前端开发面试题自测
哪些情况会导致内存泄漏
1、意外的全局变量:由于使用未声明的变量,而意外的创建了一个全局变量,而使这个变量一直留在内存中无法被回收
2、被遗忘的计时器或回调函数:设置了 setInterval 定时器,而忘记取消它,如果循环函数有对外部变量的引用的话,那么这个变量会被一直留在内存中,而无法被回收。
3、脱离 DOM 的引用:获取一个 DOM 元素的引用,而后面这个元素被删除,由于一直保留了对这个元素的引用,所以它也无法被回收。
4、闭包:不合理的使用闭包,从而导致某些变量一直被留在内存当中。
什么是 DOM 和 BOM?
- DOM 指的是文档对象模型,它指的是把文档当做一个对象,这个对象主要定义了处理网页内容的方法和接口。
- BOM 指的是浏览器对象模型,它指的是把浏览器当做一个对象来对待,这个对象主要定义了与浏览器进行交互的法和接口。BOM的核心是 window,而 window 对象具有双重角色,它既是通过 js 访问浏览器窗口的一个接口,又是一个 Global(全局)对象。这意味着在网页中定义的任何对象,变量和函数,都作为全局对象的一个属性或者方法存在。window 对象含有 location 对象、navigator 对象、screen 对象等子对象,并且 DOM 的最根本的对象 document 对象也是 BOM 的 window 对象的子对象。
display的属性值及其作用
| 属性值 | 作用 |
|---|---|
| none | 元素不显示,并且会从文档流中移除。 |
| block | 块类型。默认宽度为父元素宽度,可设置宽高,换行显示。 |
| inline | 行内元素类型。默认宽度为内容宽度,不可设置宽高,同行显示。 |
| inline-block | 默认宽度为内容宽度,可以设置宽高,同行显示。 |
| list-item | 像块类型元素一样显示,并添加样式列表标记。 |
| table | 此元素会作为块级表格来显示。 |
| inherit | 规定应该从父元素继承display属性的值。 |
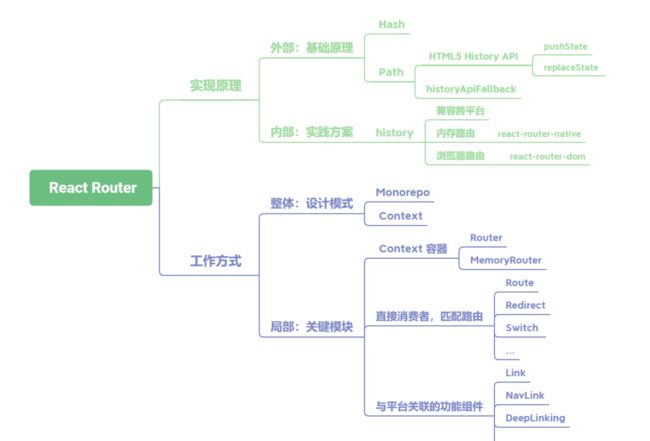
React-Router 的实现原理及工作方式分别是什么
React Router路由的基础实现原理分为两种,如果是切换 Hash的方式,那么依靠浏览器Hash变化即可;如果是切换网址中的Path,就要用到HTML5 History API中的pushState、replaceState等。在使用这个方式时,还需要在服务端完成historyApiFallback配置- 在
React Router内部主要依靠history库完成,这是由React Router自己封装的库,为了实现跨平台运行的特性,内部提供两套基础history,一套是直接使用浏览器的History API,用于支持react-router-dom;另一套是基于内存实现的版本,这是自己做的一个数组,用于支持react-router-native。 React Router的工作方式可以分为设计模式与关键模块两个部分。从设计模式的角度出发,在架构上通过Monorepo进行库的管理。Monorepo具有团队间透明、迭代便利的优点。其次在整体的数据通信上使用了 Context API 完成上下文传递。- 在关键模块上,主要分为三类组件:
第一类是 Context 容器,比如 Router 与 MemoryRouter;第二类是消费者组件,用以匹配路由,主要有 Route、Redirect、Switch 等;第三类是与平台关联的功能组件,比如Link、NavLink、DeepLinking等。

参考:前端进阶面试题详细解答
对盒模型的理解
CSS3中的盒模型有以下两种:标准盒子模型、IE盒子模型 盒模型都是由四个部分组成的,分别是margin、border、padding和content。
标准盒模型和IE盒模型的区别在于设置width和height时,所对应的范围不同:
- 标准盒模型的width和height属性的范围只包含了content,
- IE盒模型的width和height属性的范围包含了border、padding和content。
可以通过修改元素的box-sizing属性来改变元素的盒模型:
box-sizeing: content-box表示标准盒模型(默认值)box-sizeing: border-box表示IE盒模型(怪异盒模型)
什么是物理像素,逻辑像素和像素密度,为什么在移动端开发时需要用到@3x, @2x这种图片?
