理解“生成高斯随机测量矩阵”段代码;奇异值分解(SVD)的理解
#生成高斯随机测量矩阵
sampleRate=0.7 #采样率
Phi=np.random.randn(256,256)
u, s, vh = np.linalg.svd(Phi)
Phi = u[:256*sampleRate,] #将测量矩阵正交化这段代码让我产生了如下疑问:
1.采样率的作用是什么?怎么使用的?
2.为何奇异值分解的各参数服从高斯分布?
(到了最后也没有解决,不过我也不关心这个问题了)
3.奇异值分解出的s为何没有在重建过程中使用?
# s对角阵;奇异值分解——非非方阵求特征向量;u[M,M]、s(因只有对角线元素,是一维向量)、vh[N,N]
Phi=np.random.randn(256,256)
u, s, vh = np.linalg.svd(Phi)
Phi = orth(u)# #将测量矩阵正交化因为不理解求测量矩阵求的好好的,为什么不直接对生成的高斯矩阵Phi正交化,而要对奇异值分解后的u正交化,所以,
首先验证了一下分解之后是否也符合正态分布(0,1/256)
1、np.mean(Phi) = -0.00017111176740819786
np.var(Phi) = 0.0039062207207630545
2、np.mean(u) = 0.0001780504308824002
np.var(u) = 0.003906218298044062
3、np.mean(vh) = -7.129320284399146e-05
np.var(vh) = 0.003906244917279228
# 1/256 = 0.00390625
结果很有意思 ==> 分解出的u, vh均符合正太分布(意思就是说,可以用作高斯测量矩阵)
略微怀疑了一下 u ?= v-1 验证了一下,明显不是
>>> #a1=np.mat(u)
>>> a1.I #u的逆
matrix([[-4.55884095e-02, 5.01492239e-02, -5.37609946e-02, ...,
7.25312963e-05, -7.17153014e-02, 8.61231127e-02],
[ 3.14760438e-02, 8.56614350e-03, 1.23950561e-01, ...,
-2.85124678e-02, 5.13144366e-02, -5.08340339e-03],
[ 7.18833262e-03, -5.02030288e-02, -1.48515675e-03, ...,
-4.26118590e-02, -8.96434310e-02, -6.31311900e-02],
...,
[ 5.24490210e-02, 7.30977342e-02, -1.57502857e-02, ...,
-4.77213973e-02, 1.38245059e-02, -2.21201867e-02],
[-8.48229098e-03, 6.69047256e-03, -4.33598024e-02, ...,
-2.53218586e-02, 7.85389472e-02, 9.52016682e-02],
[ 6.90270319e-02, 4.69091488e-02, -1.73791108e-02, ...,
1.36255683e-01, 4.55514037e-02, 1.37026750e-02]])
>>> a1 #u
matrix([[-4.55884095e-02, 3.14760438e-02, 7.18833262e-03, ...,
5.24490210e-02, -8.48229098e-03, 6.90270319e-02],
[ 5.01492239e-02, 8.56614350e-03, -5.02030288e-02, ...,
7.30977342e-02, 6.69047256e-03, 4.69091488e-02],
[-5.37609946e-02, 1.23950561e-01, -1.48515675e-03, ...,
-1.57502857e-02, -4.33598024e-02, -1.73791108e-02],
...,
[ 7.25312963e-05, -2.85124678e-02, -4.26118590e-02, ...,
-4.77213973e-02, -2.53218586e-02, 1.36255683e-01],
[-7.17153014e-02, 5.13144366e-02, -8.96434310e-02, ...,
1.38245059e-02, 7.85389472e-02, 4.55514037e-02],
[ 8.61231127e-02, -5.08340339e-03, -6.31311900e-02, ...,
-2.21201867e-02, 9.52016682e-02, 1.37026750e-02]])
再看了看奇异值分解(SVD)的概念
(1)特征值

Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值
假如说矩阵是下面的样子:

它所描述的变换是下面的样子:

总结:特征值分解可以得到特征值与特征向量
特征值表示的是这个特征到底有多重要;特征向量表示这个特征是什么
可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。
(2)奇异值
SVD将数据分解成三个矩阵U,S,VT,这里得到的S是一个对角阵,其中对角元素为奇异值,它代表着矩阵的重要特征,从左上角到右下角重要程度递减。因为奇异值往往对应着矩阵中隐含的重要信息,而且奇异值大小与重要性正相关。
优点:简化数据,优化数据的表达形式。
缺点:难于计算。
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的
奇异值分解是一个能适用于任意的矩阵的一种分解的方法:

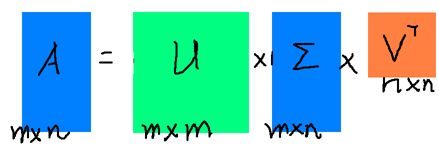
在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了

到这里我认为,
奇异值分解对于所需理解代码的作用是——保证方形矩阵(图片可能是长方形)
奇异值分解最精华的部分就是中间的s(Σ)——这是本文压根就没有用到的地方Σ( ° △ °|||)︴