【论文下饭】A Systematic Survey on Deep Generative Models for Graph Generation
内容有省略,详细见原文。水平有限,有误请指出。
A Systematic Survey on Deep Generative Models for Graph Generation
文章目录
- 1 介绍
-
- 1.2 挑战
- 1.3 贡献
- 1.5 与现有调研的关系
- 2 无条件深度图生成模型
-
- 2.1 顺序生成
-
- 2.1.1 基于节点序列
- 2.1.2 基于边的序列
- 2.1.3 基于基序序列(Motif-sequence-based)
- 2.1.4 基于规则序列(Rule-sequence-based)
- 2.1.5 不同方法的比较
- 2.2 一次生成
-
- 2.2.1 基于邻接矩阵
- 2.2.2 基于边列表
- 2.2.3 比较
- 3 条件深度图生成模型
-
- 3.1 辅助信息是图
-
- 3.1.1. 边转换
- 3.1.2 节点-边共同转换(Node-Edge Co-Transforamtion,NECT)
- 3.1.3 比较
- 3.2 辅助信息是序列
- 3.3 辅助信息是语义上下文
- 4 深度图生成的评估标准
-
- 4.1 深度图生成的 通用评估方法
-
- 4.1.1 基于统计(的评估方法)
- 4.1.2 基于分类器(的评估方法)
- 4.1.3 基于内在质量(的评估方法)
- 4.2 条件深度图生成的评估方法
-
- 4.2.1 基于图属性
- 4.2.2 基于映射关系
- 5 应用
- 6 未来机会
- 7 总结
1 介绍
图上的工作主要分为两类,
(1)预测和分析给定图的模式。
(2)学习给定图的分布,并生成新的图。(本文重点)
经典图模型,
- 随机图(random walk)
- 小世界模型(small-world models)
- 随机块模型(stochastic block models)
- 贝叶斯网络模型(Bayesian network models)
但这些模型比较简单且依赖相对应的先验知识,限制了经典图模型在更大范围内的探索与应用。
得益于出现的深度生成模型,
- 变分自编码器(VAE)
- 生成对抗网络(GAN)
已经提出了很多的深度图生成模型。
1.2 挑战
不唯一的表示(Non-unique Representations)。考虑到图节点的排列,一共有n!种可能。我们很难去计算 生成图与真实图 之间的距离(相似度)。这就要求我们设计一个,
- 预先定义好顺序的 重构目标函数,或
- 节点排列不变的 重构目标函数。
复杂的依赖(Complex Dependencies)。图的节点和边之间存在复杂的依赖关系。例如,如果两个节点有公共的邻居,那么它们之间更可能相互连接。因此,不能将每个节点或边的生成建模为独立事件。一种解决办法是自回归决策,前一个节点/边的生成取绝于之前的状态。
巨大的输出空间(Large Output Spaces)。为了生成具有n个节点的图,生成模型可能需要输出n^2个值来明确其结构。这就使得成本十分高昂,尤其是对于大型图。但在现实世界的数据中,图的数量和规模往往都是巨大的。这就要求生成模型能够适应大规模图。
自然界中离散对象(Discrete Objects by Nature)。标准的机器学习数据都是连续的。而图、句子这种数据是离散的。通常的做法是将离散数据投影到连续空间,并将其表示为向量/矩阵。然而,从连续表示重构生成图是一件比较困难的事情。
隐式属性的评估方法(Evaluation for Implicit Properties)。
- 计算 测试集图 和 生成图 的 图统计分布距离。
- 间接地使用 分类器 度量。
各种有效性要求(Various Validity Requirements)。在真实数据集上的应用,需要满足物理限制。如,分子图的化合价。
低可靠的黑盒(Black-box with Low Reliability)。基于深度学习的图建模方式就像是黑盒,具有低可解释性和可靠性的缺点。提高深度图生成模型的可解释性可能是打开生成过程黑匣子并为更广泛的应用领域铺平道路的一个关键问题。
1.3 贡献
- 提出一种 按【解决问题和方法论】分类的 用于图深度生成模型 分类法。
- 提供了用于图生成、深度生成模型 的描述、分析和比较。
- 总结、分类了 现有的评估过程、度量、基准数据集以及结果。
- 介绍了图深度生成模型的应用。
- 提出了图深度生成领域的几个开放性问题 和 未来的研究方向。
1.5 与现有调研的关系
现有三种类型的调研 与 本文相关。
- 围绕经典图论和网络科学的传统图生成,而不是人工智能中深度生成神经网络的最新进展。
- 图上的表示学习,重点是学习图嵌入表示。
- 特定于应用的,如分子设计,而不是通用的技术领域。
已经有两篇同期的图深度生成模型的综述工作。
Deep graph generators: A survey
A survey on deep graph generation: Methods and applications
我们的不同之处,
- 全面总结了用于无条件和有条件生成问题的技术。
- 从特定于图的角度进行分类(多步生成、一步生成)。
- 全面调研了各种应用的评估方法和指标。
- 更多的应用。
- 性能的比较。
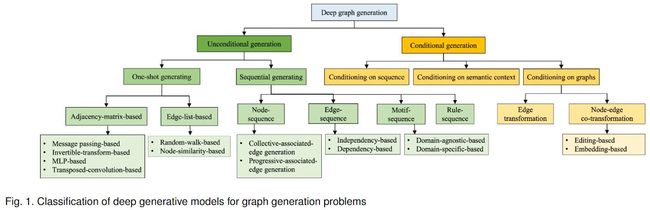
2 无条件深度图生成模型
无条件深度图生成的目标 是从观察的真实图 G \mathcal{G} G中,学习到其分布 p m o d e l ( G ) p_{model}(\mathcal{G}) pmodel(G)。
根据生成过程,我们可以分为,
(1)顺序生成(sequential generating):按顺序依次生成节点和边。
(2)一次生成(One-shot generating):基于矩阵表示构建概率图模型,可以一次性生成所有节点和边。
顺序生成 高效地在局部范围内决策,因此它很难保留长期依赖性,比如图的全局属性(无标度(scale-free 属性)。
一次生成 能够通过多次迭代同步生成和细化整个图(即节点和边),从而对图的全局属性进行建模。由于需要对节点之间的全局关系进行集体建模,大多数方法很难扩展到大型图,时间复杂度通常超过 O ( N 2 ) O(N^2) O(N2)。
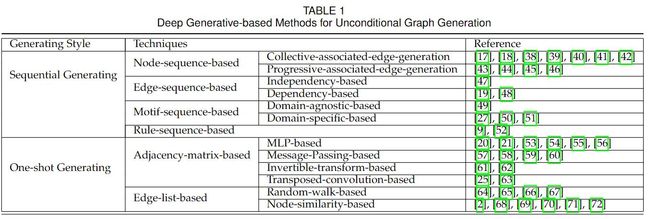
2.1 顺序生成
2.1.1 基于节点序列
每次生成一个节点 与 它的边。
2.1.2 基于边的序列
每次生成 一条边和其末端的两个节点。
2.1.3 基于基序序列(Motif-sequence-based)
S e q ( G ) = { C 1 , . . . , C M } Seq(G) = \{C_1, ..., C_M\} Seq(G)={C1,...,CM}。每次选择一个基序 C i C_i Ci,拼接到 G i G_i Gi上。
2.1.4 基于规则序列(Rule-sequence-based)
通过一些方法生成一系列生产规则或命令,指导图的构建。
通常目标图具有很强的约束 或 语法选择方式,必须满足这些约束或语法才能构造有效图。例如,分子不能违反电荷守恒等基本物理性质。
为了确保生成的图的有效性,通过 生成解析树 来转换图的生成,解析树利用上下文无关语法(CFG)描述离散的分子结构,而解析树本身可以进一步表示为基于预定义顺序的规则序列。
2.1.5 不同方法的比较
从三个方面进行比较,
(1)可伸缩性:时间复杂度决定了图生成法相的可伸缩性。 N N N表示节点数量, E E E表示边数量,
- 基于节点序列: O ( N ) O(N) O(N)
- 基于边序列: O ( E ) O(E) O(E)
- 基于基序序列: O ( N 2 ) O(N^2) O(N2)(域不可知类型), O ( N ⋅ ∣ C ∣ ) O(N \cdot |C|) O(N⋅∣C∣)(域特定类型),其中 ∣ C ∣ |C| ∣C∣是基序的数量。
- 基于规则序列:复杂度与生成图中规则数量线性相关。
(2)表达能力:生成模型的表达能力取绝于 它对图中对象之间的复杂依赖关系进行建模的能力。
基于节点序列和基于边序列的方法,可以捕获最复杂的相关性,包括节点-节点相关性、边相关性和节点-边相关性。
基于基序的方法,能够捕捉高阶关系和全局模式的图基序之间的依赖。
基于规则的方法,可以对操作规则之间的依赖进行建模,捕获真实图的语义模式。这通常很难直接从图的拓扑结构中学习。
(3)应用场景:
基于节点和边序列的方法,适用于生成 没有 领域专业知识。
基于基序的方法,可以通过从 预定义的有效基序候选中选择图基序来部分保证生成的图的有效性。
基于规则序列的方法,通过遵循正确的语法和约束,在生成有效的真实图方面更有效。
后两种方法在有效性敏感的应用中是首选的,如分子生成和程序建模。
2.2 一次生成
一次生成的方法,将每个图映射成一个统一的潜在表示,该表示遵循潜在空间的某种概率分布。通过采样该概率分布,一次性生成完整的图。
此类方法的问题在于,如何同时生成图的拓扑结构与节点、边的属性。考虑到图的拓扑结构通常可以使用邻接矩阵和节点属性矩阵表示,经典的解决方法就是同时学习这两个矩阵的分布,并一次性生成他们。这又被叫做基于邻接矩阵的生成。
学习邻接矩阵的分布 有强大的表达能力,但空间和时间效率往往较低。为了解决这个问题,基于边列表的方式,通过学习局部模式,更擅长解决有更简单全局特征的大图。
2.2.1 基于邻接矩阵
基于邻接矩阵的方法,将潜在嵌入向量 z z z(通过 神经网络)映射到输出图,并添加节点和边的属性矩阵。
如何做到 高表达能力 和 高效率 是目前的主要挑战,也是需要权衡的因素之一。
目前主流的方法有,
- 基于MLP
- 基于消息传递
- 基于可逆变换
- 基于转置卷积
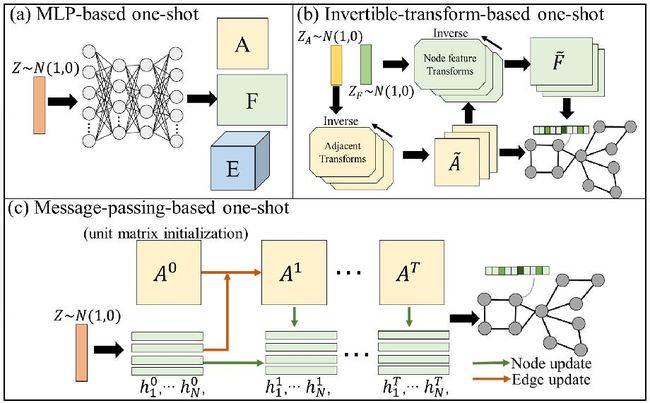
基于MLP。通过简单的构建图解码器 g ( z ) g(z) g(z),模型的参数可以在VAE和GAN的框架下进行优化。输入潜在表示 z z z,输出 连续、紧密的 邻接矩阵 A ~ π \tilde{A}^\pi A~π 和 节点属性矩阵 F ~ π \tilde{F}^\pi F~π。之后,再离散化得到 A π A^\pi Aπ和 F π F^\pi Fπ。现有的工作一般有两种方法来实现这个步骤。
第一种方法,在训练时,使用sigmoid激活函数来计算 A ~ π \tilde{A}^\pi A~π和 F ~ π \tilde{F}^\pi F~π。在测试时,可以使用edge-wise或node-wise的argmax来得到离散值。
第二种方法,使用Gumbel-Softmax的分类再参数化,在前向过程中采样分类分布,在反向过程中采样原始的连续值 A ~ π \tilde{A}^\pi A~π和 F ~ π \tilde{F}^\pi F~π。
基于信息传递。基于消息传递的方法通过MPNN(消息传递神经网络)迭代细化 初始化图 的 拓扑结构 和 节点表示 来生成图。
从简单分布(如,高斯分布)采样的 z z z初始化 邻接矩阵 A 0 A^0 A0与节点特征 H 0 H^0 H0。之后,通过每一层MPNN更新邻接矩阵与节点表示。
每一层的公式可表示如下:
A i , j l + 1 = A i , j l + R e L u ( v 1 A i , j l + v 2 h i l + v 3 h j l ) h i l + 1 = h i l + R e L u ( w 1 h i l + ∑ j N η i , j w 2 h j l ) A_{i,j}^{l+1}=A^l_{i,j} + ReLu(v_1A_{i,j}^l + v_2 h_i^l + v_3 h_j^l) \\ h_i^{l+1} = h_i^l + ReLu(w_1 h_i^l + \sum_j^N \eta_{i,j} w_2 h_j^l) Ai,jl+1=Ai,jl+ReLu(v1Ai,jl+v2hil+v3hjl)hil+1=hil+ReLu(w1hil+j∑Nηi,jw2hjl)
其中, v 1 , v 2 , v 3 , w 1 , w 2 v1, v2 , v3, w1, w2 v1,v2,v3,w1,w2都是可训练的参数。
基于可逆变换。通过使用一个唯一的可逆变换函数,基于流的生成方法也可以做到一步生成。
基于转置卷积的方法。在一次生成技术中,图解码器的一个典型就是使用 转置卷积神经网络。它将节点潜在表示向量作为输入,输出邻接矩阵。基于转置卷积的解码器包含了节点转置卷积层 和 多个边转置卷积层。
节点转置卷积层 使用节点嵌入特征 来对 边的特征进行解码。例如,在节点转置卷积层之后,边特征 E i , j E_{i,j} Ei,j,节点特征 v i v_i vi和 v j v_j vj可以如下计算:
E i , j = ∑ m = 1 L ( σ ( H i m μ ˉ j ) + σ ( H j m v ˉ i ) ) E_{i,j} = \sum_{m=1}^L(\sigma(H_i^m \bar{\mu}_j)+\sigma(H_j^m \bar{v}_i)) Ei,j=m=1∑L(σ(Himμˉj)+σ(Hjmvˉi))
其中, ( σ ( H i m μ ˉ j ) (\sigma(H_i^m \bar{\mu}_j) (σ(Himμˉj) 是节点 v i v_i vi到其潜在边 E i , j E_{i,j} Ei,j转置卷积的权重。
2.2.2 基于边列表
总体框架。 此类方法通常需要生成模型学习独立生成 边 的概率。这些方法通常在大规模图上使用。通用的流程共分为两个主要步骤。为每条边计算分数(概率),采样生成边。
针对如何生成边的概率,现有工作进一步分为,
- 基于随机游走
- 基于节点相似度
基于节点相似度的模型,根据,每对节点之间的相似度,计算边的概率。
基于随机游走的模型,根据,随机游走中边出现的频率,计算边的概率。
2.2.3 比较
(1)时间复杂度:
基于邻接矩阵 和 基于节点相似度 方法 都具有 O ( N 2 ) O(N^2) O(N2)的时间复杂度。
(2)应用场景:
基于邻接矩阵的方法,可以注意到全局特征,并拥有高表达和较小的时间开支。此类方法多用于小并且全局特征比较重要的图(节点数小于1000个节点),比如,分子和蛋白质。
基于边列表的方法,在生成大图的局部模式时,非常有效,如 社交网络和引文网络。
3 条件深度图生成模型
条件深度图生成的目标是,给定一系列图G与辅助信息y中,学习到一个条件分布 p m o d e l ( G ∣ y ) p_{model}(G|y) pmodel(G∣y)。辅助信息可以是类别标签,语义上下文,来自其他分布的图等。
与无条件深度图生成相比,条件生成还需要考虑如何从给定条件中提取特征并将其集成到图的生成中。下面介绍三种辅助信息的类型,图、序列和语义上下文。
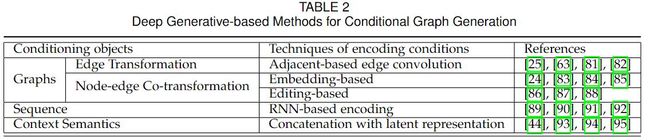
3.1 辅助信息是图
根据另一个图 生成 新的图,也叫做 深度图转换(deep graph transformation)或者 深度图变换(deep graph translator)。它的目标是将输入图 G S G_S GS从源域 转换到 对应的输出域。考虑到在转换过程中的实体,深度图转换可以分为两大类,
- 边转换
- 节点-边共同转换
(单纯的节点、边属性转换,可以使用经典的GNN解决节点分类 或者 链接预测 任务,并不是本文讨论的重点)
3.1.1. 边转换
总体问题定义。 边变换问题是 在输入图上 生成目标图限制的 拓扑与边分布。它需要边集 E \mathcal{E} E,和边属性 E E E发生变化,而 节点集 和 节点属性是固定的 。转换过程可以看作 T : G S ( V , E S , F , E S ) → G T ( V , E T , F , E T ) \mathcal{T}:G_S(\mathcal{V,E_S}, F, E_S) \to G_T(\mathcal{V, E_T}, F, E_T) T:GS(V,ES,F,ES)→GT(V,ET,F,ET)。
边转换问题具有广泛的现实应用,如化学反应建模,蛋白质折叠,恶意软件网络合成。现有的工作采用不用的框架来对转换的过程建模。
一些工作(GT-GAN、UGT-GAN)采用编码器-解码器框架,通过编码器学习输入图的抽象潜在表示,然后通过解码器基于这些隐藏信息生成目标图。
(UGT-GAN)Local Event Forecasting and Synthesis Using Unpaired Deep Graph Translations
(GT-GAN)Deep Graph Translation
Graph U-Nets
GT-GAN提出了基于GAN模型的图拓扑变换,它包含 图转换器 和 条件图判别器。
图转换器 包含两个部分:图编码器 和 图解码器。图编码器 使用了 图卷积神经网络(Brainnetcnn),将图嵌入到节点级表示。图解码器 使用了图反卷积网络 来生成新的图。
Brainnetcnn: Convolutional neural networks for brain networks; towards predicting neurodevelopment
Misc-GAN,提出了对输入图不同颗粒度的结构进行加墨,然后将这种分层分布 从源域 变换到 目标域。
3.1.2 节点-边共同转换(Node-Edge Co-Transforamtion,NECT)
总体问题定义。 根据给定输入图的节点和边属性的基础上,生成目标图的节点和边属性。目前的工作可以分为两类,基于嵌入的,基于编辑的。
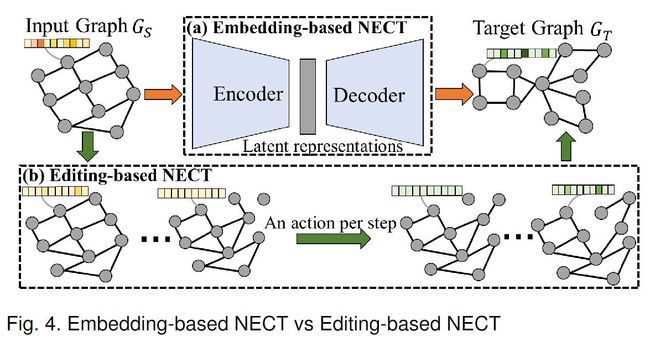
基于嵌入的NECT。基于嵌入的NECT通常将输入图 嵌入到 包含丰富高等级信息的 潜在表示中,然后使用 解码器 解码为目标图。
Graph to graph: a topology aware approach for graph structures learning and generation
A neural framework for learning dag to dag translation
(JTVNN)Learning multimodal graph-to-graph translation for molecular optimization
Mol-cyclegan: a generative model for molecular optimization
Composing molecules with multiple property constraints
这些方法通常都是基于 条件VAE 和 条件GAN。
基于编辑的NECT。与编码器-解码器架构不同,基于编辑的NECT直接迭代修改输入图,来生成目标图。
Graph convolutional policy network for goal-directed molecular graph generation
Optimization of molecules via deep reinforcement learning
Deep multi-attributed graph translation with node-edge co-evolution
3.1.3 比较
(1)从输入图捕捉的模式:基于嵌入的NECT可以捕获输入图的全局模式对目标图的影像,并具有图级别潜在表示。
(2)可解释性:基于编辑的NECT提供了更易于解释的方式,它逐步地显式地将输入转换到输出。这更适合高置信度地应用。
(3)应用场景:基于嵌入地NECT能够对主要、复杂地变化进行建模;基于编辑地NECT更适合处理微小变化。
3.2 辅助信息是序列