以 iPhone XS 为例,当写 CSS 代码时,针对于单位 px,其宽度为 414px & 896px,也就是说当赋予一个 DIV元素宽度为 414px,这个 DIV 就会填满手机的宽度;
而如果有一把尺子来实际测量这部手机的物理像素,实际为 1242*2688 物理像素;经过计算可知,1242/414=3,也就是说,在单边上,一个逻辑像素=3个物理像素,就说这个屏幕的像素密度为 3,也就是常说的 3 倍屏。
对于图片来说,为了保证其不失真,1 个图片像素至少要对应一个物理像素,假如原始图片是 500300 像素,那么在 3 倍屏上就要放一个 1500900 像素的图片才能保证 1 个物理像素至少对应一个图片像素,才能不失真。 当然,也可以针对所有屏幕,都只提供最高清图片。虽然低密度屏幕用不到那么多图片像素,而且会因为下载多余的像素造成带宽浪费和下载延迟,但从结果上说能保证图片在所有屏幕上都不会失真。
还可以使用 CSS 媒体查询来判断不同的像素密度,从而选择不同的图片:
my-image { background: (low.png); }
@media only screen and (min-device-pixel-ratio: 1.5) {
#my-image { background: (high.png); }
}
隐藏元素的方法有哪些
- display: none:渲染树不会包含该渲染对象,因此该元素不会在页面中占据位置,也不会响应绑定的监听事件。
- visibility: hidden:元素在页面中仍占据空间,但是不会响应绑定的监听事件。
- opacity: 0:将元素的透明度设置为 0,以此来实现元素的隐藏。元素在页面中仍然占据空间,并且能够响应元素绑定的监听事件。
- position: absolute:通过使用绝对定位将元素移除可视区域内,以此来实现元素的隐藏。
- z-index: 负值:来使其他元素遮盖住该元素,以此来实现隐藏。
- clip/clip-path :使用元素裁剪的方法来实现元素的隐藏,这种方法下,元素仍在页面中占据位置,但是不会响应绑定的监听事件。
- transform: scale(0,0):将元素缩放为 0,来实现元素的隐藏。这种方法下,元素仍在页面中占据位置,但是不会响应绑定的监听事件。
title与h1的区别、b与strong的区别、i与em的区别?
- strong标签有语义,是起到加重语气的效果,而b标签是没有的,b标签只是一个简单加粗标签。b标签之间的字符都设为粗体,strong标签加强字符的语气都是通过粗体来实现的,而搜索引擎更侧重strong标签。
- title属性没有明确意义只表示是个标题,H1则表示层次明确的标题,对页面信息的抓取有很大的影响
- i内容展示为斜体,em表示强调的文本
JavaScript有哪些数据类型,它们的区别?
JavaScript共有八种数据类型,分别是 Undefined、Null、Boolean、Number、String、Object、Symbol、BigInt。
其中 Symbol 和 BigInt 是ES6 中新增的数据类型:
- Symbol 代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题。
- BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。
这些数据可以分为原始数据类型和引用数据类型:
- 栈:原始数据类型(Undefined、Null、Boolean、Number、String)
- 堆:引用数据类型(对象、数组和函数)
两种类型的区别在于存储位置的不同:
- 原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储;
- 引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定。如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
堆和栈的概念存在于数据结构和操作系统内存中,在数据结构中:
- 在数据结构中,栈中数据的存取方式为先进后出。
- 堆是一个优先队列,是按优先级来进行排序的,优先级可以按照大小来规定。
在操作系统中,内存被分为栈区和堆区:
- 栈区内存由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆区内存一般由开发着分配释放,若开发者不释放,程序结束时可能由垃圾回收机制回收。
BFC
块级格式化上下文,是一个独立的渲染区域,让处于
BFC内部的元素与外部的元素相互隔离,使内外元素的定位不会相互影响。
IE下为
Layout,可通过zoom:1触发
触发条件:
- 根元素
position: absolute/fixeddisplay: inline-block / tablefloat元素ovevflow !== visible
规则:
- 属于同一个
BFC的两个相邻Box垂直排列 - 属于同一个
BFC的两个相邻Box的margin会发生重叠 BFC中子元素的margin box的左边, 与包含块 (BFC)border box的左边相接触 (子元素absolute除外)BFC的区域不会与float的元素区域重叠- 计算
BFC的高度时,浮动子元素也参与计算 - 文字层不会被浮动层覆盖,环绕于周围
应用:
- 阻止
margin重叠 - 可以包含浮动元素 —— 清除内部浮动(清除浮动的原理是两个
div都位于同一个BFC区域之中) - 自适应两栏布局
- 可以阻止元素被浮动元素覆盖
对this对象的理解
this 是执行上下文中的一个属性,它指向最后一次调用这个方法的对象。在实际开发中,this 的指向可以通过四种调用模式来判断。
- 第一种是函数调用模式,当一个函数不是一个对象的属性时,直接作为函数来调用时,this 指向全局对象。
- 第二种是方法调用模式,如果一个函数作为一个对象的方法来调用时,this 指向这个对象。
- 第三种是构造器调用模式,如果一个函数用 new 调用时,函数执行前会新创建一个对象,this 指向这个新创建的对象。
- 第四种是 apply 、 call 和 bind 调用模式,这三个方法都可以显示的指定调用函数的 this 指向。其中 apply 方法接收两个参数:一个是 this 绑定的对象,一个是参数数组。call 方法接收的参数,第一个是 this 绑定的对象,后面的其余参数是传入函数执行的参数。也就是说,在使用 call() 方法时,传递给函数的参数必须逐个列举出来。bind 方法通过传入一个对象,返回一个 this 绑定了传入对象的新函数。这个函数的 this 指向除了使用 new 时会被改变,其他情况下都不会改变。
这四种方式,使用构造器调用模式的优先级最高,然后是 apply、call 和 bind 调用模式,然后是方法调用模式,然后是函数调用模式。
JavaScript 类数组对象的定义?
一个拥有 length 属性和若干索引属性的对象就可以被称为类数组对象,类数组对象和数组类似,但是不能调用数组的方法。常见的类数组对象有 arguments 和 DOM 方法的返回结果,还有一个函数也可以被看作是类数组对象,因为它含有 length 属性值,代表可接收的参数个数。
常见的类数组转换为数组的方法有这样几种:
(1)通过 call 调用数组的 slice 方法来实现转换
