bp神经网络参数怎么设置,神经网络调参训练技巧
神经网络算法中,参数的设置或者调整,有什么方法可以采用
若果对你有帮助,请点赞。神经网络的结构(例如2输入3隐节点1输出)建好后,一般就要求神经网络里的权值和阈值。
现在一般求解权值和阈值,都是采用梯度下降之类的搜索算法(梯度下降法、牛顿法、列文伯格-马跨特法、狗腿法等等),这些算法会先初始化一个解,在这个解的基础上,确定一个搜索方向和一个移动步长(各种法算确定方向和步长的方法不同,也就使各种算法适用于解决不同的问题),使初始解根据这个方向和步长移动后,能使目标函数的输出(在神经网络中就是预测误差)下降。
然后将它更新为新的解,再继续寻找下一步的移动方向的步长,这样不断的迭代下去,目标函数(神经网络中的预测误差)也不断下降,最终就能找到一个解,使得目标函数(预测误差)比较小。
而在寻解过程中,步长太大,就会搜索得不仔细,可能跨过了优秀的解,而步长太小,又会使寻解过程进行得太慢。因此,步长设置适当非常重要。
学习率对原步长(在梯度下降法中就是梯度的长度)作调整,如果学习率lr=0.1,那么梯度下降法中每次调整的步长就是0.1*梯度,而在matlab神经网络工具箱里的lr,代表的是初始学习率。
因为matlab工具箱为了在寻解不同阶段更智能的选择合适的步长,使用的是可变学习率,它会根据上一次解的调整对目标函数带来的效果来对学习率作调整,再根据学习率决定步长。
机制如下:ifnewE2/E2>maxE_inc%若果误差上升大于阈值lr=lr*lr_dec;%则降低学习率elseifnewE2
祝学习愉快。
谷歌人工智能写作项目:小发猫

神经网络weight参数怎么初始化
不一定,也可设置为[-1,1]之间AI爱发猫。事实上,必须要有权值为负数,不然只有激活神经元,没有抑制的也不行。至于为什么在[-1,1]之间就足够了,这是因为归一化和Sigmoid函数输出区间限制这两个原因。
一般在编程时,设置一个矩阵为bounds=ones(S,1)*[-1,1];%权值上下界。在MATLAB中,可以直接使用net=init(net);来初始化。
我们可以通过设定网络参数net.initFcn和net.layer{i}.initFcn这一技巧来初始化一个给定的网络。net.initFcn用来决定整个网络的初始化函数。
前馈网络的缺省值为initlay,它允许每一层用单独的初始化函数。设定了net.initFcn,那么参数net.layer{i}.initFcn也要设定用来决定每一层的初始化函数。
对前馈网络来说,有两种不同的初始化方式经常被用到:initwb和initnw。
initwb函数根据每一层自己的初始化参数(net.inputWeights{i,j}.initFcn)初始化权重矩阵和偏置。前馈网络的初始化权重通常设为rands,它使权重在-1到1之间随机取值。
这种方式经常用在转换函数是线性函数时。initnw通常用于转换函数是曲线函数。
它根据Nguyen和Widrow[NgWi90]为层产生初始权重和偏置值,使得每层神经元的活动区域能大致平坦的分布在输入空间。
怎么选取训练神经网络时的Batch size?
选取训练神经网络时先选好batchsize,再调其他的超参数。并且实践上来说,就两个原则——batchsize别太小,也别太大,其他都行。
因为合适的batchsize范围和训练数据规模、神经网络层数、单元数都没有显著的关系。合适的batchsize范围主要和收敛速度、随机梯度噪音有关。为什么batchsize别太小。
别太小的限制在于,batchsize太小,会来不及收敛。所以batchsize下限主要受收敛的影响。所以在常见的setting(~100epochs),batchsize一般不会低于16。
如果你要选更小的batchsize,你需要给自己找到很好的理由。为什么batchsize别太大:batchsize别太大的限制在于两个点。1、batchsize太大,memory容易不够用。
这个很显然,就不多说了。2、batchsize太大,深度学习的优化trainingloss降不下去和泛化generalizationgap都会出问题。
随机梯度噪音的magnitude在深度学习的continuous-timedynamics里是正比于learningrate/batchsize。batchsize太大,噪音就太小了。
而大家已经知道,随机梯度噪音对于逃离saddlepoints [2]和sharpminima[3]都必不可少的作用。前者可以解释为什么优化出问题,后者则可以解释为什么泛化出问题。
SPSS的神经网络模型参数设置疑问
卷积神经网络是如何反向调整参数的?
神经网络的隐含层节点数怎么设置啊?比如要设置18层隐含节点数!跪求,工作急用!
隐层一般是一层或两层,很少会采用三层以上,至少隐层的节点数确定,一般有以下几种方法:1、有经验的人员根据以往的经验凑试出节点个数。
2、某些学术研究出固定的求节点方法,如2m+1个隐层节点,m为输入个数。3、修剪法。刚开始建立足够多的节点数,在训练过程中,根据节点数的相关程度,删除重复的节点。
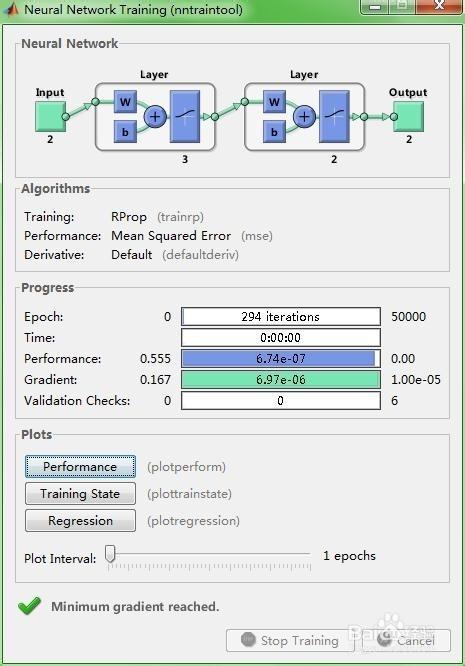
神经网络gradient怎么设置
梯度是计算得来的,不是“设置”的。传统的神经网络通过前向、后向两步运算进行训练。其中最关键的就是BP算法,它是网络训练的根本方式。
在运行BP的过程中,你需要先根据定义好的“代价函数”分别对每一层的参数(一般是W和b)求偏导(也就是你说的gradient),用该偏导数在每一次迭代中更新对应的W和b,直至算法收敛。
具体实现思路和细节可以参考: