一文读懂交叉熵损失函数
进行二分类或多分类问题时,在众多损失函数中交叉熵损失函数较为常用。
下面的内容将以这三个问题来展开
- 什么是交叉熵损失
- 以图片分类问题为例,理解交叉熵损失函数
- 从0开始实现交叉熵损失函数
1,什么是交叉熵损失
交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性
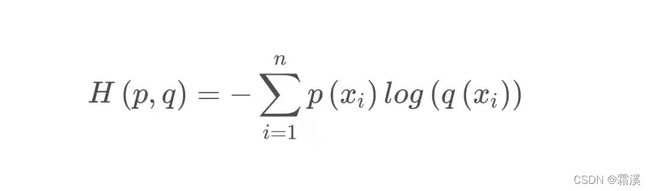
p(x)表示样本的真实分布,q(x)表示模型所预测的分布
**交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。**
2,以图片分类问题为例,理解交叉熵损失函数
Fashion-MNIST数据集是一个包含60000衣服,鞋子等图片的数据集,也是实验图像分类算法经常用的数据集。具体图片类别及其标签如下
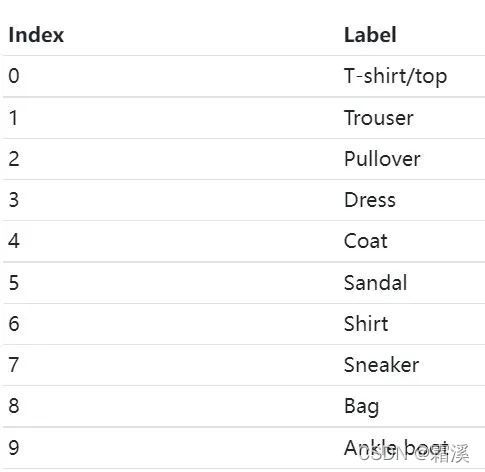
这里,我们就以在这个数据集上的图片分类问题为例,理解交叉熵损失函数。
假设某个场景如下:对于我们设计的用于图片分类的卷积神经网络的训练还没有完成,此时,终止我们的训练,显然,各种层的参数已经保留。从数据集中任选一张图片(类别已经被记录),输入我们的神经网络,结果输出的是一个包含10个数据的一维张量,这10个数据分别对应10种物品的概率。不妨记为
q=[0.1058, 0.1043, 0.0988, 0.1066, 0.0875, 0.0881, 0.1027, 0.1046, 0.1057, 0.0958]
很显然,这个预测结果有点糟糕,不过主要是因为网络没有训练好。同时我们也已知道这个图片的真实类别为4,这时记
p=[0,0,0,0,1,0,0,0,0,0]
带入交叉熵损失函数,计算如下:
loss= -(0xlog(0.1058)+0xlog(0.1043)+0xlog(0.0988)+0xlog(0.1066)+1xlog(0.0875)+0xlog(0.0881)+0xlog(0.1027)+0xlog(0.1046)+0xlog( 0.1057)+0xlog(0.0958))=2.4361
这个结果就是我们的交叉熵损失,当然,我们希望越小越好,这意味着我们的神经网络较为成功。
其实,这个神经网络的训练过程就是对于输入的60000个数据(这里全部作为训练集,没有设置测试集),进行预测,计算损失,更新权重不断使得损失减小,循环往复。最终在训练很多轮后,使得损失足够小,分类的精度足够的高。那么我们可以认为这个神经网络在这个数据集上有较为不错的效果。
3,从0开始实现交叉熵损失函数
当然,pytorch中已经有这个函数,叫做 CrossEntropyLoss()。当然这个函数的输入不是一组概率,而是一组数据,可正可负。
这个函数先对输入的数据进行softMax操作 ,将其转换为概率,再与标签数据按上面的交叉熵损失函数计算。
也就等价于softMax+上面定义的函数(log+NLLLOSS)。
所以我们的交叉熵损失函数实现如下:
softmax:
def soft_max(data):
t1=torch.exp(data)#对所有数据进行指数运算
s=t1.sum(dim=1) #按行求和
shape=data.size()
m=shape[0]#获取行数
n=shape[1]
for i in range(m):
t1[i]=t1[i]/s[i]
return t1
cross_entropyloss
def cross_entropyloss(input,target):
shape=data.size()
m=shape[0]#获取行数
output=-torch.log(input[range(m),target.flatten()]).sum()/m
print(input[range(m),target.flatten()])
return output
比较:
#自己编写
data=torch.tensor([[-1,0.5,2],[-1,0.5,3]])
t1=soft_max(data)#将预测数据转换为概率!!!
#此处为重点
t2=cross_entropyloss(t1,torch.tensor([1,2]))
print(t2)
------------------------------------------
#PyTorch中的原函数
crossentropyloss=nn.CrossEntropyLoss()
t3=crossentropyloss(data,torch.tensor([1,2]))
print(t3)
-------------------------------------------
结果:
tensor(0.9185)
tensor(0.9185)
当然,在实际进行训练时,肯定是一个batch一个batch的进行,也就是一次输入几十张甚至上百张图片。所以理解上面的程序是非常必要的。
基于使问题简化的原则,程序的数据为图片三分类问题的两个样本预测数据(与第二问无任何关系)
程序描述:程序中的数据如下
注:(未对pred进行softmax操作,也就是在神经网络的最后一个全连接层后未加softmax操作)
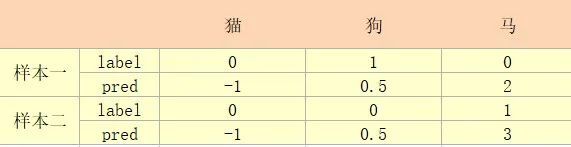
解释: [1]可写为[0,1,0],也就是说明预测值为[-1,0.5,2]的样本属于第二个类别,为狗。
[2]可写为[0,0,1], 也就是说明预测值为[-1,0.5,3]的样本属于第三个类别,为马。
手动计算过程:
第一步:既然要计算交叉熵,那么就要将这些预测数据转换为概率,也就是进行softmax操作,如果这些数据原本就是概率,则直接进行第二步
[-1,0.5,2]—————— [0.0391, 0.1753, 0.7856]
[-1,0.5,3]—————— [0.0166, 0.0746, 0.9088]
第二步:
loss1=-(0xlog(0.0391)+1xlog(0.1753)+0xlog(0.7856))=1.7413
loss2=-(0xlog(0.0166)+0xlog(0.0746)+1xlog(0.9088))=0.0956
loss=(loss1+loss2)/2=0.9185
注:上述式中的log函数默认是自然对数
我的公众号:Math and Code
欢迎关注!