Array.prototype.slice.call(arrayLike);
(2)通过 call 调用数组的 splice 方法来实现转换
Array.prototype.splice.call(arrayLike, 0);
(3)通过 apply 调用数组的 concat 方法来实现转换
Array.prototype.concat.apply([], arrayLike);
(4)通过 Array.from 方法来实现转换
Array.from(arrayLike);
性能优化
性能优化是前端开发中避不开的问题,
性能问题无外乎两方面原因:渲染速度慢、请求时间长。性能优化虽然涉及很多复杂的原因和解决方案,但其实只要通过合理地使用标签,就可以在一定程度上提升渲染速度以及减少请求时间
1. script 标签:调整加载顺序提升渲染速度
- 由于浏览器的底层运行机制,
渲染引擎在解析 HTML 时,若遇到 script 标签引用文件,则会暂停解析过程,同时通知网络线程加载文件,文件加载后会切换至 JavaScript 引擎来执行对应代码,代码执行完成之后切换至渲染引擎继续渲染页面。 - 在这一过程中可以看到,
页面渲染过程中包含了请求文件以及执行文件的时间,但页面的首次渲染可能并不依赖这些文件,这些请求和执行文件的动作反而延长了用户看到页面的时间,从而降低了用户体验。
为了减少这些时间损耗,可以借助 script 标签的 3 个属性来实现。
async 属性。立即请求文件,但不阻塞渲染引擎,而是文件加载完毕后阻塞渲染引擎并立即执行文件内容defer 属性。立即请求文件,但不阻塞渲染引擎,等到解析完 HTML 之后再执行文件内容- HTML5 标准 type 属性,对应值为“module”。让浏览器按照 ECMA Script 6 标准将文件当作模块进行解析,默认阻塞效果同 defer,也可以配合 async 在请求完成后立即执行。

绿色的线表示执行解析 HTML ,蓝色的线表示请求文件,红色的线表示执行文件
当渲染引擎解析 HTML 遇到 script 标签引入文件时,会立即进行一次渲染。所以这也就是为什么构建工具会把编译好的引用 JavaScript 代码的 script 标签放入到 body 标签底部,因为当渲染引擎执行到 body 底部时会先将已解析的内容渲染出来,然后再去请求相应的 JavaScript 文件
2. link 标签:通过预处理提升渲染速度
在我们对大型单页应用进行性能优化时,也许会用到按需懒加载的方式,来加载对应的模块,但如果能合理利用 link 标签的 rel 属性值来进行预加载,就能进一步提升渲染速度。
dns-prefetch。当link标签的rel属性值为“dns-prefetch”时,浏览器会对某个域名预先进行 DNS 解析并缓存。这样,当浏览器在请求同域名资源的时候,能省去从域名查询 IP 的过程,从而减少时间损耗。下图是淘宝网设置的 DNS 预解析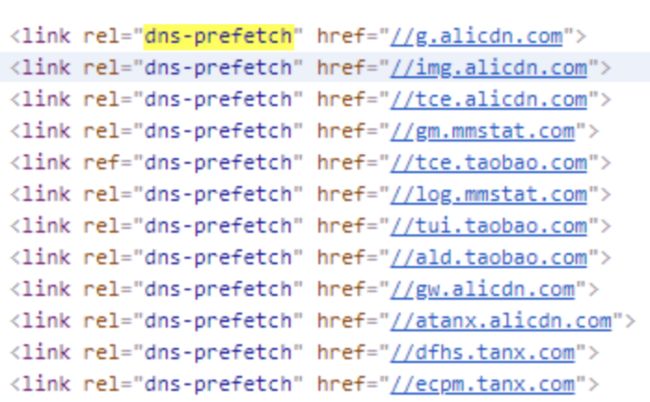
preconnect。让浏览器在一个 HTTP 请求正式发给服务器前预先执行一些操作,这包括DNS 解析、TLS 协商、TCP 握手,通过消除往返延迟来为用户节省时间prefetch/preload。两个值都是让浏览器预先下载并缓存某个资源,但不同的是,prefetch 可能会在浏览器忙时被忽略,而preload 则是一定会被预先下载。prerender。浏览器不仅会加载资源,还会解析执行页面,进行预渲染
这几个属性值恰好反映了浏览器获取资源文件的过程,在这里我绘制了一个流程简图,方便你记忆。

3. 搜索优化
- meta 标签:提取关键信息
- 通过 meta 标签可以设置页面的描述信息,从而让搜索引擎更好地展示搜索结果。
- 示例
VDOM:三个 part
- 虚拟节点类,将真实
DOM节点用js对象的形式进行展示,并提供render方法,将虚拟节点渲染成真实DOM - 节点
diff比较:对虚拟节点进行js层面的计算,并将不同的操作都记录到patch对象 re-render:解析patch对象,进行re-render
补充1��VDOM 的必要性?
- 创建真实DOM的代价高 :真实的
DOM节点node实现的属性很多,而vnode仅仅实现一些必要的属性,相比起来,创建一个vnode的成本比较低。 - 触发多次浏览器重绘及回流 :使用
vnode,相当于加了一个缓冲,让一次数据变动所带来的所有node变化,先在vnode中进行修改,然后diff之后对所有产生差异的节点集中一次对DOM tree进行修改,以减少浏览器的重绘及回流。
补充2:vue 为什么采用 vdom?
