBoost/lightgbm:分类效果极佳,但可解释性较差
- 分类算法事项:正负样本均衡问题
- 使用场景:
- 提炼规则(决策树/随机森林)
- 提取特征(XGBoost/lightgbm)
- 处理缺失值
- 常用的分类算法:
-
-
无监督学习(仅有特征值而没有目标值)
聚类:将大量数据集中具有“相似”特征的数据点或样本划分为同一类别(根据不同的特征聚类,产生的聚类结果不同)- 常用于数据探索或挖掘前期,在没有做先验经验的背景下做的探索性分析
- 应用场景(用户分群)
- 针对企业整体的用户特征,在未得到相关知识或经验之前,先根据数据本身特点进行用户分群,然后针对不同群体做进一步分析
- 客户分群的数据维度:
- 消费者行为习惯数据
- 消费者对产品的态度
- 消费者自身的人口统计学特征
- 顾客消费行为的度量(
RFM)等数据
- 聚类分析能解决的问题:
- 数据集可以分为几类
- 每个类别有多少样本量
- 不同类别中各个变量的强弱关系
- 不同类别的典型特征是什么
- 客户分群的目的:
- 可以为不同客群提供定制化的产品或者服务
- 设定品牌的主要形象和定位
- 根据顾客需求,挖掘新的产品和服务机会
- 聚类需要具有的效果:
- 聚类后的用户分群有明显特征(高富帅 矮穷矬)
- 聚类之后的用户分群有足够数量的用户
- 分群之后的用户是否能触达(有联系方式)
- 经聚类方法后需要对分群结果进行业务解读,通过业务合理性来选择分群的数量
-
半监督学习
训练集同时包含有标记样本数据和未标记样本数据- 强化学习
定义:实质是make decisions问题,即自动进行决策,并且可以做连续决策。
五个元素:agent,action,reward,environment,observation;
目标:获得最多的累计奖励
举例:
小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
小孩就是agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
- 强化学习
区别
| 算法分类 | 输入的数据 | 输出 | 目的 | 案例 |
|---|---|---|---|---|
监督学习 (supervised learning) |
有标签 | 有反馈 | 预测结果 | 猫狗分类 房价预测 |
无监督学习 (unsupervised learning) |
无标签 | 无反馈 | 发现潜在结构 | “物以类聚,人以群分” |
半监督学习 (Semi-Supervised Learning) |
部分有标签,部分无标签 | 有反馈 | 降低数据标记的难度 | |
强化学习 (reinforcement learning) |
决策流程及激励系统 | 一系列行动 | 长期利益最大化 | 学下棋 |
五 模型评估
作用:于发现表达数据的最佳模型和所选模型将来工作的性能如何。
评估方式:二元分类使用AUC.多元分类使用accuracy、回归分析使用RMSE
拟合和欠拟合(评估结果效果)
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
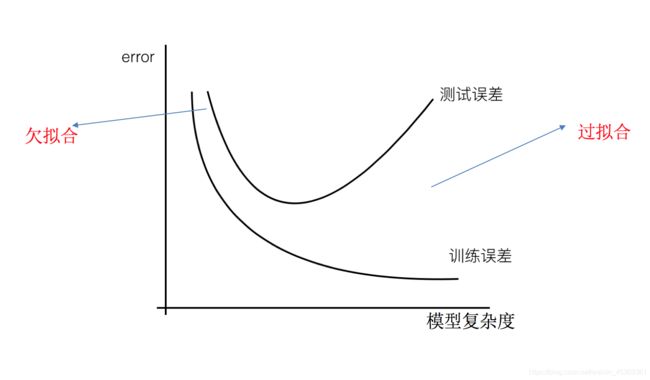
- 近似误差:
- 对现有训练集的训练误差,关注训练集,
- 如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测,模型本身不是最接近最佳模型。
- 估计误差:
- 对测试集的测试误差,关注测试集,
- 估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型
欠拟合
欠拟合(under-fitting):模型学习的太过粗糙(在训练数集和测试集上皆没有很好的拟合数据),没有学习到数据的特征,在训练集和测试集评估效果均不好
欠拟合原因以及解决办法
- 原因:学习到数据的特征过少
- 解决办法:
- 添加其他特征项,有时候我们模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段,无论在什么场景,除此之外,“上下文特征”、“平台特征”等等,都可以作为特征添加的首选项。
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
过拟合
过拟合(over-fitting):模型过于复杂(模型尝试去兼顾各个测试数据点),设置特征过多,所建的模型过于拟合训练样本数据,导致在测试数据集中表现不佳
过拟合原因以及解决办法
- 原因:原始特征过多,存在嘈杂特征
- 解决办法:
- 重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
- 增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
- 减少特征维度,防止维灾难,删除、合并一些特征
- 正则化:算法在学习的时候尽量减少 影响模型复杂度或者异常点较多 的特征
分类模型评估
混淆矩阵:在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)