基于序列的深度图生成问题可以形式化为,深度序到到图转换问题。目的是生成输入序列 X X X限制的目标图 G T G_T GT。这些问题通常是NLP、时间序列挖掘。
3.3 辅助信息是语义上下文
语义上下文可以是标签、模态或其他任何信息。主要的问题是,在什么地方加入辅助信息。本文总结了三种加入辅助信息的模块:
- 节点状态初始化模块
- 基于MPNN解码的消息传递过程
- 用于顺序生成的条件分布参数化
4 深度图生成的评估标准
评估生成的图 以及 学习到的图的分布,是具有挑战性的。因为,
(1)与仅需要评估确定性预测的 传统预测问题不同,深度图生成 需要 评估学习分布。
(2)与具有矩阵/向量结构的简单数据 或 语义数据(如图像和文本)相比,图结构数据更难评估。
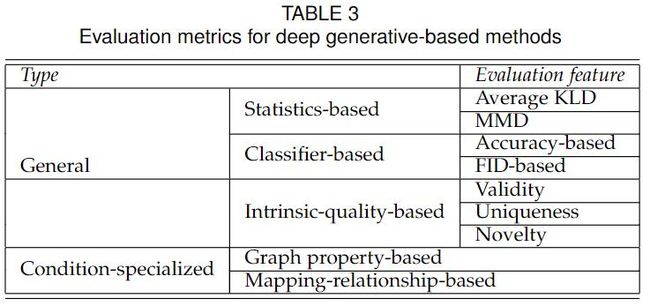
4.1 深度图生成的 通用评估方法
分为三类,
- 基于统计
- 基于分类器
- 基于内在质量
前两种评估要求 生成图集 与 实际图集进行比较,而第三种评估 直接评估生成图的属性。
4.1.1 基于统计(的评估方法)
在基于统计的评估中,通过计算 真实图与生成图 的图统计分布 之间的距离,来评估生成图的质量。本文,介绍7中经典的图统计,然后介绍两种 分布距离的度量。
(1)节点度分布(Node degree distribution):图的经验节点度分布,可以对其局部连通性模式进行建模。
(2)聚类系数分布(Clustering coefficient distribution):图的经验聚类系数分布。直观地说,节点的聚类系数计算为该节点可能包含的三角型的潜在数量与该节点实际包含的三角型数量之比。
(3)轨道数分布(Orbit count distribution):图的4个轨道节点的数量的分布。
(4)最大连通分量(Largest connected component):图中最大连通分量的大小。。
(5)三角型计数(Triangle count):图中三角形的数量。
(6)特征路径长度(Characteristic path length):图中所有节点对沿最短路径的平均步数。
(7)关联性(Assortativity):图中相互连接节点的度的皮尔森系数。
前三种图统计是关于每个图的分布,并且表示为向量,而后四个图统计表示为每个图的标量值。为了评估两组图之间的距离,下面介绍两种主要的 分布距离度量方法。
(1)平均Kullback-Leibler(KL)散度。
(2)最大平均偏差(MDD)。第一步,得到生成图集P和真实图集Q的 图统计分布 的MDD的平方。
标量值统计的距离度量
(1)计算 生成的图集 与 真实图集 之间 统计量平均值的差。
(2)计算 生成的图集 与 实际图集 之间 统计量的分布的距离。可以使用许多距离度量,如KL-D,JS(Jensen-Shannon distance),HD(Hellinger distance)
4.1.2 基于分类器(的评估方法)
基于分类器的评估方法 通常来评估 生成的图是否遵循与真实图相同的分布。通常,分类器在真实图上训练,并在生成图上测试。只有当 训练多个图生成模型以分别生成多种类型的图时,才使用这种方法。这里本文介绍两种方法,它们基于图同构网络(GIN)。
基于准确率。在包含多种类型图的训练集上 预训练的GIN,在生成图上进行分类。
基于Fréchet Inception Distance(FID)。FID计算嵌入空间中 生成图集 和 测试集 的多元高斯分布。较低的FID值表示更好的生成质量和多样性。首先,将测试集中生成图和真实图送入 预训练的GIN中,得到图嵌入。然后分别计算生成图 和 真实图 图嵌入的均值 μ G \mu_G μG和方差 Σ G \Sigma_G ΣG。
F I D = ∥ μ G − μ R ∥ 2 2 + T r ( Σ G + Σ R − 2 ( Σ G Σ R ) 1 2 ) FID = \lVert \mu_G - \mu_R \rVert_2^2 + \mathrm{Tr}(\Sigma_G + \Sigma_R - 2(\Sigma_G\Sigma_R)^{1 \over 2}) FID=∥μG−μR∥22+Tr(ΣG+ΣR−2(ΣGΣR)21)
Frechet Inception Distance
4.1.3 基于内在质量(的评估方法)
除了评估 真实图 和 生成图之间的相似度,还有三个额外的评估方式,直接对生成图进行评估。
有效性(Validity)。由于有时候生成图需要保留一些属性,因此 可以直接判断它们是否满足某些条件。例如:(1)循环图/树图:循环和树是具有明显结构属性的图,有效性 为生成图实际是循环或树的百分比。(2)分子图:有效的分子生成 是 有效分子的比例。
唯一性(Uniqueness)。理想情况下,高质量生成的图应该是 多样的、相似的,但不完全相同。因此,利用唯一性 来捕获生成图的 多样性。为了计算生成图的唯一性,首先移除与其他生成图同构的子图。此操作后剩余图形的百分比定义为唯一性。例如,如果模型生成100个图,所有图都相同,则唯一性为1/100=1%。
新颖性(Novelty)。新颖性是 测量 生成图不是训练集图的子图 的百分比,反之亦然。相同的图被定义为彼此同构的子图。换而言之,新颖性 会检查 模型是否能够泛化 没见过的图。
4.2 条件深度图生成的评估方法
除了上述图生成 的一般评估指标外,对于条件深度图生成模型,还有一些额外的指标。包括,基于图属性的评估 和 基于映射关系的评估。
4.2.1 基于图属性
考虑到在条件图生成任务中,每个生成图都可以将其关联的真实图 作为标签,我们可以通过 基于某些图属性 或 图核,来测量它们的相似度 或 距离。
(1)基于随机游走的图核 来测量随机游走图核相似性。
(2)Hamming and Ipsen-Mikhailov距离组合。
(3)密度矩阵的谱向性。
(4)特征向量中心距离。
(5)接近中心距离。
(6)Weisfeiler Lehman 核相似性。
(7)相邻子图对 核,通过匹配具有不同半径和距离的子图对。
4.2.2 基于映射关系
基于映射关系的评估,衡量 学习到的条件和生成的图之间的关系 是否 与条件和真实图之间的真实关系一致。
显式映射关系。在预先知道输入条件和生成的图之间的真实关系的情况下,可以如下进行评估:
(1)当条件是类别标签时,我们可以通过使用 图分类器 来检查生成的图是否属于条件类别。具体而言,真实图用于训练分类器,分类器用于对生成的图进行分类。然后将准确度计算为与输入条件相同的预测类别的百分比。
(2)当条件是一个图时,其中的任务是更改输入图的某些属性,我们可以定量地比较生成的和输入图的属性得分,以查看更改是否确实符合要求。例如,可以计算分子优化任务中优化分子的logP分数的提高。
隐式映射关系。考虑到深度图转换问题,有时,从输入图到目标图的底层模式是隐式的,难以定义和测量。因此,可以使用基于分类器的评估度量。通过将输入图和目标图视为两个类,假设分类器能够将正确地区分生成图和真实图。具体地,首先基于输入和生成的目标图训练图分类器。然后测试该训练的图分类器,以对输入图和真实目标图进行分类,结果将用作评估指标。
5 应用
深度图生成 是一个 非常活跃的研究领域,提出的应用越来越多,包括 分子优化和生成、NLP中的语义解析、代码建模和伪工业SAT实例生成。
6 未来机会
可拓展性。对大型图更有效率。
可解释性。当我们学习复杂结构化数据(即图)的潜在分布时,学习明显语义的数据的可解释表示非常重要。
超越训练数据。深度生成模型是数据驱动的模型。生成图的新颖性是很重要的。
动态图。现有的深度生成图模型通常侧重于静态图,但现实世界中的许多图是动态的。
7 总结
在本文中,本文对深度图生成模型进行系统的回顾。
- 本文提出了基于 问题设置 和 技术细节的 深度图生成模型分类,然后对他们进行了详细的介绍、比较和讨论。
- 本文还对深度图生成模型的评估度量方法进行了系统的回顾,包括 无条件生成 和 有条件生成 的通用评估方法。
- 本文对该领域流行应用进行了汇总。