引入
Virtual DOM在性能方面的考量仅仅是一方面。
- 性能受场景的影响是非常大的,不同的场景可能造成不同实现方案之间成倍的性能差距,所以依赖细粒度绑定及
Virtual DOM哪个的性能更好还真不是一个容易下定论的问题。 Vue之所以引入了Virtual DOM,更重要的原因是为了解耦HTML依赖,这带来两个非常重要的好处是:
- 不再依赖
HTML解析器进行模版解析,可以进行更多的AOT工作提高运行时效率:通过模版AOT编译,Vue的运行时体积可以进一步压缩,运行时效率可以进一步提升;- 可以渲染到
DOM以外的平台,实现SSR、同构渲染这些高级特性,Weex等框架应用的就是这一特性。
综上,
Virtual DOM在性能上的收益并不是最主要的,更重要的是它使得Vue具备了现代框架应有的高级特性。
列举几个css中可继承和不可继承的元素
- 不可继承的:
display、margin、border、padding、background、height、min-height、max-height、width、min-width、max-width、overflow、position、left、right、top、bottom、z-index、float、clear、table-layout、vertical-align - 所有元素可继承:
visibility和cursor。 - 内联元素可继承:
letter-spacing、word-spacing、white-space、line-height、color、font、font-family、font-size、font-style、font-variant、font-weight、text-decoration、text-transform、direction。 - 终端块状元素可继承:
text-indent和text-align。 - 列表元素可继承:
list-style、list-style-type、list-style-position、list-style-image`。
transition和animation的区别
Animation和transition大部分属性是相同的,他们都是随时间改变元素的属性值,他们的主要区别是transition需要触发一个事件才能改变属性,而animation不需要触发任何事件的情况下才会随时间改变属性值,并且transition为2帧,从from .... to,而animation可以一帧一帧的
isNaN 和 Number.isNaN 函数的区别?
- 函数 isNaN 接收参数后,会尝试将这个参数转换为数值,任何不能被转换为数值的的值都会返回 true,因此非数字值传入也会返回 true ,会影响 NaN 的判断。
- 函数 Number.isNaN 会首先判断传入参数是否为数字,如果是数字再继续判断是否为 NaN ,不会进行数据类型的转换,这种方法对于 NaN 的判断更为准确。
从输入URL到页面展示过程

1. DNS域名解析

- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
DNS的域名查找,在客户端和浏览器,本地DNS之间的查询方式是递归查询;在本地DNS服务器与根域及其子域之间的查询方式是迭代查询;

在客户端输入 URL 后,会有一个递归查找的过程,从浏览器缓存中查找->本地的hosts文件查找->找本地DNS解析器缓存查找->本地DNS服务器查找,这个过程中任何一步找到了都会结束查找流程。
如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程如下图:

结合起来的过程,可以用一个图表示:

在查找过程中,有以下优化点:
- DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种:
浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。 - 在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
2. 建立TCP连接
首先,判断是不是https的,如果是,则HTTPS其实是HTTP + SSL / TLS 两部分组成,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据
进行三次握手,建立TCP连接。
- 第一次握手:建立连接。客户端发送连接请求报文段
- 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认
- 第三次握手:客户端收到服务器的SYN+ACK报文段,向服务器发送ACK报文段
SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
完成了之后,客户端和服务器端就可以开始传送数据
发送HTTP请求,服务器处理请求,返回响应结果
TCP连接建立后,浏览器就可以利用
HTTP/HTTPS协议向服务器发送请求了。服务器接受到请求,就解析请求头,如果头部有缓存相关信息如if-none-match与if-modified-since,则验证缓存是否有效,若有效则返回状态码为304,若无效则重新返回资源,状态码为200
这里有发生的一个过程是HTTP缓存,是一个常考的考点,大致过程如图:

3. 关闭TCP连接
4. 浏览器渲染
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、栅格化和显示。如图:
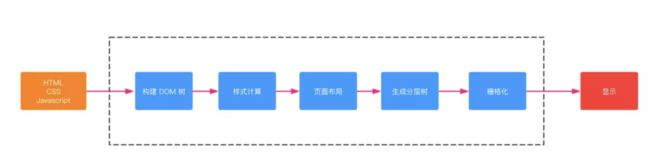
- 渲染进程将 HTML 内容转换为能够读懂DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的
styleSheets,计算出DOM节点的样式。 - 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
构建 DOM 树
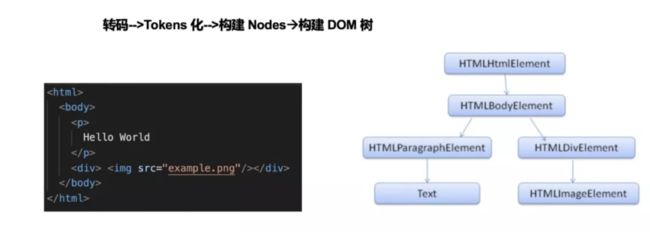
- 转码(Bytes -> Characters)—— 读取接收到的 HTML 二进制数据,按指定编码格式将字节转换为 HTML 字符串
- Tokens 化(Characters -> Tokens)—— 解析 HTML,将 HTML 字符串转换为结构清晰的 Tokens,每个 Token 都有特殊的含义同时有自己的一套规则
- 构建 Nodes(Tokens -> Nodes)—— 每个 Node 都添加特定的属性(或属性访问器),通过指针能够确定 Node 的父、子、兄弟关系和所属 treeScope(例如:iframe 的 treeScope 与外层页面的 treeScope 不同)
- 构建 DOM 树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系
样式计算
渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
CSS 样式来源主要有 3 种,分别是通过 link 引用的外部 CSS 文件、style标签内的 CSS、元素的 style 属性内嵌的 CSS。
页面布局
布局过程,即
排除 script、meta 等功能化、非视觉节点,排除display: none的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图:
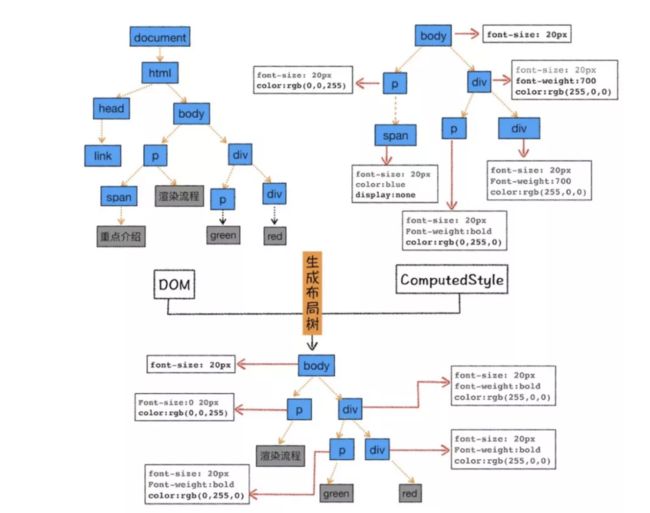
其中,这个过程需要注意的是回流和重绘
生成分层树
页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图
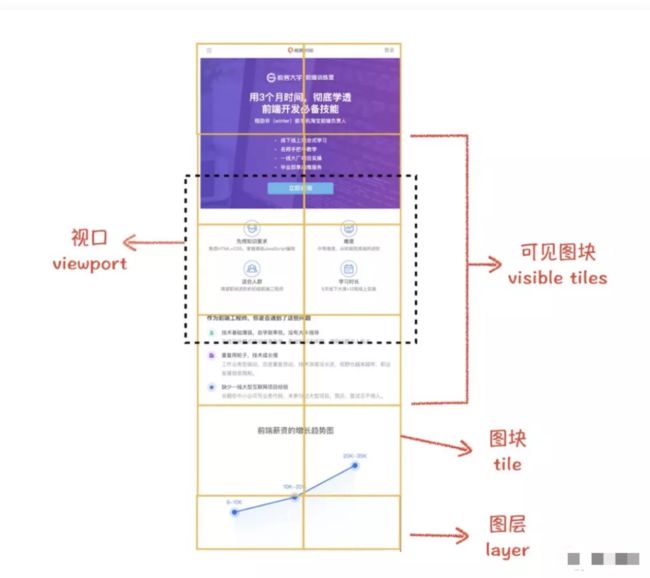
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
显示
最后,合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上,渲染过程完成。
Ajax
它是一种异步通信的方法,通过直接由 js 脚本向服务器发起 http 通信,然后根据服务器返回的数据,更新网页的相应部分,而不用刷新整个页面的一种方法。

面试手写(原生):
//1:创建Ajax对象
var xhr = window.XMLHttpRequest?new XMLHttpRequest():new ActiveXObject('Microsoft.XMLHTTP');// 兼容IE6及以下版本
//2:配置 Ajax请求地址
xhr.open('get','index.xml',true);
//3:发送请求
xhr.send(null); // 严谨写法
//4:监听请求,接受响应
xhr.onreadysatechange=function(){
if(xhr.readySate==4&&xhr.status==200 || xhr.status==304 )
console.log(xhr.responsetXML)
}
jQuery写法
$.ajax({
type:'post',
url:'',
async:ture,//async 异步 sync 同步
data:data,//针对post请求
dataType:'jsonp',
success:function (msg) {
},
error:function (error) {
}
})
promise 封装实现:
// promise 封装实现:
function getJSON(url) {
// 创建一个 promise 对象
let promise = new Promise(function(resolve, reject) {
let xhr = new XMLHttpRequest();
// 新建一个 http 请求
xhr.open("GET", url, true);
// 设置状态的监听函数
xhr.onreadystatechange = function() {
if (this.readyState !== 4) return;
// 当请求成功或失败时,改变 promise 的状态
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
// 设置错误监听函数
xhr.onerror = function() {
reject(new Error(this.statusText));
};
// 设置响应的数据类型
xhr.responseType = "json";
// 设置请求头信息
xhr.setRequestHeader("Accept", "application/json");
// 发送 http 请求
xhr.send(null);
});
return promise;
}
const对象的属性可以修改吗
const保证的并不是变量的值不能改动,而是变量指向的那个内存地址不能改动。对于基本类型的数据(数值、字符串、布尔值),其值就保存在变量指向的那个内存地址,因此等同于常量。
但对于引用类型的数据(主要是对象和数组)来说,变量指向数据的内存地址,保存的只是一个指针,const只能保证这个指针是固定不变的,至于它指向的数据结构是不是可变的,就完全不能控制了。
常见的图片格式及使用场景
(1)BMP,是无损的、既支持索引色也支持直接色的点阵图。这种图片格式几乎没有对数据进行压缩,所以BMP格式的图片通常是较大的文件。
(2)GIF是无损的、采用索引色的点阵图。采用LZW压缩算法进行编码。文件小,是GIF格式的优点,同时,GIF格式还具有支持动画以及透明的优点。但是GIF格式仅支持8bit的索引色,所以GIF格式适用于对色彩要求不高同时需要文件体积较小的场景。
(3)JPEG是有损的、采用直接色的点阵图。JPEG的图片的优点是采用了直接色,得益于更丰富的色彩,JPEG非常适合用来存储照片,与GIF相比,JPEG不适合用来存储企业Logo、线框类的图。因为有损压缩会导致图片模糊,而直接色的选用,又会导致图片文件较GIF更大。
(4)PNG-8是无损的、使用索引色的点阵图。PNG是一种比较新的图片格式,PNG-8是非常好的GIF格式替代者,在可能的情况下,应该尽可能的使用PNG-8而不是GIF,因为在相同的图片效果下,PNG-8具有更小的文件体积。除此之外,PNG-8还支持透明度的调节,而GIF并不支持。除非需要动画的支持,否则没有理由使用GIF而不是PNG-8。
(5)PNG-24是无损的、使用直接色的点阵图。PNG-24的优点在于它压缩了图片的数据,使得同样效果的图片,PNG-24格式的文件大小要比BMP小得多。当然,PNG24的图片还是要比JPEG、GIF、PNG-8大得多。
(6)SVG是无损的矢量图。SVG是矢量图意味着SVG图片由直线和曲线以及绘制它们的方法组成。当放大SVG图片时,看到的还是线和曲线,而不会出现像素点。SVG图片在放大时,不会失真,所以它适合用来绘制Logo、Icon等。
(7)WebP是谷歌开发的一种新图片格式,WebP是同时支持有损和无损压缩的、使用直接色的点阵图。从名字就可以看出来它是为Web而生的,什么叫为Web而生呢?就是说相同质量的图片,WebP具有更小的文件体积。现在网站上充满了大量的图片,如果能够降低每一个图片的文件大小,那么将大大减少浏览器和服务器之间的数据传输量,进而降低访问延迟,提升访问体验。目前只有Chrome浏览器和Opera浏览器支持WebP格式,兼容性不太好。
- 在无损压缩的情况下,相同质量的WebP图片,文件大小要比PNG小26%;
- 在有损压缩的情况下,具有相同图片精度的WebP图片,文件大小要比JPEG小25%~34%;
- WebP图片格式支持图片透明度,一个无损压缩的WebP图片,如果要支持透明度只需要22%的格外文件大小。