Scrapy框架进阶一Crawlspider爬虫案例
文章目录
- 前言
-
- 往期知识点
- 最终效果
- CrawlSpider介绍
-
- 项目的创建
- LinkExtractors和Rule规则
- scrapy爬虫实战
-
- 页面分析
- 代码部分
- 总结
前言
本章就来聊聊scrapy框架中的CrawlSpider,它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则Rule来提供跟进链接的方便的机制,从爬取的网页结果中获取链接并继续爬取的工作
往期知识点
往期内容回顾
【python爬虫】scrapy框架案例实现数据保存入MySQL
【python教程】保姆版教使用pymysql模块连接MySQL实现增删改查
selenium自动化测试实战案例哔哩哔哩信息至Excel
MySQL基础练习题(带答案)

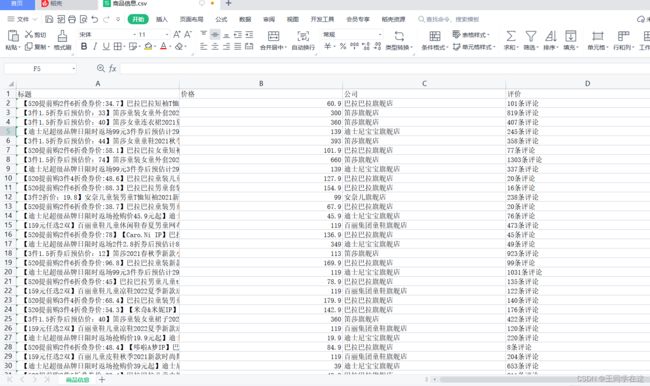
最终效果
CrawlSpider介绍
项目的创建
创建一个项目
scrapy srartproject 项目名
创建CrawlSpider爬虫
scrapy genspider -t crawl 称名 域名
用pycharm打开项目文件夹,即可得到下图(这里我创建的项目为dandan,爬虫名称为shop)


LinkExtractors和Rule规则
crawlspider,适合爬取那些具有一定规则的网站,它基于Spider并有一些独特属性:
LinkExtractors
LinkExtractors的目的很简单:提取链接,主要参数为:
- allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
- deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
- allow_domains:会被提取的链接的domains。
- deny_domains:一定不会被提取链接的domains。
- restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。还有一个类似的restrict_css
直白的说LinkExtractors就是一个网页链接提取器
Rule规则
作用:当链接提取器提取到链接将链接进行指定规则(callback)的解析操作
- link_extractors:是一个LinkExtractor对象,用于定义需要提取的链接
- callback:从link_extractor中没获取链接时,参数所制定的值作为回调函数,该回调函数接受一个response作为起第一个参数
- 注意:当编写爬虫规则是,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了parse方法,CrawlSpider将会运行失败
- follow:是一个布尔值(boolean),制定了根据该规则从response提取的链接是偶需要跟进。如果callback为None,follow默认设置为True,否则默认为Flase
- process_links:指定该Spider中那个的函数将会被调用,从link_extractor中获取到链接列表是将会调用该函数。该方法主要用来过滤
- process_request:指定该Spider中那个的函数将会被调用,该规则提取到每个request是都会调用该函数。(用来过滤request)
总的来说,只要写代码的时候遵循一下这些规则便能很快的实现我们的需求。

scrapy爬虫实战
页面分析
首先是打开网址找到翻页的规律,写好LinkExtractors链接提取器提取每一页的链接,然后rule规则解析进行回调解析每一页所需要的信息

这里用正则来进行链接提取

在规则解析器里面记得设置follow=True: 我们可以将链接提取器 继续作用到 链接提取器提取到的链接 所对应的页面中 (实现全部页面链接的提取)

回调的方法中对商品的价格,标题,评价,店铺等进行信息的提取。

分析完了接下来就可以进行实战了
代码部分
1.settings部分
首先把机器人协议关掉。添加headers。然后打开管道。三个操作。
# 让终端显示指定类型的日志信息,只输出错误类型信息
LOG_LEVEL = 'ERROR'
# Obey robots.txt rules 机器人协议
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5 # 下载延迟
# 开启管道
ITEM_PIPELINES = {
'dandan.pipelines.DandanPipeline': 300,
}
2.strat
创建一个py用来运行scrapy程序的,不用每次都在终端中打命令行运行。
from scrapy import cmdline
# 开启程序
cmdline.execute('scrapy crawl shop'.split(" "))
3.items部分
这里我爬取了如上图所示的:标题,价格,店铺以及评价这四个字段的内容
import scrapy
class DandanItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
momey = scrapy.Field()
company = scrapy.Field()
scosc = scrapy.Field()
4.重要的spider部分
这里主要是进行爬取流程的实现,最后得到的结果交给了管道
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from fake_useragent import UserAgent
from ..items import DandanItem
class ShopSpider(CrawlSpider):
name = 'shop'
# allowed_domains = ['www.baidu.com']
start_urls = ['http://category.dangdang.com/cid4004344.html']
# user-Agent
ua = UserAgent().random
# 重写请求方法
def start_requests(self):
yield scrapy.Request(self.start_urls[0])
# 翻页
# 链接提取器:根据指定规则(allow=“正则”)进行指定。 自动发起请求 链接的提取,链接提取器遇到重复的链接,去重操作也是默认去除重复的链接。
link = LinkExtractor(allow=r'/pg\d+-cid4004344.html')
# 规则解析器: 当链接提取器提取到链接将链接提取器提取到的链接进行指定规则(callback)的解析操作
rules = (
Rule(link,callback='parse_item', follow=True),
# follow=True: 我们可以将链接提取器 继续作用到 链接提取器提取到的链接 所对应的页面中 (实现全部页面链接的提取)
)
def parse_item(self, response):
# 每一页的链接有了,进行信息提取
all_list = response.xpath('//*[@id="component_47"]/li')
# 遍历
for i in all_list:
item = DandanItem()
try:
item['title'] = i.xpath('./p[2]/a/text()').extract()[0]
item['momey'] = i.xpath('./p[1]/span/text()').extract()[0].strip('¥')
item['company'] = i.xpath('./p[5]/a/text()').extract()[0]
item['scosc'] = i.xpath('./p[4]/a/text()').extract()[0]
except:
item['scosc'] = 'NOT'
print(item)
# 提交管道
yield item
5.pipelines部分
管道对数据进行持久化存储,保存到了csv中。
import csv
class DandanPipeline:
def __init__(self):
self.filt = open('商品信息.csv',mode='w',encoding='utf-8',newline='')
self.csvwriter = csv.writer(self.filt)
self.csvwriter.writerow(['标题','价格','公司','评价'])
def process_item(self, item, spider):
self.csvwriter.writerow([item['title'],item['momey'],item['company'],item['scosc']])
return item
def close_csv(self,spider):
self.filt.close()
实现结果


总结
到这里我们就把数据实现了持久化储存,是不是感觉这样的方式比较轻松捏,只要遵循一下规则就能高效的把需求实现。