准确率
准确率:预测正确的数占样本总数的比例((TP+TN)/(TP+TN+FN+FP))表示预测的对不对
sklearn API:模型.score(x_test, y_test)
精确率、召回率、F1-score
用于:不关注预测的准确率,而是关注在所有的样本当中 某分类(确诊癌症) 有没有被全部预测出来
精确率:预测结果为正例样本中真实为正例的比例(TP/(TP+FP))表示预测的准不准

召回率:真实为正例的样本中预测结果为正例的比例(TP/(TP+FN))标是查的全不全

F1-score,反映了模型的稳健性

sklearn
分类评估报告API:sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
参数:
y_true:真实目标值y_pred:估计器预测的目标值labels:指定目标值类别对应的数字target_names:为目标值类别起别名用于人性化现实
返回值:每个类别的 精确率、召回率、F1-score

混淆矩阵API:sklearn.metrics.confusion_matrix(y_true, y_pred)
AUC指标(ROC线下面积)
作用:适合样本不均衡情况,比较哪个模型更好
ROC曲线
横坐标:FPR = FP / (FP + TN)所有真实类别为0的样本中,预测类别为1的比例
纵坐标:TPR = TP / (TP + FN) 所有真实类别为1的样本中,预测类别为1的比例

(0,0)表示:全预测为假(1,1)表示:前预测为真
AUC指标 和 KS值
计算ROC线下面积,即AUC值
AUC的概率意义是随机取一对正负样本,正样本得分大于负样本得分的概率AUC的范围在[0, 1]之间,并且越接近1越好,越接近0.5属于乱猜AUC=1:完美分类器,绝大多数预测的场合,不存在完美分类器。0.5
TPR - FPR的最大值,即KS值(主要用于风控模型)
0.4>KS>0.2勉强可用0.6>KS>0.4一般KS > 0.7较好- KS值越高越好
AUC计算API
sklearn
导入模块:from sklearn.metrics import roc_auc_score
计算API:roc_auc_score(y_true, y_score)
y_true:每个样本的真实类别,必须为0(反例),1(正例)标记y_score:预测得分,可以是正类的估计概率、置信值 或者 分类器方法的预测值(y_pred)
# 方法二
from sklearn.metrics import roc_curve,auc
fpr,tpr,threshold=roc_curve(y_train,y_pred_train)
roc_auc=auc(fpr,tpr)
roc_ks=abs(fpr-tpr).max()
AUC只能用来评价二分类,非常适合评价样本不平衡中的分类器性能
回归模型评估
均方误差(Mean Squared Error)
MSE是一个衡量回归模型误差率的常用公式。 不过,它仅能比较误差是相同单位的模型。
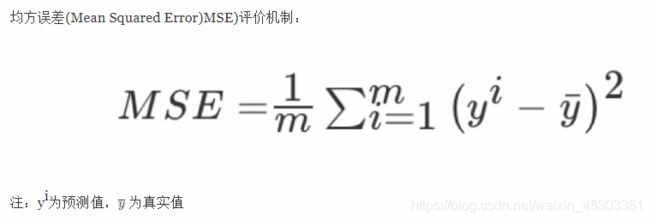
代码实现:
Pandas 直接计算:
predictions=model模型.predict(x) # 根据模型获取y预测值
error=predictions-y # 计算误差
mse=(error**2).mean() # 计算 mse
rse=(error**2).mean()**.5 # 计算 rse
mae=abs(error).mean() # 计算 mae
sklearn API:sklearn.metrics.mean_squared_error(y_true, y_pred)
y_true:真实值y_pred:预测值return返回值:浮点数均方根结果
其他评价指标:
- 相对平方误差(
Relative Squared Error,RSE) - 平均绝对误差(
mean_absolute_error,MAE) - 相对绝对误差(
Relative Absolute Error,RAE)
决定系数(Coefficient of Determination)
R2:目标的变化由特征引起的比例
![]()
只要R2达到0.5-0.6就已经很好了
此外,从理论上来说,只要增加特征的个数,R2的值是一直增加的,不管这个特征x和目标y是否有关。
因此,R2通常用于特征选择。如果增加一个特征,模型的R2值上升很多,那就说明这个特征和目标有关。
adjusted R2:与R2类似,不过增加了惩罚项,因此adjusted R2一定小于等于R2。
如果新增的特征没有带来任何有用的信息,那么adjusted R2会变小,只有在新增的特征带来足够多的信息(足够抵消惩罚项)时,adjusted R2才会增加。其缺点是无法像R2一样对模型进行解释

如果以R2为评价指标,容易让模型出现过拟合现象,因此建议用adjusted R-squared来选择模型,用R2来解释模型
六 模型的保存和加载
sklearn
导包:from sklearn.externals import joblib- 保存:
joblib.dump(训练好的模型, '路径/模型名.pkl') - 加载:
estimator = joblib.load('路径/模型名.pkl')需要变量承接
- 保存: